
Chapter 7. Concurrency
1. Daniel Plakosh is a senior member of the technical staff in the CERT Program of Carnegie Mellon’s Software Engineering Institute (SEI). David Svoboda is a member of the technical staff in the CERT Program of Carnegie Mellon’s Software Engineering Institute (SEI). Dean Sutherland is a senior member of the technical staff in the CERT Program of Carnegie Mellon’s Software Engineering Institute (SEI).
The race is not to the swift, nor the battle to the strong.
Ecclesiastes 9:11
Concurrency is a property of systems in which several computations execute simultaneously and potentially interact with each other [Wikipedia 2012b]. A concurrent program typically performs computations using some combination of sequential threads and/or processes, each performing a computation, which can be logically executed in parallel. These processes and/or threads can execute on a single processor system using preemptive time sharing (interleaving the execution steps of each thread and/or process in a time-slicing way), in a multicore/multiprocessor system, or in a distributed computing system. Concurrent execution of multiple control flows is an essential part of a modern computing environment.
7.1. Multithreading
Concurrency and multithreading are often erroneously considered synonymous. Multithreading is not necessarily concurrent [Liu 2010]. A multithreaded program can be constructed in such a way that its threads do not execute concurrently.
A multithreaded program splits into two or more threads that may execute concurrently. Each thread acts as an individual program, but all the threads work in and share the same memory. Furthermore, switching between threads is faster than switching between processes [Barbic 2007]. Finally, multiple threads can be executed in parallel on multiple CPUs to boost performance gains.
Even without multiple CPUs, improvements in CPU architecture can now allow simultaneous multithreading, which weaves together multiple independent threads to execute simultaneously on the same core. Intel calls this process hyperthreading. For example, while one thread waits for data to arrive from a floating-point operation, another thread can perform integer arithmetic [Barbic 2007].
Regardless of the number of CPUs, thread safety must be dealt with to avoid potentially devastating bugs arising from possible execution orderings.
A single-threaded program is exactly that—the program does not spawn any additional threads. As a result, single-threaded programs usually do not need to worry about synchronization and can benefit from a single powerful core processor [Barbic 2007]. However, they don’t benefit from the performance of multiple cores, because all instructions must be run sequentially in a single thread on one processor. Some processors can take advantage of instruction-level parallelism by running multiple instructions from the same instruction stream simultaneously; when doing so, they must produce the same result as if the instructions had been executed sequentially.
However, even single-threaded programs can have concurrency issues. The following program demonstrates interleaved concurrency in that only one execution flow can take place at a time. The program also contains undefined behavior resulting from the use of a signal handler, which provides concurrency issues without multithreading:
01 char *err_msg;
02 #define MAX_MSG_SIZE = 24;
03 void handler(int signum) {
04 strcpy(err_msg, "SIGINT encountered.");
05 }
06
07 int main(void) {
08 signal(SIGINT, handler);
09 err_msg = (char *)malloc(MAX_MSG_SIZE);
10 if (err_msg == NULL) {
11 /* handle error condition */
12 }
13 strcpy(err_msg, "No errors yet.");
14 /* main code loop */
15 return 0;
16 }
While using only one thread, this program employs two control flows: one using main() and one using the handler() function. If the signal handler is invoked during the call to malloc(), the program can crash. Furthermore, the handler may be invoked between the malloc() and strcpy() calls, effectively masking the signal call, with the result being that err_msg contains "No errors yet." For more information, see The CERT C Secure Coding Standard [Seacord 2008], “SIG30-C. Call only asynchronous-safe functions within signal handlers.”
7.2. Parallelism
Concurrency and parallelism are often considered to be equivalent, but they are not. All parallel programs are concurrent, but not all concurrent programs are parallel. This means that concurrent programs can execute in both an interleaved, time-slicing fashion and in parallel, as shown in Figure 7.1 and Figure 7.2 [Amarasinghe 2007].


Parallel computing is the “simultaneous use of multiple computer resources to solve a computational problem” [Barney 2012]. The problem is broken down into parts, which are broken down again into series of instructions. Instructions from each part are then run in parallel on different CPUs to achieve parallel computing. Each part must be independent of the others and simultaneously solvable; the end result is that the problem can be solved in less time than with a single CPU.
The scale of parallelism in computing can vary. When a computation problem is broken up, the parts can be split among an arbitrary number of computers connected by a network. Subsequently, each individual computer can break the problem into even smaller parts and divide those parts among multiple processors. The problem at hand is solved in significantly less time than if a single computer with a single core were to solve it [Barney 2012].
Data Parallelism
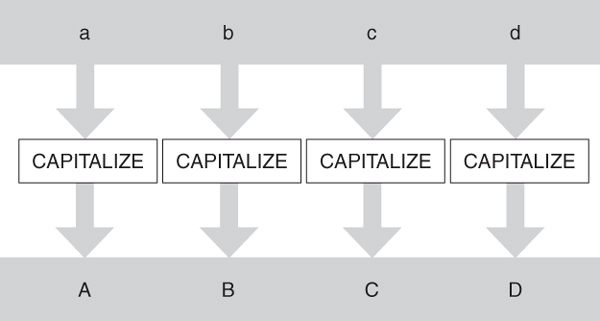
Parallelism consists of both data parallelism and task parallelism. These vary by the degree to which a problem is decomposed. Data parallelism, shown in Figure 7.3, decomposes a problem into data segments and applies a function in parallel, in this case to capitalize characters stored in an array. Data parallelism can be used to process a unit of computation in a shorter period of time than sequential processing would require; it is fundamental to high-performance computing. For example, to calculate the sum of a two-dimensional array, a sequential solution would linearly go through and add every array entry. Data parallelism can divide the problem into individual rows, sum each row in parallel to get a list of subsums, and finally sum each subsum to take less overall computing time.
Single instruction, multiple data (SIMD) is a class of parallel computers with multiple processing elements that perform the same operation on multiple data points simultaneously. Examples of CPUs that support SIMD are Streaming SIMD Extensions (SSE) on Intel or AMD processors and the NEON instructions on ARM processors. Intel 64 and AMD64 processors include a set of 16 scalar registers (for example, RAX, RBX, and RCX) that can be used to perform arithmetic operations on integers. These registers can hold just one value at any time. A compiler might use the RAX and RBX registers to perform a simple addition. If we have 1,000 pairs of integers to add together, we need to execute 1,000 such additions. SSE adds 16 additional 128-bit wide registers. Rather than hold a single, 128-bit wide value, they can hold a collection of smaller values—for example, four 32-bit wide integers (with SSE2). These registers are called XMM0, XMM1, and so forth. They are called vector registers because they can hold several values at any one time. SSE2 also provides new instructions to perform arithmetic on these four packed integers. Consequently, four pairs of integers can be added with a single instruction in the same time it takes to add just one pair of integers when using the scalar registers [Hogg 2012].
Vectorization is the process of using these vector registers, instead of scalar registers, to improve performance. It can be performed manually by the programmer. Developers must write in assembly language or call built-in intrinsic functions. Vectorization offers the developer low-level control but is difficult and not recommended.
Most modern compilers also support autovectorization. An example is Microsoft Visual C++ 2012. The autovectorizer analyzes loops and uses the vector registers and instructions to execute them if possible. For example, the following loop may benefit from vectorization:
for (int i = 0; i < 1000; ++i)
A[i] = B[i] + C[i];
The compiler targets the SSE2 instructions in Intel and AMD processors or the NEON instructions on ARM processors. The autovectorizer also uses the newer SSE4.2 instruction set if your processor supports it.
Visual C++ allows you to specify the /Qvec-report (Auto-Vectorizer Reporting Level) command-line option to report either successfully vectorized loops only—/Qvec-report:1—or both successfully and unsuccessfully vectorized loops—/Qvec-report:2.
Microsoft Visual C++ 2012 also supports a /Qpar compiler switch that enables automatic parallelization of loops. A loop is parallelized only if the compiler determines that it is valid to do so and that parallelization would improve performance.
Microsoft Visual C++ 2012 also provides a loop pragma that controls how loop code is evaluated by the autoparallelizer and/or excludes a loop from consideration by the autovectorizer.
The loop(hint_parallel(n)) pragma is a hint to the compiler that this loop should be parallelized across n threads, where n is a positive integer literal or 0. If n is 0, the maximum number of threads is used at runtime. This is a hint to the compiler, not a command, and there is no guarantee that the loop will be parallelized. If the loop has data dependencies, or structural issues—for example, the loop stores to a scalar that’s used beyond the loop body—then the loop will not be parallelized. The loop(ivdep) pragma is a hint to the compiler to ignore vector dependencies for this loop. It is used in conjunction with hint_parallel.
By default, the autovectorizer is on and will attempt to vectorize all loops that it determines will benefit. The loop(no_vector) pragma disables the autovectorizer for the loop that follows the pragma.
Task Parallelism
Task parallelism, shown in Figure 7.4, decomposes a problem into distinct tasks that may share data. The tasks are executed at the same time, performing different functions. Because the number of tasks is fixed, this type of parallelism has limited scalability. It is supported by major operating systems and many programming languages and is generally used to improve the responsiveness of programs. For example, the average, minimum value, binary, or geometric mean of a dataset may be computed simultaneously by assigning each computation to a separate task [Plakosh 2009].

7.3. Performance Goals
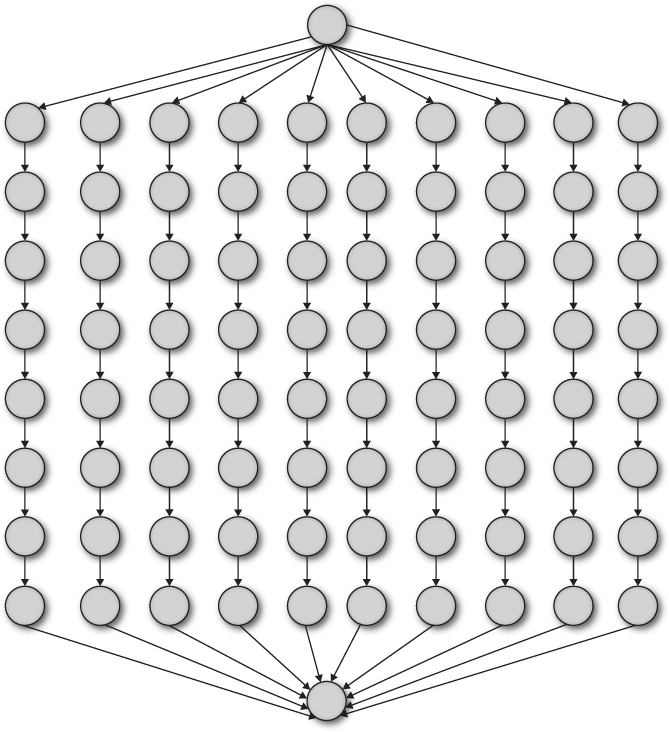
In addition to the notion of parallel computing, the term parallelism is used to represent the ratio of work (the total time spent in all the instructions) to span (the time it takes to execute the longest parallel execution path, or the critical path). The resulting value is the average amount of work performed along each step of the critical path and is the maximum possible speedup that can be obtained by any number of processors. Consequently, achievable parallelism is limited by the program structure, dependent on its critical path and amount of work. Figure 7.5 shows an existing program that has 20 seconds of work and a 10-second span. The work-to-span ratio provides little performance gain beyond two processors.
Figure 7.5. Achievable parallelism is limited by the structure (Source: Adapted from [Leiserson 2008]).
The more computations that can be performed in parallel, the bigger the advantage. This advantage has an upper bound, which can be approximated by the work-to-span ratio. However, restructuring code to be parallelized can be an expensive and risky undertaking [Leiserson 2008], and even under ideal circumstances it has limits, as shown in Figure 7.6. In this example, the work to be performed is 82 seconds, and the span is 10 seconds. Consequently, there is little performance improvement to be gained by using more than eight processors.
Amdahl’s Law
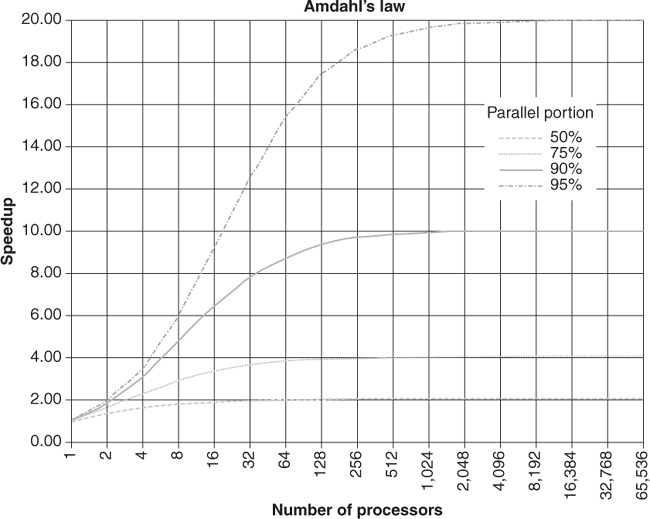
Amdahl’s law gives a more precise upper bound to the amount of speedup parallelism can achieve. Let P be the proportion of instructions that can be run in parallel and N be the number of processors. Then, according to Amdahl’s law, the amount of speedup that parallelism can achieve is at most [Plakosh 2009]

Figure 7.7 graphs the speedup according to the proportion of instructions that can be run in parallel and the number of processors.
7.4. Common Errors
Programming for concurrency has always been a difficult and error-prone process, even in the absence of security concerns. Many of the same software defects that have plagued developers over the years can also be used as attack vectors for various exploits.
Race Conditions
Uncontrolled concurrency can lead to nondeterministic behavior (that is, a program can exhibit different behavior for the same set of inputs). A race condition occurs in any scenario in which two threads can produce different behavior, depending on which thread completes first.
Three properties are necessary for a race condition to exist:
1. Concurrency property: At least two control flows must be executing concurrently.
2. Shared object property: A shared race object must be accessed by both of the concurrent flows.
3. Change state property: At least one of the control flows must alter the state of the race object.
Race conditions are a software defect and are a frequent source of vulnerabilities. Race conditions are particularly insidious because they are timing dependent and manifest sporadically. As a result, they are difficult to detect, reproduce, and eliminate and can cause errors such as data corruption or crashes [Amarasinghe 2007].
Race conditions result from runtime environments, including operating systems that must control access to shared resources, especially through process scheduling. It is the programmer’s responsibility to ensure that his or her code is properly sequenced regardless of how runtime environments schedule execution (given known constraints).
Eliminating race conditions begins with identifying race windows. A race window is a code segment that accesses the race object in a way that opens a window of opportunity during which other concurrent flows could “race in” and alter the race object. Furthermore, a race window is not protected by a lock or any other mechanism. A race window protected by a lock or by a lock-free mechanism is called a critical section.
For example, suppose a husband and wife simultaneously attempt to withdraw all money from a joint savings account, each from a separate ATM. Both check the balance, then withdraw that amount. The desired behavior would be to permit one person to withdraw the balance, while the other discovers that the balance is $0. However, a race condition may occur when both parties see the same initial balance and both are permitted to withdraw that amount. It is even possible that the code allowing the race condition will fail to notice the overdraft in the account balance!
For the savings account race condition, the concurrent flows are represented by the husband and wife, the shared object is the savings account, and the change state property is satisfied by withdrawals. Savings account software that contains such a race condition might be exploited by an attacker who is able to coordinate the actions of several actors using ATMs simultaneously.
Following is a code example of a C++ function with a race condition that is not thread-safe:
1 static atomic<int> UnitsSold = 0;
2
3 void IncrementUnitsSold(void) {
4 UnitsSold = UnitsSold + 1;
5 }
In this example, if two separate threads invoke the function IncrementUnitsSold(), the race condition shown in Table 7.1 can occur.

After the two threads invoke the function IncrementUnitsSold(), the variable UnitsSold should be set to 2 but instead is set to 1 because of the inherent race condition resulting from unsynchronized access to the variable UnitsSold.
Corrupted Values
Values written during a race condition can easily become corrupted. Consider what would happen if the following code were executed on a platform that performs stores of only 8-bit bytes:
1 short int x = 0;
2
3 // Thread 1 // Thread 2
4 x = 100; x = 300;
If the platform were to write a 16-bit short int, it might do so by writing first the upper 8 bits in one instruction and then the lower 8 bits in a second instruction. If two threads simultaneously perform a write to the same short int, it might receive the lower 8 bytes from one thread but the upper 8 bytes from the other thread. Table 7.2 shows a possible execution scenario.

The most common mitigation to prevent such data corruption is to make x an atomic type. Doing so would guarantee that the two writes cannot be interleaved and would mandate that once the threads had completed, x would be set either to 100 or to 300.
Here is a similar example:
1 struct {int x:8; int y:8} s;
2 s.x = 0; s.y = 0;
3
4 // Thread 1 // Thread 2
5 s.x = 123; s.y = 45;
An implementation that can only perform stores of 16-bit bytes would be unable to write s.x without also overwriting s.y. If two threads simultaneously perform a write to the word containing both bit-field integers, then s.x may receive the 0 implicitly assigned by thread 2, while s.y receives the 0 implicitly assigned by thread 1.
Volatile Objects
An object that has volatile-qualified type may be modified in ways unknown to the compiler or have other unknown side effects. Asynchronous signal handling, for example, may cause objects to be modified in a manner unknown to the compiler.
The volatile type qualifier imposes restrictions on access and caching. According to the C Standard:
Accesses to volatile objects are evaluated strictly according to the rules of the abstract machine.
According to the C99 Rationale [ISO/IEC 2003]:
No caching through this lvalue: each operation in the abstract semantics must be performed (that is, no caching assumptions may be made, since the location is not guaranteed to contain any previous value).
In the absence of the volatile qualifier, the contents of the designated location may be assumed to be unchanged except for possible aliasing. For example, the following program relies on the reception of a SIGINT signal to toggle a flag to terminate a loop. However, the read from interrupted in main() may be optimized away by the compiler because the variable is not declared volatile, despite the assignment to the variable in the signal handler, and the loop may never terminate. When compiled on GCC with the -O optimization flag, for example, the program fails to terminate even upon receiving a SIGINT.
01 #include <signal.h>
02
03 sig_atomic_t interrupted; /* bug: not declared volatile */
04
05 void sigint_handler(int signum) {
06 interrupted = 1; /* assignment may not be visible in main() */
07 }
08
09 int main(void) {
10 signal(SIGINT, sigint_handler);
11 while (!interrupted) { /* loop may never terminate */
12 /* do something */
13 }
14 return 0;
15 }
By adding the volatile qualifier to the variable declaration, interrupted is guaranteed to be accessed from its original address for every iteration of the while loop as well as from within the signal handler. The CERT C Secure Coding Standard [Seacord 2008], “DCL34-C. Use volatile for data that cannot be cached,” codifies this rule.
01 #include <signal.h>
02
03 volatile sig_atomic_t interrupted;
04
05 void sigint_handler(int signum) {
06 interrupted = 1;
07 }
08
09 int main(void) {
10 signal(SIGINT, sigint_handler);
11 while (!interrupted) {
12 /* do something */
13 }
14 return 0;
15 }
When a variable is declared volatile, the compiler is forbidden to reorder the sequence of reads and writes to that memory location. However, the compiler might reorder these reads and writes relative to reads and writes to other memory locations. The following program fragment attempts to use a volatile variable to signal a condition about a nonvolatile data structure to another thread:
1 volatile int buffer_ready;
2 char buffer[BUF_SIZE];
3
4 void buffer_init() {
5 for (size_t i = 0; i < BUF_SIZE; i++)
6 buffer[i] = 0;
7 buffer_ready = 1;
8 }
The for loop on line 5 neither accesses volatile locations nor performs any side-effecting operations. Consequently, the compiler is free to move the loop below the store to buffer_ready, defeating the developer’s intent.
It is a misconception that the volatile type qualifier guarantees atomicity, visibility, or memory access sequencing. The semantics of the volatile type qualifier are only loosely specified in the C and C++ standards because each implementation may have different needs. For example, one implementation may need to support multiple cores, while another may need only to support access to memory-mapped I/O registers. In the pthread context, the volatile type qualifier has generally not been interpreted to apply to interthread visibility. According to David Butenhof, “The use of volatile accomplishes nothing but to prevent the compiler from making useful and desirable optimizations, providing no help whatsoever in making code ‘thread safe.’”2 As a result, most implementations fail to insert sufficient memory fences to guarantee that other threads, or even hardware devices, see volatile operations in the order in which they were issued. On some platforms, some limited ordering guarantees are provided, either because they are automatically enforced by the underlying hardware or, as on Itanium, because different instructions are generated for volatile references. But the specific rules are highly platform dependent. And even when they are specified for a specific platform, they may be inconsistently implemented [Boehm 2006].
2. comp.programming.threads posting, July 3, 1997, https://groups.google.com/forum/?hl=en&fromgroups=#!topic/comp.programming.threads/OZeX2EpcN9U.
Type-qualifying objects as volatile does not guarantee synchronization between multiple threads, protect against simultaneous memory accesses, or guarantee atomicity of accesses to the object.
7.5. Mitigation Strategies
Many libraries and platform-specific extensions have been developed to support concurrency in the C and C++ languages. One common library is the POSIX threading library (pthreads), first published by POSIX.1c [IEEE Std 1003.1c-1995].
In 2011, new versions of the ISO/IEC standards for C and C++ were published; both provide support for multithreaded programs. Integrating thread support into the language was judged to have several major advantages over providing thread support separately via a library. Extending the language forces compiler writers to make compilers aware of multithreaded programs and thread safety. The thread support for C was derived from the thread support for C++ for maximum compatibility, making only syntactic changes to support C’s smaller grammar. The C++ thread support uses classes and templates.
Memory Model
Both C and C++ use the same memory model, which was derived (with some variations) from Java. The memory model for a standardized threading platform is considerably more complex than previous memory models. The C/C++ memory model must provide thread safety while still allowing fine-grained access to the hardware, and especially to any low-level threading primitives that a platform might offer.
It is tempting to believe that when two threads avoid accessing the same object simultaneously, the program has acted correctly. However, such programs can still be dangerous because of compiler reordering and visibility:
Compiler reordering. Compilers are given considerable latitude in reorganizing a program. The C++ 2011 standard says, in Section 1.9, paragraph 1:
The semantic descriptions in this International Standard define a parameterized nondeterministic abstract machine. This International Standard places no requirement on the structure of conforming implementations. In particular, they need not copy or emulate the structure of the abstract machine. Rather, conforming implementations are required to emulate (only) the observable behavior of the abstract machine as explained below.5
Footnote 5 says:
This provision is sometimes called the “as-if” rule, because an implementation is free to disregard any requirement of this International Standard as long as the result is as if the requirement had been obeyed, as far as can be determined from the observable behavior of the program. For instance, an actual implementation need not evaluate part of an expression if it can deduce that its value is not used and that no side effects affecting the observable behavior of the program are produced.
The C Standard contains a similar version of the as-if rule in Section 5.1.2.3, “Program execution.”
The as-if rule gives license to compilers to alter the order of instructions of a program. Compilers that are not designed to compile multithreaded programs may employ the as-if rule in a program as if the program were single-threaded. If the program uses a thread library, such as POSIX threads, the compiler may, in fact, transform a thread-safe program into a program that is not thread-safe.
The following code is commonly known as Dekker’s example [Boehm 2012], after the Dutch mathematician Theodorus Jozef Dekker:
1 int x = 0, y = 0, r1 = 0, r2 = 0;
2
3 // Thread 1 // Thread 2
4 x = 1; y = 1;
5 r1 = y; r2 = x;
Ideally, when both threads complete, both r1 and r2 are set to 1. However, the code lacks protection against race conditions. Therefore, it is possible for thread 1 to complete before thread 2 begins, in which case r1 will still be 0. Likewise, it is possible for r2 to remain 0 instead.
However, there is a fourth possible scenario: both threads could complete with both r1 and r2 still set to 0! This scenario is possible only because compilers and processors are allowed to reorder the events in each thread, with the stipulation that each thread must behave as if the actions were executed in the order specified. So the execution ordering shown in Table 7.3 is valid.

Visibility. Even if the compiler avoids reordering statements in this fashion, hardware configurations may still permit this scenario to occur. This could happen, for example, if each thread were executed by a separate processor, and each processor had one level of cache RAM that mirrors general memory. Note that modern hardware can have two or even three levels of cache memory isolating processors from RAM. It is possible for thread 1 to set x to 1 before thread 2 reads the value of x, but for the updated value of x to fail to reach thread 2’s cache before thread 2 reads the value, causing thread 2 to read a stale value of 0 for x.
Data Races
The problems of visibility and the possibility of compiler reordering of a program complicate thread safety for C and C++. To address these issues, the standards for both languages define a specific type of race condition called a data race.
Both the C and C++ standards state:
The execution of a program contains a data race if it contains two conflicting actions in different threads, at least one of which is not atomic, and neither happens before the other. Any such data race results in undefined behavior.
Two expression evaluations conflict if one of them modifies a memory location and the other one reads or modifies the same memory location.
Happens-Before
The standard also has a specific definition for when one action “happens before” another. If two actions that involve shared data are executed by different threads, the actions must be synchronized. For example, if a mutex is unlocked by the first thread after its action, and the same mutex is locked by the second thread before its action, the appropriate happens-before relationship is established. Likewise, if an atomic value is written by the first thread and is subsequently read by the second thread, the first action happens before the second. Finally, if two actions occur within a single thread, the first action happens before the second.
According to the standard C memory model, the data race in Dekker’s example occurs because two threads access a shared value (both x and y in this example), and at least one thread attempts to write to the value. Furthermore, the example lacks synchronization to establish a happens-before relationship between the threads’ actions. This scenario can be mitigated by locks, which guarantee that no stale values are read and enforce restrictions on the order in which statements can be executed on each thread.
Data races, unlike race conditions, are specific to memory access and may not apply to other shared objects, such as files.
Relaxed Atomic Operations
Relaxed atomic operations can be reordered in both directions, with respect to either ordinary memory operations or other relaxed atomic operations. But the requirement that updates must be observed in modification order disallows this if the two operations may apply to the same atomic object. The same restriction applies to the one-way reordering of acquire/release atomic operations [Boehm 2007]. It is also important to note that relaxed atomic operations are not synchronization operations. The permitted reordering and the lack of synchronization make these operations difficult to use in isolation. However, they can be used in conjunction with acquire/release operations. The detailed rules regarding safe use of relaxed atomic operations can be confusing, even for experts. Consequently, we recommend that such operations be used only when absolutely necessary and only by experts. Even then, substantial care and review are warranted.
Synchronization Primitives
To prevent data races, any two actions that act on the same object must have a happens-before relation. The specific order of the operations is irrelevant. This relation not only establishes a temporal ordering between the actions but also guarantees that the memory altered by the first action is visible to the second action.
A happens-before relation can be established using synchronization primitives. C and C++ support several different kinds of synchronization primitives, including mutex variables, condition variables, and lock variables. Underlying operating systems add support for additional synchronization primitives such as semaphores, pipes, named pipes, and critical section objects. Acquiring a synchronization object before a race window and then releasing it after the window ends makes the race window atomic with respect to other code using the same synchronization mechanism. The race window effectively becomes a critical section of code. All critical sections appear atomic to all appropriately synchronized threads other than the thread performing the critical section.
Many strategies exist to prevent critical sections from executing concurrently. Most of these involve a locking mechanism that causes one or more threads to wait until another thread has exited the critical section.
Here is an example of a program that uses threads to manipulate shared data:
01 #include <thread>
02 #include <iostream>
03 using namespace std;
04
05 int shared_data = 0;
06
07 void thread_function(int id) {
08 shared_data = id; // start of race window on shared_data
09 cout << "Thread " << id << " set shared value to "
10 << shared_data << endl;
11 usleep(id * 100);
12 cout << "Thread " << id << " has shared value as "
13 << shared_data << endl;
14 // end of race window on shared_data
15 }
16
17 int main(void) {
18 const size_t thread_size = 10;
19 thread threads[thread_size];
20
21 for (size_t i = 0; i < thread_size; i++)
22 threads[i] = thread(thread_function, i);
23
24 for (size_t i = 0; i < thread_size; i++)
25 threads[i].join();
26 // Wait until threads are complete before main() continues
27
28 cout << "Done" << endl;
29 return 0;
30 }
This code fails to protect shared_data from being viewed inconsistently by each call to thread_function(). Typically, each thread will report that it successfully set the shared value to its own ID, and then sleep. But when the threads wake up, each thread will report that the shared value contains the ID of the last thread to set it. Mutual exclusion is necessary to maintain a consistent value for the shared data.
Each thread exhibits a race window between the point when it assigns its own ID to the shared data and the point at which the thread last tries to print the shared data value, after the thread has slept. If any other thread were to modify the shared data during this window, the original thread would print an incorrect value. To prevent race conditions, no two threads can access the shared data during the race window; they must be made mutually exclusive. That is, only one thread may access the shared data at a time.
The following code sample attempts to use a simple integer as a lock to prevent data races on the shared_data object. When the lock is set by one thread, no other thread may enter the race window until the first thread clears the lock. This makes the race windows on shared_lock mutually exclusive.
01 int shared_lock = 0;
02
03 void thread_function(int id) {
04 while (shared_lock) // race window on shared_lock begins here
05 sleep(1);
06 shared_lock = 1; // race window on shared_lock ends here
07 shared_data = id; // race window on shared_data begins here
08 cout << "Thread " << id << " set shared value to "
09 << shared_data << endl;
10 usleep(id * 100);
11 cout << "Thread " << id << " has shared value as "
12 << shared_data << endl;
13 // race window on shared_data ends here
14 shared_lock = 0;
15 }
Unfortunately, this program introduces a second race window, this one on the shared lock itself. It is possible for two threads to simultaneously discover that the lock is free, then to both set the lock and proceed to enter the race window on the shared data. In essence, this code sample merely shifts the data race away from the data and onto the lock, leaving the program just as vulnerable as it was without the lock.
Clearly, programmers who intend to use an object as a lock require an object that prevents race windows on itself.
Mutexes
One of the simplest locking mechanisms is an object called a mutex. A mutex has two possible states: locked and unlocked. After a thread locks a mutex, any subsequent threads that attempt to lock that mutex will block until the mutex is unlocked. After the mutex is unlocked, a blocked thread can resume execution and lock the mutex to continue. This strategy ensures that only one thread can run bracketed code at a time. Consequently, mutexes can be wrapped around critical sections to serialize them and make the program thread-safe. Mutexes are not associated with any other data. They serve only as lock objects.
The previous program fragment can be made thread-safe by using a mutex as the lock:
01 mutex shared_lock;
02
03 void thread_function(int id) {
04 shared_lock.lock();
05 shared_data = id;
06 cout << "Thread " << id << " set shared value to "
07 << shared_data << endl;
08 usleep(id * 100);
09 cout << "Thread " << id << " has shared value as "
10 << shared_data << endl;
11 shared_lock.unlock();
12 }
As shown, C++ mutexes can be locked and unlocked. When a lock() operation is performed on an already-locked mutex, the function blocks until the thread currently holding the lock releases it. The try_lock() method attempts to lock the mutex but immediately returns if the mutex is already locked, allowing the thread to perform other actions. C++ also supports timed mutexes that provide try_lock_for() and try_lock_until() methods. These methods block until either the mutex is successfully locked or a specified amount of time has elapsed. All other methods behave like normal mutexes. C++ also supports recursive mutexes. These mutexes behave like normal mutexes except that they permit a single thread to acquire the lock more than once without an intervening unlock. A thread that locks a mutex multiple times must unlock it the same number of times before any other thread can lock the mutex. Nonrecursive mutexes cannot be locked more than once by the same thread without an intervening unlock. Finally, C++ supports mutexes that are both timed and recursive.
C mutex support is semantically identical to C++ mutex support, but with different syntax because C lacks classes and templates. The C standard library provides the mtx_lock(), mtx_unlock(), mtx_trylock(), and mtx_timedlock() functions to lock and unlock mutexes. It also provides mtx_init() and mtx_destroy() to create and destroy mutexes. The signature of the mtx_init() function is
int mtx_init(mtx_t *mtx, int type);
The mtx_init function creates a mutex object with properties indicated by type that must have one of these values:
• mtx_plain for a simple nonrecursive mutex
• mtx_timed for a nonrecursive mutex that supports time-out
• mtx_plain | mtx_recursive for a simple recursive mutex
• mtx_timed | mtx_recursive for a recursive mutex that supports time-out
Lock Guards
A lock guard is a standard object that assumes responsibility for a mutex (actually, for any lock object). When a lock guard is constructed over a mutex, it attempts to lock the mutex; it unlocks the mutex when the lock guard is itself destroyed. Lock guards apply Resource Acquisition Is Initialization (RAII) to mutexes. Consequently, we recommend use of lock guards when programming in C++ to mitigate the problems that would otherwise occur if a critical section were to throw an exception or otherwise exit without explicitly unlocking the mutex. Here is a version of the previous code example that uses a lock guard:
01 mutex shared_lock;
02
03 void thread_function(int id) {
04 lock_guard<mutex> lg(shared_lock);
05 shared_data = id;
06 cout << "Thread " << id << " set shared value to "
07 << shared_data << endl;
08 usleep(id * 100);
09 cout << "Thread " << id << " has shared value as "
10 << shared_data << endl;
11 // lg destroyed and mutex implicitly unlocked here
12 }
Atomic Operations
Atomic operations are indivisible. That is, an atomic operation cannot be interrupted by any other operation, nor can the memory it accesses be altered by any other mechanism while the atomic operation is executing. Consequently, an atomic operation must run to completion before anything else can access the memory used by the operation; the operation cannot be divided into smaller parts. Simple machine instructions, such as a register load, may be uninterruptible. A memory location accessed by an atomic load may not be accessed by any other thread until the atomic operation is complete.
An atomic object is any object that guarantees that all actions performed on it are atomic. By imposing atomicity on all operations over an object, an atomic object cannot be corrupted by simultaneous reads or writes. Atomic objects are not subject to data races, although they still may be affected by race conditions.
C and C++ provide extensive support for atomic objects. Every basic data type has an analogous atomic data type. As a result, the previous code example can also be made thread-safe by using an atomic object as the lock:
01 volatile atomic_flag shared_lock;
02
03 void thread_function(int id) {
04 while (shared_lock.test_and_set()) sleep(1);
05 shared_data = id;
06 cout << "Thread " << id << " set shared value to "
07 << shared_data << endl;
08 usleep(id * 100);
09 cout << "Thread " << id << " has shared value as "
10 << shared_data << endl;
11 shared_lock.clear();
12 }
The atomic_flag data type provides the classic test-and-set functionality. It has two states, set and clear. In this code example, the test_and_set() method of the atomic_flag object sets the flag only when the flag was previously unset. The test_and_set() method returns false when the flag was successfully set and true when the flag was already set. This has the same effect as setting an integer lock to 1 only when it was previously 0; however, because the test_and_set() method is atomic, it lacks a race window in which other methods could tamper with the flag. Because the shared lock prevents multiple threads from entering the critical section, the code is thread-safe.
The following example is also thread-safe:
01 atomic<int> shared_lock;
02
03 void thread_function(int id) {
04 int zero = 0;
05 while (!atomic_compare_exchange_weak(&shared_lock, &zero, 1))
06 sleep(1);
07 shared_data = id;
08 cout << "Thread " << id << " set shared value to "
09 << shared_data << endl;
10 usleep(id * 100);
11 cout << "Thread " << id << " has shared value as "
12 << shared_data << endl;
13 shared_lock = 0;
14 }
The principle is the same as before, but the lock object is now an atomic integer that can be assigned numeric values. The atomic_compare_exchange_weak() function safely sets the lock to 1. Unlike the atomic_flag::test_and_set() method, the atomic_compare_exchange_weak() function is permitted to fail spuriously. That is, it could fail to set the atomic integer to 1 even when it had the expected value of 0. For this reason, atomic_compare_exchange_weak() must always be invoked inside a loop so that it can be retried in the event of spurious failure.
Programs can access atomic types and related functions by including the stdatomic.h header file. Atomicity support is available when the __STDC_NO_ATOMICS__ macro is undefined. The C standard also defines the _Atomic qualifier, which designates an atomic type. The size, representation, and alignment of an atomic type need not be the same as those of the corresponding unqualified type. For each atomic type, the standard also provides an atomic type name, such as atomic_short or atomic_ulong. The atomic_ulong atomic type name has the same representation and alignment requirements as the corresponding direct type _Atomic unsigned long. These types are meant to be interchangeable as arguments to functions, return values from functions, and members of unions.
Each atomic integer type supports load and store operations as well as more advanced operations. The atomic_exchange() generic function stores a new value into an atomic variable while returning the old value. And the atomic_compare_exchange() generic function stores a new value into an atomic variable when, and only when, the variable currently contains a specific value; the function returns true only when the atomic variable was successfully changed. Finally, the atomic integers support read-modify-write operations such as the atomic_fetch_add() function. This function has behavior similar to that of the += operator with two differences. First, it returns the variable’s old value, whereas += returns the sum. Second, += lacks thread-safety guarantees; the atomic fetch function promises that the variable cannot be accessed by any other threads while the addition takes place. Similar fetch functions exist for subtraction, bitwise-and, bitwise-or, and bitwise-exclusive-or.
The C Standard also defines an atomic_flag type which supports only two functions: the atomic_flag_clear() function clears the flag; the atomic_flag_test_and_set() function sets the flag if, and only if, it was previously clear. The atomic_flag type is guaranteed to be lock-free. Variables of other atomic types may or may not be manipulated in a lock-free manner.
The C++ Standard provides a similar API to C. It provides the <atomic> header file. C++ provides an atomic<> template for creating atomic versions of integer types, such as atomic<short> and atomic<unsigned long>. The atomic_bool behaves similarly to C and has a similar API.
The C++ Standard supports the same atomic operations as C; however, they may be expressed either as functions or as methods on the atomic template objects. For instance, the atomic_exchange() function works as in C but is supplanted by the atomic<>::exchange() template method. Furthermore, C++ provides overloaded versions of the additive operators (+, -, ++, --, +=, -=) that use the atomic_fetch_add() and similar functions. C++ lacks operators that provide the corresponding bitwise functionality.
Fences
A memory barrier, also known as a memory fence, is a set of instructions that prevents the CPU and possibly the compiler from reordering read and write operations across the fence. Remember that data races are a more egregious problem than other types of race conditions because data races can arise from compilers reordering instructions or from data written by one thread that is not readable from another thread at a later time. Once again, consider Dekker’s example:
1 int x = 0, y = 0, r1 = 0, r2 = 0;
2
3 // Thread 1 // Thread 2
4 x = 1; y = 1;
5 r1 = y; r2 = x;
It is possible for both r1 and r2 to be set to 0 after this program completes. This would occur if thread 1 reads y before thread 2 has assigned 1 to it. Or thread 2 may have assigned 1 to y, but the value 1 may have been cached and consequently have failed to reach thread 1 by the time thread 1 read y.
Memory barriers are a low-level approach to mitigating such data races. The following code fragment adds memory fences:
1 int x = 0, y = 0, r1 = 0, r2 = 0;
2
3 // Thread 1 // Thread 2
4 x = 1; y = 1;
5 atomic_thread_fence( atomic_thread_fence(
6 memory_order_seq_cst); memory_order_seq_cst);
7 r1 = y; r2 = x;
The fences prevent the program from completing with both r1 and r2 having the value 0. This is because the fences guarantee that x has a nonzero value before r1 is assigned, and that y has a nonzero value before r2 is assigned. Furthermore, the memory fence for thread 1 guarantees that if thread 1 reaches its fence instruction before thread 2 reads the value of x, thread 2 will see x as having the value 1. Thread 2’s fence also guarantees that it will not read the value of x before assigning y to 1, and thread 1 will therefore see y having the value 1 should thread 2’s memory fence be executed before thread 1’s read of y.
This code is still subject to race conditions; either r1 or r2 could still have a value of 0, depending on how quickly each thread executes its code. But by imposing constraints on both the ordering of the instructions and the visibility of the data, the fences prevent the counterintuitive scenario where both r1 and r2 wind up with the value 0.
Semaphores
A semaphore is similar to a mutex, except that a semaphore also maintains a counter whose value is declared upon initialization. Consequently, semaphores are decremented and incremented rather than locked and unlocked. Typically, a semaphore is decremented at the beginning of a critical section and incremented at the end of the critical section. When a semaphore’s counter reaches 0, subsequent attempts to decrement the semaphore will block until the counter is incremented.
The benefit of a semaphore is that it controls the number of threads currently accessing a critical section or sections that are guarded by the semaphore. This is useful for managing pools of resources or coordinating multiple threads that use a single resource. The initial value of the semaphore counter is the total number of threads that will be granted concurrent access to critical sections guarded by that semaphore. Note that a semaphore with an initial counter of 1 behaves as though it were a mutex.
Lock-Free Approaches
Lock-free algorithms provide a way to perform operations on shared data without invoking costly synchronization functions between threads. Although lock-free approaches sound appealing, implementing lock-free code that is perfectly correct is difficult in practice [Sutter 2008]. Additionally, known correct lock-free solutions are not generally useful for solving problems where locking is required. That said, some lock-free solutions do have value in certain situations, but they must be used cautiously.
The standard atomic_compare_exchange_weak() function and the atomic_flag::test_and_set() method are lock-free approaches. They use built-in mutual exclusion techniques to make them atomic rather than using explicit lock objects, such as mutexes.
Message Queues
Message queues are an asynchronous communication mechanism used for communication between threads and processes. Message-passing concurrency tends to be far easier to reason about than shared-memory concurrency, which usually requires the application of some form of locking (for example, mutexes, semaphores, or monitors) to coordinate between threads [Wikipedia 2012c].
Thread Role Analysis (Research)
Many multithreaded software systems contain policies that regulate associations among threads, executable code, and potentially shared state. For example, a system may constrain which threads are permitted to execute particular code segments, usually as a means to constrain those threads from reading or writing particular elements of state. These thread usage policies ensure properties such as state confinement or reader/writer constraints, often without recourse to locking or transaction discipline. The concept of thread usage policy is not language specific; similar issues arise in many popular languages, including C, C++, Java, C#, Objective-C, and Ada. Currently, the preconditions contained in thread usage policies are often difficult to identify, poorly considered, unstated, poorly documented, incorrectly expressed, outdated, or simply difficult to find.
Most modern graphical user interface (GUI) libraries, for example, require that the majority of their functions be invoked only from a particular thread, often known as the event thread.3 This implementation decision allows the GUI libraries’ internal code to avoid the expense of locking all accesses to its internal data structures. Furthermore, because events could originate either from the underlying system or from the user, and consequently propagate through the library in opposing directions, it can be difficult or impossible for GUI library implementers to find a consistent lock ordering that avoids the potential for deadlock. Requiring single-threaded access by client code eliminates this problem by confining the internal state to a single thread at a time. However, it also makes these libraries vulnerable to client code that violates the required thread usage policy. Thread role analysis is a promising technique that enables developers to express, discover, and enforce thread usage policies with zero runtime cost.
3. Examples include most X Window System implementations, the Macintosh GUI, and the AWT/Swing and SWT GUI libraries for Java.
Many current libraries and frameworks lack explicit specification of thread usage policies. In the absence of explicit specifications, developers must make assumptions about what the missing preconditions might be; these assumptions are frequently incorrect. Failure to comply with the actual thread-related preconditions can lead to errors such as state corruption and deadlock. These errors are often intermittent and difficult to diagnose, and they can introduce security vulnerabilities.
Thread role analysis addresses these issues by introducing a lightweight annotation language for expressing thread usage policies and an associated static analysis that can check the consistency of an expressed policy and as-written code. An existing system prototype supports incremental adoption through analysis of partially annotated programs, providing useful results even when most code lacks annotations.
Annotation Language
A thread usage policy consists of three main parts:
1. A declaration of the relevant thread roles and their compatibility with each other
2. Annotation of key function headers to indicate which thread roles may execute them
3. Annotation of the code locations where thread roles may change
The static analysis tracks the changing thread roles through the code and reports inconsistencies along with suggestions for likely next-step annotations.
The following examples use C++ annotation syntax; systems supporting this analysis may use alternate syntax, but all concepts remain the same.
Thread roles4 are declared with the thrd_role_decl annotation. The annotation [[thrd_role_decl(Event, Compute)]], for example, declares two thread roles named Event and Compute. The names of thread roles lack any built-in semantics; their meaning is up to the developer. To indicate that threads performing the Event role may never simultaneously perform the Compute role, you specify [[thrd_role_inc(Event, Compute)]]. Finally, to indicate that there can be at most one Event thread at a time, you specify [[thrd_role_count(Event, 1)]]. Unlike other thread role annotations, thrd_role_count is purely declarative and is unchecked. Most programs require only a handful of declarative annotations. The largest number of thread roles seen in a single program to date is under 30.
4. Thread roles are used instead of thread identity both because many roles are performed by multiple threads (consider worker threads from a pool) and because many individual threads perform multiple roles simultaneously (for example, a Worker thread that is currently a Compute thread that is Rendering text to print).
The majority of thread role annotations are constraints placed on functions. These constraints specify which thread roles are permitted (or forbidden) to execute the annotated function. The argument to the annotation is a simple Boolean expression over the names of thread roles. When placed on a function, the annotation [[thrd_role(Event)]] indicates that the function may be executed only by threads performing the Event role.5 This annotation is equivalently written as [[thrd_role(Event & !Compute)]] because of the previous thrd_role_inc annotation. Consequently, the function may be called only from code contexts that are known to be executed by such threads and may not be called from code contexts known to be executed by threads performing incompatible roles (such as the Compute role in this example). Constraint annotations should generally be placed on API functions; the static analysis infers the constraints for most non-API functions.
5. Negated roles are disallowed, nonnegated roles are required, and unmentioned roles are “don’t-care.”
Finally, the static analysis must be informed where thread roles change, using the thrd_role_grant annotation. Typical locations for these annotations are inside the functions that serve as the main entry point for a thread, with the annotation specifying the role performed by that thread. A secondary use is to add one or more thread roles to an existing thread, for example, when assigning work to a worker thread from a pool of threads. Granted roles persist until exit from the lexical block in which the annotation appears.
Static Analysis
Thread role analysis checks for consistency between the as-written code and the expressed thread usage policy. The current research prototype for C, built as an extension to the LLVM C compiler, performs only simple sanity checks at compile time. The actual consistency check is performed at link time. This allows whole program analysis.6 For fully annotated code, the current research prototype is both conservatively correct and sound. That is, there are no false-negative reports and extremely few false positives. For partially annotated code in its default mode, the analysis suppresses errors for code that entirely lacks annotations, produces warnings and suggestions for possible additional annotations at the boundaries between annotated and unannotated code, and produces sound results for fully annotated subregions. Suppressing errors for code that lacks all thread role annotations supports incremental adoption by avoiding bothering programmers with spurious errors in code they are not yet prepared to analyze, while still providing checking for code that has expressed thread usage policies. The analysis also supports a strict mode for quality assurance or production purposes, where any missing annotation is treated as an error.
6. This assumes that mechanisms such as partial linking or runtime linking of libraries are not used.
Immutable Data Structures
As already seen, race conditions are possible only when two or more threads share data and at least one thread tries to modify the data. One common approach to providing thread safety is to simply prevent threads from modifying shared data, in essence making the data read-only. Locks are not required to protect immutable shared data.
There are several tactics for making shared data read-only. Some classes simply fail to provide any methods for modifying their data once initialized; objects of these classes may be safely shared between threads. Declaring a shared object to be const is a common tactic in C and C++.
Another approach is to clone any object that a thread may wish to modify. In this scenario, again, all shared objects are read-only, and any thread that needs to modify an object creates a private copy of the shared object and subsequently works only with its copy. Because the copy is private, the shared object remains immutable.
Concurrent Code Properties
Thread Safety
The use of thread-safe functions can help eliminate race conditions. By definition, a thread-safe function protects shared resources from concurrent access by locks [IBM 2012b] or other mechanisms of mutual exclusion. As a result, a thread-safe function can be called simultaneously by multiple threads without concern. If a function does not use static data or shared resources, it is trivially thread-safe. However, the use of global data raises a red flag for thread safety, and any use of global data must be synchronized to avoid race conditions.
To make a function thread-safe, it is necessary to synchronize access to shared resources. Specific data accesses or entire libraries can be locked. However, using global locks on a library can result in contention (described later in this section).
Reentrant
Reentrant functions can also mitigate concurrent programming bugs. A function is reentrant if multiple instances of the same function can run in the same address space concurrently without creating the potential for inconsistent states [Dowd 2006]. IBM defines a reentrant function as one that does not hold static data over successive calls, nor does it return a pointer to static data. Consequently, all data used in a reentrant function is provided by the caller, and reentrant functions must not call non-reentrant functions. Reentrant functions can be interrupted and reentered without loss of data integrity; consequently, reentrant functions are thread-safe [IBM 2012b].
Thread-Safe versus Reentrant
Thread safety and reentrancy are similar concepts yet have a few important differences. Reentrant functions are also thread-safe, but thread-safe functions may fail to be reentrant. The following function, for example, is thread-safe when called from multiple threads, but not reentrant:
01 #include <pthread.h>
02
03 int increment_counter () {
04 static int count = 0;
05 static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
06
07 pthread_mutex_lock(&mutex);
08 count++;
09 int result = count;
10 pthread_mutex_unlock(&mutex);
11
12 return result;
13 }
The increment_counter() function can be safely invoked by multiple threads because a mutex is used to synchronize access to the shared counter variable. However, if the function is invoked by an interrupt handler, interrupted, and reentered, the second invocation will deadlock.
7.6. Mitigation Pitfalls
Vulnerabilities can be introduced when concurrency is incorrectly implemented incorrectly. The paper “A Study of Common Pitfalls in Simple Multi-Threaded Programs” [Choi 2000] found the following common mistakes:
• Not having shared data protected by a lock (that is, a data race)
• Not using the lock when accessing shared data when the lock does exist
• Prematurely releasing a lock
• Acquiring the correct lock for part of an operation, releasing it, and later acquiring it again and then releasing it, when the correct approach would have been to hold the lock for the entire time
• Accidentally making data shared by using a global variable where a local one was intended
• Using two different locks at different times around shared data
• Deadlock caused by
– Improper locking sequences (locking and unlocking sequences must be kept consistent)
– Improper use or selection of locking mechanisms
– Not releasing a lock or trying to reacquire a lock that is already held
Some other common concurrency pitfalls include the following:
• Lack of fairness—all threads do not get equal turns to make progress.
• Starvation—occurs when one thread hogs a shared resource, preventing other threads from using it.
• Livelock—thread(s) continue to execute but fail to make progress.
• Assuming the threads will
– Run in a particular order
– NOT run simultaneously
– Run simultaneously
– Make progress before one thread ends
• Assuming that a variable doesn’t need to be locked because the developer thinks that it is written in only one thread and read in all others. This also assumes that the operations on that variable are atomic.
• Use of non-thread-safe libraries. A library is considered to be thread-safe if it is guaranteed to be free of data races when accessed by multiple threads simultaneously.
• Relying on testing to find data races and deadlocks.
• Memory allocation and freeing issues. These issues may occur when memory is allocated in one thread and freed in another thread; incorrect synchronization can result in memory being freed while it is still being accessed.
The remainder of this section examines some of these problems in detail.
Deadlock
Traditionally, race conditions are eliminated by making conflicting race windows mutually exclusive so that, once a critical section begins execution, no additional threads can execute until the previous thread exits the critical section. The savings account race condition, for example, can be eliminated by combining the account balance query and the withdrawal into a single atomic transaction.
The incorrect use of synchronization primitives, however, can result in deadlock. Deadlock occurs whenever two or more control flows block each other in such a way that none can continue to execute. In particular, deadlock results from a cycle of concurrent execution flows in which each flow in the cycle has acquired a synchronization object that results in the suspension of the subsequent flow in the cycle.
The following program illustrates the concept of deadlock. This code produces a fixed number of threads; each thread modifies a value and then reads it. The shared data value is guarded by one lock for each thread (thread_size), although normally one would suffice. Each thread must acquire both locks before accessing the value. If one thread acquires lock 0 first, and a second thread acquires lock 1, the program will deadlock.
01 #include <iostream>
02 #include <thread>
03 #include <mutex>
04 using namespace std;
05
06 int shared_data = 0;
07 mutex *locks = NULL;
08 int thread_size;
09
10 void thread_function(int id) {
11 if (id % 2)
12 for (int i = 0; i < thread_size; i++)
13 locks[i].lock();
14 else
15 for (int i = thread_size - 1; i >= 0; i--)
16 locks[i].lock();
17
18 shared_data = id;
19 cout << "Thread " << id << " set data to " << id << endl;
20
21 if (id % 2)
22 for (int i = thread_size - 1; i >= 0; i--)
23 locks[i].unlock();
24 else
25 for (int i = 0; i < thread_size; i++)
26 locks[i].unlock();
27 }
28
29 int main(int argc, char** argv) {
30 thread_size = atoi(argv[1]);
31 thread* threads = new thread[thread_size];
32 locks = new mutex[thread_size];
33
34 for (int i = 0; i < thread_size; i++)
35 threads[i] = thread(thread_function, i);
36
37 for (int i = 0; i < thread_size; i++)
38 threads[i].join();
39 // Wait until threads are complete before main() continues
40 delete[] locks;
41 delete[] threads;
42
43 return 0;
44 }
Here is a sample output when the preceding code is run with five threads. In this case, the program deadlocked after only one thread was allowed to complete.
thread 0 set data to 0
The potential for deadlock can be eliminated by having every thread acquire the locks in the same order. This program cannot deadlock no matter how many threads are created:
01 void thread_function(int id) {
02 for (int i = 0; i < thread_size; i++)
03 locks[i].lock();
04
05 shared_data = id;
06 cout << "Thread " << id << " set data to " << id << endl;
07
08 for (int i = thread_size - 1; i >= 0; i--)
09 locks[i].unlock();
10 }
Here is a sample output of this program when run with five threads:
Thread 0 set data to 0
Thread 4 set data to 4
Thread 2 set data to 2
Thread 3 set data to 3
Thread 1 set data to 1
The code in Example 7.1 represents two bank accounts that can accept transfers of cash between them. One thread transfers money from the first account to the second, and another thread transfers money from the second account to the first.
Example 7.1. Deadlock Caused by Improper Locking Order
01 #include <thread>
02 #include <iostream>
03 #include <mutex>
04
05 using namespace std;
06
07 int accounts[2];
08 mutex locks[2];
09
10 void thread_function(int id) { // id is 0 or 1
11 // We transfer money from our account to the other account.
12 int amount = (id + 2) * 10;
13 lock_guard<mutex> this_lock(locks[id]);
14 lock_guard<mutex> that_lock(locks[!id]);
15 accounts[id] -= amount;
16 accounts[!id] += amount;
17 cout << "Thread " << id << " transferred $" << amount
18 << " from account " << id << " to account " << !id << endl;
19 }
20
21 int main(void) {
22 const size_t thread_size = 2;
23 thread threads[thread_size];
24
25 for (size_t i = 0; i < 2; i++)
26 accounts[i] = 100;
27 for (size_t i = 0; i < 2; i++)
28 cout << "Account " << i << " has $" << accounts[i] << endl;
29
30 for (size_t i = 0; i < thread_size; i++)
31 threads[i] = thread(thread_function, i);
32
33 for (size_t i = 0; i < thread_size; i++)
34 threads[i].join();
35 // Wait until threads are complete before main() continues
36
37 for (size_t i = 0; i < 2; i++)
38 cout << "Account " << i << " has $" << accounts[i] << endl;
39 return 0;
40 }
This program will typically complete its transfers with the first account having a net balance of $110 and the second having a net balance of $90. However, the program can deadlock when thread 1 locks the first mutex and thread 2 locks the second mutex. Then thread 1 must block until thread 2’s mutex is released, and thread 2 must block until thread 1’s mutex is released. Because neither is possible, the program will deadlock.
To mitigate this problem, the accounts should be locked in a consistent order, as shown by the following code:
01 void thread_function(int id) { // id is 0 or 1
02 // We transfer money from our account to the other account.
03 int amount = (id + 2) * 10;
04 int lo_id = id;
05 int hi_id = !id;
06 if (lo_id > hi_id) {
07 int tmp = lo_id;
08 lo_id = hi_id;
09 hi_id = tmp;
10 }
11 // now lo_id < hi_id
12
13 lock_guard<mutex> this_lock(locks[lo_id]);
14 lock_guard<mutex> that_lock(locks[hi_id]);
15 accounts[id] -= amount;
16 accounts[!id] += amount;
17 cout << "Thread " << id << " transferred $" << amount
18 << " from account " << id << " to account " << !id << endl;
19 }
In this solution, the IDs of the two accounts are compared, with the lower ID being explicitly locked before the higher ID. Consequently, each thread will lock the first mutex before the second, regardless of which account is the giver or receiver of funds.
The modification to thread_function() in Example 7.2 would cause deadlock if thread 1 is not the last thread to complete running. This is because thread 1 will never actually unlock its mutex, leaving other threads unable to acquire it.
Example 7.2. Deadlock Caused by Not Releasing a Lock
01 void thread_function(int id) {
02 shared_lock.lock();
03 shared_data = id;
04 cout << "Thread " << id << " set shared value to "
05 << shared_data << endl;
06 // do other stuff
07 cout << "Thread " << id << " has shared value as "
08 << shared_data << endl;
09 if (id != 1) shared_lock.unlock();
10 }
An obvious security vulnerability from deadlock is a denial of service. In August 2004, the Apache Software Foundation reported such a vulnerability in Apache HTTP Server versions 2.0.48 and older (see US-CERT vulnerability note VU#1321107). This vulnerability results from the potential for a deadlocked child process to hold the accept mutex, consequently blocking future connections to a particular network socket.
7. www.kb.cert.org/vuls/id/132110.
Deadlock is clearly undesirable, but is deadlock or any other race condition something that an attacker can exploit? An unpatched Apache Server might run for years without exhibiting deadlock. However, like all data races, deadlock behavior is sensitive to environmental state and not just program input. In particular, deadlock (and other data races) can be sensitive to the following:
• Processor speeds
• Changes in the process- or thread-scheduling algorithms
• Different memory constraints imposed at the time of execution
• Any asynchronous event capable of interrupting the program’s execution
• The states of other concurrently executing processes
An exploit can result from altering any of these conditions. Often, the attack is an automated attempt to vary one or more of these conditions until the race behavior is exposed. Even small race windows can be exploited. By exposing the computer system to an unusually heavy load, it may be possible to effectively lengthen the time required to exploit a race window. As a result, the mere possibility of deadlock, no matter how unlikely, should always be viewed as a security flaw.
Prematurely Releasing a Lock
Consider the code in Example 7.3, which runs an array of threads. Each thread sets a shared variable to its thread number and then prints out the value of the shared variable. To protect against data races, each thread locks a mutex so that the variable is set correctly.
Example 7.3. Prematurely Releasing a Lock
01 #include <thread>
02 #include <iostream>
03 #include <mutex>
04
05 using namespace std;
06
07 int shared_data = 0;
08 mutex shared_lock;
09
10 void thread_function(int id) {
11 shared_lock.lock();
12 shared_data = id;
13 cout << "Thread " << id << " set shared value to "
14 << shared_data << endl;
15 shared_lock.unlock();
16 // do other stuff
17 cout << "Thread " << id << " has shared value as "
18 << shared_data << endl;
19 }
20
21 int main(void) {
22 const size_t thread_size = 3;
23 thread threads[thread_size];
24
25 for (size_t i = 0; i < thread_size; i++)
26 threads[i] = thread(thread_function, i);
27
28 for (size_t i = 0; i < thread_size; i++)
29 threads[i].join();
30 // Wait until threads are complete before main() continues
31
32 cout << "Done" << endl;
33 return 0;
34 }
Unfortunately, while every write to the shared variable is protected by the mutex, the subsequent reads are unprotected. The following output came from an invocation of the program that used three threads:
Thread 0 set shared value to 0
Thread 0 has shared value as 0
Thread 1 set shared value to 1
Thread 2 set shared value to 2
Thread 1 has shared value as 2
Thread 2 has shared value as 2
Done
Both reads and writes of shared data must be protected to ensure that every thread reads the same value that it wrote. Extending the critical section to include reading the value renders this code thread-safe:
01 void thread_function(int id) {
02 shared_lock.lock();
03 shared_data = id;
04 cout << "Thread " << id << " set shared value to "
05 << shared_data << endl;
06 // do other stuff
07 cout << "Thread " << id << " has shared value as "
08 << shared_data << endl;
09 shared_lock.unlock();
10 }
Here is an example of correct output from this code. Note that the order of threads can still vary, but each thread correctly prints out its thread number.
Thread 0 set shared value to 0
Thread 0 has shared value as 0
Thread 1 set shared value to 1
Thread 1 set shared value to 1
Thread 2 has shared value as 2
Thread 2 has shared value as 2
Done
Contention
Lock contention occurs when a thread attempts to acquire a lock held by another thread. Some lock contention is normal; this indicates that the locks are “working” to prevent race conditions. Excessive lock contention can lead to poor performance.
Poor performance from lock contention can be resolved by reducing the amount of time locks are held or by reducing the granularity or amount of resources protected by each lock. The longer a lock is held, the greater the probability that another thread will try to obtain the lock and be forced to wait. Conversely, reducing the duration a lock is held reduces contention. For example, code that does not act on a shared resource does not need to be protected within the critical section and can run in parallel with other threads. Executing a blocking operation within a critical section extends the duration of the critical section and consequently increases the potential for contention. Blocking operations inside critical sections can also lead to deadlock. Executing blocking operations inside critical sections is almost always a serious mistake.
Lock granularity also affects contention. Increasing the number of shared resources protected by a single lock, or the scope of the shared resource—for example, locking an entire table to access a single cell—increases the probability that multiple threads will try to access the resource at the same time.
There is a trade-off between increasing lock overhead and decreasing lock contention when choosing the number of locks. More locks are required for finer granularity (each protecting small amounts of data), increasing the overhead of the locks themselves. Extra locks also increase the risk of deadlock. Locks are generally quite fast, but, of course, a single execution thread will run slower with locking than without.
The ABA Problem
The ABA problem occurs during synchronization, when a location is read twice and has the same value for both reads. However, a second thread has executed between the two reads and modified the value, performed other work, then modified the value back, thereby fooling the first thread into thinking that the second thread is yet to execute.
The ABA problem is commonly encountered when implementing lock-free data structures. If an item is removed from the list and deleted, and then a new item is allocated and added to the list, the new object is often placed at the same location as the deleted object because of optimization. The pointer to the new item may consequently be equal to the pointer to the old item, which can cause an ABA problem. As previously mentioned in Section 7.5 under “Lock-free approaches,” implementing perfectly correct lock-free code is difficult in practice [Sutter 2008].
The C language example shown in Example 7.4 [Michael 1996] implements a queue data structure using lock-free programming. Its execution can exhibit the ABA problem. It is implemented using glib. The function CAS() uses g_atomic_pointer_compare_and_exchange().
Example 7.4. C Example ABA Problem
01 #include <glib.h>
02 #include <glib-object.h>
03
04 struct Node {
05 void *data;
06 Node *next;
07 };
08
09 struct Queue {
10 Node *head;
11 Node *tail;
12 };
13
14 Queue* queue_new(void) {
15 Queue *q = g_slice_new(sizeof(Queue));
16 q->head = q->tail = g_slice_new0(sizeof(Node));
17 return q;
18 }
19
20 void queue_enqueue(Queue *q, gpointer data) {
21 Node *node;
22 Node *tail;
23 Node *next;
24 node = g_slice_new(Node);
25 node->data = data;
26 node->next = NULL;
27 while (TRUE) {
28 tail = q->tail;
29 next = tail->next;
30 if (tail != q->tail) {
31 continue;
32 }
33 if (next != NULL) {
34 CAS(&q->tail, tail, next);
35 continue;
36 }
37 if (CAS(&tail->next, null, node)) {
38 break;
39 }
40 }
41 CAS(&q->tail, tail, node);
42 }
43
44 gpointer queue_dequeue(Queue *q) {
45 Node *node;
46 Node *tail;
47 Node *next;
48 while (TRUE) {
49 head = q->head;
50 tail = q->tail;
51 next = head->next;
52 if (head != q->head) {
53 continue;
54 }
55 if (next == NULL) {
56 return NULL; // Empty
57 }
58 if (head == tail) {
59 CAS(&q->tail, tail, next);
60 continue;
61 }
62 data = next->data;
63 if (CAS(&q->head, head, next)) {
64 break;
65 }
66 }
67 g_slice_free(Node, head);
68 return data;
69 }
Assume there are two threads (T1 and T2) operating simultaneously on the queue, and that the queue looks like this:
head → A → B → C → tail
The sequence of operations shown in Table 7.4 illustrates how the ABA problem can occur.
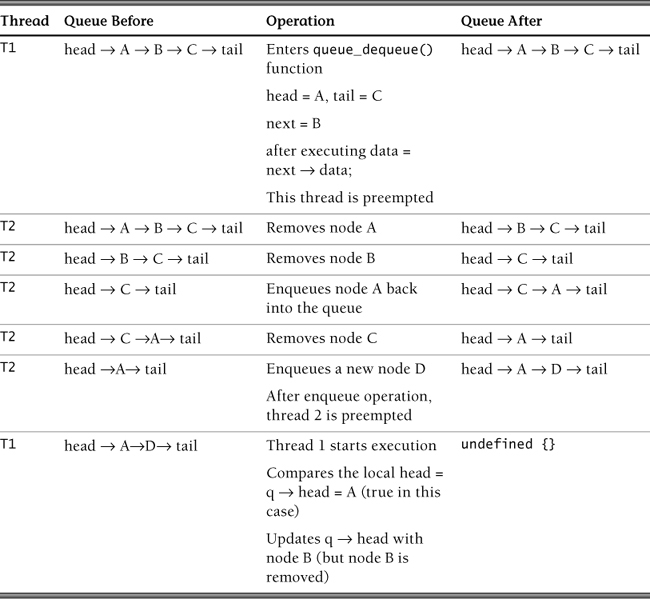
According to the sequence of events, head will now point to memory that was freed. Also, if reclaimed memory is returned to the operating system (for example, using munmap()), access to such a memory location can result in fatal access violation errors.
One solution to solving the ABA problem is through the use of hazard pointers. The core idea is to associate a number (typically one or two) of single-writer, multireader shared pointers, called hazard pointers.
A hazard pointer is stored in a separate data structure as a marker to indicate that the pointed-to object is in use by the current thread and should not be changed or deallocated by other threads. Threads that need to operate on a modified version of the object must first copy the object and then modify their copy.
A hazard pointer either has a null value or points to a node that may be accessed later by that thread without further validation that the reference to the node is still valid. Each hazard pointer may be written only by its owner thread but may be read by other threads.
In the solution shown in Example 7.5, the pointer being removed is stored in the hazard pointer, preventing other threads from reusing it and consequently avoiding the ABA problem.
Example 7.5. C Example Solution to the ABA Problem
01 void queue_enqueue(Queue *q, gpointer data) {
02 Node *node;
03 Node *tail;
04 Node *next;
05 node = g_slice_new(Node);
06 node->data = data;
07 node->next = NULL;
08 while (TRUE) {
09 tail = q->tail;
10 LF_HAZARD_SET(0, tail); // Mark tail as hazardous
11 if (tail != q->tail) { // Check tail hasn't changed
12 continue;
13 }
14 next = tail->next;
15 if (tail != q->tail) {
16 continue;
17 }
18 if (next != NULL) {
19 CAS(&q->tail, tail, next);
20 continue;
21 }
22 if (CAS(&tail->next, null, node) {
23 break;
24 }
25 }
26 CAS(&q->tail, tail, node);
27 }
28
29 gpointer queue_dequeue(Queue *q) {
30 Node *node;
31 Node *tail;
32 Node *next;
33 while (TRUE) {
34 head = q->head;
35 LF_HAZARD_SET(0, head); // Mark head as hazardous
36 if (head != q->head) { // Check head hasn't changed
37 continue;
38 }
39 tail = q->tail;
40 next = head->next;
41 LF_HAZARD_SET(1, next); // Mark next as hazardous
42 if (head != q->head) {
43 continue;
44 }
45 if (next == NULL) {
46 return NULL; // Empty
47 }
48 if (head == tail) {
49 CAS(&q->tail, tail, next);
50 continue;
51 }
52 data = next->data;
53 if (CAS(&q->head, head, next)) {
54 break;
55 }
56 }
57 LF_HAZARD_UNSET(head); // Retire head, and perform
58 // reclamation if needed.
59 return data;
60 }
Spinlocks
A spinlock is a type of lock implementation in which a thread repeatedly attempts to acquire a lock in a loop until it finally succeeds. Generally, spinlocks are efficient only when the waiting time to acquire a lock is short. In this case, spinlocks avoid the costly context switch time and the time it takes to be scheduled to run while waiting for the resource that occurs in traditional locks. When the waiting time to acquire a lock is significant, the spinlock can waste a significant amount of CPU time attempting to acquire a lock.
The following program fragment demonstrates an implementation of a spinlock. The resulting code is thread-safe but wastes CPU cycles while waiting for locks to be cleared.
01 volatile atomic_flag lock = ATOMIC_FLAG_INIT;
02
03 // ...
04
05 void *thread_function(void *ptr) {
06 size_t thread_num = (pthread_t*) ptr - threads; // get which
07 //index in thread array
08 while (!atomic_flag_test_and_set(&lock)) {} // spinlock
09 lock = 1;
10 shared_data = thread_num;
11 // do other stuff
12 printf("thread %u set shared value to %u
", (int) thread_num,
13 (int) shared_data);
14 atomic_flag_clear(&lock);
15 return NULL;
16 }
A common mitigation to prevent spinlocks from wasting CPU cycles is to have the thread sleep or yield control to other threads during the while loop.
7.7. Notable Vulnerabilities
Many notable vulnerabilities result from the incorrect use of concurrency. This section describes some classes of vulnerabilities as well as some specific examples.
DoS Attacks in Multicore Dynamic Random-Access Memory (DRAM) Systems
Today’s DRAM memory systems do not distinguish between memory access requests from different threads running on separate cores [Moscibroda 2007]. This lack of differentiation renders multicore systems vulnerable to an attack that exploits unfairness in the memory system. This unfairness allows a thread to get prioritized access to memory over requests from other threads by accessing memory with a particular memory access pattern. This prioritized access results in long memory access to the other threads. Moscibroda gives two major reasons why one thread can deny service to another in current DRAM memory systems:
1. Unfairness of row-hit-first scheduling: A thread whose accesses result in row hits (called a high row-buffer locality) gets higher priority compared to a thread whose accesses result in row conflicts. Consequently, an application that has a high row-buffer locality (for example, one that is streaming through memory) can significantly delay another application with low row-buffer locality if they happen to be accessing the same DRAM banks.
2. Unfairness of oldest-first scheduling: Oldest-first scheduling implicitly gives higher priority to those threads that can generate memory requests at a faster rate than others. Such aggressive threads can flood the memory system with requests at a faster rate than the memory system can service. As such, aggressive threads can fill the memory system’s buffers with their requests, while less-memory-intensive threads are blocked from the memory system until all the earlier-arriving requests from the aggressive threads are serviced [Moscibroda 2007].
Using these memory access techniques on a multicore system allows an attacker to deny or slow memory access to other threads. Over time it is anticipated that hardware issues such as these will be corrected to ensure fairness.
Concurrency Vulnerabilities in System Call Wrappers
System call interposition is a kernel extension technique used to increase operating system security policies (widely used by commercial antivirus software), but when it is combined with current operating systems, it becomes vulnerable and may lead to privilege escalation and audit bypass [Ergonul 2012].
The following system call wrappers are known to have concurrency vulnerabilities:
• The GSWKT (Generic Software Wrappers Toolkit) (CVE-2007-4302): Multiple race conditions in certain system call wrappers in GSWTK allow local users to defeat system call interposition and possibly gain privileges or bypass auditing.
• Systrace: Systrace is an access-control system for multiple operating platforms. The sysjail utility is a containment facility that uses the Systrace framework. The sudo utility is a privilege-management tool; a CVS-only prerelease version of sudo includes a monitor mode based on Systrace. Systrace is prone to multiple concurrency vulnerabilities because of its implementation of system call wrappers. Both sudo (monitor mode) and sysjail use this functionality.
• Cerb CerbNG (CVE-2007-4303): Multiple race conditions in (1) certain rules and (2) argument copying during VM protection in CerbNG for FreeBSD 4.8 allow local users to defeat system call interposition and possibly gain privileges or bypass auditing, as demonstrated by modifying command lines in log-exec.cb.
Three forms of concurrency vulnerabilities have been identified in the system call wrappers [Watson 2007]:
1. Synchronization bugs in wrapper logic leading to incorrect operation such as the improper locking of data
2. Data races resulting from a lack of synchronization between the wrapper and the kernel in copying system call arguments, such that arguments processed by the wrapper and the kernel differ
3. Data races resulting from a lack of synchronization between the wrapper and the kernel in interpreting system call arguments
In the paper “Exploiting Concurrency Vulnerabilities in System Call Wrappers,” Robert Watson observed that the most frequently identifiable and exploitable vulnerabilities fell into three categories [Watson 2007]:
1. Time-of-check-to-time-of-use (TOCTTOU; also referred to as time-of-check, time of use, or TOCTOU) vulnerabilities in which access control checks are nonatomic with the operations they protect, allowing an attacker to violate access control rules.
2. Time-of-audit-to-time-of-use (TOATTOU) vulnerabilities in which the trail diverges from actual accesses because of nonatomicity, violating accuracy requirements. This allows an attacker to mask activity, avoiding intrusion detection software (IDS) triggers.
3. Time-of-replacement-to-time-of-use (TORTTOU) vulnerabilities, unique to wrappers, in which attackers modify system call arguments after a wrapper has replaced them but before the kernel has accessed them, violating the security policy.
7.8. Summary
Concurrency has been around for several decades. For much of this time, common wisdom has held that concurrency is the next big thing, and that we will all soon be implementing concurrent programs. Concurrency has been adopted in application areas where the benefits of concurrency outweigh its costs. Two factors, however, have inhibited the broader adoption of concurrent programs. First, developing concurrent programs is difficult and error prone for the vast majority of programmers. Second, processor speeds have increased exponentially, providing performance improvements without the need for concurrency. Until 2005, CPU clock rates improved consistently, which by itself was sufficient to improve the performance of all applications executing on those CPUs.
There is increasing evidence that the era of steadily improving single-CPU performance is over. Since 2005, clock rates have remained static. Instead, processor makers have been increasing the number of execution units (cores) on each individual chip. Consequently, single-threaded applications performance has largely stalled as additional cores provide little to no advantage for such applications. The only way for an individual application to exploit the available CPU cores efficiently is through parallelism. This trend puts pressure on the application development and programming language development communities to support concurrency effectively. Consequently, the new 2011 versions of both the C and C++ standards integrate thread support into their respective languages. Compiler vendors have begun to implement and deliver these features. Initial releases of these compilers have been conservative in their support of parallelism to support existing code bases. However, the industry appears to be poised on the brink of a series of lurches and halts in performance improvements through concurrent execution and tool implementation changes during which code bases will need to be modernized to operate correctly and securely.
Unfortunately, developing concurrent systems remains difficult and error prone for the vast majority of programmers; we still lack a programming model that enables the widespread adoption of concurrency. With the possible exception of lambdas in C++, the approaches to multithreading adopted by the C and C++ standards are largely the same approaches that developers have struggled with for years without success. The application development and programming language development communities are well aware of this issue and have proposed many solutions such as Cilk, Intel Threading Building Blocks, OpenMP, QtConcurrent, and so forth. There is limited experience with these various approaches. To date, no cost-effective solution appears to solve the fundamental problem that programmers have difficulty reasoning about concurrency.
So what happens when the increased pressure to adopt concurrency encounters the inability of developers to program concurrently? Expressed lightly, hilarity ensues. Concurrency is likely to be the source of a large number of vulnerabilities in the years to come as we struggle to discover which approaches will succeed and which will be left by the wayside.