
Chapter 15. Application Techniques
By now, you should have a solid understanding of the details of the PHP language and its use in a variety of common situations. Now we’re going to show you some techniques you may find useful in your PHP applications, such as code libraries, templating systems, efficient output handling, error handling, and performance tuning.
Code Libraries
As you’ve seen, PHP ships with numerous extension libraries that combine useful functionality into distinct packages that you can access from your scripts. We covered using the GD, FPDF, and Libxslt extension libraries in Chapter 10, Chapter 11, and Chapter 12, respectively.
In addition to using the extensions that ship with PHP, you can create libraries of your own code that you can use in more than one part of your website. The general technique is to store a collection of related functions in a PHP file. Then, when you need to use that functionality in a page, you can use require_once() to insert the contents of the file into your current script.
Note
Note that there are three other inclusion type functions that can also be employed. They are require(), include_once(), and include(). Chapter 2 discusses these functions in detail.
For example, say you have a collection of functions that help create HTML form elements in valid HTML: one function in your collection creates a text field or a textarea (depending on how many characters you set as the maximum), another creates a series of pop ups from which to set a date and time, and so on. Rather than copying the code into many pages—which is tedious, leads to errors, and makes it difficult to fix any bugs found in the functions—creating a function library is the sensible choice.
When you are combining functions into a code library, be careful to maintain a balance between grouping related functions and including functions that are not often used. When you include a code library in a page, all of the functions in that library are parsed, whether you use them all or not. PHP’s parser is quick, but not parsing a function is even faster. At the same time, you don’t want to split your functions across too many libraries, causing you to have to include lots of files in each page, because file access is slow.
Templating Systems
A templating system provides a way of separating the code in a web page from the layout of that page. In larger projects, templates can be used to allow designers to deal exclusively with designing web pages and programmers to deal (more or less) exclusively with programming. The basic idea of a templating system is that the web page itself contains special markers that are replaced with dynamic content. A web designer can create the HTML for a page and simply worry about the layout, using the appropriate markers for different kinds of dynamic content that are needed. The programmer, on the other hand, is responsible for creating the code that generates the dynamic content for the markers.
To make this more concrete, let’s look at a simple example. Consider the following web page, which asks the user to supply a name and then, if a name is provided, thanks the user:
<html>
<head>
<title>User Information</title>
</head>
<body>
<?php if (!empty($_GET['name'])) {
// do something with the supplied values ?>
<p><font face="helvetica,arial">Thank you for filling out the form,
<?php echo $_GET['name'] ?>.</font></p>
<?php }
else { ?>
<p><font face="helvetica,arial">Please enter the following information:</font></p>
<form action="<?php echo $_SERVER['PHP_SELF'] ?>">
<table>
<tr>
<td>Name:</td>
<td>
<input type="text" name="name" />
<input type="submit" />
</td>
</tr>
</table>
</form>
<?php } ?>
</body>
</html>
The placement of the different PHP elements within various layout tags, such as the font and table elements, is better left to a designer, especially as the page gets more complex. Using a templating system, we can split this page into separate files, some containing PHP code and some containing the layout. The HTML pages will then contain special markers where dynamic content should be placed. Example 15-1 shows the new HTML template page for our simple form, which is stored in the file user.template. It uses the {DESTINATION} marker to indicate the script that should process the form.
Example 15-1. HTML template for user input form
<html>
<head>
<title>User Information</title>
</head>
<body>
<p>Please enter the following information:</p>
<form action="{DESTINATION}">
<table>
<tr>
<td>Name:</td>
<td><input type="text" name="name" /></td>
</tr>
</table>
</form>
</body>
</html>
Example 15-2 shows the template for the thank-you page, called thankyou.template, which is displayed after the user has filled out the form. This page uses the {NAME} marker to include the value of the user’s name.
Example 15-2. HTML template for thank-you page
<html>
<head>
<title>Thank You</title>
</head>
<body>
<p>Thank you for filling out the form, {NAME}.</p>
</body>
</html>
Now we need a script that can process these template pages, filling in the appropriate information for the various markers. Example 15-3 shows the PHP script that uses these templates (one for before the user has given us information and one for after). The PHP code uses the fillTemplate() function to join our values and the template files. This file is called form_template.php.
Example 15-3. Template script
<?php
$bindings["DESTINATION"] = $_SERVER["PHP_SELF"];
$name = $_GET["name"];
if (!empty($name)) {
// do something with the supplied values
$template = "thankyou.template";
$bindings["NAME"] = $name;
}
else {
$template = "user.template";
}
echo fillTemplate($template, $bindings);
Example 15-4 shows the fillTemplate() function used by the script in Example 15-3. The function takes a template filename (relative to a directory named templates located in the document root), an array of values, and an optional instruction denoting what to do if a marker is found for which no value is given. The possible values are delete, which deletes the marker; comment, which replaces the marker with a comment noting that the value is missing; or anything else, which just leaves the marker alone. This file is called func_template.php.
Example 15-4. The fillTemplate() function
<?php
function fillTemplate($name, $values = array(), $unhandled = "delete") {
$templateFile = "{$_SERVER['DOCUMENT_ROOT']}/templates/{$name}";
if ($file = fopen($templateFile, 'r')) {
$template = fread($file, filesize($templateFile));
fclose($file);
}
$keys = array_keys($values);
foreach ($keys as $key) {
// look for and replace the key everywhere it occurs in the template
$template = str_replace("{{$key}}", $values[$key], $template);
}
if ($unhandled == "delete") {
// remove remaining keys
$template = preg_replace("/{[^ }]*}/i", "", $template);
}
else if ($unhandled == "comment") {
// comment remaining keys
$template = preg_replace("/{([^ }]*)}/i", "<!-- \1 undefined -->", $template);
}
return $template;
}
Clearly, this example of a templating system is somewhat contrived. But if you think of a large PHP application that displays hundreds of news articles, you can imagine how a templating system that used markers such as {HEADLINE}, {BYLINE}, and {ARTICLE} might be useful, as it would allow designers to create the layout for article pages without needing to worry about the actual content.
While templates may reduce the amount of PHP code that designers have to see, there is a performance trade-off, as every request incurs the cost of building a page from the template. Performing pattern matches on every outgoing page can really slow down a popular site. Andrei Zmievski’s Smarty (http://www.smarty.net/) is an efficient templating system that neatly side-steps much of this performance hit by turning the template into straight PHP code and caching it. Instead of doing the template replacement on every request, it does it only when the template file is changed.
Handling Output
PHP is all about displaying output in the web browser. Accordingly, there are a few different techniques that you can use to handle output more efficiently or conveniently.
Output Buffering
By default, PHP sends the results of echo and similar commands to the browser after each command is executed. Alternately, you can use PHP’s output buffering functions to gather the information that would normally be sent to the browser into a buffer and send it later (or kill it entirely). This allows you to specify the content length of your output after it is generated, capture the output of a function, or discard the output of a built-in function.
You turn on output buffering with the ob_start() function:
ob_start([callback]);
The optional callback parameter is the name of a function that postprocesses the output. If specified, this function is passed the collected output when the buffer is flushed, and it should return a string of output to send to the browser. You can use this, for instance, to turn all occurrences of http://www.yoursite.com to http://www.mysite.com.
While output buffering is enabled, all output is stored in an internal buffer. To get the current length and contents of the buffer, use ob_get_length() and ob_get_contents():
$len = ob_get_length(); $contents = ob_get_contents();
If buffering isn’t enabled, these functions return false.
There are two ways to throw away the data in the buffer. The ob_clean() function erases the output buffer but does not turn off buffering for subsequent output. The ob_end_clean() function erases the output buffer and ends output buffering.
There are three ways to send the collected output to the browser (this action is known as flushing the buffer). The ob_flush() function sends the output data to the web server and clears the buffer, but doesn’t terminate output buffering. The flush() function not only flushes and clears the output buffer, but also tries to make the web server send the data to the browser immediately. The ob_end_flush() function sends the output data to the web server and ends output buffering. In all cases, if you specified a callback with ob_start(), that function is called to decide exactly what gets sent to the server.
If your script ends with output buffering still enabled—that is, if you haven’t called ob_end_flush() or ob_end_clean()—PHP calls ob_end_flush() for you.
The following code collects the output of the phpinfo() function and uses it to determine whether you have the GD graphics module installed:
ob_start();
phpinfo();
$phpinfo = ob_get_contents();
ob_end_clean();
if (strpos($phpinfo, "module_gd") === false) {
echo "You do not have GD Graphics support in your PHP, sorry.";
}
else {
echo "Congratulations, you have GD Graphics support!";
}
Of course, a quicker and simpler approach to check if a certain extension is available is to pick a function that you know the extension provides and check if it exists. For the GD extension, you might do:
if (function_exists("imagecreate")) {
// do something useful
}
To change all references in a document from http://www.yoursite.com to http://www.mysite.com, simply wrap the page like this:
ob_start(); ?> Visit <a href="http://www.yoursite.com/foo/bar">our site</a> now! <?php $contents = ob_get_contents(); ob_end_clean();
echo str_replace("http://www.yoursite.com/",
"http://www.mysite.com/", $contents);
?> Visit <a href="http://www.mysite.com/foo/bar">our site</a> now!
Another way to do this is with a callback. Here, the rewrite() callback changes the text of the page:
function rewrite($text) {
return str_replace("http://www.yoursite.com/",
"http://www.mysite.com/", $text);
}
ob_start("rewrite"); ?>
Visit <a href="http://www.yoursite.com/foo/bar">our site</a> now!
Visit <a href="http://www.mysite.com/foo/bar">our site</a> now!
Output Compression
Recent browsers support compressing the text of web pages; the server sends compressed text and the browser decompresses it. To automatically compress your web page, wrap it like this:
ob_start("ob_gzhandler");
The built-in ob_gzhandler() function can be used as the callback for a call to ob_start(). It compresses the buffered page according to the Accept-Encoding header sent by the browser. Possible compression techniques are gzip, deflate, or none.
It rarely makes sense to compress short pages, as the time for compression and decompression exceeds the time it would take to simply send the uncompressed text. It does make sense to compress large (greater than 5 KB) web pages, however.
Instead of adding the ob_start() call to the top of every page, you can set the output_handler option in your php.ini file to a callback to be made on every page. For compression, this is ob_gzhandler.
Performance Tuning
Before thinking much about performance tuning, take the time to get your code working properly. Once you have sound working code, you can locate the slower sections, or “bottlenecks.” If you try to optimize your code while writing it, you’ll discover that optimized code tends to be more difficult to read and generally takes more time to write. If you spend that time on a section of code that isn’t actually causing a problem, that’s time wasted, especially down the road when you need to maintain that code and you can no longer read it.
Once you get your code working, you may find that it needs some optimization. Optimizing code tends to fall within one of two areas: shortening execution times and reducing memory requirements.
Before you begin optimization, ask yourself whether you need to optimize at all. Too many programmers have wasted hours wondering whether a complex series of string function calls are faster or slower than a single Perl regular expression, when the page where this code is located is viewed once every five minutes. Optimization is necessary only when a page takes so long to load that the user perceives it as slow. Often this is a symptom of a very popular site—if requests for a page come in fast enough, the time it takes to generate that page can mean the difference between prompt delivery and server overload. With a possible long wait on your site, you can bet that your web visitors won’t take long to decide to look elsewhere for their information.
Once you’ve decided that your page needs optimization (this can best be done with some end user testing and observation), you can move on to working out exactly what is slow. You can use the techniques in the section “Profiling” to time the various subroutines or logical units of your page. This will give you an idea of which parts of your page are taking the longest time to produce—these parts are where you should focus your optimization efforts. If a page is taking 5 seconds to produce, you’ll never get it down to 2 seconds by optimizing a function that accounts for only 0.25 seconds of the total time. Identify the biggest time-wasting blocks of code and focus on them. Time the page and the pieces you’re optimizing to make sure your changes are having a positive, and not a negative, effect.
Finally, know when to quit. Sometimes there is an absolute limit for the speed at which you can get something to run. In these circumstances, the only way to get better performance is to throw new hardware at the problem. The solution might turn out to be faster machines, or more web servers with a reverse-proxy cache in front of them.
Benchmarking
If you’re using Apache, you can use the Apache benchmarking utility, ab, to do high-level performance testing. To use it, run:
$ /usr/local/apache/bin/ab -c 10 -n 1000 http://localhost/info.php
This command tests the speed of the PHP script info.php 1,000 times, with 10 concurrent requests running at any given time. The benchmarking tool returns various information about the test, including the slowest, fastest, and average load times. You can compare those values to a static HTML page to see how quickly your script performs.
For example, here’s the output from 1,000 fetches of a page that simply calls phpinfo():
This is ApacheBench, Version 1.3d <$Revision: 1.2 $> apache-1.3 Copyright (c) 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Copyright (c) 1998-2001 The Apache Group, http://www.apache.org/ Benchmarking localhost (be patient) Completed 100 requests Completed 200 requests Completed 300 requests Completed 400 requests Completed 500 requests Completed 600 requests Completed 700 requests Completed 800 requests Completed 900 requests Finished 1000 requests Server Software: Apache/1.3.22 Server Hostname: localhost Server Port: 80 Document Path: /info.php Document Length: 49414 bytes Concurrency Level: 10 Time taken for tests: 8.198 seconds Complete requests: 1000 Failed requests: 0 Broken pipe errors: 0 Total transferred: 49900378 bytes HTML transferred: 49679845 bytes Requests per second: 121.98 [#/sec] (mean) Time per request: 81.98 [ms] (mean) Time per request: 8.20 [ms] (mean, across all concurrent requests) Transfer rate: 6086.90 [Kbytes/sec] received Connnection Times (ms) min mean[+/-sd] median max Connect: 0 12 16.9 1 72 Processing: 7 69 68.5 58 596 Waiting: 0 64 69.4 50 596 Total: 7 81 66.5 79 596 Percentage of the requests served within a certain time (ms) 50% 79 66% 80 75% 83 80% 84 90% 158 95% 221 98% 268 99% 288 100% 596 (last request)
If your PHP script uses sessions, the results you get from ab will not be representative of the real-world performance of the scripts. Since a session is locked across a request, results from the concurrent requests run by ab will be extremely poor. However, in normal usage, a session is typically associated with a single user, who isn’t likely to make concurrent requests.
Using ab tells you the overall speed of your page but gives you no information on the speed of individual functions of blocks of code within the page. Use ab to test changes you make to your code as you attempt to improve its speed. We show you how to time individual portions of a page in the next section, but ultimately these microbenchmarks don’t matter if the overall page is still slow to load and run. The ultimate proof that your performance optimizations have been successful comes from the numbers that ab reports.
Profiling
PHP does not have a built-in profiler, but there are some techniques you can use to investigate code that you think has performance issues. One technique is to call the microtime() function to get an accurate representation of the amount of time that elapses. You can surround the code you’re profiling with calls to microtime() and use the values it returns to calculate how long the code took.
For instance, here’s some code you can use to find out just how long it takes to produce the phpinfo() output:
ob_start(); $start = microtime(true); phpinfo(); $end = microtime(true); ob_end_clean(); echo "phpinfo() took " . ($end - $start) . " seconds to run. ";
Reload this page several times, and you’ll see the number fluctuate slightly. Reload it often enough, and you’ll see it fluctuate quite a lot. The danger of timing a single run of a piece of code is that you may not get a representative machine load—the server might be paging as a user starts emacs, or it may have removed the source file from its cache. The best way to get an accurate representation of the time it takes to do something is to time repeated runs and look at the average of those times.
The Benchmark class available in PEAR makes it easy to repeatedly time sections of your script. Here is a simple example that shows how you can use it:
require_once 'Benchmark/Timer.php';
$timer = new Benchmark_Timer;
$timer->start();
sleep(1);
$timer->setMarker('Marker 1');
sleep(2);
$timer->stop();
$profiling = $timer->getProfiling();
foreach ($profiling as $time) {
echo $time["name"] . ": " . $time["diff"] . "<br>
";
}
echo "Total: " . $time["total"] . "<br>
";
The output from this program is:
Start: - Marker 1: 1.0006979703903 Stop: 2.0100029706955 Total: 3.0107009410858
That is, it took 1.0006979703903 seconds to get to marker 1, which is set right after our sleep(1) call, so it is what you would expect. It took just over two seconds to get from marker 1 to the end, and the entire script took just over three seconds to run. You can add as many markers as you like and thereby time various parts of your script.
Optimizing Execution Time
Here are some tips for shortening the execution times of your scripts:
Avoid
printf()whenechois all you need.Avoid recomputing values inside a loop, as PHP’s parser does not remove loop invariants. For example, don’t do this if the size of $array doesn’t change:
for ($i = 0; $i < count($array); $i++) { /* do something */ }Instead, do this:
$num = count($array); for ($i = 0; $i < $num; $i++) { /* do something */ }Include only files that you need. Split included files to include only functions that you are sure will be used together. Although the code may be a bit more difficult to maintain, parsing code you don’t use is expensive.
If you are using a database, use persistent database connections—setting up and tearing down database connections can be slow.
Don’t use a regular expression when a simple string-manipulation function will do the job. For example, to turn one character into another in a string, use
str_replace(), notpreg_replace().
Optimizing Memory Requirements
Here are some techniques for reducing the memory requirements of your scripts:
Use numbers instead of strings whenever possible:
for ($i = "0"; $i < "10"; $i++) // bad for ($i = 0; $i < 10; $i++) // good
When you’re done with a large string, set the variable holding the string to an empty string. This frees up the memory to be reused.
Only include or require files that you need. Use include_once() and require_once() instead of
include()andrequire().Release MySQL or other database result sets as soon as you are done with them. There is no benefit to keeping result sets in memory beyond their use.
Reverse Proxies and Replication
Adding hardware is often the quickest route to better performance. It’s better to benchmark your software first, though, as it’s generally cheaper to fix software than to buy new hardware. Three common solutions to the problem of scaling traffic are reverse-proxy caches, load-balancing servers, and database replication.
Reverse-proxy caches
A reverse proxy is a program that sits in front of your web server and handles all connections from client browsers. Proxies are optimized to serve up static files quickly, and despite appearances and implementation, most dynamic sites can be cached for short periods of time without loss of service. Normally, you’ll run the proxy on a separate machine from your web server.
Take, for example, a busy site whose front page is hit 50 times per second. If this first page is built from two database queries and the database changes as often as twice a minute, you can avoid 5,994 database queries per minute by using a Cache-Control header to tell the reverse proxy to cache the page for 30 seconds. The worst-case scenario is that there will be a 30-second delay from database update to a user seeing this new data. For most applications that’s not a very long delay, and it gives significant performance benefits.
Proxy caches can even intelligently cache content that is personalized or tailored to the browser type, accepted language, or similar feature. The typical solution is to send a Vary header telling the cache exactly which request parameters affect the caching.
There are hardware proxy caches available, but there are also very good software implementations. For a high-quality and extremely flexible open source proxy cache, have a look at Squid (http://www.squid-cache.org). See the book Web Caching (http://oreil.ly/Web_Caching) by Duane Wessels (O’Reilly) for more information on proxy caches and how to tune a website to work with one.
Load balancing and redirection
One way to boost performance is to spread the load over a number of machines. A load-balancing system does this by either evenly distributing the load or sending incoming requests to the least-loaded machine. A redirector is a program that rewrites incoming URLs, allowing fine-grained control over the distribution of requests to individual server machines.
Again, there are hardware HTTP redirectors and load balancers, but redirection and load balancing can also be done effectively in software. By adding redirection logic to Squid through a tool like SquidGuard (http://www.squidguard.org), you can improve performance in a number of ways.
MySQL replication
Sometimes the database server is the bottleneck—many simultaneous queries can bog down a database server, resulting in sluggish performance. Replication is one of the best solutions. Take everything that happens to one database and quickly bring one or more other databases in sync, so you end up with multiple identical databases. This lets you spread your queries across many database servers instead of loading down only one.
The most effective model is to use one-way replication, where you have a single master database that gets replicated to a number of slave databases. Database writes go to the master server, and database reads are load-balanced across multiple slave databases. This technique is aimed at architectures that do a lot more reads than writes. Most web applications fit this scenario nicely.
Figure 15-1 shows the relationship between the master and slave databases during replication.
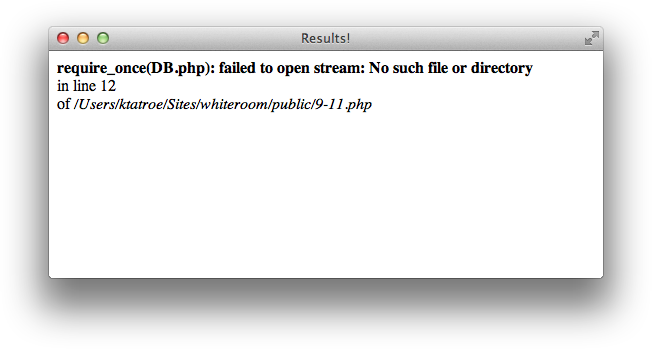
Figure 15-1. Database replication relationship
Many databases support replication, including MySQL, PostgreSQL, and Oracle.
Putting it all together
For a really high-powered architecture, pull all these concepts together into a configuration like the one shown in Figure 15-2.
Figure 15-2. Putting it all together
Using five separate machines—one for the reverse proxy and redirector, three web servers, and one master database server—this architecture can handle a huge number of requests. The exact number depends only on the two bottlenecks—the single Squid proxy and the single master database server. With a bit of creativity, either or both of these could be split across multiple servers as well, but as it is, if your application is somewhat cacheable and heavy on database reads, this is a nice approach.
Each Apache server gets its own read-only MySQL database, so all read requests from your PHP scripts go over a Unix-domain local socket to a dedicated MySQL instance. You can add as many of these Apache/PHP/MySQL servers as you need under this framework. Any database writes from your PHP applications will go over a TCP socket to the master MySQL server.
What’s Next
In the next chapter, we’ll dive deeper into using PHP to develop and deploy web services.