
CHAPTER 1
Informational Patterns
1.1 INTRODUCTION
The Informational Patterns identified here are loosely categorized as those that serve information-sharing and organizational purposes. The Information Resource Pattern itself really needs no motivation. It has an established reference implementation called the World Wide Web. The logically named, interlinked HTML documents became the way of sharing information with collaborators, partners, clients, and the general public. As we grew discontented with static documents, we found ways to make them dynamic and to reflect the contents of our data stores in user-friendly and navigable ways. This in turn fueled a hunger for zero-installation, dynamic systems. Web sites became web applications.
From there, we started to consider longer-term and more flexible ways of organizing our information. The REpresentational State Transfer (REST) architectural style got us to think about expanding our world view of resources to include non-document sources. Resource identifiers were applied to arbitrary partitions of information spaces. We needed to think about how to organize collections of information resources in meaningful and reusable ways. We eventually pursued full-blown Webs of Data; interlinked and interoperable. We needed to name not only our entities, but also the relationships that connected them. As consumers of these resources, we wanted a greater say in defining what was important to us. We wanted to be able to share what we valued with those we valued, with the same ease as any other location on the Web.
The shifts in thinking that brought us these technologies were crucial but subtle. They were so subtle that we failed to notice that the World Wide aspects of the Web did not preclude it from being equally applicable in smaller environments such as the Enterprise. After a decade or more of service-only thinking, we were ready to adopt the resource abstractions as a superset of the documents, data, services, and concepts that comprised our business.
1.2 INFORMATION RESOURCE
1.2.1 INTENT
The Information Resource Pattern is the basic building block of the Web. It provides an addressable, resolvable, relatively course-grained piece of information. It should generally have a stable identifier associated with it and optionally support content negotiation, updates, and deletions.

Figure 1.1: Basic Information Resource Pattern.
1.2.2 MOTIVATION
The main feature of the Information Resource Pattern is the use of logical names to identify them. These names serve the dual purpose of identification and manipulation. We are using the name as an identifier in global context as well as name as a handle with which to interact with the information resource. The logical identifier isolates us from implementation details. It keeps us from thinking about code or even services. We are talking about the information itself. This approach elevates information to its rightful place as the leading component of the systems we build. We give identity to the things we care about and we ask for it through these names. We do not need to write a query or invoke a separate service to retrieve the thing we seek.
On the public Web, we recognize the ability to refer to a specific document:
http://bosatsu.net/index.html.
We can think beyond documents, however. Whatever domain we work in, we can imagine translating the data elements we care about into named resources:
http://example.com/account/user/jsmith,
http://example.com/employee/id/12345,
http://example.com/order/id/101-276-32, or
http://example.com/product/id/upc/800314900528.
These names represent good, long-lived, stable identifiers for these disparate domains. A reference to one of these resources today could still be valid a year from now—or ten years from now. The reason for this is because we also lose any coupling to how the information is produced. We do not know what, or even who, is producing the result. Honestly, we do not care. As long as something is still responding to the requests, we as clients are in good shape.
The separation of the name of the thing from the production process is only part of the story, however. The shape of the information is also free to change based upon the context of the request. Developers, business analysts, accounting departments, and end users may all lay claim to a preferred form for the information. This is as it should be. A development-oriented format like XML or JSON is useless to someone who wants to look at it in a spreadsheet or in a browser.
The separation of the name from the form does not require a new identity. We can turn the request into a negotiated conversation and, where possible, satisfy the needs of disparate consumers from a single location. Avoiding data extraction, transformation, and loading (ETL)1 steps reduces the burden of having multiple copies of our information repositories. We can achieve the goals of a Master Data Management2 solution while simultaneously avoiding the unnecessary limitations of a prescribed format.
If we decide to update the information, we can send a new copy back to the location from where we got it. Again, no separate service or software is required on our part as long as the request is handled. The general mechanism of pushing and pulling on information resources is generalizable and somewhat universally applicable. We quickly recognize that, as consumers or producers of information, we do not need to come up with separate ways of handling the information types we care about. It can all basically work the same way. Just like the Web does.
We ignore many details with this generalization, but we will address them separately in other sections. The main benefits we get from this pattern are loose-coupling, scalability, and predictability.
1.2.3 EXAMPLE
The Web itself is the single best example of the Information Resource Pattern we have. We generally understand how and why it grows and evolves over time, but we tend to sell the pattern short. People draw distinctions between the public Web and what happens behind firewalls. They see artificial boundaries between sharing documents and sharing data.
Architectural styles such as the REpresentational State Transfer (REST) broaden the applicability of the pattern by defining strategies for sharing information in scalable, flexible, loosely coupled ways. We use stable, HTTP identifiers to define the resources. We manipulate them via HTTP verbs. We extend the architecture so that it supports new shapes for the information with content negotiation.
In the REST architectural style, the body of what is returned for an information resource should be a self-describing, hypermedia message that yields the affordances available to the client. These include links for the resource in alternate forms, the discovery of links to manipulate the resource further, or means to find related resources. The abstraction remains the information resource, however. This can be a pure abstraction over the domains reflected to minimize the visibility by the client into actual production considerations.
A common problem when developers first attempt to produce REST APIs is to think of an information resource as equivalent to a domain object. They employ simple conversions tools to emit XML or JSON serializations of the object structure for the representation. Perhaps it is non-intuitive, but what is easy for the developer is often bad for the API. The resource is not a domain object. By that, we mean that the representation of the resource should not be tightly bound to an existing domain model. The reason for this is that we want stability and predictability in our APIs. Changes to the domain model will automatically flow through to changes in the serialization. When that acts as your API, your clients will break. This is the opposite of what we want. Instead, we need to pick a form that represents the information resource without being tightly coupled to how it is stored or produced. This is the “R” in REST’s REpresentation State Transfer.
A first attempt at this might look something like the following.3 To retrieve an account from http://example.com/account/id/12345, the client would issue an HTTP GET request to that URL:
![]()
and the server might respond with a language and platform-independent representation of an account:

With an advertised MIME type of application/xml, there is no reason for a client to know that this is an account, or what to do with it. Certainly a programmer could write the client to know to treat it like an account. It expects an association between the URL http://example.com/account/id/12345 and an XML representation of the account. Again, this seems like a minor thing but it absolutely flies in the face of how the Web works. When you point your browser at any random website, it does not “know” anything. It issues a standard, semantically constrained verb, called GET, to a named element and responds to what comes back. “Oh, an HTML document! I know how to parse that.” or “Oh, a plain text file, I know how to display that.” It is reactive. It does not know. Knowledge is a form of coupling. If the server changes what it returns, the client breaks. The Web would never have worked like that.
Now, there is not much a browser can do with a “text/plain” file but display it. An HTML document on the other hand is filled with affordances. This is a design term for something that allows you to achieve a goal. Discovering an image allows you to see it in the current document. Discovering a link allows you to visit another document. Everything that the Web allows us to do is a function of the affordances presented to us (e.g., login, submit queries, buy stuff, check headlines, play games, chat). These are not presented in domain-specific ways. They are presented as options for us to choose in the body of a standard representation.
Strict REST conformance requires representations to be self-describing hypermedia messages. The client does not know what it is going to get, it reacts to what is returned. It knows how to parse standard types. And from there, it discovers what options to present to the user (if there is one).4 While there are definitely reusable hypermedia formats (HTML, Atom, SVG, VoiceXML), there are currently no standards-based, general-purpose hypermedia formats5 for representing arbitrary informational content. Some Restafarians advocate the use of HTML for even non-presentation purposes, but that is not a widely supported position.
To counter this current gap, many pragmatic members of the community advocate the creation of custom MIME types. While it is not ideal, it is a way to document a representation format. Rather than identifying your account representation as application/xml, you might define a new format and call it application/vnd-example-account+XML. This format is simply a convention. The application/vnd part of the name indicates that it is for a specific custom use. The example segment identifies your organization (e.g., we are assuming a domain name of example.com for most of our examples). The account portion identifies the resource within your domain and the +XML gives you notice that it is an XML serialization. The same custom type in JSON might be application/vnd-example-account+JSON. You are encouraged to register your custom names with the Internet Assigned Numbers Authority (IANA),6 but there is nothing to force you to do so.
The media type should be designed to support hypermedia links. This should identify the resource itself, as well as its related resources. Clients will be able to “follow their noses” through your hypermedia representations. In the following example, we can find our way back to the account resource itself (useful if we did not fetch it initially but were given the representation as part of an orchestration), its recent orders, as well as individual orders.

![]()
your client knows how to handle this type, assuming you have added the capability to your application. In this sense, your client applications become more like browsers. They react to what they are given. They know how to handle certain types of representations. And, they find everything they need in the bodies of what is returned. There is no out-of-band communication being used to tell it what to do. For a larger discussion on hypermedia and representation design, please see Amundsen [2011] and Richardson [2013].
The HTTP verbs give us the ability to interact with resources directly. As we have seen, we can retrieve a resource with the GET verb. We update resources with POST, PUT and PATCH, depending upon the nature of the update. We can remove resources by issuing DELETE requests. We can discover metadata about a resource with the HEAD method. We can discover what we are allowed to do to a resource with the OPTIONS method. The verbs are classified based upon whether the requests associated with them can be repeated. As a non-destructive, safe, read-only request, there should be no problem issuing multiple GETs. This is important because, in the face of potential temporary network failure, we do not want the HTTP client to give up and create an application level error. If it is able to retry the request, it should. This property is called idempotency and it is a key reason Restafarians get mad when you violate this principle.
A GET request that actually changes state (a violation committed by way too many developers who do not know or care what they are doing) messes up the potential for caching results and can have unexpected results if the request is bookmarked.7
PUTs and DELETEs are intended to be idempotent. PATCH can be made idempotent with the use of Etags and conditional processing. POST, as a mostly semantically meaningless method, is not. It is extremely useful for the resilience of your system to understand and correctly leverage idempotency where you can.
The response codes give us an indication of success or failure. “200 OK” means the request is successful. “204 No Content” is used to indicate that the request was successful but there is no other response. A “401 Unauthorized” means, without more information, you are not allowed to see the resource. A “403 Forbidden” means you are simply not allowed to see it.
The main thing to remember is that none of these identifiers, verbs, or response codes are specific to a particular domain or application. The Web architecture has a Uniform Interface. Your browser is unaware of whether you are checking headlines or chatting on a forum. It all works the same way. Our goal in using the Information Resource Pattern is to make the various aspects of our systems also work the same way. As we have discussed above, particular types may offer different capabilities or affordances, but they all generally function alike.
Finally, not everyone will want an XML serialization of the accounts, orders, customers, or whatever else we are talking about. We also want to support content negotiation at the resource level to allow people to ask for information in the shape that they want it. This alternate form will still be served from the same location. We do not need to break existing clients to support new formats. We do not need to support all of the formats at once. We can incrementally add capabilities as they are requested, without having to export the data and serve it up from somewhere else in another form.
The HTTP GET request allows a client to specify a desired representation type:

Here the client is expressing a preference for the JSON form of our accounts, but indicates that it will also accept the XML form if we are unable to satisfy its first choice. The most important concept here is that the same name, http://example.com/account/id/12345, can be represented in multiple ways. Unfortunately, HTML does not support the Read Control (CR) HFactor,8 which means it cannot use content negotiation natively. Instead, it would have to rely on a JavaScript invocation of XMLHttpRequest:9
![]()
Traditionally, developers use suffixes to trigger this behavior. For the XML form, they might publish http://example.com/account/id/12345.xml. For JSON, http://example.com/account/id/12345.json. There is fundamentally nothing wrong with this approach, but it can make it more difficult for systems that your client interacts with (i.e., as part of an orchestration across resources) to negotiate the resource into a different representation. The other issue here at a larger resource-oriented level is that you are forking the identity of the resource. Every new suffix stands for a new resource. Any metadata captured about this resource with something like the Resource Description Framework (RDF) would need to be linked to all of the forms. There are ways of managing this, we just end up working harder than we need to. If possible, you should consider using the purely logical identifier not bound to a particular type, and content negotiate as needed.
We are alerted to one final problem with this approach by Allamaraju [2010]. If we are going to vary the response type for the same identifier based upon Accept headers, we need to indicate that in our response. We need to include a Vary response header to indicate that intermediate proxies should identify resources by compound keys involving both the name and the MIME type. Otherwise, they might accidentally return the wrong type to a client, thinking they are asking for what has already been cached because they use the same name.
1.2.4 CONSEQUENCES
Any abstraction has a cost. The choice of adopting an Information Resource Pattern may have implications involving performance, network traffic, and security. TCP/IP is a connection-oriented protocol that is expensive to establish in the face of high-speed requests and transactions. Advances in protocols such as SPDY10 and HTTP 2.011 are attempting to mediate these issues by reusing the TCP/IP connection for long periods in order to amortize the set-up cost over more interactions.
Beyond the performance issue, the purity of the abstraction may hide the complexity of interactions between multiple backend systems. State change notifications and transactional boundaries may not fit as cleanly into the abstraction. This pattern requires stateless interaction, which may be an issue depending on the nature of the clients that are using it.
From the client’s perspective, the Information Resource Pattern pushes a significant amount of complexity to it. The server is free to support various representation forms (or not), so the client may have to do the integration between resources to merge multiple XML schemas, JSON, and other data.
See also: Collection Resource (1.3), Guard (2.2), Gateway (3.2)
1.3 COLLECTION RESOURCE

Figure 1.2: Collection Resource Pattern.
1.3.1 INTENT
The Collection Resource Pattern is a form of the Information Resource Pattern (1.2) that allows us to refer to sets of resources based upon arbitrary partitions of the information spaces we care about. To keep client resources from having to care about server-specific details, these resources should provide the mechanism for relationship discovery and pagination across the collections.
1.3.2 MOTIVATION
In Section 1.2, we discovered the benefit of adopting the Information Resource Pattern for specific pieces of information. Now, we would like to expand our expressive capacity to talk about collections of these resources. A useful way to think about these is as sets and members of sets. We would like to be able to give names to whatever sets make sense to our domain. Consider a commerce application that deals with accounts, products, promotions, etc. Each one of these general categories can be thought of as the set of all entities of that type. Because we are dealing with logically named resources, we can imagine defining:
http://example.com/product, and
The choice of whether to use plural terms to refer to the sets is likely to be subjective, but we will use the singular form, and understand that we are identifying a potentially infinite set of resources. We are not yet worrying about the practicality of such large sets, we are simply creating identifiers.
Within an individual space, we might like to partition it along arbitrary boundaries. We might like to refer to the set of all new accounts, the best accounts, the overdue accounts, etc. As we are breaking them up on a status partition, it makes sense to introduce that notion into our identifiers:
http://example.com/account/status/new,
http://example.com/account/status/top, and
http://example.com/account/status/overdue.
These partitions make sense, as does giving them identifiers that behave like our singular information resources. These identifiers will map to a REST service endpoint that will translate the request into a backend query. As consumers of this information, we do not care what kind of data store is being queried nor how it happens. All we care about is giving meaningful business concepts stable identifiers and being able to resolve them.
The resolution process works like any resource request. An HTTP GET request to the identifier returns a representation of the collection resource. The body of the response is mostly about providing linkage to the individual resources, however, it is important to think about how a client might use the resource. If the resource handler returned something such as the following:

then there is very little the client can do without resolving each of the individual resources. From a performance perspective, we are inducing an excessive number of roundtrips before anything can be displayed. You will learn to strike a balance between sending too much information in a representation payload and not sending enough.
A slightly more verbose representation:
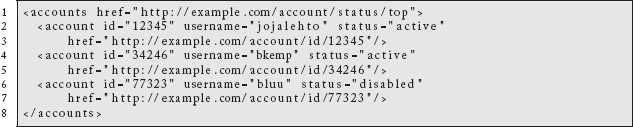
gives a client the ability to present some amount of information about the members in this particular collection without requiring a trip back to the server. The user might be presented with a sorted list, color-encoded by status, or whatever made sense.
1.3.3 EXAMPLE
While it might be tempting to build a custom MIME type for each resource collection we have, there are definitely existing choices we can use. Unless there is a specialized need that is not met by existing formats, it is a good idea to reuse established types. We could use the Atom Publishing Protocol,12 which has support for collections of resources. We could also use the Open Data Protocol (OData),13 which uses either JSON or Atom to create uniform APIs. Either of those would be good choices, but we will try a registered type that is slightly lighter weight.
Mike Amundsen14 designed the application/vnd.collection+json15 format to have a reusable collection type expressed in JSON. He has registered it with the IANA,16 so it is a legitimate and proper hypermedia format supporting six of his nine HFactors.17 In addition to supporting lists of resources, it also supports arbitrary key/value pairs for the resources, related links, query templates, and a discoverable mechanism for creating new item elements in the collection.
Here we reimagine our collection of top accounts as a application/vnd.collection+json representation:
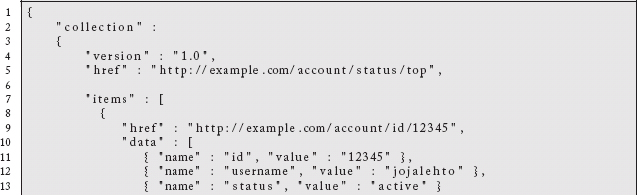

The URL for the collection itself is identified by the outer href key. From there we have the individual items of the collection. Note that we do not explicitly identify a type for the items, but that might not be an unreasonable extension. If there were related links for each item, they could be specified individually. We also have a related link for the collection. It points to a description of the various account classifications. It is here that we could imagine support for pagination over very large collections:

The clients will not have to know how to paginate across arbitrary collections, they will simply discover links related to the collection with a rel type of next or previous. The server still drives URL layout, which is what we want in a hypermedia system.
We do not have values for the template key because we do not explicitly add items to the top collection. They are implicitly added based on attributes on the account. If this were another type of collection, however, in the template section we could discover links, required key value pairs, and a prompt for collecting information from the user. The collection also can have an optional error key that lists related error conditions.
Hopefully it is no great leap to imagine different collections of resources using the same format. These could either be other collections of different resource types, or other partitions of the same resource type (e.g., overdue accounts, new accounts, etc.). The benefit of a reusable type is, obviously, that you only have to write the code to support it once. The format is extensible because we can add arbitrary key/value information for the collection or each individual item. Clients can discover the URLs in the body of the representation so that they remain uncoupled to a particular server layout.
1.3.4 CONSEQUENCES
There are not many substantial consequences, positive or negative, from the use of the Collection Resource Pattern for information resources. The ultimate trick is whether the level of detail returned per item is sufficient for the clients’ needs or not. It is important to strike an appropriate balance for the general case, but this may leave specific clients with either too much or too little data. Too much data is a waste of bandwidth, or perhaps an increased parsing load for large collections. Too little data is probably the more serious issue. As we identified with accounts in Section 1.3.2, if we just returned links for each account, any meaningful use of the data will require expensive network GET requests for each element. That is still true when using a standard format such as application/vnd.collection+json. If there are required attributes on each item that are not conveyed through the key/value capabilities, a client will have to fetch the individual resources to get what it needs. That would most likely be prohibitively expensive and generally represent a mismatch in representation. It may be worth establishing a separate URL endpoint with a more detailed view of the item data to solve the problem. Fortunately, we could do so without inventing a new type, just returning more resource state per item.
See also: Information Resource (1.2)
1.4 LINKED DATA

Figure 1.3: Linked Data Pattern.
1.4.1 INTENT
The Linked Data Pattern is an approach to exposing data sets with network-friendly technologies. The entities and their relationships are all given identifiers that can be resolved and explored. It also bridges the worlds of network addressability and non-network addressability. Resources that do not directly reside in a machine-processable form are still useful as means of identifying people, places, concepts, or any term or relationship from a domain of interest. Once a data set is made available like this, it becomes possible to connect it to a variety of other data sets, including ones you do not control.
1.4.2 MOTIVATION
The progression we have seen between the two previous patterns was from exposing individual resources, through logical identifiers to collections of these resources. By taking advantage of embedded links and response headers we can imagine building an ecosystem of interrelated content for our organization. The account resources can link to the order resources, which in turn can connect to the product resources. This gives us the ability to follow our noses, use content negotiation to request the information in specific formats, get architectural separation from implementation details, increase the scale of requests horizontally, etc.
As we will discuss in the Gateway Pattern (2.3), this shifts much of the burden to the client. Even if there is consistency in the design of the various representations, it requires custom development to integrate one XML schema with another one, or to merge two separate JSON documents. Within an organization or the confines of a particular domain, there is sufficient value to go to the trouble of connecting these resources through custom object models or similar strategy. This absolutely limits the scale of integration though. There is simply not going to be enough economic motivation to do this too many times outside of well-understood and clearly useful collections of datasets.
And, yet, the Web is filled with information on a variety of topics that we would love to be able to connect. This is where linked data comes in. By embracing the infrastructure of the Web and a data model that is designed to accept input from other sources, we can minimize the economic disincentive and demonstrate the value of building Webs of interrelated data, not just documents.
Linked Data as a specific approach grew out of the Semantic Web activity and is usually framed upon its enabling standards such as URIs, the Resource Description Framework, SPARQL, and more.18 There are several public efforts afoot (we will discuss the main one below), but as an approach, it could just as easily provide value within an organization as well.
The idea can be summarized by the following four rules from Tim Berners-Lee:19
1. Use URIs as names for things.
2. Use HTTP URIs so that people can look up those names.
3. When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL).
4. Include links to other URIs so that they can discover more things.
The first rule is about identification and disambiguation using a standard naming scheme. The URI scheme defines an extensible format that can introduce new naming schemes in the future that will be parseable by the URI parsers of today. By standardizing the mechanism through which we identify things, we will be able to tell the difference between everything we care about, including our entities and our relationships. Primary keys and column names are useless outside of the context of the database. We would be unable to accept arbitrary information if we were concerned about collisions in our identifiers. Because we use globally unique schemes, we have the freedom be more accepting of third-party data sources.
The second rule helps reinforce the use of global HTTP identifiers by grounding them in domain name-controlled contexts. You cannot publish identifiers in my domains and vice versa. Additionally, HTTP identifiers are resolvable. The name functions as both an identifier and a handle. If I name an entity and use a resolvable identifier, then you must simply issue a GET request to learn more about it.
The third rule helps us move beyond more straightforward resources, such as documents and REST services, to include non-network-addressable concepts as well. Individuals, organizations, and terms for concepts in general are not to be found on the Web by resolving a protocol. We would like to be able to still learn about them, however, so following a link and discovering more information is a useful strategy.
We run into a conundrum here, though. How can we tell the difference between a URI reference to a concept and one to a document about that concept? Documents are expected to return 200 responses when you resolve them. How is a client to know that a resource is not network-addressable?
Without getting into the larger arguments, we have two main proposals. One is to use fragment identifiers when naming non-network-addressable URIs. By definition, these are not resolvable on their own. So, to refer to myself, I could use the URL http://example.com/person/brian#me while using http://example.com/person/brian to refer to a document about me.
A second approach is to use 303 See Also redirects to alert clients that a non-information resource has been requested. I use this approach with the identifier http://purl.org/net/bsletten.20 If you attempt to resolve that resource, you will be redirected to an RDF document that describes me. The redirection is the hint to the client to the general nature of the resource.
There are advocates and detractors of both approaches. The first provides hints in the URI itself and is useful for collections of terms that are not too large and can conveniently be bundled into a single file. The fragment identifier scheme is used more conventionally, however, to bookmark into named portions of documents such as http://example.com/story#chap03. A modern browser that resolved that document would probably move the viewport to show the third chapter if it were marked like this:

To opponents of the fragment identifier scheme, this is too useful of a tool to give up. Additionally, if the collection of terms and concepts is large, resolving the source document for a single non-information resource can be quite expensive. You get the entire thing even if you only wanted part of it.
The non-fragment identifier scheme works better for a large number of identifiers because each can redirect to its own document. You only download what you want. However, opponents of the 303 approach lament the constant roundtrip resolution process needed to resolve information resources. While there is nothing preventing a server from caching these kinds of redirects with Cache-Control and Expires headers browser support for the feature remains spotty at best.
Whichever naming approach you take, the third rule indicates that we want to learn more when we resolve our entity and relationship identifiers. Tell us about the thing we are asking about. What is it? What is it used for? Where can we find more information.
Finally, the fourth rule allows us to connect one resource to related resources using the same techniques. This keeps the linkage going from resource to resource and allows us to connect arbitrarily complicated webs of data. The fundamental data structure is a graph. We may never have the entire graph in a single location, but we can still resolve the pieces that we need, when we want to. Because the RDF graph model provides the logical structure that supports the Open World Assumption (OWA) and a series of standard serializations, we now have most of the basic pieces in place to share and consume information from any source that uses this form.21 SPARQL provides both a protocol for accessing the data on the server side, as well as standard query language for asking questions of arbitrarily complex graphs. We will discuss SPARQL more in the Named Query pattern (1.5) below.
With these tools and ideas, we can now imagine being able to describe and connect all of the different resources in our organization to each other and to external data sources. An account resource could link to an order resource that could connect to a product resource. If we came across a third-party source of reviews for this product and could request or produce RDF representations of those reviews, we can automatically connect them to our existing product data without writing custom software.
RDF is expressed as a series of facts or “triples”. A subject is connected to a value through a relationship called a predicate. The subject might be like a key in a database. The predicate is like a column name. The value is obviously like the value in a column for a row in a relational database. As we indicated above, the interesting thing about these facts is that we use URIs to identify the entities and the relationships. When we are talking about Linked Data, we will use HTTP-based identifiers.
If I wanted to express that I know Manu Sporny, I would need an identifier for myself, for Manu, and for the notion of “knowing someone.” I have already indicated that I use http://purl.org/net/bsletten for myself. There is a collection of RDF terms, classes, and relationships called Friend of a Friend (FOAF)22 that has a term called knows grounded in a resolvable HTTP identifier (http://xmlns.com/foaf/0.1/knows). If you try to resolve that term, you will be redirected to a document that describes the meaning behind these terms. Each identifier is expressed in a machine-processable way using RDF.
So, if I know that Manu’s URI is http://manu.sporny.org/about#manu,23 I could express that in an RDF serialization called N-Triples:
![]()
The graph representing that fact would conceptually look like this:

Figure 1.4: An RDF graph of one fact.
If I added the following facts about our names:

I now have three facts about the two of us. Notice that nothing has yet indicated that Manu also knows me. It is a directional relationship. We can engage more technology later to allow these kinds of statements to be assumed to go both directions so we do not have to say both facts. That is outside the scope of this discussion, however.
The new graph would look like this:

Figure 1.5: An RDF graph of three facts.
One of the standard formats for publishing RDF is called RDF/XML. These three facts serialized in that format would look like:
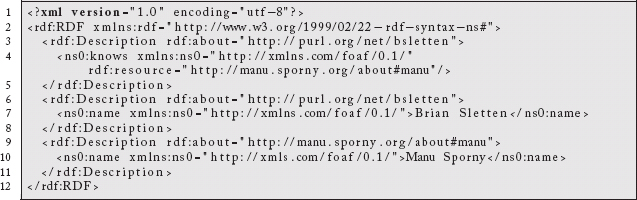
This is the same information as expressed in the N-Triples format, it has just been converted into XML. If I published that file on the Web, anyone could resolve it and discover these three facts. If they were unfamiliar with the identifiers for myself, Manu, or the FOAF knows and name relationships, they would be able to resolve those and learn what was intended by them as well.
If Manu published a similar file somewhere else and used the same names,24 someone could read that file as well. If both files were read into the same in-memory model or RDF-aware datastore (e.g., Stardog,25 Virtuoso,26 AllegroGraph,27) then the two graphs would connect automatically. This is the power of RDF. It seems more complicated than simple data formats like JSON and XML, but it also enables some tremendous data integration capabilities, largely for free.
When we apply the four rules from above with these data models, we can start to imagine what a Web of Data would look like. We have barely touched upon strategies for using these ideas more widely. For further guidance on building systems around the Linked Data principles, please see Heath and Bizer [2011].
1.4.3 EXAMPLE
There is a very public initiative called The Linked Data Project28 that applies these ideas to connect publicly available data sets. The people involved with that effort have been tremendously successful in applying these ideas at scale on the Web. They began in 2007 with a small number of data sets that were publicly available.
These data sets were managed by different organizations and available individually. The Geo-Names database is a Creative Commons-licensed collection of millions of place names from every country in the world.29 DBPedia30 provides structured representation of much of the human-curated content from Wikipedia. The idea behind connecting them was that the entities from one source could be linked to the other sources in ways that unified the collected facts about the resources. For example, facts about the subject of “Los Angeles, CA” from the GeoNames project could be connected to the facts provided DBPedia, the U.S. Census, etc. While it is easy to imagine connecting the same entities across the data sources, it is also possible to cross domains so that population information can be connected to a geographic region, its crime patterns, job opportunities, education rates, etc. If the integration costs were kept low, the value proposition would not have to be too strong to be worth it. Someone at some point would be interested in navigating that Web of Data.
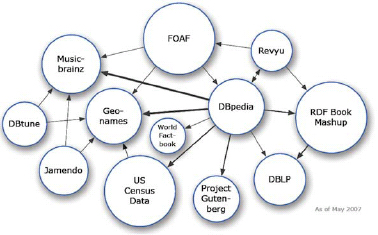
Figure 1.6: The original Linked Data Project data sets.
After an explosive few years, the project has grown to connect an unimaginable amount of data. When you consider how long it takes most organizations to connect a single new data source using conventional technologies, the success is even more pronounced.
Figure 1.7: Linked Data Project data sets after several years.
Not all of the data is “clean.” Some people may not care for the connections or may not trust a source of data. We are collectively building experience at managing these large data sets more carefully to improve the quality, indicate licensing grants, provenance chains, etc.
Tools such as PoolParty31 are starting to mix natural language processing and Linked Data to generate semi-automated taxonomies of domain-specific terms to help organize content. Services like OpenCalais32 are using entity extraction and Linked Data to identify references to people, places, organizations, etc. within documents to help structure them. This is only the beginning of how these connected data sources will provide value to us. The Linked Data Pattern helps guide us in the use of these techniques for our organizational content as well. We will no longer always be required to write custom software to do integration between data sources that are valuable to us.33
1.4.4 CONSEQUENCES
The extra complexity of modeling both the entities and the relationships as URIs has seemed too heavy for many people for years. When compared to the simplicity of a JSON document, or the speed of a SQL query, it is not entirely clear to developers that it is worth it. While it is legitimate to question the burden of a particular pattern or abstraction, the direct approach obscures all of the benefits that RDF and Linked Data provide.
JSON documents cannot generally be merged without writing custom software. Any RDF system can connect just about any other RDF whenever and however it wants to. This is not magic, we are just using global identifiers and a tolerant data model designed to share information. We will see examples of this elsewhere in the book. Additionally, SPARQL queries can run against information kept in arbitrary storage systems (e.g., documents, databases, etc.). As the tools have gotten better, the unnecessary complexity and slowness to process and query claims have become unconvincing.
Until recently, an RDF and SPARQL-based system was going to be mostly read-only, as there was no mechanism to update the results. Additionally, fans of hypermedia and REST bemoan the lack of hypermedia controls in RDF datasets. These issues are largely addressed via SPARQL 1.1,34 the Linked Data Platform Working Group,35 and the SPARQL 1.1 Graph Store HTTP Protocol.36
Despite all of these advances, it is still entirely reasonable to want the merged data sets in plain JSON for interaction with popular Web UI frameworks. There is nothing saying that you cannot re-project the data in one of these formats. Not everyone has to touch RDF and LinkedData, even if everyone can benefit from them. Finding the appropriate place to apply any technology is crucial to understanding its consequences.
See also: Information Resource (1.2), Named Query (1.5) and Curated URIs (3.3).
1.5 NAMED QUERY
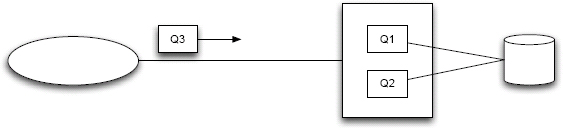
Figure 1.8: Named Query Pattern.
1.5.1 INTENT
The Named Query Pattern generalizes the idea of providing an identifier for a reusable query. The naming process might be explicit or implicit, based on ad hoc, but identifiable, query structures. By giving the query identity, it becomes reusable, shareable, cacheable, and perhaps a new data source.
1.5.2 MOTIVATION
In Sections 1.2 and 1.3, we learned about information resources and collections of information resources. These are generally sets of information uniquely identified by logical names managed by the producers of the information. It is easy to imagine the pre-defined set of resources being insufficient for a client’s needs over time. There may be new elements of interest, new ways to organize the content, or even just experimental activity that a user would like to be able to define, bookmark, and perhaps share with others. We would like to do this without requiring software engineers in the middle to capture the requirements, build an endpoint, and deploy the new information sources. That is often simply too slow of a process and is frequently not necessary.
Historically, we have managed this capability by allowing users to run arbitrary queries against our data stores, or extract information into spreadsheets for further manipulation and exploration. The down side of this approach is that it does not usually facilitate the sharing and reuse of this work. We e-mail documents with the results in them to others or push them to a Wiki or other document-management system. Both approaches generally lock up the information in ways that make them less useful.
If it were possible for clients to define queries into the data sources they were interested in and share the results directly, we would get the benefits of user-driven exploration and server-mediated information sharing. This is what the Named Query Pattern does for us.
The first approach to this pattern would be for the client to POST a query definition in some agreed-upon format to a known endpoint. If the named query endpoint is http://example.com/ query, a client might POST a query to it. The expression of the query will be language and usage specific, but we can imagine it being submitted either in the body of the request or as a URL-encoded form submission. Once the server accepts the request, it approves and creates the endpoint bound to it, and returns the following:
From this, the client learns the identity of the Named Query resource in the Location header in the response.37 This link can be bookmarked or shared. Anyone interested in the result can simply issue a GET request to fetch the results.
The other main approach for supporting this pattern is to have an endpoint that accepts a ?query=<URL-encoded-query-definition> parameter. This approach skips the server-created resource step and simply allows the client to specify the query as a URL. There is no resource discovery process, the identity of the requested URL is the resource to request.
1.5.3 EXAMPLE
The SPARQL Protocol38 is a great example of a standard supporting the Named Query Pattern. Any server that wants to support the protocol will provide a resource endpoint such as http://example.com/sparql. Clients have the ability to submit queries as:
• GET request and query parameter
• POST request and URL-encoded parameters
• POST request with query in the body
The SPARQL query language39 has many forms including SELECT, ASK, DESCRIBE and CONSTRUCT. The SELECT form is the most common form and it returns a result set based on matching a graph pattern and selecting bindings between variables and the selected row values.
The DBPedia40 site makes structured information extracted from Wikipedia available as RDF data. It supports a SPARQL Protocol endpoint (http://dbpedia.org/sparql) powered by the Virtuoso engine from OpenLink Software.41
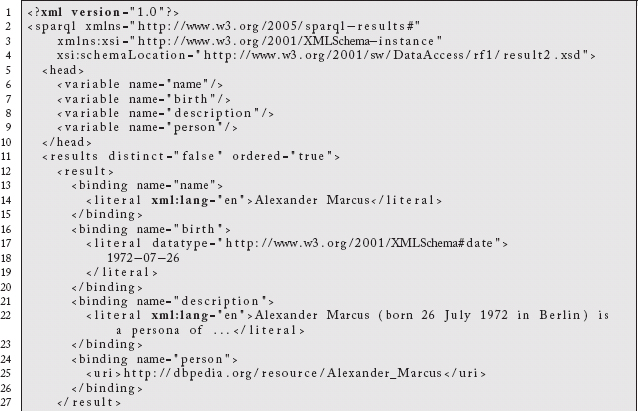
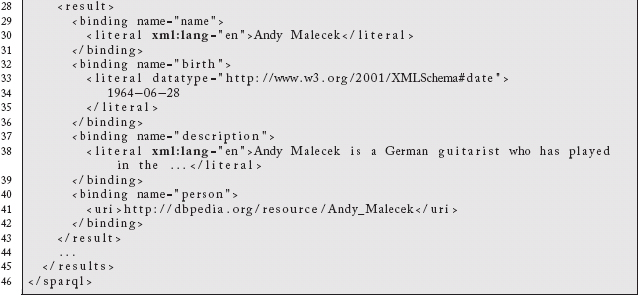
Consider the sample query that looks for German musicians who were born in Berlin:

This can be URL encoded into the following query:
http://dbpedia.org/sparql?query=PREFIX%20%3A%20%3Chttp%3A%2F%2Fdbpedia.org%2Fresource%2F%3E%0APREFIX%20rdfs%3A%20%3Chttp%3A%2F%2Fwww.w3.org%2F2000%2F01%2Frdf-schema%23%3E%0APREFIX%20dbo%3A%20%3Chttp%3A%2F%2Fdbpedia.org%2Fontology%2F%3E%0A%0ASELECT%20%3Fname%20%3Fbirth%20%3Fdescription%20%3Fperson%20WHERE%20%7B%0A%20%20%20%20%20%3Fperson%20dbo%3AbirthPlace%20%3ABerlin%20.%0A%20%20%20%20%20%3Fperson%20%3Chttp%3A%2F%2Fpurl.org%2Fdc%2Fterms%2Fsubject%3E%20%3Chttp%3A%2F%2Fdbpedia.org%2Fresource%2FCategory%3AGerman_musicians%3E%20.%0A%20%20%20%20%20%3Fperson%20dbo%3AbirthDate%20%3Fbirth%20.%0A%20%20%20%20%20%3Fperson%20foaf%3Aname%20%3Fname%20.%0A%20%20%20%20%20%3Fperson%20rdfs%3Acomment%20%3Fdescription%20.%0A%20%20%20%20%20FILTER%20(LANG(%3Fdescription)%20%3D%20’en’)%20.%0A%7D%0AORDER%20BY%20%3Fname.42
Which yields the following results:
One of the more compelling examples of this pattern is mixing the SPARQL protocol with the CONSTRUCT form of the query. Rather than returning the result set shown above, this form of query returns an actual graph.
If we have the following query:

We are defining the graph pattern in the WHERE clause like we do for the SELECT form. However, we are constructing a new graph (rather a sub-graph) of all facts we know about anyone who is a German Musician. When mixed with the SPARQL Protocol:
http://dbpedia.org/sparql?query=PREFIX%20%3A%20%3Chttp%3A%2F%2Fdbpedia.org%2Fresource%2F%3E%0APREFIX%20rdfs%3A%20%3Chttp%3A%2F%2Fwww.w3.org%2F2000%2F01%2Frdf-schema%23%3E%0APREFIX%20dbo%3A%20%3Chttp%3A%2F%2Fdbpedia.org%2Fontology%2F%3E%0A%0ACONSTRUCT%20%7B%20%3Fmusician%20%3Fp%20%3Fo%20%7D%20%0AWHERE%20%7B%20%3Fmusician%20%3Chttp%3A%2F%2Fpurl.org%2Fdc%2Fterms%2Fsubject%3E%20%3Chttp%3A%2F%2Fdbpedia.org%2Fresource%2FCategory%3AGerman_musicians%3E%3B%0A%3Fp%20%3Fo%0A%7D43
we have defined a subgraph extraction of DBPedia’s much larger data set. We could grab it using curl. By default, the endpoint returns the graph as Turtle.44 If we want it as RDF/XML, we can use content negotiation to get it:
![]()
This becomes a data source we can run another SPARQL query against. If we have this query in a file called sparql.rq:

we will get the name and a link to the thumbnail of any German Musician identified in our subgraph. If we use the Jena45 sparql command line tool to run against our data:
![]()
we will get a long list of names and URLs to thumbnail images.
If we wanted to extract the subgraph as N-Triples46 in one go, we could use the rdfcat command line tool:
![]()
to get a very long list of RDF triples, one per line.
Ultimately the Named Query we defined has become a reusable resource unto itself, which was the entire point of this pattern.
1.5.4 CONSEQUENCES
One positive consequence of this pattern is the ability to cache results of potentially arbitrary queries. The approach where the user submits a query and learns of the created resource is more cacheable because the server can give it a stable name. As long as the client bookmarks it or shares it, subsequent requests can be cached. If the client does not bookmark the new resource, it may be more difficult to find it after the fact. How would you define or describe it? The server could track queries submitted by each user and allow them to return to historical requests.
Associating the query with just the user, however, might complicate the ability to reuse the query across users who ask the same questions. If the query is put into a canonical form, the server might be able to reuse existing links when someone submits equivalent queries in the future.
The second approach of passing the query in as a parameter does not require a step to find a related URL to a resource. The downside is that, given the user definition of the query (and thus the URL), it is going to be less likely that the exact same query is asked by multiple users. Renaming or reordering query variables would result in a different URL, defeating the potential for caching between users. Subsequent requests to the exact same Named Query resource, due to bookmarks or shared links, can still be cached.
The major negative consequence of this pattern is the potential for clients to impose nontrivial computational burdens on your backend resources. Unconstrained and poorly written queries could potentially consume too much processing. If this is a problem, or you wish to avoid it being a problem, there is nothing that precludes the use of identity-based authentication and authorization schemes to control access and minimize the impact a client can have. Pay special attention to the mechanism by which clients are issuing requests to these resources. A complicated authentication scheme might be overkill. HTTP Basic Authentication over SSL may be sufficient to restrict access, but in a widely supported and low-effort approach.
Beyond simply restricting the Named Query Pattern to trusted and registered clients, you may wish to add support for velocity checking and resource use quotas per user. This would reduce the negative impact an individual client can have on the server by throttling access to the backend, based on cumulative use or request rate. The combination of the Resource Heatmap and Guard patterns can help apply these protections in declarative and reusable ways.
Another concern in allowing arbitrary queries to be submitted by clients is the risk of privilege escalation. Data sources of sensitive information usually have quite rigid access control policies in place, based upon the identity of the user. In supporting open-ended queries, you may want to avoid creating new accounts in your data stores for potentially one-off users. You might consider allowing system or channel-specific accounts to issue queries on behalf of the distributed users. If you have sensitive tables, columns, attributes, and values, you may wish to engage a declarative approach to filter or reject queries that attempt to access them from non-privileged accounts.
See also: Resource Heatmap (2.4) and Guard (2.2).
1http://en.wikipedia.org/wiki/Extract,_transform,_load
2http://en.wikipedia.org/wiki/Master_data_management
3We are ignoring any kind of security model at this point.
4Many people think that hypermedia affordances are only useful when there is a human involved. That is simply not true. These links are discoverable by software agents and bots as well.
5Although there are some proposals on the table, most notably HAL (http://stateless.co/hal_specification.html) and SIREN (https://github.com/kevinswiber/siren), we will revisit these formats in the discussion of the Workflow Pattern (3.5).
6http://www.iana.org/assignments/media-types
7It can also open you up to a form of attack called Cross Site Request Forgery (CSRF). See http://en.wikipedia.org/wiki/Cross-site_request_forgery for more information.
8See Amundsen [2011] for the definition of the various Hypermedia Factors (HFactors). We will discuss them more in the Workflow Pattern (3.5).
9This is also how you have to specify non-idempotent methods like DELETE and PUT when using HTML, because it lacks support for the Idempotent Links (LI) HFactor.
10http://en.wikipedia.org/wiki/SPDY
11http://en.wikipedia.org/wiki/HTTP_2.0
12http://tools.ietf.org/html/rfc5023
15http://amundsen.com/media-types/collection/
16http://www.iana.org/assignments/media-types/application/vnd.collection+json
17Again, see Amundsen [2011] for a discussion of Hypermedia Factors (HFactors).
18The idea of connected data obviously transcends these ideas. The Open Data Protocol (OData) initiative is another example. See http://odata.org.
19http://www.w3.org/DesignIssues/LinkedData.html
20We will discuss Persistent URLs (PURLs) permanent identifiers in the Curated URI Pattern section (3.3).
21We do not require that a data set be stored in RDF, just that, when resolved or queried, it can provide the information in RDF so that it is easily connected to other content.
23Note he uses a fragment identifier where I use a 303 redirect!
24It is not required that he use the same names, but it is certainly more convenient if he does.
26http://virtuoso.openlinksw.com
27http://www.franz.com/agraph/allegrograph/
33Amusingly, Watson, IBM’s Jeopardy-winning system, used information from the Linked Data project to beat its human competitors.(http://www-03.ibm.com/innovation/us/watson/)
34http://www.w3.org/TR/2013/REC-sparql11-query-20130321/
35http://www.w3.org/2012/ldp/wiki/Main_Page
36http://www.w3.org/TR/sparql11-http-rdf-update/
37The client should not generally need to be able to define the name of the endpoint, but that is certainly a variation you could support should the requirement arise.
38http://www.w3.org/TR/sparql11-protocol/
39http://www.w3.org/TR/rdf-sparql-query/
41http://virtuoso.openlinksw.com
42For your convenience, I have created a TinyURL (http://tinyurl.com) for the this long query: http://tinyurl.com/8hrq4y6.
43Also shortened for your convenience: http://tinyurl.com/ckho3gr.