
2
The Basics of Java EE
WHAT’S IN THIS CHAPTER?
- Introduction to the core concepts of Java EE
- Discussion of the multitier structure of an enterprise application
- Explanation of Java EE–compliant servers and the web profile
- Convention over configuration overview
- Content Dependency Injection overview
- Interceptor overview
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
The wrox.com code download for this chapter is found at www.wrox.com/go/projavaeedesignpatterns on the Download Code tab. The code is in the Chapter 2 download and individually named according to the names throughout the chapter.
The Java EE programming model has been simplified substantially since J2EE. Annotations have replaced the XML descriptors files, convention over configuration have replaced the tedious manual configuration, and dependency injection hides the creation and lookup of resources. Developers need to reconsider their approach to design and coding.
The development of Java EE enterprise applications has gotten easier. All that you need is a POJO (Plain Old Java Object) annotated with some metadata and, depending on the annotation used, the POJO becomes an Enterprise JavaBeans (EJB, stateful or stateless), a servlet, a JSF backing bean, a persistence entity, a singleton, or a REST web service. You can optionally declare many of these services using XML in a deployment descriptor.
Listing 2-1 shows how to make a POJO into a singleton bean that is instantiated and initialized at start-up and then managed by the container simply by adding the @Singleton and @Startup annotations to the class and @PostConstruct to the initialization method. See Chapter 4, “Singleton Pattern,” for a detailed explanation of the use of these annotations.
The aim of Java EE has not changed; it continues to recognize the requirement that developers and enterprises have for distributed and transactional applications that harness speed, security, and reliability. The Java EE platform is designed to make the production of large-scale, multitiered applications easier, more reliable, and more secure.
MULTITIER ARCHITECTURE
The architecture of a Java EE application is separated into tiers: the Client tier, the Middle tier (which consists of the Web layer and the Business layer), and the Enterprise Information Systems (EIS) tier. Each tier has unique responsibilities and utilizes different Java EE technologies. The segregation of an application into distinct tiers brings greater flexibility and adaptability. You have the choice of adding or modifying just a specific layer rather than refactoring the entire application. Each tier is physically separate and located on different machines. And in the case of a web application, the Client tier is distributed globally.
Java EE works within the realm of the Middle tier, although it touches both the Client and the EIS tiers. The Middle tier receives requests from the Client tier application. The Middle tier’s Web layer processes the request and prepares a response, which it sends back to the Client tier, whereas the Business layer applies the business logic before persisting it in the EIS tier. Within the Middle tier, there is fluid communication between the layers and the EIS tier, while preparing the response to the Client tier. A multitier architecture can be represented visually, as in Figure 2.1.

Figure 2.1 Multitier architecture showing the interaction between tiers
THE CLIENT TIER
The Client tier is usually a browser that connects to the Java EE server via Hypertext Transfer Protocol (HTTP), although it can be any application on any machine as long as it behaves as a client in a server-client relationship. The client application sends a request to the server for a resource; the server then processes the request and returns a response. This is usually the extent of the relationship between the client and the server.
THE MIDDLE TIER
The Java EE server sits on the Middle tier and provides two logical containers: the web container and the EJB container. These containers roughly correspond to the Web layer and the Business layer, respectively. Each layer has distinct but sometimes overlapping responsibilities.
The MVC pattern is commonly used to clearly separate the view generation responsibilities of the Web layer from the data modeling responsibilities of the Business layer. Chapter 14, “Model Viewer Controller Pattern,” discusses in detail how to implement this separation of concerns.
Web Layer
The Web layer manages the interactions between the Client tier and the Business layer.
The Web layer receives a request for a resource from the Client tier. The request may include data that the user inputted, such as a username and password or sign-up information. The request is processed and, if necessary, an interaction between the Web layer and the Business layer takes place. The response is dynamically prepared in one of several forms (usually in the form of a HyperText Markup Language [HTML] web page for a response originating from a browser) and sent to the client.
The Web layer maintains the user’s states in a session and may even perform some business logic and temporarily persist data in memory.
The technologies that are typically used in the Web layer relate to the management of the interactions between the Client tier and the Middle tier and the construction of the response. Serlvets control the web flow and manage interactions while JavaServer Pages (JSP), Expression Language (EL), and JavaServer Pages Standard Tag Library (JSTL) prepare the response to the client. This is just a snapshot of the technologies that you can use in the Web layer. For a complete list, see Figure 2.2.
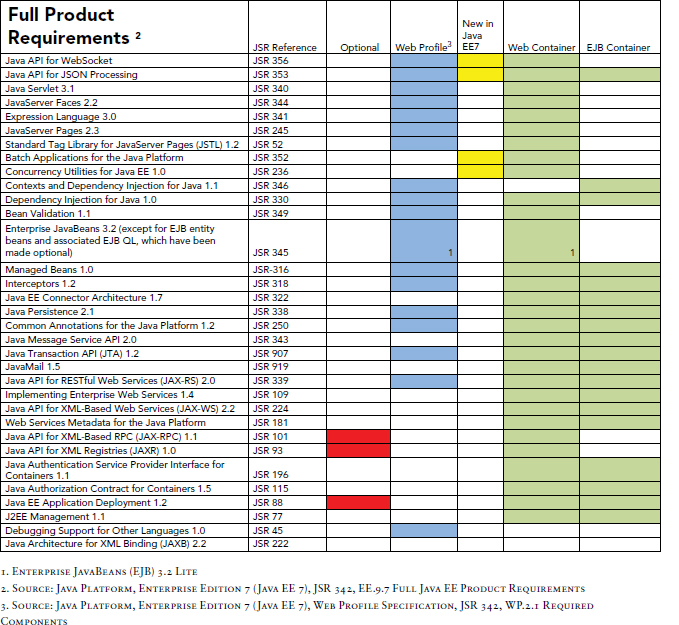
Figure 2.2 Technology used in the Web and Business layers
In Java EE 7, four new technologies were added to the EE universe: WebSockets, Concurrency Utilities, Batch, and JSON-P. You can use all but WebSockets in both layers.
Business Layer
The Business layer executes business logic that resolves business problems or satisfies a particular business need within the business domain.
Normally, this would involve data that has been retrieved from the database in the EIS tier or collected from the client. In a banking domain, a transaction fee might be applied to a transaction amount and sent to the client via the Web layer for the client to confirm the transaction. In an e-commerce domain, a different tax rate might be applied to a product depending on the physical location of the client before being passed to the Web layer, and the web page would be rendered according to this info.
The Business layer is where the core logic of the business application resides. Business logic is wrapped up in the EJB, and the data used by the business logic is retrieved from the EIS tier via Java Persistence API (JPA), Java Transaction API (JTA), and Java Database Connectivity (JDBC). It is common to request and modify data via web services that use JAX-RS and JAX-WS. (See Chapter 14, “REST,” for more on this topic.) This is just a snapshot of the technologies that you can use in the web layer. For a complete list, see Figure 2.2.
THE EIS TIER
The EIS tier consists of data storage units, often in the form of databases, but they can be any resource that provides data. It may be an antiquated legacy system or a file system.
JAVA EE SERVERS
As you have seen, the Middle tier hosts the Java EE server, which provides the Java EE functionality needed for an enterprise application.
Java EE is based on 30 standards, called Java Specification Requests (JSRs) (http://www.oracle
.com/technetwork/java/javaee/tech/index.html). These requests go through the Java Community Process (JCP) before they can become accepted as part of the Java EE universe. The JCP is an open process in which anyone can participate and give feedback on JSRs or even submit their own JSR (https://www.jcp.org/en/home/index).
These specifications are bundled together and represent the technologies that a server application must implement to be able to claim that it is Java EE compliant.
Additionally, Oracle requires that the server application passes the Technology Compatibility Kit (TCK). This is a nontrivial test suite that checks that the application server behaves as the specification requires. This ensures that if you develop your application following the Java EE specifications, you will be able to deploy and execute it on any Java EE application.
At the time of writing, three application servers have been certified fully compatible with Java EE 7. They are GlassFish Server Open Source Edition 4.0 (http://glassfish.java.net), Wildfly 8.0.0 (http://wildfly.org), and TMAX JEUS 8 (http://tmaxsoft.com/product/jeus/certification/). Eleven application servers are Java EE 6 compatible (http://en.wikipedia
.org/wiki/Java_Platform,_Enterprise_Edition#Java_EE_6_certified).
THE JAVA EE WEB PROFILE
The Java EE web profile is a subset of technologies that comprise the most appropriate technologies required for the development of web-based enterprise applications. The profile reduces the size and complexity of the platform to just the technologies required for the development of a modern web application. The web profile is a complete stack comprising technologies related to workflow and core functionality (Servlet), presentation (JSF and JSP), business logic (EJB lite), transactions (JTA), persistence (JPA), the new WebSocket, and much more. It omits a lot of enterprise-related technologies such as the Concurrency Utilities, Java Message Services, JAX-RPC, JAXR, and JAX-WS. See Figure 2.2 for a complete rundown of the technologies included in the web profile.
CORE PRINCIPLES OF JAVA EE
The core principles of Java EE include a number of design paradigms and patterns that are essential to the way you develop enterprise applications. At the center of Java EE is the design paradigm of convention over configuration: a way to simplify the development of enterprise applications without losing flexibility and obscuring its code’s purpose. It is not a new idea and has been a part of other frameworks including Grails, Ruby on Rails, and Spring Boot for some time—in some cases for nearly a decade. Thankfully, it has made its way into the heart of Java EE, where it helps others write beautiful code.
Java EE makes good use of its component model, which includes the components Entities, JavaBeans, EJBs, Managed Beans, Servlets, SOAP, and RESTful web services. All these components can be “injectable” dependencies; the container manages, in some way, their life cycle (from instantiation to destruction)—whether they are bound to a context or not—and their decoupling from dependent components via dependency injection.
A loosely coupled application allows for extensibility: Old classes can be swapped with new ones with no requirement to change the dependent class. Dependency injection decouples an object from its dependencies, whereas interceptors decouple business concerns from technical and cross-cutting concerns. Such technological concerns would be performance and logging, and a cross-cutting concern would be security.
CONVENTION OVER CONFIGURATION
All class names should start with a capital letter as part of convention. It’s not obligatory; the class will still compile if it starts with a lowercase letter, but starting with a capital letter makes the code easier to read and maintain. When setting up a project in an IDE, you only need to specify the type of the project and its name for the most appropriate directory structure to be created; the most common application programming interfaces (APIs) to be imported; and the default files such as web.xml, index.jsp, etc. to be created with appropriate default settings for ease of development. You do all of this based on agreed convention.
The amount of work you have to do and the decisions you have to make as a developer are substantially reduced when you rely on convention. You don’t specify any configuration that is considered conventional; you are required to specify only the unconventional. This has a significant effect. With just a few annotations on a POJO, you can do away with a lot of your ugly XML deployment descriptors and application configuration files. As you have seen in Listing 2-1, you need to apply just three annotations to make a POJO into a singleton bean that will be instantiated and initialized at start-up and then managed by the container.
CONTEXT AND DEPENDENCY INJECTION
Dependency injection is a design pattern (see Chapter 5, “Dependency Injection and CDI”) that decouples the relationship between a component and its dependencies. It does this by injecting the dependency into an object rather than the object creating the dependency by using the new keyword. By removing the creation of the dependency from the object and delegating that responsibility to the container, you can swap out the dependency for another compatible object at compile time and run time.
Beans that the container manages are called Context and Dependency Injection (CDI)-managed beans and are instantiated when the container starts up. All POJOs that have a default constructor and are not created using the new keyword are CDI beans that are injected into an object based on type matching. To be injected, the receiving object must declare a field, constructor, or method using the @Inject annotation. Then the type of the declared object is used to determine which dependency to inject.
In Listing 2-2, you have a POJO that has a default constructor and therefore will be managed as a CDI bean, and in Listing 2-3, you inject the managed bean. The container knows to inject the Message bean based on its type. The container manages only one CDI bean of type Message, so this is the bean it injects.
An inquiring mind might ask: What happens if the container is managing more than one bean of type Message? For this to be true, Message would have to be an interface that has more than one concrete implementation. This is where it becomes more interesting . There are several strategies that you can employ to resolve these types of ambiguities. You will encounter several of these during the course of this book. If curiosity has gotten the better of you, skip to Chapter 5.
Context is the distinguishing feature between EJBs and CDI-managed beans. CDI beans exist within a defined context; EJBs do not. CDI beans are created within the context of a scope; they exist for the life of the scope and are destroyed when the scope finishes. There are four scopes that are annotated as follows: @ApplicationScope, @ConversationScope, @SessionScope, and @RequestScope. The CDI container controls the life of a bean based on the bean’s defined scope. For example, a bean annotated with @SessionScope exists for as long as the HTTP session is alive; at the end the scope, the bean is destroyed and marked for garbage collection. This behavior is in contrast to that of EJBs, which are not bound to a scope. This means that you must explicitly remove the bean by calling a method annotated by the @Remove annotation.
INTERCEPTORS
Most applications have concerns that don’t comfortably fit into the core concern of the application logic but cannot be cleanly separated from the application’s design or implementation. These concerns are cross-cutting and affect different parts of the application. They are often responsible for duplicate code and interdependencies that make the system less extensible. The implementation of these noncore concerns as interceptors allows them to be decoupled from the core concern. You do this by logically separating their implementation and intercepting method calls to the core and invoking the appropriate method.
You implement interceptors using the annotation @Interceptors followed by the class name of the crossing-cutting concern. In Listing 2-4, the setValue method is intercepted upon its invocation by the LoggerInterceptor.class.
The logger interceptor can access the intercepted method’s parameters and perform the cross-cutting logic before returning to fully execute the intercepted method.
In Listing 2-5, the logger interceptor accesses the parameters of the setValues method and logs them to the system logger.
You can define interceptors in the business code and in the deployment descriptor files. This aspect of interceptors and much more is discussed in Chapter 8, “Aspect-Oriented Programming (Interceptors).”
SUMMARY
In this chapter, you have seen a brief summary of Java EE and the history of the current principles of it.
You have discovered how the architecture should be layered properly in a Java EE project. We also provide a long JSR compatibility list to help you determine which container best suits your project. Finally the chapter focused on Core Principles of Java EE by presenting convention over configuration and giving a brief summary of CDI.
Next, we will be ready to move on to each pattern, focusing on their implementations and providing specific examples.
EXERCISES
-
Think about a banking application where you need to integrate into the mainframe back end and provide services for web, mobile, and native desktop clients.
-
Think about implementing the web application for the project you designed in the first step. Which layer should host the web application?
-
After a long debate, the bank you are working for decided to move away from the mainframe, asking you to design a substitute system. What parts of the current project will be impacted?