
2
Data Modeling and Database Design
In this chapter, we'll begin our journey into the theory behind the credential syllabus, starting with Data Modelling and Database Design. You will learn how a Salesforce data model is architected, the design decisions behind it, and how a data model you may create in your job as a Salesforce Data Architect affects sharing and security. We'll go over the Salesforce sharing model so that you have an overview of what is available when considering options around data access.
Next, we'll look at the different types of objects (such as standard, custom, big, and external), and how they fit into a data model design strategy. While we're there, we'll cover the different relationship types so that you can understand when to apply them.
Turning to performance, we'll cover data skew to provide you with an understanding of this concept in Salesforce. We'll then cover diagramming techniques so that you can begin to effectively design and represent Salesforce data models.
In this chapter, we'll be covering the following topics:
- The Salesforce data model
- Understanding Salesforce sharing and security
- Exploring standard, custom, external, and big objects
- Overcoming data skew
- Bringing it all together with data modeling
The Salesforce data model
Salesforce abstracts the underlying data structure in its database for a given customer org by providing a faux RDBMS view of the objects within it. For example, take the diagram you find when viewing the Sales Cloud ERM at https://architect.salesforce.com/diagrams/template-gallery/sales-cloud-overview-data-model:
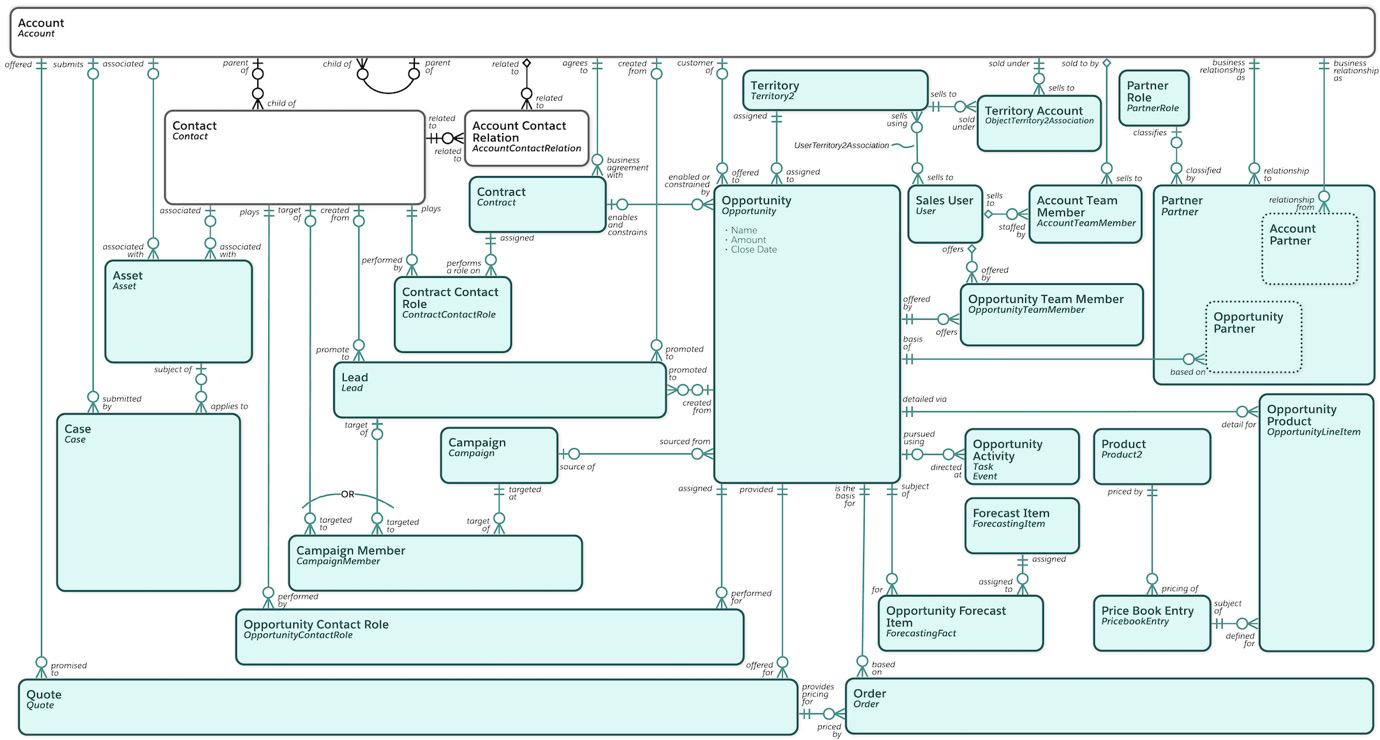
Figure 2.1 – The Salesforce Sales Cloud data model
As we can see, a contact record will have an AccountId represented as a lookup (which would be a foreign key in RDBMS terminology). Take this example for Account and Contact from Schema Builder for a brand-new Developer Edition org:

Figure 2.2 – Account and Contact represented in Schema Builder in a brand-new Developer Edition org
See for Yourself
Feel free to sign up for a (completely free) Developer Edition Salesforce org at https://developer.salesforce.com/signup in order to follow along with the examples in this book, including exploring Schema Builder.
Salesforce would have you think that Account and Contact exist as two separate database tables (and indeed there would be a separate table for each standard or custom object in the schema). Indeed, it is perfectly normal to think about the objects in this way in your day-to-day work as a Salesforce Data Architect.
The truth is, however, that Salesforce has a few large, underlying database tables (one for objects, one for fields, one for data that maps to those objects and fields, pivot tables, and so on) that provide for a virtual data structure for each org that is materialized at runtime. One virtual storage area contains standard objects and standard fields, another contains standard objects and custom fields, and another contains custom objects and their custom fields. This is explained in further detail at https://developer.salesforce.com/wiki/multi_tenant_architecture. In essence, the standard object/standard fields storage area is populated when a new org is provisioned, and the custom storage areas are added to whenever a new custom object or custom field is added (no matter whether that custom field is added to a standard or custom object). This structure can therefore be represented as follows, imagining a custom field is added to each of the standard Account and Contact objects:

Figure 2.3 – Representation of the Salesforce database (object data only) with a custom field added to the Account and Contact standard objects
Let's now add a custom object to see how the virtual storage is affected and what that change looks like in Schema Builder:

Figure 2.4 – Representation of the Salesforce database (object data only) with a custom object added to the org and a custom field added to that new custom object
Figure 2.5 includes both the custom object and the custom field in the schema:
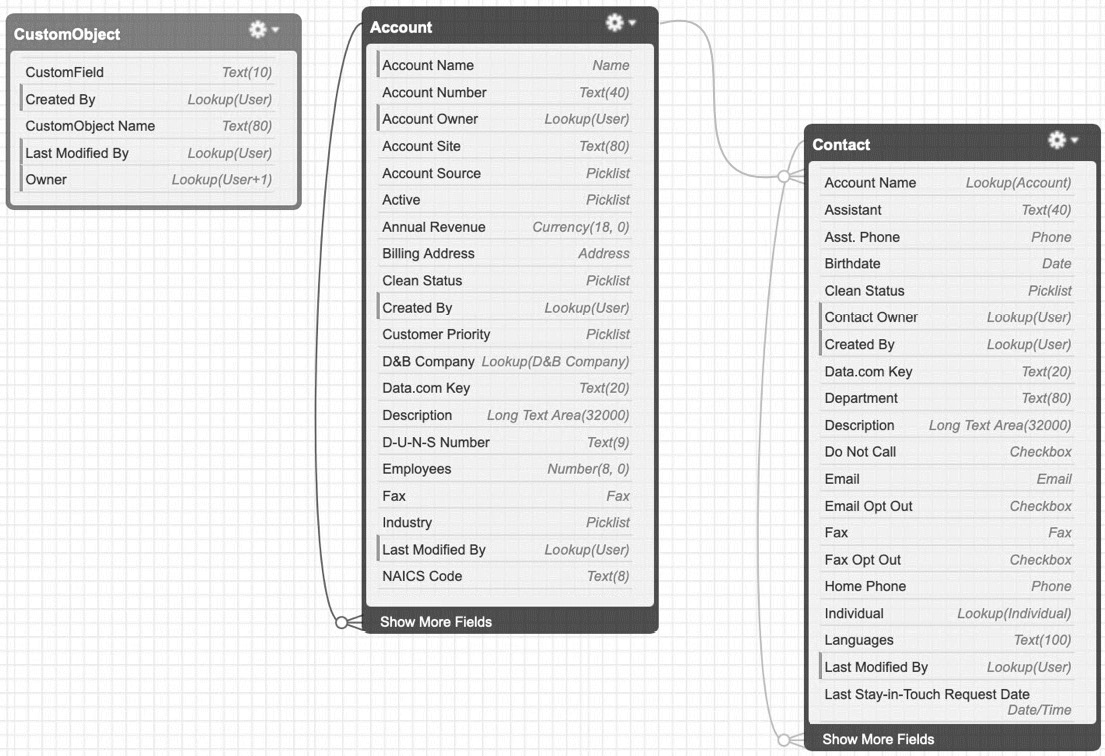
Figure 2.5 – Schema Builder with the representation of the newly added custom object and custom field
Armed with the knowledge of how the underlying Salesforce data model is represented (which is important for performance tuning and the like, covered later in this book), we can now turn our attention to what standard objects are available in Salesforce. These objects have been created to address common use cases (such as accounts to represent companies and contacts to represent people), and therefore should be used as much as possible. This not only reduces reinventing the wheel, but also Salesforce has extended the standard functionality to account for specific use cases, such as account teams. Account teams extend the sharing model for accounts to allow bespoke sharing among a team of folks that will collaboratively work on an account. Similar functionality is available for cases and opportunities (called case teams and opportunity teams, respectively). This teams functionality is an example of a standard feature supported in the Salesforce data model that isn't extended to custom objects.
A full and exhaustive listing of the available objects in Salesforce and their fields is provided by the API documentation (available at https://developer.salesforce.com/docs/atlas.en-us.api.meta/api/sforce_api_objects_list.htm), but some of the most commonly used objects are as follows:
- Account – Represents a company or institution that you may do business with.
- Contact – Represents a person (who is normally associated with one or sometimes many accounts).
- Lead – Represents a prospect or unqualified sale. Leads are typically used in a presales scenario, with the goal of converting the lead into an account, contact, and optionally, an opportunity.
- Person Account – A grouping account/contact object (mainly to allow opportunities to be associated to individual buyers instead of accounts/companies). This is essentially the account/contact relationship changed from a lookup to Controlled By Parent. This has effects on sharing and data visibility.
- Case – Represents a tracked issue or work item requiring attention. It's typically used by support staff.
- Opportunity – Represents a business deal.
- Opportunity Line Item – An item that forms part of the opportunity and is used to drive its value.
Standard Object Data Model Diagrams
The Salesforce standard data models are available at https://developer.salesforce.com/docs/atlas.en-us.api.meta/api/data_model.htm (remember, they show the logical representation of the objects and their relationships, not the physical database structure).
Now we are aware of the standard objects, and the three tables that facilitate standard objects/standard fields, standard objects/custom fields, and custom objects/custom fields, we can now turn our attention to understanding how data queries work, paying attention to performance across these tables.
When issuing a form of query to the Salesforce database for data, such as Salesforce Object Query Language (SOQL) or a REST API call, that request is turned into system-generated SQL for the underlying database. It is not possible to tune the SQL that is generated but being mindful of how our data queries will affect the generation of the SQL provides us with something that we can affect to a certain extent. It is within these parameters that we can optimize our data queries.
For example, consider this SOQL query for the first 10 account record names as they would appear in an alphabetically sorted list:
SELECT Name FROM Account ORDER BY Name ASC LIMIT 10Given that we're querying a standard field from a standard object, Salesforce will only need to retrieve data from the standard objects/standard fields table for Account.
When adding a custom field into the mix (which we'll assume is unimaginatively called CustomField for the purposes of this explanation), we're then asking the underlying database query to have a JOIN in order to allow data from the Standard Object/Custom Fields table to be retrieved. Therefore, a query as simple as this will cause data to be retrieved from more than one underlying database table:
SELECT Name, CustomField__c FROM Account ORDER BY Name ASC LIMIT 10;Now consider a third scenario. We are going to query a custom object (called CustomObj__c) that has a lookup to an account (called Account__c), and also place the name of the account and the custom account field from the last example in the results:
SELECT Name, Account__c.Name, Account__c.CustomField__c FROM CustomObj__c ORDER BY Name ASC LIMIT 10;We've now queried the Custom Object/Custom Fields, Standard Object/Custom Fields, and Standard Object/Standard Fields tables, all for the retrieval of 10 rows worth of data from 3 fields!
It is therefore best practice to design our data access queries to avoid joins as much as possible, therefore ensuring we get the best performance possible. Given the way in which the underlying Salesforce data is structured, having a well-structured data model (avoiding joins as much as possible) means reporting, dashboards, and list views will perform well.
Chapter 6, Understanding Large Data Volumes, describes the issues that can arise with large amounts of data (particularly with performance) and how to mitigate them.
With the Salesforce data model now introduced, let's turn our attention to sharing and security, which affect how data is accessed.
Understanding Salesforce sharing and security
Any data access in Salesforce is determined by a layered security model. With each layer, data access is gradually opened up. Therefore, it is imperative that at the lowest level the sharing and security requirements are well understood in order to configure the security settings as appropriate. The layers of the Salesforce security model can be visualized as follows:

Figure 2.6 – A visual representation of the layers of the Salesforce security model
The layers that make up the security model, how they are configured, and their impacts are explained in this section.
Organization-Wide Defaults
The access that users have to each other's records by default is specified in the Organization-Wide Defaults (OWDs) for a Salesforce instance. Essentially, OWDs lock data access down to the most restrictive level, and then the other sharing and data access tools (explained in the following sections) are used to gradually open up data access to your users. For example, setting a read-only account OWD will mean that users cannot edit accounts by default. If users require the ability to only edit accounts they own, grant edit and read access at the object level through the use of a profile or permission set, leaving the OWD set to read-only for accounts. There are separate OWDs for internal and external (through a Salesforce Community or otherwise) users. The premise of access is the same, but the external OWDs facilitate locking down to a more restrictive data access model by default. For example, you may opt for all regular (sometimes referred to as internal) Salesforce users having read-only access to all accounts by default, with external users accessing Salesforce through a community having an OWD of private for account records so that those external users can only see account records they own. The values available to be set for OWDs are explained in the following subsections.
OWD values
There are several options available when setting OWDs in your Salesforce instance, and they all have an impact on how data access works for a given object or associated records/objects.
Private
Only the record owner, or those users higher than the record owner's role in the role hierarchy can view, edit, and report on records of this object.
Public Read-Only
All users can see records of this object type, but only the record owner and those folks higher than the record owner's role in the role hierarchy can view, edit, and report on records of this object.
Public Read/Write
All users can view, edit, and report on data held in records of this object.
Public Read/Write/Transfer
Only applicable to case and lead objects, all users can view, edit, transfer, and report on data held in lead or case records where this option is set.
Public Full Access
This is only applicable to the campaign object. All users can view, edit, delete, transfer, and report on data held in campaign records if this option is set.
Controlled by Parent
Users can perform actions on related records (such as edit or delete) based on access to the parent record. For example, if a custom object called Invoice has Account as its parent object, and Invoice's OWD is set to Controlled by Parent, then a users access to Account automatically means they have access to the invoice record associated with the account record. If the user has edit permissions on an account, then they will automatically have edit access to the associated invoice record.
It Is Imperative That OWDs Are Correct
OWDs were until recently the only way to restrict user access to a record. Changing an OWD will have an impact throughout the Salesforce Org (not least on the time it will take to perform sharing re-calculations), resulting in users potentially being able to see more data than they should do. Therefore, it is crucial that a users data access is thoroughly understood before implementing OWDs. Since the release of Winter '22, a feature called restriction rules facilitates restricting access to certain records to a select group of users. This is explained in further detail in the Restriction rules section. Restriction rules are used to restrict users and are not a substitute for a well-designed OWD strategy.
Profiles and permission sets
Specifying the object-level security access is the main function of profiles (although additional settings are present, such as login hours, IP ranges, and the like, that aren't in the scope of this exam). By specifying Create, Read, Edit, and Delete access to specific objects, users access to those objects can be further opened up beyond the OWDs already set in the organization. Field-level security is also set in profiles and permission sets, so it is here where Read or Edit access to specific fields is done.
Every user must have a profile assigned to them. Permission sets can be used to grant further selective access to objects and other features through organization settings available in the permission set. Managed packages typically use permission sets to allow assigned users access to the functionality offered by the managed package.
A Quick Word on View All and Modify All
View All and Modify All essentially allow users to be given blanket Read or Edit access across the organization for a given object. They effectively ignore sharing rules for a specific object. Therefore, if users are assigned a profile or permission set with View All set for accounts, they will have read access to every account. Similarly, Modify All against accounts gives edit access to any account in the organization. View All Data and Modify All Data permissions are set at the organization level, and sharing is effectively ignored to grant read or edit access to all objects and records in the organization to users that have this permission.
Role Hierarchy
Much like the structure of an organization, the role hierarchy is used to determine data access for groups of users and ensures that managers always have the same level of data access as their employees (regardless of the OWDs in place for that object). Each level of the role hierarchy should align with a level of data access needed by a particular group of users. Role hierarchies therefore deviate slightly from an organization chart as the system administrator will typically sit in a role toward the top of the hierarchy. Depending on the licensing in place for your Salesforce org, external users may have roles assigned, and therefore they may be subordinates to one of the internal roles.
The role hierarchy provides a special provision for access to cases, contacts, and opportunities outside of the OWD setup. Roles determine a users access to cases, contacts, and opportunities, irrespective of which user is the owner of those records. For example, you can set the contact object access so that all users in a particular role have edit rights to all contact records associated with account records that they own, regardless of which users actually own the contact records.
Role Hierarchy Limits
Organizations are allowed 500 roles by default, which can be increased by Salesforce if required (but you should be questioning if this increase is required, or a more effective role hierarchy design will work better).
Just like when changing the OWD for a given object, changing a users role will incur a sharing recalculation, as Salesforce will need to re-evaluate to correct the users access to data, as necessary. Also, just because you have two people in the same role, access to each other's data is not guaranteed (as this would depend on the rest of the sharing setup of the organization). Sharing rules can be used in this instance.
Role Hierarchy Best Practices
Keep to the following best practices when designing your role hierarchy: no more than 10 levels of branches, no more than 25,000 internal roles, and no more than 100,000 external roles.
The role hierarchy is a foundational aspect of the entire Salesforce sharing model, and therefore taking the time to get it right is crucial. No one wants a soup of sharing rules for users having correct data access because the role hierarchy isn't designed properly!
Sharing rules
Sharing rules exist to provide exceptions to the OWD and role hierarchy, opening up users record access based on conditions. Sharing rules fall into two categories:
- Owner-based sharing rules: These allow records to be shared with other users based on the owner of the record, such as peers within the same role.
- Criteria-based sharing rules: These allow records to be shared with other users based on the criteria of the record (a value of a field, for example). Record ownership is not a consideration, as that scenario is covered by owner-based sharing rules.
Manual sharing
In bespoke sharing scenarios not covered by the mechanisms we've covered already, manual sharing exists to provide a facility to manually share a record, granting read and edit permissions, with users who don't have access to the record. Manual sharing, as the name implies, is a user-driven process that involves clicks in the Salesforce user interface to grant record access to other users. It is possible to create manual shares programmatically (for more information, see the dedicated subsection on Programmatic sharing).
Sharing a record with another user creates a share record in the Salesforce database. Programmatic solutions will need to manage record shares for share reasons other than manual share. Programmatic shares with a manual share row cause can be maintained using the Share button on the record, much like the out-of-the-box share button functionality.
When Manual Shares Cease to Work
If a record owner of a shared record changes, then the manual share is removed. If the sharing doesn't open up access beyond what is set in the OWD for that object, the share isn't created in the first place. Both of these statements are also true in programmatic scenarios.
Team access
Accounts, opportunities, and cases have a teams record-sharing concept, whereby groups of users can work collaboratively on accounts, opportunities, or cases. The record owner, someone higher in the role hierarchy (who therefore inherits the same level of record access), or administrators can add people to a team to work collaboratively on a record or modify the access level (say, from read-only to read/write).
Teams are generally used to give specific users in Salesforce an elevated level of access to a record so that they can work collaboratively on an account, opportunity, or case. For example, if a user already has write access to a particular account record, adding them as read/write in the account team for that record has no effect.
Creating a team against an account, opportunity, or case record creates a team record and an associated share record in the Salesforce database. Programmatic solutions will have to maintain both of these records. See the dedicated subsection for more information on programmatic sharing.
What About Multiple Teams Accessing One Record?
If multiple teams are required to access a particular record, then territory management or programmatic sharing may be more suitable. There is only one team per account, opportunity, or case, and therefore the concept of multiple teams against a single record is not supported.
Territory hierarchy access
It is possible to create a hierarchy to represent your organization's sales territories. This essentially facilitates automatic account assignment based on criteria to denote it belonging to a particular branch of the territory model. Chapter 12, Territory Management, covers territory management in further detail.
Programmatic sharing
Using what used to be known as Apex managed sharing, programmatic sharing allows the use of code to build sharing settings when data access requirements cannot be fulfilled using any of the means described in the preceding sections. Code-based sharing solutions can be quite fancy and sophisticated, but equally require careful management, and therefore it is important to understand how programmatic sharing works before embarking on a code-based sharing solution.
Each object in Salesforce has an associated share object. This has two naming conventions (one for standard objects and another for custom objects). For standard objects, the associated share object is named objectShare, such as AccountShare, CaseShare, and so on. For custom objects, the associated share objects are named using a format similar to object__Share. In the example of a custom object called MyObject__c, the associated share object is called MyObject__Share.
Objects that are on the detail side of a master-detail relationship don't have an associated share object because access to the object on the Master side of the relationship grants implicit access to the object on the detail side. Custom objects that have a Public Read/Write OWD also do not have an associated share object.
When programmatically sharing a record using code, the associated share object requires an entry with a row cause to essentially store the reason the sharing has taken place. Sharing a record with a user through the Salesforce UI creates an entry in the associated share object with a row cause of manual share. Programmatic sharing can create entries with using the manual share row cause, but custom row cause values can be used. The values in a share object entry are as follows:
- ParentID: ID of the record being shared. This value cannot be changed once the row is created.
- RowCause: As explained in the previous paragraph, this is the reason why the record is being shared. This can be manual sharing to simulate the Share button in the Salesforce UI being pressed, or a custom reason can be used. Custom sharing reasons need to be created in the Salesforce UI before they can be used. Objects have an Apex sharing reasons related list in the Management Settings of the object in Salesforce Setup.
- UserOrGroupId: The Salesforce ID of the user or group that the record is being shared with.
- objectAccessLevel: The level of access being granted as part of the share. The name of the property is the share object name of which the record is being shared followed by AccessLevel. For example, CaseShareAccessLevel. Values can be edit, or read, or edit or read-only access, respectively.
A Note on Records Shared Programmatically with Manual Share Row Causes
When records that are shared with row causes of manual share (both programmatically and through the UI) change owner, any manual share row cause records are removed from the associated share object. Custom row shares are persisted when a shared records owner changes.
Restriction rules
Generally available as of the Winter '22 release, restriction rules can be used to control the records a specific user group is allowed to see. As per the documentation for creating a restriction rule (https://help.salesforce.com/s/articleView?id=sf.security_restriction_rule_create.htm&type=5), When a restriction rule is applied to a user, the data that the user has access to via org-wide defaults, sharing rules, and other sharing mechanisms is filtered by the record criteria that you specify.
At the time of writing, restriction rules are available for the following objects:
- Custom objects
- Contracts
- Events
- Tasks
- Time sheets
- Time sheet entries
Up to two restriction rules can be created per supported object in the Enterprise and Developer editions, and up to five restriction rules per supported object in the Performance and Unlimited editions.
Now that we have an understanding of sharing and security on the Salesforce platform and how it affects data access, we can now look at each Salesforce object type.
Exploring standard, custom, external, and big objects
Salesforce objects can broadly fit into one of four types. While you will no doubt have worked with the standard and custom object functionality available on the platform, it is necessary to understand how they work at a lower level to truly understand what it means to issue SOQL queries against those object types and how it affects performance. Secondly, you may not have worked with external objects and big objects before. These are different when it comes to data storage and access (external object data isn't stored on the platform and is accessed on-demand through an external data source. Big object data ensures consistent performance but data lives in a separate location to standard/custom objects within the Salesforce platform).
sObjects
An sObject is the generic form of any Salesforce Object. The standard Salesforce objects and the custom objects you create are concrete types of sObjects (they all inherit common properties and behavior). Another way to think of an sObject is that it abstracts the actual representation of any Salesforce object, much like objects in the Java programming language all inherit from the Object base class.
Standard objects
Depending on your license type, Salesforce provides access to many standard objects that are designed to fulfill many business use cases with minimal customization.
These objects and their fields, in an out-of-the-box state, will all be held in the standard objects/standard fields underlying database table. From an object access perspective, additional Salesforce licenses such as Service Cloud will essentially grant access to the underlying Service Cloud standard objects such as milestone and entitlement and their out-of-the-box fields.
Standard objects and standard fields don't have a special suffix and therefore are represented as Account (in the example of a standard object name) and Name (in the example of a standard field name) when issuing SOQL queries. Here's an example:
SELECT Name FROM AccountWithout any customization, querying for standard object data is very fast. This is because there is only one database table being queried for. As soon as a single custom field is added to a standard object, that field is created in the Custom Objects/Custom Fields table, and therefore any queries for that field will essentially cause a JOIN query issued to the underlying Salesforce database, as we now require results from both tables.
Custom objects
Custom objects and their custom fields are all created in the Custom Objects/Custom Fields table in the underlying Salesforce database. Custom object data resides within the Salesforce database, and both custom objects and custom fields have a __c suffix. In the example of a SOQL query issued for data held in a custom field called MyField in an object called MyObject, the syntax would look as follows:
SELECT MyField__c FROM MyObject__cQueries on data held purely within these objects will be relatively quick, but any data on parent objects (especially where that object is a standard object) will incur a small performance penalty as the results will require the use of a JOIN in the underlying SQL query issued to the Salesforce database.
External objects
While the data for both standard and custom objects is held on-platform within the Salesforce database, external object data is held off-platform in an external data source, typically within another application. The idea behind external objects is that data is held off-platform, but end users interact with it as if it were on-platform. Salesforce uses web service callouts to access external data in real time. External data is available to users in real time through Salesforce, and the external object will always return the most up-to-date data from the external data source.
External objects require an external data source definition in the Salesforce instance, which is then used to determine how to access the external system.
External objects are denoted in Salesforce with a __x suffix in the object name. For example, invoice data from SAP for an order within Salesforce will have the name Invoice__x. External objects support indirect and external lookups to link the data with your Salesforce records.
External objects are supported in Salesforce API version 32 and later and are available with Salesforce Connect and Files Connect.
Big objects
Big objects are used to store and manage huge amounts of data (up to 1 million records out of the box, but this can be scaled up at an additional cost to tens of millions or even billions of records). Big objects provide consistent performance. In my experience, big objects tend to lend themselves to auditing and archiving use cases, but anything that requires consistent performance when working with hundreds of millions or billions of records is what big objects are designed for.
Big objects work using a distributed database and are not transactional in nature. Therefore, sharing isn't supported on big objects other than object and field permissions. Additionally, this means that automation from workflow, to flow, to triggers is not supported on big objects.
Idempotence
When the same record representation (that is, exactly the same set of data for a record) is inserted multiple times to a big object, only a single record is created. This is so that writes to the big object can remain idempotent. Inserting the same record representation into an sObject (whether standard or custom) will result in multiple entries.
Object relationship types
Salesforce objects are linked together through relationships in one of several ways. These relationship can affect sharing and data access. The various relationship types are explained here.
Master/detail relationship
A Master/detail relationship closely links two objects together, so much so that certain behavior of the child record is affected. This includes sharing, where access to the Master (or parent) record gives access to the detail (or child) record. Master/detail relationships also support roll-up summaries.
When Master records are deleted, all child records are deleted. However, un-deleting a Master record restores all child records. When a detail record is deleted, it is moved to the recycle bin. If a detail record is deleted and subsequently the Master record is deleted, the detail record cannot be restored as it no longer has a Master record to associate to.
Many-to-many
Lookup and master-detail relationship types are both one-to-many (where many records can be linked to one other record, for example an account having multiple contacts). Many-to-many relationships (for example, linking a case to more than one custom bug record, and multiple custom bug records to the same case) are represented using two master/detail relationships connected via a junction object (a custom object with two master-detail relationships). Many-to-many relationships can only therefore be used to connect one object to a different object. In our cases and bugs example, we have the standard case object with a master-detail relationship to our BugCaseAssociation junction object, and a custom bug object with a master-detail relationship to our BugCaseAssociation junction object. This can be represented pictorially:

Figure 2.7 – Representing a many-to-many relationship with two master-detail relationships
With master/detail and many-to-many relationships now covered, let's look at the other relationship types.
Lookup relationship
A lookup relationship links two objects together, except that sharing is not affected (and therefore the child object can have separate sharing, unlike that of master-detail relationships where sharing is affected), and roll-up summaries aren't supported. Lookup relationships support linking two objects together, but that can include looking up to records of the same object type (think account hierarchies where an account record can have a parent account record to represent the hierarchy of a company group structure). An object with a lookup relationship to itself is called a self-relationship. The user object should instead use a hierarchy relationship (see the Hierarchical section) when looking up to itself.
External lookup
When linking external object records to a Salesforce standard or custom object, and the external object is the parent object, then an external lookup relationship is used. The standard external ID field on the parent external object is matched against the values of the child object's external lookup relationship field.
Indirect lookup
When linking external object records to a parent object whose data exists in Salesforce as either a standard or custom object, an indirect lookup relationship should be used to associate the records. When creating an indirect lookup, you specify which field in the parent object and which field on the external object to match against and therefore associate records. A custom, unique, external ID field is selected on the parent object to match against the child external object's indirect lookup field, which comes from the external data source.
Hierarchical
Only available on the user object, a hierarchical relationship is a special type of lookup to associate one user to another (where the record does not directly or indirectly refer to itself). Storing a users manager as a lookup to another user record is a common use-case for this functionality.
Now we know the different ways in which we can relate objects and their data to each other, let's look at what happens when performance is affected by relating too many records to a single ancestor record or user.
Custom hierarchy (parent/child) relationships
It is possible to create custom parent/child hierarchies by utilizing a custom Sub object that does a double lookup (of type lookup relationship) on the object you wish to create the parent/child relationship for. One lookup has a name format of Parent, the other Sub. For example, to create a parent/child opportunity relationship, create a custom object called SubOpportunity with a lookup called ParentOpportunity and another SubOpportunity that both look up to the opportunity object. This is explained in more detail at https://help.salesforce.com/s/articleView?id=000326493&type=1.
Overcoming data skew
Automatic scaling is an expected feature of the Salesforce platform, particularly as the count of records for a particular object increases. Customers will demand a consistent level of performance when tens of thousands of records of the same type are present within the system. There are a couple of performance degradations that happen in a couple of select use cases. These are as follows:
- A user owns more than 10,000 records of the same type (such as a user owning over 10,000 account records). This is known as ownership skew.
- A single account record has a large number of child records, such as 10,000 or more contact records with the same account as their AccountId lookup. This is known as account skew.
- Similar to account skew, when a large number of child records (10,000+) are associated with the same parent there can be performance problems. This is known as lookup skew.
We'll look at the causes for each of these and how they can be mitigated.
Ownership skew
When a single user or queue is the owner for more than 10,000 records of a particular type (such as contact), then performance issues due to ownership skew may arise. In Salesforce instances, it is very common to have a default user or queue that owns all otherwise unassigned or unused records. Changes to sharing settings or other sharing-related operations affect performance because re-calculating sharing based on a change of role for the owning user or another sharing-related calculation will result in a long-running Salesforce operation, locking the records while this operation takes place.
Ownership skew mitigation
To mitigate ownership skew, consider the following:
- Based on the data projections for large amounts of records that will result in a single owner (such as a default owner for lead records), consider having multiple owners for such ownership scenarios. Assignment rules are available for leads and cases (standard objects that tend to have high volumes), but other automation techniques are available to assign records based on the criteria of the record to an appropriate owner.
- If one user must be used, performance impacts can be reduced by not assigning the user to a role. This removes any role-based impacts from sharing calculations.
- If the owning user must have a role, then that role should exist at the top of the role hierarchy. The user therefore will not need to be moved around the hierarchy, reducing the impact of sharing calculations being a long-running process.
- Ensure any owning user is not a member of a public group that is used in the criteria for any sharing rules. If this is the case, changes to the record owner will trigger re-calculations of those sharing rules also, further slowing things down.
Account skew
Some standard Salesforce objects maintain a special data relationship to facilitate record access under private sharing models. This is especially true of accounts and opportunities (and, in fact, is how account and opportunity teams are facilitated with regard to sharing and access to select records).
Account skew is the result of an account record having a large number of child records. I've seen this manifest with some clients as a single account record called Unassigned Accounts that has many tens of thousands of child account records that may be old, unused, or otherwise unassigned accounts. This scenario causes issues with performance and record locking.
When updates are made to a child record, Salesforce will lock the parent account record (to maintain record integrity in the database). Therefore, updating a large number of child records under the same account record will potentially cause contention (where multiple processes or operations try to access the same thing at the same time) with trying to lock the parent record (which is done using a separate system thread).
When updates are made to the parent account record, such as changing the owner, then all sharing will have to be recalculated on all child records. This can trigger a chain reaction because sharing rules, role hierarchy calculations, and many other operations related to sharing will have to take place. This will lead to long-running processes and potentially record locking issues.
Account skew mitigation
To mitigate account skew, distribute child records across multiple parent account records. 10,000 is the magic number here. By distributing records across multiple accounts, we can avoid account skew and its performance impacts related to record locking and sharing operations.
Lookup skew
Similar in principle to account skew, lookup skew can happen when there are a large number of child records associated (via the lookup field on those child records) with a single parent record. While account skew is specific to the account object, lookup skew can affect multiple objects.
Lookup skew mitigation
Try the following to mitigate lookup skew:
- Remove unnecessary workflows, process builders, or flows from affected objects in order to reduce saving time when records for affected objects are created or saved.
- Distribute the skew across multiple records. For example, have separate parent object records for the lookups on the child records to reduce or even eliminate record locking and sharing recalculations.
- Use picklist values instead of lookups. This will mean that there won't be linking to actual parent records but reports on those picklist values can instead be used to query the associated data for a given parent record. This mitigation technique doesn't lend itself to large amounts of lookup values, and therefore should only be used when the number of picklist values is low.
Data skew summary
We've explored the three types of data skew in Salesforce and how to mitigate them. When designing an effective data management strategy within Salesforce, be mindful of data skew and how it can affect performance. By designing for data skew from the outset when building a data strategy, even the largest orgs can perform without degradation.
Now we understand the different types of data skew and their impact, let's combine what we've covered throughout this chapter.
Bringing it all together with data modeling
We've covered a lot in this chapter, but now it is time to put the theory into practice and produce something tangible in the form of a data model. Now we know the OWDs we can set, the relationships between objects we can influence, and the owners of records, we can bring them together to produce a data model.
Throughout this book, any data model diagrams will be drawn to the following format (essentially an expanded legend from the example diagram in Chapter 1, Introducing the Salesforce Data Architect Journey):
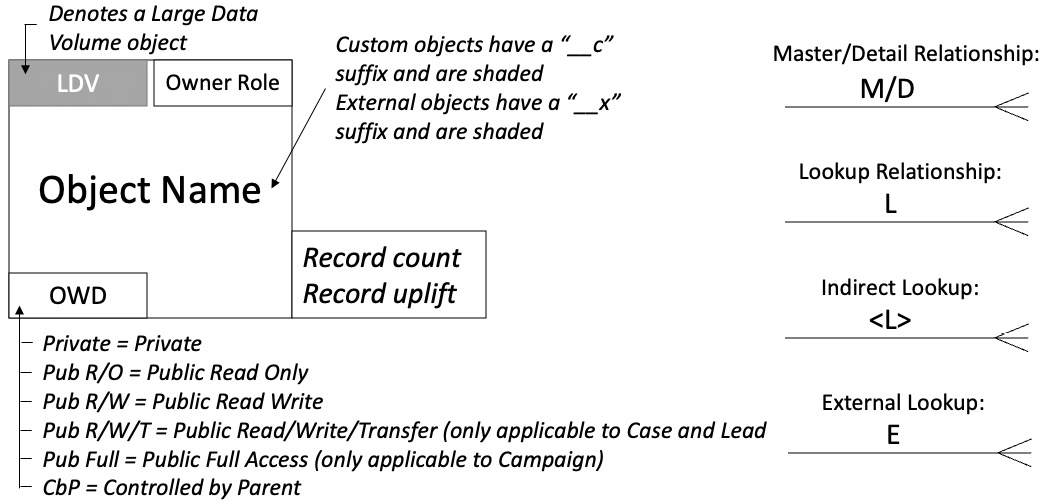
Figure 2.8 – The format for diagramming Salesforce objects used throughout this book
Now we've looked at the data modeling format, let's now look at a data modeling example.
Data modeling example and explanation
With our data modeling format now covered, let's take a look at an example data model to show how much information we can glean from a single artifact. Here's the example, which is similar to the one shared in Chapter 1, Introducing the Salesforce Data Architect Journey:
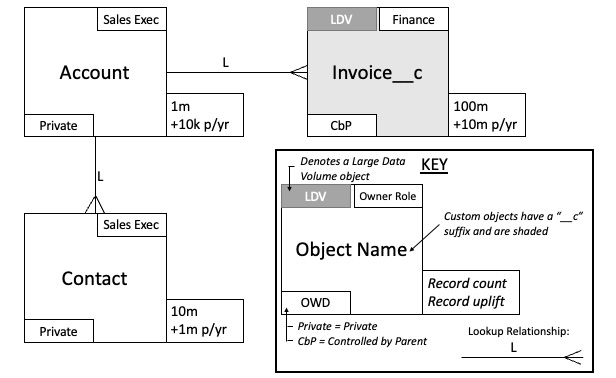
Figure 2.9 – Example data model
Let's look at the data model and see what we can determine from it:
- There is a private OWD model in play, so only record owners of Account and Contact and roles higher up in the role hierarchy will be able to view and edit records (unless records are shared using one of the other methods explained in this chapter, such as manual sharing).
- The Sales Exec role is designated the owner of accounts and contacts, with Finance the owner of the Invoice__c custom object. However, we can see that the OWD for Invoice__c is set to Controlled by Parent, so Sales Exec folks that own account records will be able to view and edit Invoice__c records as well.
- The Invoice__c object has been designated LDV given the amount of data, so we'll need to ensure that we consider data skew. In this instance, we have both account skew and ownership skew to think about, and therefore we should ensure that no account record is the parent of more than 10,000 Invoice__c records, and also no single person from the Finance department owns more than 10,000 Invoice__c records, otherwise performance issues (as explained in the Overcoming data skew section) may occur.
As I'm sure you'll agree, there is a lot of information packed into a seemingly small diagram, but it can quickly be determined what the default data access looks like and the sharing implications of the relationships, and we also get early insight into any LDV implications.
When answering practice questions related to data access and its effect on other objects, try to visualize how the question could be represented in a diagram where it makes sense to do so in order to get to the right answer.
The Importance of the Data Model in the Certified Technical Architect (CTA) review board
Those of you who are looking to pursue the CTA review board will be required to produce a data model that's similar in nature to what we will produce throughout this book. The data model is considered a core artifact of the review board, and as such it is important that you know how to quickly produce clear data model diagrams that convey the right level of information.
Summary
We've started our learning journey and begun with concepts around data modelling and design. We've covered sharing and security, delving into the various mechanisms available in Salesforce to control access to data. We've paid particular attention to how the OWDs and role hierarchy can have a profound impact on the data that your users can access. We've seen how OWDs affect data model design for solutions on the Salesforce platform, and why it is important to get these right based on a solid understanding of the impact of a particular OWD setting when building Salesforce solutions that address customer requirements.
We've also covered the different object types available on the platform, highlighting the differences between standard, custom, external, and big objects and the various use cases for each. Again, the use of certain object types (and in particular big objects and external objects) can affect the user experience with regard to data access.
We've covered relationships and their effect on Salesforce functionality and data access, and we've seen the different methods of objects and their data together on the Salesforce platform, highlighting how we relate data held in external data sources with that held within Salesforce.
We've also looked at performance around data with regard to data skew and the methods available to mitigate the impacts of a user owning more than 10,000 records or an account being the parent account for more than 10,000 child records.
With a solid grounding in the concepts highlighted in this chapter, you now understand why it is important to plan for the future from the outset of the design on your Salesforce data model to mitigate the risks associated with data skew and other factors that affect performance.
Lastly, we brought together the concepts when modeling data solutions and introduced a standard for data model diagrams.
In Chapter 3, Master Data Management, we'll dive into what Master Data Management (MDM) is and learn how to effectively design and implement an MDM strategy on the Salesforce platform. We'll look at the concept of a golden record, preserve data traceability across multiple data sources, and learn how this affects the context in which business rules run.
Practice questions
- The Public Read/Write/Transfer OWD is applicable to which objects?
- Performance issues related to an account record that has more than 10,000 child records is known as what?
- What OWD is available for the campaign object that isn't available to others?
- What type of Salesforce object is used to access data held in an external system in real time?
- True or false: Big objects will store multiple commits of the same representation of a row of data.
- What OWD causes the object to inherit the same data access permissions as the object it is associated with?
- How is a many-to-many relationship created?
- What type of relationship is only available on the user object?
- What happens to the child records when a master record in a master-detail relationship gets deleted?
- True or false: sharing the child object is affected when using a lookup relationship.
Answers
- Lead and case.
- Account skew.
- Public Full Access.
- External object.
- False – Big objects only store a single row for multiple commits of the same representation of data.
- Controlled by Parent.
- Two master-detail relationships, one on each object, relating them to each other.
- Hierarchical relationship.
- Child records are also deleted.
- False.
Further reading
- Data Access in Salesforce: https://developer.salesforce.com/docs/atlas.en-us.dat.meta/dat/dat_components.htm
- Salesforce Standard Objects: https://developer.salesforce.com/docs/atlas.en-us.api.meta/api/sforce_api_objects_list.htm
- Salesforce Data Model Diagrams: https://architect.salesforce.com/diagrams#template-gallery
- Salesforce Object Relationships Overview: https://help.salesforce.com/articleView?id=overview_of_custom_object_relationships.htm&type=0
- Restriction Rules: https://help.salesforce.com/s/articleView?id=release-notes.rn_forcecom_sharing_restriction_rules.htm&type=5&release=234