
Welcome to Day 18! Today you'll learn about Java's connection to Extensible Markup Language (XML) and Extensible Stylesheet Language Transformations (XSLT). Java 1.4 has been augmented to contain a great deal of functionality for working with both XML and XSLT, and you'll see what's available. Here are today's topics:
Creating XML documents
Sending XML documents to the browser using JSP
Parsing XML documents with DOM techniques
Parsing XML documents with SAX techniques
Using XSLT to transform XML into HTML
There's a lot coming up today—starting with XML itself.
XML has become the new standard for sending data on the Internet, and you can decode that data using Java. You can send and receive data on the Internet using XML, as well as create and decipher XML documents.
Like HTML, XML is text-based. Unlike HTML, you're free to create your own tags—you're not restricted to the tags that an HTML browser already understands, such as <P> and <INPUT>. That's both liberating and constricting—although you're now free to structure your own documents from top to bottom, it's also true that browsers will have no idea what to do with the elements in your XML document. The browser can't know, for example, that you mean the tag <RED> to indicate red text.
Tip
You can check out the official W3C recommendation for XML at www.w3.org/TR/REC-xml. W3C maintains the specifications for XML and XSLT.
<?xml version="1.0"?>
<PLANETS>
.
.
.
</PLANETS>
If you want to, you could also specify the encoding for the character set you're using with the encoding attribute, such as the 8-bit Unicode here:
<?xml version="1.0" encoding="UTF-8"?>
<PLANETS>
.
.
.
</PLANETS>
Each planet will have a <PLANET> element, containing elements like <NAME> to store the planet's name, <MASS> to store its mass, and so on—note that XML elements can have attributes, and you can also use HTML-style comments in XML documents, as you see here:
<?xml version="1.0"?>
<PLANETS>
<PLANET>
<NAME>Mercury</NAME>
<MASS UNITS="(Earth = 1)">.0553</MASS>
<DAY UNITS="days">58.65</DAY>
<RADIUS UNITS="miles">1516</RADIUS>
<DENSITY UNITS="(Earth = 1)">.983</DENSITY>
<DISTANCE UNITS="million miles">43.4</DISTANCE><!--At perihelion-->
</PLANET>
.
.
.
Here's what the sample XML document looks like with all the planets installed:
<?xml version="1.0"?>
<PLANETS>
<PLANET>
<NAME>Mercury</NAME>
<MASS UNITS="(Earth = 1)">.0553</MASS>
<DAY UNITS="days">58.65</DAY>
<RADIUS UNITS="miles">1516</RADIUS>
<DENSITY UNITS="(Earth = 1)">.983</DENSITY>
<DISTANCE UNITS="million miles">43.4</DISTANCE><!--At perihelion-->
</PLANET>
<PLANET>
<NAME>Venus</NAME>
<MASS UNITS="(Earth = 1)">.815</MASS>
<DAY UNITS="days">116.75</DAY>
<RADIUS UNITS="miles">3716</RADIUS>
<DENSITY UNITS="(Earth = 1)">.943</DENSITY>
<DISTANCE UNITS="million miles">66.8</DISTANCE><!--At perihelion-->
</PLANET>
<PLANET>
<NAME>Earth</NAME>
<MASS UNITS="(Earth = 1)">1</MASS>
<DAY UNITS="days">1</DAY>
<RADIUS UNITS="miles">2107</RADIUS>
<DENSITY UNITS="(Earth = 1)">1</DENSITY>
<DISTANCE UNITS="million miles">128.4</DISTANCE><!--At perihelion-->
</PLANET>
</PLANETS>
The details of setting up a DTD or XML schema are involved and beyond the scope of this book, but you can see a DTD for the sample XML document, ch18_01.xml, in Listing 18.1 (the DTD is in the highlighted lines). Keep in mind that the previous version of this document, without the DTD, is fine too—both are well-formed XML documents—but if you also want the browser to check the syntax of the document to make sure it's okay, you can make it a valid document by including a DTD or XML schema.
Example 18.1. A Sample XML Document (ch18_01.xml)
<?xml version="1.0"?> <!DOCTYPE PLANETS [ <!ELEMENT PLANETS (PLANET*)> <!ELEMENT PLANET (NAME, MASS, DAY, RADIUS, DENSITY, DISTANCE)> <!ELEMENT NAME (#PCDATA)> <!ELEMENT MASS (#PCDATA)> <!ELEMENT DAY (#PCDATA)> <!ELEMENT RADIUS (#PCDATA)> <!ELEMENT DENSITY (#PCDATA)> <!ELEMENT DISTANCE (#PCDATA)> <!ATTLIST MASS UNITS CDATA #IMPLIED> <!ATTLIST DAY UNITS CDATA #IMPLIED> <!ATTLIST RADIUS UNITS CDATA #IMPLIED> <!ATTLIST DENSITY UNITS CDATA #IMPLIED> <!ATTLIST DISTANCE UNITS CDATA #IMPLIED> ]> <PLANETS> <PLANET> <NAME>Mercury</NAME> <MASS UNITS="(Earth = 1)">.0553</MASS> <DAY UNITS="days">58.65</DAY> <RADIUS UNITS="miles">1516</RADIUS> <DENSITY UNITS="(Earth = 1)">.983</DENSITY> <DISTANCE UNITS="million miles">43.4</DISTANCE><!--At perihelion--> </PLANET> <PLANET> <NAME>Venus</NAME> <MASS UNITS="(Earth = 1)">.815</MASS> <DAY UNITS="days">116.75</DAY> <RADIUS UNITS="miles">3716</RADIUS> <DENSITY UNITS="(Earth = 1)">.943</DENSITY> <DISTANCE UNITS="million miles">66.8</DISTANCE><!--At perihelion--> </PLANET> <PLANET> <NAME>Earth</NAME> <MASS UNITS="(Earth = 1)">1</MASS> <DAY UNITS="days">1</DAY> <RADIUS UNITS="miles">2107</RADIUS> <DENSITY UNITS="(Earth = 1)">1</DENSITY> <DISTANCE UNITS="million miles">128.4</DISTANCE><!--At perihelion--> </PLANET> </PLANETS>
Some browsers, like Internet Explorer, let you view XML documents directly—and you can see ch18_01.xml in Internet Explorer in Figure 18.1.
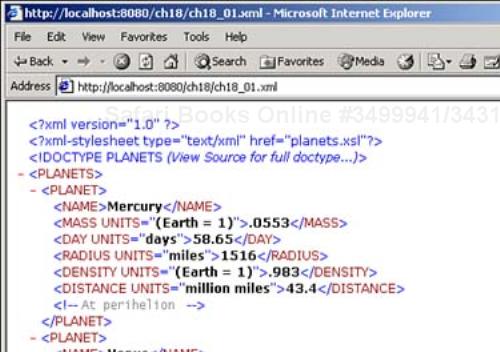
That's fine if you want to download an XML document directly from the browser—the server knows it's an XML document because of the .xml extension, and lets the browser know. But what if you want to send an XML document from JSP? When you're using out.println, there is no file extension to let the browser know what kind of data you're sending.
It turns out to be easy enough to let the browser know that the document you're sending to the browser is an XML document—you just have to use the contentType attribute of the page directive, setting it to "application/xml":
<%@ page contentType="application/xml" import="java.sql.*" %>
For example, take a look at Listing 18.2, which contains an example that connects to the pubs database, reads the publisher name and ID fields from the Publishers table, and displays the result as an XML document. (Note that the code goes to some length to replace the "&" character in publisher's names with "and", because "&" is a special character with special meaning for browsers, and Internet Explorer has trouble with it.)
Example 18.2. Implementing Database Lookup (ch18_02.jsp)
<%@ page contentType="application/xml" import="java.sql.*" %>
<% Class.forName("sun.jdbc.odbc.JdbcOdbcDriver") ; %>
<?xml version="1.0"?>
<publishers>
<%
Connection connection = DriverManager.getConnection(
"jdbc:odbc:data", "Steve", "password");
Statement statement = connection.createStatement() ;
ResultSet resultset =
statement.executeQuery("select pub_name, pub_id from Publishers") ; %>
<%
while(resultset.next()){
%>
<publisher>
<<%=resultset.getMetaData().getColumnName(1)%>>
<%
String s = resultset.getString(1);
int index = s.indexOf("&");
StringBuffer sb = new StringBuffer(s);
if(index > 0){
sb.replace(index, index + 1, "and");
}
out.println(sb);
%>
</<%=resultset.getMetaData().getColumnName(1)%>>
<<%=resultset.getMetaData().getColumnName(2)%>>
<%= resultset.getString(2) %>
</<%=resultset.getMetaData().getColumnName(2)%>>
</publisher>
<%
}
%>
</publishers>
You can see the results in Figure 18.2.
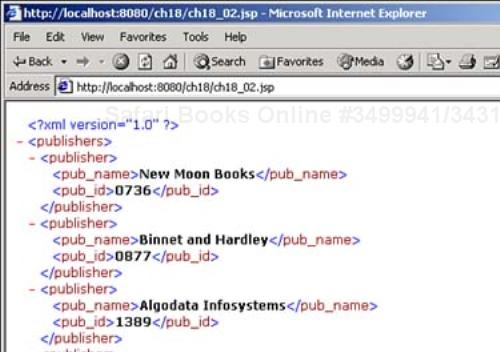
The Java API (Application Programming Interface) for XML Processing (JAXP) supports the processing of XML documents using DOM, SAX, and XSLT, and you're going to see all three today. In previous versions of Java, JAXP was a separate package that you downloaded and installed separately. However, as of Java 1.4, JAXP is built into Java, no separate downloading required.
Note
If you're using a version of Java before 1.4, you'll need to download JAXP. Currently, the download page is http://java.sun.com/xml/downloads/javaxmlpack.html (if that page doesn't exist when you read this, go to http://java.sun.com/xml). After downloading, place jaxp-api.jar and xalan.jar in jakarta-tomcat-4.0.3lib in order to run today's examples.
JAXP itself consists of four packages:
javax.xml.parsers—. The JAXP APIs.org.w3c.dom—. Defines theDocumentclass, as well as classes for Document Object Model (DOM) parsing.org.xml.sax—. Defines the basic classes for Simple API for XML (SAX) parsing.javax.xml.transformDefines the XSLT APIs that let you transform XML into other forms.
The W3C Document Object Model (DOM) interprets XML documents as a tree of nodes, and you can use various Java methods to move through such trees. Specifically, DOM parsing turns the XML document into a tree of Java Node objects that you can access in your code, moving around the tree and getting node values at will. You'll see a DOM XML example later on.
Tip
You can read more about the W3C DOM at http://www.w3.org/DOM/DOMTR.
This example, ch18_03.jsp, will simply read in the sample XML document ch18_01.xml and work its way through it, reading element names, attributes and attribute values, and so on. The code will simply display these parts of the original document, mirroring that document in the output (except the output will be HTML, not XML). Once you know how to read an XML document in this way, you can implement your own processing of each element to handle the data the XML document represents.
This example creates a method named displayDocument, to which you pass the URL of the XML document you want to work with. The code will read through that XML document and return to you an HTML version, ready for displaying in a browser. In the displayDocument method, the code creates a new DocumentBuilderFactory object, which it uses to create a DocumentBuilder object. You can use the DocumentBuilder object's parse method to parse the XML document itself and get a Document object, which contains the DOM tree of nodes for the document. This code then passes that Document object on to another method, display, which displays the XML document using the document tree. Here's what the code that actually parses the document and creates the parsed Document object looks like:
public String[] displayDocument(String uri)
{
DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance();
DocumentBuilder db = null;
try {
db = dbf.newDocumentBuilder();
}
catch (ParserConfigurationException pce) {}
Document document = null;
document = db.parse(uri);
display(document, "");
.
.
.
The display method, which you'll see in a moment, will decode the entire XML document from the Document object and display it. You can see the methods of the javax.xml.parsers.DocumentBuilderFactory class in Table 18.1, and the methods of the javax.xml.parsers.DocumentBuilder class in Table 18.2. You can see the methods of the org.w3c.dom.Document interface—which the preceding code uses to store the parsed XML document—in Table 18.3.
Table 18.1. Methods of the javax.xml.parsers.DocumentBuilderFactory Class
Table 18.2. Methods of the javax.xml.parsers.DocumentBuilder Class
Method | Does This |
|---|---|
| The default constructor. |
| |
| |
| True if this parser is configured to validate XML documents. |
| Returns a new instance of a DOM |
| Parses the content of the file as an XML document and returns a new DOM Document object. |
| Parses the content of the specified source as an XML document and returns a new DOM |
| Parses the content of the specified |
| Parses the content of the specified |
| Parses the content of the specified URI as an XML document and returns a new DOM |
| Specifies the |
|
Table 18.3. Methods of the org.w3c.dom.Document Interface
Tip
For more about the node types in the W3C DOM, visit http://www.w3.org/TR/2000/REC-DOM-Level-2-Core-20001113/core.html#ID-1950641247.
Table 18.4. Fields of the Node Interface
Field | Means This |
|---|---|
| |
| The node is an XML CDATA section. |
| The node is a comment. |
| The node is a document fragment. |
| The node is a document. |
| The node is a document type node. |
| The node is an element. |
| The node is an XML entity. |
| The node is an entity reference. |
| The node is an XML notation. |
| The node is a processing instruction (much like a directive in JSP). |
|
In ch18_03.jsp, the display method in this example works through all the nodes in the parsed Document object using a Java switch statement to handle the node types you see in Table 18.3. This method converts the entire document into an array of HTML strings named displayStrings that you can send back to the browser, displaying the original XML document using HTML.
For example, if the current node is an element node, you can use the getNodeName method to get the name of the element and store that name in the array of strings like this (note that this example also indents the HTML output using HTML non-breaking spaces, stored in a variable named indent):
public void display(Node node, String indent)
{
if (node == null) {
return;
}
int type = node.getNodeType();
switch (type) {
.
.
.
case Node.ELEMENT_NODE: {
displayStrings[numberDisplayLines] = indent;
displayStrings[numberDisplayLines] += "<";
displayStrings[numberDisplayLines] += node.getNodeName();
.
.
.
That's how you can get the name of the current node—using Node interface's getNodeName method. You can see all the methods of this interface, org.w3c.dom.Node, in Table 18.5.
Table 18.5. Methods of the org.w3c.dom.Node Interface
Method | Does This |
|---|---|
| Adds the specified node to the end of the list of children of the current node. |
| Returns a duplicate of this node. |
| Returns the attributes of this node if it is an |
| Returns all the children of this node. |
| Returns the first child of this node. |
| Returns the last child of this node. |
| Returns the local part of the full name of this node. |
| Returns the namespace URI of this node. |
| Returns the node following this node. |
| Returns the name of this node. |
| Returns the type of node's object, as defined in Table 18.4. |
| Returns the value of this node. |
| Returns the |
| Returns the parent of this node. |
| Returns the namespace prefix of this node. |
| |
| True if this node has any attributes. |
| True if this node has any children. |
| Inserts the new node before the existing reference child node. |
| True if the specific feature is implemented. |
| Puts all |
| Removes the child node and returns it. |
| Replaces the child node in the list of children, and returns the old child node. |
| Sets the value of a node. |
|
You can use the getAttributes method to get any possible attributes in the element, and the getNodeName and getNodeValue methods to get the attribute's name and value, so you can display those attributes using code like this:
case Node.ELEMENT_NODE: {
displayStrings[numberDisplayLines] = indent;
displayStrings[numberDisplayLines] += "<";
displayStrings[numberDisplayLines] += node.getNodeName();
int length = (node.getAttributes() != null) ? node.getAttributes().getLength() : 0;
Attr attributes[] = new Attr[length];
for (int loopIndex = 0; loopIndex < length; loopIndex++) {
attributes[loopIndex] = (Attr)node.getAttributes(). item(loopIndex);
}
for (int loopIndex = 0; loopIndex < attributes.length; loopIndex++) {
Attr attribute = attributes[loopIndex];
displayStrings[numberDisplayLines] += " ";
displayStrings[numberDisplayLines] += attribute. getNodeName();
displayStrings[numberDisplayLines] += "="";
displayStrings[numberDisplayLines] += attribute. getNodeValue();
displayStrings[numberDisplayLines] += """;
}
displayStrings[numberDisplayLines] += ">";
.
.
.
Finally, you can check whether this element has any child elements with the getChildNodes method, which returns a NodeList element, and loop over each child element, calling display and any child elements it has recursively:
case Node.ELEMENT_NODE: {
displayStrings[numberDisplayLines] = indent;
displayStrings[numberDisplayLines] += "<";
displayStrings[numberDisplayLines] += node.getNodeName();
int length = (node.getAttributes() != null) ? node. getAttributes().getLength() : 0;
Attr attributes[] = new Attr[length];
for (int loopIndex = 0; loopIndex < length; loopIndex++) {
attributes[loopIndex] = (Attr)node.getAttributes(). item(loopIndex);
}
for (int loopIndex = 0; loopIndex < attributes.length; loopIndex++) {
Attr attribute = attributes[loopIndex];
displayStrings[numberDisplayLines] += " ";
displayStrings[numberDisplayLines] += attribute. getNodeName();
displayStrings[numberDisplayLines] += "="";
displayStrings[numberDisplayLines] += attribute. getNodeValue();
displayStrings[numberDisplayLines] += """;
}
displayStrings[numberDisplayLines] += ">";
numberDisplayLines++;
NodeList childNodes = node.getChildNodes();
if (childNodes != null) {
length = childNodes.getLength();
indent += " ";
for (int loopIndex = 0; loopIndex < length; loopIndex++ ) {
display(childNodes.item(loopIndex), indent);
}
}
break;
}
You can process the other types of nodes and display the array of strings created, as you see in Listing 18.3. And that's how DOM parsing works—after creating a Document object, you can use methods like getChildNodes, getNextSibling, and getPreviousSibling to move through the node tree, and methods like getNodeName, getNodeValue, and getAttributes to work with those nodes. DOM parsing turns the entire XML document into Java objects that you can access in code.
Example 18.3. Parsing an XML Document with DOM Techniques (ch18_03.jsp)
<%@ page import="javax.xml.parsers.*, org.xml.sax.*, org.xml.sax.helpers.*, org.w3c.dom.*,java.io.*" %> <%! public class xparser { String displayStrings[] = new String[1000]; int numberDisplayLines = 0; public String[] displayDocument(String uri) { try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = null; try { db = dbf.newDocumentBuilder(); } catch (ParserConfigurationException pce) {} Document document = null; document = db.parse(uri); numberDisplayLines = 0; display(document, ""); } catch (Exception e) { e.printStackTrace(System.err); } return displayStrings; } public void display(Node node, String indent) { if (node == null) { return; } int type = node.getNodeType(); switch (type) { case Node.DOCUMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<?xml version="1.0" encoding=""+ "UTF-8" + ""?>"; numberDisplayLines++; display(((Document)node).getDocumentElement(), ""); break; } case Node.ELEMENT_NODE: { displayStrings[numberDisplayLines] = indent; displayStrings[numberDisplayLines] += "<"; displayStrings[numberDisplayLines] += node.getNodeName(); int length = (node.getAttributes() != null) ? node. getAttributes()
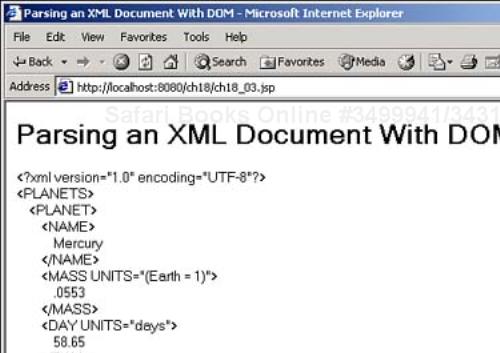
You can see the results in Figure 18.3, which shows the sample XML document parsed and converted to HTML, line by line. That's how it works in DOM parsing—the entire document is presented to you as a tree of Java Node objects, and you can move those objects around and access them using Java methods.
SAX functions with callback methods, one for each part of a document, that are called by Java as the document is parsed. All you need to do is override the methods you want to handle. Here are some of the SAX methods you can use to handle the various parts of an XML document you're parsing:
startDocument—. Called when the start of the document is encountered.endDocument—. Called when the end of the document is encountered.startElement—. Called when the opening tag of an element is encountered.endElement—. Called when the closing tag of an element is encountered.characters—. Called when the XML parser sees text characters.
These methods are called automatically when a SAX parser parses your document, and you can handle each element on a case-by-case basis. Where do the methods you override come from? They're built into the org.xml.sax.helpers.DefaultHandler class, so you start by deriving a new class—which will simply be called parser here—from that class:
<%@ page import="org.xml.sax.*, org.xml.sax.helpers.DefaultHandler, javax.xml.parsers.*,
You can see the methods of the DefaultHandler class in Table 18.6.
Table 18.6. Methods of the org.xml.sax.helpers.DefaultHandler Class
Now you can override the methods you want to handle the various parts of the XML document, such as the start of the whole document, the beginning of an element, and so on:
<%@ page import="org.xml.sax.*, org.xml.sax.helpers.DefaultHandler, javax.xml.parsers.*,
So how do you actually connect the XML document to your code? This example will use a method named parse to which you pass the name of the file. The parse method creates a new object of the SAXParserFactory class, which is then used to create a new object of the SAXParser class. You can pass the SAXParser object's parse method the name of the file to parse, as well as the object that implements the callback methods, like startElement; in this case, that object is the current object, which you can specify with the Java this keyword:
<%@ page import="org.xml.sax.*, org.xml.sax.helpers.DefaultHandler, javax.xml.parsers.*,
You can see the methods of the javax.xml.parsers.SAXParserFactory class in Table 18.7, and the methods of the javax.xml.parsers.SAXParser class in Table 18.8.
Table 18.7. Fields of the javax.xml.parsers.SAXParserFactory Interface
Table 18.8. Methods of the SAXParser Class
Now you can add code to methods like startElement to handle the parsing of the document. As in the DOM example, this SAX example will mirror the document and display it. Here's what the startElement method looks like—note that this method is passed an object that holds all the attributes of the current element, which makes displaying those attributes and their values easy:
public void startElement(String namespaceURI, String localName, String qualifiedName,
In the same way, you can add code to handle the end of elements, and so on, as you see in Listing 18.4.
Example 18.4. SAX Parsing an XML Document (ch18_04.jsp)
<%@ page import="org.xml.sax.*, org.xml.sax.helpers.DefaultHandler, javax.xml.parsers.*,
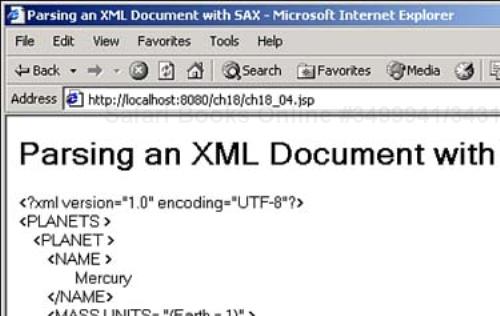
You can see the results in Figure 18.4, which shows the parsed document. Compare this figure showing SAX parsing of ch18_01.xml to Figure 18.3 showing DOM parsing of the same document—as you can see, you can get the same results with either type of parsing.
The preceding XML parsing examples parse ch18_01.xml and display the results as HTML to show how parsing works—but in fact, there's a more direct way to convert XML documents into HTML using JSP. You can use Extensible Stylesheet Language Transformations (XSLT) to translate XML documents into other forms—HTML, plain text, Microsoft Word .doc files, XHTML (W3C's XML-compliant form of HTML), and so on. And the XSLT APIs defined in javax.xml.transform let you perform these kinds of transformations.
Tip
You can check out the W3C recommendations for XSLT at www.w3.org/TR/xslt20.
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
.
.
.
XSLT stylesheets that convert XML to HTML are actually much like JSP pages in one respect—you embed the HTML you want to use directly in the document, and use special elements to do the processing itself. In XSLT, that works by creating templates with the <xsl:template> element. Each template can match an element in the XML document, and the template's contents are used in the output instead of the original element. For example, to replace the <PLANETS> document element, you can use this template to start the HTML table that will display the results:
<xsl:template match="/PLANETS">
<HTML>
<HEAD>
<TITLE>
The Planets Table
</TITLE>
</HEAD>
<BODY>
<H1>
The Planets Table
</H1>
<TABLE BORDER="1">
<TD>Name</TD>
<TD>Mass</TD>
<TD>Radius</TD>
<TD>Day</TD>
<xsl:apply-templates/>
</TABLE>
</BODY>
</HTML>
</xsl:template>
Notice the <xsl:apply-templates/> element here. That element makes XSLT search for other templates to match the child elements of the <PLANETS> element. The child elements of the <PLANETS> elements are <PLANET> elements, so you can create a new template to match <PLANET> elements next. That new template will insert the name of each planet into the output using an XSLT <xsl:value-of> element, and use an <xsl:apply-templates> element to apply additional templates for the <MASS>, <RADIUS>, and <DAY> subelements:
<xsl:template match="PLANET">
<TR>
<TD><xsl:value-of select="NAME"/></TD>
<TD><xsl:apply-templates select="MASS"/></TD>
<TD><xsl:apply-templates select="RADIUS"/></TD>
<TD><xsl:apply-templates select="DAY"/></TD>
</TR>
</xsl:template>
In each of the <MASS>, <RADIUS>, and <DAY> templates, you can extract the value of the current element (for example, that's 58.65 in the element <DAY UNITS="days">58.65 </DAY>) and the units for that value using the UNITS attribute (that's "days" in the element <DAY UNITS="days">58.65</DAY>) like this—note that a dot (.) stands for the current element, and that you preface the name of an attribute with an ampersand (@):
<xsl:template match="MASS">
<xsl:value-of select="."/>
<xsl:text> </xsl:text>
<xsl:value-of select="@UNITS"/>
</xsl:template>
The <xsl:text> </xsl:text> element inserts a space between the element's value and the units. And that's all you need—you can see the entire stylesheet in Listing 18.5, ch18_05.xsl (note that XSLT stylesheets usually have the extension .xsl).
Example 18.5. Implementing Database Lookup (ch18_05.xsl)
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/PLANETS"> <HTML> <HEAD> <TITLE> The Planets Table </TITLE> </HEAD> <BODY> <H1> The Planets Table </H1> <TABLE BORDER="1"> <TD>Name</TD> <TD>Mass</TD> <TD>Radius</TD> <TD>Day</TD> <xsl:apply-templates/> </TABLE> </BODY> </HTML> </xsl:template> <xsl:template match="PLANET"> <TR> <TD><xsl:value-of select="NAME"/></TD> <TD><xsl:apply-templates select="MASS"/></TD> <TD><xsl:apply-templates select="RADIUS"/></TD> <TD><xsl:apply-templates select="DAY"/></TD> </TR> </xsl:template> <xsl:template match="MASS"> <xsl:value-of select="."/> <xsl:text> </xsl:text> <xsl:value-of select="@UNITS"/> </xsl:template> <xsl:template match="RADIUS"> <xsl:value-of select="."/> <xsl:text> </xsl:text> <xsl:value-of select="@UNITS"/> </xsl:template> <xsl:template match="DAY"> <xsl:value-of select="."/> <xsl:text> </xsl:text> <xsl:value-of select="@UNITS"/> </xsl:template> </xsl:stylesheet>
So how do you put this stylesheet to work? You use an object of the JAXP Transformer class, and you can get such an object using the JAXP TransformerFactory class. The transformer object is going to do the actual XSLT transformation of ch18_01.xml, and when you create it using the newTransformer method of a TransformerFactory object, you pass it the stylesheet to use, which is ch18_05.xsl in this case. To pass it that stylesheet, you can pass the newTransformer method a Java StreamSource object connected to that stylesheet:
try
{
TransformerFactory transformerfactory = TransformerFactory. newInstance();
Transformer transformer = transformerfactory.newTransformer(new StreamSource(new File
(application.getRealPath("/") + "ch18_05.xsl")));
.
.
.
}
catch(Exception e) {}
Now the new Transformer object is ready to use the stylesheet you created to transform documents. You can see the methods of the TransformerFactory class in Table 18.9, the methods of the Transformer class in Table 18.10, and the methods of the StreamSource class in Table 18.11.
Table 18.9. Methods of the TransformerFactory Class
Table 18.10. Methods of the javax.xml.transform.Transformer Class
Table 18.11. Methods of the javax.xml.transform.stream.StreamSource Class
Method | Does This |
|---|---|
| The default constructor. |
| |
| Constructs a |
| Constructs a |
| |
| Constructs a |
| Gets the byte stream that was set with |
| Gets the public identifier that was set with |
| Gets the character stream that was set with |
| Gets the system identifier that was set with |
| Sets the byte stream to be used as input. |
| Sets the public identifier for this |
| Sets the input to be a character reader. |
| Sets the system ID from a |
|
To actually perform the XSLT transformation of ch18_01.xml into an HTML document called, say, ch18_07.html, you use the transformer object's transform method. You can pass this method a StreamSource object corresponding to the XML document to transform, ch18_01.xml, and a new StreamResult object corresponding to the new HTML document to create, ch18_07.html:
try
{
TransformerFactory transformerfactory = TransformerFactory. newInstance();
Transformer transformer = transformerfactory.newTransformer(new StreamSource(new File
(application.getRealPath("/") + "ch18_05.xsl")));
transformer.transform(new StreamSource(new File(application. getRealPath("/") +
"ch18_01.xml")),
new StreamResult(new File(application.getRealPath("/") + "ch18_07.html")));
}
catch(Exception e) {}
You can see the methods of the StreamResult class in Table 18.12.
Table 18.12. Methods of the javax.xml.transform.stream.StreamResult Class
Method | Does This |
|---|---|
| The default constructor. |
| |
| Constructs a |
| Constructs a |
| Constructs a |
| Gets the byte stream that was set with |
| Gets the system identifier that was set with |
| Gets the character stream that was set with |
| Sets the |
| Sets the system ID from a |
| Sets the system ID that may be used in association with the byte or character stream. |
|
Using the transform method transforms ch18_01.xml into ch18_07.html. To display that HTML in the output, you can use a BufferedReader object (as discussed in Day 15, “Handling Files on the Server,”) as you see in Listing 18.6. (Alternatively, you could also use a <jsp:include> element.)
Example 18.6. Implementing XSLT Transformations (ch18_06.jsp)
<%@ page import="javax.xml.transform.*, javax.xml.transform.stream.*, java.io.*" %> <% try { TransformerFactory transformerfactory = TransformerFactory. newInstance(); Transformer transformer = transformerfactory.newTransformer(new StreamSource(new File (application.getRealPath("/") + "ch18_05.xsl"))); transformer.transform(new StreamSource(new File(application. getRealPath("/") + "ch18_01.xml")), new StreamResult(new File(application.getRealPath("/") + "ch18_07.html"))); } catch(Exception e) {} FileReader filereader = new FileReader(application.getRealPath("/") + "ch18_07.html"); BufferedReader bufferedreader = new BufferedReader(filereader); String instring; while((instring = bufferedreader.readLine()) != null) { %> <%= instring %> <% } filereader.close(); %>
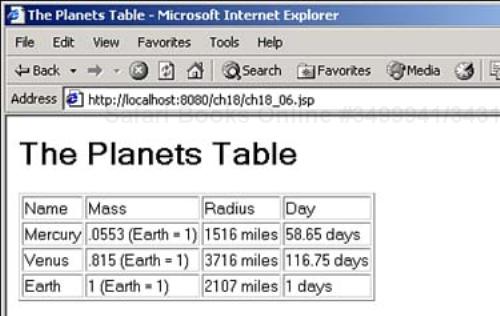
You can see the results in Figure 18.5, where the XML document has been formatted nicely into an HTML table.
Today you got an introduction to working with XML and XSLT in JSP. Java 1.4 comes with a great deal of built-in power to handle both XML and XSLT.
You learned how to create XML documents, and how to display them in Internet Explorer. You also learned that you can send XML back to the browser by setting the page directive's contentType attribute to a value like application/xml.
As of Java 1.4, these JAXP packages are built into Java to handle XML and XSLT:
javax.xml.parsersorg.w3c.domorg.xml.saxjavax.xml.transform
You learned how to use these packages and the classes in them to parse XML documents using DOM techniques. In that case, you create a Document object that represents the XML document as a tree of nodes, and navigate through the tree.
You learned how to use SAX techniques to parse a document using callback techniques, where methods like startDocument, startElement, and endElement let you handle the parts of a document.
Finally, you got an introduction to XSLT, which enables you to transform XML documents into various other forms, such as HTML, plain text, XHTML, and so on.
Tomorrow, we'll turn to a new topic—using the Struts framework, which is designed to help you create JSP applications easily.
Are there any other XML parsing and XSLT transforming Java packages out there? | |
A1: | There sure are—for example, the Apache project (related to the team who brings you the Tomcat server), supports the Xerces XML parser and the Xalan XSLT transformer. See http://xml.apache.org/ for more information. For that matter, there are XML and XSLT tools in Microsoft Internet Explorer called MSXML, and they'll not only parse XML documents, but can also perform XSLT transformations. Take a look at http://msdn.microsoft.com/library/default.asp?url=/nhp/Default.asp?contentid=28000438. |
Which is better, DOM or SAX parsing? | |
A2: | That really depends on your style and needs—which is to say, it's a matter of taste. If you're familiar with working with node trees, the DOM techniques will be easier, but many people find SAX parsing, with its callback methods, easier than DOM parsing. |
This workshop tests whether you understand all the concepts you learned today. It's a good idea to master today's concepts by honing your knowledge here before starting tomorrow's material. You can find the answers to the quiz questions in Appendix A.