
An index is an optionally created database object used primarily to increase query performance. Indexes can also limit the amount of data that is returned in the results without having to retrieve all of data columns of a table. This can help keep results in memory and bring back results faster. The purpose of a database index is similar to that of an index in the back of a book. A book index associates a topic with a page number. When you are locating information in a book, it is usually much faster to examine the index first, find the topic of interest, and identify associated page numbers. With this information, you can navigate directly to specific page numbers in the book.
If a topic only appears on a few pages within the book, then the number of pages to read is minimal. In this manner, the usefulness of the index decreases with an increase in the number of times a topic appears in a book. In other words, if a subject entry appears on every page of the book, there would be no benefit to creating an index on it. In this scenario, regardless of the presence of an index, it would be more efficient for the reader to scan every page of the book.
Note
In database parlance, searching all blocks of a table is known as a full-table scan. Full-table scans occur when there is no available index or when the query optimizer determines a full-table scan is a more efficient access path than using an existing index.
Similar to a book index (topic and page number), a database index stores the column value of interest, along with its row identifier (ROWID) . The ROWID contains the physical location of the table row on disk that stores the column value. With the ROWID in hand, Oracle can efficiently retrieve table data with a minimum of disk reads. In this way, indexes function as a shortcut to the table data. If there is no available index, then Oracle reads each row in the table to determine if the row contains the desired information.
Note
In addition to improving performance, Oracle uses indexes to help enforce enabled primary key and unique key constraints. Additionally, Oracle can better manage certain table-locking scenarios when indexes are placed on foreign key columns.
Whereas it is possible to build a database application devoid of indexes, without them or too many of them, you are almost guaranteeing poor performance. Indexes allow for excellent scalability, even with very large data sets. If indexes are so important to database performance, why not place them on all tables and column combinations? The answer is short: indexes are not free. They consume disk space and system resources. As column values are modified, any corresponding indexes must also be updated. In this way, indexes use storage, I/O, CPU, and memory resources. A poor choice of indexes leads to wasted disk usage and excessive consumption of system resources. This results in a decrease in database performance and greater cost for DML statements.
Automation and proactively tuning database applications are ever-growing areas of the database. Indexes, statistics, and overall database configuration play into developing the strategies to tune. Oracle 18c provides enhanced statistics and collection of information about indexes being used. These tools can be utilized as part of the index planning and design for the database tables and indexes.
For these reasons, when you design and build an Oracle database application, consideration must be given to your indexing strategy. As an application architect, you must understand the physical properties of an index, what types of indexes are available, and strategies for choosing which table and column combinations to index. A correct indexing methodology is central to achieving maximum performance for your database.
Deciding When to Create an Index
Proactively, when first deploying an application; the DBAs/ developers make an educated guess as to which tables and columns to index.
Reactively, when application performance bogs down, and users complain of poor performance; then, the DBAs/developers attempt to identify slow-executing SQL queries and how indexes might be a solution.
The prior two topics are discussed in the next two sections.
Proactively Creating Indexes
Define a primary key constraint for each table. This results in an index automatically being created on the columns specified in the primary key.
Create unique key constraints on columns that are required to be unique and that are different from the primary key columns. Each unique key constraint results in an index automatically being created on the columns specified in the constraint.
Manually create indexes on foreign key columns. This is done for better performance, to avoid certain locking issues.
In other words, some of the decision process on what tables and columns to index is automatically done for you when determining the table constraints. When creating primary and unique key constraints, Oracle automatically creates indexes for you. There is some debate about whether or not to create indexes on foreign key columns. See the section “Indexing Foreign Key Columns,” later in this chapter, for further discussion.
These indexes can be automated to run with table creation or as part of the object builds in the database. Also, if foreign keys are newly created, an index can be generated as part of the code to make sure that the indexes are be created as changes are made and instead of manually checking all of the constraints, indexes, and keys, DDL can be generated based on new objects and added as part of proactively creating indexes.
In addition to creating indexes related to constraints, if you have enough knowledge of the SQL contained within the application, you can create indexes related to tables and columns referenced in SELECT, FROM, and WHERE clauses. In my experience, DBAs and developers are not adept at proactively identifying such indexes. Rather, these indexing requirements are usually identified reactively.
Reactively Creating Indexes
Rarely do DBAs and developers accurately create the right mix of indexes when first deploying an application. And, that is not a bad thing or unexpected; it is hard to predict everything that occurs in a large database system. Furthermore, as the application matures, changes are introduced to the database (new tables, new columns, new constraints, database upgrades that add new features/behaviors, and so on). The reality is that you will have to react to unforeseen situations in your database that warrant adding indexes to improve performance.
Index strategies also have to be revisited for major database releases or system resource changes. For example, more memory on the server will allow for a table scan to perform better and maybe eliminate a need for an index. Or for an index that was beneficial because of how the optimizer was calculating cost, upgrades might validate a different query plan for better performance.
Note
Index strategies are not just about creating indexes but also about cleaning up indexes that are no longer in use because of better statistics and optimizer query plans without the index.
- 1.
A poorly performing SQL statement is identified (a user complains about a specific statement, the DBA runs automatic database diagnostic monitor (ADDM), or automatic workload repository (AWR) reports to identify resource-consuming SQL, and so on).
- 2.
DBA checks the table and index statistics to ensure that out-of-date statistics are not causing the optimizer to make bad choices.
- 3.
DBA/developer determines that the query cannot be rewritten in a way that alleviates performance issues.
- 4.
DBA/developer examines the SQL statement and determines which tables and columns are being accessed, by inspecting the SELECT, FROM, and WHERE clauses.
- 5.
DBA/developer performs testing and recommends that an index be created, based on a table and one or more columns.
Create indexes on columns used often as predicates in the WHERE clause; when multiple columns from a table are used in the WHERE clause, consider using a concatenated (multicolumn) index.
Create a covering index (i.e., an index on all columns) in the SELECT clause.
Create indexes on columns used in the ORDER BY, GROUP BY, UNION, and DISTINCT clauses .
Oracle allows you to create an index that contains more than one column. Multicolumn indexes are known as concatenated indexes (also called composite indexes). These indexes are especially effective when you often use multiple columns in the WHERE clause when accessing a table. Concatenated indexes are, in many instances, more efficient in this situation than creating separate, single-column indexes (See the section “Creating Concatenated Indexes,” later in this chapter, for more details).
Columns included in the SELECT and WHERE clauses are also potential candidates for indexes. Sometimes, a covering index in a SELECT clause results in Oracle using the index structure itself (and not the table) to satisfy the results of the query. Also, if the column values are selective enough, Oracle can use an index on columns referenced in the WHERE clause to improve query performance.
Also consider creating indexes on columns used in the ORDER BY , GROUP BY , UNION , and DISTINCT clauses . This may result in greater efficiency for queries that frequently use these SQL constructs.
It is okay to have multiple indexes per table. However, the more indexes you place on a table, the slower the DML statements. Do not fall into the trap of randomly adding indexes to a table until you stumble upon the right combination of indexed columns. Rather, verify the performance of an index before you create it in a production environment. Oracle 18c has improved how it reviews index usage, and these statistics can be taken into consideration when deciding to keep indexes or if a different index is needed.
Also keep in mind that it is possible to add an index that increases the performance of one statement, while hurting the performance of others. You must be sure that the statements that are improved warrant the penalty being applied to other statements. You should only add an index when you are certain it will improve performance.
Planning for Robustness
Type of index
Initial space required and growth
Temporary tablespace usage while the index is being created (for large indexes)
Tablespace placement
Naming conventions
Which column(s) to include
Whether to use a single column or a combination of columns
Special features, such as the PARALLEL clause, NOLOGGING, compression, and invisible indexes
Uniqueness
Impact on performance of SELECT statements (improvement)
Impact on performance of INSERT, UPDATE, and DELETE statements
These topics are discussed in subsequent sections in this chapter.
Determining Which Type of Index to Use
Oracle Index Type and Usage Descriptions
Index Type | Usage |
|---|---|
B-tree | Default index; good for columns with high cardinality (i.e., high degree of distinct values). Use a normal B-tree index unless you have a concrete reason to use a different index type or feature. |
IOT | This index is efficient when most of the column values are included in the primary key. You access the index as if it were a table. The data are stored in a B-tree-like structure. See Chapter 7 for details on this type of index. |
Unique | A form of B-tree index; used to enforce uniqueness in column values; often used with primary key and unique key constraints but can be created independently of constraints. |
Reverse key | A form of B-tree index; useful for balancing I/O in an index that has many sequential inserts. |
Key compressed | Good for concatenated indexes in which the leading column is often repeated; compresses leaf block entries; applies to B-tree and IOT indexes. |
Descending | A form of B-tree index; used with indexes in which corresponding column values are sorted in a descending order (the default order is ascending). You cannot specify descending for a reverse-key index, and Oracle ignores descending if the index type is bitmap. |
Bitmap | Excellent in data warehouse environments with low cardinality (i.e., low degree of distinct values) columns and SQL statements using many AND or OR operators in the WHERE clause. Bitmap indexes are not appropriate for OLTP databases in which rows are frequently updated. You cannot create a unique bitmap index. |
Bitmap join | Useful in data warehouse environments for queries that use star schema structures that join fact and dimension tables. |
Function based | Good for columns that have SQL functions applied to them; can be used with either a B-tree or bitmap index. |
Indexed virtual column | An index defined on a virtual column (of a table); useful for columns that have SQL functions applied to them; a viable alternative to a function-based index. |
Virtual | Allows you to create an index with no physical segment or extents via the NOSEGMENT clause of CREATE INDEX; useful in tuning SQL without consuming resources required to build the physical index. Any index type can be created as virtual. |
Invisible | The index is not visible to the query optimizer. However, the structure of the index is maintained as table data are modified. Useful for testing an index before making it visible to the application. Any index type can be created as invisible. |
Global partitioned | Global index across all partitions in a partitioned or regular table; can be a B-tree index type and cannot be a bitmap index type. |
Local partitioned | Local index based on individual partitions in a partitioned table; can be either a B-tree or bitmap index type. |
Domain | Specific for an application or cartridge. |
B-tree cluster | Used with clustered tables. |
Hash cluster | Used with hash clusters. |
Note
Several of the index types listed in Table 8-1 are actually just variations on the B-tree index. A reverse-key index, for example, is merely a B-tree index optimized for evenly spreading I/O when the index value is sequentially generated and inserted with similar values.
This chapter focuses on the most commonly used indexes and features—B-tree, function based, unique, bitmap, reverse key, and key compressed—and the most used options. IOTs are covered in Chapter 7, and partitioned indexes are covered in Chapter 12. If you need more information about index types or features, see the Oracle SQL Reference Guide, which is available for download from the Technology Network area of the Oracle web site ( http://otn.oracle.com ).
Estimating the Size of an Index Before Creation
If you do not work with large databases, then you do not need to worry about estimating the amount of space an index will initially consume. However, for large databases, you absolutely need an estimate on how much space it will take to create an index. If you have a large table in a data warehouse environment, a corresponding index could easily be hundreds of gigabytes in size. In this situation, you need to ensure that the database has adequate disk space available.
The best way to predict the size of an index is to create it in a test environment that has a representative set of production data. If you cannot build a complete replica of production data, a subset of data can often be used to extrapolate the size required in production. If you do not have the luxury of using a cut of production data, you can also estimate the size of an index using the DBMS_SPACE.CREATE_INDEX_COST procedure.
Note
I have seen tables that are several hundred gigabytes in size, but the index space is twice the amount of the tablespace. It is not because the index has more columns but because it has so many different indexes. Having three or more indexes for each very large table starts to add up quickly.
The used_bytes variable gives you an estimate of how much room is required for the index data. The alloc_bytes variable provides an estimate of how much space will be allocated within the tablespace.
Your results may vary, depending on the number of records, the number of columns, the data types, and the accuracy of statistics.
In addition to the initial sizing, keep in mind that the index will grow as records are inserted into the table. You will have to monitor the space consumed by the index and ensure that there is enough disk space to accommodate future growth requirements.
Creating Indexes and Temporary Tablespace Space
Related to space usage, sometimes DBAs forget that Oracle often requires space in either memory or disk to sort an index as it is created. If the available memory area is consumed, then Oracle allocates disk space as required within the default temporary tablespace. If you are creating a large index, you may need to increase the size of your temporary tablespace.
Another approach is to create an additional temporary tablespace and then assign it to be the default temporary tablespace of the user creating the index. After the index is created, you can drop the temporary tablespace (that was created just for the new index) and reassign the user’s default temporary tablespace back to the original temporary tablespace.
Creating Separate Tablespaces for Indexes
Doing so allows for differing backup and recovery requirements. You may want the flexibility of backing up the indexes at a different frequency than the tables. Or, you may choose not to back up indexes because you know that you can re-create them.
If you let the table or index inherit its storage characteristics from the tablespace, when using separate tablespaces, you can tailor storage attributes for objects created within the tablespace. Tables and indexes often have different storage requirements (such as extent size and logging).
When running maintenance reports, it is sometimes easier to manage tables and indexes when the reports have sections separated by tablespace.
If these reasons are valid for your environment, it is probably worth the extra effort to employ different tablespaces for tables and indexes. If you do not have any of the prior needs, then it is fine to put tables and indexes together in the same tablespace.
I should point out that DBAs often consider placing indexes in separate tablespaces for performance reasons. If you have the luxury of creating a storage system from scratch and can set up mount points that have their own sets of disks and controllers, you may see some I/O benefits from separating tables and indexes into different tablespaces. Nowadays, storage administrators often give you a large slice of storage in a storage area network (SAN), and there is no way to guarantee that data and indexes will be stored physically, on separate disks (and controllers). Thus, you typically do not gain any performance benefits by separating tables and indexes into different tablespaces.
I prefer to use uniform extent sizes because that ensures that all extents within the tablespace will be of the same size, which reduces fragmentation as objects are created and dropped. The automatic segment space management feature allows Oracle to manage automatically many storage attributes that previously had to be monitored and maintained by the DBA manually.
Inheriting Storage Parameters from the Tablespace
When creating a table or an index, there are a few tablespace-related technical details to be aware of. For instance, if you do not specify storage parameters when creating tables and indexes, then they inherit storage parameters from the tablespace. This is the desired behavior in most circumstances; it saves you from having to specify these parameters manually. If you need to create an object with storage parameters different from those of its tablespace, then you can do so within the CREATE TABLE/INDEX statement.
Also keep in mind that if you do not explicitly specify a tablespace, by default, indexes are created in the default permanent tablespace for the user. This is acceptable for development and test environments. For production environments, you should consider explicitly naming tablespaces in the CREATE TABLE/INDEX statement .
Placing Indexes in Tablespaces, Based on Extent Size
Indexes that have small space and growth requirements are placed in the INV_IDX_SMALL tablespace, and indexes that have medium storage requirements would be created in INV_IDX_MED. If you discover that an index is growing at an unpredicted rate, consider dropping the index and re-creating it in a different tablespace or rebuilding the index in a more appropriate tablespace.
Creating Portable Scripts
I oftentimes find myself working in multiple database environments, such as development, testing, and production. Typically, I will create a tablespace first in development, then later in testing, and finally in production. Frequently, there are aspects of the script that need to change as it is promoted through the environments. For instance, development may need only 100MB of space, but production may need 10GB.
If you are only working with one tablespace, then there is not much to gain from using the prior technique. But, if you are creating dozens of tablespaces within numerous environments, then it pays to build in the reusability. Keep in mind that you can use ampersand variables anywhere within the script for any values you think may differ from one environment to the next.
Establishing Naming Standards
Diagnosing issues is simplified when error messages contain information that indicates the table, index type, and so on.
Reports that display index information are more easily grouped and therefore are more readable, making it easier to spot patterns and issues.
Primary key index names should contain the table name and a suffix such as _PK.
Unique key index names should contain the table name and a suffix such as _UKN, where N is a number.
Indexes on foreign key columns should contain the foreign key table and a suffix such as _FKN, where N is a number.
Indexes that are not used for constraints should contain the table name and a suffix such as _IDXN, where N is a number.
Function-based index names should contain the table name and a suffix such as _FNXN, where N is a number.
Bitmap index names should contain the table name and a suffix such as _BMXN, where N is a number.
Some shops use prefixes when naming indexes. For example, a primary key index would be named PK_CUST (instead of CUST_PK). All these various naming standards are valid.
Tip
It does not matter what the standard is, as long as everybody on the team follows the same standard.
Creating Indexes
As described previously, when you think about creating tables, you must think about the corresponding index architecture. Creating the appropriate indexes and using the correct index features will usually result in dramatic performance improvements. Conversely, creating indexes on the wrong columns or using features in the wrong situations can cause dramatic performance degradation.
Having said that, after giving some thought to what kind of index you need, the next logical step is to create the index. Creating indexes and implementing specific features are discussed in the next several sections.
Creating B-tree Indexes
Tip
If you do not specify any physical storage properties for an index, the index inherits its properties from the tablespace in which it is created. This is usually an acceptable method for managing index storage.
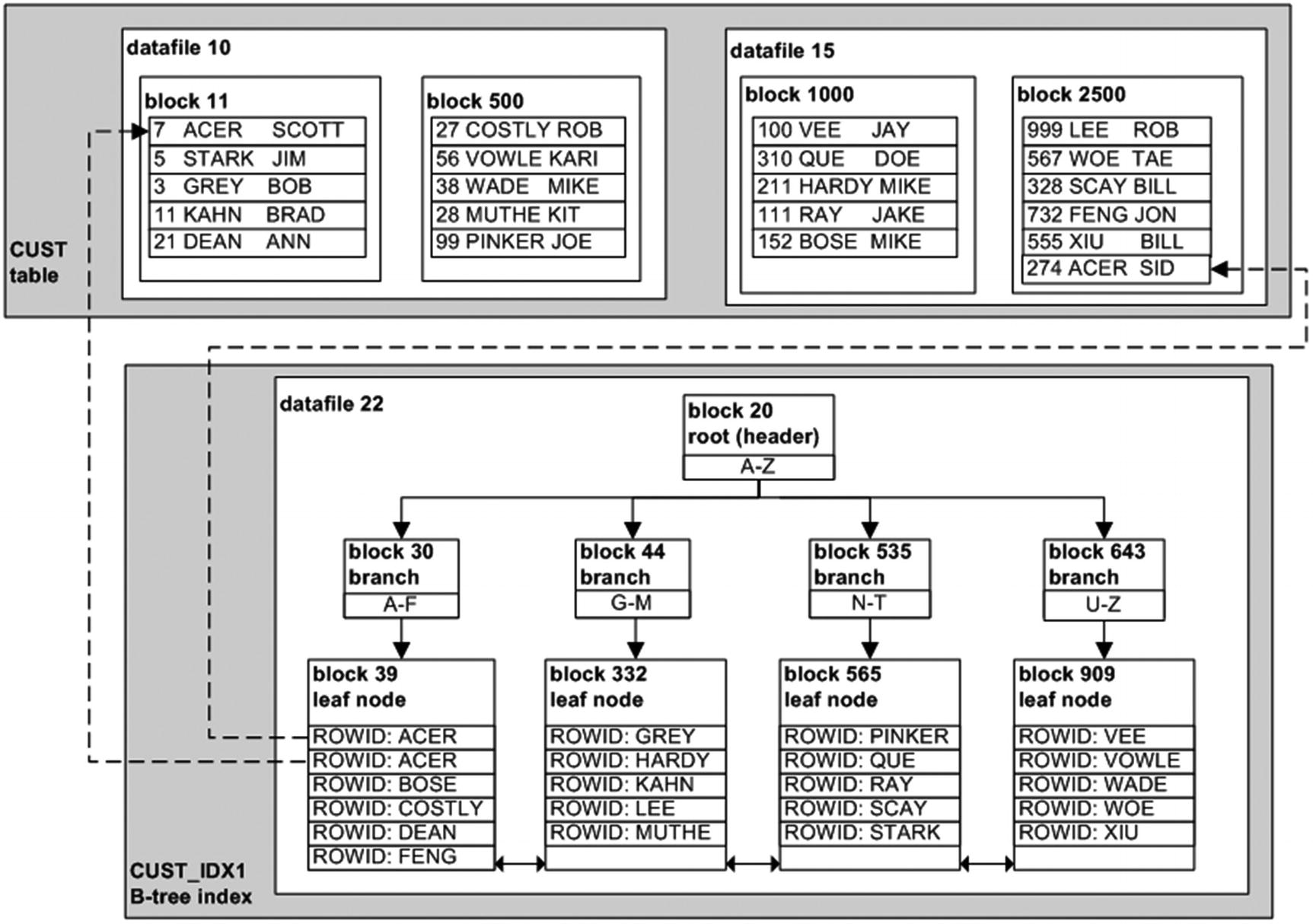
Oracle B-tree hierarchical index structure and associated table
The index definition is associated with a table and column(s). The index structure stores a mapping of the table’s ROWID and the column data on which the index is built. A ROWID usually uniquely identifies a row within a database and contains information to physically locate a row (data file, block, and row position within block). The two dotted lines in Figure 8-1 depict how the ROWID (in the index structure) points to the physical row in the table for the column values of ACER .
The B-tree index has a hierarchical tree structure. When Oracle accesses the index, it starts with the top node, called the root (or header) block. Oracle uses this block to determine which second-level block (also called a branch block) to read next. The second-level block points to several third-level blocks (leaf nodes), which contain a ROWID and the name value. In this structure, it will take three I/O operations to find the ROWID. Once the ROWID is determined, Oracle will use it to read the table block that contains the ROWID.
To determine where to start the range scan, Oracle would read the root, block 20; then, the branch block 30; and, finally, the leaf node block 39. Because the leaf node blocks are linked, Oracle can navigate forward as needed to find all required blocks (and does not have to navigate up and down through branch blocks). This is a very efficient traversal mechanism for range scans .
Arboristic Views
INDEX_STATS
DBA/ALL/USER_INDEXES
The DBA/ALL/USER_INDEXES views contain statistics, such as BLEVEL (number of blocks from root to branch blocks; this equals HEIGHT – 1); LEAF_BLOCKS (number of leaf blocks); and so on. The DBA/ALL/USER_INDEXES views are populated automatically when the index is created and refreshed via the DBMS_STATS package.
Creating Concatenated Indexes
Oracle allows you to create an index that contains more than one column. Multicolumn indexes are known as concatenated indexes. These indexes are especially effective when you often use multiple columns in the WHERE clause when accessing a table.
In older versions of Oracle (circa version 8)if the leading-edge column (or columns) appeared in the WHERE clause. In modern versions the optimizer can use a concatenated index even if the leading-edge column (or columns) is not present in the WHERE clause. This ability to use an index without reference to leading-edge columns is known as the skip-scan feature.
A concatenated index that is used for skip scanning can, in certain situations, be more efficient than a full-table scan. However, you should try to create concatenated indexes that use the leading column. If you are consistently using only a lagging-edge column of a concatenated index, then consider creating a single-column index on the lagging column .
Creating Multiple Indexes on the Same Set of Columns
Prior to Oracle Database 12c, you could not have multiple indexes defined on the exact same combination of columns in one table. This has changed in 12c. You can now have multiple indexes on the same set of columns. However, you can only do this if there is something physically different about the indexes, for example, one index is created as a B-tree index, and the second, as a bitmap index.
Prior to Oracle Database 12c, if you attempted the previous operation, the second creation statement would throw an error such as ORA-01408: such column list already indexed.
Why would you want two indexes defined on the same set of columns? You might want to do this if you originally implemented B-tree indexes and now wanted to change them to bitmap—the idea being, you create the new indexes as invisible, then drop the original indexes and make the new indexes visible. In a large database environment, this would enable you to make the change quickly. See the section on “Implementing Invisible Indexes” for more information.
Implementing Function-Based Indexes
In this scenario there may be a normal B-tree index on the FIRST_NAME column, but Oracle will not use a regular index that exists on a column when a function is applied to it.
Function-based indexes allow index lookups on columns referenced by functions in the WHERE clause of an SQL query. The index can be as simple as the preceding example, or it can be based on complex logic stored in a PL/SQL function .
Note
Any user-created SQL functions must be declared deterministic before they can be used in a function-based index. Deterministic means that for a given set of inputs, the function always returns the same results. You must use the keyword DETERMINISTIC when creating a user-defined function that you want to use in a function-based index.
The SET LONG command in this example tells SQL*Plus to display up to 500 characters from the COLUMN_EXPRESSION column, which is of type LONG.
Creating Unique Indexes
When you create a B-tree index, you can also specify that the index be unique . Doing so ensures that non-NULL values are unique when you insert or update columns in a table.
Note
The unique index does not enforce uniqueness for NULL values inserted into the table. In other words, you can insert the value NULL into the indexed column for multiple rows.
You must be aware of some interesting nuances regarding unique indexes, primary key constraints, and unique key constraints (see Chapter 7 for a detailed discussion of primary key constraints and unique key constraints). When you create a primary key constraint or a unique key constraint, Oracle automatically creates a unique index and a corresponding constraint that is visible in DBA/ALL/USER_CONSTRAINTS.
In this situation, you can enable and disable the constraint independent of the index. However, because the index was created as unique, the index still enforces uniqueness regardless of whether the constraint has been disabled.
When should you explicitly create a unique index versus creating a constraint and having Oracle automatically create the index? There are no hard-and-fast rules. I prefer creating a unique key constraint and letting Oracle automatically create the unique index, because then I get information in both the DBA/ALL/USER_CONSTRAINTS and DBA/ALL/USER_INDEXES views .
But, Oracle’s documentation recommends that if you have a scenario in which you are strictly using a unique constraint to improve query performance, it is preferable to create only the unique index. This is appropriate. If you take this approach, just be aware that you may not find any information in the constraint-related data dictionary views.
Implementing Bitmap Indexes
Bitmap indexes are recommended for columns with a relatively low degree of distinct values (low cardinality). You should not use bitmap indexes in OLTP databases with high INSERT/UPDATE/DELETE activities, owing to locking issues; the structure of the bitmap index results in many rows potentially being locked during DML operations, which causes locking problems for high-transaction OLTP systems .
Bitmap indexes are commonly used in data warehouse environments. A typical star schema structure consists of a large fact table and many small dimension (lookup) tables. In these scenarios, it is common to create bitmap indexes on fact table foreign key columns. The fact tables are typically inserted into on a daily basis and usually are not updated or deleted from.
Results of an OR Operation
Value/Row | Row 1 | Row 2 | Row 3 | Row 4 | Row 5 | Row 6 | Row 7 |
|---|---|---|---|---|---|---|---|
EAST | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
WEST | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Boolean OR on EAST and WEST | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
Note
Bitmap indexes and bitmap join indexes are available only with the Oracle Enterprise Edition of the database. Also, you cannot create a unique bitmap index.
Creating Bitmap Join Indexes
The optimizer can choose to use the bitmap join index, thus avoiding the expense of having to join the tables. For small amounts of data, the optimizer will most likely choose not to use the bitmap join index, but as the data in the table grow, using the bitmap join index becomes more cost-effective than full-table scans or using other indexes .
Implementing Reverse-Key Indexes
Reverse-key indexes can perform better in scenarios in which you need a way to evenly distribute index data that would otherwise have similar values clustered together. Thus, when using a reverse-key index, you avoid having I/O concentrated in one physical disk location within the index during large inserts of sequential values.
Note
You cannot specify REVERSE for a bitmap index or an IOT.
Creating Key-Compressed Indexes
Reduced storage
More rows stored in leaf blocks, which can result in less I/O when accessing a compressed index
Note
You cannot create a key-compressed index on a bitmap index.
Parallelizing Index Creation
If you do not specify a degree of parallelism, Oracle selects a degree, based on the number of CPUs on the box times the value of PARALLEL_THREADS_PER_CPU.
Avoiding Redo Generation When Creating an Index
The redo is not generated that would be required to recover the index in the event of a media failure.
Subsequent direct-path operations also will not generate the redo required to recover the index information in the event of a media failure.
This error indicates that the index is logically corrupt. In this scenario, you must re-create the index before it is usable. In most scenarios it is acceptable to use the NOLOGGING clause when creating an index, because the index can be recreated without affecting the table on which the index is based.
Implementing Invisible Indexes
As discussed in creating an index on the same columns with only one visible, you have the option of making an index invisible to the optimizer. Oracle still maintains an invisible index (as DML occurs on the table) but does not make it available for use by the optimizer. You can use the OPTIMIZER_USE_INVISIBLE_INDEXES database parameter to make an invisible index visible to the optimizer .
Altering an index to be invisible before dropping it allows you to quickly recover if you later determine that the index is required.
You may be able to add an invisible index to a third-party application without affecting existing code or support agreements.
These two scenarios are discussed in the following sections .
Making an Existing Index Invisible
Suppose you have identified an index that is not being used and are considering dropping it. In earlier releases of Oracle, you could mark the index UNUSABLE and then later drop indexes that you were certain weren’t being used. If you later determined that you needed an unusable index, the only way to re-enable the index was to rebuild it. For large indexes this could take a great amount of time and database resources.
Making an index invisible has the advantage of telling only the optimizer not to use the index. The invisible index is still maintained as the underlying table has records inserted, updated, and deleted. If you decide that you later need the index, there is no need to rebuild it; you simply make it visible again.
Caution
If you have a B-tree index on a foreign key column, and you decide to make it invisible, Oracle can still use the index to prevent certain locking issues. Before you drop an index on a column associated with a foreign key constraint, ensure that it is not used by Oracle to prevent locking issues. See the section “Indexing Foreign Key Columns,” later in this chapter, for details.
Guaranteeing Application Behavior Is Unchanged When You Add an Index
You can also use an invisible index when you are working with third-party applications. Often, third-party vendors do not support customers adding their own indexes to an application. However, there may be a scenario in which you are certain you can increase a query’s performance without affecting other queries in the application .
Keep in mind that invisible index simply means an index the optimizer cannot see. Just like any other index, an invisible index consumes space and resources during DML statements .
Maintaining Indexes
Renaming an index
Displaying the DDL for an index
Rebuilding an index
Setting indexes to unusable
Monitoring an index
Dropping an index
Each of these items is discussed in the following sections.
Renaming an Index
Displaying Code to Re-create an Index
Rebuilding an Index
Modifying storage characteristics, such as changing the tablespace
Rebuilding an index that was previously marked unusable to make it usable again
The DDL_LOCK_TIMEOUT initialization parameter instructs Oracle to repeatedly attempt to obtain a lock (for 15 seconds, in this case).
Note
See the sections “Avoiding Redo Generation When Creating an Index” and “Parallelizing Index Creation,” earlier in this chapter, for details on using these features with indexes.
Rebuilding for Performance Reasons
However, it is debatable whether rebuilding an index with the newer versions of Oracle achieves any performance gain. Usually, the only valid reason for rebuilding an index is that the index has become corrupt or unusable or that you want to modify storage characteristics (such as the tablespace) .
Making Indexes Unusable
If you have identified an index that is no longer being used, you can mark it UNUSABLE. From that point forward, Oracle will not maintain the index, nor will the optimizer consider the index for use in SELECT statements. The advantage of marking the index UNUSABLE (rather than dropping it) is that if you later determine that the index is being used, you can alter it to a USABLE state and rebuild it without needing the DDL on hand to re-create it.
Another common scenario for marking indexes UNUSABLE is that you are performing a large data load. When you want to maximize table-loading performance, you can mark the indexes UNUSABLE before performing the load. After you have loaded the table, you must rebuild the indexes to make them usable again.
Note
The alternative to setting an index to UNUSABLE is to drop and re-create it. This approach requires the CREATE INDEX DDL.
Monitoring Index Usage
You may have inherited a database, and as part of getting to know the database and application, you want to determine which indexes are being used (or not). The idea is that you can identify indexes that are not being used and drop them, thus eliminating the extra overhead and storage required.
The prior query removes the line from the query that restricts the currently logged-in user. This provides you with a convenient way to view all monitored indexes.
Caution
Keep in mind that Oracle can use an index defined on a foreign key column to prevent certain locking issues (see the sections “Determining if Foreign Key Columns Are Indexed” and “Implementing an Index on a Foreign Key Column,” later in this chapter, for further discussion). Oracle’s internal use of the index is not recorded in DBA_INDEX_USAGE or V$INDEX_USAGE_INFO. Be very careful before dropping an index defined on a foreign key column.
Dropping an Index
Dropping an index is a permanent DDL operation; there is no way to undo an index drop other than to rebuild the index. Before you drop an index, it does not hurt to quickly capture the DDL required to rebuild the index. Doing so will allow you to re-create the index in the event you subsequently discover that you did need it after all.
Indexing Foreign Key Columns
Foreign key constraints ensure that when inserting into a child table, a corresponding parent table record exists. This is the mechanism for guaranteeing that data conform to parent–child business relationship rules. Foreign keys are also known as referential integrity constraints.
Oracle can often make use of an index on foreign key columns to improve the performance of queries that join a parent table and child table (using the foreign key columns).
If no B-tree index exists on the foreign key columns, when you insert or delete a record from a child table, all rows in the parent table are locked. For applications that actively modify both the parent and child tables, this will cause locking and deadlock issues (see the section “Determining if Foreign Key Columns Are Indexed,” later in this chapter, for an example of this locking issue).
One could argue that if you know your application well enough and can predict that queries will not be issued that join tables on foreign key columns and that certain update/delete scenarios will never be encountered (that result in entire tables being locked), then, by all means, do not place an index on foreign key columns. In my experience, however, this is seldom the case: developers rarely think about how the “black box database” might lock tables; some DBAs are equally unaware of common causes of locking; teams experience high turnover rates, and the DBA de jour is left holding the bag for issues of poor database performance and hung sessions. Considering the time and resources spent chasing down locking and performance issues, it does not cost that much to put an index on each foreign key column in your application. I know some purists will argue against this, but I tend to avoid pain, and an unindexed foreign key column is a ticking bomb.
Having made my recommendation, I’ll first cover creating a B-tree index on a foreign key column. Then, I’ll show you some techniques for detecting unindexed foreign key columns.
Implementing an Index on a Foreign Key Column
Note
A foreign key column must reference a column in the parent table that has a primary key or unique key constraint defined on it. Otherwise, you will receive the error ORA-02270: no matching unique or primary key for this column-list.
You do not have to name the index the same name as the foreign key (as I did in these lines of code). It is a personal preference as to whether you do that. I feel it is easier to maintain environments when the constraint and corresponding index have the same name.
Note
An index on foreign key columns does not have to be of the type B-tree. In data warehouse environments, it is common to use bitmap indexes on foreign key columns in star schema fact tables. Unlike B-tree indexes, bitmap indexes on foreign key columns do not resolve parent–child table-locking issues. Applications that use star schemas typically are not deleting or modifying the child record from fact tables; therefore, locking is less of an issue, in this situation, regardless of the use bitmap indexes on foreign key columns .
Determining if Foreign Key Columns Are Indexed
If you are creating an application from scratch , it is fairly easy to create the code and ensure that each foreign key constraint has a corresponding index. However, if you have inherited a database, it is prudent to check if the foreign key columns are indexed.
This query, while simple and easy to understand, does not correctly report on unindexed foreign keys for all situations. For example, in the case of multicolumn foreign keys, it does not matter if the constraint is defined in an order different from that of the index columns, as long as the columns defined in the constraint are in the leading edge of the index. In other words, if the constraint is defined as COL1 and then COL2, then it is okay to have a B-tree index defined on leading-edge COL2 and then COL1.
Another issue is that a B-tree index protects you from locking issues, but a bitmap index does not. In this situation, the query should also check the index type .
This query will prompt you for a schema name and then will display foreign key constraints that do not have corresponding indexes. This query also checks for the index type; as previously stated, bitmap indexes may exist on foreign key columns but do not prevent locking issues .
Table Locks and Foreign Keys
The delete from the parent table hangs until the child table transaction is committed. Without a regular B-tree index on the foreign key column in the child table, any time you attempt to insert or delete in the child table, a table-wide lock is placed on the parent table; this prevents deletes or updates in the parent table until the child table transaction completes.
You should be able to run the prior two delete statements independently. When you have a B-tree index on the foreign key columns, if deleting from the child table, Oracle will not excessively lock all rows in the parent table .
Summary
Indexes are critical objects separate from tables; they vastly increase the performance of a database application. Your index architecture should be well planned, implemented, and maintained. Carefully choose which tables and columns are indexed. Although they dramatically increase the speed of queries, indexes can slow down DML statements, because the index has to be maintained as the table data changes. Indexes also consume disk space. Thus, indexes should be created only when required.
New versions of Oracle and more resources bring improvements to how index or table scans perform. With upgrades and changes to the database system, old indexes should be reviewed if they are still needed. SQL Tuning steps to verify the indexes are very important, and using tools such as making an index invisible will help to validate if an index is needed before being dropped.
Summary of Guidelines for Creating Indexes
Guideline | Reasoning |
|---|---|
Create as many indexes as you need, but try to keep the number to a minimum. Add indexes judiciously. Test first to determine quantifiable performance gains. | Indexes increase performance, but also consume disk space and processing resources and time for DML statements. Do not add indexes unnecessarily. |
The required performance of queries you execute against a table should form the basis of your indexing strategy. | Indexing columns used in SQL queries will help performance the most. |
Consider using the SQL Tuning Advisor or the SQL Access Advisor for indexing recommendations. | These tools provide recommendations and a second set of “eyes” on your indexing decisions. |
Create primary key constraints for all tables. | This will automatically create a B-tree index (if the columns in the primary key are not already indexed). |
Create unique key constraints where appropriate. | This will automatically create a B-tree index (if the columns in the unique key are not already indexed). |
Create indexes on foreign key columns. | Foreign key columns are usually included in the WHERE clause when joining tables and thus improve performance of SQL SELECT statements. Creating a B-tree index on foreign key columns also reduces locking issues when updating and inserting into child tables. |
Carefully select and test indexes on small tables (small being fewer than a few thousand rows). | Even on small tables, indexes can sometimes perform better than full-table scans. |
Use the correct type of index. | Correct index usage maximizes performance. See Table 8-1 for more details. |
Use the basic B-tree index type if you do not have a verifiable performance gain from using a different index type. | B-tree indexes are suitable for most applications in which you have high-cardinality column values. |
Consider using bitmap indexes in data warehouse environments. | These indexes are ideal for low-cardinality columns in which the values are not updated often. Bitmap indexes work well on foreign key columns on star schema fact tables in which you often run queries that use AND and OR join conditions. |
Consider using a separate tablespace for indexes (i.e., separate from tables). | Table and index data may have different storage or backup and recovery requirements, or both. Using separate tablespaces lets you manage indexes separately from tables. |
Let the index inherit its storage properties from the tablespace. | This makes it easier to manage and maintain index storage. |
Use consistent naming standards. | This makes maintenance and troubleshooting easier. |
Do not rebuild indexes unless you have a solid reason to do so. | Rebuilding indexes is generally unnecessary unless an index is corrupt or unusable, or you want to move an index to different tablespace. |
Monitor your indexes, and drop those that are not used. | Doing this frees up physical space and improves the performance of DML statements. |
Before dropping an index, consider marking it invisible. | This allows you to better determine if there are any performance issues before you drop the index. These options let you rebuild or re-enable the index without requiring the DDL creation statement. |
Refer to these guidelines as you create and manage indexes in your databases. These recommendations are intended to help you correctly use index technology.
Using automated tuning procedures and statistics from the Oracle database will provide information about the need and use of indexes. Along with understanding the strategies for using indexes, these tools will be helpful in managing the objects and using indexes to help with query performance.
After you build a database and users and configure the database with tables and indexes, the next step is to create additional objects needed by the application and users. Besides tables and indexes, typical objects include views, synonyms, and sequences. Building these database objects is detailed in the next chapter.