
Chapter 12. XML
XML, the Extensible Markup Language, is a standardized data format. It looks a little like HTML, with tags (<example>like this</example>) and entities (&). Unlike HTML, however, XML is designed to be easy to programmatically parse, and there are rules for what you can and cannot do in an XML document. XML is now the standard data format in fields as diverse as publishing, engineering, and medicine. It’s used for remote procedure calls, databases, purchase orders, and much more.
There are many scenarios where you might want to use XML. Because it is a common format for data transfer, other programs can emit XML files for you to either extract information from (parse) or display in HTML (transform). This chapter shows you how to use the XML parser bundled with PHP, as well as how to use the optional XSLT extension to transform XML. We also briefly cover generating XML.
Recently, XML has been used in remote procedure calls (XML-RPC). A client encodes a function name and parameter values in XML and sends them via HTTP to a server. The server decodes the function name and values, decides what to do, and returns a response value encoded in XML. XML-RPC has proved a useful way to integrate application components written in different languages. We’ll show you how to write XML-RPC servers and clients in Chapter 16, but for now let’s look at the basics of XML.
Lightning Guide to XML
Most XML consists of elements (like HTML tags), entities, and regular data. For example:
<book isbn="1-56592-610-2"> <title>Programming PHP</title> <authors> <author>Rasmus Lerdorf</author> <author>Kevin Tatroe</author> <author>Peter MacIntyre</author> </authors> </book>
In HTML, you often have an open tag without a close tag. The most common example of this is:
<br>
In XML, that is illegal. XML requires that every open tag be closed. For tags that don’t enclose anything, such as the line break <br>, XML adds this syntax:
<br />
Tags can be nested but cannot overlap. For example, this is valid:
<book><title>Programming PHP</title></book>
This, however, is not valid, because the <book> and <title> tags overlap:
<book><title>Programming PHP</book></title>
XML also requires that the document begin with a processing instruction that identifies the version of XML being used (and possibly other things, such as the text encoding used). For example:
<?xml version="1.0" ?>
The final requirement of a well-formed XML document is that there be only one element at the top level of the file. For example, this is well formed:
<?xml version="1.0" ?> <library> <title>Programming PHP</title> <title>Programming Perl</title> <title>Programming C#</title> </library>
This is not well formed, as there are three elements at the top level of the file:
<?xml version="1.0" ?> <title>Programming PHP</title> <title>Programming Perl</title> <title>Programming C#</title>
XML documents generally are not completely ad hoc. The specific tags, attributes, and entities in an XML document, and the rules governing how they nest, compose the structure of the document. There are two ways to write down this structure: the document type definition (DTD) and the schema. DTDs and schemas are used to validate documents—that is, to ensure that they follow the rules for their type of document.
Most XML documents don’t include a DTD; in these cases, the document is considered valid merely if it’s valid XML. Others identify the DTD as an external entity with a line that gives the name and location (file or URL) of the DTD:
<!DOCTYPE rss PUBLIC 'My DTD Identifier' 'http://www.example.com/my.dtd'>
Sometimes it’s convenient to encapsulate one XML document in another. For example, an XML document representing a mail message might have an attachment element that surrounds an attached file. If the attached file is XML, it’s a nested XML document. What if the mail message document has a body element (the subject of the message), and the attached file is an XML representation of a dissection that also has a body element, but this element has completely different DTD rules? How can you possibly validate or make sense of the document if the meaning of body changes partway through?
This problem is solved with the use of namespaces. Namespaces let you qualify the XML tag—for example, email:body and human:body.
There’s a lot more to XML than we have time to go into here. For a gentle introduction to XML, read Learning XML (http://oreil.ly/Learning_XML) by Erik Ray (O’Reilly). For a complete reference to XML syntax and standards, see XML in a Nutshell (http://oreil.ly/XML_Nutshell) by Elliotte Rusty Harold and W. Scott Means (O’Reilly).
Generating XML
Just as PHP can be used to generate dynamic HTML, it can also be used to generate dynamic XML. You can generate XML for other programs to make use of based on forms, database queries, or anything else you can do in PHP. One application for dynamic XML is Rich Site Summary (RSS), a file format for syndicating news sites. You can read an article’s information from a database or from HTML files and emit an XML summary file based on that information.
Generating an XML document from a PHP script is simple. Simply change the MIME type of the document, using the header() function, to "text/xml". To emit the <?xml ... ?> declaration without it being interpreted as a malformed PHP tag, simply echo the line from within PHP code:
echo '<?xml version="1.0" encoding="ISO-8859-1" ?>';
Example 12-1 generates an RSS document using PHP. An RSS file is an XML document containing several channel elements, each of which contains some news item elements. Each news item can have a title, a description, and a link to the article itself. More properties of an item are supported by RSS than Example 12-1 creates. Just as there are no special functions for generating HTML from PHP, there are no special functions for generating XML. You just echo it!
Example 12-1. Generating an XML document
<?php
header('Content-Type: text/xml');
echo "<?xml version="1.0" encoding="ISO-8859-1" ?>";
?>
<!DOCTYPE rss PUBLIC "-//Netscape Communications//DTD RSS 0.91//EN"
"http://my.netscape.com/publish/formats/rss-0.91.dtd">
<rss version="0.91">
<channel>
<?php
// news items to produce RSS for
$items = array(
array(
'title' => "Man Bites Dog",
'link' => "http://www.example.com/dog.php",
'desc' => "Ironic turnaround!"
),
array(
'title' => "Medical Breakthrough!",
'link' => "http://www.example.com/doc.php",
'desc' => "Doctors announced a cure for me."
)
);
foreach($items as $item) {
echo "<item>
";
echo " <title>{$item['title']}</title>
";
echo " <link>{$item['link']}</link>
";
echo " <description>{$item['desc']}</description>
";
echo " <language>en-us</language>
";
echo "</item>
";
} ?>
</channel>
</rss>
This script generates output such as the following:
<?xml version="1.0" encoding="ISO-8859-1" ?> <!DOCTYPE rss PUBLIC "-//Netscape Communications//DTD RSS 0.91//EN" "http://my.netscape.com/publish/formats/rss-0.91.dtd"> <rss version="0.91"> <channel> <item> <title>Man Bites Dog</title> <link>http://www.example.com/dog.php</link> <description>Ironic turnaround!</description> <language>en-us</language> </item> <item> <title>Medical Breakthrough!</title> <link>http://www.example.com/doc.php</link> <description>Doctors announced a cure for me.</description> <language>en-us</language> </item> </channel> </rss>
Parsing XML
Say you have a set of XML files, each containing information about a book, and you want to build an index showing the document title and its author for the collection. You need to parse the XML files to recognize the title and author elements and their contents. You could do this by hand with regular expressions and string functions such as strtok(), but it’s a lot more complex than it seems. In addition, such methods are prone to breakage even with valid XML documents. The easiest and quickest solution is to use one of the XML parsers that ship with PHP.
PHP includes three XML parsers: one event-driven library based on the expat C library, one DOM-based library, and one for parsing simple XML documents named, appropriately, SimpleXML.
The most commonly used parser is the event-based library, which lets you parse but not validate XML documents. This means you can find out which XML tags are present and what they surround, but you can’t find out if they’re the right XML tags in the right structure for this type of document. In practice, this isn’t generally a big problem.
PHP’s event-based XML parser calls various handler functions you provide while it reads the document as it encounters certain “events,” such as the beginning or end of an element.
In the following sections, we discuss the handlers you can provide, the functions to set the handlers, and the events that trigger the calls to those handlers. We also provide sample functions for creating a parser to generate a map of the XML document in memory, tied together in a sample application that pretty-prints XML.
Element Handlers
When the parser encounters the beginning or end of an element, it calls the start and end element handlers. You set the handlers through the xml_set_element_handler() function:
xml_set_element_handler(parser, start_element, end_element);
The start_element and end_element parameters are the names of the handler functions.
The start element handler is called when the XML parser encounters the beginning of an element:
startElementHandler(parser, element, &attributes);
The start element handler is passed three parameters: a reference to the XML parser calling the handler, the name of the element that was opened, and an array containing any attributes the parser encountered for the element. The $attribute array is passed by reference for speed.
Example 12-2 contains the code for a start element handler, startElement(). This handler simply prints the element name in bold and the attributes in gray.
Example 12-2. Start element handler
function startElement($parser, $name, $attributes) {
$outputAttributes = array();
if (count($attributes)) {
foreach($attributes as $key => $value) {
$outputAttributes[] = "<font color="gray">{$key}="{$value}"</font>";
}
}
echo "<<b>{$name}</b> " . join(' ', $outputAttributes) . '>';
}
The end element handler is called when the parser encounters the end of an element:
endElementHandler(parser, element);
It takes two parameters: a reference to the XML parser calling the handler, and the name of the element that is closing.
Example 12-3 shows an end element handler that formats the element.
Example 12-3. End element handler
function endElement($parser, $name) {
echo "<<b>/{$name}</b>>";
}
Character Data Handler
All of the text between elements (character data, or CDATA in XML terminology) is handled by the character data handler. The handler you set with the xml_set_character_data_handler() function is called after each block of character data:
xml_set_character_data_handler(parser, handler);
The character data handler takes in a reference to the XML parser that triggered the handler and a string containing the character data itself:
characterDataHandler(parser, cdata);
Here’s a simple character data handler that simply prints the data:
function characterData($parser, $data) {
echo $data;
}
Processing Instructions
Processing instructions are used in XML to embed scripts or other code into a document. PHP itself can be seen as a processing instruction and, with the <?php ... ?> tag style, follows the XML format for demarking the code. The XML parser calls the processing instruction handler when it encounters a processing instruction. Set the handler with the xml_set_processing_instruction_handler() function:
xml_set_processing_instruction_handler(parser, handler);
A processing instruction looks like:
<? target instructions ?>
The processing instruction handler takes in a reference to the XML parser that triggered the handler, the name of the target (for example, 'php'), and the processing instructions:
processingInstructionHandler(parser, target, instructions);
What you do with a processing instruction is up to you. One trick is to embed PHP code in an XML document and, as you parse that document, execute the PHP code with the eval() function. Example 12-4 does just that. Of course, you have to trust the documents you’re processing if you include the eval() code in them. eval() will run any code given to it—even code that destroys files or mails passwords to a cracker. In practice, executing arbitrary code like this is extremely dangerous.
Example 12-4. Processing instruction handler
function processing_instruction($parser, $target, $code) {
if ($target === 'php') {
eval($code);
}
}
Entity Handlers
Entities in XML are placeholders. XML provides five standard entities (&, >, <, ", and '), but XML documents can define their own entities. Most entity definitions do not trigger events, and the XML parser expands most entities in documents before calling the other handlers.
Two types of entities, external and unparsed, have special support in PHP’s XML library. An external entity is one whose replacement text is identified by a filename or URL rather than explicitly given in the XML file. You can define a handler to be called for occurrences of external entities in character data, but it’s up to you to parse the contents of the file or URL yourself if that’s what you want.
An unparsed entity must be accompanied by a notation declaration, and while you can define handlers for declarations of unparsed entities and notations, occurrences of unparsed entities are deleted from the text before the character data handler is called.
External entities
External entity references allow XML documents to include other XML documents. Typically, an external entity reference handler opens the referenced file, parses the file, and includes the results in the current document. Set the handler with xml_set_external_entity_ref_handler(), which takes in a reference to the XML parser and the name of the handler function:
xml_set_external_entity_ref_handler(parser, handler);
The external entity reference handler takes five parameters: the parser triggering the handler, the entity’s name, the base URI for resolving the identifier of the entity (which is currently always empty), the system identifier (such as the filename), and the public identifier for the entity, as defined in the entity’s declaration. For example:
externalEntityHandler(parser, entity, base, system, public);
If your external entity reference handler returns false (which it will if it returns no value), XML parsing stops with an XML_ERROR_EXTERNAL_ENTITY_HANDLING error. If it returns true, parsing continues.
Example 12-5 shows how you would parse externally referenced XML documents. Define two functions, createParser() and parse(), to do the actual work of creating and feeding the XML parser. You can use them both to parse the top-level document and any documents included via external references. Such functions are described in the section “Using the Parser”. The external entity reference handler simply identifies the right file to send to those functions.
Example 12-5. External entity reference handler
function externalEntityReference($parser, $names, $base, $systemID, $publicID) {
if ($systemID) {
if (!list ($parser, $fp) = createParser($systemID)) {
echo "Error opening external entity {$systemID}
";
return false;
}
return parse($parser, $fp);
}
return false;
}
Unparsed entities
An unparsed entity declaration must be accompanied by a notation declaration:
<!DOCTYPE doc [ <!NOTATION jpeg SYSTEM "image/jpeg"> <!ENTITY logo SYSTEM "php-tiny.jpg" NDATA jpeg> ]>
Register a notation declaration handler with xml_set_notation_decl_handler():
xml_set_notation_decl_handler(parser, handler);
The handler will be called with five parameters:
notationHandler(parser, notation, base, system, public);
The base parameter is the base URI for resolving the identifier of the notation (which is currently always empty). Either the system identifier or the public identifier for the notation will be set, but not both.
Register an unparsed entity declaration with the xml_set_unparsed_entity_decl_handler() function:
xml_set_unparsed_entity_decl_handler(parser, handler);
The handler will be called with six parameters:
unparsedEntityHandler(parser, entity, base, system, public, notation);
The notation parameter identifies the notation declaration with which this unparsed entity is associated.
Default Handler
For any other event, such as the XML declaration and the XML document type, the default handler is called. To set the default handler, call the xml_set_default_handler() function:
xml_set_default_handler(parser, handler);
The handler will be called with two parameters:
defaultHandler(parser, text);
The text parameter will have different values depending on the kind of event triggering the default handler. Example 12-6 just prints out the given string when the default handler is called.
Example 12-6. Default handler
function default($parser, $data) {
echo "<font color="red">XML: Default handler called with '{$data}'</font>
";
}
Options
The XML parser has several options you can set to control the source and target encodings and case folding. Use xml_parser_set_option() to set an option:
xml_parser_set_option(parser, option, value);
Similarly, use xml_parser_get_option() to interrogate a parser about its options:
$value = xml_parser_get_option(parser, option);
Character encoding
The XML parser used by PHP supports Unicode data in a number of different character encodings. Internally, PHP’s strings are always encoded in UTF-8, but documents parsed by the XML parser can be in ISO-8859-1, US-ASCII, or UTF-8. UTF-16 is not supported.
When creating an XML parser, you can give it an encoding format to use for the file to be parsed. If omitted, the source is assumed to be in ISO-8859-1. If a character outside the possible range in the source encoding is encountered, the XML parser will return an error and immediately stop processing the document.
The target encoding for the parser is the encoding in which the XML parser passes data to the handler functions; normally, this is the same as the source encoding. At any time during the XML parser’s lifetime, the target encoding can be changed. The parser demotes any characters outside the target encoding’s character range by replacing them with a question mark character (?).
Use the constant XML_OPTION_TARGET_ENCODING to get or set the encoding of the text passed to callbacks. Allowable values are "ISO-8859-1" (the default), "US-ASCII", and "UTF-8".
Case folding
By default, element and attribute names in XML documents are converted to all uppercase. You can turn off this behavior (and get case-sensitive element names) by setting the XML_OPTION_CASE_FOLDING option to false with the xml_parser_set_option() function:
xml_parser_set_option(XML_OPTION_CASE_FOLDING, false);
Skipping whitespace-only
To ignore values consisting entirely of whitespace characters, set the XML_OPTION_SKIP_WHITE option.
xml_parser_set_option(XML_OPTION_SKIP_WHITE, true);
Truncating tag names
When creating a parser, you can optionally have it truncate characters at the start of each tag name. To truncate the start of each tag by a number of characters, provide that value in the XML_OPTION_SKIP_TAGSTART option:
xml_parser_set_option(XML_OPTION_SKIP_TAGSTART, 4); // <xsl:name> truncates to "name"
In this case, the tag name will be truncated by four characters.
Using the Parser
To use the XML parser, create a parser with xml_parser_create(), set handlers and options on the parser, and then hand chunks of data to the parser with the xml_parse() function until either the data runs out or the parser returns an error. Once the processing is complete, free the parser by calling xml_parser_free().
The xml_parser_create() function returns an XML parser:
$parser = xml_parser_create([encoding]);
The optional encoding parameter specifies the text encoding ("ISO-8859-1", "US-ASCII", or "UTF-8") of the file being parsed.
The xml_parse() function returns true if the parse was successful and false if it was not:
$success = xml_parse(parser, data[, final ]);
The data argument is a string of XML to process. The optional final parameter should be true for the last piece of data to be parsed.
To easily deal with nested documents, write functions that create the parser and set its options and handlers for you. This puts the options and handler settings in one place, rather than duplicating them in the external entity reference handler. Example 12-7 shows such a function.
Example 12-7. Creating a parser
function createParser($filename) {
$fh = fopen($filename, 'r');
$parser = xml_parser_create();
xml_set_element_handler($parser, "startElement", "endElement");
xml_set_character_data_handler($parser, "characterData");
xml_set_processing_instruction_handler($parser, "processingInstruction");
xml_set_default_handler($parser, "default");
return array($parser, $fh);
}
function parse($parser, $fh) {
$blockSize = 4 * 1024; // read in 4 KB chunks
while ($data = fread($fh, $blockSize)) {
if (!xml_parse($parser, $data, feof($fh))) {
// an error occurred; tell the user where
echo 'Parse error: ' . xml_error_string($parser) . " at line " .
xml_get_current_line_number($parser);
return false;
}
}
return true;
}
if (list ($parser, $fh) = createParser("test.xml")) {
parse($parser, $fh);
fclose($fh);
xml_parser_free($parser);
}
Errors
The xml_parse() function returns true if the parse completed successfully, and false if there was an error. If something did go wrong, use xml_get_error_code() to fetch a code identifying the error:
$error = xml_get_error_code($parser);
The error code corresponds to one of these error constants:
XML_ERROR_NONE XML_ERROR_NO_MEMORY XML_ERROR_SYNTAX XML_ERROR_NO_ELEMENTS XML_ERROR_INVALID_TOKEN XML_ERROR_UNCLOSED_TOKEN XML_ERROR_PARTIAL_CHAR XML_ERROR_TAG_MISMATCH XML_ERROR_DUPLICATE_ATTRIBUTE XML_ERROR_JUNK_AFTER_DOC_ELEMENT XML_ERROR_PARAM_ENTITY_REF XML_ERROR_UNDEFINED_ENTITY XML_ERROR_RECURSIVE_ENTITY_REF XML_ERROR_ASYNC_ENTITY XML_ERROR_BAD_CHAR_REF XML_ERROR_BINARY_ENTITY_REF XML_ERROR_ATTRIBUTE_EXTERNAL_ENTITY_REF XML_ERROR_MISPLACED_XML_PI XML_ERROR_UNKNOWN_ENCODING XML_ERROR_INCORRECT_ENCODING XML_ERROR_UNCLOSED_CDATA_SECTION XML_ERROR_EXTERNAL_ENTITY_HANDLING
The constants generally aren’t very useful. Use xml_error_string() to turn an error code into a string that you can use when you report the error:
$message = xml_error_string(code);
For example:
$error = xml_get_error_code($parser);
if ($error != XML_ERROR_NONE) {
die(xml_error_string($error));
}
Methods as Handlers
Because functions and variables are global in PHP, any component of an application that requires several functions and variables is a candidate for object-oriented design. XML parsing typically requires you to keep track of where you are in the parsing (e.g., “just saw an opening title element, so keep track of character data until you see a closing title element”) with variables, and of course you must write several handler functions to manipulate the state and actually do something. Wrapping these functions and variables into a class enables you to keep them separate from the rest of your program and easily reuse the functionality later.
Use the xml_set_object() function to register an object with a parser. After you do so, the XML parser looks for the handlers as methods on that object, rather than as global functions:
xml_set_object(object);
Sample Parsing Application
Let’s develop a program to parse an XML file and display different types of information from it. The XML file given in Example 12-8 contains information on a set of books.
Example 12-8. books.xml file
<?xml version="1.0" ?> <library> <book> <title>Programming PHP</title> <authors> <author>Rasmus Lerdorf</author> <author>Kevin Tatroe</author> <author>Peter MacIntyre</author> </authors> <isbn>1-56592-610-2</isbn> <comment>A great book!</comment> </book> <book> <title>PHP Pocket Reference</title> <authors> <author>Rasmus Lerdorf</author> </authors> <isbn>1-56592-769-9</isbn> <comment>It really does fit in your pocket</comment> </book> <book> <title>Perl Cookbook</title> <authors> <author>Tom Christiansen</author> <author whereabouts="fishing">Nathan Torkington</author> </authors> <isbn>1-56592-243-3</isbn> <comment>Hundreds of useful techniques, most applicable to PHP as well as Perl</comment> </book> </library>
The PHP application parses the file and presents the user with a list of books, showing just the titles and authors. This menu is shown in Figure 12-1. The titles are links to a page showing the complete information for a book. A page of detailed information for Programming PHP is shown in Figure 12-2.
We define a class, BookList, whose constructor parses the XML file and builds a list of records. There are two methods on a BookList that generate output from that list of records. The showMenu() method generates the book menu, and the showBook() method displays detailed information on a particular book.
Parsing the file involves keeping track of the record, which element we’re in, and which elements correspond to records (book) and fields (title, author, isbn, and comment). The $record property holds the current record as it’s being built, and $currentField holds the name of the field we’re currently processing (e.g., title). The $records property is an array of all the records we’ve read so far.
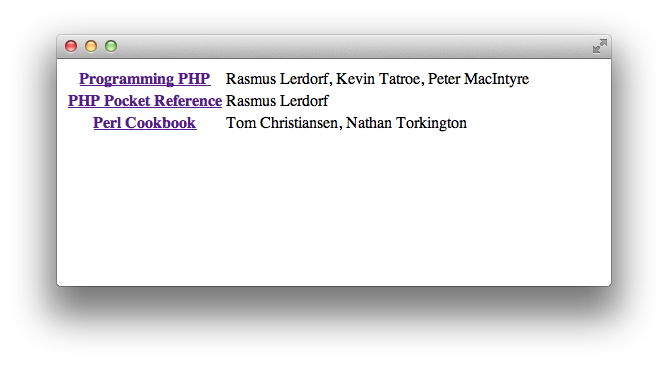
Figure 12-1. Book menu

Figure 12-2. Book details
Two associative arrays, $fieldType and $endsRecord, tell us which elements correspond to fields in a record and which closing element signals the end of a record. Values in $fieldType are either 1 or 2, corresponding to a simple scalar field (e.g., title) or an array of values (e.g., author), respectively. We initialize those arrays in the constructor.
The handlers themselves are fairly straightforward. When we see the start of an element, we work out whether it corresponds to a field we’re interested in. If it is, we set the $currentField property to be that field name so when we see the character data (e.g., the title of the book), we know which field it’s the value for. When we get character data, we add it to the appropriate field of the current record if $currentField says we’re in a field. When we see the end of an element, we check to see if it’s the end of a record; if so, we add the current record to the array of completed records.
One PHP script, given in Example 12-9, handles both the book menu and book details pages. The entries in the book menu link back to the menu URL with a GET parameter identifying the ISBN of the book to display.
Example 12-9. bookparse.php
<html>
<head>
<title>My Library</title>
</head>
<body>
<?php
class BookList {
const FIELD_TYPE_SINGLE = 1;
const FIELD_TYPE_ARRAY = 2;
const FIELD_TYPE_CONTAINER = 3;
var $parser;
var $record;
var $currentField = '';
var $fieldType;
var $endsRecord;
var $records;
function __construct($filename) {
$this->parser = xml_parser_create();
xml_set_object($this->parser, $this);
xml_set_element_handler($this->parser, "elementStarted", "elementEnded");
xml_set_character_data_handler($this->parser, "handleCdata");
$this->fieldType = array(
'title' => self::FIELD_TYPE_SINGLE,
'author' => self::FIELD_TYPE_ARRAY,
'isbn' => self::FIELD_TYPE_SINGLE,
'comment' => self::FIELD_TYPE_SINGLE,
);
$this->endsRecord = array('book' => true);
$xml = join('', file($filename));
xml_parse($this->parser, $xml);
xml_parser_free($this->parser);
}
function elementStarted($parser, $element, &$attributes) {
$element = strtolower($element);
if ($this->fieldType[$element] != 0) {
$this->currentField = $element;
}
else {
$this->currentField = '';
}
}
function elementEnded($parser, $element) {
$element = strtolower($element);
if ($this->endsRecord[$element]) {
$this->records[] = $this->record;
$this->record = array();
}
$this->currentField = '';
}
function handleCdata($parser, $text) {
if ($this->fieldType[$this->currentField] == self::FIELD_TYPE_SINGLE) {
$this->record[$this->currentField] .= $text;
}
else if ($this->fieldType[$this->currentField] == self::FIELD_TYPE_ARRAY) {
$this->record[$this->currentField][] = $text;
}
}
function showMenu() {
echo "<table>
";
foreach ($this->records as $book) {
echo "<tr>";
echo "<th><a href="{$_SERVER['PHP_SELF']}?isbn={$book['isbn']}">";
echo "{$book['title']}</a></th>";
echo "<td>" . join(', ', $book['author']) . "</td>
";
echo "</tr>
";
}
echo "</table>
";
}
function showBook($isbn) {
foreach ($this->records as $book) {
if ($book['isbn'] !== $isbn) {
continue;
}
echo "<p><b>{$book['title']}</b> by " . join(', ', $book['author']) . "<br />";
echo "ISBN: {$book['isbn']}<br />";
echo "Comment: {$book['comment']}</p>
";
}
echo "<p>Back to the <a href="{$_SERVER['PHP_SELF']}">list of books</a>.</p>";
}
}
$library = new BookList("books.xml");
if (isset($_GET['isbn'])) {
// return info on one book
$library->showBook($_GET['isbn']);
}
else {
// show menu of books
$library->showMenu();
} ?>
</body>
</html>
Parsing XML with the DOM
The DOM parser provided in PHP is much simpler to use, but what you take out in complexity comes back in memory usage—in spades. Instead of firing events and allowing you to handle the document as it is being parsed, the DOM parser takes an XML document and returns an entire tree of nodes and elements:
$parser = new DOMDocument();
$parser->load("books.xml");
processNodes($parser->documentElement);
function processNodes($node) {
foreach ($node->childNodes as $child) {
if ($child->nodeType == XML_TEXT_NODE) {
echo $child->nodeValue;
}
else if ($child->nodeType == XML_ELEMENT_NODE) {
processNodes($child);
}
}
}
Parsing XML with SimpleXML
If you’re consuming very simple XML documents, you might consider the third library provided by PHP, SimpleXML. SimpleXML doesn’t have the ability to generate documents as the DOM extension does, and isn’t as flexible or memory-efficient as the event-driven extension, but it makes it very easy to read, parse, and traverse simple XML documents.
SimpleXML takes a file, string, or DOM document (produced using the DOM extension) and generates an object. Properties on that object are arrays providing access to elements in each node. With those arrays, you can access elements using numeric indices and attributes using non-numeric indices. Finally, you can use string conversion on any value you retrieve to get the text value of the item.
For example, we could display all the titles of the books in our books.xml document using:
$document = simplexml_load_file("books.xml");
foreach ($document->book as $book) {
echo $book->title . "
";
}
Using the children() method on the object, you can iterate over the child nodes of a given node; likewise, you can use the attributes() method on the object to iterate over the attributes of the node:
$document = simplexml_load_file("books.xml");
foreach ($document->book as $node) {
foreach ($node->attributes() as $attribute) {
echo "{$attribute}
";
}
}
Finally, using the asXml() method on the object, you can retrieve the XML of the document in XML format. This lets you change values in your document and write it back out to disk easily:
$document = simplexml_load_file("books.xml");
foreach ($document->children() as $book) {
$book->title = "New Title";
}
file_put_contents("books.xml", $document->asXml());
Transforming XML with XSLT
Extensible Stylesheet Language Transformations (XSLT) is a language for transforming XML documents into different XML, HTML, or any other format. For example, many websites offer several formats of their content—HTML, printable HTML, and WML (Wireless Markup Language) are common. The easiest way to present these multiple views of the same information is to maintain one form of the content in XML and use XSLT to produce the HTML, printable HTML, and WML.
PHP’s XSLT extension uses the Libxslt C library to provide XSLT support.
Three documents are involved in an XSLT transformation: the original XML document, the XSLT document containing transformation rules, and the resulting document. The final document doesn’t have to be in XML; in fact, it’s common to use XSLT to generate HTML from XML. To do an XSLT transformation in PHP, you create an XSLT processor, give it some input to transform, and then destroy the processor.
Create a processor by creating a new XsltProcessor object:
$processor = new XsltProcessor;
Parse the XML and XSL files into DOM objects:
$xml = new DomDocument; $xml->load($filename); $xsl = new DomDocument; $xsl->load($filename);
Attach the XML rules to the object:
$processor->importStyleSheet($xsl);
Process a file with the transformToDoc(), transformToUri(), or transformToXml() methods:
$result = $processor->transformToXml($xml);
Each takes the DOM object representing the XML document as a parameter.
Example 12-10 is the XML document we’re going to transform. It is in a similar format to many of the news documents you find on the web.
Example 12-10. XML document
<?xml version="1.0" ?> <news xmlns:news="http://slashdot.org/backslash.dtd"> <story> <title>O'Reilly Publishes Programming PHP</title> <url>http://example.org/article.php?id=20020430/458566</url> <time>2002-04-30 09:04:23</time> <author>Rasmus and some others</author> </story> <story> <title>Transforming XML with PHP Simplified</title> <url>http://example.org/article.php?id=20020430/458566</url> <time>2002-04-30 09:04:23</time> <author>k.tatroe</author> <teaser>Check it out</teaser> </story> </news>
Example 12-11 is the XSL document we’ll use to transform the XML document into HTML. Each xsl:template element contains a rule for dealing with part of the input document.
Example 12-11. News XSL transform
<?xml version="1.0" encoding="utf-8" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes" encoding="utf-8" />
<xsl:template match="/news">
<html>
<head>
<title>Current Stories</title>
</head>
<body bgcolor="white" >
<xsl:call-template name="stories"/>
</body>
</html>
</xsl:template>
<xsl:template name="stories">
<xsl:for-each select="story">
<h1><xsl:value-of select="title" /></h1>
<p>
<xsl:value-of select="author"/> (<xsl:value-of select="time"/>)<br />
<xsl:value-of select="teaser"/>
[ <a href="{url}">More</a> ]
</p>
<hr />
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Example 12-12 is the very small amount of code necessary to transform the XML document into an HTML document using the XSL stylesheet. We create a processor, run the files through it, and print the result.
Example 12-12. XSL transformation from files
<?php
$processor = new XsltProcessor;
$xsl = new DOMDocument;
$xsl->load("rules.xsl");
$processor->importStyleSheet($xsl);
$xml = new DomDocument;
$xml->load("feed.xml");
$result = $processor->transformToXml($xml);
echo "<pre>{$result}</pre>";
Although it doesn’t specifically discuss PHP, Doug Tidwell’s book XSLT (http://oreil.ly/XSLT_2E) provides a detailed guide to the syntax of XSLT stylesheets.
What’s Next
While XML remains a major format for sharing data, a simplified version of JavaScript data encapsulation, known as JSON, has rapidly become the de facto standard for simple, readable, and terse sharing of web service responses and other data. That’s the subject we’ll turn to in the next chapter.