
1 Privacy considerations in machine learning
- The importance of privacy protection in the era of big data artificial intelligence
- Types of privacy-related threats, vulnerabilities, and attacks in machine learning
- Techniques that can be utilized in machine learning tasks to minimize or evade privacy risks and attacks
Our search queries, browsing history, purchase transactions, watched videos, and movie preferences are a few types of information that are collected and stored daily. Advances in artificial intelligence have increased the ability to capitalize on and benefit from the collection of private data.
This data collection happens within our mobile devices and computers, on the streets, and even in our own offices and homes, and the data is used by a variety of machine learning (ML) applications in different domains, such as marketing, insurance, financial services, mobility, social networks, and healthcare. For instance, more and more cloud-based data-driven ML applications are being developed by different service providers (who can be classified as the data users, such as Facebook, LinkedIn, and Google). Most of these applications leverage the vast amount of data collected from each individual (the data owner) to offer users valuable services. These services often give users some commercial or political advantage by facilitating various user recommendations, activity recognition, health monitoring, targeted advertising, or even election predictions. However, on the flip side, the same data could be repurposed to infer sensitive (private) information, which would jeopardize the privacy of individuals. Moreover, with the increased popularity of Machine Learning as a Service (MLaaS), where cloud-based ML and computing resources are bundled together to provide efficient analytical platforms (such as Microsoft Azure Machine Learning Studio, AWS Machine Learning, and Google Cloud Machine Learning Engine), it is necessary to take measures to enforce privacy on those services before they are used with sensitive datasets.
1.1 Privacy complications in the AI era
Let’s first visit a real-world example of private data leakage to visualize the problem. During the Facebook-Cambridge Analytica scandal in April 2018, data from about 87 million Facebook users was collected by a Facebook quiz app (a cloud-based data-driven application) and then paired with information taken from those users’ social media profiles (including their gender, age, relationship status, location, and “likes”) without any privacy-preserving operations being taken other than anonymization. How did this happen?
The quiz, called “This Is Your Digital Life,” was originally created by Aleksandr Kogan, a Russian psychology professor at the University of Cambridge. The quiz was designed to collect personality information, and around 270,000 people were paid to take part. However, in addition to what the quiz was created to collect, it also pulled data from the participants’ friends’ profiles, making a large data pile. Later, Kogan shared this information in a commercial partnership with Cambridge Analytica, which harvested personal information from this dataset, such as where users lived and what pages they liked, eventually helping Cambridge Analytica to build psychological profiles and infer certain sensitive information about each individual, such as their identity, sexual orientation, and marital status, as summarized in figure 1.1.
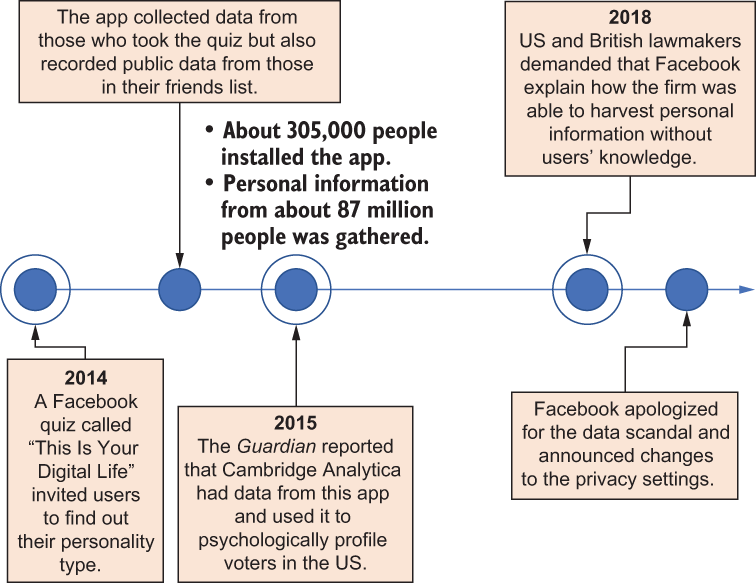
Figure 1.1 The Facebook-Cambridge Analytica scandal raised the alarm about privacy concerns.
That was just one incident! In 2020, after another privacy scandal, Facebook agreed to pay $550 million to settle a class-action lawsuit over its use of ML-based facial recognition technology, which again raised questions about the social network’s data-mining practices. The suit said the company violated an Illinois biometric privacy law by harvesting facial data for tag suggestions from the photos of millions of users in the state without their permission and without telling them how long the data would be kept. Eventually, Facebook disabled the tag-suggestion feature amid privacy concerns.
These unprecedented data leak scandals raised the alarm about privacy concerns in cloud-based data-driven applications. People began to think twice before submitting any data to cloud-based services. Thus, data privacy has become a hotter topic than ever before among academic researchers and technology companies, which have put enormous efforts into developing privacy-preserving techniques to prevent private data leaks. For instance, Google developed Randomized Aggregatable Privacy-Preserving Ordinal Response (RAPPOR), a technology for crowdsourcing statistics from end-user client software. Apple also claimed it first introduced its well-developed privacy techniques with iOS 11, for crowdsourcing statistics from iPhone users regarding emoji preferences and usage analysis. In 2021 Google introduced its privacy sandbox initiative to the Chrome web browser by replacing third-party cookies and putting boundaries around how advertising companies could interact with private data used in the browser. When people use the internet, publishers and advertisers want to provide content, including ads, that is relevant and interesting to them. People’s interests are often gauged on today’s web by observing what sites or pages they visit, relying on third-party cookies or less transparent and undesirable mechanisms like device fingerprinting. With this privacy sandbox initiative, Google introduced a new way to provide relevant content and ads by clustering large groups of people with similar browsing patterns, hiding individuals in the crowd and keeping their web histories on their browsers, without using third-party cookies.
1.2 The threat of learning beyond the intended purpose
ML can be seen as the capability of an algorithm to mimic intelligent human behavior, performing complex tasks by looking at data from different angles and analyzing it across domains. This learning process is utilized by various applications in our day-to-day life, from product recommendation systems in online web portals to sophisticated intrusion detection mechanisms in internet security applications.
1.2.1 Use of private data on the fly
ML applications require vast amounts of data from various sources to produce high confidence results. Web search queries, browsing histories, transaction histories of online purchases, movie preferences, and individual location check-ins are some of the information collected and stored on a daily basis, usually without users’ knowledge. Some of this information is private to the individuals, but it is uploaded to high-end centralized servers mostly in clear-text format so ML algorithms can extract patterns and build ML models from it.
The problem is not limited to the collection of this private data by different ML applications. The data is also exposed to insider attacks because the information is available to workers at data-mining companies. For example, database administrators or application developers may have access to this data without many restrictions. This data may also be exposed to external hacking attacks, with private information being revealed to the outside world. For instance, in 2015 Twitter fired an engineer after intelligence officials found that he might have been spying on the accounts of Saudi dissidents by accessing user details such as phone numbers and IP addresses. According to the New York Times, the accounts belonged to security and privacy researchers, surveillance specialists, policy academics, and journalists. This incident is yet another example of how big the problem is. Most importantly, it is possible to extract additional information from private data even if it is transformed to a different embedding (anonymized), or if datasets and ML models are inaccessible and only the testing results are revealed.
1.2.2 How data is processed inside ML algorithms
To understand the relationship between data privacy and ML algorithms, knowing how ML systems work with the data they process is crucial. Typically, we can represent the input data for an ML algorithm (captured from various sources) as a set of sample values, and each sample can be a group of features. Let’s take the example of a facial recognition algorithm that recognizes people when they upload an image to Facebook. Consider an image of 100 × 100 pixels where a single value from 0 to 255 represents each pixel. These pixels can be concatenated to form a feature vector. Each image can be represented to the ML algorithm as a vector of data, along with an associated label for that data. The ML algorithm would use multiple feature vectors and their associated labels during the training phase to produce an ML model. This model would then be used with fresh, unseen data (testing samples) to predict the result—in this case, to recognize a person.
1.2.3 Why privacy protection in ML is important
When personal information is used for a wrong or unintended purpose, it can be manipulated to gain a competitive advantage. When massive volumes of personal records are coupled with ML algorithms, no one can predict what new results they may produce or how much private information those results may reveal. The Facebook-Cambridge Analytica scandal discussed earlier is a perfect example of the wrongful use of personal data.
Hence, when designing ML algorithms for an application, ensuring privacy protection is vital. First, it ensures that other parties (data users) cannot use the personal data for their own advantage. Second, everyone has things that they do not want others to know. For example, they may not want others to know the details of their medical history. But ML applications are data driven, and we need training samples to build a model. We want to use the private data to build a model, but we want to prevent the ML algorithm from learning anything sensitive. How can we do that?
Let’s consider a scenario where we use two databases: a sanitized medical database that lists patients’ histories of medication prescriptions, and another data source with user information and pharmacies visited. When these sources are linked together, the correlated database can have additional knowledge, such as which patient bought their medication from which pharmacy. Suppose we are using this correlated dataset with an ML application to extract relationships between the patients, medications, and pharmacies. While it will extract the obvious relations between different diseases and the medications prescribed, it may also learn roughly where the patient resides simply by referring to the zip codes of their most-visited pharmacies, even if the data does not contain patient addresses. This is a simple example, but you can imagine how severe the consequences could be if privacy is not protected.
1.2.4 Regulatory requirements and the utility vs. privacy tradeoff
Traditionally, data security and privacy requirements were set by the data owners (such as organizations) to safeguard the competitive advantage of the products and services they offered. However, in the big data era, data has become the most valuable asset in the digital economy, and governments imposed many privacy regulations to prevent the use of sensitive information beyond its intended purpose. Privacy standards such as HIPAA (Health Insurance Portability and Accountability Act of 1996), PCI DSS (Payment Card Industry Data Security Standard), FERPA (Family Educational Rights and Privacy Act), and the European Union’s GDPR (General Data Protection Regulation) are some of the privacy regulations that organizations commonly adhere to. For example, regardless of the size of practice, most healthcare providers transmit health information electronically, such as for claims, medication records, benefit eligibility inquiries, referral authorization requests, and the like. However, HIPAA regulations require that these healthcare providers protect sensitive patient health information from being disclosed without the patient’s consent or knowledge.
Regardless of whether the data is labeled or not, or whether raw data is preprocessed, ML models are essentially very sophisticated statistics based on the training dataset, and ML algorithms are optimized to squeeze every bit of utility out of the data. Therefore, in most conditions, they are capable of learning sensitive attributes in the dataset, even when that is not the intended task. When we attempt to preserve privacy, we want to prevent these algorithms from learning sensitive attributes. Hence, as you can see, utility and privacy are on opposite ends of the spectrum. When you tighten privacy, it can affect the performance of the utility.
The real challenge is balancing privacy and performance in ML applications so that we can better utilize the data while ensuring the privacy of the individuals. Because of the regulatory and application-specific requirements, we cannot degrade privacy protection just to increase the utility of the application. On the other hand, privacy has to be implemented systematically without using arbitrary mechanisms, as many additional threats must be considered. ML applications are prone to different privacy and security attacks. We will explore these potential attacks in detail next and look at how we can mitigate them by designing privacy-preserving ML (PPML) algorithms.
1.3 Threats and attacks for ML systems
We discussed a few privacy leakage incidents in the previous section, but many other threats and attacks on ML systems are being proposed and discussed in the literature and could potentially be deployed in real-world scenarios. For instance, figure 1.2 is a time-line showing a list of threats and attacks for ML systems, including de-anonymization (re-identification) attacks, reconstruction attacks, parameter inference attacks, model inversion attacks, and membership inference attacks. We will briefly explore the details of these threats or attacks in this section.

Figure 1.2 A timeline of threats and attacks identified for ML systems
Although some leading companies, such as Google and Apple, started designing and utilizing their own privacy-preserving methodologies for ML tasks, it is still a challenge to improve public awareness of these privacy technologies, mainly due to the lack of well-organized tutorials and books that explain the concepts methodically and systematically.
1.3.1 The problem of private data in the clear
Figure 1.3 illustrates a typical client/server application scenario. As you can see, when an application collects private information, that information is often transferred, possibly through encrypted channels, to cloud-based servers where the learning happens. In the figure, a mobile application connects to a cloud server to perform an inference task.

Figure 1.3 The problem of storing private data in cleartext format
For example, a parking app may send the user’s location data to find a nearby available garage. Even though the communication channel is secured, the data most likely resides in the cloud in its original unencrypted form or as features extracted from the original record. This is one of the biggest challenges to privacy because that data is susceptible to various insider and outsider attacks.
1.3.2 Reconstruction attacks
As you’ve seen, it is essential to store private data on the server in encrypted form, and we should not send raw data directly to the server in its original form. However, reconstruction attacks pose another possible threat: the attacker could reconstruct data even without having access to the complete set of raw data on the server. In this case, the adversary gains an advantage by having external knowledge of feature vectors (the data used to build the ML model).
The adversary usually requires direct access to the ML models deployed on the server, which is referred to as white-box access (see table 1.1). They then try to reconstruct the raw private data by using their knowledge of the feature vectors in the model. These attacks are possible when the feature vectors used during the training phase to build the ML model are not flushed from the server after building the model.
Table 1.1 Difference between white-box, black-box, and grey-box access
|
Has full access to the internal details of the ML models, such as parameters and loss functions |
How reconstruction works: An attacker’s perspective
Now that you’ve had a high-level overview of how a reconstruction attack works, let’s look into the details of how it is possible. The approach taken to reconstruct the data depends on what information (background knowledge) the attacker has available to reproduce the data accurately. We’ll consider the following two use case examples of biometric-based authentication systems:
-
Reconstruction of fingerprint images from a minutiae template—Nowadays, fingerprint-based authentication is prevalent in many organizations: users are authenticated by comparing a newly acquired fingerprint image with a fingerprint image already saved in the user authentication system. In general, these fingerprint-matching systems use one of four different representation schemes known as grayscale, skeleton, phase, and minutiae (figure 1.4). Minutiae-based representation is the most widely adopted due to the compactness of the representation. Because of this compactness, many people erroneously think that the minutiae template does not contain enough information for attackers to reconstruct the original fingerprint image.
In 2011, a team of researchers successfully demonstrated an attack that could reconstruct fingerprint images directly from minutiae templates [1]. They reconstructed a phase image from minutiae, which was then converted into the original (grayscale) image. Next, they launched an attack against fingerprint recognition systems to infer private data.

Figure 1.4 The four different types of representation schemes used in fingerprint matching systems: (a) grayscale image, (b) skeleton image, (c) phase image, and (d) minutiae
-
Reconstruction attacks against mobile-based continuous authentication systems—Al-Rubaie et al. investigated the possibility of reconstruction attacks that used gestural raw data from users’ authentication profiles in mobile-based continuous authentication systems [2]. Continuous authentication is a method of verifying the user not just once but continuously throughout an entire session (such as Face ID in iPhones). Without continuous authentication, organizations are more vulnerable to many attack vectors, such as a system being taken over when it is no longer being used but the session remains open. In such a scenario, a reconstruction attack could use available private information that is leaked to the adversary. At a high level, Al-Rubaie et al. used the feature vectors stored in user profiles to reconstruct the raw data and then used that information to hack into other systems.
In most of these cases, the privacy threat resulted from a security threat to the authentication system in which reconstructed raw data misguided the ML system by forcing it to think that the raw data belonged to a specific user. For example, in the case of mobile-based continuous authentication systems, an attacker gained access to the mobile device and its personal records; hence, the authentication mechanism failed to protect the user’s privacy. Another class of reconstruction attack might reveal private information directly, as you’ll see next.
A real-world scenario involving reconstruction attacks
In 2019, Simson Garfinkel and his team at the US Census Bureau presented a detailed example of how a reconstruction attack can be primed by an attacker, just utilizing data available to the public [3]. They further explained that publishing the frequency count, mean, and median age of a population, broken down by a few demographics, allows anyone with access to the statistics and a personal computer to accurately reconstruct the personal data of almost the entire survey population. This incident raised concerns about the privacy of census data. Based on this finding, the US Census Bureau conducted a series of experiments on 2010 census data. Among 8 billion statistics, 25 data points per person allowed successful reconstruction of confidential records for more than 40% of the US population.
Even though this is not directly related to ML algorithms, you can probably understand how scary the problem is. The vast amount of sensitive data published by statistical agencies each year may provide a determined attacker with more than enough information to reconstruct some or all of the target database and breach the privacy of millions of people. The US Census Bureau has identified this risk and implemented the correct measures to protect the 2020 US Census, but it is important to note that reconstruction is no longer a theoretical danger. It is real.
Now the question is, how can we prevent such attacks from succeeding? In terms of mitigating reconstruction attacks tailored for ML models, the best approach is to avoid storing explicit feature vectors inside the ML model. If the feature vectors are required to be stored (e.g., SVM requires feature vectors and metadata to be stored alongside the model), they should be inaccessible to the users of the ML model so that they are hard to reconstruct. Feature names can at least be anonymized. To mitigate reconstruction attacks targeting database or data mining operations (as in the US Census example), different and well-established data sanitization and disclosure-avoidance techniques can be used.
This discussion has just been a summary of how reconstruction attacks work. We will discuss these techniques and other mitigation strategies in more detail in the forthcoming chapters.
1.3.3 Model inversion attacks
While some ML models store explicit feature vectors, other ML algorithms (such as neural networks and ridge regression) do not keep feature vectors inside the model. In these circumstances, the adversary’s knowledge is limited, but they may still have access to the ML model, as discussed in the white-box access scenario.
In another black-box access scenario, the adversary does not have direct access to the ML model: they can listen for incoming requests to an ML model when a user submits new testing samples and for responses generated by the model. In model inversion attacks, the adversary utilizes the responses generated by the ML model in a way that resembles the original feature vectors used to create the ML model [4]. Figure 1.5 illustrates how a model inversion attack works.
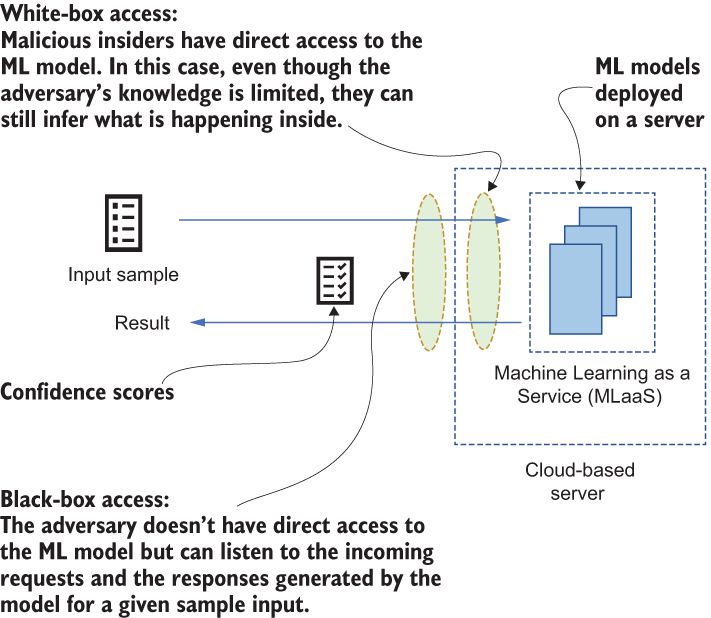
Figure 1.5 The difference between white-box access and black-box access. White-box access requires direct access and permission for the ML model to infer data; black-box access usually involves listening to the communication channel.
Typically, such attacks utilize the confidence values received from the ML model (such as the probability decision score) to generate feature vectors. For example, let’s consider a facial recognition algorithm. When you submit a face image to the algorithm, the algorithm produces a result vector with the class and the corresponding confidence score based on the features it identifies in that image. For now, assume the result vector generated by the algorithm is
[John:.99, Simon:.73, Willey:.65]
What is the meaning of this result? The algorithm is 99% confident (the decision score) that this image belongs to John (the class) and 73% confident that it belongs to Simon, and so on.
What if the adversary can listen to all these communications? Even though they do not have the input image or know whose image it is, they can deduce that they will get a confidence score in this range if they input a similar image. By accumulating results over a certain period, the attacker can produce an average score representing a certain class in the ML model. If the class represents a single individual, as in a facial recognition algorithm, identifying the class could result in a threatening privacy breach. At the beginning of the attack, the adversary does not know who the person is, but by accumulating data over time, they will be able to identify the person, which is serious.
Therefore, the model inversion attack is a severe threat to ML-based systems. Note that in some cases, model inversion attacks can be classified as a subclass of reconstruction attacks, based on how well the features are arranged in raw data.
In mitigating model inversion attacks, limiting the adversary to black-box access is important, because it limits the adversary’s knowledge. In our example of face recognition-based authentication, instead of providing the exact confidence value of a certain ML class, we could round it. Alternatively, only the final predicted class label may be returned, so that it is harder for an adversary to learn anything beyond the specific prediction.
1.3.4 Membership inference attacks
Whereas model inversion attacks do not try to reproduce an actual sample from the training dataset, membership inference attacks try to infer a sample based on the ML model output to identify whether it was in the original training dataset. The idea behind a membership inference attack is that given an ML model, a sample, and domain knowledge, the adversary can determine whether the sample is a member of the training dataset used to build the ML model, as shown in figure 1.6.

Figure 1.6 How membership inference attack works
Let’s consider an ML-based disease diagnosis system by analyzing the input medical information and conditions. For instance, suppose a patient participates in a study that diagnoses the correct difficulty level for a complex game designed to identify people who have Alzheimer’s disease. If an attacker succeeds in carrying out membership inference, they will know whether this patient was in the original dataset used to build the model. Not only that, by knowing the difficulty level of the game, the adversary can deduce whether this patient suffers from Alzheimer’s disease. This scenario describes is a serious leakage of sensitive information that could be used later for targeted action against the patient.
In this kind of attack, the adversary intends to learn whether an individual’s personal record was used to train the original ML model. To do so, the attacker first generates a secondary attack model by utilizing the model’s domain knowledge. Typically, these attack models are trained using shadow models previously generated based on noisy versions of actual data, data extracted from model inversion attacks, or statistics-based synthesis. To train these shadow models, the adversary requires black- or white-box access to the original ML model and sample datasets.
With that, the attacker has access to both the ML service and the attack model. The attacker observes the dissimilarities between the output data produced by ML model predictions used during the training phase and the data not included in the training set [5], as depicted in figure 1.6. Membership inference attempts to learn whether a particular record is in the training dataset, not the dataset itself.
There are a couple of strategies for mitigating membership inference attacks, such as regularization or coarse precision of prediction values. We will discuss these regularization strategies in chapter 8. However, limiting the output of the ML model only to class labels is the most effective way of downgrading the threat. In addition, differential privacy (DP) is an effective resisting mechanism for membership inference attacks, as we’ll discuss in chapter 2.
1.3.5 De-anonymization or re-identification attacks
Anonymizing datasets before releasing them to third-party users is a typical approach to protecting user privacy. In simple terms, anonymization protects private or sensitive information by erasing or changing identifiers that connect an individual to stored data. For example, you can anonymize personally identifiable information such as names, addresses, and social security numbers through a data anonymization process that retains the data but keeps the source anonymous. Some organizations employ various strategies to release only anonymized versions of their datasets for the general public’s use (e.g., public voter databases, Netflix prize dataset, AOL search data, etc.). For example, Netflix published a large dataset of 500,000 Netflix subscribers with anonymized movie ratings by inviting different contestants to perform data mining and propose new algorithms to build better movie recommender systems.
However, even when data is cleared of identifiers, attacks are still possible through de-anonymization. De-anonymization techniques can easily cross-reference publicly available sources and reveal the original information. In 2008, Narayanan et al. demonstrated that even with data anonymization techniques such as k-anonymity, it is possible to infer the private information of individuals [6]. In their attack scenario, they utilized the Internet Movie Database (IMDb) as background knowledge to identify the Netflix records of known users, apparently uncovering users’ political preferences. Thus, simple syntax-based anonymization cannot reliably protect data privacy against strong adversaries. We need to rely on something like differential privacy. We will discuss re-identification attacks in more detail in chapter 8.
1.3.6 Challenges of privacy protection in big data analytics
Apart from the threats and attacks tailored explicitly to ML models and frameworks, another privacy challenge arises at the opposite end of the ML and privacy spectrum. That is, how can we protect data at rest, such as data stored in a database system before it is fed to an ML task, and data in transit, where data flows through various elements in the underlying ML framework? The ongoing move toward larger and connected data reservoirs makes it more challenging for database systems and data analytics tools to protect data against privacy threats.
One of the significant privacy threats in database systems is linking different database instances to explore an individual’s unique fingerprint. This type of attack can be categorized as a subclass of a re-identification attack and is most often an insider attack in terms of database applications. Based on the formation and identification of data, these attacks can be further classified into two types: correlation attacks and identification attacks.
The ultimate purpose of a correlation attack is to find a correlation between two or more data fields in a database or set of database instances to create unique and informative data tuples. As you know, in some cases we can bring domain knowledge from external data sources into the identification process. For example, let’s take a medical records database that lists user information with a history of medication prescriptions. Consider another data source with user information along with pharmacies visited. Once these sources are linked together, the correlated database can include some additional knowledge, such as which patient bought their medication from which pharmacy. Moreover, if it is smart enough to explore the frequently visited pharmacies, an adversary might obtain a rough estimate of where the patient resides. Thus, the final correlated dataset can have more private information per user than the original datasets.
While a correlation attack tries to extract more private information, an identification attack tries to identify a targeted individual by linking entries in a database instance. The idea is to explore more personal information about a particular individual for identification. We can consider this one of the most threatening types of data privacy attacks on a dataset as it affects an individual’s privacy more. For example, suppose an employer looked into all the occurrences of its employees in a medical record or pharmacy customer database. That might reveal lots of additional information about the employees’ medication records, medical treatments, and illnesses. Thus, this attack is an increasing threat to individual privacy.
At this point, it should be clear that we need to have sophisticated mechanisms in data analytics and ML applications to protect individuals’ privacy from different targeted attacks. Using multiple layers of data anonymization and data pseudonymization techniques makes it possible to protect privacy in such a way that linking different datasets is still possible, but identifying an individual by analyzing the data records is challenging. Chapters 7 and 8 provide a comprehensive assessment of different privacy-preserving techniques, a detailed analysis of how they can be used in modern data-driven applications, and a demonstration of how you can implement them in Python.
1.4 Securing privacy while learning from data: Privacy-preserving machine learning
Many privacy-enhancing techniques concentrate on allowing multiple input parties to collaboratively train ML models without releasing the private data in its original form. This collaboration can be performed by utilizing cryptographic approaches (e.g., secure multiparty computation) or differential private data release (perturbation techniques). Differential privacy is especially effective in preventing membership inference attacks. Finally, as discussed previously, the success of model inversion and membership inference attacks can be decreased by limiting the model’s prediction output (e.g., class labels only).
This section introduces several privacy-enhancing techniques at a high level to give you a general understanding of how they work. These techniques include differential privacy, local differential privacy (LDP), privacy-preserving synthetic data generation, privacy-preserving data mining techniques, and compressive privacy. Each will be expanded on later in this book.
1.4.1 Use of differential privacy
The data explosion has resulted in greatly increased amounts of data being held by individuals and entities, such as personal images, financial records, census data, and so on. However, the privacy concern is raised when this data leaves the hands of data owners and is used in some computations. The AOL search engine log attack [7] and Netflix prize contest attacks [8] demonstrate the existence of such threats and emphasize the importance of having privacy-aware ML algorithms.
Differential privacy (DP) is a promising solution for providing privacy protection for data. It attempts to protect an individual’s sensitive information from any inference attacks targeting the statistics or aggregated data of the individual. Publishing only the statistics or aggregated data of multiple people in a dataset does not necessarily ensure privacy protection in many cases. Let’s consider a simple retail use case with a loyalty card scenario. Suppose we have two aggregate statistics: the total amount spent by all customers on a particular day and a subgroup of that—the total amount spent by customers using a loyalty card on the same day. Suppose there is precisely one customer who purchases without a loyalty card. In that case, by simply comparing the difference between two such statistics, someone could easily infer this customer’s total amount spent, based on only those aggregate statistics.
DP is based on the idea that statistics or aggregated data (including ML models) should not reveal whether an individual appears in the original dataset (the training data for the ML models). For example, given two identical datasets, one including an individual’s information and the other without their information, DP ensures that the probability of generating specific statistics or aggregated values is nearly the same whether conducted on the first or the second dataset.
To be more specific, consider a trusted data curator that gathers data from multiple data owners and performs a computation on the data, such as calculating the mean value or finding the maximum or minimum value. To ensure no one can reliably infer any individual sample from the computation result, DP requires the curator to add random noise to the result, such that the released data will not change if any sample of the underlying data changes. Since no single sample can significantly affect the distribution, adversaries cannot confidently infer the information corresponding to any individual sample. Thus, a mechanism is differentially private if the computation result of the data is robust to any change in the individual samples.
Due to its underlying mechanisms, DP techniques resist membership inference attacks by adding random noise to the input data, to iterations of a particular ML algorithm, or to algorithm output. In chapters 2 and 3, we will thoroughly analyze how we can adopt differential privacy in privacy-preserving ML (PPML) applications.
1.4.2 Local differential privacy
When the input parties do not have enough information to train an ML model, it can be better to utilize approaches that rely on local differential privacy (LDP). For instance, multiple cancer research institutions want to build an ML model to diagnose skin lesions, but no single party has enough data to train a model. LDP is one of the solutions that they can use to train an ML model collaboratively without violating individual privacy.
In LDP, individuals send their data to the data aggregator after privatizing data by perturbation. Hence, these techniques provide plausible deniability (an adversary cannot prove that the original data exists) for individuals. The data aggregator collects all the perturbed values and estimates statistics such as the frequency of each value in the population. Compared with DP, LDP shifts the perturbation from the central site to the local data owner. It considers a scenario where there is no trusted third party and an untrustworthy data curator needs to collect data from data owners and perform certain computations. The data owners are still willing to contribute their data, but the privacy of the data must be enforced.
An old and well-known version of local privacy is a randomized response (RR), which provides plausible deniability for respondents to sensitive queries. For example, a respondent flips a fair coin:
An ML-oriented work, AnonML, utilized the ideas of RR to generate histograms from multiple input parties [9]. AnonML uses these histograms to create synthetic data on which an ML model can be trained. Like other LDP approaches, AnonML is a good option when no input party has enough data to build an ML model on their own (and when there is no trusted aggregator). In chapters 4 and 5, we will present a detailed analysis of how LDP differs from differential privacy and how it can be used in different ML applications.
1.4.3 Privacy-preserving synthetic data generation
Although many privacy-preserving techniques have been proposed and developed for all kinds of ML algorithms, sometimes data users may want to execute new ML algorithms and analysis procedures. When there is no predefined algorithm for the requested operation, data users may request data to utilize it locally. To that end, different privacy-preserving data-sharing techniques such as k-anonymity, l-diversity, t-closeness, and data perturbation have been proposed in the past. These techniques can be fine-tuned to generate a new anonymized dataset from the same original dataset. However, in some cases, anonymization alone may hurt the utility of the underlying ML algorithms. Thus, a promising solution for data sharing is to generate synthetic yet representative data that can be safely shared with others.
Synthetic data is generated artificially rather than produced through real-world events at a high level. It is usually generated algorithmically and is often used as a stand-in for training and testing ML models. Nevertheless, in practice, sharing a synthetic dataset in the same format (preserving the same statistical characteristics) as the original dataset gives data users much more flexibility with minimal privacy concerns.
Different studies have investigated privacy-preserving synthetic data generation on different dimensions. For instance, plausible deniability is one such approach employing a privacy test after generating the synthetic data. In 2012, Hardt et al. proposed an algorithm that combines the multiplicative weights approach and an exponential mechanism for differentially private data release [10]. On the other hand, Bindschaedler et al. proposed a generative model, a probabilistic model that captures the joint distribution of features based on correlation-based feature selection [11]. In 2017, Domingo-Ferrer et al. proposed a micro-aggregation-based differential private data releasing approach, which reduces the noise required by differential privacy based on k-anonymity [12]. All in all, privacy-preserving synthetic data generation is gaining traction within the ML community.
The benefits of using synthetic data, such as reduced constraints when using sensitive data and the capability to tailor the data for certain conditions that cannot be obtained with authentic data, have already gained attention in many real-world practical use cases. In chapter 6, we will introduce different mechanisms for synthetic data generation with the goal of privacy-preserving ML.
1.4.4 Privacy-preserving data mining techniques
So far in this chapter, we have looked into different privacy protection approaches for ML algorithms. Now, let’s focus on protecting privacy while engaging data mining operations. The evolving interest in advances in ML algorithms, storage, and the flow of sensitive information poses significant privacy concerns. As a result, different approaches to handling and publishing sensitive data have been proposed over the past decade.
Among privacy-preserving data mining (PPDM) techniques, the vast majority rely on either modifying data or removing some of the original content to protect privacy. The resulting quality degradation from this sanitization or transformation is the tradeoff between the quality of data and the level of privacy. Nevertheless, the basic idea behind all these PPDM techniques is to efficiently mine data while preserving the privacy of individuals. There are three main classes of techniques for dealing with PPDM, based on the different stages of data collection, publishing, and processing. Let’s briefly look at these approaches.
Techniques for privacy-preserving data collection
The first class of PPDM techniques ensures privacy at the stage of data collection. It usually incorporates different randomization techniques at the data collection stage and generates privatized values, so original values are never stored. The most common randomization approach is to modify data by adding some noise with a known distribution. Whenever data mining algorithms are involved, the original data distribution, but not the individual values, can be reproduced. Additive and multiplicative noise approaches are two of the most common data randomization techniques in this category.
Different approaches to data publishing and processing
The second class of PPDM deals with techniques related to when data is released to third parties (published) without disclosing the ownership of sensitive information. Removing attributes that can explicitly identify an individual from a dataset is not sufficient, as users may still be identified by combining nonsensitive attributes or records. For example, consider a dataset of patient records from a hospital. We can remove the identifiable attributes, such as name and address, from this dataset before publishing it, but if someone else knows the age, gender, and zip code of a patient, they might be able to combine that information to trace the specific patient’s record in the dataset, even without having access to the name attribute.
Hence, PPDM techniques usually incorporate one or more data sanitization operations, such as generalization, suppression, anatomization, and perturbation. Based on these sanitization operations, a set of privacy models can be proposed, which are now broadly used in different application domains for privacy protection. We will discuss these techniques and privacy models in chapter 7.
Protecting privacy of data mining algorithm output
Even with only implicit access to the original dataset, outputs of data mining algorithms may reveal private information about the underlying dataset. An active adversary may access these algorithms and query data to infer some private information. Thus, different techniques have been proposed to preserve the privacy of the output of data mining algorithms:
-
Association rule hiding—In data mining, association rule mining is a popular rule-based data mining approach to discover relationships between different variables in datasets. However, these rules sometimes may disclose an individual’s private or sensitive information. The idea of association rule hiding is to mine only the nonsensitive rules, ensuring that no sensitive rule is discovered. The most straightforward approach is to perturb the entries so that all sensitive, but not nonsensitive, rules are hidden.
-
Downgrading classifier effectiveness—As we discussed in the context of membership inference attacks, classifier applications may leak information such that an adversary can determine whether a particular record is in the training dataset. Going back to our example of an ML service for diagnosing diseases, an adversary can devise an attack to learn whether a record for a specific individual has been used to train the ML model. In such circumstances, downgrading the accuracy of the classifier is one way to preserve privacy.
-
Query auditing and restriction—In some applications, users can query the original dataset but with limited query functionality, such as aggregate queries (SUM, AVERAGE, etc.). However, an adversary may still infer some private information by looking at the sequences of the queries and their corresponding results. Query auditing is commonly used to protect privacy in such scenarios by either perturbing the query results or denying one or more queries from a sequence of queries. On the downside, the computational complexity of this approach is much higher than that of the other approaches.
This discussion is just an overview of how PPDM works. In chapters 7 and 8, we will walk through a comprehensive analysis of PPDM techniques, as well as privacy-enhanced data management techniques in database systems.
1.4.5 Compressive privacy
Compressive privacy perturbs the data by projecting it to a lower-dimensional hyperplane via compression and dimensionality reduction techniques. Most of these transformation techniques are lossy. Liu et al. suggested that compressive privacy would strengthen the privacy protection of the sensitive data, since recovering the exact original data from a transformed version (i.e., compressed or dimensionality reduced data) would not be possible [13].
In figure 1.7, xi is the original data, and ![]() is the corresponding transformed data—the projection of xi on dimension U1. We know that
is the corresponding transformed data—the projection of xi on dimension U1. We know that ![]() can be mapped back to an infinite number of points perpendicular to U1. In other words, the possible solutions are infinite as the number of equations is less than the number of unknowns. Therefore, Liu et al. proposed applying a random matrix to reduce the dimensions of the input data. Since a random matrix might decrease the utility, other approaches used both unsupervised and supervised dimensionality reduction techniques, such as principal component analysis, discriminant component analysis, and multidimensional scaling. These techniques attempt to find the best projection matrix for utility purposes while relying on the reduced dimensionality to enhance privacy.
can be mapped back to an infinite number of points perpendicular to U1. In other words, the possible solutions are infinite as the number of equations is less than the number of unknowns. Therefore, Liu et al. proposed applying a random matrix to reduce the dimensions of the input data. Since a random matrix might decrease the utility, other approaches used both unsupervised and supervised dimensionality reduction techniques, such as principal component analysis, discriminant component analysis, and multidimensional scaling. These techniques attempt to find the best projection matrix for utility purposes while relying on the reduced dimensionality to enhance privacy.
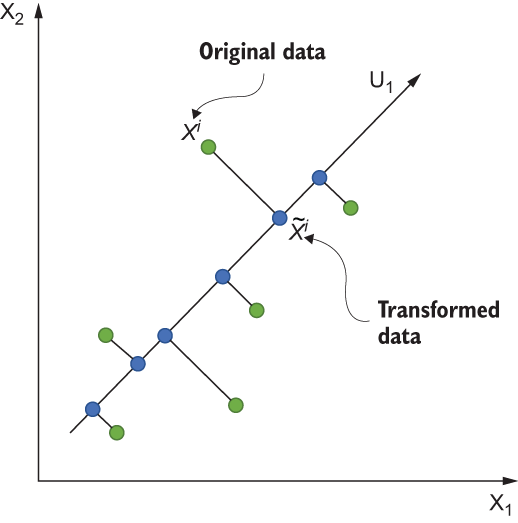
Figure 1.7 Compressive privacy works by projecting data to a lower-dimensional hyperplane.
DEFINITION What is a lower dimensional hyperplane? In general, a hyperplane is a subspace whose dimension is one less than that of its original space. For example, in figure 1.7 the original ambient space is two-dimensional; hence, its hyperplanes are one-dimensional lines, as shown.
Compressive privacy guarantees that the original data can never be fully recovered. However, we can still obtain an approximation of the original data from the reduced dimensions. Therefore, some approaches, such as Jiang et al. [14], combine compressive privacy techniques (dimensionality reduction) with differential privacy techniques to publish differentially private data.
Although some entities may attempt to totally hide their data, compressive privacy has another benefit for privacy. For datasets that have samples with two labels—a utility label and a privacy label—Kung [15] proposes a dimensionality reduction method that enables the data owner to project their data in a way that maximizes the accuracy of learning the utility labels while decreasing the accuracy of learning the privacy labels. Although this method does not eliminate all data privacy risks, it controls the misuse of the data when the privacy target is known. Chapter 9 will walk through the different approaches to and applications of compressive privacy.
1.5 How is this book structured?
The forthcoming chapters of this book are structured as follows. Chapters 2 and 3 will discuss how differential privacy can be utilized in PPML, with different use case scenarios and applications. If you are interested in finding out how to use DP in practical applications, along with a set of real-world examples, these chapters have got you covered.
In chapters 4 and 5, we will walk through methods and applications of applying differential privacy in the local setup, with an added restriction so that even if an adversary has access to individual responses, they will still be unable to learn anything beyond those responses.
Chapter 6 will investigate how synthetic data generation techniques can be used in the PPML paradigm. As we already discussed, synthetic data generation is gaining traction within the ML community, especially as a stand-in for training and testing ML models. If you are interested in finding ways and means to generate synthetic data with the goal of PPML, this is your chapter.
In chapters 7 and 8, we will explore how privacy-enhancing technologies can be applied in data mining tasks and used and implemented in database systems. We know that, ultimately, everything has to be stored in a database somewhere, whether the data model is relational, NoSQL, or NewSQL. What if these databases or data mining applications are prone to privacy attacks while accessing or releasing data? These two chapters will investigate different techniques, methodologies, and well-established industry practices for mitigating such privacy leaks.
Next, we will look at another possible approach to PPML involving compressing or reducing the dimension of data by projecting it to another hyperplane. To that end, we will be discussing different compressive privacy approaches with their applications in chapter 9. If you are designing or developing privacy applications for constrained environments with compressed data, we suggest you invest more time in this chapter. We will employ practical examples of data compression techniques to achieve privacy preservation for different application scenarios.
Finally, in chapter 10 we will put everything together and design a platform for research data protection and sharing by emphasizing the design challenges and implementation considerations.

Summary
-
In reconstruction attacks, the adversary gains the advantage by having external knowledge of feature vectors or the data used to build the ML model.
-
Reconstruction attacks usually require direct access to the ML models deployed on the server; we call this white-box access.
-
Sometimes an adversary can listen to both the incoming requests to an ML model, when a user submits new testing samples, and the responses generated by the model for a given sample. This can lead to model inversion attacks.
-
A membership inference attack is an extended version of the model inversion attack where an adversary tries to infer a sample based on the ML model’s output to identify whether the sample is in the training dataset.
-
Even when datasets are anonymized, ensuring a system’s ability to reliably protect data privacy is challenging because attackers can utilize background knowledge to infer data with de-anonymization or re-identification attacks.
-
Linking different database instances together to explore an individual’s unique fingerprint is a significant privacy threat to database systems.
-
Differential privacy (DP) attempts to protect sensitive information from inference attacks targeting an individual’s statistics or aggregated data by adding random noise.
-
Local differential privacy (LDP) is the local setting of DP, where individuals send their data to the data aggregator after privatizing the data by perturbation, thus providing plausible deniability.
-
Compressive privacy perturbs data by projecting it to a lower-dimensional hyperplane via compression and dimensionality reduction techniques.
-
Synthetic data generation is a promising solution for data sharing that produces and shares a synthetic dataset in the same format as the original data, which gives much more flexibility in how data users can use the data, with no concerns about query-based budgets for privacy.
-
Privacy-preserving data mining (PPDM) can be achieved using different techniques, which can be categorized into three main classes: privacy-preserving approaches to data collection, data publishing, and modifying data mining output.