
Users
Users are a terrible thing. Systems would be much better off with no users.
Obviously, I’m being somewhat tongue-in-cheek. Although users do present numerous risks to stability, they’re also the reason our systems exist. Yet the human users of a system have a knack for creative destruction. When your system is teetering on the brink of disaster like a car on a cliff in a movie, some user will be the seagull that lands on the hood. Down she goes! Human users have a gift for doing exactly the worst possible thing at the worst possible time.
Worse yet, other systems that call ours march remorselessly forward like an army of Terminators, utterly unsympathetic about how close we are to crashing.
Traffic
As traffic grows, it will eventually surpass your capacity. (If traffic isn’t growing, then you have other problems to worry about!) Then comes the biggest question: how does your system react to excessive demand?
“Capacity” is the maximum throughput your system can sustain under a given workload while maintaining acceptable performance. When a transaction takes too long to execute, it means that the demand on your system exceeds its capacity. Internal to your system, however, are some harder limits. Passing those limits creates cracks in the system, and cracks always propagate faster under stress.
If you are running in the cloud, then autoscaling is your friend. But beware! It’s not hard to run up a huge bill by autoscaling buggy applications.
Heap Memory
One such hard limit is memory available, particularly in interpreted or managed code languages. Take a look at the following figure. Excess traffic can stress the memory system in several ways. First and foremost, in web app back ends, every user has a session. Assuming you use memory-based sessions (see Off-Heap Memory, Off-Host Memory, for an alternative to in-memory sessions), the session stays resident in memory for a certain length of time after the last request from that user. Every additional user means more memory.
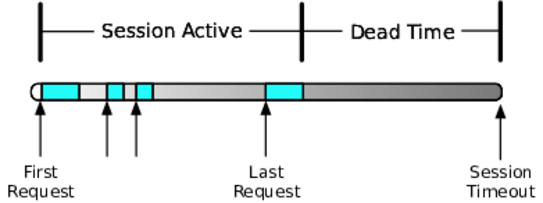
During that dead time, the session still occupies valuable memory. Every object you put into the session sits there in memory, tying up precious bytes that could be serving some other user.
When memory gets short, a large number of surprising things can happen. Probably the least offensive is throwing an out-of-memory exception at the user. If things are really bad, the logging system might not even be able to log the error. If no memory is available to create the log event, then nothing gets logged. (This, by the way, is a great argument for external monitoring in addition to log file scraping.) A supposedly recoverable low-memory situation will rapidly turn into a serious stability problem.
Your best bet is to keep as little in the in-memory session as possible. For example, it’s a bad idea to keep an entire set of search results in the session for pagination. It’s better if you requery the search engine for each new page of results. For every bit of data you put in the session, consider that it might never be used again. It could spend the next thirty minutes uselessly taking up memory and putting your system at risk.
It would be wonderful if there was a way to keep things in the session (therefore in memory) when memory is plentiful but automatically be more frugal when memory is tight. Good news! Most language runtimes let you do exactly that with weak references.[5] They’re called different things in different libraries, so look for System.WeakReference in C#, java.lang.ref.SoftReference in Java, weakref in Python, and so on. The basic idea is that a weak reference holds another object, called the payload, but only until the garbage collector needs to reclaim memory. When only soft references to the object are left (as shown in the following figure), it can be collected.
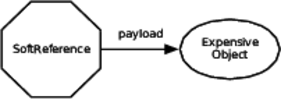
You construct a weak reference with the large or expensive object as the payload. The weak reference object actually is a bag of holding. It keeps the payload for later use.
| | MagicBean hugeExpensiveResult = ...; |
| | SoftReference ref = new SoftReference(hugeExpensiveResult); |
| | |
| | session.setAttribute(EXPENSIVE_BEAN_HOLDER, ref); |
This is not a transparent change. Accessors must be aware of the indirection. Think about using a third-party or open source caching library that uses weak references to reclaim memory.
What is the point of adding this level of indirection? When memory gets low, the garbage collector is allowed to reclaim any weakly reachable objects. In other words, if there are no hard references to the object, then the payload can be collected. The actual decision about when to reclaim softly reachable objects, how many of them to reclaim, and how many to spare is totally up to the garbage collector. You have to read your runtime’s docs very carefully, but usually the only guarantee is that weakly reachable objects will be reclaimed before an out-of-memory error occurs.
In other words, the garbage collector will take advantage of all the help you give it before it gives up. Be careful to note that it is the payload object that gets garbage-collected, not the weak reference itself. Since the garbage collector is allowed to harvest the payload at any time, callers must also be written to behave nicely when the payload is gone. Code that uses the payload object must be prepared to deal with a null. It can choose to recompute the expensive result, redirect the user to some other activity, or take any other protective action.
Weak references are a useful way to respond to changing memory conditions, but they do add complexity. When you can, it’s best to just keep things out of the session.
Off-Heap Memory, Off-Host Memory
Another effective way to deal with per-user memory is to farm it out to a different process. Instead of keeping it inside the heap—that is, inside the address space of your server’s process—move it out to some other process. Memcached is a great tool for this.[6] It’s essentially an in-memory key-value store that you can put on a different machine or spread across several machines.
Redis is another popular tool for moving memory out of your process.[7] It’s a fast “data structure server” that lives in a space between cache and database. Many systems use Redis to hold session data instead of keeping it in memory or in a relational database.
Any of these approaches exercise a trade-off between total addressable memory size and latency to access it. This notion of memory hierarchy is ranked by size and distance. Registers are fastest and closest to the CPU, followed by cache, local memory, disk, tape, and so on. On one hand, networks have gotten fast enough that “someone else’s memory” can be faster to access than local disk. Your application is better off making a remote call to get a value than reading it from storage. On the other hand, local memory is still faster than remote memory. There’s no one-size-fits-all answer.
Sockets
You may not spend much time thinking about the number of sockets on your server, but that’s another limit you can run into when traffic gets heavy. Every active request corresponds to an open socket. The operating system assigns inbound connections to an “ephemeral” port that represents the receiving side of the connection. If you look at the TCP packet format, you’ll see that a port number is 16 bits long. It can only go up to 65535. Different OSs use different port ranges for ephemeral sockets, but the IANA recommended range is 49152 to 65535. That gives your server the ability to have at most 16,383 connections open. But your machine is probably dedicated to your service rather than handling, say, user logins. So we can stretch that range to ports 1024--65535, for a maximum of 64,511 connections.
Now I’ll tell you that some servers are handling more than a million concurrent connections. Some people are pushing toward ten million connections on a single machine.
If there are only 64,511 ports available for connections, how can a server have a million connections? The secret is virtual IP addresses. The operating system binds additional IP addresses to the same network interface. Each IP address has its own range of port numbers, so we would need a total of 16 IP addresses to handle that many connections.
This is not a trivial thing to tackle. Your application will probably need some changes to listen on multiple IP addresses and handle connections across them all without starving any of the listen queues. A million connections also need a lot of kernel buffers. Plan to spend some time learning about your operating system’s TCP tuning parameters.
Closed Sockets
Not only can open sockets be a problem, but the ones you’ve already closed can bite you too. After your application code closes a socket, the TCP stack moves it through a couple of terminal states. One of them is the TIME_WAIT state. TIME_WAIT is a delay period before the socket can be reused for a new connection. It’s there as part of TCP’s defense against bogons.
No, really. Bogons. I’m not making this up.
A bogon is a wandering packet that got routed inefficiently and arrives late, possibly out of sequence, and after the connection is closed. If the socket were reused too quickly, then a bogon could arrive with the exact right combination of IP address, destination port number, and TCP sequence number to be accepted as legitimate data for the new connection. In essence a bit of data from the old connection would show up midstream in the new one.
Bogons are a real, though minor, problem on the Internet at large. Within your data center or cloud infrastructure, though, they are less likely to be an issue. You can turn the TIME_WAIT interval down to get those ports back into use ASAP.
Expensive to Serve
Some users are way more demanding than others. Ironically, these are usually the ones you want more of. For example, in a retail system, users who browse a couple of pages, maybe do a search, and then go away are both the bulk of users and the easiest to serve. Their content can usually be cached (however, see Use Caching, Carefully, for important cautions about caching). Serving their pages usually does not involve external integration points. You will likely do some personalization, maybe some clickstream tracking, and that’s about it.
But then there’s that user who actually wants to buy something. Unless you’ve licensed the one-click checkout patent, checkout probably takes four or five pages. That’s already as many pages as a typical user’s entire session. On top of that, checking out can involve several of those troublesome integration points: credit card authorization, sales tax calculation, address standardization, inventory lookups, and shipping. In fact, more buyers don’t just increase the stability risk for the front-end system, they can place back-end or downstream systems at risk too. (See Unbalanced Capacities.) Increasing the conversion rate might be good for the profit-and-loss statement, but it’s definitely hard on the systems.
There is no effective defense against expensive users. They are not a direct stability risk, but the increased stress they produce increases the likelihood of triggering cracks elsewhere in the system. Still, I don’t recommend measures to keep them off the system, since they are usually the ones who generate revenue. So, what should you do?
The best thing you can do about expensive users is test aggressively. Identify whatever your most expensive transactions are and double or triple the proportion of those transactions. If your retail system expects a 2 percent conversion rate (which is about standard for retailers), then your load tests should test for a 4, 6, or 10 percent conversion rate.
If a little is good, then a lot must be better, right? In other words, why not test for a 100 percent conversion rate? As a stability test, that’s not a bad idea. I wouldn’t use the results to plan capacity for regular production traffic, though. By definition, these are the most expensive transactions. Therefore, the average stress on the system is guaranteed to be less than what this test produces. Build the system to handle nothing but the most expensive transactions and you will spend ten times too much on hardware.
Unwanted Users
We would all sleep easier if the only users to worry about were the ones handing us their credit card numbers. In keeping with the general theme of “weird, bad things happen in the real world,” weird, bad users are definitely out there.
Some of them don’t mean to be bad. For example, I’ve seen badly configured proxy servers start requesting a user’s last URL over and over again. I was able to identify the user’s session by its cookie and then trace the session back to the registered customer. Logs showed that the user was legitimate. For some reason, fifteen minutes after the user’s last request, the request started reappearing in the logs. At first, these requests were coming in every thirty seconds. They kept accelerating, though. Ten minutes later, we were getting four or five requests every second. These requests had the user’s identifying cookie but not his session cookie. So each request was creating a new session. It strongly resembled a DDoS attack, except that it came from one particular proxy server in one location.
Once again, we see that sessions are the Achilles’ heel of web applications. Want to bring down nearly any dynamic web application? Pick a deep link from the site and start requesting it without sending cookies. Don’t even wait for the response; just drop the socket connection as soon as you’ve sent the request. Web servers never tell the application servers that the end user stopped listening for an answer. The application server just keeps on processing the request. It sends the response back to the web server, which funnels it into the bit bucket. In the meantime, the 100 bytes of the HTTP request cause the application server to create a session (which may consume several kilobytes of memory in the application server). Even a desktop machine on a broadband connection can generate hundreds of thousands of sessions on the application servers.
In extreme cases, such as the flood of sessions originating from the single location, you can run into problems worse than just heavy memory consumption. In our case, the business users wanted to know how often their most loyal customers came back. The developers wrote a little interceptor that would update the “last login” time whenever a user’s profile got loaded into memory from the database. During these session floods, though, the request presented a user ID cookie but no session cookie. That meant each request was treated like a new login, loading the profile from the database and attempting to update the “last login” time.
Imagine 100,000 transactions all trying to update the same row of the same table in the same database. Somebody is bound to get deadlocked. Once a single transaction with a lock on the user’s profile gets hung (because of the need for a connection from a different resource pool), all the other database transactions on that row get blocked. Pretty soon, every single request-handling thread gets used up with these bogus logins. As soon as that happens, the site is down.
So one group of bad users just blunder around leaving disaster in their wake. More crafty sorts, however, deliberately do abnormal things that just happen to have undesirable effects. The first group isn’t deliberately malicious; they do damage inadvertently. This next group belongs in its own category.
An entire parasitic industry exists by consuming resources from other companies’ websites. Collectively known as competitive intelligence companies, these outfits leech data out of your system one web page at a time.
These companies will argue that their service is no different from a grocery store sending someone into a competing store with a list and a clipboard. There is a big difference, though. Given the rate that they can request pages, it’s more like sending a battalion of people into the store with clipboards. They would crowd out the aisles so legitimate shoppers could not get in.
Worse yet, these rapid-fire screen scrapers do not honor session cookies, so if you are not using URL rewriting to track sessions, each new page request will create a new session. Like a flash mob, pretty soon the capacity problem will turn into a stability problem. The battalion of price checkers could actually knock down the store.
Keeping out legitimate robots is fairly easy through the use of the robots.txt file.[8] The robot has to ask for the file and choose to respect your wishes. It’s a social convention—not even a standard—and definitely not enforceable. Some sites also choose to redirect robots and spiders, based on the user-agent header. In the best cases, these agents get redirected to a static copy of the product catalog, or the site generates pages without prices. (The idea is to be searchable by the big search engines but not reveal pricing. That way, you can personalize the prices, run trial offers, partition the country or the audience to conduct market tests, and so on.) In the worst case, the site sends the agent into a dead end.
So the robots most likely to respect robots.txt are the ones that might actually generate traffic (and revenue) for you, while the leeches ignore it completely.
I’ve seen only two approaches work.
The first is technical. Once you identify a screen scraper, block it from your network. If you’re using a content distribution network such as Akamai, it can provide this service for you. Otherwise, you can do it at the outer firewalls. Some of the leeches are honest. Their requests come from legitimate IP addresses with real reverse DNS entries. ARIN is your friend here.[9] Blocking the honest ones is easy. Others stealthily mask their source addresses or make requests from dozens of different addresses. Some of these even go so far as to change their user-agent strings around from one request to the next. (When a single IP address claims to be running Internet Explorer on Windows, Opera on Mac, and Firefox on Linux in the same five-minute window, something is up. Sure, it could be an ISP-level supersquid or somebody running a whole bunch of virtual emulators. When these requests are sequentially spidering an entire product category, it’s more likely to be a screen scraper.) You may end up blocking quite a few subnets, so it’s a good idea to periodically expire old blocks to keep your firewalls performing well. This is a form of Circuit Breaker.
The second approach is legal. Write some terms of use for your site that say users can view content only for personal or noncommercial purposes. Then, when the screen scrapers start hitting your site, sic the lawyers on them. (Obviously, this requires enough legal firepower to threaten them effectively.) Neither of these is a permanent solution. Consider it pest control—once you stop, the infestation will resume.
Malicious Users
The final group of undesirable users are the truly malicious. These bottom-feeding mouth breathers just live to kill your baby. Nothing excites them more than destroying the very thing you’ve put blood, sweat, and tears into building. These were the kids who always got their sand castles kicked over when they were little. That deep-seated bitterness compels them to do the same thing to others that was done to them.
Truly talented crackers who can analyze your defenses, develop a customized attack, and infiltrate your systems without being spotted are blessedly rare. This is the so-called “advanced persistent threat.” Once you are targeted by such an entity, you will almost certainly be breached. Consult a serious reference on security for help with this. I cannot offer you sound advice beyond that. This gets into deep waters with respect to law enforcement and forensic evidence.
The overwhelming majority of malicious users are known as “script kiddies.” Don’t let the diminutive name fool you. Script kiddies are dangerous because of their sheer numbers. Although the odds are low that you will be targeted by a true cracker, your systems are probably being probed by script kiddies right now.
This book is not about information security or online warfare. A robust approach to defense and deterrence is beyond my scope. I will restrict my discussion to the intersection of security and stability as it pertains to system and software architecture. The primary risk to stability is the now-classic distributed denial-of-service (DDoS) attack. The attacker causes many computers, widely distributed across the Net, to start generating load on your site. The load typically comes from a botnet. Botnet hosts are usually compromised Windows PCs, but with the Internet of Things taking off, we can expect to see that population diversify to include thermostats and refrigerators. A daemon on the compromised computer polls some control channel like IRC or even customized DNS queries, through which the botnet master issues commands. Botnets are now big business in the dark Net, with pay-as-you-go service as sophisticated as any cloud.
Nearly all attacks vector in against the applications rather than the network gear. These force you to saturate your own outbound bandwidth, denying service to legitimate users and racking up huge bandwidth charges.
As you have seen before, session management is the most vulnerable point of a server-side web application. Application servers are particularly fragile when hit with a DDoS, so saturating the bandwidth might not even be the worst issue you have to deal with. A specialized Circuit Breaker can help to limit the damage done by any particular host. This also helps protect you from the accidental traffic floods, too.
Network vendors all have products that detect and mitigate DDoS attacks. Proper configuring and monitoring of these products is essential. It’s best to run these in “learning” or “baseline” mode for at least a month to understand what your normal, cyclic traffic patterns are.
Remember This
- Users consume memory.
-
Each user’s session requires some memory. Minimize that memory to improve your capacity. Use a session only for caching so you can purge the session’s contents if memory gets tight.
- Users do weird, random things.
-
Users in the real world do things that you won’t predict (or sometimes understand). If there’s a weak spot in your application, they’ll find it through sheer numbers. Test scripts are useful for functional testing but too predictable for stability testing. Look into fuzzing toolkits, property-based testing, or simulation testing.
- Malicious users are out there.
-
Become intimate with your network design; it should help avert attacks. Make sure your systems are easy to patch—you’ll be doing a lot of it. Keep your frameworks up-to-date, and keep yourself educated.
- Users will gang up on you.
-
Sometimes they come in really, really big mobs. When Taylor Swift tweets about your site, she’s basically pointing a sword at your servers and crying, “Release the legions!” Large mobs can trigger hangs, deadlocks, and obscure race conditions. Run special stress tests to hammer deep links or hot URLs.