
As a database administrator (DBA) or developer, one of your most important goals is to ensure that the query times are consistent with the service-level agreement (SLA) and are meeting user expectations. Along with other performance enhancement techniques, creating indexes for your queries on underlying tables is one of the most effective and common ways to achieve this objective.
The indexes of underlying relational tables are very similar in purpose to an index section at the back of a book. For example, instead of flipping through each page of the book, you use the index section at the back of the book to quickly find the particular information or topic within the book. In the same way, instead of scanning each individual row on the data page, SQL Server uses indexes to quickly find the data for the qualifying query. Therefore, by indexing an underlying relational table, you can significantly enhance the performance of your database.
Indexing affects the processing speed for both OLTP and OLAP and helps you achieve optimum query performance and response time.
As mentioned earlier, SQL Server uses indexes to optimize overall query performance. However, there is also a cost associated with indexes; that is, indexes slow down insert, update, and delete operations. Therefore, it is important to consider the cost and benefits associated with indexes when you plan your indexing strategy.
A table that doesn't have a clustered index is stored in a set of data pages called a heap. Initially, the data in the heaps is stored in the order in which the rows are inserted into the table. However, SQL Server Database Engine moves the data around the heap to store the rows efficiently. Therefore, you cannot predict the order of the rows for heaps because data pages are not sequenced in any particular order. The only way to guarantee the order of the rows from a heap is to use the SELECT statement with the ORDER BY clause.
When you access the data, SQL Server first determines whether there is a suitable index available for the submitted SELECT statement. If no suitable index is found for the submitted SELECT statement, SQL Server retrieves the data by scanning the entire table. The database engine begins scanning at the physical beginning of the table and scans through the full table page by page and row by row to look for qualifying data that is specified in the submitted SELECT statement. Then, it extracts and returns the rows that meet the criteria in the format specified in the submitted SELECT statement.
The process is improved when indexes are present. If the appropriate index is available, SQL Server uses it to locate the data. An index improves the search process by sorting data on key columns. The database engine begins scanning from the first page of the index and only scans those pages that potentially contain qualifying data based on the index structure and key columns. Finally, it retrieves the data rows or pointers that contain the locations of the data rows to allow direct row retrieval.
In SQL Server, all indexes—except full-text, XML, in-memory optimized, and columnstore indexes—are organized as a balanced tree (B-tree). This is because full-text indexes use their own engine to manage and query full-text catalogs, XML indexes are stored as internal SQL Server tables, in-memory optimized indexes use the Bw-tree structure, and columnstore indexes utilize SQL Server in-memory technology.
In the B-tree structure, each page is called a node. The top page of the B-tree structure is called the root node. Non-leaf nodes, also referred to as intermediate levels, are hierarchical tree nodes that comprise the index sort order. Non-leaf nodes point to other non-leaf nodes that are one step below in the B-tree hierarchy, until reaching the leaf nodes. Leaf nodes are at the bottom of the B-tree hierarchy. The following diagram illustrates the typical B-tree structure:
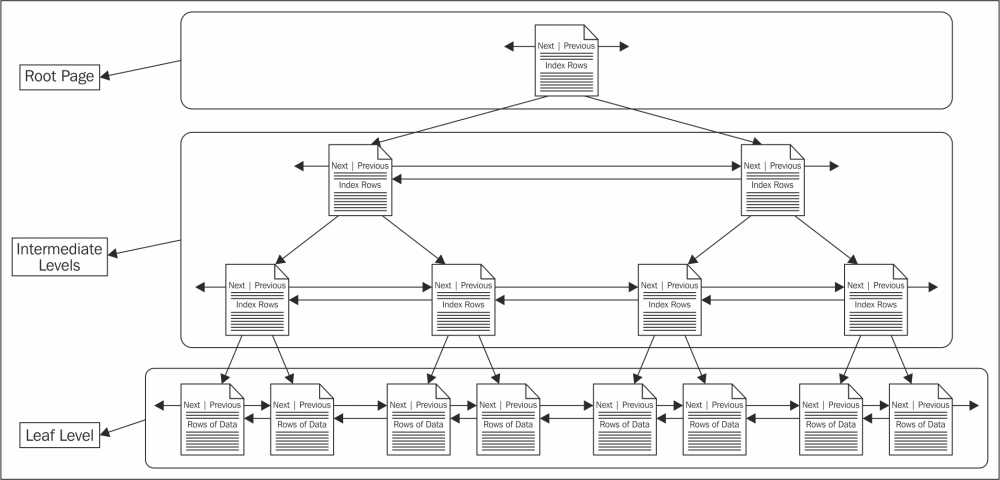
In SQL Server 2014, you can create several types of indexes. They are explored in the next sections.
A clustered index sorts table or view rows in the order based on clustered index key column values. In short, a leaf node of a clustered index contains data pages, and scanning them will return the actual data rows. Therefore, a table can have only one clustered index. Unless explicitly specified as nonclustered, SQL Server automatically creates the clustered index when you define a PRIMARY KEY constraint on a table.
Although it is not mandatory to have a clustered index per table, according to the TechNet article, Clustered Index Design Guidelines, with few exceptions, every table should have a clustered index defined on the column or columns that used as follows:
- The table is large and does not have a nonclustered index. The presence of a clustered index improves performance because without it, all rows of the table will have to be read if any row needs to be found.
- A column or columns are frequently queried, and data is returned in a sorted order. The presence of a clustered index on the sorting column or columns prevents the sorting operation from being started and returns the data in the sorted order.
- A column or columns are frequently queried, and data is grouped together. As data must be sorted before it is grouped, the presence of a clustered index on the sorting column or columns prevents the sorting operation from being started.
- A column or columns data that are frequently used in queries to search data ranges from the table. The presence of clustered indexes on the range column will help avoid the sorting of the entire table data.
Nonclustered indexes do not sort or store the data of the underlying table. This is because the leaf nodes of the nonclustered indexes are index pages that contain pointers to data rows. SQL Server automatically creates nonclustered indexes when you define a UNIQUE KEY constraint on a table. A table can have up to 999 nonclustered indexes.
Note
You can use the CREATE INDEX statement to create clustered and nonclustered indexes. A detailed discussion on the CREATE INDEX statement and its parameters is beyond the scope of this chapter. For help with this, refer to the CREATE INDEX (Transact-SQL) article at http://msdn.microsoft.com/en-us/library/ms188783.aspx.
SQL Server 2014 also supports new inline index creation syntax for standard, disk-based database tables, temp tables, and table variables. For more information, refer to the CREATE TABLE (SQL Server) article at http://msdn.microsoft.com/en-us/library/ms174979.aspx.
As the name implies, single-column indexes are based on a single-key column. You can define it as either clustered or nonclustered. You cannot drop the index key column or change the data type of the underlying table column without dropping the index first. Single-column indexes are useful for queries that search data based on a single column value.
Composite indexes include two or more columns from the same table. You can define composite indexes as either clustered or nonclustered. You can use composite indexes when you have two or more columns that need to be searched together. You typically place the most unique key (the key with the highest degree of selectivity) first in the key list.
For example, examine the following query that returns a list of account numbers and names from the Purchasing.Vendor table, where the name and account number starts with the character A:
USE [AdventureWorks2012];
SELECT [AccountNumber] ,
[Name]
FROM [Purchasing].[Vendor]
WHERE [AccountNumber] LIKE 'A%'
AND [Name] LIKE 'A%';
GOIf you look at the execution plan of this query without modifying the existing indexes of the table, you will notice that the SQL Server query optimizer uses the table's clustered index to retrieve the query result, as shown in the following screenshot:
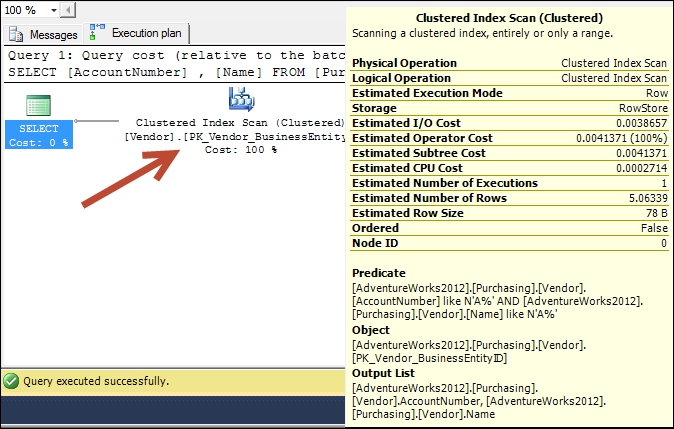
As our search is based on the Name and AccountNumber columns, the presence of the following composite index will improve the query execution time significantly:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [AK_Vendor _ AccountNumber_Name] ON [Purchasing].[Vendor] ([AccountNumber] ASC, [Name] ASC) ON [PRIMARY]; GO
Now, examine the query execution plan of this query once again, after creating the previous composite index on the Purchasing.Vendor table, as shown in the following screenshot:
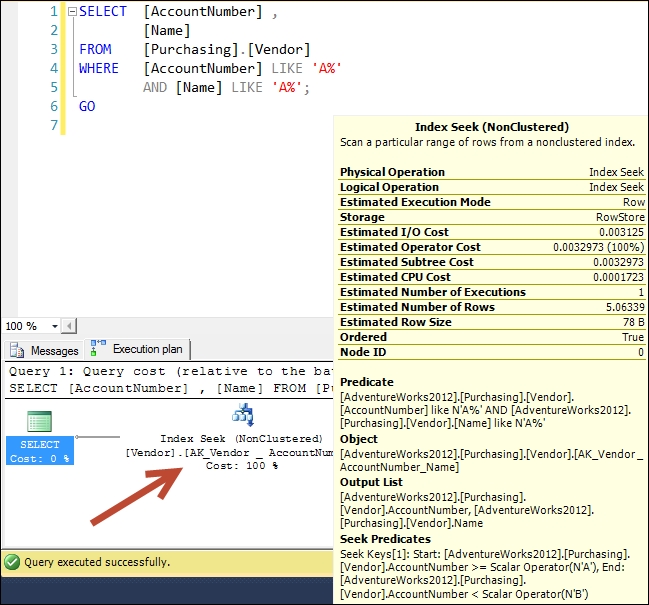
As you can see, SQL Server performs a seek operation on this composite index to retrieve the qualifying data.
SQL Server 2005 introduces included columns in indexes, also known as covering indexes. Included columns are nonkey columns. Query performance improves when all columns in a query are included in the index as either key or nonkey columns. SQL Server Database Engine stores nonkey columns at the index leaf level, which is the bottommost level of the index hierarchy, and not in the index row. Included columns are supported on nonclustered indexes only. Columns included as nonkey columns have the following features:
- They are not included in the 900-byte index key limit
- They can be data types that are not allowed as key columns
- They can include computed columns, but require deterministic values
- They cannot include
text,ntext, orimagedata types - They cannot be used as both key and nonkey columns
For example, consider that you now want to retrieve all columns from the Purchasing.Vendor table based on the values of the Name and AccountNumber columns. To accomplish this, execute the following query:
USE [AdventureWorks2012];
GO
SELECT [AccountNumber]
,[Name]
,[CreditRating]
,[PreferredVendorStatus]
,[ActiveFlag]
,[PurchasingWebServiceURL]
,[ModifiedDate]
FROM [Purchasing].[Vendor]
WHERE [AccountNumber] IN (N'AUSTRALI0001', N'JEFFSSP0001', N'MITCHELL0001')
AND [Name] IN (N'Inner City Bikes', N'Hill Bicycle Center'),
GOExamine the execution plan of this query without modifying the existing indexes of the table; refer to the following screenshot:
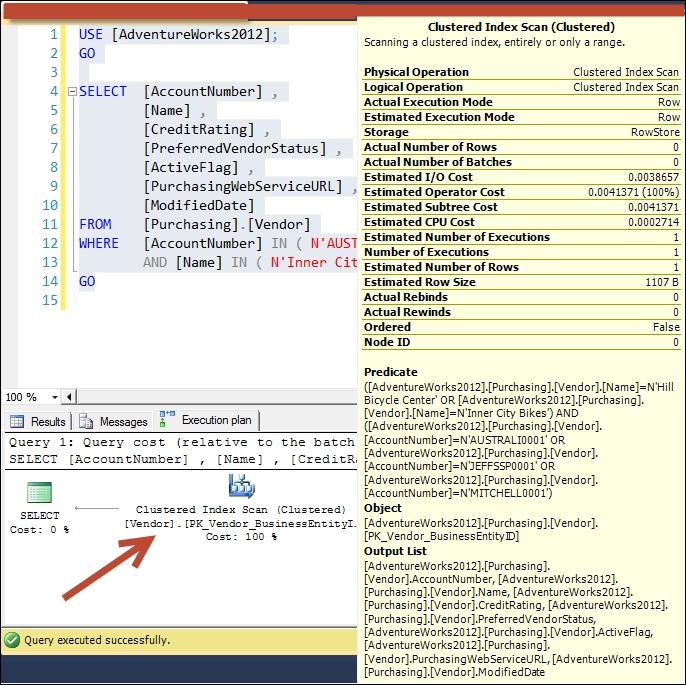
You will notice that SQL Server uses the table's clustered index to retrieve the query result. This is because the query contains the columns that are not part of the nonclustered index. Therefore, SQL Server uses the clustered index to retrieve the query results. To improve this query performance, you can modify your nonclustered composite index on the Purchasing.Vendor table, which we created earlier, to add the remaining columns of the query as nonkey columns in this composite index. Have a look at the following code snippet:
USE [AdventureWorks2012];
GO
CREATE NONCLUSTERED INDEX [AK_Vendor_AccountNumber_Name]
ON [Purchasing].[Vendor] ([AccountNumber] ASC, [Name] ASC )
INCLUDE([CreditRating]
,[PreferredVendorStatus]
,[ActiveFlag]
,[PurchasingWebServiceURL]
,[ModifiedDate]) ON [PRIMARY];
GOAfter creating the previous composite index with included columns, run the query and examine its query execution plan as show in the following screenshot:
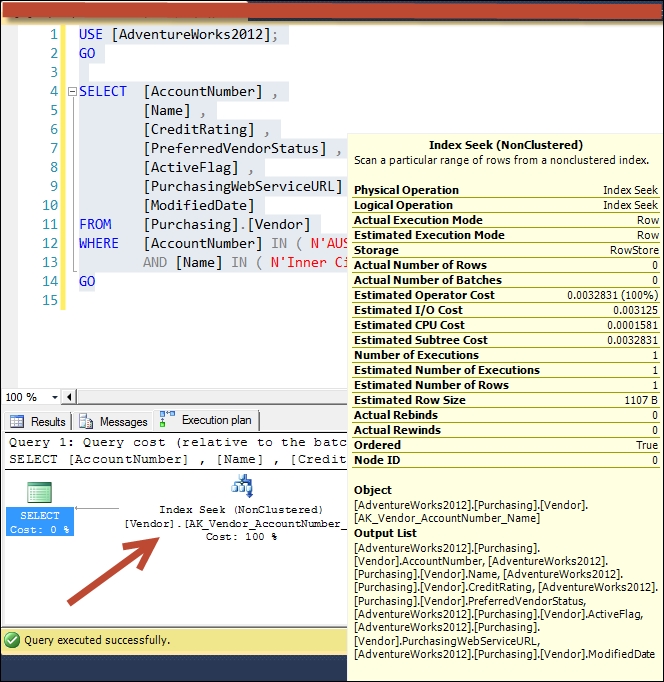
You can use unique indexes to enforce uniqueness on the key columns. If you attempt to add rows or change data that generates duplicate data in a table that is indexed by a unique index, the operation is aborted and SQL Server reports an error. A unique index has the following features:
- It can have one or more key columns
- It can be created as a clustered or nonclustered index
- It checks for duplicate values when the index is created or rebuilt
- It checks for duplicate values during data manipulation (
INSERTorUPDATE)
By default, SQL Server creates a unique clustered index when you define a primary key and a unique nonclustered index when you define a unique constraint. However, you can override the default behavior to define a nonclustered index on the primary key and clustered unique constraint. A unique index ensures the data integrity of the defined columns and provides additional information that is helpful to the query optimizer and can produce more efficient execution plans.
Note
For more information on unique indexes, refer to the Create Unique Indexes article at http://msdn.microsoft.com/en-us/library/ms187019.aspx.
SQL Server supports spatial data and spatial indexes. A spatial index is an extended index that allows you to index a spatial column. A spatial column is a data table column that contains spatial data types, such as geometry or geography.
Partitioned indexes are created on partitioned tables. They are partitioned on the same horizontal filter and ranges as the table that they are based on. You can specify the table partition scheme (how the table is partitioned) when creating partitioned indexes. You can also create partitioned indexes on existing nonpartitioned tables, but to do this, you first have to convert the existing nonpartitioned tables into partitioned tables. To do this, you first need to add appropriate partitioned filegroups, then create a partitioned function and partition scheme inside of the database. Once done, you need to rebuild the desired table index/indexes on this partition.
Partitioned indexes not only help optimize queries that include data only from a single partition, but they also help make index management operations easier because you can also rebuild the partition of an index that is fragmented individually.
Note
A detailed discussion on partitioned tables and indexes is outside the scope of this chapter. For more information, see the Partitioned Tables and Indexes article at http://msdn.microsoft.com/en-us/library/ms190787.aspx.
Beginning with SQL Server 2008, Microsoft introduced a new type of nonclustered index known as a filtered index. A filtered index is an optimized nonclustered index that only contains the subset of data specified by the filter predicate. Filtered indexes are especially useful to cover those queries that frequently need access to a well-defined subset of data. Having a well-designed filtered index can improve query performance, reducing the overall index maintenance costs and index storage costs compared to full-table indexes.
For example, have a look at the following query that returns all of the orders from Sales.SalesOrderDetail that are placed on or after January 1, 2008:
USE [AdventureWorks2012]
GO
SELECT [SalesOrderID] ,
[SalesOrderDetailID] ,
[OrderQty] ,
[ProductID] ,
[SpecialOfferID] ,
[UnitPrice] ,
[UnitPriceDiscount] ,
[LineTotal] ,
[ModifiedDate]
FROM [Sales].[SalesOrderDetail]
WHERE [ModifiedDate] >= '2008-01-01 00:00:00.000';
GOBy creating the following filtered index, you can significantly improve the query response time because SQL Server will perform an index seek on this filtered index to retrieve the qualifying data:
USE [AdventureWorks2012];
GO
CREATE NONCLUSTERED INDEX IXNC_SalesOrderDetail_ModifiedDate
ON [Sales].[SalesOrderDetail] ([ModifiedDate])
INCLUDE ([SalesOrderID]
,[SalesOrderDetailID]
,[OrderQty]
,[ProductID]
,[SpecialOfferID]
,[UnitPrice]
,[UnitPriceDiscount]
,[LineTotal])
WHERE [ModifiedDate] >= '2007-01-01 00:00:00.000';
GOA full-text search is a word search based on character string data. The Microsoft Full-Text Engine for SQL Server automatically creates and maintains a full-text catalog when you enable a table to do a full-text search.
For more information on full-text indexes, see the Populate Full-Text Indexes article at http://msdn.microsoft.com/en-us/library/ms142575.aspx.
XML indexes are persisted representations of the data contained in an XML data type column. They have different procedures of creation and management from standard indexes, and they are structured differently from standard indexes as well. There are two main XML index types: primary and secondary. You must create a primary index first and can then create one or more secondary indexes. When creating XML indexes, the base table must have a primary key constraint defined. If the base table is a partitioned table, XML indexes will use the same partitioning function and partitioning scheme. Moreover, you can create one primary index and one or more secondary indexes for each XML column in the base table. If you are using data type methods, you should create at least a primary index. All data type methods use the primary index for optimization if it is present.
For more information on XML indexes, see the XML Indexes (SQL Server) article at http://msdn.microsoft.com/en-us/library/ms191497.aspx.
You create memory-optimized indexes on memory-optimized tables. You can only create nonclustered indexes on memory-optimized tables. The nonclustered indexes of memory-optimized tables are structured as a Bw-tree. The Bw-tree is a high-performance, latch-free B-tree index structure that exploits log-structured storage. The following diagram illustrates the Bw-tree architecture:

Like memory-optimized tables, memory-optimized indexes also reside in memory. You can create two types of nonclustered indexes. These are as follows:
- Nonclustered, memory-optimized hash indexes: These indexes are made for point lookups. They do not have pages and are always fixed in size. The values returned from a query using a hash index are not sorted. Hash indexes are optimized for index seeks on equality predicates and also support full index scans. Queries that use hash indexes return results in an unsorted order.
- Nonclustered, memory-optimized non-hash indexes: These are made for range scans and ordered scans. They support everything that hash indexes support, plus seek operations, such as greater than or less than, on inequality predicates as well as sort order. Queries that use non-hash indexes return results in a sorted order.
For more information on memory-optimized indexes, see the extensive set of documentation named Introduction to Indexes on Memory-Optimized Tables at http://msdn.microsoft.com/en-us/library/dn511012.aspx.
SQL Server 2014 is another fascinating release, which has several compelling, performance-related features, out of which the updatable, in-memory columnstore (abbreviated to xVelocity where appropriate) index is one of them. Columnstore indexes allow you to deliver predictable performance for large data volumes. Columnstore indexes were first introduced with SQL Server 2012 to significantly improve the performance of data warehouse workloads. According to Microsoft, you can achieve up to 10x performance improvements for certain data warehousing analytical queries using in-memory columnstore indexes.
The in-memory columnstore index feature is one of the most significant scalability and performance enhancements of SQL Server 2012. However, the SQL Server 2012 implementation of in-memory columnstore indexes is not updatable, which means that you cannot perform DML operations on tables once the in-memory columnstore index is created on them. Therefore, the underlying table that you are creating the columnstore index on has to be read only. Moreover, to update data on the underlying table, you need to first drop or disable the columnstore index and then enable or recreate the columnstore index once the data in the underlying table is updated. SQL Server 2014 removed this restriction and introduced updatable in-memory columnstore indexes.
Unlike SQL Server 2012 Database Engine, which only supports nonclustered columnstore indexes, SQL Server 2014 Database Engine supports both clustered and nonclustered columnstore indexes. Both these types of SQL Server 2014 columnstore indexes use the same in-memory technology but have different purposes. The clustered columnstore indexes of SQL Server 2014 are updatable, which means that you can perform DML operations on the underlying table without having to disable or remove the clustered columnstore index.
Unlike traditional B-tree indexes, where data is stored and grouped in a row-based fashion, the columnstore indexes group and store data for each column on a separate set of disk pages. For example, consider the following table with 8 columns:
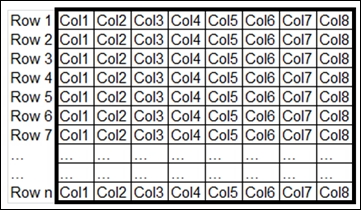
When you create the traditional B-tree index on this table, SQL Server stores multiple table rows per index page as illustrated in the following diagram:
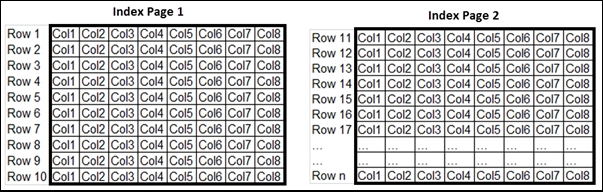
When you create the columnstore index on this table, SQL Server stores the data for each column on a separate index page as illustrated in the following diagram:
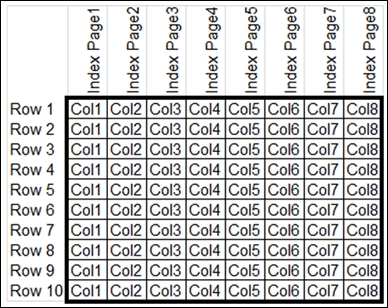
A columnstore index does not physically store columns in a sorted order. Instead, it is based on VertiPaq compression technology, which allows large amounts of data to be compressed in memory. This highly compressed, in-memory store, significantly improves the query execution time by improving the buffer pool usage, while reducing the total disk I/O and CPU usage. This is because only the column-based data pages needed to solve the query are fetched from disk and moved in memory.
You can use the CREATE CLUSTERED COLUMNSTORE INDEX statement to create a clustered columnstore index and the CREATE COLUMNSTORE INDEX statement to create a nonclustered columnstore index. To create a clustered columnstore index, use the following code:
CREATE CLUSTERED COLUMNSTORE INDEX index_name
ON [database_name].[schema_name].[table_name]
[ WITH ( <columnstore_index_option> [ ,...n ] ) ]
[ ON {
partition_scheme_name ( column_name )
| filegroup_name
| "default"
}][ ; ]To create a nonclustered columnstore index, use the following code:
CREATE [NONCLUSTERED] COLUMNSTORE INDEX index_name
ON [database_name].[schema_name].[table_name]
( column [ ,...n ] )
[ WITH ( <columnstore_index_option> [ ,...n ] ) ]
[ ON {
partition_scheme_name ( column_name )
| filegroup_name
| "default"
} ] [ ; ]When creating columnstore indexes, you need to consider the following:
- The columnstore index feature is only available in the SQL Server 2014 Enterprise, Evaluation, and Developer editions.
- Columnstore indexes cannot be combined with the following SQL Server features: page and row compression, replication, filestreams, change tracking, and CDC.
- Clustered columnstore indexes must include all columns of the table.
- You cannot create columnstore indexes on other indexes or indexed views.
- Columnstore indexes cannot have more than 1,024 columns.
- Columnstore indexes cannot include sparse columns, unique constraints, primary key constraints, or foreign key constraints.
- Columnstore indexes cannot include columns with the following data types:
ntext,text,image,varchar(max),nvarchar(max),varbinary(max),rowversion(andtimestamp),sql_variant, CLR types (hierarchyidand spatial types), and XML. - Avoid creating columnstore indexes on tables that are frequently updated or need small lookup queries. They are only suitable for read-mostly, read-intensive, large database tables.
You can use the ALTER INDEX statement to modify a columnstore index. You can use ALTER INDEX…REBUILD with the COLUMNSTORE_ARCHIVE data compression option to further compress the columnstore index, which is suitable for situations where the archiving of data is possible. You can use the DROP INDEX statement to delete a columnstore index.
You can also use SQL Server 2014 Management Studio to create columnstore indexes in the same way that you use it to manage standard, disk-based table indexes. For example, to create a new clustered columnstore index, in Object Explorer, expand table and right-click on the Indexes folder. Next, choose New Index and then the new clustered columnstore index.
The following sections will cover some guidelines that you can follow to make indexes more effective and improve performance during the creation, implementation, and maintenance of indexes.
Indexes are the solution to many performance problems, but too many indexes on tables affect the performance of INSERT, UPDATE, and DELETE statements. This is because SQL Server updates all indexes on the table when you add (INSERT), change (UPDATE), or remove (DELETE) data from a table. Therefore, it is recommended that you only create required indexes on the tables by analyzing the data access requirements of the application or users.
As mentioned earlier, the leaf layer of a clustered index is made up of data pages that contain table rows, and the leaf layer of a nonclustered index is made up of index pages that contain pointers to the data rows. In addition, SQL Server sorts table rows in the clustered index order based on key column values, while the nonclustered index does not affect the table sort order. When we define the nonclustered index on a table first, the nonclustered index contains a nonclustered index key value and a row locator, which points to a heap that contains a key value. However, if the table has a clustered index, a leaf node of the nonclustered index points to a leaf node location in the clustered index. So, when you create or rebuild the clustered index, the leaf node structure of the nonclustered index also changes. Therefore, you need to follow this rule because the creation or changing of the clustered index will also change the nonclustered indexes of the tables.
Foreign key columns are always good candidates for nonclustered indexes because they are mostly used in JOIN operations.
Be sure to create nonclustered indexes on columns that are frequently used in JOIN operations as this will improve query performance when the JOIN operation is being performed by reducing the time required to locate the required rows in each table.
When you use composite indexes, you create fewer indexes for your queries because a composite index is defined from two or more columns from the same table. This improves the query performance because the query requires less disk I/O than the same query that uses a single column index.
Covering indexes also improve query performance by reducing the overall disk I/O because all of the data needed to satisfy the query exists within the index itself.
We need to limit key columns to columns with a high level of selectability because the higher the level of selectivity in a column, the more likely that it is a key column candidate. For example, good candidates for index key columns are the ones used in the DISTINCT, WHERE, ORDER BY, GROUP BY, and LIKE clauses.
When the database engine needs to add a row to a full index page, the database engine has to split this page to make additional space for the new row. This process of splitting pages will help keep the index hierarchy intact.
Obviously, this process is resource intensive as it depends on the size of the index and other activities in the database. The process can result in a significant loss in performance, and to prevent splits, or at least reduce the need for them, you should pad the index and specify the fill factor value. The fill factor value specifies the percentage of space on each leaf-level page to be filled with data, reserving the remainder of space for future growth. The fill factor can either be set to 0 or to a percentage between 1 and 100. The server-wide default for the fill factor value is 0, which means the leaf-level pages are filled to capacity.
A padding index leaves an open space on each page at the intermediate level of the index. The padding option in indexing is useful only when the fill factor is specified as it uses the percentage specified by the fill factor. By default, SQL Server ensures that each index page has enough space to accommodate at least one row of the maximum index size, given the set of keys on the intermediate pages. However, when you pad an index, if the percentage specified for the fill factor is not large enough to accommodate a row, SQL Server internally overrides the percentage to allow the minimum. For more information, refer to the Specify Fill Factor for an Index article at http://msdn.microsoft.com/en-us/library/ms177459.aspx.
Index fragmentation can occur in an active database because SQL Server maintains indexes on an ongoing basis during DML operations so that they reflect data changes. As a DBA or developer, your main goal is to look for index fragmentation and correct the fragmentation with a minimal impact on user operations.
Luckily, SQL Server provides the sys.dm_db_index_physical_stats dynamic management view, which you can use to detect the fragmentation in a specific index, all of the indexes in a table or indexed view, all indexes in databases, or all indexes in all databases. The avg_fragmentation_in_percent column of this view returns the percentage of fragmented data. Depending on the level of fragmentation, you can either rebuild or reorganize the index. For more information, see the Reorganize and Rebuild Indexes article at http://msdn.microsoft.com/en-us/library/ms189858.aspx.