
Chapter 6. Memory
Tyrell: If we give them a past, we create a cushion for their emotions and, consequently, we can control them better.Deckard: Memories. You’re talking about memories.
In this chapter, you will learn everything you need to know about memory in embedded systems. In particular, you will learn about the types of memory you are likely to encounter, how to test memory devices to see whether they are working properly, and how to use flash memory.
Types of Memory
Many types of memory devices are available for use in modern computer systems. As an embedded software engineer, you must be aware of the differences between them and understand how to use each type effectively. In our discussion, we will approach these devices from a software viewpoint. As you are reading, try to keep in mind that the development of these devices took several decades. The names of the memory types frequently reflect the historical nature of the development process.
Most software developers think of memory as being either RAM or ROM. But, in fact, there are subtypes of each class, and even a third class of hybrid memories that exhibit some of the characteristics of both RAM and ROM. In a RAM device, the data stored at each memory location can be read or written, as desired. In a ROM device, the data stored at each memory location can be read at will, but never written. The hybrid devices offer ROM-like permanence, but under some conditions it is possible to overwrite their data. Figure 6-1 provides a classification system for the memory devices that are commonly found in embedded systems.
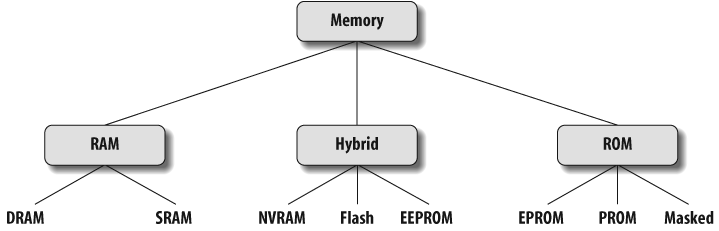
Types of RAM
There are two important memory devices in the RAM family: SRAM and DRAM. The main difference between them is the duration of the data stored. Static RAM (SRAM) retains its contents as long as electrical power is applied to the chip. However, if the power is turned off or lost temporarily, its contents will be lost forever. Dynamic RAM (DRAM), on the other hand, has an extremely short data lifetime—usually less than a quarter of a second. This is true even when power is applied continuously.
In short, SRAM has all the properties of the memory you think of when you hear the word RAM. Compared with that, DRAM sounds kind of useless. What good is a memory device that retains its contents for only a fraction of a second? By itself, such a volatile memory is indeed worthless. However, a simple piece of hardware called a DRAM controller can be used to make DRAM behave more like SRAM (see the sidebar “DRAM Controllers,” in this section for more information). The job of the DRAM controller, often included within the processor, is to periodically refresh the data stored in the DRAM. By refreshing the data several times a second, the DRAM controller keeps the contents of memory alive for as long as they are needed. So, DRAM is as useful as SRAM after all.
When deciding which type of RAM to use, a system designer must consider access time and cost. SRAM devices offer extremely fast access times (approximately four times faster than DRAM) but are much more expensive to produce. Generally, SRAM is used only where access speed is crucial. However, if a system requires only a small amount of memory, SRAM may make more sense because you could avoid the cost of a DRAM controller.
A much lower cost-per-byte makes DRAM attractive whenever large amounts of RAM are required. DRAM is also available in much larger capacities than SRAM. Many embedded systems include both types: a small block of SRAM (a few hundred kilobytes) along a critical data path and a much larger block of DRAM (in the megabytes) for everything else. Some small embedded systems get by without any added memory: they use only the microcontroller’s on-chip memory.
Tip
There are quite a few variations of DRAM you may encounter, including Synchronous DRAM (SDRAM), Double Data Rate SDRAM (DDR SDRAM), and Rambus DRAM (RDRAM).
Types of ROM
Memories in the ROM family are distinguished by the methods used to write new data to them (usually called programming or burning) and the number of times they can be rewritten. This classification reflects the evolution of ROM devices from hardwired to one-time programmable to erasable-and-programmable. A common feature across all these devices is their ability to retain data and programs forever, even when power is removed.
The very first ROMs were hardwired devices that contained a preprogrammed set of data or instructions. The contents of the ROM had to be specified before chip production, so the actual data could be used to arrange the transistors inside the chip! Hardwired memories are still used, though they are now called masked ROMs to distinguish them from other types of ROM. The main advantage of a masked ROM is a low production cost. Unfortunately, the cost is low only when hundreds of thousands of copies of the same ROM are required, and no changes are ever needed.
Another type of ROM is the programmable ROM (PROM), which is purchased in an unprogrammed state. If you were to look at the contents of an unprogrammed PROM, you would see that all the bits are 1s. The process of writing your data to the PROM involves a special piece of equipment called a device programmer, which writes data to the device by applying a higher-than-normal voltage to special input pins of the chip. Once a PROM has been programmed in this way, its contents can never be changed. If the code or data stored in the PROM must be changed, the chip must be discarded and replaced with a new one. As a result, PROMs are also known as one-time programmable (OTP) devices. Many small embedded microcontrollers are also considered one-time programmable, because they contain built-in PROM.
An erasable-and-programmable ROM (EPROM) is programmed in exactly the same manner as a PROM. However, EPROMs can be erased and reprogrammed repeatedly. To erase an EPROM, simply expose the device to a strong source of ultraviolet light. (There is a “window” in the top of the device to let the ultraviolet light reach the silicon. You can buy an EPROM eraser containing this light.) By doing this, you essentially reset the entire chip to its initial—unprogrammed—state. The erasure time of an EPROM can be anything from 10 to 45 minutes, which can make software debugging a slow process.
Though more expensive than PROMs, their ability to be reprogrammed made EPROMs a common feature of the embedded software development and testing process for many years. It is now relatively rare to see EPROMs used in embedded systems, as they have been supplanted by newer technologies.
Hybrid Types
As memory technology has matured in recent years, the line between RAM and ROM devices has blurred. There are now several types of memory that combine the best features of both. These devices do not belong to either group and can be collectively referred to as hybrid memory devices. Hybrid memories can be read and written as desired, like RAM, but maintain their contents without electrical power, just like ROM. Write cycles to hybrid memories are similar to RAM, but they take significantly longer than writes to a RAM, so you wouldn’t want to use this type for your main system memory. Two of the hybrid devices, EEPROM and flash, are descendants of ROM devices; the third, NVRAM, is a modified version of SRAM.
An electrically-erasable-and-programmable ROM (EEPROM) is internally similar to an EPROM, but with the erase operation accomplished electrically. Additionally, a single byte within an EEPROM can be erased and rewritten. Once written, the new data will remain in the device forever—or at least until it is electrically erased. One tradeoff for this improved functionality is higher cost; another is that typically EEPROM is good for 10,000 to 100,000 write cycles.
EEPROMs are available in a standard (address and data bus) parallel interface as well as a serial interface. In many designs, the Inter-IC (I2C) or Serial Peripheral Interface (SPI) buses are used to communicate with serial EEPROM devices. We’ll take a look at the I2C and SPI buses in Chapter 13.
Flash is the most important recent advancement in memory technology. It combines all the best features of the memory devices described thus far. Flash memory devices are high-density, low-cost, nonvolatile, fast (to read, but not to write), and electrically reprogrammable. These advantages are overwhelming, and the use of flash memory has increased dramatically in embedded systems as a direct result.
Erasing and writing data to a flash memory requires a specific sequence of writes using certain data values. From a software viewpoint, flash and EEPROM technologies are very similar. The major difference is that flash devices can be erased only one sector at a time, not byte by byte. Typical sector sizes range from 8 KB to 64 KB. Despite this disadvantage, flash is much more popular than EEPROM and is rapidly displacing many of the ROM devices as well.
The third member of the hybrid memory class is nonvolatile RAM (NVRAM). Nonvolatility is also a characteristic of the ROM and hybrid memories discussed earlier. However, an NVRAM is physically very different from those devices. An NVRAM is usually just an SRAM with a battery backup. When the power is on, the NVRAM operates just like any other SRAM. But when the power is off, the NVRAM draws just enough electrical power from the battery to retain its current contents. NVRAM is sometimes found in embedded systems to store system-critical information. Incidentally, the “CMOS” in an IBM-compatible PC was historically an NVRAM.
Table 6-1 summarizes the characteristics of different memory types.
| Memory type | Volatile? | Writable? | Erase/rewrite size | Erase/rewrite cycles | Relative cost | Relative speed |
| SRAM | Yes | Yes | Byte | Unlimited | Expensive | Fast |
| DRAM | Yes | Yes | Byte | Unlimited | Moderate | Moderate |
| Masked ROM | No | No | N/A | N/A | Inexpensive (in quantity) | Slow |
| PROM | No | Once, with programmer | N/A | N/A | Moderate | Slow |
| EPROM | No | Yes, with programmer | Entire chip | Limited (see specs) | Moderate | Slow |
| EEPROM | No | Yes | Byte | Limited (see specs) | Expensive | Moderate to read, slow to write |
| Flash | No | Yes | Sector | Limited (see specs) | Moderate | Fast to read, slow to write |
| NVRAM | No | Yes | Byte | None | Expensive | Fast |
Direct Memory Access
Since we are discussing memory, this is a good time to discuss a memory transfer technique called direct memory access (DMA). DMA is a technique for transferring blocks of data directly between two hardware devices with minimal CPU involvement. In the absence of DMA, the processor must read the data from one device and write it to the other, one byte or word at a time. For each byte or word transferred, the processor must fetch and execute a sequence of instructions. If the amount of data to be transferred is large, or the frequency of transfers is high, the rest of the software might never get a chance to run. However, if a DMA controller is present, it can perform the entire transfer, with little assistance from the processor.
Here’s how DMA works. When a block of data needs to be transferred, the processor provides the DMA controller with the source and destination addresses and the total number of bytes. The DMA controller then transfers the data from the source to the destination automatically. When the number of bytes remaining reaches zero, the block transfer ends.
In a typical DMA scenario, the block of data is transferred directly to or from memory. For example, a network controller might want to place an incoming network packet into memory as it arrives but notify the processor only once the entire packet has been received. By using DMA, the processor can spend more time processing the data once it arrives and less time transferring it between devices. The processor and DMA controller must use the same address and data buses during this time, but this is handled automatically by the hardware, and the processor is otherwise uninvolved with the actual transfer. During a DMA transfer, the DMA controller arbitrates control of the bus between the processor and the DMA operation.
Endian Issues
Endianness is the attribute of a system that indicates whether integers are represented from left to right or right to left. Why, in today’s world of virtual machines and gigaHertz processors, would a programmer care about such a silly topic? Well, unfortunately, endianness must be chosen every time a hardware or software architecture is designed, and there isn’t much in the way of natural law to help in the decision.
Endianness comes in two varieties: big and little. A big-endian representation has a multibyte integer written with its most significant byte on the left; a number represented thus is easily read by English-speaking humans. A little-endian representation, on the other hand, places the most significant byte on the right. Of course, computer architectures don’t have an intrinsic “left” or “right.” These human terms are borrowed from our written forms of communication. The following definitions are more precise:
- Big-endian
Means that the most significant byte of any multibyte data field is stored at the lowest memory address, which is also the address of the larger field
- Little-endian
Means that the least significant byte of any multibyte data field is stored at the lowest memory address, which is also the address of the larger field
The origin of the odd terms big-endian and little-endian can be traced to the 1726 book Gulliver’s Travels, by Jonathan Swift. In one part of the story, resistance to an imperial edict to break soft-boiled eggs on the “little end” escalates to civil war. The plot is a satire of England’s King Henry VIII’s break with the Catholic Church. A few hundred years later, in 1981, Danny Cohen applied the terms and the satire to our current situation in IEEE Computer (vol. 14, no. 10).
Endianness in Devices
Endianness doesn’t matter on a single system. It matters only when two computers are trying to communicate. Every processor and every communication protocol must choose one type of endianness or the other. Thus, two processors with different endianness will conflict if they communicate through a memory device. Similarly, a little-endian processor trying to communicate over a big-endian network will need to do software-byte reordering.
Intel’s 80x86 processors and their clones are little-endian. Sun’s SPARC, Motorola’s 68K, and the PowerPC families are all big-endian. Some processors even have a bit in a register that allows the programmer to select the desired endianness. The PXA255 processor supports both big- and little-endian operation via bit 7 in Control Register 1 (Coprocessor 15 (CP15) register 1).
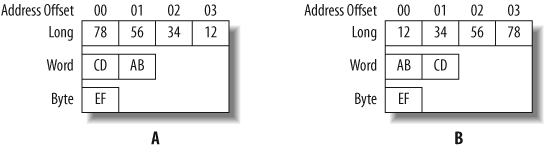
An endianness difference can cause problems if a computer unknowingly tries to read binary data written in the opposite format from a shared memory location or file. Figure 6-2(a) shows the memory contents for the data 0x12345678 (a long), 0xABCD (a word), and 0xEF (a byte) on a little-endian machine. The same data represented on a big-endian machine is shown in Figure 6-2(b).
Endianness in Networking
Another area where endianness is an issue is in network communications. Since different processor types (big-endian and little-endian) can be on the same network, they must be able to communicate with each other. Therefore, network stacks and communication protocols must also define their endianness. Otherwise, two nodes of different endianness would be unable to communicate. This is a more substantial example of endianness affecting the embedded programmer.
As it turns out, all of the protocol layers in the TCP/IP suite are defined as big-endian. In other words, any 16- or 32-bit value within the various layer headers (for example, an IP address, a packet length, or a checksum) must be sent and received with its most significant byte first.
Let’s say you wish to establish a TCP socket connection to a computer whose IP address is 192.0.1.2. IPv4 uses a unique 32-bit integer to identify each network host. The dotted decimal IP address must be translated into such an integer.
The multibyte integer representation used by the TCP/IP protocols is sometimes called network byte order. Even if the computers at each end are little-endian, multibyte integers passed between them must be converted to network byte order prior to transmission across the network, and then converted back to little-endian at the receiving end.
Suppose an 80x86-based, little-endian PC is talking to a SPARC-based, big-endian server over the Internet. Without further manipulation, the 80x86 processor would convert 192.0.1.2 to the little-endian integer 0x020100C0 and transmit the bytes in the following order: 0x02, 0x01, 0x00, 0xC0. The SPARC would receive the bytes in the followng order: 0x02, 0x01, 0x00, 0xC0. The SPARC would reconstruct the bytes into a big-endian integer 0x020100c0, and misinterpret the address as 2.1.0.192.
Preventing this sort of confusion leads to an annoying little implementation detail for TCP/IP stack developers. If the stack will run on a little-endian processor, it will have to reorder (at runtime) the bytes of every multibyte data field within the various layers’ headers. If the stack will run on a big-endian processor, there’s nothing to worry about. For the stack to be portable (that is, to be able to run on processors of both types), it will have to decide whether or not to do this reordering. The decision is typically made at compile time.
A common solution to the endianness problem is to define a set of four preprocessor macros:
htons()Reorder the bytes of a 16-bit unsigned value from processor order to network order. The macro name can be read “host to network short.”
htonl()Reorder the bytes of a 32-bit unsigned value from processor order to network order. The macro name can be read “host to network long.”
ntohs()Reorder the bytes of a 16-bit unsigned value from network order to processor order. The macro name can be read “network to host short.”
ntohl()Reorder the bytes of a 32-bit unsigned value from network order to processor order. The macro name can be read “network to host long.”
Following is an example of the implementation of these macros.
We will take a look at the left shift (<<) and right shift (>>) operators in Chapter 7.
#if defined(BIG_ENDIAN) && !defined(LITTLE_ENDIAN)
#define htons(A) (A)
#define htonl(A) (A)
#define ntohs(A) (A)
#define ntohl(A) (A)
#elif defined(LITTLE_ENDIAN) && !defined(BIG_ENDIAN)
#define htons(A) ((((uint16_t)(A) & 0xff00) >> 8) | \
(((uint16_t)(A) & 0x00ff) << 8))
#define htonl(A) ((((uint32_t)(A) & 0xff000000) >> 24) | \
(((uint32_t)(A) & 0x00ff0000) >> 8) | \
(((uint32_t)(A) & 0x0000ff00) << 8) | \
(((uint32_t)(A) & 0x000000ff) << 24))
#define ntohs htons
#define ntohl htohl
#else
#error Either BIG_ENDIAN or LITTLE_ENDIAN must be #defined, but not both.
#endifIf the processor on which the TCP/IP stack is to be run is itself also big-endian, each of the four macros will be defined to do nothing, and there will be no runtime performance impact. If, however, the processor is little-endian, the macros will reorder the bytes appropriately. These macros are routinely called when building and parsing network packets and when socket connections are created.
Runtime performance penalties can occur when using TCP/IP on a little-endian processor. For that reason, it may be unwise to select a little-endian processor for use in a device with an abundance of network functionality, such as a router or gateway. Embedded programmers must be aware of the issue and be prepared to convert between their different representations as required.
Memory Testing
One of the first pieces of serious embedded software you are likely to write is a memory test. Once the prototype hardware is ready, the designer would like some reassurance that he has wired the address and data lines correctly and that the memory chips are working properly. At first this might seem like a fairly simple assignment, but as you look at the problem more closely, you will realize that it can be difficult to detect subtle memory problems with a simple test. In fact, as a result of programmer naiveté, many embedded systems include memory tests that would detect only the most catastrophic memory failures. Some of these might not even notice that the memory chips have been removed from the board!
The purpose of a memory test is to confirm that each storage location in a memory device is working. In other words, if you store the number 50 at a particular address, you expect to find that number stored there until another number is written. The basic idea behind any memory test, then, is to write some set of data values to each address in the memory device and verify the data by reading it back. If all of the values read back are the same as those that were written, then the memory device is said to pass the test. As you will see, it is only through careful selection of the set of data values that you can be sure that a passing result is meaningful.
Of course, a memory test such as the one just described is unavoidably destructive. In the process of testing the memory, you must overwrite its prior contents. Because it is generally impractical to overwrite the contents of nonvolatile memories, the tests described in this section are generally used only for RAM testing. In fact, running comprehensive memory tests on flash or EEPROM is often a bad idea because the number of writes involved can shorten the useful life of the device. However, if the contents of a hybrid memory are unimportant—as they are during the product development stage—these same algorithms can be used to test those devices as well. We address the problem of validating the contents of a nonvolatile memory in the section “Validating Memory Contents,” later in this chapter.
Common Memory Problems
Before learning about specific test algorithms, you should be familiar with the types of memory problems that are likely to occur. One common misconception among software engineers is that most memory problems occur within the chips themselves. Though a major issue at one time (a few decades ago), problems of this type are increasingly rare. The manufacturers of memory devices perform a variety of post-production tests on each batch of chips. If there is a problem with a particular batch, it is unlikely that one of the bad chips will make its way into your system.
The one type of memory chip problem you could encounter is a catastrophic failure. This is usually caused by some sort of physical or electrical damage to the chip after manufacture. Catastrophic failures are uncommon, and they usually affect large portions of the chip. Because a large area is affected, it is reasonable to assume that catastrophic failure will be detected by any decent test algorithm.
In our experience, a more common source of memory problems is the circuit board. Typical circuit board problems are:
Problems with the wiring between the processor and memory device
Missing memory chips
Improperly inserted memory chips
These are the problems that a good memory test algorithm should be able to detect. Such a test should also be able to detect catastrophic memory failures without specifically looking for them. So let’s discuss circuit board problems in more detail.
Electrical wiring problems
An electrical wiring problem could be caused by an error in design or production of the board or as the result of damage received after manufacture. Each of the wires that connect the memory device to the processor is one of three types:
Address signal
Data signal
Control signal
The address and data signals select the memory location and transfer the data, respectively. The control signals tell the memory device whether the processor wants to read or write the location and precisely when the data will be transferred. Unfortunately, one or more of these wires could be improperly routed or damaged in such a way that it is either shorted (i.e., connected to another wire on the board) or open (not connected to anything). Shorting is often caused by a bit of solder splash, whereas an open wire could be caused by a broken trace. Both cases are illustrated in Figure 6-3.

Problems with the electrical connections to the processor will cause the memory device to behave incorrectly. Data might be corrupted when it’s stored, stored at the wrong address, or not stored at all. Each of these symptoms can be explained by wiring problems on the data, address, and control signals, respectively.
If the problem is with a data signal, several data bits might appear to be “stuck together” (i.e., two or more bits always contain the same value, regardless of the data transmitted). Similarly, a data bit might be either “stuck high” (always 1) or “stuck low” (always 0). These problems can be detected by writing a sequence of data values designed to test that each data pin can be set to 0 and 1, independently of all the others.
If an address signal has a wiring problem, the contents of two memory locations might appear to overlap. In other words, data written to one address will instead overwrite the contents of another address. This happens because an address bit that is shorted or open causes the memory device to see an address different from the one selected by the processor.
Another possibility is that one of the control signals is shorted or open. Although it is theoretically possible to develop specific tests for control signal problems, it is not possible to describe a general test that covers all platforms. The operation of many control signals is specific to either the processor or the memory architecture. Fortunately, if there is a problem with a control signal, the memory probably won’t work at all, and this will be detected by other memory tests. If you suspect a problem with a control signal, it is best to seek the advice of the board’s designer before constructing a specific test.
Missing memory chips
A missing memory chip is clearly a problem that should be detected. Unfortunately, because of the capacitive nature of unconnected electrical wires, some memory tests will not detect this problem. For example, suppose you decided to use the following test algorithm: write the value 1 to the first location in memory, verify the value by reading it back, write 2 to the second location, verify the value, write 3 to the third location, verify, and so on. Because each read occurs immediately after the corresponding write, it is possible that the data read back represents nothing more than the voltage remaining on the data bus from the previous write. If the data is read back quickly, it will appear that the data has been correctly stored in memory, even though there is no memory chip at the other end of the bus!
To detect a missing memory chip, a better test must be used. Instead of performing the verification read immediately after the corresponding write, perform several consecutive writes followed by the same number of consecutive reads. For example, write the value 1 to the first location, write the value 2 to the second location, write the value 3 to the third location, and then verify the data at the first location, the second location, and so on. If the data values are unique (as they are in the test just described), the missing chip will be detected: the first value read back will correspond to the last value written (3) rather than to the first (1).
Improperly inserted chips
If a memory chip is present but improperly inserted, some pins on the memory chip will either not be connected to the circuit board at all or will be connected at the wrong place. These pins will be part of the data bus, address bus, or control wiring. The system will usually behave as though there is a wiring problem or a missing chip. So as long as you test for wiring problems and missing chips, any improperly inserted chips will be detected automatically.
Before going on, let’s quickly review the types of memory problems we must be able to detect. Memory chips only rarely have internal errors, but if they do, they are typically catastrophic in nature and should be detected by any test. A more common source of problems is the circuit board, where a wiring problem can occur or a memory chip might be missing or improperly inserted. Other memory problems can occur, but the ones described here are the most common and also the simplest to test in a generic way.
Developing a Test Strategy
By carefully selecting your test data and the order in which the addresses are tested, you can detect all of the memory problems described earlier. It is usually best to break your memory test into small, single-purpose pieces. This helps to improve the efficiency of the overall test and the readability of the code. More specific tests can also provide more detailed information about the source of the problem, if one is detected.
We have found that it is best to have three individual memory tests, which should be executed in the following order:
Data bus test
Address bus test
Device test
The first two test for electrical wiring problems and improperly inserted chips; the third is intended to detect missing chips and catastrophic failures. As an unintended consequence, the device test will also uncover problems with the control bus wiring, though it cannot provide useful information about the source of such a problem.
The reason the order is important is that the address bus test assumes a working data bus, and the device test results are meaningless unless both the address and data buses are known to be sound. If any of the tests fail, you should work with a hardware engineer to locate the source of the problem. By looking at the data value or address at which the test failed, she should be able to quickly isolate the problem on the circuit board.
Data bus test
The first thing we want to test is the data bus wiring. We need to confirm that any value placed on the data bus by the processor is correctly received by the memory device at the other end. The most obvious way to test that is to write all possible data values and verify that the memory device stores each one successfully. However, that is not the most efficient test available. A faster method is to test the bus one bit at a time. The data bus passes the test if each data bit can be set to 0 and 1, independently of the other data bits.
A good way to test each bit independently is to perform the so-called walking 1’s test. Table 6-2 shows the data patterns used in an 8-bit version of this test. The name walking 1’s comes from the fact that a single data bit is set to 1 and “walked” through the entire data word. The number of data values to test is the same as the width of the data bus. This reduces the number of test patterns from 2n to n, where n is the width of the data bus.
| 00000001 |
| 00000010 |
| 00000100 |
| 00001000 |
| 00010000 |
| 00100000 |
| 01000000 |
| 10000000 |
Because we are testing only the data bus at this point, all of the data values can be written to the same address. Any address within the memory device will do. However, if the data bus splits as it makes its way to more than one memory chip, you will need to perform the data bus test at multiple addresses—one within each chip.
To perform the walking 1’s test, simply write the first data value in the table, verify it by reading it back, write the second value, verify, and so on. When you reach the end of the table, the test is complete. This time, it is okay to do the read immediately after the corresponding write because we are not yet looking for missing chips. In fact, this test may provide meaningful results even if the memory chips are not installed!
The function memtestDataBus
shows how to implement the walking 1’s test. It assumes that the
caller will select the test address, and tests the entire set of
data values at that address. If the data bus is working properly,
the function returns 1 and the parameter ppFailAddr is set to NULL. Otherwise it returns 0, and the
address at which the test failed is returned in the parameter
ppFailAddr.
/* Set the data bus width to 32 bits. */
typedef uint32_t datum;
/**********************************************************************
*
* Function: memtestDataBus
*
* Description: Test the data bus wiring in a memory region by
* performing a walking 1's test at a fixed address
* within that region. The address (and hence the
* memory region) is selected by the caller.
*
* Notes:
*
* Returns: 0 if the test fails. The failure address is returned
* in the parameter ppFailAddr.
* 1 if the test succeeds. The parameter ppFailAddr is
* set to NULL.
*
**********************************************************************/
int memtestDataBus(datum *pAddress, datum **ppFailAddr)
{
datum pattern;
*ppFailAddr = NULL;
/* Perform a walking 1's test at the given address. */
for (pattern = 1; pattern != 0; pattern <<= 1)
{
/* Write the test pattern. */
*pAddress = pattern;
/* Read it back (immediately is okay for this test). */
if (*pAddress != pattern)
{
*ppFailAddr = pAddress;
return 0;
}
}
return 1;
}Address bus test
After confirming that the data bus works properly, you should next test the address bus. Address bus problems lead to overlapping memory locations. There are many possible addresses that could overlap. However, it is not necessary to check every possible combination. You should instead follow the example of the previous data bus test and try to isolate each address pin during testing. You simply need to confirm that each of the address pins can be set to 0 and 1 without affecting any of the others.
The smallest set of addresses that will cover all possible combinations is the set of power-of-two addresses. These addresses are analogous to the set of data values used in the walking 1’s test. The corresponding memory locations are 0x00000001, 0x00000002, 0x00000004, 0x00000008, 0x00000010, 0x00000020, and so forth. In addition, address 0x00000000 must be tested. The possibility of overlapping locations makes the address bus test harder to implement. After writing to one of the addresses, you must check that none of the others has been overwritten.
It is important to note that in some cases not all of the address signals can be tested in this way. Part of the address—the most significant bits on the left end—selects the memory chip itself. Another part—one or two least significant bits on the right—might not be relevant if the data bus is wider than 8 bits. These extra bits should remain constant throughout your address bus test and will thus reduce the number of test addresses. For example, if the processor has 20 address bits, it can address up to 1 MB of memory. If you want to test a 128 KB block of memory—that is, 1/8 of the total one-megabyte address space—the 3 most significant address bits will remain constant. In that case, only the 17 least significant bits of the address bus can actually be tested.
To confirm that no two memory locations overlap, you should first write some initial data value at each power-of-two offset within the device. Then write a new value—an inverted copy of the initial value is a good choice—to the first test offset, and verify that the initial data value is still stored at every other power-of-two offset. If you find a location (other than the one you just wrote) that contains the new data value, you have found a problem with the current address bit. If no overlapping is found, repeat the procedure for each of the remaining offsets.
The function memtestAddressBus shows how this can be
done in practice. The function accepts three parameters. The first
parameter is the base address of the memory block to be tested, the
second is its size (in bytes), and the third is used to return the
address of the failure, if one occurs. The size is used to determine
which address bits should be tested. For best results, the base
address should contain a 0 in each of those bits. If the address bus
test fails, 0 is returned and the address at which the first error
was detected is returned in the parameter ppFailAddr. Otherwise, the function
returns 1 to indicate success and sets ppFailAddr to NULL.
/**********************************************************************
* Function: memtestAddressBus
*
* Description: Test the address bus wiring in a memory region by
* performing a walking 1's test on the relevant bits
* of the address and checking for aliasing. The test
* will find single-bit address failures such as stuck
* high, stuck low, and shorted pins. The base address
* and size of the region are selected by the caller.
*
* Notes: For best results, the selected base address should
* have enough LSB 0's to guarantee single address bit
* changes. For example, to test a 64 KB region, select
* a base address on a 64 KB boundary. Also, the number
* of bytes must describe a power-of-two region size.
*
* Returns: 0 if the test fails. The failure address is returned
* in the parameter ppFailAddr.
* 1 if the test succeeds. The parameter ppFailAddr is
* set to NULL.
*
**********************************************************************/
int memtestAddressBus(datum *pBaseAddress, uint32_t numBytes, datum **ppFailAddr)
{
uint32_t addressMask = (numBytes - 1);
uint32_t offset;
uint32_t testOffset;
datum pattern = (datum) 0xAAAAAAAA;
datum antipattern = (datum) ~pattern;
*ppFailAddr = NULL;
/* Write the default pattern at each of the power-of-two offsets. */
for (offset = sizeof(datum); (offset & addressMask) != 0; offset <<= 1)
pBaseAddress[offset] = pattern;
/* Check for address bits stuck high. */
pBaseAddress[0] = antipattern;
for (offset = sizeof(datum); offset & addressMask; offset <<= 1)
{
if (pBaseAddress[offset] != pattern)
{
*ppFailAddr = &pBaseAddress[offset];
return 0;
}
}
pBaseAddress[0] = pattern;
/* Check for address bits stuck low or shorted. */
for (testOffset = sizeof(datum); testOffset & addressMask; testOffset <<= 1)
{
pBaseAddress[testOffset] = antipattern;
for (offset = sizeof(datum); offset & addressMask; offset <<= 1)
{
if ((pBaseAddress[offset] != pattern) && (offset != testOffset))
{
*ppFailAddr = &pBaseAddress[offset];
return 0;
}
}
pBaseAddress[testOffset] = pattern;
}
return 1;
}
Device test
Once you know that the address and data bus wiring are correct, it is necessary to test the integrity of the memory device itself. The goal is to test that every bit in the device is capable of holding both 0 and 1. This test is fairly straightforward to implement, but it takes significantly longer to execute than the previous two tests.
For a complete device test, you must write and verify every memory location twice. You are free to choose any data value for the first pass, as long as you invert that value during the second. And because there is a possibility of missing memory chips, it is best to select a set of data that changes with (but is not equivalent to) the address. A simple example is an increment test.
The data values for the increment test are shown in the first two columns of Table 6-3. The third column shows the inverted data values used during the second pass of this test. The second pass represents a decrement test. There are many other possible choices of data, but the incrementing data pattern is adequate and easy to compute.
| Memory offset | Binary value | Inverted value |
| 0x00 | 00000001 | 11111110 |
| 0x01 | 00000010 | 11111101 |
| 0x02 | 00000011 | 11111100 |
| 0x03 | 00000100 | 11111011 |
| ... | ... | ... |
| 0xFE | 11111111 | 00000000 |
| 0xFF | 00000000 | 11111111 |
The function memtestDevice
implements just such a two-pass increment/decrement
test. It accepts three parameters from the caller. The first
parameter is the starting address, the second is the number of bytes
to be tested, and the third is used to return the address of the
failure, if one occurs. The first two parameters give the user
maximum control over which areas of memory are overwritten. The
function returns 1 on success, and the parameter ppFailAddr is set to NULL. Otherwise, 0 is returned and the
first address that contains an incorrect data value is returned in
the parameter ppFailAddr.
/**********************************************************************
*
* Function: memtestDevice
*
* Description: Test the integrity of a physical memory device by
* performing an increment/decrement test over the
* entire region. In the process, every storage bit
* in the device is tested as a zero and a one. The
* base address and the size of the region are
* selected by the caller.
*
* Notes:
*
* Returns: 0 if the test fails. The failure address is returned
* in the parameter ppFailAddr.
* 1 if the test succeeds. The parameter ppFailAddr is
* set to NULL.
*
**********************************************************************/
int memtestDevice(datum *pBaseAddress, uint32_t numBytes, datum **ppFailAddr)
{
uint32_t offset;
uint32_t numWords = numBytes / sizeof(datum);
datum pattern;
*ppFailAddr = NULL;
/* Fill memory with a known pattern. */
for (pattern = 1, offset = 0; offset < numWords; pattern++, offset++)
pBaseAddress[offset] = pattern;
/* Check each location and invert it for the second pass. */
for (pattern = 1, offset = 0; offset < numWords; pattern++, offset++)
{
if (pBaseAddress[offset] != pattern)
{
*ppFailAddr = &pBaseAddress[offset];
return 0;
}
pBaseAddress[offset] = ~pattern;
}
/* Check each location for the inverted pattern and zero it. */
for (pattern = 1, offset = 0; offset < numWords; pattern++, offset++)
{
if (pBaseAddress[offset] != ~pattern)
{
*ppFailAddr = &pBaseAddress[offset];
return 0;
}
pBaseAddress[offset] = 0;
}
return 1;
}Putting it all together
To make our discussion more concrete, let’s consider a practical example. Suppose that we want to test a 64 KB chunk of the DRAM starting at address 0x00500000 on the Arcom board. To do this, we would call each of the three test routines in turn. In each case, the first parameter is the base address of the memory block. The width of the data bus is 32 bits, and there are a total of 64 KB to be tested (corresponding to the right most 16 bits of the address bus).
If any of the memory test routines returns a zero, we’ll immediately turn on the red LED to visually indicate the error. Otherwise, after all three tests have completed successfully, we will turn on the green LED. New LED functions have been added, which allow the LEDs to be turned on or off.
In the event of an error, the test routine that failed will
return some information about the problem encountered in the
parameter pFailAddr. This
information can be useful when communicating with a hardware
engineer about the nature of the problem. However, the information
returned by the function is visible only if we are running the test
program in a debugger or emulator. Later we will look at a serial
driver that will allow input from and output to a serial port on the
board. This can be an invaluable tool for getting debug output from
a program.
The best way to proceed is to assume the best, download the test program, and let it run to completion. Then, if and only if the red LED comes on, you must examine the return codes and contents of the memory to see which test failed and why.
Following is the program’s main function, which performs a few LED
initializations and then executes the previously defined memory test
functions:
#include "memtest.h"
#include "led.h"
#define BASE_ADDRESS (datum *)(0x00500000)
#define NUM_BYTES (0x10000)
/**********************************************************************
*
* Function: main
*
* Description: Test a 64 KB block of DRAM.
*
* Notes:
*
* Returns: 0 on failure.
* 1 on success.
*
**********************************************************************/
int main(void)
{
datum *pFailAddr;
/* Configure the LED control pins. */
ledInit();
/* Make sure all LEDs are off before we start the memory test. */
ledOff(LED_GREEN | LED_YELLOW | LED_RED);
if ((memtestDataBus(BASE_ADDRESS, &pFailAddr) != 1) ||
(memtestAddressBus(BASE_ADDRESS, NUM_BYTES, &pFailAddr) != 1) ||
(memtestDevice(BASE_ADDRESS, NUM_BYTES, &pFailAddr) != 1))
{
ledOn(LED_RED);
return 0;
}
else
{
ledOn(LED_GREEN);
return 1;
}
}Unfortunately, it is not always possible to write memory tests in a high-level language. For example, C requires the use of a stack. But a stack itself requires working memory. This might be reasonable in a system that has more than one memory device. For example, you might create a stack in an area of RAM that is already known to be working, while testing another memory device. In a common situation, a small SRAM could be tested from assembly and the stack could be created in this SRAM afterward. Then a larger block of DRAM could be tested using a test algorithm implemented in a high-level language, such as the one just shown. If you cannot assume enough working RAM for the stack and data needs of the test program, you will need to rewrite these memory test routines entirely in assembly language.
Tip
It might be possible to use the processor cache for the stack. Or if the processor uses a link register, and variables are kept in registers, it may still be possible to write tests in C without needing a stack.
Another option is to run the memory test program from an in-circuit emulator. In this case, you could choose to place the stack in an area of the emulator’s own internal memory. By moving the emulator’s internal memory around in the target memory map, you could systematically test each memory device on the target.
Warning
Running an emulator before you are assured that your hardware is working entails risk. If there is a physical (electrical/bus) fault in your system, the fault could destroy your expensive ICE.
You also need to be careful that the processor’s cache does not fool you into thinking that the memory tests falsely succeeded. For example, imagine that the processor stores the data that you intended to write out to a particular memory location in its cache. When you read that memory location back, the processor provides the cached value. In this case, you get a valid result regardless of whether there is an actual memory error. It is best to run the memory tests with the cache (at least the data cache) disabled.
The need for memory testing is perhaps most apparent during product development, when the reliability of the hardware and its design are still unproved. However, memory is one of the most critical resources in any embedded system, so it might also be desirable to include a memory test in the final release of your software. In that case, the memory test and other hardware confidence tests should be run each time the system is powered on or reset. Together, this initial test suite forms a set of hardware diagnostics. If one or more of the diagnostics fail, a repair technician can be called in to diagnose the problem and repair or replace the faulty hardware.
Validating Memory Contents
It does not usually make sense to perform the type of memory testing described earlier when dealing with ROM or hybrid memory devices. ROM devices cannot be written at all, and hybrid devices usually contain data or programs that you can’t overwrite because you’d lose the information. However, it should be clear that the same sorts of memory problems can occur with these devices. A chip might be missing, improperly inserted, or physically or electrically damaged, or there could be an electrical wiring problem. Rather than just assuming that these nonvolatile memory devices are functioning properly, you would be better off having some way to confirm that the device is working and that the data it contains is valid. That’s where checksums and cyclic redundancy checks come in.
Checksums
How can we tell whether the data or program stored in a nonvolatile memory device is still valid? One of the easiest ways is to compute a checksum of the data when it is known to be valid—prior to programming the ROM, for example. Then, each time you want to confirm the validity of the data, you need only recalculate the checksum and compare the result to the previously computed value. If the two checksums match, the data is assumed to be valid. By carefully selecting the checksum algorithm, we can increase the probability that specific types of errors will be detected, while keeping the size of the checksum, and the time required to check it, down to a reasonable size.
The simplest checksum algorithm is to add up all the data bytes (or—if you prefer a 16-bit checksum—words), discarding carries along the way. A noteworthy weakness of this algorithm is that if all of the data (including the stored checksum) is accidentally overwritten with 0s, this data corruption will be undetectable; the sum of a large block of zeros is also zero. The simplest way to overcome this weakness is to add a final step to the checksum algorithm: invert the result. That way, if the data and checksum are somehow overwritten with 0s, the test will fail because the proper checksum would be 0xFF.
Unfortunately, a simple sum-of-data checksum such as this one fails to detect many of the most common data errors. Clearly, if one bit of data is corrupted (switched from 1 to 0, or vice versa), the error would be detected. But what if two bits from the very same “column” happened to be corrupted alternately (the first switches from 1 to 0, the other from 0 to 1)? The proper checksum does not change, and the error would not be detected. If bit errors can occur, you will probably want to use a better checksum algorithm. We’ll see one of these in the next section.
After computing the expected checksum, you’ll need a place to store it. One option is to compute the checksum ahead of time and define it as a constant in the routine that verifies the data. This method is attractive to the programmer but has several shortcomings. It is possible that the data—and, as a result, the expected checksum—might change during the lifetime of the product. This is particularly likely if the data being tested is embedded software that will be periodically updated as bugs are fixed or new features added.
A better idea is to store the checksum at some fixed location in nonvolatile memory. For example, you might decide to use the very last location of the memory device being verified. This makes insertion of the checksum easy: just compute the checksum and insert it into the memory image prior to programming the memory device. When you recalculate the checksum, simply skip over the location that contains the expected result and compare the runtime checksum to the value stored there. Another good place to store the checksum is in another nonvolatile memory device. Both of these solutions work very well in practice.
Cyclic Redundancy Checks
A cyclic redundancy check (CRC) is a specific checksum algorithm that is designed to detect the most common data errors. The theory behind the CRC is quite mathematical and beyond the scope of this book. However, cyclic redundancy codes are frequently useful in embedded applications that require the storage or transmission of large blocks of data. What follows is a brief explanation of the CRC technique and some source code that shows how it can be implemented in C. Thankfully, you don’t need to understand why CRCs detect data errors—or even how they are implemented—to take advantage of their ability to detect errors.
Here’s a very brief explanation of the mathematics. When computing a CRC, think of the set of data as a very long string of 1s and 0s (called the message). This binary string is divided—in a rather peculiar way—by a smaller fixed binary string called the generator polynomial. The remainder of this binary long division is the CRC checksum. By carefully selecting the generator polynomial for certain desirable mathematical properties, you can use the resulting checksum to detect most (but never all) errors within the message. The strongest of these generator polynomials are able to detect all single- and double-bit errors, and all odd-length strings of consecutive error bits. In addition, greater than 99.99 percent of all burst errors—defined as a sequence of bits that has one error at each end—can be detected. Together, these types of errors account for a large percentage of the possible errors within any stored or transmitted binary message.
Generator polynomials with the best error-detection capabilities are frequently adopted as international standards. Two such standards are described in Table 6-4. Associated with each standard are its width (in bits), the generator polynomial, a binary representation of the polynomial (called the divisor), an initial value for the remainder, and a value to exclusive OR operation (XOR) with the final remainder. [1]
| Parameters | CRC16 | CRC32 |
| Checksum size (width) | 16 bits | 32 bits |
| Generator polynomial | x16 + x15 + x2 + 1 | x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x1 + 1 |
| Divisor (polynomial) | 0x8005 | 0x04C11DB7 |
| Initial remainder | 0x0000 | 0xFFFFFFFF |
| Final XOR value | 0x0000 | 0xFFFFFFFF |
The following code can be used to compute any CRC formula that
has a similar set of parameters. To make this as easy as possible, we
have defined all of the CRC parameters as constants. To select the CRC
parameters according to the desired standard, define one (and only
one) of the macros CRC16 or
CRC32.
/* The CRC parameters. Currently configured for CRC16. */
#define CRC_NAME "CRC16"
#define POLYNOMIAL 0x8005
#define INITIAL_REMAINDER 0x0000
#define FINAL_XOR_VALUE 0x0000
#define REFLECT_DATA TRUE
#define REFLECT_REMAINDER TRUE
#define CHECK_VALUE 0xBB3D
/* The width of the CRC calculation and result. */
typedef uint16_t crc_t;
#define WIDTH (8 * sizeof(crc_t))
#define TOPBIT (1 << (WIDTH - 1))The function crcCompute can
be called over and over from your application to compute and verify
CRC checksums.
/*********************************************************************
*
* Function: crcCompute
*
* Description: Compute the CRC of a given message.
*
* Notes:
*
* Returns: The CRC of the message.
*
*********************************************************************/
crc_t crcCompute(uint8_t const message[], uint32_t numBytes)
{
crc_t remainder = INITIAL_REMAINDER;
uint32_t byte;
int nBit;
/* Perform modulo-2 division, a byte at a time. */
for (byte = 0; byte < numBytes; byte++)
{
/* Bring the next byte into the remainder. */
remainder ^= (REFLECT_DATA(message[byte]) << (WIDTH - 8));
/* Perform modulo-2 division, a bit at a time. */
for (nBit = 8; nBit > 0; nBit--)
{
/* Try to divide the current data bit. */
if (remainder & TOPBIT)
remainder = (remainder << 1) ^ POLYNOMIAL;
else
remainder = (remainder << 1);
}
}
/* The final remainder is the CRC result. */
return (REFLECT_REMAINDER(remainder) ^ FINAL_XOR_VALUE);
}A function named crcFast that
uses a lookup table to compute a CRC more efficiently is included on
this book’s web site (http://www.oreilly.com/catalog/9780596009830).
Precomputing the remainders for all 256 possible bytes of data in
advance (crcInit) substantially
reduces the amount of processing done for each bit. These intermediate
results are stored in a lookup table. By doing it this way, the CRC of
a large message can be computed a byte at a time rather than bit by
bit. This reduces the CRC calculation time significantly.
An additional benefit of splitting the computation between
crcInit and crcFast is that the crcInit function need not be executed on the
embedded system. In practice, the crcInit function could either be called
during the target’s initialization sequence (thus placing the CRC
table in RAM), or it could be run ahead of time on your development
computer with the results stored in the target device’s ROM. The
values in the table are then referenced over and over by crcFast.
Using Flash Memory
Flash memory offers advantages over other types of memory. Systems with flash memory can be updated in the field to incorporate new features or bug fixes discovered after the product has been shipped. This can eliminate the need to ship the unit back to the manufacturer for software upgrades. There are several issues that need to be considered when upgrading software for units in the field.
- Limit downtime
The timing of the upgrade should take place during downtime. Since the unit will probably not be able to function at its full capacity during the upgrade, you need to make sure that the unit is not performing a critical task. The customer will have to dictate the most convenient time.
- Power failure
How will the unit recover should power be removed (intentionally or otherwise) while the upgrade is taking place? If only a few bytes of the application image have been programmed into flash when the power is removed, you need a way to determine that an error occurred and prevent that code from executing. A solution may be to include a loader (similar to a debug monitor) that cannot be erased because it resides in protected flash sectors. One of the boot tasks for the loader is to check the flash memory for a valid application image (i.e., for a valid checksum). If a valid image is not present, the loader needs to know how to get a valid image onto the board, via serial port, network, or some other means.
Another solution for power failures may be to include a flash memory device that is large enough to store two application images: the current image and the old image. When new firmware is available, the old image is overwritten with the new software; the current image is left alone. Only after the image has been programmed properly and verified does it become the current image. This technique ensures that the unit always has a valid application image to execute should something bad happen during the upgrade procedure.
- Upgrade code execution
From which memory chip will the software execute during the erase and programming of the new software? The software that downloads the image may be able to run from flash memory; however, the code to erase and reprogram a flash chip might need to be run from another memory device.
- Device timing requirements
It is important to understand the timing requirements of the program and erase cycles for the particular flash device. It is best to make sure all data is present (and validated) before starting the programming cycle. You wouldn’t want to start the programming the device and then be caught waiting for the rest of the new software to come in over a network connection. The device may have timing limits for program and erase cycles that cause the device to revert back to read mode if these limits are exceeded. The flash device driver would fail to write the data if this occurs.
- Software image validity
It is important to validate the image that is written into the flash. This will ensure that the software is received into the unit correctly. The CRC algorithm presented earlier in this chapter may be sufficient to satisfy the validity of the upgrade software.
- Security
If security of the image is an issue, you may need to find an algorithm to digitally sign and/or encrypt the new software. The validation and decryption of the software would then be performed prior to programming the new software into the flash memory.
Working with Flash Memory
From the programmer’s viewpoint, flash is arguably the most complicated memory device ever invented. The hardware interface has improved somewhat since the original devices were introduced in 1988, but there is still a long way to go. Reading from flash memory is fast and easy, as it should be. In fact, reading data from a flash is not all that different from reading from any other memory device. The processor simply provides the address, and the memory device returns the data stored at that location. Most flash devices enter this type of “read” mode automatically whenever the system is reset; no special initialization sequence is required to enable reading.
Writing data to a flash is not as straightforward. Two factors make writes difficult. Firstly, each memory location must be erased before it can be rewritten. If the old data is not erased, the result of the write operation will be a mathematical combination of the old and new values.
The second thing that makes writes to a flash difficult is that at least one sector, or block, of the device must be erased; it is impossible to erase a single byte. The size of an individual sector varies from device to device, but each sector is usually on the order of several kilobytes. In addition, within the same device, different sector sizes may be used.
One other small difference is worth noting: the erase and write cycles take longer than the read cycle.
Flash Drivers
The process of erasing the old data and writing the new varies from one manufacturer to another and is usually rather complicated. These device programming interfaces are so awkward that it is usually best to add a layer of software to make the flash memory easier to use. If implemented, this hardware-specific layer of software is usually called the flash driver.
The purpose of a device driver in general is to hide the details of a specific device from the application software. In this case, the flash driver contains the specific method for writing to and erasing a specific flash device. The flash driver should present a simple application programming interface (API) consisting of the erase and write operations. Parts of the application software that need to modify data stored in flash memory simply call the driver and let it handle the details. This allows the application programmer to make high-level requests such as “Erase the block at address 0xD0000000” or “Write a block of data, beginning at address 0xD4000000.” Distinct driver routines also keep the device-specific code separate, so it can be easily modified if another manufacturer’s flash device is later used.
Flash device manufacturers typically include device drivers on their web sites. If you’re looking for some example code, these web sites are a great place to start. Some of the example code may cover the very basic operations. In particular, these implementations may not handle any of the chip’s possible errors. What if the erase operation never completes? You’ll want to think through the problems that might arise when deploying your routines, and add error checking if necessary. More robust implementations may use a software time-out as a backup. For example, if the flash device doesn’t respond within twice the maximum expected time (as stated in the device’s datasheet), the routine could stop polling and indicate the error to the caller (or user) in some way.
Another feature enhancement is to include code for retries. If an erase or program cycle fails, the code could automatically retry the operation before returning a failure to the calling application.
Another thing that people sometimes do with flash memory is
implement a small filesystem (similar to the FIS portion of RedBoot).
Because the flash memory provides nonvolatile storage that is also
rewriteable, it can be thought of as similar to any other secondary
storage system, such as a hard drive. However, you must keep in mind
the write cycle limitation of flash as well. In the filesystem case,
the functions provided by the driver would be more file-oriented.
Standard filesystem functions such as open, close, read, and write provide a good starting point for the
driver’s API. The underlying filesystem structure can be as simple or
complex as your system requires. However, a well-understood format
such as the File Allocation Table (FAT) structure, used by DOS, is
good enough for most embedded projects.
[1] The divisor is simply a binary representation of the coefficients of the generator polynomial, each of which is either 0 or 1. To make this even more confusing, the highest-order coefficient of the generator polynomial (always a 1) is left out of the binary representation. For example, the polynomial in CRC16 has four nonzero coefficients. But the corresponding binary representation has only three 1s in it (bits 15, 2, and 0).