
Literate Programming
A common approach to software documentation is to extract documentation from the source documents relying on the structure of the programs and their comments. (A good example is JavaDoc, the documentation extraction tool shipped with Java and used almost universally on Java projects.) Other projects separate code and documentation. For both approaches, documentation and comments often evolve separately from the code, and the documentation eventually goes out of date.
Projects tend to focus on the code. Documentation is often considered a side project, less important than the code. Donald Knuth, the inventor of the term “literate programming,” has a contrary point of view:
“I believe that the time is ripe for significantly better documentation of programs, and that we can best achieve this by considering programs to be works of literature. Hence, my title: “Literate Programming.”[2]
Knuth charges us with the task of changing our traditional attitude to the construction of programs. Instead of giving priority to instructing a computer what to do, he suggests that programmers concentrate on explaining to human beings what the computer is supposed to do.
“The practitioner of literate programming can be regarded as an essayist whose main concern is with exposition and excellence of style. Such an author, with thesaurus in hand, chooses variable names carefully and explains what each variable means. He or she strives for a program that is comprehensible. The program’s concepts have been introduced in an order that is best for human understanding, using a mixture of formal and informal methods that reinforce each other.”
Norm Walsh has adapted the concept to XML. Tools for literate programming in XML are available under the name "litprog” by the DocBook project on SourceForge (http://sourceforge.net/projects/docbook/). The basic idea of literate programming (or litprog) is to include a snippet of code (or a snippet of schemas in our case) within the documentation, which can be written in any XML format, including XHTML or DocBook. From this single document embedding code in documentation, a couple of XSLT transformations generate a formatted documentation and the source code.
This makes two big changes. First, as expected, you’re working upside-down compared to the common usage of adding comments in the code. The other major practical difference is that you are now defining the relations between the snippets of code or schema using the mechanisms of litprog instead of the mechanisms specific to each programming language. The granularity of the documentation becomes virtually independent of the granularity of your functions, methods, or, in our case, named patterns. This independence lets you group several languages in a single literate documentation. You can describe, for instance, a RELAX NG schema of a document using an XSLT transformation to manipulate the document, and then have a DOM application read it.
Out of the Box
Literate programming works well with RELAX NG, as I will demonstrate
next. A literate programming document embeds
src:fragment elements to combine the fragments of
a schema into the program documentation. The fragments are then
assembled with a complete schema. The documentation can use any
format, such as DocBook, XHTML, or even RDDL. Using XHTML, the
description of the name element can be:
<div>
<h2>The <tt>name</tt> element</h2>
<p>This is the name of the character.</p>
<src:fragment id="name" xmlns="">
<rng:element name="name">
<rng:text/>
</rng:element>
</src:fragment>
</div>or, in the compact syntax:
<div>
<h2>The <tt>name</tt> element</h2>
<p>This is the name of the character.</p>
<src:fragment id="name" xmlns="">
element name { text }
</src:fragment>
</div>In the first snippet, the definition of the element is simple enough
that it doesn’t have to reference any other
patterns, but a definition can also make a reference to an
src:fragment element by using
src:fragref, as in:
<div>
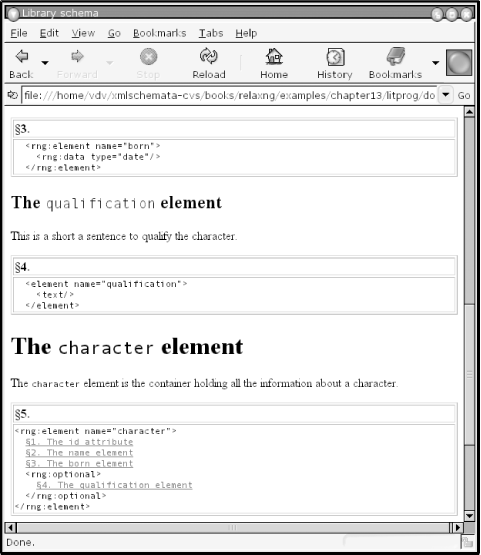
<h1>The <tt>character</tt> element</h1>
<p>The <tt>character</tt> element is the container
holding all the information about a character.</p>
<src:fragment id="character" xmlns="">
<rng:element name="character">
<src:fragref linkend="id"/>
<src:fragref linkend="name"/>
<src:fragref linkend="born"/>
<rng:optional>
<src:fragref linkend="qualification"/>
</rng:optional>
</rng:element>
</src:fragment>
</div>or, using the compact syntax:
<div>
<h1>The <tt>character</tt> element</h1>
<p>The <tt>character</tt> element is the container
holding all the information about a character.</p>
<src:fragment id="character" xmlns="">
element character {
<src:fragref linkend="id"/>,
<src:fragref linkend="name"/>,
<src:fragref linkend="born"/>,
<src:fragref linkend="qualification"/> ?
}
</src:fragment>
</div>From this literate programming document, XSLT transformation can produce two different outputs. The first one is the schema itself. Assuming that I’ve defined all the attributes and subelements of our character element, the generated schema is:
<?xml version="1.0" encoding="utf-8"?>
<rng:grammar xmlns:rng="http://relaxng.org/ns/structure/1.0"
xmlns:src="http://nwalsh.com/xmlns/litprog/fragment"
datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<rng:start>
<rng:element name="character">
<rng:attribute name="id">
<rng:data type="id"
datatypeLibrary="http://relaxng.org/ns/compatibility/datatypes/1.0"/>
</rng:attribute>
<rng:element name="name">
<rng:text/>
</rng:element>
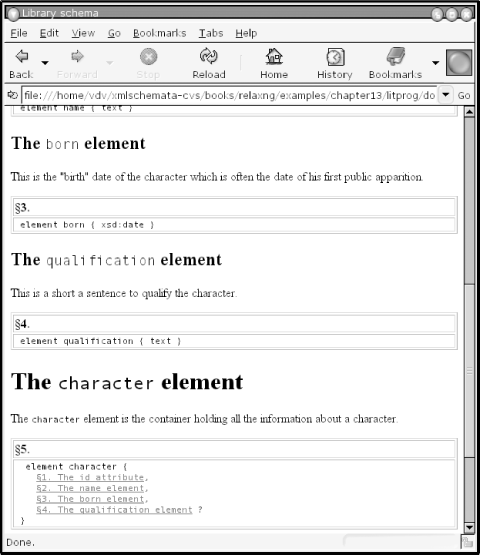
<rng:element name="born">
<rng:data type="date"/>
</rng:element>
<rng:optional>
<element name="qualification">
<text/>
</element>
</rng:optional>
</rng:element>
</rng:start>
</rng:grammar>or, converted to the compact syntax:
datatypes d = "http://relaxng.org/ns/compatibility/datatypes/1.0"
start=
element character {
attribute id { d:id },
element name { text },
element born { xsd:date },
element qualification { text } ?
}This is a pretty normal-looking schema. The thing to highlight is the
way it has been modularized. Up to now, we’ve been
using named patterns, a mechanism provided by RELAX NG, to split a
schema into small, manageable pieces. I could have done the same
thing in the last example, but this is another way to split the
schema. Now I can use the mechanisms provided by the literate
programming framework and define and combine fragments using
src:fragment and src:fragref
instead of the define and ref
elements from RELAX NG. By doing so, I can generate a monolithic
Russian-doll schema through a modular description of its elements and
attributes.
The second output from this literate programming document is the XHTML documentation, shown in Figure 14-1. The compact syntax is shown in Figure 14-2.
Adding Bells and Whistles for RDDL
RDDL can be read as plain XHTML by human beings in a standard web browser and by applications that use the semantic attributes of XLink to discover resources such as schemas and stylesheets.
RDDL documents can be generated from annotated RELAX NG schemas. When documenting XML vocabularies, RDDL can also generate schemas. It is very tempting to use the literate programming framework to produce RDDL documents. RDDL is extremely similar to XHTML, which makes this easier. I could use the DocBook litprog stylesheets right away, but I could also import them into stylesheets to facilitate the authoring of RDDL documents.
The main burden when writing RDDL documents is that the information
made available to the application needs to be repeated for human
readers (or vice versa). For instance, to publish a snippet of schema
describing the name element as an RDDL normative reference, I can
write this (note the mundane-result-prefixes
attributes, which the RDDL tools need to control various namespaces
introduced for RDDL):
<rddl:resource id="name-elt" xlink:type="simple"
xlink:arcrole="http://www.rddl.org/purposes#normative-reference"
xlink:role="http://www.w3.org/1999/xhtml"
xlink:title="The name element"
xlink:href="#name-elt">
<div class="resource">
<h2>The <tt>name</tt> element</h2>
<src:fragment id="name" xmlns=""
mundane-result-prefixes="cr xlink">
<rng:element name="name">
<rng:text/>
</rng:element>
</src:fragment>
</div>
</rddl:resource>This sample isn’t complicated, but there is some
repetition here. The content of the h2 element is
copied into xlink:title, and
xlink:href reuses the value of the
id attribute because the resource is local.
External resources have similar redundancies. When the RDDL document
is generated by an XSLT transformation, as is the case in literate
programming, it’s tempting to define shortcuts that
avoid these redundancies. I can then write:
<cr:resource id="name-elt"
role="http://www.w3.org/1999/xhtml"
arcrole="http://www.rddl.org/purposes#normative-reference">
<h2>The <tt>name</tt> element</h2>
<p>This is the name of the character.</p>
<src:fragment id="name" xmlns=""
mundane-result-prefixes="cr xlink">
<rng:element name="name">
<rng:text/>
</rng:element>
</src:fragment>
</cr:resource>Other features can easily be added, such as numbering the divisions, generating a table of contents, indexes of resources, and pretty printing code snippets. The resulting document is shown in Figure 14-3.
