
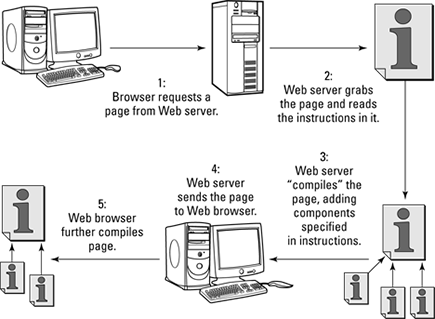
Figure 7-1: How Web pages are created.
Chapter 7
Creating Pages That Search Engines Love
In This Chapter
![]() Getting your site read
Getting your site read
![]() Knowing what search engines see
Knowing what search engines see
![]() Exploring keyword concepts
Exploring keyword concepts
![]() Creating Web pages
Creating Web pages
In this chapter, you find out how to create Web pages that search engines really like — pages that can be read and indexed and that put your best foot forward. Before you begin creating pages, I recommend that you read not only this chapter but also Chapter 8 to find out how to avoid things that search engines hate. There are a lot of ways to make a Web site work, and just as many ways to break it, too. Before you get started creating your pages, you should be aware of the problems you may face and what you can do to avoid them.
 I’m assuming that you or your Web designer understand HTML and can create Web pages. I focus on the most important search engine–related things you need to know while creating your pages. It’s beyond the scope of this book to cover basic HTML and Cascading Style Sheets.
I’m assuming that you or your Web designer understand HTML and can create Web pages. I focus on the most important search engine–related things you need to know while creating your pages. It’s beyond the scope of this book to cover basic HTML and Cascading Style Sheets.
Preparing Your Site
When you’re creating a Web site, the first thing to consider is where to put your site. By that, I mean the Web server and the domain name.
Finding a hosting company
Although many large companies place their Web sites on their own Web servers, most small companies don’t. They shouldn’t do this, in fact, because there’s simply no way you can do it anywhere near as cheaply and reliably as a good hosting company can do it. Rather, a hosting company rents space on its servers to other businesses.
Although you have to consider many factors when selecting a hosting company, I focus on the factors related to search engine optimization. When looking for a hosting company, make sure that you can
![]() Upload Web pages you created by yourself. Some services provide simple tools you can use to create Web pages; it’s fine if they provide these tools as long as you can also create pages yourself. You must have control over the HTML in your pages.
Upload Web pages you created by yourself. Some services provide simple tools you can use to create Web pages; it’s fine if they provide these tools as long as you can also create pages yourself. You must have control over the HTML in your pages.
![]() Use the company’s traffic-analysis tool or, if you plan to use your own analysis tool, access the raw traffic logs. A log-analysis tool shows you how many people visit your site and how they get there. See Chapter 24 for more information about traffic analysis. (These days many people use Google Analytics, Google’s free stats program. As long as you can add a little piece of JavaScript to the bottom of every page, you can use Analytics; see
Use the company’s traffic-analysis tool or, if you plan to use your own analysis tool, access the raw traffic logs. A log-analysis tool shows you how many people visit your site and how they get there. See Chapter 24 for more information about traffic analysis. (These days many people use Google Analytics, Google’s free stats program. As long as you can add a little piece of JavaScript to the bottom of every page, you can use Analytics; see www.google.com/analytics.)
You need to consider many issues when selecting a hosting company, most of which aren’t directly related to the search engine issue. If you want to find out more about what to look for in a hosting company, I’ve posted an article about selecting a host on my Web site; find it at www.SearchEngineBulletin.com.
Picking a domain name
Search engines read uniform resource locators (URLs), looking for keywords in them. For instance, if you have a Web site with the domain name rodent-racing.com and someone searches Google for rodent racing, Google sees rodent-racing as a match; because a dash appears between the two words, Google recognizes the words in the domain name. If, however, you run the words together (rodentracing), Google doesn’t regard the individual words as individual words; it sees them as part of the same word. That’s not to say that Google can’t find text within words — it can, and you sometimes see words on the search results pages partially bolded when Google does just that — but when ranking the page, Google doesn’t regard the word it found inside another word as the same as finding the word itself.

 To see this concept in action, use the allinurl: search syntax at Google. Type allinurl:rodent, for example, and Google finds URLs that contain the word rodent (including the directory names and filenames).
To see this concept in action, use the allinurl: search syntax at Google. Type allinurl:rodent, for example, and Google finds URLs that contain the word rodent (including the directory names and filenames).
So, putting keywords into the domain name and separating keywords with dashes provides a small benefit. Another advantage to adding dashes between words is that you can relatively easily come up with a domain name that’s not already taken. Although it may seem as though most of the good names were taken long ago, you can often come up with some kind of keyword phrase, separated with dashes, that’s still available. Furthermore, search engines don’t care which first-level domain you use; you can use .com, .net, .biz, .tv, or whatever; it doesn’t matter.
Now, having said all that, let me tell you my philosophy regarding domain names. In the search engine optimization field, it has become popular to use dashes and keywords in domain names, but in most cases, the lift provided by keywords in domain names is relatively small, and you should consider other, more important factors when choosing a domain name:
![]() A domain name should be short, easy to spell, and easy to remember. It should also pass the radio test. Imagine that you’re being interviewed on the radio and want to tell listeners your URL. You want something that’s instantly understandable without having to be spelled. You don’t want to have to say “rodent dash racing dash events dot com”; it’s better to say “rodent racing events dot com.”
A domain name should be short, easy to spell, and easy to remember. It should also pass the radio test. Imagine that you’re being interviewed on the radio and want to tell listeners your URL. You want something that’s instantly understandable without having to be spelled. You don’t want to have to say “rodent dash racing dash events dot com”; it’s better to say “rodent racing events dot com.”
![]() In almost all cases, you should get the .com version of a domain name. If the .com version is taken, do not try to use the .net or .org version for branding purposes! People remember .com, even if you say .org or .net or whatever. So, if you’re planning to promote your Web site in print, on the radio, on TV, on billboards, and so on, you need the .com version.
In almost all cases, you should get the .com version of a domain name. If the .com version is taken, do not try to use the .net or .org version for branding purposes! People remember .com, even if you say .org or .net or whatever. So, if you’re planning to promote your Web site in print, on the radio, on TV, on billboards, and so on, you need the .com version.
A classic example is a situation involving Rent.com and Rent.net. These two different Web sites were owned by two different companies. Rent.net spent millions of dollars on advertising; every time I saw a Rent.net ad on a bus, I had to wonder how much of the traffic generated by these ads actually went to Rent.com! (Rent.net is now out of business — the domain name now points to Move.com — and Rent.com isn’t. I don’t know whether that’s a coincidence!)
Are keyworded domain names worth the trouble? Because the lift provided by keywords in the domain name may be rather small — and, in fact, putting too many keywords into a name can hurt your placement — you should probably focus on a single, brandable domain name (a .com version).
On the other hand, you might register both versions. For instance, register both Rodent-Racing-Events.com and RodentRacingEvents.com. Use Rodent-Racing-Events.com as the primary domain name, the one you want the search engines to see. Then do a 301 Redirect to point RodentRacingEvents.com to Rodent-Racing-Events.com. (See Chapter 24 for information on the 301 Redirect.) That way, you can tell people to go to “rodent racing events dot com” without having to mention the dashes, yet the search engine will regard all links to either domain as pointing to the same site and will see the keywords rodent and racing in the domain name.
 Don’t use a domain-forwarding service for Web sites that you want to turn up in search engines. Many registrars now allow you to simply forward browsers to a particular site: A user types www.domain1.com, and the registrar forwards the browser to www.domain2.com, for instance. Such forwarding systems often use frames (discussed in Chapter 8), which means that search engines don’t index the site properly. Your site should be properly configured by using the name server settings, not a simple forward.
Don’t use a domain-forwarding service for Web sites that you want to turn up in search engines. Many registrars now allow you to simply forward browsers to a particular site: A user types www.domain1.com, and the registrar forwards the browser to www.domain2.com, for instance. Such forwarding systems often use frames (discussed in Chapter 8), which means that search engines don’t index the site properly. Your site should be properly configured by using the name server settings, not a simple forward.
Seeing Through a Search Engine’s Eyes
What a search engine sees when it loads one of your pages isn’t the same as what your browser sees. To understand why, you need to understand how a Web page is created. See Figure 7-1 and read this quick explanation:
1. A user types a URL into his browser or clicks a link, causing the browser to send a message to the Web server asking for a particular page.
2. The Web server grabs the page and quickly reads it to see whether it needs to do anything to the page before sending it.
3. The Web server compiles the page, if necessary.
In some cases, the Web server may have to run ASP or PHP scripts, for instance, or it may have to find an SSI (server-side include), an instruction telling it to grab something from another page and insert it into the one it’s about to send.
4. After the server has completed any instructions, it sends the page to the browser.
5. When the browser receives the page, it reads through the page looking for instructions and then, if necessary, further compiles the page.
6. When the browser is finished, it displays the page for the user to read.
Here are a few examples of instructions the browser may find inside the file:
• <SCRIPT> tags containing JavaScript scripts or references to scripts stored in other files: The browser then runs those scripts.
• Cascading Style Sheets (CSS): These instructions tell the browser how the page — in particular, the text on the page — should be formatted.
• References to images or other forms of media: After the browser finds these references, it pulls them into the page.
So that’s what happens normally when Web pages are created. But what about searchbots, the programs used by search engines to index pages? Well, in the past, they worked differently. When a searchbot requested a page, the server did what it would normally do — construct the page according to instructions and send it to the searchbot. But the searchbot didn’t follow all the instructions in the page — it just read the page. For example, it wouldn’t run scripts in the page, and it wouldn’t use the Cascading Style Sheet information to format the page.
Thus, you can use two kinds of instructions to build Web pages:
![]() Server-side instructions: These instructions, such as ASP and PHP scripts and SSI instructions, are carried out by the server before sending the information to the searchbots.
Server-side instructions: These instructions, such as ASP and PHP scripts and SSI instructions, are carried out by the server before sending the information to the searchbots.
![]() Browser-side (or client-side) instructions: These instructions are embedded into the Web page and, in the past, generally ignored by searchbots. For instance, if you created a page with a navigation system built with JavaScript, the search engines may not be able to read it. Some people even used browser-side instructions to intentionally hide things from search engines.
Browser-side (or client-side) instructions: These instructions are embedded into the Web page and, in the past, generally ignored by searchbots. For instance, if you created a page with a navigation system built with JavaScript, the search engines may not be able to read it. Some people even used browser-side instructions to intentionally hide things from search engines.
But things are different today; the only question is how much. Google, for instance, now does read browser-side scripting. It can read JavaScript, for instance, allowing it to read content inserted into pages using scripts; for example, it can read Facebook page content, much of which is inserted browser side. Today’s searchbots are much more sophisticated than in the past. But that doesn’t necessarily mean they’ll read everything inserted browser side. There’s an almost limitless variety of ways to use scripts and stylesheets, and it’s likely that the searchbots decipher some things and not others.
My belief is that if you want to make sure that something is definitely seen by the search engines, place it into the page server side. Yes, Google can read Facebook pages, but that doesn’t necessarily mean it’ll spend the time to figure out the scripts on your pages.
These concepts are very important:
Server side = visible to searchbots
Browser side = sometimes not visible to searchbots
Understanding Keyword Concepts
Here’s the basic concept of using keywords: You put keywords into your Web pages in such a manner that search engines can find them, read them, and regard them as significant.
Your keyword list is probably very long, perhaps hundreds of keywords, so you need to pick a few to work with. (If you haven’t yet developed a keyword list, refer to Chapter 6 for details.) The keywords you pick should be either
![]() Words near the top of the list that have many searches.
Words near the top of the list that have many searches.
![]() Words lower on the list that may be worth targeting because you have relatively few competitors. That is, when someone searches for a keyword phrase by using an exact search in quotation marks (“rodent racing” rather than rodent racing), the search engine finds relatively few matches.
Words lower on the list that may be worth targeting because you have relatively few competitors. That is, when someone searches for a keyword phrase by using an exact search in quotation marks (“rodent racing” rather than rodent racing), the search engine finds relatively few matches.
It’s often easy to create pages that rank well for the keywords at the bottom of your list because they’re unusual terms that don’t appear in many Web pages. However, they’re at the bottom of your list because people don’t often search for them! Therefore, you have to decide whether it’s worthwhile to rank well on a search term that’s searched for only once or twice a month.
Picking one or two phrases per page
You optimize each page for one or two keyword phrases. By optimize, I mean that you create the page in such a manner that it has a good chance of ranking well for the chosen keyword phrase or phrases when someone uses them in a search engine.
You can’t optimize a page well for more than one keyword phrase at a time. The <TITLE> tag is one of the most important components on a Web page, and the best position for a keyword is at the beginning of that tag. Remember that you can place only one phrase at the beginning of the tag. (However, sometimes, as you find out in Chapter 6, you can combine keyword phrases — for example, optimizing for rodent racing scores also, in effect, optimizes for rodent racing.)
Have primary and secondary keyword phrases in mind for each page you’re creating, but also consider all the keywords you’re interested in working into the pages. For instance, you might create a page that you plan to optimize for the phrase rodent racing, but you also have several other keywords that you want to scatter around your site: rodent racing scores, handicap, gerbil, rodentia, furry friend events, and so on. Typically, you pick one main phrase for each page and incorporate the other keyword phrases throughout the page, where appropriate.
Place your keyword list into a word processor, enlarge the font, and then print the list and tape it to the wall. Occasionally, while creating your pages, glance at the list to remind yourself which words you need to weave into your pages.
Checking prominence
The term prominence refers to where the keyword appears — how prominent it is within a page component (the body text, the <TITLE> tag, and so on). A word near the top of the page is more prominent than one near the bottom; a word at the beginning of a <TITLE> tag is more prominent than one at the end; a word at the beginning of the DESCRIPTION meta tag is more prominent than one at the end; and so on.
Prominence is good. If you’re creating a page with a particular keyword or keyword phrase in mind, make that term prominent — in the body text, in the <TITLE> tag, in the DESCRIPTION meta tag, and elsewhere — to convey to search engines that the keyword phrase is important in this particular page. Consider this title tag:
<TITLE>Everything about Rodents - Looking after Them, Feeding Them, Rodent Racing, and More.</TITLE>
When you read this tag, you can see that Rodent Racing is just one of several terms the page is related to. The search engine comes to the same conclusion because the term is near the end of the title, meaning that it’s probably not the predominant term. But what about the following tag?
<TITLE>Rodent Racing - Looking after Your Rodents, Feeding Them, Everything You Need to Know</TITLE>
Placing Rodent Racing at the beginning of the tag places the stress on that concept; search engines are likely to conclude that the page is mainly about rodent racing.
Watching density
Another important concept is keyword density. When a user searches for a keyword phrase, the search engine looks at all pages that contain the phrase and checks the density — the ratio of the search phrase to the total number of words in the page.
Suppose that you search for rodent racing and the search engine finds a page that contains 400 words, with the phrase rodent racing appearing 10 times — that’s a total of 20 words. Because 20 is 5 percent of 400, the keyword density is 5 percent.
Keyword density is important, but you can overdo it. If the search engine finds that the search phrase makes up 50 percent of the words in the page, it may decide that the page was created purely to grab the search engine’s attention for that phrase and thus decide to ignore it. On the other hand, if the density is too low, you risk having the search engines regard other pages as more relevant for the search.
You can get hung up on keyword density, and some people use special tools to check the density on every page. This strategy can be very time consuming, especially for large sites. You’re probably better off eyeballing the density in most cases.
Here’s my general rule: If the phrase for which you’re optimizing appears an awful lot, you’ve overdone it. If the text sounds clumsy because of the repetition, you’ve overdone it.
Placing keywords throughout your site
Suppose that someone searches for rodent racing, and the search engine finds two sites that use the term. One site has a single page in which the term occurs; the other site has dozens of pages containing the term. Which site does the search engine think is most relevant? The one that has many pages related to the subject, of course.
In most cases, you’re not likely to grab a top position by simply creating a single page optimized for the keyword phrase. You may need dozens, perhaps hundreds, of pages to grab the search engines’ attention (with plenty of links between pages and from other sites back to yours — which you find out about in Chapters 15 through 17).
Creating Your Web Pages
When you’re creating your Web pages, you need to focus on two essential elements:
![]() The underlying structure of the pages
The underlying structure of the pages
![]() The text you plunk down on the pages
The text you plunk down on the pages
The next sections fill you in on what you need to look out for.
Naming files
Search engines get clues about the nature of a site from its domain name as well as from the site’s directory and file structure. The added lift is probably not large, but every little bit counts, right? You might as well name directories, Web pages, and images by using keywords.
For example, rather than create a directory named /events/, you could name it /rodent-racing-events/. Rather than have a file named gb123.jpg, you can use a more descriptive name, such as rodent-racing-scores.jpg. Don’t have too many dashes in the file and directory names, though, because overdoing it may cause search engines to ignore the name.
You should separate keywords in a name with dashes, but not with underscores, despite what your Web designer may tell you. Since the last edition of this book, Google has dramatically changed the way in which it deals with underscores in URLs, so it’s no longer as important as it once was (Google regards rodent_racing, for instance, as a single word). However, I still recommend dashes — hyphens — for several reasons:
![]() It’s what Google recommends, and if it’s good enough for Google, it’s good enough for me.
It’s what Google recommends, and if it’s good enough for Google, it’s good enough for me.
![]() Some search engines may still have problems with underscores.
Some search engines may still have problems with underscores.
![]() There was never any real reason for using underscores anyway, despite what many geeks seemed to think.
There was never any real reason for using underscores anyway, despite what many geeks seemed to think.
Don’t let anyone tell you that you should be using underscores rather than dashes in file and directory names — it’s simply not true!
Creating directory structure
First, let me explain a common belief in the SEO business: It may be a good idea to keep a flat directory structure in your Web site — that is, keep your pages as close to the root domain as possible, rather than have a complicated multilevel directory tree. Create a directory for each navigation tab and keep all the files in that directory.
Many observers believe that search engines downgrade pages that are lower in the directory structure. This effect is probably small, but the theory is that you’re better off using a structure with fewer sublevels than with more. For instance, the first page that follows, according to this theory, would be weighted more highly than the second page:
http://www.domainname.com/page.html
http://www.domainname.com/dir1/dir2/dir3/dir4/page.html
However, a flat directory structure is probably not terribly important. Matt Cutts of Google (see Chapter 23) claims that the directory structure doesn’t matter to Google, the single most important search engine, of course. And sometimes it’s nice to use a directory structure to add a few keywords to the URL to tell the search engines what the page is about. For instance, you might have the following in a real estate site:
http://www.domain.com/real-estate/
Don’t use too many hyphens, though; a few here and there are okay (I have three in the second directory name), but overdoing it might cause problems.
Viewing TITLE tags
Most search engines use the site’s <TITLE> tag as the link and main title of the site’s listing on the search results page, as shown in Figure 7-2.
<TITLE> tags tell a browser what text to display in the browser’s title bar and are very important for search engines as well. Searchbots read page titles and use that information to determine what the pages are about. If your <TITLE> tags have a keyword between them that competing pages don’t have, you have a good chance of getting at or near the top of the search results.
The <TITLE> tag is one of the most important components as far as search engines are concerned. However, these tags are usually wasted because few sites bother placing useful keywords in them. Titles are often generic: Welcome to Acme, Inc., or Acme Inc. – Home Page. Such titles are not beneficial for search engine optimization.
Figure 7-2: Search results from Google, showing where components come from.
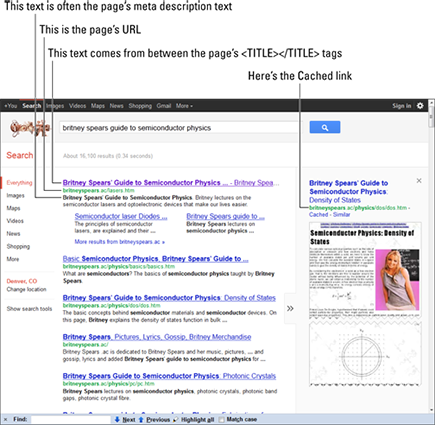
I searched at Google for intitle:welcome to find out how many pages have the word welcome in their <TITLE> tags. The result? Around 634 million! Around 449 million have welcome to in the title (allintitle:”welcome to”). Having Welcome to as the first words in your title is a waste of space — only slightly more wasteful than your company name! Give the search engines a really strong clue about your site’s content by using a keyword phrase in the <TITLE> tags. Here’s how:
1. Place your <TITLE> tags immediately below the <HEAD> tag.
2. Place 40 to 60 characters between the <TITLE> and </TITLE> tags, including spaces.
3. Put the keyword phrase you want to focus on for this page at the beginning of the <TITLE> tag.
If you want, you can repeat the primary keywords once. Limit the number of two-letter words and very common words (known as stop words), such as as, the, and a, because search engines ignore them.
Here’s a sample <TITLE> tag:
<TITLE>Rodent Racing Info. Rats, Mice, Gerbils, Stoats, All Kinds of Rodent Racing</TITLE>
(By the way, I am aware that a stoat is not, strictly speaking, a rodent, but it looks quite rodenty to me, and I’m sure someone races them.)
Although the title tag is used as the link on the search-results page, it will be truncated if it’s too long. On Google, for instance, depending on spacing between words, the title may be truncated to around 55 to 65 characters and have an ellipsis (. . .) displayed at the end of the line — that is, Rodent Racing Info. Rats, Mice, Gerbils, Stoats, All Kinds of Rodent Racing may be displayed as Rodent Racing Info. Rats, Mice, Gerbils, Stoats, All Kinds of Rodent . . . — so make sure you get the important words that you want to be visible on the search-results page into those first 55 or so characters.
Also, use title case (capitalizing the initial letter of each word, as in Rodent Racing Info. Rats, Mice, Gerbils, Stoats, All Kinds of Rodent Racing, not Rodent racing info. rats, mice, gerbils, stoats, all kinds of rodent racing). Title case is much easier for people to read as they scan down the page.
The <TITLE> tag and often the DESCRIPTION tag (explained in the next section) appear on the search results page, so both these tags should encourage people to visit your site.
Using the DESCRIPTION meta tag
Meta tags are special HTML tags that you can use to carry information, which browsers or other programs can then read. When Internet search engines were first created, Webmasters included meta tags in their pages to make it easy for search engines to determine what the pages were about. Search engines also used these meta tags when deciding how to rank the page for different keywords.
The DESCRIPTION meta tag describes the Web page to the search engines. Search engines use this meta tag in two ways:
![]() They read and index the text in the tag and, in some circumstances, use it to figure out a page’s relevance to a search term. (Google claims it doesn’t use the tag for page ranking, but other search engines may.)
They read and index the text in the tag and, in some circumstances, use it to figure out a page’s relevance to a search term. (Google claims it doesn’t use the tag for page ranking, but other search engines may.)
![]() In many cases, they use the text verbatim in the search results page. That is, if your Web page is returned in the search results page, the search engine may grab the text from the
In many cases, they use the text verbatim in the search results page. That is, if your Web page is returned in the search results page, the search engine may grab the text from the DESCRIPTION tag and place it under the text from the <TITLE> tag so that the searcher can read your description.
Now, this process can vary between search engines, and over time for the same search engine. Until sometime in 2007, in most cases, Google didn’t use the text from the DESCRIPTION meta tag in its search results page. Rather, Google grabbed a block of text where it found the search keywords on the page and then used that text in the results page. However, these days it will often use the DESCRIPTION tag text if it finds the searched-for words in the description. If it doesn’t, or if it finds only some of the searched for words, it may grab text from within the page content and display that instead. The DESCRIPTION meta tag is pretty important, so you should definitely use it. Think of it as serving two purposes:
![]() It’s a page-ranking tool, helping, in some search engines, the page to rank higher on the search-results page.
It’s a page-ranking tool, helping, in some search engines, the page to rank higher on the search-results page.
![]() It’s a sales pitch, seen by people viewing the search engine’s search-results page; it should encourage people to click the link.
It’s a sales pitch, seen by people viewing the search engine’s search-results page; it should encourage people to click the link.
As is the <TITLE> tag, the DESCRIPTION is truncated; in Google search results, the text will be truncated to around 140 or 150 characters. For instance, here’s the description tag from Payless.com:
Shop Online or Nearest Store for Women’s Shoes, Children’s Shoes, Men’s Shoes, and Designer Shoe Styles | Free Shipping to a Store | Payless Online Shoe Store
And here’s how it appears in the Google search results:
Shop Online or Nearest Store for Women’s Shoes, Children’s Shoes, Men’s Shoes, and Designer Shoe Styles | Free Shipping to a Store | Payless Online Shoe . . .
So if you want part of the text to be seen, make sure it appears before that 140th-or-so character. You can have a longer description and get a few more keywords in there (though remember that as Google doesn’t use it for ranking you won’t be helping your position, at least with that search engine), but don’t make it too long; perhaps 170 to 200 characters maximum (including spaces). Place the DESCRIPTION tag immediately below the <TITLE> (opening and closing) tags. Here’s an example:
<META NAME=“description” CONTENT=“Rodent Racing - Scores, Schedules, Everything Rodent Racing. Mouse Racing, Stoat Racing, Rat Racing, Gerbil Racing. The Web’s Top Rodent Racing Systems and Racing News”>
As with the <TITLE> tag, title case is also a good thing; title case makes the DESCRIPTION text easier to read. Duplicating your most important keywords once is okay, but don’t overdo it, or you’ll upset the search engines. Don’t, for instance, do this:
<META NAME=“description” CONTENT=“Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing”>
Overloading your DESCRIPTION (or any other page component) with the same keyword or keyword phrase is known as spamming (a term I hate, but hey, I don’t make the rules), and trying such tricks may get your page penalized; rather than help your page’s search engine position, it may cause search engines to omit it from their indexes.
By the way, you should consider your DESCRIPTION tag to be not only a search engine component but also a sales tool. Remember that much of the tag — perhaps the first 150 to 160 characters — will quite likely be seen in the search results, so you want to use text that encourages people to click the link — text that helps your links stand apart from the others on the page. An example is a compelling sales message or your phone number, which helps build credibility by ensuring that people recognize that it’s a real site and not some search engine spam result! (Using a phone number also has the effect of making your listing stand out a little; the eye “trips” over changes in the pattern, such as numbers and capitalized words.) You might also want to think about your site’s Unique Selling Proposition (USP). What makes your site special compared to others — a huge selection? Free shipping? Remember, this is a sales pitch to get people to click, so think about how you can do that.
Tapping into the KEYWORDS meta tag
The KEYWORDS meta tag was originally created as an indexing tool — that is, a way for the page author to tell search engines what the page is about by listing (yep) keywords. Although quite important many years past, this meta tag isn’t so important these days. Some search engines may use it, but many don’t, and even those that do use it don’t give it much value. (Google and Bing almost certainly don’t use it. Ask.com may, but again, it doesn’t give it much weight.) Still, you might as well include the KEYWORDS meta tag. You do have a list of keywords, after all.
Don’t worry too much about the tag — it’s not worth spending a lot of time over. Here are a few points to consider, though:
![]() Limit the tag to 10 to 12 words. Originally, the
Limit the tag to 10 to 12 words. Originally, the KEYWORDS tag could be very large, up to 1,000 characters. These days, many search engine observers are wary of appearing to be spamming search engines by stuffing keywords into any page component, so these observers recommend that you use short KEYWORDS tags.
![]() You can separate each keyword with a comma and a space. However, you don’t have to use both — you can have a comma and no space, or a space and no comma.
You can separate each keyword with a comma and a space. However, you don’t have to use both — you can have a comma and no space, or a space and no comma.
![]() Make sure that most of the keywords in the tag are also in the body text. If they aren’t, the tag probably won’t do you any good. Many people also use the
Make sure that most of the keywords in the tag are also in the body text. If they aren’t, the tag probably won’t do you any good. Many people also use the KEYWORDS tag as a good place to stuff spelling mistakes that are commonly searched.
![]() Don’t use a lot of repetition. You shouldn’t do this, for instance: Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, or even Rodent Racing, Rodent Racing Scores, Rodent Racing, Gerbils, Rodent Racing Scores, Rodent Racing. . . .
Don’t use a lot of repetition. You shouldn’t do this, for instance: Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, Rodent Racing, or even Rodent Racing, Rodent Racing Scores, Rodent Racing, Gerbils, Rodent Racing Scores, Rodent Racing. . . .
![]() Don’t use the same
Don’t use the same KEYWORD tag in all your pages. You can create a primary tag to use in your first page and then copy it to other pages and move terms around in the tag.
Here’s an example of a well-constructed KEYWORD tag:
<META NAME=“keywords” CONTENT=“rodent racing, racing rodents, gerbils, mice, mouse, raceing, mouse, rodent races, rat races, mouse races, stoat, stoat racing”>
Using other meta tags
What about other meta tags? Sometimes if you look at the source of a page, you see all sorts of meta tags, as shown in Figure 7-3 (in bold to make seeing them easier). Meta tags are useful for various reasons, but from a search engine perspective, you can forget most of them. (And most meta tags really aren’t of much use for any purpose.)
Figure 7-3: Examples of meta tags you generally don’t need.

You’ve heard about DESCRIPTION and KEYWORDS meta tags, but also of relevance to search engine optimization — though not always useful — are the REVISIT-AFTER and ROBOTS meta tags:
![]()
REVISIT-AFTER tells search engines how often to reindex the page. Save the electrons; don’t expect search engines to follow your instructions. Search engines re-index pages on their own schedules.
![]()
ROBOTS blocks search engines from indexing pages. (I discuss this topic in detail in “Blocking searchbots,” later in this chapter.) But many Web authors use it to tell search engines to index a page. Here’s an example:
<META NAME=“robots“ CONTENT=“ALL“>
This tag is a waste of time. If a search engine finds your page and wants to index it, and hasn’t been blocked from doing so, it will. And if the search engine doesn’t want to index the page, it doesn’t. Telling the search engine to do so doesn’t make a difference.
There are also a few special Google meta tags:
<META NAME=“googlebot” CONTENT=“nosnippet”>
This meta tag tells Google not to place a description under a search result’s link. This tag also has the effect of removing the page from Google’s cache (the saved version of an indexed Web page; you see Cached links by entries in the search-results page).
Here’s another example:
<META NAME=“googlebot” CONTENT=“noarchive”>
This meta tag tells Google not to place a copy of the page into the cache. If you have an average corporate attorney on staff who doesn’t like the idea of Google storing a copy of your company’s information on its servers, you can tell Google not to. There’s also the NOINDEX tag, which tells Google not to index the page, and the NOFOLLOW tag, which tells it not to follow links from that page.
Including image ALT text
You use the <IMG> tag to insert images into Web pages. This tag can include the ALT= attribute, which means alternative text. ALT text was originally displayed if the browser viewing the page couldn’t display images. ALT text is also used by programs that “speak” the page (for individuals without sight). In many browsers, ALT text also appears in a little pop-up box when you hold your mouse over an image for a few moments. (If you use Firefox, you can install an add-on called Popup ALT Attribute to make it happen.)
ALT attributes are also read by search engines. Why? Because these tag “attributes” offer another clue about the content of the Web page, by providing a description of what the image is. How much do ALT tags help? Perhaps not so much these days, because some Web designers have abused the technique by stuffing ALT attributes with tons of keywords. But using ALT attributes can’t hurt (assuming that you don’t stuff them with tons of keywords, but rather simply drop in a few here and there) and may even help push your page up a little in the search engine rankings.
You can place keywords in your ALT attributes like this:
<IMG SRC=“rodent-racing-1.jpg” ALT=“Rodent Racing - Ratty Winners of our Latest Rodent Racing Event”>
It’s definitely a good idea to use ALT attributes on image links, by the way. Doing so gives Google an idea of what the page referenced by the link is about.
Adding body text
You need text in your page. How much? More than a little, but not too much. Maybe 200 to 400 words is a good range. Don’t get hung up on these numbers, though. If you put an article in a page and the article is 1,000 words, that’s fine, and some pages may not have much text at all. But in general, when building a page that you want people to find in the search engines, a number in the 200 to 400 word range is good. That amount of content allows you to really define what the page is about and helps the search engine understand what the page is about.
Keep in mind that a Web site needs content in order to be noticed by search engines. (For more on this topic, see Chapter 10.) If the site doesn’t have much content for the search engine to read, the search engine will have trouble determining what the page is about and may not properly rank it. In effect, the page loses points in the contest for search engine ranking. Certainly, placing keywords in content is not all there is to being ranked in search engines; as you find out in Chapters 15 through 17, for instance, linking to the pages is also very important. But keywords in content are very significant, so search engines have a natural bias toward Web sites with a large amount of content.
This bias toward content could be considered very unfair. After all, your site may be the perfect fit for a particular keyword search, even if you don’t have much content in your site. In fact, inappropriate sites often appear in searches simply because they have a lot of pages, some of which have the right keywords.
Suppose that your rodent-racing Web site is the only site in the world at which you can buy tickets for rodent-racing events. Your site doesn’t provide a lot of content because rodent-racing fans simply want to be able to buy tickets and nothing more. However, because your site has less content than other sites, it is at a disadvantage to sites that have lots of content related to rodent racing, even if these other sites aren’t directly related to the subject. (On the other hand, if rodent-racing fans throughout the world decide that your site is the one on which to buy tickets, and enough of them link to you, you can still rank well regardless of how much page content you have.)
You can’t do much to confront this problem, except to add more content (or create a lot of links)! You can find some ideas on where to get content in Chapter 10 and read all about links in Chapters 15 through 17.
Creating headers: CSS versus <H> tags
Back when the Web began, browsers defined what pages looked like. A designer could say, “I want body text here and a heading there and an address over there,” but the designer had no way to define what the page actually looked like. The browser decided. The browser defined what a header looked like, what body text looked like, and so on. The page might appear one way in one browser and another way in a different browser.
These days, designers have a useful tool available to them: Cascading Style Sheets (CSS). With CSS, designers can define exactly what each element should look like on a page.
Now, here’s the problem. HTML has several tags that define headers: <H1>, <H2>, <H3>, and so on. These headers are useful in search engine optimization because when you put keywords into a heading, you’re saying to a search engine, “These keywords are so important that they appear in my heading text.” Search engines pay more attention to them, weighing them more heavily than keywords in body text.
But many designers have given up on using the <H> tags and rely solely on CSS to make headers look the way they want them to. The plain <H> tags are often rather ugly when displayed in browsers, so designers don’t like to use them. <H> tags also cause spacing issues; for example, an <H1> tag always includes a space above and below the text contained in the tag.
However, there’s no reason you can’t use both <H> tags and CSS. You can use style sheets in two basic ways:
![]() Create a style class and then assign that class to the text you want to format.
Create a style class and then assign that class to the text you want to format.
![]() Define the style for a particular HTML tag.
Define the style for a particular HTML tag.
Many designers do the former; they create a style class in the style sheet, as in the following example:
.headtext { font-family: Verdana, Arial, Helvetica, sans-serif; font-size: 16px; font-weight: bold; color: #3D3D3D }
Then they assign the style class to a piece of text, like this:
<DIV CLASS=“headtext”>Rodent Racing for the New Millennium!</div>
In this example, the headtext class makes the text appear the way the designer wants the headings to appear. But, as far as search engines are concerned, this is just normal body text.
A better way is to define the <H> tags in the style sheets, as in the following example:
H1 {
font-family: Verdana, Arial, Helvetica, sans-serif;
font-size: 16px;
font-weight: bold;
color: #3D3D3D
}
Now, whenever you add an <H1> tag to your pages, the browser reads the style sheet and knows exactly which font family, size, weight, and color you want. It’s the best of both worlds — you get the appearance you want, and search engines know it’s an <H1> tag. (Note to Web designers who don’t want to listen: Don’t take my word for it. Even Google recommends that you use <H> tags.)
Formatting text
You can also tell search engines that a particular word might be significant in several other ways. If the text is in some way different from most of the other text in the page, search engines may assume that it has been set off for some reason, that the Web designer has treated it differently because it is in some way different and more significant than the other words.
Here are a few things you can do to set your keywords apart from the other words on the page:
![]() Make the text bold.
Make the text bold.
![]() Make the text italic.
Make the text italic.
![]() Use title case (uppercase the First Letter in Each Word and lowercase the other letters in the word).
Use title case (uppercase the First Letter in Each Word and lowercase the other letters in the word).
![]() Put the keywords in bullet lists.
Put the keywords in bullet lists.
For each page, you have a particular keyword phrase in mind; this is the phrase for which you use the preceding techniques.
Another way to emphasize the text is to make a piece of text larger than the surrounding text. (Just make sure that you do this in a way that doesn’t look tacky.) For example, you can use <H> tags for headers but also use slightly larger text at the beginning of a paragraph or for subheaders.
Creating links
Links in your pages serve several purposes:
![]() They help searchbots find other pages in your site.
They help searchbots find other pages in your site.
![]() Keywords in links tell search engines about the pages that the links are pointing at.
Keywords in links tell search engines about the pages that the links are pointing at.
![]() Keywords in links also tell search engines about the page containing the links.
Keywords in links also tell search engines about the page containing the links.
You need links into — and out of — your pages. You don’t want dangling or orphan pages — pages with links into them but no links out. All your pages should be part of the navigation structure. It’s also a good idea to have links within the body text, too.
Search engines read link text for not only clues about the page being referred to but also hints about the page containing the link. I’ve seen situations in which links convinced a search engine that the page the links pointed to were relevant for the keywords used in the links, even though the page didn’t contain those words. The classic example was an intentional manipulation of Google, late in 2003, to get it to display George Bush’s bio (www.whitehouse.gov/president/gwbbio.html) when people searched for the term miserable failure. This was done by a small group of people using links in blog pages. Despite the fact that this page contained neither the word miserable nor the word failure, and certainly not the term miserable failure, a few dozen links with the words miserable failure in the link text were enough to trick Google. (After several years, Google put a stop to the miserable failure situation, but the principle still works. I discuss this Googlebomb in Chapter 15.)
So when you’re creating pages, create links on the page to other pages and make sure that other pages within your site link back to the page you’re creating, using the keywords you placed in your <TITLE> tag.
Don’t create simple Click Here links or You’ll Find More Information Here links. These words (also called anchor text) don’t help you. Instead, create links like these:
For more information, see our rodent-racing scores page.
Our rodent-racing background page provides you with the information you’re looking for.
Visit our rat events and mouse events pages for more info.
Links are critical. In Chapters 15 through17, you find out about another aspect of links: getting links from other sites to point back to yours.
Using other company and product names
Here’s a common scenario: Many of your prospective visitors and customers are searching online for other companies’ names or for the names of products produced or sold by other companies. Can you use these names in your pages? Yes, but be careful how you use them.
Many large companies are aware of this practice, and a number of lawsuits have been filed that relate to the use of keywords by companies other than the trademark owners. Here are a few examples:
![]() A law firm that deals with Internet domain disputes sued Web-design and Web-hosting firms for using its name, Oppedahl & Larson, in their
A law firm that deals with Internet domain disputes sued Web-design and Web-hosting firms for using its name, Oppedahl & Larson, in their KEYWORDS meta tags. These firms thought that merely having the words in the tags could bring traffic to their sites. The law firm won. Duh! (Didn’t anyone ever tell you not to upset large law firms?)
![]() Playboy Enterprises sued Web sites that were using the terms playboy and playmates throughout their pages, site names, domain names, and meta tags to successfully boost their positions. Not surprisingly, Playboy won.
Playboy Enterprises sued Web sites that were using the terms playboy and playmates throughout their pages, site names, domain names, and meta tags to successfully boost their positions. Not surprisingly, Playboy won.
![]() Insituform Technologies, Inc. sued National Envirotech Group after discovering that Envirotech was using its name in its meta tags. Envirotech lost. The judge felt that using the name in the meta tag without having any relevant information in the body of the pages was clearly a strategy for misdirecting people to the Envirotech site.
Insituform Technologies, Inc. sued National Envirotech Group after discovering that Envirotech was using its name in its meta tags. Envirotech lost. The judge felt that using the name in the meta tag without having any relevant information in the body of the pages was clearly a strategy for misdirecting people to the Envirotech site.
So, yes, you can get sued. But then again, you can get sued for anything. In some instances, the plaintiff loses. Playboy won against a number of sites, but lost against former playmate Terri Welles. Playboy didn’t want her to use the terms playboy and playmate on her Web site, but she believed she had the right to, as a former Playboy Playmate. A judge agreed with her. The real point of the Terri Welles case is that nobody owns a word, a product name, or a company name. They merely own the right to use it in certain contexts. Thus, Playboy doesn’t own the word playboy — you can say “playboy,” and you can use it in print. But Playboy owns the right to use the word in certain contexts and to stop other people from using it in those same contexts.
If you use product and company names to mislead or misrepresent, you could be in trouble. But you can use the terms in a valid, nonfraudulent manner. For instance, you can have a product page in which you compare your products to another, named competitor. That’s perfectly legal. No, I’m not a lawyer, but I’m perfectly willing to play one on TV, given the opportunity. And I would bet that you won’t be seeing the courts banning product comparisons on Web sites.
If you have information about competing products and companies on your pages, used in a valid manner, you can also include the keywords in the <TITLE>, DESCRIPTION, and KEYWORDS tags, as Terri Welles did:
<META NAME=“keywords” CONTENT=“ terri, welles, playmate, playboy, model, models, semi-nudity, naked, censored by editors, censored by editors, censored by editors, censored by editors, censored by editors, censored by editors, censored by editors, censored by editors”>
And there’s nuthin’ Playboy can do about it.
What’s ironic is that firms are being sued for putting other companies’ names and brand names in their KEYWORDS tags, when it has very little influence on search engine rank these days.
Creating navigation structures that search engines can read
Your navigation structure needs to be visible to search engines. As I explain earlier in the section “Seeing Through a Search Engine’s Eyes,” some page components are simply invisible to search engines. For instance, a navigation structure created with JavaScript may not be deciphered by search engines. If the only way to navigate your Web site is with the JavaScript navigation, you could have a problem; search engines may not be able to find their way around your site.
Here are a few tips for search engine–friendly navigation:
![]() If you use JavaScript navigation or another technique that could be invisible (which is covered in more detail in Chapter 8), make sure that you have a plain HTML navigation system, too, such as basic text links at the bottom of your pages.
If you use JavaScript navigation or another technique that could be invisible (which is covered in more detail in Chapter 8), make sure that you have a plain HTML navigation system, too, such as basic text links at the bottom of your pages.
![]() Even if your navigation structure is visible to the search engines, you may want to have these bottom-of-page links as well. They’re convenient for site visitors and provide another chance for the search engines to find your other pages.
Even if your navigation structure is visible to the search engines, you may want to have these bottom-of-page links as well. They’re convenient for site visitors and provide another chance for the search engines to find your other pages.
Yet another reason for bottom-of-page, basic text navigation: If you have some kind of image-button navigation, you don’t have any keywords in the navigation for the search engines to read.
![]() Add a sitemap page and link to it from your main navigation. It provides another way for search engines to find all your pages.
Add a sitemap page and link to it from your main navigation. It provides another way for search engines to find all your pages.
![]() Whenever possible, provide keywords in text links as part of the navigation structure.
Whenever possible, provide keywords in text links as part of the navigation structure.
Using rich snippets and schemas
A rich snippet is a Google term for extended information displayed in search results. For instance, search Google for, say, lamb and then click the word Recipes in the left column, and Google knows that you are looking for lamb recipes (see Figure 7-4). You’ll notice a few things; the search results contain both pictures and ingredient lists; some contain star ratings; and Google has a grid on the left side, which allows you to filter the results to show, for example, only the recipes that include mint, or those that do not use mint. You can even filter using the Cook Time and Calories tools. Google is able to provide these rich snippets thanks to special codes used in the HTML that identify each piece of information to the search engine; Google is able to extract the information, store it in a manner that it understands the data, and display it in the search results.
Google introduced its rich snippets in 2009, reading certain microformats or structured data markup. You can find information about the Google rich snippets markups here:
http://support.google.com/webmasters/bin/answer.py?hl=en&answer=99170
However, Google now also recognizes the schemas published at www.schema.org, which is also used by Bing and some other search engines (though today Google recognizes both its rich-snippet markups and the schema standards).
Figure 7-4: Google Recipe results; notice the starred reviews, photos, and filters on the left side.
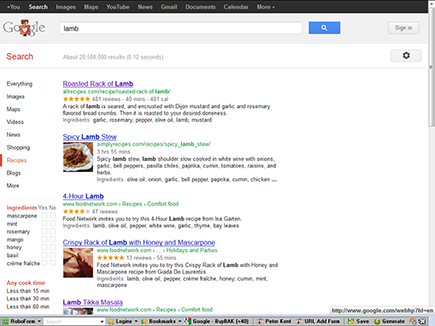
Rich snippets and schemas let you code information such as the following:
![]() Events
Events
![]() Local businesses
Local businesses
![]() Music
Music
![]() Navigation breadcrumb trails
Navigation breadcrumb trails
![]() Offers
Offers
![]() Organizations
Organizations
![]() People
People
![]() Products
Products
![]() Recipes
Recipes
![]() Restaurants
Restaurants
![]() Reviews
Reviews
![]() Software
Software
![]() Videos
Videos
Google provides a great little Rich Snippets Testing Tool (www.google.com/webmasters/tools/richsnippets) that helps you learn by example. Enter the URL of a page you think has been coded, and the tool pulls the data from the page and extracts the individual fields.
Here, for instance, are a few pieces of code that I pulled from a FoodNetwork.com recipe. (I’ve removed a few pieces of code to focus on the important bits.) First, here’s the photograph that Google displayed in the search results:
<img class=“photo” height=“120” width=“160” src=“http://img.foodnetwork.com/FOOD/2004/04/28/ee2e01_leg_of_lamb_med.jpg”>
The class=“photo” piece identifies this as the photograph of the dish. In the next piece of code, Food Network is identifying the author of the recipe; yep, the class=“author” is the relevant code:
<p class=“author”>Recipe courtesy Emeril Lagasse, 2004</p>
Here you can see various ingredients (which Google will then parse to pull out the primary terms that it places into the snippet on the search results page: garlic, not 8 cloves garlic, minced):
<li class=“ingredient”>1 leg of lamb, bone in (about 6 to 7 1/2 pounds</li>
<li class=“ingredient”>1/4 cup fresh lemon juice</li>
<li class=“ingredient”>8 cloves garlic, minced</li>
<li class=“ingredient”>3 tablespoons chopped fresh rosemary leaves</li>
Simple, eh? Well, not entirely. It can take some figuring out, but if you have specialty data such as the preceding listed types, you should spend some time reading up on this stuff. Google claims that coding data like this doesn’t help with ranking, but I don’t understand how that can be correct. If Google is trying to provide recipes with all the nice rich snippets, as it did when I searched for lamb recipe, if your recipe doesn’t contain the structured data, Google can’t use your data to create rich snippets, and then, I have to assume, your recipe doesn’t make it onto the search-results page.
Blocking searchbots
You may want to block particular pages, or even entire areas of your Web site, from being indexed. Here are a few examples of pages or areas you may want to block:
![]() Pages that are under construction
Pages that are under construction
![]() Pages with information intended for internal use (you should probably password-protect that area of the site, too, of course)
Pages with information intended for internal use (you should probably password-protect that area of the site, too, of course)
![]() Directories in which you store scripts and CSS style sheets
Directories in which you store scripts and CSS style sheets
Using the ROBOTS meta tag or the robots.txt file, you can tell search engines to stay away. The meta tag looks like this:
<META NAME=“robots” CONTENT=“noindex, nofollow”>
This tag does two things: noindex means “Don’t index this page” and nofollow means “Don’t follow the links from this page.”
To block entire directories on your Web site, create a text file called robots.txt and place it in your site’s root directory — which is the same directory as your home page. When a search engine looks at a site, it generally requests the robots.txt file first; that is, it requests http://www.domainame.com/robots.txt.
The robots.txt file allows you to block specific search engines and allow others, but Webmasters rarely do so. In the file, you specify which search engine (user agent) you want to block and from which directories or files. Here’s how:
User-agent: *
Disallow: /includes/
Disallow: /scripts/
Disallow: /info/scripts/
Disallow: /staff.html
Because User-agent is set to *, all searchbots are blocked from www.domainname.com/includes/, www.domainname.com/scripts/, www.domainname.com/info/scripts/ directories, and the www.domainname.com/staff.html/code> file. (If you know the name of a particular searchbot that you want to block, replace the asterisk with that name.)
Be careful with your robots.txt file. If you make incomplete changes and end up with the following code, you’ve just blocked all search engines from your entire site:
User-agent: *
Disallow: /
In fact, this technique is sometimes used nefariously; I know of one case in which someone hacked into a site and placed the Disallow: / command into the robots.txt file — and Google dropped the site from its index!
Google now has a nice little robots.txt test tool in its Webmasters Console; see Chapter 12 for more information.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.