


Understanding IBM Spectrum Scale RAID components
This chapter describe some basic components of IBM Spectrum Scale RAID for a better understanding of how IBM software RAID is implemented in IBM Spectrum Scale. IBM Spectrum Scale RAID is a software implementation of storage RAID technologies within IBM Spectrum Scale.
By using conventional dual-ported disk or solid-state drives in a JBOD configuration, IBM Spectrum Scale RAID implements sophisticated data placement and error-correction algorithms to deliver high levels of storage reliability, availability, and performance.
This chapter focuses on an essential subset of IBM Spectrum Scale RAID components only.
For more information about IBM Spectrum Scale RAID and its components, see the IBM Spectrum Scale RAID administration guide.
This chapter includes the following topics:
3.1 Recovery Group
A Recovery Group (RG) is a set of nodes that can access the same set of disks. Within an IBM Elastic Storage Server (ESS), two RGs are configured by default, with half of all physical disk drives assigned to each. Each ESS head node is responsible for one RG as primary server and as backup for the other RG.
All drives are SAS twin tailed, which are connected to both head nodes. The control of an RG can be failed or taken over by the other node during maintenance or failure situations.
3.2 RAID Code, VDisk, and declustered array
IBM Spectrum Scale RAID supports 2- and 3-fault-tolerant Reed-Solomon codes and 2-, 3-, and 4-way replication. These configurations detect and correct up to one, two, or three concurrent faults, depending on the chosen RAID level. The redundancy code layouts that IBM Spectrum Scale RAID supports are also known as tracks, and map to one block that is inside the IBM Spectrum Scale file system (see Figure 3-1).
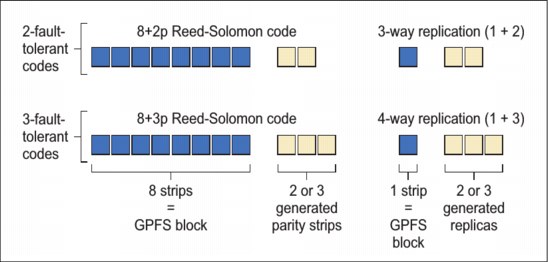
Figure 3-1 Fault-tolerant codes
The IBM Spectrum Scale RAID code allocates the needed space for the RAID tracks from specific sets of disk. This set of disk is called declustered array (DA). The number of physical disk drives (PDisks) that belong to the same DA is configurable in IBM Spectrum Scale RAID.
However, with models G(S,L)(1, 2, 4, 6), a fixed number of PDisks is available. Therefore, the IBM Spectrum Scale RAID deployment procedure reflects the possible choices according to your hardware model. A VDisk consists of many, wildly distributed RAID tracks. Therefore, IBM Spectrum Scale RAID allocates the RAID tracks for a VDisk within one DA.
An important positive effect of having a higher distribution that you get with a single DAis that it reduces the likeliness of your system being critically affected by multiple physical disk failures. The configuration scenario for a single DA is shown in Figure 3-2.
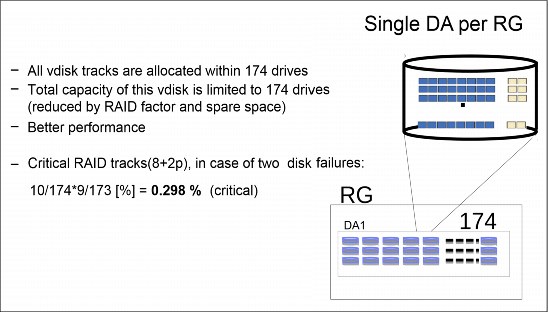
Figure 3-2 Single DA per RG
A VDisk is a logical construct of allocated space with a certain RAID level. The amount of space that is allocated for each full RAID track must be specified. This amount must reflect the block size for which this VDisk is used.
For example, for a targeted block size of 16 MB and a RAID level of 8+2p, a VDisk is created with a RAID segment size of approximately 2 MB. In this configuration, a full RAID track allocates approximately 10 x 2 MB.
IBM Spectrum Scale RAID code adds a check sum trailer and a version number to each write to protect against lost writes and silent data corruption. A regular NSD device is created on top of the VDisk, which contains the characteristics such as disk usage (dataOnly and MetaDataOnly), failure group, and storage pool.
An overview is shown in Figure 3-3.
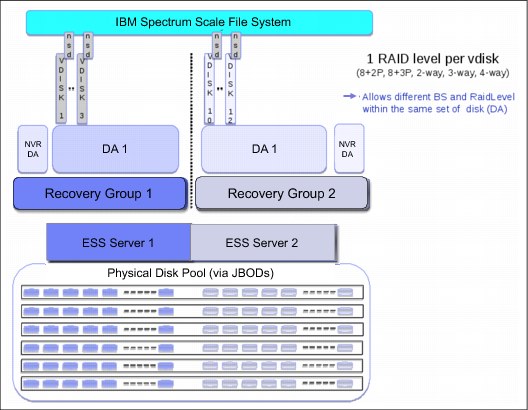
Figure 3-3 Overview IBM Spectrum Scale RAID configuration layers
3.3 IBM Spectrum Scale RAID: Fast writes (NVR)
The fast-write IO path is one of the major recent enhancements in IBM Spectrum Scale/ESS. It is essential for the performance improvement of small I/O writes. The clipping level of the I/Os is considered small and eligible for fast writes, so they are configurable.
3.3.1 Fundamental considerations
The number of IOPS in an ESS is limited by the number of physical drives. The highest bandwidth is achieved only if large block sizes (8 MB or 16 MB) are used, which leads to I/O sizes down to the PDisk of 1 MB or 2 MB, according to the chosen RAID level 8+[2, 3]p.
I/O sizes up to 2 MB can be handled by all NL-SAS disks types without breaking data into smaller fractions. The ESS default deployment procedure pre-configures the appropriate OS (RHEL) settings that adjust the needed values for the kernel and devices.
|
Note: It is not recommended to configure VDisk with n-WayReplication for block sizes that are larger than 2 MB.
For VDisks with 8+[2, 3]p RAID level, a minimum block size of 512 KB is required.
|
The use of a large block size for good throughput performance and high bandwidth on the one side can generate a lot of overhead for workloads with small random I/Os on the other side. Even worse is when I/O is done with DIRECT_IO /O_SYNC.
Writing smaller fractions of data than the block size to disk generates the need to read the corresponding VDisk track from disk into memory to modify the data and write back the VDisk track, which is known as read-modify-write (RMW).
With the introduction of so-called fast writes in IBM Spectrum Scale RAID, RMW can be avoided completely or at least significantly reduced to improve overall performance in environments with small I/O workloads or mixed workloads.
How fast writes (IBM Spectrum Scale RAID) work is shown in Figure 3-4.
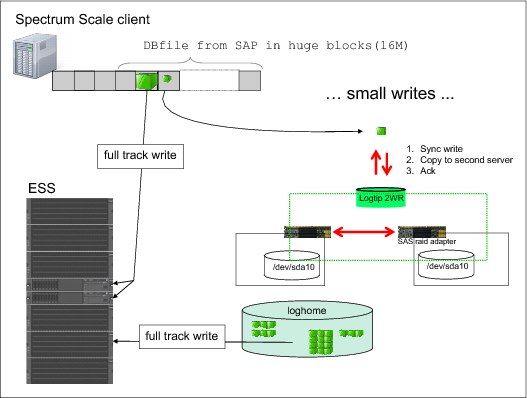
Figure 3-4 IBM Spectrum Scale RAID fast writes
As shown on the right side of Figure 3-4, small writes are written to the so-called logtip, which is a VDisk in a special DA that is named NVR. The logtip is a two-way replicated VDisk that is configured by default up on disk partitions from each node from its internal hard disk drives. The internal drives do not take the I/O. The key is that these devices are connected to RAID controller with a reasonable amount of NVRAM so that all the I/Os can be satisfied by the cache. IBM Spectrum Scale RAID then mirrors the inflight I/O across the two head nodes.
The I/Os from the clients can immediately be acknowledged as they are written successfully to the logtip. The information that is written by logtip is all kept in the cache (NVR of the SAS RAID adapter) of both head nodes. The IBM Spectrum Scale RAID codes then take the content from the logtip and write it into loghome, which is a four-way replicated VDisk in the DA1 to free the space in the logtip without the need to immediately write to the final VDisk tracks. By having the data safely staged down to disk, IBM Spectrum Scale RAID can hold them for a longer period.
By using this configuration, IBM Spectrum Scale RAID can collect and coalesce many small I/Os into bigger portions of data, intentionally trying to reach a full track write to physical disk. During normal operation, IBM Spectrum Scale RAID never reads from loghome (all data is still kept in the pagepool).
If the reserved space runs out of buffer, IBM Spectrum Scale RAID must flush down data to the final VDisk track if enough data is available to do full track writes or IBM Spectrum Scale RAID must fetch data first and do RMW to write down changes to disk. Therefore, the larger the loghome and pagepool are, the more they can store many small writes and the more likely RMW can be avoided completely. Also, a greater loghome means more allocated space among all the physical disk drives in the DA1, which improves performance.
|
Tip: A loghome VDisk with a greater size than the default of 20 GB can improve performance for small writes. Loghome size must be fixed during the initial installation and cannot be changed after other VDisks are created in the RG. Therefore, this configuration must be done during the initial deployment of the ESS. For more information about checking loghome size, see Appendix B, “Loghome configuration of an ESS building block” on page 35.
|
During normal operation, IBM Spectrum Scale RAID never reads from loghome, so all data must be kept in the pagepool. Therefore, having sufficient amount of pagepool depends on the total amount of memory, which is assembled in the I/O head nodes. Configuring the ESS models with 256 GB further improves the small write performance by having the chance to use larger pagepool sizes.
|
Tip: Configure your ESS models with 256 GB internal memory for better performance with small I/O workloads.
|
3.4 IBM Spectrum Scale RAID: Hot spare and disk failures
This section describes hot spare and disk failures in IBM Spectrum Scale RAID.
3.4.1 Hot spares in IBM Spectrum Scale RAID
In general, the IBM Spectrum Scale RAID distributes the logical capacity of the hot spare widely among all drives. Therefore, no physical reserved disks are used, and only its capacity is reserved. By default, the deployment procedure configures two theoretical hot spares every 58 disks. Depending on the overall configuration that is used (single or multiple DA), a specific amount of spare space is configured. The number of spares can be customized according to your needs.
To verify the number of hot spares, use the mmlsrecoverygroup command and review the spares column that is shown in Example 3-1. The first value is the number of spares. In our example, six spares are defined by using the rule of two spares every 58 drives. The second value is 89 and represents how many drives out of the 174 drives that would need to be lost before affecting the VDisk information. If you use every available capacity for VDisks, IBM Spectrum Scale RAID still reserves a capacity of six drives for spare, which means this space cannot be used for creating VDisks.
Example 3-1 Use the mmlsrecoverygroup command to review the spares settings
[root@p8n06 ~]# mmlsrecoverygroup ess02_L -L
declustered current allowable
recovery group arrays VDisks pdisks format version format version
----------------- ----------- ------ ------ -------------- -------------
ess02_L 3 7 179 4.2.0.1 4.2.2.0
declustered needs replace scrub background activity
array service VDisks pdisks spares threshold free space duration task progress priority
----------- ------- ------ ------ ------ --------- ---------- -------- -------------------------
SSD no 0 3 0,0 1 558 GiB 14 days inactive 0% low
NVR no 1 2 0,0 1 3632 MiB 14 days scrub 91% low
DA1 no 6 174 6,89 2 62 TiB 14 days scrub 71% low
3.4.2 Disk failure
This section uses an example that includes an 8+2p configured VDisk (a two-fault tolerant configuration scenario). A disk becomes less than perfectly usable for the following reasons:
•The administrator might remove it by using the mmdelpdisk command (unlikely).
•The IBM Spectrum Scale RAID disk hospital might find that the disk is not functioning and sets the systemDraining state flag.
In this scenario, one PDisk is becoming generically draining. The state of that DA changes from scrub to rebuild-1r because we are rebuilding something that has only one redundancy missing. Also, the state of the data VDisks changes from OK to 1/2-deg because they are degraded by missing one disk out of a fault tolerance of two disks.
The rebuild process moves slowly and often finishes in a day. However, the process can take as much as a few days, depending on how full the DA is, whether the data on the VDisks was ever written, how fast the CPU and the disks are, and the intensity of the foreground workload.
IBM Spectrum Scale RAID rebuilds the data onto spare space, which is distributed on all other disks. How much data depends on the VDisk (capacity utilization) and the RAID level. For our example (8+2P data VDisks), 174 disks are used (single DA in a GL6), of which one PDisk is draining.
Each track of the VDisks is spread over 10 disks (8+2p). Therefore, each track has a 10/174 chance of having a single fault. The amount of affected data per VDisk is 10/174 x VDisk size. According to the RAID level, only 8/10 really is data (the rest is parity) and only one of these segments must be rebuilt. For more information about this calculation, see Appendix C, “Calculating maximum capacity of a DA” on page 37. The total amount of data to rebuild in the DA is the sum over all VDisks, individually according to its RAID level (fault tolerance).
3.4.3 Second disk failure
The first disk failure that was described in this chapter is easy to explain and handle. It is rebuilt and then spare space is available in a fully utilized (space) DA with one fewer PDisks. Even if a second disk failure occurs, the data is still available by using Raid 8+2 for data protection.
The second disk failed soon after the first failure while the rebuilding process of the first failure was still in progress. Therefore, some tracks still had a single fault. Now, some tracks likely feature a double fault, while many more new affected tracks have a single fault.
Because we are using a two-fault tolerant code in our example, the system is in a critical state, with some tracks having two faults or having no redundancy at all. After the system becomes critical, the rebuild accomplishes two things: It rebuilds only those tracks that are critical, and it runs at much higher speeds.
The DA state in mmlsrecoverygroup shows as “rebuild-critical”, with a high priority and the state of the VDisks most likely is at first critical. As all the critical tracks are rebuilt, the state of the VDisks changes back to 1/2-deg, which indicates that they still have many single faults. Most likely, the critical part of rebuild will only take several minutes.
The amount of affected data can be estimated as shown in Figure 3-2 on page 13 and described in Appendix C, “Calculating maximum capacity of a DA” on page 37. The rest of rebuild happens in the same way as a single disk fault. The same rules apply for an 8+3p or n-Way replication. Dependent on the fault tolerance configured (e.g. 8+3p = Fault tolerance of 3 failed disks), the data is protected until all parity disks are used.
3.4.4 Spare space
If enough spare space is available, IBM Spectrum Scale RAID always rebuilds all VDisk tracks back to their intended fault toleration (RAID level) in case of physical disk failures. In addition, you can configure the system so that the available space in the DA is not used by VDisks. In that case, the rebuild process can use deallocated space to rebuild, allowing the deallocated DA data space to temporarily act as spare space.
However, you might be faced with running out of spare space because poor administration or delayed disk replacement can occur.
IBM Spectrum Scale RAID never reduces a healthy, perfect VDisk track and therefore lower its fault tolerance to repair a critical track. In this case, the rebuilding process stops working until a new, usable disk is available. When the replacement disk is inserted and activated (for example, by using the mmchcarrier or mmaddpdisk --replace commands), a disk’s worth of spare space is available and the rebuild process proceeds.
|
Note: A PDisk can be removed for replacement only. If all data was removed (including metadata), verify the status of the PDisk by using the mmlspdisk command and see that drained is set in the PDisk state. That is, you must wait until all the data from a draining disk is rebuilt elsewhere because any data that is still on the disk might be useful for finishing the rebuild.
Also, any PDisk in the dead state can be replaced immediately (even if data is allocated on them but is unreadable) because there is no expectation that dead disks can be readable again.
|
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.