
We have covered a number of technologies and toolkits in the previous chapters that, when combined together, offer a great opportunity to build modern and scalable-reactive web applications in Scala. Scala now celebrates 10 years of existence with an active community and large corporations supporting it, leading to a perpetual exploration of innovative ideas touching the language and the ecosystem.
We propose, in this last chapter, to touch upon a few areas where we have found some exciting ongoing projects or technologies and where we feel that Scala can provide elegant solutions to be both productive and fun. We will cover some of the following aspects:
- NoSQL database access through MongoDB
- Introducing DSLs and in particular, a glimpse at Parser Combinators
- Scala.js—compiling Scala to JavaScript on the client side
As the volume of information to process and store has drastically increased in the past few years, many IT shops have been looking for alternatives to traditional relational databases to store and query data. The not only SQL (NoSQL) database movement has gained popularity as a way to trade consistency and structure of the data for more efficient or flexible data storage. MongoDB (www.mongodb.org) is a database product designed to store documents in formats, such as JSON, and with no strict database schema. Along with the Java driver built to access and query a MongoDB database, we are going to discover how the Casbah Scala toolkit (https://github.com/mongodb/casbah) can be used to conveniently access and query such a database through a DSL.
The only requirement to start experimenting with Casbah is to add its .jar library dependency to an SBT or Play project. In a new directory on your disk, type > play new ch10samples from a terminal window and add the Casbah dependency to the build.sbt file in the root directory of the project. This dependency is added by adding the following code (note that the given version of Casbah was the latest available at the time of writing this chapter, but should soon be available as the final version 2.7.0):
name := "ch10samples" version := "1.0-SNAPSHOT" libraryDependencies ++= Seq( jdbc, anorm, cache, "org.mongodb" %% "casbah" % "2.7.0-RC1" ) play.Project.playScalaSettings
If you are using an SBT project instead of Play, you may also add a default SLF4J logging implementation, as shown in the following code snippet, as otherwise the default used is a no-operation implementation:
libraryDependencies += "org.slf4j" % "slf4j-simple" % "1.7.6"
As usual, starting an REPL can be done either by entering the > play command followed by a > console command or just > play console:
scala> import com.mongodb.casbah.Imports._ import com.mongodb.casbah.Imports._
After some imports, we connect to the MongoDB database on port 27017 using the following code:
scala> val mongoClient = MongoClient("localhost", 27017) mongoClient: com.mongodb.casbah.MongoClient = com.mongodb.casbah.MongoClient@6fd10428 scala> val db = mongoClient("test") db: com.mongodb.casbah.MongoDB = test scala> val coll = db("test") coll: com.mongodb.casbah.MongoCollection = test
These statements have, so far, been executed without a direct contact with the database. From now on, we need to make sure we have a running instance of the MongoDB process before we retrieve any content. Start the
mongod daemon if it is not running yet (download instructions can be found at https://www.mongodb.org/downloads), then enter the following command to fetch the names of the stored collections:
scala> db.collectionNames res0: scala.collection.mutable.Set[String] = Set()
We obviously get an empty set as a result, as we haven't stored any document yet. Let's create a couple of entries:
scala> val sales = MongoDBObject("title" -> "sales","amount"->50) sales: com.mongodb.casbah.commons.Imports.DBObject = { "title" : "sales" , "amount" : 50} scala> val sweden = MongoDBObject("country" -> "Sweden") sweden: com.mongodb.casbah.commons.Imports.DBObject = { "country" : "Sweden"}
The created items have yet to be added to the database, using the insert command as shown in the following commands:
scala> coll.insert(sales) res1: com.mongodb.casbah.TypeImports.WriteResult = { "serverUsed" : "localhost:27017" , "n" : 0 , "connectionId" : 7 , "err" : null , "ok" : 1.0} scala> coll.insert(sweden) res2: com.mongodb.casbah.TypeImports.WriteResult = { "serverUsed" : "localhost:27017" , "n" : 0 , "connectionId" : 7 , "err" : null , "ok" : 1.0} scala> coll.count() res3: Int = 2
Retrieving the elements of the
coll collection can be done using the find method:
scala> val documents = coll.find() foreach println { "_id" : { "$oid" : "530fd91d03645ab9c17d9012"} , "title" : "sales" , "amount" : 50} { "_id" : { "$oid" : "530fd92703645ab9c17d9013"} , "country" : "Sweden"} documents: Unit = ()
Notice that a primary key for each document has been created as we did not provide any while inserting the document into the collection. You may as well retrieve a single document if you know exactly the object you are looking for and provide it as an argument. For this, the findOne method is available, passing a new SearchedCountry MongoDBObject as expressed in the following command lines:
scala> val searchedCountry = MongoDBObject("country" -> "Sweden") searchedCountry: com.mongodb.casbah.commons.Imports.DBObject = { "country" : "Sweden"} scala> val result = coll.findOne(searchedCountry) result: Option[coll.T] = Some({ "_id" : { "$oid" : "530fd92703645ab9c17d9013"} , "country" : "Sweden"})
As there might not always be a matching element, the findOne method returns Option, which in the previous case resulted in Some(value), in contrast to the following empty result:
scala> val emptyResult = coll.findOne(MongoDBObject("country" -> "France")) emptyResult: Option[coll.T] = None
Deleting elements is performed with the
remove method, which can be used in a manner similar to the findOne method:
scala> val result = coll.remove(searchedCountry) result: com.mongodb.casbah.TypeImports.WriteResult = { "serverUsed" : "localhost:27017" , "n" : 1 , "connectionId" : 9 , "err" : null , "ok" : 1.0} scala> val countryNoMore = coll.findOne(searchedCountry) countryNoMore: Option[coll.T] = None
Finally, updating a document can be done as follows:
scala> sales res3: com.mongodb.casbah.commons.Imports.DBObject = { "title" : "sales" , "amount" : 50} scala> val newSales = MongoDBObject("title" -> "sales","amount"->100) newSales: com.mongodb.casbah.commons.Imports.DBObject = { "title" : "sales" , "amount" : 100 scala> val result = coll.update(sales,newSales) result: com.mongodb.casbah.TypeImports.WriteResult = { "serverUsed" : "localhost:27017" , "updatedExisting" : true , "n" : 1 , "connectionId" : 9 , "err" : null , "ok" : 1.0} scala> coll.find foreach println { "_id" : { "$oid" : "530fd91d03645ab9c17d9012"} , "title" : "sales" , "amount" : 100}
We can see here that the primary key "530fd91d03645ab9c17d9012" is still the one we had when we initially inserted the sales document into the database, showing that the update operation was not a removal and then inserting a brand new element.
Updating multiple documents at once is also supported and we refer to the documentation available at http://mongodb.github.io/casbah/guide/index.html for further operations.
Among the great features of document-oriented databases such as MongoDB, there is the possibility to run the MapReduce functions. MapReduce is an approach where you break up a query or task into smaller chunks of work, and then aggregate the results of those chunks. To illustrate how a document-based approach can sometimes be useful in contrast with a traditional relational database, let's take a small example of financial consolidation. In such a domain, aggregating and calculating sales figures globally for a large corporation may involve working with a number of orthogonal dimensions. For instance, sales figures can be gathered from each subsidiary that each has its own geographic location, time intervals, own currency, and specific categories, following some tree-based structures in each dimension as depicted in the following figure:
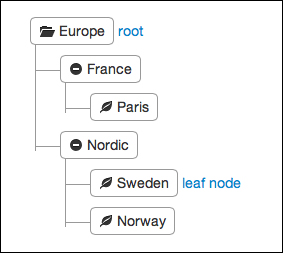
The geographic location might be a decisive factor when it comes to the currency used, and conversion should be done to sum figures consistently. To that extent, the currency used to produce global reports usually follows the root of the company ownership tree. A company tree structure is given in the following figure:
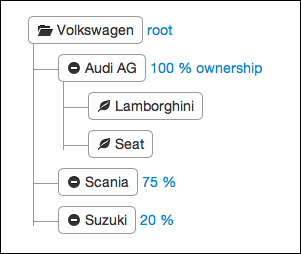
Similarly, various sales categories might define yet another hierarchy, as shown on the following figure:
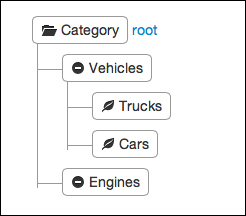
Such reported sales figures may either be very detailed or already accumulated, therefore, reported at various levels of the hierarchies. As large corporations are usually made of smaller groups with various degrees of ownership that are furthermore changing regularly, the consolidation job requires to aggregate and compute data according to all these parameters.
As for a number of data warehousing solutions expressed in relational databases, the heart of the domain model can be a huge table containing facts referring to the various dimensions expressed in the previous figure. For instance, some sample input data for this example can consist in the following list of sales figures (that is, amounts) as XML rows:

The following construct shows how to represent a tree structure in JSON:
{
"title" : "root",
"children" : [
{
"title" : "node 1",
"children" : [
{
"title" : "node 1.1",
"children" : [
...
]
},
{
"title" : "node 1.2",
"children" : [
...
]
}
]
},
{
"title" : "node 2",
"children" : [
...
]
}
]
}The following is an example of a JSON document that contains sales figures by geographic location:
{
"title" : "sales",
"regions" : [
{
"title" : "nordic",
"regions" : [
{
"title" : "norway",
"amount" : 150
},
{
"title" : "sweden",
"amount" : 200
}
]
},
{
"title" : "france",
"amount" : 400
}
]
}By storing documents coming from various subsidiaries of a large corporation, such as JSON, we can consolidate the figures through MapReduce transformations already supported by the database. Moreover, Casbah takes advantage of the aggregation framework (http://mongodb.github.io/casbah/guide/aggregation.html) of MongoDB to be able to aggregate values without having to use MapReduce
To conclude with MongoDB, we will just mention the ReactiveMongo project (www.reactivemongo.org) that figures a reactive asynchronous and non-blocking driver for MongoDB. As it uses the Iteratee pattern that we covered in Chapter 9, Building Reactive Web Applications, combining it with a stream-friendly framework, such as Play, can result in a number of interesting and scalable demos, as listed on their website.