
Chapter 23. Modular Programming
Many hands make light work.
So far, we have been dealing with small programs. As programs grow larger and larger, they should be split into sections, or modules. C++ allows programs to be split into multiple files, compiled separately, and then combined (linked) to form a single program.
In this chapter, we go through a programming example, discussing
the C++ techniques needed to create good modules. You also are shown how
to use make to put these modules
together to form a program.
Modules
A module is a collection of functions or classes that perform
related functions. For example, there could be a module to handle
database functions such as lookup,
enter, and sort. Another module could handle complex
numbers, and so on.
Also, as programming problems get big, more and more programmers are needed to finish them. An efficient way of splitting up a large project is to assign each programmer a different module. That way each programmer only has to worry about the internal details of her own code.
In this chapter, we discuss a module to handle infinite arrays. The functions in this package allow the user to store data in an array without worrying about the array’s size. The infinite array grows as needed (limited only by the amount of memory in the computer). The infinite array will be used to store data for a histogram, but it can also be used to store things such as line numbers from a cross-reference program or other types of data.
Public and Private
Modules are divided into two parts, public and private. The public part tells the user how to call the functions in the module and contains the definitions of data structures and functions that are to be used from outside the module. The public definitions are put in a header file, which is included in the user’s program. In the infinite array example, we have put the public declarations in the file ia.h (see listing in Example 23-2).
Anything internal to the module is private. Everything that is not directly usable by the outside world should be kept private.
The extern Storage Class
The extern storage class is used to indicate that a variable or function is defined outside the current file but is used in this file. Example 23-1 illustrates a simple use of the extern modifier.
#include <iostream>
/* number of times through the loop */
extern int counter;
/* routine to increment the counter */
extern void inc_counter( );
int main( )
{
int index; /* loop index */
for (index = 0; index < 10; ++index)
inc_counter( );
std::cout << "Counter is " << counter << '
';
return (0);
}/* number of times through the loop */
int counter = 0;
/* trivial example */
void inc_counter( )
{
++counter;
}The function main uses the
variable counter. Because counter is not defined in main, it is defined in the file
count.cpp. The extern declaration is used by
main.cpp to indicate that counter is declared somewhere else, in this
case the file count.cpp. The modifier extern is not used in this file, because this
is the “real” declaration of the variable.
Actually, three storage class identifiers can be used to indicate the files in which a variable is defined, as shown in Table 23-1.
Notice that the keyword static
has two meanings. (It is the most overworked keyword in the C++
language. For a complete list of the meanings of static see Table 14-1.) For data defined
globally, static means “private to
this file.” For data defined inside a function, it means “variable is
allocated from static memory (instead of the temporary stack).”
C++ is very liberal in its use of the rules for static ,
extern, and <blank> storage
classes. It is possible to declare a variable as extern at the beginning of a program and later
define it as <blank>.
extern sam; int sam = 1; // This is legal
This ability is useful when you have all your external variables defined in a header file. The program includes the header file (and defines the variables as extern), and then defines the variable for real.
Another problem concerns declaring a variable in two different files.
File: main.cpp int flag = 0; // Flag is off int main( ) { std::cout << "Flag is " << flag << ' '; } File: sub.cpp int flag = 1; // Flag is on
What happens in this case? There are several possibilities:
flagcould be initialized to 0 because main.cpp is loaded first.flagcould be initialized to 1 because the entry in sub.cpp overwrites the one in main.cpp.I don’t know, but whatever it is, it’s probably bad.
In this case, there is only one global variable called flag. It will be initialized to either 1 or
0 depending on the whims of the compiler. (The good ones generate an
error.) It is entirely possible for the program main to print out:
flag is 1
even though we initialized it to 0. To avoid the problem of hidden initializations, use the keyword static to limit the scope of variables to the file in which they are declared.
Say we wrote the following:
File: main.cpp static int flag = 0; // Flag is off int main( ) { std::cout << "Flag is " << flag << ' '; } File: sub.cpp static int flag = 1; // Flag is on
In this case, flag in
main.cpp is an entirely different variable from
flag in
sub.cpp. However, you should still give the
variables
different names to avoid
confusion.
Headers
Information that is shared between modules should be put in a header file. By convention, all header filenames end with “.h”. In the infinite array example, we use the file ia.h.
The header should contain all the public information, such as:
A comment section describing clearly what the module does and what is available to the user
Public class declarations
Common constants
Public structures
Prototypes of all the public functions
extern declarations for public variables
In the infinite array example, more than half the file ia.h is devoted to comments. This commenting is not excessive; the real guts of the coding is hidden in the program file ia.cpp. The ia.h file serves both as a program file and as documentation to the outside world.
Notice that there is no mention in the ia.h comments about how the infinite array is implemented. At this level, we don’t care how something is done, just what functions are available.
/********************************************************
* definitions for the infinite array (ia) class *
* *
* An infinite array is an array whose size can grow *
* as needed. Adding more elements to the array *
* will just cause it to grow. *
*------------------------------------------------------*
* class infinite_array *
* Member functions *
* infinite_array( ) -- default constructor *
* ~infinite_array( ) -- destructor *
* int& operator [](int index) *
* gets an element of the infinite array *
********************************************************/
#include <string.h>
// number of elements to store in each cell of the infinite array
const unsigned int BLOCK_SIZE = 10;
class infinite_array {
private:
// the data for this block
int data[BLOCK_SIZE];
// pointer to the next array
class infinite_array *next;
public:
// Default constructor
infinite_array( )
{
next = NULL;
memset(data, '�', sizeof(data));
}
// Default destructor
~infinite_array( );
// Return a reference to an element of the array
int& operator[] (const unsigned int index);
};A few things should be noted about this file. Everything in the file is a constant definition, a data structure declaration, or an external declaration. Any code that is defined is inline. No actual code or storage is defined in the header file.
The Body of the Module
The body of the module contains all the functions and data for that module. Private functions that are not to be called from outside the module should be declared static. Variables declared outside of a function that are not used outside the module are declared static.
A Program to Use Infinite Arrays
The infinite array structure is shown in Figure 23-1. The program uses a simple linked list to store the elements of the array. A linked list can grow longer as needed (until you run out of memory). Each list element, or bucket, can store 10 numbers. To find element 38, the program starts at the beginning, skips past the first three buckets, and extracts element 8 from the data in the current bucket.
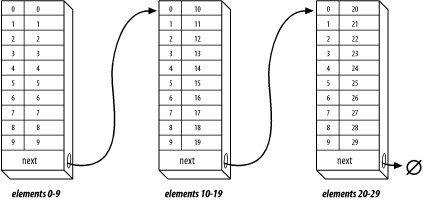
Example 23-4 contains the code for module ia.cpp.
/********************************************************
* infinite-array -- routines to handle infinite arrays *
* *
* An infinite array is an array that grows as needed. *
* There is no index too large for an infinite array *
* (unless we run out of memory). *
********************************************************/
#include <iostream>
#include <cstdlib>
#include <cassert>
#include "ia.h" // get common definitions
/********************************************************
* operator [] -- find an element of an infinite array *
* *
* Parameters *
* index -- index into the array *
* *
* Returns *
* Reference to the element in the array *
********************************************************/
int& infinite_array::operator [] (const unsigned int index)
{
// pointer to the current bucket
class infinite_array *current_ptr;
unsigned int current_index; // Index we are working with
current_ptr = this;
current_index = index;
while (current_index >= BLOCK_SIZE) {
if (current_ptr->next == NULL) {
current_ptr->next = new infinite_array;
if (current_ptr->next == NULL) {
std::cerr << "Error:Out of memory
";
exit(8);
}
}
current_ptr = current_ptr->next;
current_index -= BLOCK_SIZE;
}
assert(current_index >= 0);
assert(current_index <
sizeof(current_ptr->data)/sizeof(current_ptr->data[0]));
return (current_ptr->data[current_index]);
}
/********************************************************
* ~infinite_array -- Destroy the infinite array *
********************************************************/
infinite_array::~infinite_array( )
{
/*
* Note: We use a cute trick here.
*
* Because each bucket in the infinite array is
* an infinite array itself, when we destroy
* next, it will destroy all that bucket's "next"s
* and so on recusively clearing the entire array.
*/
if (next != NULL) {
delete next;
next = NULL;
}
}The Makefile for Multiple Files
The utility make is
designed to aid the programmer in compiling and linking programs. Before
make, the programmer had to type
compile commands explicitly each time there was a change in the
program:
g++ -Wall -g -ohello hello.cpp
Tip
In this chapter we use the commands for the GNU g++ compiler. The C++ compiler on your system may have a different name and a slightly different syntax.
As programs grow, the number of commands needed to create them
grows. Typing in a series of 10 or 20 commands is tiresome and
error-prone, so programmers started writing shell
scripts (or, in MS-DOS, .BAT
files). Then all the programmer had to type was
do-it and the computer would
compile everything. This was overkill, however, because all the files
were recompiled regardless of need.
As the number of files in a project grew, this recompiling became a significant problem. Changing one small file, starting the compilation, and then having to wait until the next day while the computer executed several hundred compile commands was frustrating—especially when only one compile was really needed.
The program make was created
to do intelligent compiles. Its purpose is to
first decide what commands need to be executed and then execute
them.
The file Makefile (upper/lowercase is
important in Unix) contains the rules used by make to decide how to build the program. The
Makefile contains the following sections:
Comments
Macros
Explicit rules
Default rules
Any line beginning with a # is a comment.
A macro has the format:
| name = data |
Name is any valid identifier.
Data is the text that will be substituted
whenever make sees
$(name).
Here’s an example:
#
# Very simple Makefile
#
MACRO = Doing All
all:
echo $(MACRO)Explicit rules tell make what
commands are needed to create the program. These rules can take
several forms. The most common is:
target :
source
[ source2 ]
[ source3 ]
|
command
|
[
command ]
|
[
command ]
|
| . . . |
Target is the name of a file to create. It is “made,” or created, out of the source file source. If the target is created out of several files, they are all listed.
The command used to create the target is listed on the next line. Sometimes it takes more than one command to create the target. Commands are listed one per line. Each is indented by a tab.
For example, the rule:
hello: hello.cpp
g++ -Wall -g -o hello hello.cpptells make to create the file
hello from the file
hello.cpp using the command:
g++ -Wall -g -o hello hello.cpp
make will create
hello only if necessary. The files used in the
creation of hello, arranged in chronological
order (by modification time), are shown in Table
23-2.
Unix | MS-DOS/Windows | Modification time |
hello.cpp | HELLO.CPP | Oldest |
hello.o | HELLO.OBJ | Old |
hello | HELLO.EXE | Newest |
If the programmer changes the source file
hello.cpp, the file’s modification time will be
out of date with respect to the other files. make will sense this and re-create the other
files.
Another form of the explicit rule is:
source :
|
command
|
[
command ]
|
In this case, the commands are executed each time make is run, unconditionally.
If the commands are omitted from an explicit rule, make uses a set of built-in rules to
determine what command to execute.
For example, the rule:
hist.o: ia.h hist.cpp
tells make to create
hist.o from hist.cpp and
ia.h, using the standard rule for making
<file>.o from
<file>.cpp. This rule is:
g++ $(CFLAGS) -c
file .cpp |
(make predefines the macro
$(CFLAGS).)
We are going to create a main program hist.cpp that calls the module ia.cpp. Both files include the header ia.h, so they depend on it. The Unix Makefile that creates the program hist from hist.cpp and ia.cpp is listed in Example 23-5.
#
# Makefile for many Unix compilers using the
# "standard" command name CC
#
CC=CC
CFLAGS=-g
SRC=ia.cpp hist.cc
OBJ=ia.o hist.o
all: hist
hist: $(OBJ)
$(CC) $(CFLAGS) -o hist $(OBJ)
hist.o: ia.h hist.cpp
$(CC) $(CFLAGS) -c hist.cpp
ia.o: ia.h ia.cpp
$(CC) $(CFLAGS) -c ia.cpp
clean:
rm hist io.o hist.oThe macro SRC is a list of
all the C++ files. OBJ is a list of
all the object (.o) files. The lines:
hist: $(OBJ)
g++ $(CFLAGS) -o hist $(OBJ)tell make to create
hist from the object files. If any of the
object files are out of date, make
will re-create them.
The line:
hist.o:ia.h
tells make to create
hist.o from ia.h and
hist.cpp (hist.cpp is
implied). Because no command is specified, the default is used.
Example 23-6 shows the
Makefile for MS-DOS/Windows, using
Borland-C++.
#
# Makefile for Borland's Borland-C++ compiler
#
CC=bcc32
#
# Flags
# -N -- Check for stack overflow
# -v -- Enable debugging
# -w -- Turn on all warnings
# -tWC -- Console application
#
CFLAGS=-N -v -w -tWC
SRC=ia.cpp hist.cpp
OBJ=ia.obj hist.obj
all: hist.exe
hist.exe: $(OBJ)
$(CC) $(CFLAGS) -ehist $(OBJ)
hist.obj: ia.h hist.cpp
$(CC) $(CFLAGS) -c hist.cpp
ia.obj: ia.h ia.cpp
$(CC) $(CFLAGS) -c ia.cpp
clean:
erase hist.exe io.obj hist.objThere is one big drawback with make. It only checks to see whether the
files have changed, not the rules. If you have compiled your entire
program with CFLAGS = -g for
debugging and need to produce the production version (CFLAGS = -O), make will not
recompile.
The Unix command touch changes the
modification date of a file. (It doesn’t change the file; it just
makes the operating system think it did.) If you touch a source file such as
hello.cpp and then run make, the program will be re-created. This
is useful if you have changed the compile-time flags and want to force
a recompilation.
Make provides a rich set of
commands for creating
programs. Only a few have
been discussed here.[1]
Using the Infinite Array
The histogram program (hist) is designed to use the infinite array
package. It takes one file as its argument. The file contains a list
of numbers between 0 and 99. Any number of entries may be used. The
program prints a histogram showing how many times each number appears.
(A histogram is a graphic representation of the frequency of data.)
This file contains a number of interesting programming techniques.
The first one technique is to let the computer do the work whenever possible. For example, don’t program like this:
const int LENGTH_X = 300; // Width of the box in dots const int LENGTH_Y = 400; // Height of the box in dots const int AREA = 12000; // Total box area in dots
In this case, the programmer has decided to multiply 300 by 400 to compute the area. He would be better served by letting the computer do the multiplying:
const int LENGTH_X = 300; // Width of the box in dots const int LENGTH_Y = 400; // Height of the box in dots const int AREA = (LENGTH_X * LENGTH_Y); // Total box area in dots
That way, if either LENGTH_X
or LENGTH_Y is changed, AREA changes automatically. Also, the
computer is more accurate in its computations. (If you noticed, the
programmer made an error: his AREA
is too small by a factor of 10.)
In the histogram program, the number of data points in each output line is computed by the following definition:
const float FACTOR = ((HIGH_BOUND - LOW_BOUND) / (float)(NUMBER_OF_LINES));
The user should be helped whenever possible. In the hist program, if the user does not type the
correct number of parameters on the command line, a message appears
telling what is wrong and how to correct it.
The program uses the library routine memset to initialize
the counters array. This routine is
highly efficient for setting all values of an array to zero. The
line:
memset(counters, '�', sizeof(counters));
zeros the entire array counters. sizeof(counters) makes sure the entire array
is zeroed. Example 23-7
contains a program that uses the infinite array for storing data used
to produce a histogram.
/********************************************************
* hist -- generate a histogram of an array of numbers *
* *
* Usage *
* hist <file> *
* *
* Where *
* file is the name of the file to work on *
********************************************************/
#include <iostream>
#include <fstream>
#include <iomanip>
#include <cstdlib>
#include <cassert>
#include "ia.h"
/*
* the following definitions define the histogram
*/
const int NUMBER_OF_LINES = 50; // # Lines in the result
const int LOW_BOUND = 0; // Lowest number we record
const int HIGH_BOUND = 99; // Highest number we record
/*
* if we have NUMBER_OF_LINES data to
* output then each item must use
* the following factor
*/
const int FACTOR =
((HIGH_BOUND - LOW_BOUND +1) / NUMBER_OF_LINES);
// number of characters wide to make the histogram
const int WIDTH = 60;
// Array to store the data in
static infinite_array data_array;
// Number of items in the array
static int data_items;
int main(int argc, char *argv[])
{
void read_data(const char *const name);// get the data into the array
void print_histogram( );// print the data
if (argc != 2) {
std::cerr << "Error:Wrong number of arguments
";
std::cerr << "Usage is:
";
std::cerr << " hist <data-file>
";
exit(8);
}
data_items = 0;
read_data(argv[1]);
print_histogram( );
return (0);
}
/********************************************************
* read_data -- read data from the input file into *
* the data_array. *
* *
* Parameters *
* name -- the name of the file to read *
********************************************************/
void read_data(const char *const name)
{
std::ifstream in_file(name); // input file
int data; // data from input
if (in_file.bad( )) {
std::cerr << "Error:Unable to open " << name << '
';
exit(8);
}
while (!in_file.eof( )) {
in_file >> data;
// If we get an eof we ran out of data in last read
if (in_file.eof( ))
break;
// No assert needed becuase data_array is an ia
data_array[data_items] = data;
++data_items;
}
}
/********************************************************
* print_histogram -- print the histogram output. *
********************************************************/
void print_histogram( )
{
// upper bound for printout
int counters[NUMBER_OF_LINES];
int low; // lower bound for printout
int out_of_range = 0;// number of items out of bounds
int max_count = 0;// biggest counter
float scale; // scale for outputting dots
int index; // index into the data
memset(counters, '�', sizeof(counters));
for (index = 0; index < data_items; ++index) {
int data;// data for this point
data = data_array[index];
if ((data < LOW_BOUND) || (data > HIGH_BOUND))
++out_of_range;
else {
// index into counters array
int count_index;
count_index = static_cast<int>(
static_cast<float>(data - LOW_BOUND) / FACTOR);
assert(count_index >= 0);
assert(count_index < sizeof(counters)/sizeof(counters[0]));
++counters[count_index];
if (counters[count_index] > max_count)
max_count = counters[count_index];
}
}
scale = float(max_count) / float(WIDTH);
low = LOW_BOUND;
for (index = 0; index < NUMBER_OF_LINES; ++index) {
// index for outputting the dots
int char_index;
int number_of_dots; // number of * to output
std::cout << std::setw(2) << index << ' ' <<
std::setw(3) << low << "-" <<
std::setw(3) << (low + FACTOR -1) << " (" <<
std::setw(4) << counters[index] << "): ";
number_of_dots = int(float(counters[index]) / scale);
for (char_index = 0; char_index < number_of_dots;
++char_index)
std::cout << '*';
std::cout << '
';
low += FACTOR;
}
std::cout << out_of_range << " items out of range
";
}A sample run of this program produces the following output:
% hist test 0: 0- 2 ( 100): ************************ 1: 2- 4 ( 200): ************************************************ 2: 4- 6 ( 100): ************************ 3: 6- 8 ( 100): ************************ 4: 8- 10 ( 0): 5: 10- 12 ( 100): ************************ 6: 12- 14 ( 50): ************ 7: 14- 16 ( 150): ************************************ 8: 16- 18 ( 50): ************ 9: 18- 20 ( 50): ************ 10: 20- 22 ( 100): ************************ 11: 22- 24 ( 100): ************************ 12: 24- 26 ( 50): ************ 13: 26- 28 ( 100): ************************ 14: 28- 30 ( 50): ************ 15: 30- 32 ( 100): ************************ 16: 32- 34 ( 50): ************ 17: 34- 36 ( 0): 18: 36- 38 ( 100): ************************ 19: 38- 40 ( 1): 20: 40- 42 ( 150): ************************************ 21: 42- 44 ( 50): ************ 22: 44- 46 ( 250): ************************************************************ 23: 46- 48 ( 100): ************************ 24: 48- 51 ( 150): ************************************ 25: 51- 53 ( 100): ************************ 26: 53- 55 ( 50): ************ 27: 55- 57 ( 200): ************************************************ 28: 57- 59 ( 50): ************ 29: 59- 61 ( 50): ************ 30: 61- 63 ( 50): ************ 31: 63- 65 ( 150): ************************************ 32: 65- 67 ( 100): ************************ 33: 67- 69 ( 0): 34: 69- 71 ( 199): *********************************************** 35: 71- 73 ( 200): ************************************************ 36: 73- 75 ( 100): ************************ 37: 75- 77 ( 50): ************ 38: 77- 79 ( 100): ************************ 39: 79- 81 ( 100): ************************ 40: 81- 83 ( 200): ************************************************ 41: 83- 85 ( 100): ************************ 42: 85- 87 ( 0): 43: 87- 89 ( 0): 44: 89- 91 ( 50): ************ 45: 91- 93 ( 150): ************************************ 46: 93- 95 ( 100): ************************ 47: 95- 97 ( 50): ************ 48: 97- 99 ( 100): ************************ 49: 99-101 ( 0): 500 items out of range
Dividing a Task into Modules
Unfortunately, computer programming is more of an art than a science. There are no hard and fast rules that tell you how to divide a task into modules. Knowing what makes a good module and what doesn’t comes with experience and practice.
This section describes some general rules for module division and how they can be applied to real-world programs. The techniques described here have worked well for me. You should use whatever works for you.
Information is a vital part of any program. The key to a program is your decision about what information you want to use and what processing you want to perform on it. Be sure to analyze the information flow before you begin the design.
Design the modules to minimize the amount of information that has to pass between them. If you look at the organization of the Army, for example, you’ll see that it is divided up into modules. There is the infantry, artillery, tank corps, and so on. The amount of information that passes between these modules is minimized. For example, if an infantry sergeant wants the artillery to bombard an enemy position, he calls up artillery command and says, “There’s a pillbox at location Y-94. Get rid of it.” The artillery command handles all the details of deciding which battery to use, how much firepower to allocate based on the requirements of other fire missions, maintaining supplies, and many more details.[2]
Programs should be organized the same way. Information that can be kept inside a module should be. Minimizing the amount of intermodule communication cuts down on communication errors and limits maintenance problems that occur when a module is upgraded.
Module Design Guidelines
Although there are no strict rules when it comes to laying out the modules for a program, here are some general guidelines:
Programming Exercises
Exercise 23-1: Write a class that handles page formatting. It
should contain the following functions:
open_file(char *name)Opens the print file.
define_header(char *heading)Defines heading text.
print_line(char *line)Sends a line to the file.
page( )Starts a new page.
close_file( )Closes the print file.
Exercise 23-2: Write a module
called search_open that receives an
array of filenames, searches the array until it finds one that exists,
and opens that file.
Exercise 23-3: Write a symbol table class containing the following functions:
void enter(const std::string& name)Enters a name into the symbol table.
int lookup(const std::string& name)Returns 1 if the name is in the table; returns 0 otherwise.
void remove(const std::string& name)Removes a name from the symbol table.
Exercise 23-4: Take the words program from Chapter 20, and combine it with the infinite array module to create a cross-reference program. (As an added bonus, teach it about C++ comments and strings to create a C++ cross-referencer.)
[1] If you are going to create programs that require more than 10 or 20 source files, it is suggested you read the book Managing Projects with make (O’Reilly & Associates, Inc.).
[2] This is a very general diagram of the division of an ideal army. The system used by the United States Army is more complex and so highly classified that even the generals don’t know how it works.