
A Ten-Minute Guide to XML Namespaces
Let’s examine the motivations behind XML namespaces. The first motivation is to have namespaces replace the formal public identifier (FPI), an inheritance from SGML. These identifiers provide a way to identify which vocabulary , or set of names, is being used in a document. The XML/SGML way of identifying the vocabulary used in our library would be to add a public identifier to the document type declaration such as:
<?xml version="1.0"?> <!DOCTYPE library PUBLIC "-//ERICVANDERVLIST//DTD for library//EN" "library.dtd"/> <library> ... </library>
This DOCTYPE declaration contains an FPI
(-//ERICVANDERVLIST//DTD for
library//EN) and the location of the DTD
describing the vocabulary (library.dtd). XML
requires that the DOCTYPE
declaration always provide a
SYSTEM
identifier—a
location—when a
PUBLIC
identifier is used, though
PUBLIC identifiers aren’t
required when SYSTEM identifiers are used. The
creators of XML 1.0 didn’t want to require parsers
to include the tools (typically XML catalog processing) for resolving
formal public identifiers to addresses, but they kept the option
open. Because the DOCTYPE declaration provides the
parser with identification of the DTD rather than the identification
of the abstract set of names, this approach is generally sensible.
The first goal of XML
namespaces is to provide identifiers for
the abstract notions of vocabularies and namespaces without linking
these identifiers directly to the technical implementations (DTDs,
schemas, or whatever) that define or enforce what they are. These
identifiers are no longer FPIs like those used in doctype
declarations but Uniform Resource
Identifiers
(URIs, or, to be
picky, “URI references”). These
identifiers can be applied to every element and attribute in a
document, not just the document as a whole. To assign a namespace to
all the elements from Example 3-1, you can use an
xmlns attribute to assign a URI to the default
namespace:
<?xml version="1.0"?> library xmlns="http://eric.van-der-vlist.com/ns/library"> ... </library>
The identifier for my namespace is the string
http://eric.van-der-vlist.com/ns/library. There
doesn’t need to be any document at this
address—it’s only a label. Though it looks
temptingly like a hyperlink, it’s not designed to be
used that way. Namespaces are identifiers that give a hint about
ownership. The assumption is I create a namespace only if I own the
domain it uses and that I won’t use the same
identifier to identify several different things. XML namespaces per
se don’t define any way to associate resources such
as schemas or documentations with a namespace URI. (For a mechanism
that does that, see Resource Directory
Description Language at http://rddl.org.)
The namespace declaration
xmlns="http://eric.van-der-vlist.com/ns/library"
has been applied to the document element
(library), and that declaration is inherited by
all its child elements, unless the child elements provide their own
namespace declarations and override it.
The second goal of XML namespaces, and the place where it goes
farther than FPIs in
DOCTYPE
declarations, is to provide a
way to mix elements and attributes from different namespaces in a
single document. In our library for instance, the
library and book elements use a
vocabulary specific to libraries, while the author
element can use a vocabulary for human resources. The
character element can be a mix of both: the
character element itself and the
qualification element would be from the library
namespace, while the name and
born elements would be from the HR vocabulary.
Figure 11-1 shows how this might look in the XML
document.
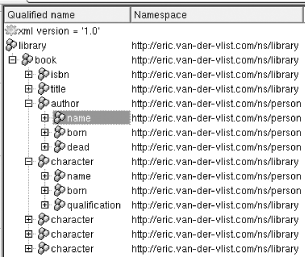
Applying
namespaces to the elements can be
achieved using the xmlns declaration as we have
already seen:
<?xml version="1.0"?>
<library xmlns="http://eric.van-der-vlist.com/ns/library">
<book id="b0836217462" available="true">
<isbn>0836217462</isbn>
<title xml:lang="en">Being a Dog Is a Full-Time Job</title>
<author id="CMS" xmlns="http://eric.van-der-vlist.com/ns/person">
<name>Charles M Schulz</name>
<born>1922-11-26</born>
<dead>2000-02-12</dead>
</author>
<character id="PP">
<name xmlns="http://eric.van-der-vlist.com/ns/person">Peppermint Patty</name>
<born xmlns="http://eric.van-der-vlist.com/ns/person">1966-08-22</born>
<qualification>bold, brash and tomboyish</qualification>
</character>
<character id="Snoopy">
<name xmlns="http://eric.van-der-vlist.com/ns/person">Snoopy</name>
<born xmlns="http://eric.van-der-vlist.com/ns/person">1950-10-04</born>
<qualification>extroverted beagle</qualification>
</character>
<character id="Schroeder">
<name xmlns="http://eric.van-der-vlist.com/ns/person">Schroeder</name>
<born xmlns="http://eric.van-der-vlist.com/ns/person">1951-05-30</born>
<qualification>brought classical music to the Peanuts strip</qualification>
</character>
<character id="Lucy">
<name xmlns="http://eric.van-der-vlist.com/ns/person">Lucy</name>
<born xmlns="http://eric.van-der-vlist.com/ns/person">1952-03-03</born>
<qualification>bossy, crabby and selfish</qualification>
</character>
</book>
</library>Applying namespace declarations to every element rapidly becomes very
verbose. To reduce this verbosity, XML namespaces provide a way
to assign prefixes to
namespaces. These prefixes can
then be applied to the names of the elements (and attributes) to
identify their namespaces. The namespace declared using the
xmlns
attribute is called the
default
namespace
because it’s
assigned to elements that have no prefix. The previous document can
be rewritten using the default namespace for the library and by
assigning an hr prefix to the other namespace:
<?xml version="1.0"?>
<library
xmlns="http://eric.van-der-vlist.com/ns/library"
xmlns:hr="http://eric.van-der-vlist.com/ns/person">
<book id="b0836217462" available="true">
<isbn>0836217462</isbn>
<title xml:lang="en">Being a Dog Is a Full-Time Job</title>
<hr:author id="CMS">
<hr:name>Charles M Schulz</hr:name>
<hr:born>1922-11-26</hr:born>
<hr:dead>2000-02-12</hr:dead>
</hr:author>
<character id="PP">
<hr:name>Peppermint Patty</hr:name>
<hr:born>1966-08-22</hr:born>
<qualification>bold, brash and tomboyish</qualification>
</character>
<character id="Snoopy">
<hr:name>Snoopy</hr:name>
<hr:born>1950-10-04</hr:born>
<qualification>extroverted beagle</qualification>
</character>
<character id="Schroeder">
<hr:name>Schroeder</hr:name>
<hr:born>1951-05-30</hr:born>
<qualification>brought classical music to the Peanuts strip</qualification>
</character>
<character id="Lucy">
<hr:name>Lucy</hr:name>
<hr:born>1952-03-03</hr:born>
<qualification>bossy, crabby and selfish</qualification>
</character>
</book>
</library>If preferred, for symmetry, you can use a prefix for both namespaces:
<?xml version="1.0"?>
<lib:library
xmlns:lib="http://eric.van-der-vlist.com/ns/library"
xmlns:hr="http://eric.van-der-vlist.com/ns/person">
<lib:book id="b0836217462" available="true">
<lib:isbn>0836217462</lib:isbn>
<lib:title xml:lang="en">Being a Dog Is a Full-Time Job</lib:title>
<hr:author id="CMS">
<hr:name>Charles M Schulz</hr:name>
<hr:born>1922-11-26</hr:born>
<hr:dead>2000-02-12</hr:dead>
</hr:author>
<lib:character id="PP">
<hr:name>Peppermint Patty</hr:name>
<hr:born>1966-08-22</hr:born>
<lib:qualification>bold, brash and tomboyish</lib:qualification>
</lib:character>
<lib:character id="Snoopy">
<hr:name>Snoopy</hr:name>
<hr:born>1950-10-04</hr:born>
<lib:qualification>extroverted beagle</lib:qualification>
</lib:character>
<lib:character id="Schroeder">
<hr:name>Schroeder</hr:name>
<hr:born>1951-05-30</hr:born>
<lib:qualification>brought classical music to the Peanuts strip
</lib:qualification>
</lib:character>
<lib:character id="Lucy">
<hr:name>Lucy</hr:name>
<hr:born>1952-03-03</hr:born>
<lib:qualification>bossy, crabby and selfish</lib:qualification>
</lib:character>
</lib:book>
</lib:library>Note that, for a namespace-aware application, the three previous documents are considered equivalent. The prefixes are only shortcuts to associate a namespace URI and a local name (the part of the name after the colon). This combination disambiguates cases in which the same local name is used in other namespaces.
Elements and attributes receive slightly different
namespace
handling. They are similar in that attribute names can be given a
prefix to show that they belong to a namespace. They get special
treatment in that the default namespace doesn’t
apply to them and any attributes that have no prefix are considered
to have no namespace URI. They sort of belong to the namespace of
their parent element but not exactly. The reason for this is that
attributes are supposed to provide metadata qualifying their parent
element rather than to contain actual information. Being qualifiers,
it’s often considered that by default they belong to
the same vocabulary as their parent elements. This is why I have kept
the id and available attributes
unprefixed in my three examples. Technically, however, these
attributes are in no namespace and have no namespace URI.
The last goal of XML namespaces (and the motivation for taking that much effort to allow several namespaces in a single document) is to facilitate the development of independent (or semi-independent) vocabularies that can be used as building blocks. One of the ideas is that if applications are cleanly designed and just ignore elements and attributes that they don’t understand, documents can be extended to support new features without breaking existing applications.
For instance, in the sample library I haven’t
defined the publisher of the book. I can add a
publisher element to our existing namespace, but
instead might want to use the definition given by the
Dublin Core Metadata
Initiative (DCMI). They’ve already created an
element for representing publishers in a namespace
they’ve defined. I can use their namespace to write:
<?xml version="1.0"?> <library xmlns="http://eric.van-der-vlist.com/ns/library" xmlns:hr="http://eric.van-der-vlist.com/ns/person" xmlns:dc="http://purl.org/dc/elements/1.1/"> <book id="b0836217462" available="true"> <isbn>0836217462</isbn> <title xml:lang="en">Being a Dog Is a Full-Time Job</title> <dc:publisher>Andrews Mc Meel Publishing</dc:publisher> </book> </library>
There are two benefits to doing this. First, everyone can easily
understand that the publisher element corresponds
to the definition given by the DCMI:
URI: http://purl.org/dc/elements/1.1/publisher Namespace:http://purl.org/
dc/elements/1.1/
Name: publisher
Label: Publisher
Definition: An entity responsible for making the resource available
Comment: Examples of a Publisher include a person, an organisation,
or a service.
Typically, the name of a Publisher should be used to
indicate the entity.
Type of term: http://dublincore.org/usage/documents/principles/#element
Status: http://dublincore.org/usage/documents/process/#recommended
Date issued: 1998-08-06
Date modified: 2002-10-04
Decision: http://dublincore.org/usage/decisions/#Decision-2002-03
This version: http://dublincore.org/usage/terms/dc/#publisher-004
Replaces: http://dublincore.org/usage/terms/dc/#publisher-003The second benefit is that if my application has been implemented to
skip elements and attributes from unsupported namespaces, the
addition of this dc:publisher element
won’t break anything. Again, note that the mechanism
to retrieve this definition isn’t specified by the
“Namespaces in XML”
recommendation.