
Chapter 27. Putting It All Together
For there isn’t a job on the top of the earth the beggar don’t know, nor do.
In this chapter we create a complete program. Every step of the process is covered, from setting forth the requirements to testing the result.
Requirements
Before we start, we need to decide what we are going to do. This is a very important step and is left out of far too many programming cycles.
This chapter’s program must fulfill several requirements. First, it must be long enough to demonstrate modular programming, but at the same time short enough to fit inside a single chapter. Second, it must be complex enough to demonstrate a wide range of C++ features, but simple enough for a novice C++ programmer to understand.
Finally, it must be useful. This is not so simple to define. What’s useful to one person might not be useful to another. We decided to refine this requirement and restate it as “It must be useful to C++ programmers.” The program we have selected reads C++ source files and generates simple statistics on the nesting of parentheses and the ratio of comments to code lines.
The specification for our statistics program is:
Preliminary Specification for a C++ Statistics Gathering Program Steve Oualline February 10, 2002
The program stat gathers
statistics about C++ source files and prints them. The command line
is:
stat fileswhere files is a list of
source files. Example 27-1
shows the output of the program on a short test file.
1 ( 0 { 0 #include <iostream>
2 ( 0 { 0
3 ( 0 { 0 int result; // the result of the calculations
4 ( 0 { 0 char oper_char; // operator the user specified
5 ( 0 { 0 int value; // value specified after the operator
6 ( 0 { 0
7 ( 0 { 0 int main( )
8 ( 0 { 1 {
9 ( 0 { 1 result = 0; // initialize the result
10 ( 0 { 1
11 ( 0 { 1 // loop forever (or until break reached)
12 ( 0 { 2 while (true) {
13 ( 0 { 2 std::cout << "Result: " << result << '
';
14 ( 0 { 2 std::cout << "Enter operator and number: ";
15 ( 0 { 2
16 ( 0 { 2 std::cin >> oper_char >> value;
17 ( 0 { 2
18 ( 0 { 2 if ((oper_char == 'q') || (oper_char == 'Q'))
19 ( 0 { 2 break;
20 ( 0 { 2
21 ( 0 { 3 if (oper_char == '+') {
22 ( 0 { 3 result += value;
23 ( 0 { 3 } else if (oper_char == '-') {
24 ( 0 { 3 result -= value;
25 ( 0 { 3 } else if (oper_char == '*') {
26 ( 0 { 3 result *= value;
27 ( 0 { 3 } else if (oper_char == '/') {
28 ( 0 { 4 if (value == 0) {
29 ( 0 { 4 std::cout << "Error:Divide by zero
";
30 ( 0 { 4 std::cout << " operation ignored
";
31 ( 0 { 3 } else
32 ( 0 { 3 result /= value;
33 ( 0 { 3 } else {
34 ( 0 { 3 std::cout << "Unknown operator " << oper_char << '
';
35 ( 0 { 2 }
36 ( 0 { 1 }
37 ( 0 { 1 return (0);
38 ( 0 { 0 }
Total number of lines: 38
Maximum nesting of ( ) : 2
Maximum nesting of {} : 4
Number of blank lines .................6
Number of comment only lines ..........1
Number of code only lines .............27
Number of lines with code and comments 4
Comment to code ratio 16.1%Code Design
There are several schools of code design. In structured programming, you divide the code into modules, the module into submodules, the submodules into subsubmodules, and so on. This is also known as procedure-oriented programming. In object-oriented programming, you try to think of the problem as a collection of data that you manipulate through member functions.
There are also other approaches, such as state tables and transition diagrams. All of these have the same basic principle at heart: “Arrange the program’s information in the clearest and simplest way possible and try to turn it into C++ code.”
Our program breaks down into several logical modules. First, there is a token scanner, which reads raw C++ code and turns it into tokens. Actually, this function sub-divides into two smaller modules. The first reads the input stream and determines what type of character we have. The second takes in character-type information and uses it to assemble tokens. The other module contains the statistics gathering and a small main program.
Token Module
Our program scans C++ source code and uses the tokens to generate statistics. A token is a group of characters that form a single word, number, or symbol. For example, the line:
answer = (123 + 456) / 89; // Compute some sort of result
consists of the tokens:
T_ID The word "answer" T_OPERATOR The character "=" T_L_PAREN Left parenthesis T_NUMBER The number 123 T_OPERATOR The character "+" T_NUMBER The number 456 T_R_PAREN Right parenthesis T_OPERATOR The divide operator T_NUMBER The number 89 T_OPERATOR The semicolon T_COMMENT The // comment T_NEW_LINE The end-of-line character
Our token module needs to identify groups of characters. For example, an identifier is defined as a letter or underscore, followed by any number of letters or digits. Our tokenizer thus needs to contain the pseudocode:
If the current character is a letter then
scan until we get a character that's not a letter or digitAs you can see from the pseudocode, our tokenizer depends a great deal on character types, so we need a module to help us with the type information.
Character-Type Module
The purpose of the character-type module is to read characters
and decode their types. Some types overlap. For example, C_ALPHA_NUMERIC includes the C_NUMERIC character set. This module
stores most of the type information in an array and requires only a
little logic to handle the special types like C_ALPHA_NUMERIC.
Statistics Class
In this program, a statistic is an object that consumes tokens and outputs statistics. We start by defining an abstract class for our statistics. This class is used as the basis for the statistics we are collecting. The class diagram can be seen in Figure 27-1.
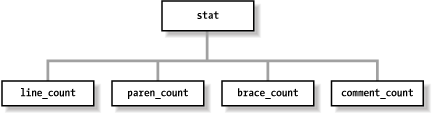
Our definition of a statistic is “something that uses tokens to collect statistics.” These statistics may be printed at the beginning of each line or at the end of the file.
Our four statistics are more specific. For example, the class
paren_counter counts the nesting
of parentheses as well as the maximum nesting. The current nesting
is printed at the beginning of each line (the “(” number). The
maximum nesting level is written out at the end of the file.
The other classes are defined in a similar manner. The only
trick used here is that we’ve made the line numbering a statistic.
It counts the number of T_NEW_LINE tokens and outputs that count
at the start of each line.
Coding
The coding process was fairly simple. The only problem that came up was getting the end-of-line correct.
Functional Description
This section describes all the classes and major functions in our program. For a more complete and detailed description, take a look at the listings at the end of this chapter.
char_type Class
The char_type class sets
the type of a character. For the most part, this is done through a
table named type_info. Some
types, such as C_ALPHA_NUMERIC,
include two different types of characters, C_ALPHA and C_DIGIT. Therefore, in addition to our
table, we need a little code for the special cases.
input_file Class
This class reads data from the input file one character at a time. It buffers a line and on command writes the line to the output.
token Class
We want an input stream of tokens. We have an input stream
consisting of characters. The main function of this class, next_token, turns characters into tokens.
Actually, our tokenizer is rather simple, because we don’t have to
deal with most of the details that a full C++ tokenizer must
handle.
The coding for this function is fairly straightforward, except for the fact that it
breaks up multiline comments into a series of T_COMMENT and T_NEW_LINE tokens.
One clever trick is used in this section. The TOKEN_LIST macro is used to generate an
enumerated list of token types and a string array containing the
names of each of the tokens. Let’s examine how this is done in more
detail.
The definition of the TOKEN_LIST class is:
#define TOKEN_LIST
T(T_NUMBER), /* Simple number (floating point or integer) */
T(T_STRING), /* String or character constant */
T(T_COMMENT), /* Comment */
T(T_NEWLINE), /* Newline character */
T(T_OPERATOR), /* Arithmetic operator */
T(T_L_PAREN), /* Character "(" */
T(T_R_PAREN), /* Character ")" */
T(T_L_CURLY), /* Character "{" */
T(T_R_CURLY), /* Character "}" */
T(T_ID), /* Identifier */
T(T_EOF) /* End of File */When invoked, this macro will generate the code:
T(T_NUMBER), T(T_STRING), // .. and so on
If we define a T macro, it
will be expanded when the TOKEN_LIST macro is expanded. We would
like to use the TOKEN_LIST macro
to generate a list of names, so we define the T macro as:
#define T(x) x // Define T( ) as the name
Now, our TOKEN_LIST macro
will generate:
T_NUMBER, T_STRING, // .. and so on
Putting all this together with a little more code, we get a
way to generate a TOKEN_TYPE
enum list:
#define T(x) x // Define T( ) as the name
enum TOKEN_TYPE {
TOKEN_LIST
};
#undef T // Remove old temporary macroLater we redefine T so it
generates a string:
#define T(x) #x // Define x as a string
This allows us to use TOKEN_LIST to generate a list of strings
containing the names of the tokens:
#define T(x) #x // Define x as a string
const char *const TOKEN_NAMES[] = {
TOKEN_LIST
};
#undef T // Remove old temporary macroWhen expanded, this macro generates:
const char *const TOKEN_NAMES[] = {
"T_NUMBER",
"T_STRING",
//....Using tricks like this is acceptable in limited cases. However, such tricks should be extensively commented so the maintenance programmer who has to fix your code can understand what you did.
stat Class
stat class is an
abstract class that is used as a basis for the four real statistics
we are collecting. It starts with a member function to consume
tokens. This function is a pure virtual function, which means that
any derived classes must define the function take_token:
class stat {
public:
virtual void take_token(TOKEN_TYPE token) = 0;The function take_token
generates statistics from tokens. We need some way of printing them
in two places. The first is at the beginning of each line, and the
second is at the end of the file. Our abstract class contains two
virtual functions to handle these two cases:
virtual void line_start( ) {};
virtual void eof( ) {};
};Unlike take_token, these
functions have default bodies—empty bodies, but bodies just the
same. What does this mean? Our derived classes
must define take_token. They don’t have to define
line_start or eof.
line_counter Class
The simplest statistic we collect is a count of the number of lines processed so far. This counting
is done through the line_counter
class. The only token it cares about is T_NEW_LINE. At the beginning of each line
it outputs the line number (the current count of the T_NEW_LINE tokens). At the end of file,
this class outputs nothing. As a matter of fact, the line_counter class doesn’t even define an
eof function. Instead, we let the
default in the base class (stat)
do the “work.”
brace_counter Class
This class keeps track of the nesting level of the curly braces { }. We feed the class a stream of
tokens through the take_token
member function. This function keeps track of the left and right
curly braces and ignores everything else:
// Consume tokens, count the nesting of {}
void brace_counter::take_token(TOKEN_TYPE token) {
switch (token) {
case T_L_CURLY:
++cur_level;
if (cur_level > max_level)
max_level = cur_level;
break;
case T_R_CURLY:
--cur_level;
break;
default:
// Ignore
break;
}
}The results of this statistic are printed in two places. The first is at the beginning of each line. The second is at the end-of-file. We define two member functions to print these statistics:
// Output start of line statistics
// namely the current line number
void brace_counter::line_start( ) {
std::cout.setf(ios::left);
std::cout.width(2);
std::cout << '{' << cur_level << ' ';
std::cout.unsetf(std::ios::left);
std::cout.width( );
}
// Output eof statistics
// namely the total number of lines
void brace_counter::eof( ) {
std::cout << "Maximum nesting of {} : " << max_level << '
';
}paren_counter Class
This class is very similar to the brace_counter class. As a matter of fact,
it was created by copying the brace_counter class and performing a few
simple edits.
We probably should combine the paren_counter class and the brace_counter class into one class that
uses a parameter to tell it what to count. Oh well, something for
the next version.
comment_counter Class
In this class, we keep track of lines with comments in them, lines with code in them, lines with both comments and code, and lines with none. The results are printed at the end of file.
do_file Procedure
The do_file procedure reads
each file one token at a time, and sends them to the take_token routine for every statistic
class. But how does it know what statistics classes to use? There is
a list:
static line_counter line_count; // Counter of lines
static paren_counter paren_count; // Counter of ( ) levels
static brace_counter brace_count; // Counter of {} levels
static comment_counter comment_count; // Counter of comment info
// A list of the statistics we are collecting
static stat *stat_list[] = {
&line_count,
&paren_count,
&brace_count,
&comment_count,
NULL
};A couple of things should be noted about this list: although
line_count, paren_count, brace_count, and comment_count are all different types,
they are all based on the type stat. This means that we can put them in
an array called stat_list. This
design also makes it easy to add another statistic to the list. All
we have to do is define a new class and put a new entry in the
stat_list.
Testing
To test this program, we came up with a small C++ program that contains every different type of possible token. The results are shown in Example 27-2.
/********************************************************
* This is a mult-line comment *
* T_COMMENT, T_NEWLINE *
********************************************************/
const int LINE_MAX = 500; // T_ID, T_OPERATOR, T_NUMBER
// T_L_PAREN, T_R_PAREN
static void do_file( const char *const name)
{
// T_L_CURLY
char *name = "Test" // T_STRING
// T_R_CURLY
}
// T_EOFRevisions
As it stands, the program collects a very limited set of statistics. It might be nice to add things like average identifier size, per-procedure statistics, and pre-class statistics. One thing we kept in mind when we designed our program is the need for expandability.
We stopped our statistics collection at four types of statistics because we had fulfilled our mission to demonstrate a reasonable, advanced set of C++ constructs. We didn’t add more because it would make the program too complex to fit in the chapter. On the whole, the program does its job well.
A Final Warning
Just because you can generate a statistic doesn’t mean it’s useful.
Program Files
The following examples contain the complete listing of our program, by file. They are listed here for reference:
Example | File |
The ch_type.h file | |
The ch_type.cpp file | |
The token.h file | |
The token.cpp file | |
The stat.cpp file | |
Unix Makefile for CC (Generic Unix) | |
Unix Makefile for g++ | |
Borland-C++ Makefile | |
Microsoft Visual C++ Makefile |
/********************************************************
* char_type -- Character type class *
* *
* Member functions: *
* type -- returns the type of a character. *
* (Limited to simple types) *
* is(ch, char_type) -- check to see if ch is *
* a member of the given type. *
* (Works for derrived types as well.) *
********************************************************/
class char_type {
public:
enum CHAR_TYPE {
C_EOF, // End of file character
C_WHITE, // Whitespace or control character
C_NEWLINE, // A newline character
C_ALPHA, // A Letter (includes _)
C_DIGIT, // A Number
C_OPERATOR, // Random operator
C_SLASH, // The character '/'
C_L_PAREN, // The character '('
C_R_PAREN, // The character ')'
C_L_CURLY, // The character '{'
C_R_CURLY, // The character '}'
C_SINGLE, // The character '''
C_DOUBLE, // The character '"'
// End of simple types, more complex, derrived types follow
C_HEX_DIGIT,// Hexidecimal digit
C_ALPHA_NUMERIC // Alpha numeric
};
private:
static enum CHAR_TYPE type_info[256]; // Information on each character
// Fill in a range of type info stuff
void fill_range(int start, int end, CHAR_TYPE type);
public:
char_type( ); // Initialize the data
// ~char_type -- default destructor
// Returns true if character is a given type
int is(int ch, CHAR_TYPE kind);
CHAR_TYPE type(int ch);
};/********************************************************
* ch_type package *
* *
* The class ch_type is used to tell the type of *
* various characters. *
* *
* The main member functions are: *
* is -- True if the character is the indicated *
* type. *
* type -- Return type of character. *
********************************************************/
#include <iostream>
#include <cassert>
#include "ch_type.h"
// Define the type information array
char_type::CHAR_TYPE char_type::type_info[256];
/********************************************************
* fill_range -- fill in a range of types for the *
* character type class *
* *
* Parameters *
* start, end -- range of items to fill in *
* type -- type to use for filling *
********************************************************/
void char_type::fill_range(int start, int end, CHAR_TYPE type)
{
int cur_ch;
for (cur_ch = start; cur_ch <= end; ++cur_ch) {
assert(cur_ch >= 0);
assert(cur_ch < sizeof(type_info)/sizeof(type_info[0]));
type_info[cur_ch] = type;
}
}
/*********************************************************
* char_type::char_type -- initialize the char type table*
*********************************************************/
char_type::char_type( )
{
fill_range(0, 255, C_WHITE);
fill_range('A', 'Z', C_ALPHA);
fill_range('a', 'z', C_ALPHA);
type_info['_'] = C_ALPHA;
fill_range('0', '9', C_DIGIT);
type_info['!'] = C_OPERATOR;
type_info['#'] = C_OPERATOR;
type_info['$'] = C_OPERATOR;
type_info['%'] = C_OPERATOR;
type_info['^'] = C_OPERATOR;
type_info['&'] = C_OPERATOR;
type_info['*'] = C_OPERATOR;
type_info['-'] = C_OPERATOR;
type_info['+'] = C_OPERATOR;
type_info['='] = C_OPERATOR;
type_info['|'] = C_OPERATOR;
type_info['~'] = C_OPERATOR;
type_info[','] = C_OPERATOR;
type_info[':'] = C_OPERATOR;
type_info['?'] = C_OPERATOR;
type_info['.'] = C_OPERATOR;
type_info['<'] = C_OPERATOR;
type_info['>'] = C_OPERATOR;
type_info['/'] = C_SLASH;
type_info['
'] = C_NEWLINE;
type_info['('] = C_L_PAREN;
type_info[')'] = C_R_PAREN;
type_info['{'] = C_L_CURLY;
type_info['}'] = C_R_CURLY;
type_info['"'] = C_DOUBLE;
type_info['''] = C_SINGLE;
}
int char_type::is(int ch, CHAR_TYPE kind)
{
if (ch == EOF) return (kind == C_EOF);
switch (kind) {
case C_HEX_DIGIT:
assert(ch >= 0);
assert(ch < sizeof(type_info)/sizeof(type_info[0]));
if (type_info[ch] == C_DIGIT)
return (1);
if ((ch >= 'A') && (ch <= 'F'))
return (1);
if ((ch >= 'a') && (ch <= 'f'))
return (1);
return (0);
case C_ALPHA_NUMERIC:
assert(ch >= 0);
assert(ch < sizeof(type_info)/sizeof(type_info[0]));
return ((type_info[ch] == C_ALPHA) ||
(type_info[ch] == C_DIGIT));
default:
assert(ch >= 0);
assert(ch < sizeof(type_info)/sizeof(type_info[0]));
return (type_info[ch] == kind);
}
};
char_type::CHAR_TYPE char_type::type(const int ch) {
if (ch == EOF) return (C_EOF);
assert(ch >= 0);
assert(ch < sizeof(type_info)/sizeof(type_info[0]));
return (type_info[ch]);
}#include <string>
#include <iostream>
/********************************************************
* token -- token handling module *
* *
* Functions: *
* next_token -- get the next token from the input *
********************************************************/
/*
* A list of tokens
* Note, how this list is used depends on defining the macro T.
* This macro is used for defining the tokens types themselves
* as well as the string version of the tokens.
*/
#define TOKEN_LIST
T(T_NUMBER), /* Simple number (floating point or integer) */
T(T_STRING), /* String or character constant */
T(T_COMMENT), /* Comment */
T(T_NEWLINE), /* Newline character */
T(T_OPERATOR), /* Arithmetic operator */
T(T_L_PAREN), /* Character "(" */
T(T_R_PAREN), /* Character ")" */
T(T_L_CURLY), /* Character "{" */
T(T_R_CURLY), /* Character "}" */
T(T_ID), /* Identifier */
T(T_EOF) /* End of File */
/*
* Define the enumerated list of tokens.
* This makes use of a trick using the T macro
* and our TOKEN_LIST
*/
#define T(x) x // Define T( ) as the name
enum TOKEN_TYPE {
TOKEN_LIST
};
#undef T // Remove old temporary macro
// A list of the names of the tokens
extern const char *const TOKEN_NAMES[];
/********************************************************
* input_file -- data from the input file *
* *
* The current two characters are store in *
* cur_char and next_char *
* *
* The member function read_char moves eveyone up *
* one character. *
* *
* The line is buffered and output everytime a newline *
* is passed. *
********************************************************/
class input_file: public std::ifstream {
private:
std::string line; // Current line
public:
int cur_char; // Current character (can be EOF)
int next_char; // Next character (can be EOF)
/*
* Initialize the input file and read the first 2
* characters.
*/
input_file(const char *const name) :
std::ifstream(name),
line("")
{
if (bad( ))
return;
cur_char = get( );
next_char = get( );
}
/*
* Write the line to the screen
*/
void flush_line( ) {
std::cout << line;
std::cout.flush( );
line = "";
}
/*
* Advance one character
*/
void read_char( ) {
line += cur_char;
cur_char = next_char;
next_char = get( );
}
};
/********************************************************
* token class *
* *
* Reads the next token in the input stream *
* and returns its type. *
********************************************************/
class token {
private:
// True if we are in the middle of a comment
int in_comment;
// True if we need to read a character
// (This hack is designed to get the new lines right)
int need_to_read_one;
// Read a /* */ style comment
TOKEN_TYPE read_comment(input_file& in_file);
public:
token( ) {
in_comment = false;
need_to_read_one = 0;
}
// Return the next token in the stream
TOKEN_TYPE next_token(input_file& in_file);
};/********************************************************
* token -- token handling module *
* *
* Functions: *
* next_token -- get the next token from the input *
********************************************************/
#include <fstream>
#include <cstdlib>
#include "ch_type.h"
#include "token.h"
/*
* Define the token name list
* This makes use of a trick using the T macro
* and our TOKEN_LIST
*/
#define T(x) #x // Define x as a string
const char *const TOKEN_NAMES[] = {
TOKEN_LIST
};
#undef T // Remove old temporary macro
static char_type char_type; // Character type information
/********************************************************
* read_comment -- read in a comment *
* *
* Parameters *
* in_file -- file to read *
* *
* Returns *
* Token read. Can be a T_COMMENT or T_NEW_LINE *
* depending on what we read. *
* *
* Multi-line comments are split into multiple *
* tokens. *
********************************************************/
TOKEN_TYPE token::read_comment(input_file& in_file)
{
if (in_file.cur_char == '
') {
in_file.read_char( );
return (T_NEWLINE);
}
while (true) {
in_comment = true;
if (in_file.cur_char == EOF) {
std::cerr << "Error: EOF inside comment
";
return (T_EOF);
}
if (in_file.cur_char == '
')
return (T_COMMENT);
if ((in_file.cur_char == '*') &&
(in_file.next_char == '/')) {
in_comment = false;
// Skip past the ending */
in_file.read_char( );
in_file.read_char( );
return (T_COMMENT);
}
in_file.read_char( );
}
}
/********************************************************
* next_token -- read the next token in an input stream *
* *
* Parameters *
* in_file -- file to read *
* *
* Returns *
* next token *
********************************************************/
TOKEN_TYPE token::next_token(input_file& in_file)
{
if (need_to_read_one)
in_file.read_char( );
need_to_read_one = 0;
if (in_comment)
return (read_comment(in_file));
while (char_type.is(in_file.cur_char, char_type::C_WHITE)) {
in_file.read_char( );
}
if (in_file.cur_char == EOF)
return (T_EOF);
switch (char_type.type(in_file.cur_char)) {
case char_type::C_NEWLINE:
in_file.read_char( );
return (T_NEWLINE);
case char_type::C_ALPHA:
while (char_type.is(in_file.cur_char,
char_type::C_ALPHA_NUMERIC))
in_file.read_char( );
return (T_ID);
case char_type::C_DIGIT:
in_file.read_char( );
if ((in_file.cur_char == 'X') || (in_file.cur_char == 'x')) {
in_file.read_char( );
while (char_type.is(in_file.cur_char,
char_type::C_HEX_DIGIT)) {
in_file.read_char( );
}
return (T_NUMBER);
}
while (char_type.is(in_file.cur_char, char_type::C_DIGIT))
in_file.read_char( );
return (T_NUMBER);
case char_type::C_SLASH:
// Check for /* characters
if (in_file.next_char == '*') {
return (read_comment(in_file));
}
// Now check for double slash comments
if (in_file.next_char == '/') {
while (true) {
// Comment starting with // and ending with EOF is legal
if (in_file.cur_char == EOF)
return (T_COMMENT);
if (in_file.cur_char == '
')
return (T_COMMENT);
in_file.read_char( );
}
}
// Fall through
case char_type::C_OPERATOR:
in_file.read_char( );
return (T_OPERATOR);
case char_type::C_L_PAREN:
in_file.read_char( );
return (T_L_PAREN);
case char_type::C_R_PAREN:
in_file.read_char( );
return (T_R_PAREN);
case char_type::C_L_CURLY:
in_file.read_char( );
return (T_L_CURLY);
case char_type::C_R_CURLY:
in_file.read_char( );
return (T_R_CURLY);
case char_type::C_DOUBLE:
while (true) {
in_file.read_char( );
// Check for end of string
if (in_file.cur_char == '"')
break;
// Escape character, then skip the next character
if (in_file.cur_char == '')
in_file.read_char( );
}
in_file.read_char( );
return (T_STRING);
case char_type::C_SINGLE:
while (true) {
in_file.read_char( );
// Check for end of character
if (in_file.cur_char == ''')
break;
// Escape character, then skip the next character
if (in_file.cur_char == '')
in_file.read_char( );
}
in_file.read_char( );
return (T_STRING);
default:
assert("Internal error: Very strange character" != 0);
}
assert("Internal error: We should never get here" != 0);
return (T_EOF); // Should never get here either
}/********************************************************
* stat *
* Produce statistics about a program *
* *
* Usage: *
* stat [options] <file-list> *
* *
********************************************************/
#include <iostream>
#include <fstream>
#include <iomanip>
#include <cstdlib>
#include <cstring>
#include <cassert>
#include "ch_type.h"
#include "token.h"
/********************************************************
* stat -- general purpose statistic *
* *
* Member functions: *
* take_token -- receives token and uses it to *
* compute statistic *
* line_start -- output stat at the beginning of *
* a line. *
* eof -- output stat at the end of the file *
********************************************************/
class a_stat {
public:
virtual void take_token(TOKEN_TYPE token) = 0;
virtual void line_start( ) {};
virtual void eof( ) {};
// Default constructor
// Default destructor
// Copy constructor defaults as well (probably not used)
};
/********************************************************
* line_counter -- handle line number / line count *
* stat. *
* *
* Counts the number of T_NEW_LINE tokens seen and *
* output the current line number at the beginning *
* of the line. *
* *
* At EOF it will output the total number of lines *
********************************************************/
class line_counter: public a_stat {
private:
int cur_line; // Line number for the current line
public:
// Initialize the line counter -- to zero
line_counter( ) {
cur_line = 0;
};
// Default destrctor
// Default copy constructor (probably never called)
// Consume tokens, count the number of new line tokens
void take_token(TOKEN_TYPE token) {
if (token == T_NEWLINE)
++cur_line;
}
// Output start of line statistics
// namely the current line number
void line_start( ) {
std::cout << std::setw(4) << cur_line << ' ' << std::setw(0);
}
// Output eof statistics
// namely the total number of lines
void eof( ) {
std::cout << "Total number of lines: " << cur_line << '
';
}
};
/********************************************************
* paren_count -- count the nesting level of ( ) *
* *
* Counts the number of T_L_PAREN vs T_R_PAREN tokens *
* and writes the current nesting level at the beginning*
* of each line. *
* *
* Also keeps track of the maximum nesting level. *
********************************************************/
class paren_counter: public a_stat {
private:
int cur_level; // Current nesting level
int max_level; // Maximum nesting level
public:
// Initialize the counter
paren_counter( ) {
cur_level = 0;
max_level = 0;
};
// Default destructor
// Default copy constructor (probably never called)
// Consume tokens, count the nesting of ( )
void take_token(TOKEN_TYPE token) {
switch (token) {
case T_L_PAREN:
++cur_level;
if (cur_level > max_level)
max_level = cur_level;
break;
case T_R_PAREN:
--cur_level;
break;
default:
// Ignore
break;
}
}
// Output start of line statistics
// namely the current line number
void line_start( ) {
std::cout.setf(std::ios::left);
std::cout.width(2);
std::cout << '(' << cur_level << ' ';
std::cout.unsetf(std::ios::left);
std::cout.width( );
}
// Output eof statistics
// namely the total number of lines
void eof( ) {
std::cout << "Maximum nesting of ( ) : " << max_level << '
';
}
};
/********************************************************
* brace_counter -- count the nesting level of {} *
* *
* Counts the number of T_L_CURLY vs T_R_CURLY tokens *
* and writes the current nesting level at the beginning*
* of each line. *
* *
* Also keeps track of the maximum nesting level. *
* *
* Note: brace_counter and paren_counter should *
* probably be combined. *
********************************************************/
class brace_counter: public a_stat {
private:
int cur_level; // Current nesting level
int max_level; // Maximum nesting level
public:
// Initialize the counter
brace_counter( ) {
cur_level = 0;
max_level = 0;
};
// Default destructor
// Default copy constructor (probably never called)
// Consume tokens, count the nesting of ( )
void take_token(TOKEN_TYPE token) {
switch (token) {
case T_L_CURLY:
++cur_level;
if (cur_level > max_level)
max_level = cur_level;
break;
case T_R_CURLY:
--cur_level;
break;
default:
// Ignore
break;
}
}
// Output start of line statistics
// namely the current line number
void line_start( ) {
std::cout.setf(std::ios::left);
std::cout.width(2);
std::cout << '{' << cur_level << ' ';
std::cout.unsetf(std::ios::left);
std::cout.width( );
}
// Output eof statistics
// namely the total number of lines
void eof( ) {
std::cout << "Maximum nesting of {} : " << max_level << '
';
}
};
/********************************************************
* comment_counter -- count the number of lines *
* with and without comments. *
* *
* Outputs nothing at the beginning of each line, but *
* will output a ratio at the end of file *
* *
* Note: This class makes use of two bits: *
* CF_COMMENT -- a comment was seen *
* CF_CODE -- code was seen *
* to collect statistics. *
* *
* These are combined to form an index into the counter *
* array so the value of these two bits is very *
* important. *
********************************************************/
static const int CF_COMMENT = (1<<0); // Line contains comment
static const int CF_CODE = (1<<1); // Line contains code
// These bits are combined to form the statistics
//
// 0 -- [0] Blank line
// CF_COMMENT -- [1] Comment only line
// CF_CODE -- [2] Code only line
// CF_COMMENT|CF_CODE -- [3] Comments and code on this line
class comment_counter: public a_stat {
private:
int counters[4]; // Count of various types of stats.
int flags; // Flags for the current line
public:
// Initialize the counters
comment_counter( ) {
memset(counters, '�', sizeof(counters));
flags = 0;
};
// Default destructor
// Default copy constructor (probably never called)
// Consume tokens, count the nesting of ( )
void take_token(TOKEN_TYPE token) {
switch (token) {
case T_COMMENT:
flags |= CF_COMMENT;
break;
default:
flags |= CF_CODE;
break;
case T_NEWLINE:
assert(flags >= 0);
assert(flags < sizeof(counters)/sizeof(counters[0]));
++counters[flags];
flags = 0;
break;
}
}
// void line_start( ) -- defaults to base
// Output eof statistics
// namely the total number of lines
void eof( ) {
std::cout << "Number of blank lines ................." <<
counters[0] << '
';
std::cout << "Number of comment only lines .........." <<
counters[1] << '
';
std::cout << "Number of code only lines ............." <<
counters[2] << '
';
std::cout << "Number of lines with code and comments " <<
counters[3] << '
';
std::cout.setf(std::ios::fixed);
std::cout.precision(1);
std::cout << "Comment to code ratio " <<
float(counters[1] + counters[3]) /
float(counters[2] + counters[3]) * 100.0 << "%
";
}
};
static line_counter line_count; // Counter of lines
static paren_counter paren_count; // Counter of ( ) levels
static brace_counter brace_count; // Counter of {} levels
static comment_counter comment_count; // Counter of comment info
// A list of the statistics we are collecting
static a_stat *stat_list[] = {
&line_count,
&paren_count,
&brace_count,
&comment_count,
NULL
};
/********************************************************
* do_file -- process a single file *
* *
* Parameters *
* name -- the name of the file to process *
********************************************************/
static void do_file(const char *const name)
{
input_file in_file(name); // File to read
token token; // Token reader/parser
TOKEN_TYPE cur_token; // Current token type
class a_stat **cur_stat; // Pointer to stat for collection/writing
if (in_file.bad( )) {
std::cerr << "Error: Could not open file " <<
name << " for reading
";
return;
}
while (true) {
cur_token = token.next_token(in_file);
for (cur_stat = stat_list; *cur_stat != NULL; ++cur_stat)
(*cur_stat)->take_token(cur_token);
#ifdef DEBUG
assert(cur_token >= 0);
assert(cur_token < sizeof(TOKEN_NAMES)/sizeof(TOKEN_NAMES[0]));
std::cout << " " << TOKEN_NAMES[cur_token] << '
';
#endif /* DEBUG */
switch (cur_token) {
case T_NEWLINE:
for (cur_stat = stat_list; *cur_stat != NULL; ++cur_stat)
(*cur_stat)->line_start( );
in_file.flush_line( );
break;
case T_EOF:
for (cur_stat = stat_list; *cur_stat != NULL; ++cur_stat)
(*cur_stat)->eof( );
return;
default:
// Do nothing
break;
}
}
}
int main(int argc, char *argv[])
{
char *prog_name = argv[0]; // Name of the program
if (argc == 1) {
std::cerr << "Usage is " << prog_name << "[options] <file-list>
";
exit (8);
}
for (/* argc set */; argc > 1; --argc) {
do_file(argv[1]);
++argv;
}
return (0);
}#
# Makefile for many Unix compilers using the
# "standard" command name CC
#
CC=CC
CFLAGS=-g
OBJS= stat.o ch_type.o token.o
all: stat.out stat
stat.out: stat
stat ../calc3/calc3.cpp >stat.out
stat: $(OBJS)
$(CC) $(CCFLAGS) -o stat $(OBJS)
stat.o: stat.cpp token.h
$(CC) $(CCFLAGS) -c stat.cpp
ch_type.o: ch_type.cpp ch_type.h
$(CC) $(CCFLAGS) -c ch_type.cpp
token.o: token.cpp token.h ch_type.h
$(CC) $(CCFLAGS) -c token.cpp
clean:
rm stat stat.o ch_type.o token.o#
# Makefile for the Free Software Foundations g++ compiler
#
CC=g++
CCFLAGS=-g -Wall
OBJS= stat.o ch_type.o token.o
all: stat.out stat
stat.out: stat
stat ../calc3/calc3.cpp >stat.out
stat: $(OBJS)
$(CC) $(CCFLAGS) -o stat $(OBJS)
stat.o: stat.cpp token.h
$(CC) $(CCFLAGS) -c stat.cpp
ch_type.o: ch_type.cpp ch_type.h
$(CC) $(CCFLAGS) -c ch_type.cpp
token.o: token.cpp token.h ch_type.h
$(CC) $(CCFLAGS) -c token.cpp
clean:
rm stat stat.o ch_type.o token.o#
# Makefile for Borland's Borland-C++ compiler
#
CC=bcc32
#
# Flags
# -N -- Check for stack overflow
# -v -- Enable debugging
# -w -- Turn on all warnings
# -tWC -- Console application
#
CFLAGS=-N -v -w -tWC
OBJS= stat.obj ch_type.obj token.obj
all: stat.out stat.exe
stat.out: stat.exe
stat ..calc3calc3.cpp >stat.out
stat.exe: $(OBJS)
$(CC) $(CCFLAGS) -estat $(OBJS)
stat.obj: stat.cpp token.h
$(CC) $(CCFLAGS) -c stat.cpp
ch_type.obj: ch_type.cpp ch_type.h
$(CC) $(CCFLAGS) -c ch_type.cpp
token.obj: token.cpp token.h ch_type.h
$(CC) $(CCFLAGS) -c token.cpp
clean:
erase stat.exe stat.obj ch_type.obj token.obj#
# Makefile for Microsoft Visual C++
#
CC=cl
#
# Flags
# AL -- Compile for large model
# Zi -- Enable debugging
# W1 -- Turn on warnings
#
CFLAGS=/AL /Zi /W1
OBJS= stat.obj ch_type.obj token.obj
all: stat.out stat.exe
stat.out: stat.exe
stat ..calc3calc3.cpp >stat.out
stat.exe: $(OBJS)
$(CC) $(CCFLAGS) $(OBJS)
stat.obj: stat.cpp token.h
$(CC) $(CCFLAGS) -c stat.cpp
ch_type.obj: ch_type.cpp ch_type.h
$(CC) $(CCFLAGS) -c ch_type.cpp
token.obj: token.cpp token.h ch_type.h
$(CC) $(CCFLAGS) -c token.cpp
clean:
erase stat.exe stat.obj ch_type.obj token.objProgramming Exercises
Exercise 27-1: Write a program that checks a text file for doubled words.
Exercise 27-2: Write a program that removes vulgar words from a file and replaces them with more acceptable equivalents.
Exercise 27-3: Write a mailing-list program. This program will read, write, sort and print mailing labels.
Exercise 27-4: Update the statistics program presented in this chapter to add a cross-reference capability.
Exercise 27-5: Write a program that takes a text file and splits each long line into two smaller lines. The split point should be at the end of a sentence if possible, or at the end of a word if a sentence is too long.