
Chapter 3. Pointer Subterfuge
1. Robert Murawski is a member of the technical staff in the CERT Program of Carnegie Mellon’s Software Engineering Institute (SEI).
Tush! tush! fear boys with bugs.
—William Shakespeare, The Taming of the Shrew, act 1, scene 2
Pointer subterfuge is a general term for exploits that modify a pointer’s value [Pincus 2004]. C and C++ differentiate between pointers to objects and pointers to functions. The type of a pointer to void or a pointer to an object type is called an object pointer type. The type of a pointer that can designate a function is called a function pointer type. A pointer to objects of type T is referred to as a “pointer to T.” C++ also defines a pointer to member type, which is the pointer type used to designate a nonstatic class member.
Function pointers can be overwritten to transfer control to attacker-supplied shellcode. When the program executes a call via the function pointer, the attacker’s code is executed instead of the intended code.
Object pointers can also be modified to run arbitrary code. If an object pointer is used as a target for a subsequent assignment, attackers can control the address to modify other memory locations.
This chapter examines function and object pointer modification in detail. It is different from other chapters in this book in that it discusses the mechanisms an attacker can use to run arbitrary code after initially exploiting a vulnerability (such as a buffer overflow). Preventing pointer subterfuge is difficult and best mitigated by eliminating the initial vulnerability. Before pointer subterfuge is examined in more detail, the relationship between how data is declared and where it is stored in memory is examined.
3.1. Data Locations
There are a number of exploits that can be used to overwrite function or object pointers, including buffer overflows.
Buffer overflows are most frequently caused by inadequately bounded loops. Most commonly, these loops are one of the following types:
Loop limited by upper bound: The loop performs N repetitions where N is less than or equal to the bound of p, and the pointer designates a sequence of objects, for example, p through p + N – 1.
Loop limited by lower bound: The loop performs N repetitions where N is less than or equal to the bound of p, and the pointer designates a sequence of objects, for example, p through p – N + 1.
Loop limited by the address of the last element of the array (aka Hi): The loop increments an indirectable pointer until it is equal to Hi.
Loop limited by the address of the first element of the array (aka Lo): The loop decrements an indirectable pointer until it is equal to Lo.
Loop limited by null terminator: The loop increments an indirectable pointer until its target is null.
For a buffer overflow of these loop types to be used to overwrite a function or object pointer, all of the following conditions must exist:
1. The buffer must be allocated in the same segment as the target function or object pointer.
2. For a loop limited by upper bound, a loop limited by Hi, or a loop limited by null terminator, the buffer must be at a lower memory address than the target function or object pointer. For a loop limited by lower bound or a loop limited by Lo, the buffer must be at a lower memory address than the target function or object pointer.
3. The buffer must not be adequately bounded and consequently susceptible to a buffer overflow exploit.
To determine whether a buffer is in the same segment as a target function or object pointer, it is necessary to understand how different variable types are allocated to the various memory segments.
UNIX executables contain both a data and a BSS2 segment. The data segment contains all initialized global variables and constants. The BSS segment contains all uninitialized global variables. Initialized global variables are separated from uninitialized variables so that the assembler does not need to write out the contents of the uninitialized variables (BSS segment) to the object file.
2. BSS stands for “block started by symbol” but is seldom spelled out.
Example 3.1 shows the relationship between how a variable is declared and where it is stored. Comments in the code describe where storage for each variable is allocated.
Example 3.1. Data Declarations and Process Memory Organization
01 static int GLOBAL_INIT = 1; /* data segment, global */
02 static int global_uninit; /* BSS segment, global */
03
04 int main(int argc, char **argv) { /* stack, local */
05 int local_init = 1; /* stack, local */
06 int local_uninit; /* stack, local */
07 static int local_static_init = 1; /* data seg, local */
08 static int local_static_uninit; /* BSS segment, local */
09 /* storage for buff_ptr is stack, local */
10 /* allocated memory is heap, local */
11 int *buff_ptr = (int *)malloc(32);
12 }
Although there are differences in memory organization between UNIX and Windows, the variables shown in the sample program in Example 3.1 are allocated in the same fashion under Windows as they are under UNIX.
3.2. Function Pointers
While stack smashing (as well as many heap-based attacks) is not possible in the data segment, overwriting function pointers is equally effective in any memory segment.
Example 3.2 contains a vulnerable program that can be exploited to overwrite a function pointer in the BSS segment. The static character array buff declared on line 3 and the static function pointer funcPtr declared on line 4 are both uninitialized and stored in the BSS segment. The call to strncpy() on line 6 is an example of an unsafe use of a bounded string copy function. A buffer overflow occurs when the length of argv[1] exceeds BUFFSIZE. This buffer overflow can be exploited to transfer control to arbitrary code by overwriting the value of the function pointer with the address of the shellcode. When the program invokes the function identified by funcPtr on line 7, the shellcode is invoked instead of good_function().
Example 3.2. Program Vulnerable to Buffer Overflow in the BSS Segment
1 void good_function(const char *str) {...}
2 int main(int argc, char *argv[]) {
3 static char buff[BUFFSIZE];
4 static void (*funcPtr)(const char *str);
5 funcPtr = &good_function;
6 strncpy(buff, argv[1], strlen(argv[1]));
7 (void)(*funcPtr)(argv[2]);
8 }
A naïve approach to eliminating buffer overflows is to redeclare stack buffers as global or local static variables to reduce the possibility of stack-smashing attacks. Redeclaring buffers as global variables is an inadequate solution because, as we have seen, exploitable buffer overflows can occur in the data segment as well.
3.3. Object Pointers
Object pointers are ubiquitous in C and C++. Kernighan and Ritchie [Kernighan 1988] observe the following:
Pointers are much used in C, partly because they usually lead to more compact and efficient code than can be obtained in other ways.
Object pointers are used in C and C++ to refer to dynamically allocated structures, call-by-reference function arguments, arrays, and other objects. These object pointers can be modified by an attacker, for example, when exploiting a buffer overflow vulnerability. If a pointer is subsequently used as a target for an assignment, an attacker can control the address to modify other memory locations, a technique known as an arbitrary memory write.
Example 3.3 contains a vulnerable program that can be exploited to create an arbitrary memory write. This program contains an unbounded memory copy on line 5. After overflowing the buffer, an attacker can overwrite ptr and val. When *ptr = val is consequently evaluated on line 6, an arbitrary memory write is performed. Object pointers can also be modified by attackers as a result of common errors in managing dynamic memory.
Example 3.3. Object Pointer Modification
1 void foo(void * arg, size_t len) {
2 char buff[100];
3 long val = ...;
4 long *ptr = ...;
5 memcpy(buff, arg, len);
6 *ptr = val;
7 ...
8 return;
9 }
Arbitrary memory writes are of particular concern on 32-bit Intel architecture (x86-32) platforms because sizeof(void *) equals sizeof(int) equals sizeof(long) equals 4 bytes. In other words, there are many opportunities on x86-32 to write 4 bytes to 4 bytes and overwrite an address at an arbitrary location.
3.4. Modifying the Instruction Pointer
For an attacker to succeed in executing arbitrary code on x86-32, an exploit must modify the value of the instruction pointer to reference the shellcode. The instruction pointer register (eip) contains the offset in the current code segment for the next instruction to be executed.
The eip register cannot be accessed directly by software. It is advanced from one instruction boundary to the next when executing code sequentially or modified indirectly by control transfer instructions (such as jmp, jcc, call, and ret), interrupts, and exceptions [Intel 2004].
The call instruction, for example, saves return information on the stack and transfers control to the called function specified by the destination (target) operand. The target operand specifies the address of the first instruction in the called function. This operand can be an immediate value, a general-purpose register, or a memory location.
Example 3.4 shows a program that uses the function pointer funcPtr to invoke a function. The function pointer is declared on line 6 as a pointer to a static function that accepts a constant string argument. The function pointer is assigned the address of good_function on line 7 so that when funcPtr is invoked on line 8 it is actually good_function that is called. For comparison, good_function() is statically invoked on line 9.
Example 3.4. Sample Program Using Function Pointers
01 void good_function(const char *str) {
02 printf("%s", str);
03 }
04
05 int main(void) {
06 static void (*funcPtr)(const char *str);
07 funcPtr = &good_function;
08 (void)(*funcPtr)("hi ");
09 good_function("there!
");
10 return 0;
11 }
Example 3.5 shows the disassembly of the two invocations of good_function() from Example 3.4. The call for the first invocation (using the function pointer) takes place at 0x0042417F. The machine code at this address is ff 15 00 84 47 00. There are several forms of call instruction in x86-32. In this case, the ff op code (shown in Figure 3.1) is used along with a ModR/M of 15, indicating an absolute, indirect call.

The last 4 bytes contain the address of the called function (there is one level of indirection). This address can also be found in the dword ptr [funcPtr (478400h)] call in Example 3.5. The actual address of good_function() stored at this address is 0x00422479.
Example 3.5. Function Pointer Disassembly
(void)(*funcPtr)("hi ");
00424178 mov esi, esp
0042417A push offset string "hi" (46802Ch)
0042417F call dword ptr [funcPtr (478400h)]
00424185 add esp, 4
00424188 cmp esi, esp
good_function("there!
");
0042418F push offset string "there!
" (468020h)
00424194 call good_function (422479h)
00424199 add esp, 4
The second, static call to good_function() takes place at 0x00424194. The machine code at this location is e8 e0 e2 ff ff. In this case, the e8 op code is used for the call instruction. This form of the call instruction indicates a near call with a displacement relative to the next instruction. The displacement is a negative number, which means that good_function() appears at a lower address.
These invocations of good_function() provide examples of call instructions that can and cannot be attacked. The static invocation uses an immediate value as relative displacement, and this displacement cannot be overwritten because it is in the code segment. The invocation through the function pointer uses an indirect reference, and the address in the referenced location (typically in the data or stack segment) can be overwritten. These indirect function references, as well as function calls that cannot be resolved at compile time, can be exploited to transfer control to arbitrary code. Specific targets for arbitrary memory writes that can transfer control to attacker-supplied code are described in the remainder of this chapter.
3.5. Global Offset Table
Windows and Linux use a similar mechanism for linking and transferring control to library functions. The main distinction, from a security perspective, is that the Linux solution is exploitable, while the Windows version is not.
The default binary format on Linux, Solaris 2.x, and SVR4 is called the executable and linking format (ELF). ELF was originally developed and published by UNIX System Laboratories (USL) as part of the application binary interface (ABI). More recently, the ELF standard was adopted by the Tool Interface Standards committee (TIS)3 as a portable object file format for a variety of x86-32 operating systems.
3. This committee is an association of microcomputer industry members formed to standardize software interfaces for IA-32 development tools.
The process space of any ELF binary includes a section called the global offset table (GOT). The GOT holds the absolute addresses, making them available without compromising the position independence of, and the ability to share, the program text. This table is essential for the dynamic linking process to work. The actual contents and form of this table depend on the processor [TIS 1995].
Every library function used by a program has an entry in the GOT that contains the address of the actual function. This allows libraries to be easily relocated within process memory. Before the program uses a function for the first time, the entry contains the address of the runtime linker (RTL). If the function is called by the program, control is passed to the RTL and the function’s real address is resolved and inserted into the GOT. Subsequent calls invoke the function directly through the GOT entry without involving the RTL.
The address of a GOT entry is fixed in the ELF executable. As a result, the GOT entry is at the same address for any executable process image. You can determine the location of the GOT entry for a function using the objdump command, as shown in Example 3.6. The offsets specified for each R_386_JUMP_SLOT relocation record contain the address of the specified function (or the RTL linking function).
Example 3.6. Global Offset Table
% objdump --dynamic-reloc test-prog
format: file format elf32-i386
DYNAMIC RELOCATION RECORDS
OFFSET TYPE VALUE
08049bc0 R_386_GLOB_DAT __gmon_start__
08049ba8 R_386_JUMP_SLOT __libc_start_main
08049bac R_386_JUMP_SLOT strcat
08049bb0 R_386_JUMP_SLOT printf
08049bb4 R_386_JUMP_SLOT exit
08049bb8 R_386_JUMP_SLOT sprintf
08049bbc R_386_JUMP_SLOT strcpy
An attacker can overwrite a GOT entry for a function with the address of shellcode using an arbitrary memory write. Control is transferred to the shellcode when the program subsequently invokes the function corresponding to the compromised GOT entry. For example, well-written C programs will eventually call the exit() function. Overwriting the GOT entry of the exit() function transfers control to the specified address when exit() is called. The ELF procedure linkage table (PLT) has similar shortcomings [Cesare 2000].
The Windows portable executable (PE) file format performs a similar function to the ELF format. A PE file contains an array of data structures for each imported DLL. Each of these structures gives the name of the imported DLL and points to an array of function pointers (the import address table or IAT). Each imported API has its own reserved spot in the IAT where the address of the imported function is written by the Windows loader. Once a module is loaded, the IAT contains the address that is invoked when calling imported functions. IAT entries can be (and are) write protected because they do not need to be modified at runtime.
3.6. The .dtors Section
Another target for arbitrary writes is to overwrite function pointers in the .dtors section for executables generated by GCC [Rivas 2001]. GNU C allows a programmer to declare attributes about functions by specifying the __attribute__ keyword followed by an attribute specification inside double parentheses [FSF 2004]. Attribute specifications include constructor and destructor. The constructor attribute specifies that the function is called before main(), and the destructor attribute specifies that the function is called after main() has completed or exit() has been called.
Example 3.7’s sample program shows the use of constructor and destructor attributes. This program consists of three functions: main(), create(), and destroy(). The create() function is declared on line 4 as a constructor, and the destroy() function is declared on line 5 as a destructor. Neither function is called from main(), which simply prints the address of each function and exits. Example 3.8 shows the output from executing the sample program. The create() constructor is executed first, followed by main() and the destroy() destructor.
Example 3.7. Program with Constructor and Destructor Attributes
01 #include <stdio.h>
02 #include <stdlib.h>
03
04 static void create(void) __attribute__ ((constructor));
05 static void destroy(void) __attribute__ ((destructor));
06
07 int main(void) {
08 printf("create: %p.
", create);
09 printf("destroy: %p.
", destroy);
10 exit(EXIT_SUCCESS);
11 }
12
13 void create(void) {
14 puts("create called.
");
15 }
16
17 void destroy(void) {
18 puts("destroy called.");
19 }
Example 3.8. Output of Sample Program
% ./dtors
create called.
create: 0x80483a0.
destroy: 0x80483b8.
destroy called.
Constructors and destructors are stored in the .ctors and .dtors sections in the generated ELF executable image. Both sections have the following layout:
0xffffffff {function-address} 0x00000000
The .ctors and .dtors sections are mapped into the process address space and are writable by default. Constructors have not been used in exploits because they are called before main(). As a result, the focus is on destructors and the .dtors section.
The contents of the .dtors section in the executable image can be examined with the objdump command as shown in Example 3.9. The head and tail tags can be seen, as well as the address of the destroy() function (in little endian format).
An attacker can transfer control to arbitrary code by overwriting the address of the function pointer in the .dtors section. If the target binary is readable by an attacker, it is relatively easy to determine the exact position to overwrite by analyzing the ELF image.
Example 3.9. Contents of the .dtors Section
1 % objdump -s -j .dtors dtors
2
3 dtors: file format elf32-i386
4
5 Contents of section .dtors:
6 804959c ffffffff b8830408 00000000
Interestingly, the .dtors section is present even if no destructor is specified. In this case, the section consists of the head and tail tag with no function addresses between. It is still possible to transfer control by overwriting the tail tag 0x00000000 with the address of the shellcode. If the shellcode returns, the process will call subsequent addresses until a tail tag is encountered or a fault occurs.
For an attacker, overwriting the .dtors section has the advantage that the section is always present and mapped into memory.4 Of course, the .dtors target exists only in programs that have been compiled and linked with GCC. In some cases, it may also be difficult to find a location in which to inject the shellcode so that it remains in memory after main() has exited.
4. The .dtors section is not removed by a strip(1) of the binary.
3.7. Virtual Pointers
C++ allows the definition of a virtual function. A virtual function is a function member of a class, declared using the virtual keyword. Functions may be overridden by a function of the same name in a derived class. A pointer to a derived class object may be assigned to a base class pointer and the function called through the pointer. Without virtual functions, the base class function is called because it is associated with the static type of the pointer. When using virtual functions, the derived class function is called because it is associated with the dynamic type of the object.
Example 3.10 illustrates the semantics of virtual functions. Class a is defined as the base class and contains a regular function f() and a virtual function g().
Example 3.10. The Semantics of Virtual Functions
01 class a {
02 public:
03 void f(void) {
04 cout << "base f" << '
';
05 };
06
07 virtual void g(void) {
08 cout << "base g" << '
';
09 };
10 };
11
12 class b: public a {
13 public:
14 void f(void) {
15 cout << "derived f" << '
';
16 };
17
18 void g(void) {
19 cout << "derived g" << '
';
20 };
21 };
22
23 int main(void) {
24 a *my_b = new b();
25 my_b->f();
26 my_b->g();
27 return 0;
28 }
Class b is derived from a and overrides both functions. A pointer my_b to the base class is declared in main() but assigned to an object of the derived class b. When the nonvirtual function my_b->f() is called on line 25, the function f() associated with a (the base class) is called. When the virtual function my_b->g() is called on line 26, the function g() associated with b (the derived class) is called.
Most C++ compilers implement virtual functions using a virtual function table (VTBL). The VTBL is an array of function pointers that is used at runtime for dispatching virtual function calls. Each individual object points to the VTBL via a virtual pointer (VPTR) in the object’s header. The VTBL contains pointers to each implementation of a virtual function. Figure 3.2 shows the data structures from the example.

It is possible to overwrite function pointers in the VTBL or to change the VPTR to point to another arbitrary VTBL. This can be accomplished by an arbitrary memory write or by a buffer overflow directly into an object. The buffer overwrites the VPTR and VTBL of the object and allows the attacker to cause function pointers to execute arbitrary code. VPTR smashing has not been seen extensively in the wild, but this technique could be employed if other techniques fail [Pincus 2004].
3.8. The atexit() and on_exit() Functions
The atexit() function is a general utility function defined in the C Standard. The atexit() function registers a function to be called without arguments at normal program termination. C requires that the implementation support the registration of at least 32 functions. The on_exit() function from SunOS performs a similar function. This function is also present in libc4, libc5, and glibc [Bouchareine 2005].
The program shown in Example 3.11 uses atexit() to register the test() function on line 8 of main(). The program assigns the string "Exiting.
" to the global variable glob (on line 9) before exiting. The test() function is invoked after the program exits and prints out this string.
Example 3.11. Program Using atexit()
01 char *glob;
02
03 void test(void) {
04 printf("%s", glob);
05 }
06
07 int main(void) {
08 atexit(test);
09 glob = "Exiting.
";
10 }
The atexit() function works by adding a specified function to an array of existing functions to be called on exit. When exit() is called, it invokes each function in the array in last-in, first-out (LIFO) order. Because both atexit() and exit() need to access this array, it is allocated as a global symbol (__atexit on BSD operating systems and __exit_funcs on Linux).
The gdb session of the atexit program shown in Example 3.12 shows the location and structure of the atexit array. In the debug session, a breakpoint is set before the call to atexit() in main() and the program is run. The call to atexit() is then executed to register the test() function. After the test() function is registered, memory at __exit_funcs is displayed. Each function is contained in a structure consisting of four doublewords. The last doubleword in each structure contains the actual address of the function. You can see that three functions have been registered by examining the memory at these addresses: _dl_fini(), __libc_csu_fini(), and our own test() function. It is possible to transfer control to arbitrary code with an arbitrary memory write or a buffer overflow directly into the __exit_funcs structure. Note that the _dl_fini() and __libc_csu_fini() functions are present even when the vulnerable program does not explicitly call the atexit() function.
Example 3.12. Debug Session of atexit Program Using gdb
(gdb) b main
Breakpoint 1 at 0x80483f6: file atexit.c, line 6.
(gdb) r
Starting program: /home/rcs/book/dtors/atexit
Breakpoint 1, main (argc=1, argv=0xbfffe744) at atexit.c:6
6 atexit(test);
(gdb) next
7 glob = "Exiting.
";
(gdb) x/12x __exit_funcs
0x42130ee0 <init>: 0x00000000 0x00000003 0x00000004 0x4000c660
0x42130ef0 <init+16>: 0x00000000 0x00000000 0x00000004 0x0804844c
0x42130f00 <init+32>: 0x00000000 0x00000000 0x00000004 0x080483c8
(gdb) x/4x 0x4000c660
0x4000c660 <_dl_fini>: 0x57e58955 0x5ce85356 0x81000054 0x0091c1c3
(gdb) x/3x 0x0804844c
0x804844c <__libc_csu_fini>: 0x53e58955 0x9510b850 x102d0804
(gdb) x/8x 0x080483c8
0x80483c8 <test>: 0x83e58955 0xec8308ec 0x2035ff08 0x68080496
3.9. The longjmp() Function
The C Standard defines the setjmp() macro, longjmp() function, and jmp_buf type, which can be used to bypass the normal function call and return discipline.
The setjmp() macro saves its calling environment for later use by the longjmp() function. The longjmp() function restores the environment saved by the most recent invocation of the setjmp() macro. Example 3.13 shows how the longjmp() function returns control back to the point of the setjmp() invocation.
Example 3.13. Sample Use of the longjmp() Function
01 #include <setjmp.h>
02 jmp_buf buf;
03 void g(int n);
04 void h(int n);
05 int n = 6;
06
07 void f(void) {
08 setjmp(buf);
09 g(n);
10 }
11
12 void g(int n) {
13 h(n);
14 }
15
16 void h(int n){
17 longjmp(buf, 2);
18 }
Example 3.14 shows the implementation of the jmp_buf data structure and related definitions on Linux. The jmp_buf structure (lines 11–15) contains three fields. The calling environment is stored in __jmpbuf (declared on line 1). The __jmp_buf type is an integer array containing six elements. The #define statements indicate which values are stored in each array element. For example, the base pointer (BP) is stored in __jmp_buf[3], and the program counter (PC) is stored in __jmp_buf[5].
Example 3.14. Linux Implementation of jmp_buf Structure
01 typedef int __jmp_buf[6];
02
03 #define JB_BX 0
04 #define JB_SI 1
05 #define JB_DI 2
06 #define JB_BP 3
07 #define JB_SP 4
08 #define JB_PC 5
09 define JB_SIZE 24
10
11 typedef struct __jmp_buf_tag {
12 __jmp_buf __jmpbuf;
13 int __mask_was_saved;
14 __sigset_t __saved_mask;
15 } jmp_buf[1];
Example 3.15 shows the assembly instructions generated for the longjmp() command on Linux. The movl instruction on line 2 restores the BP, and the movl instruction on line 3 restores the stack pointer (SP). Line 4 transfers control to the stored PC.
Example 3.15. Assembly Instructions Generated for longjmp() on Linux
longjmp(env, i)
1 movl i, %eax /* return i */
2 movl env.__jmpbuf[JB_BP], %ebp
3 movl env.__jmpbuf[JB_SP], %esp
4 jmp (env.__jmpbuf[JB_PC])
The longjmp() function can be exploited by overwriting the value of the PC in the jmp_buf buffer with the start of the shellcode. This can be accomplished with an arbitrary memory write or by a buffer overflow directly into a jmp_buf structure.
3.10. Exception Handling
An exception is any event that is outside the normal operations of a procedure. For example, dividing by zero will generate an exception. Many programmers implement exception handler blocks to handle these special cases and avoid unexpected program termination. Additionally, exception handlers are chained and called in a defined order until one can handle the exception.
Microsoft Windows supports the following three types of exception handlers. The operating system calls them in the order given until one is successful.
1. Vectored exception handling (VEH). These handlers are called first to override a structured exception handler. These exception handlers were added in Windows XP.
2. Structured exception handling (SEH). These handlers are implemented as per-function or per-thread exception handlers.
3. System default exception handling. This is a global exception filter and handler for the entire process that is called if no previous exception handler can handle the exception.
Structured and system default exception handling are discussed in the following sections. Vectored exception handling is ignored because it is not widely used in software exploits.
Structured Exception Handling
SEH is typically implemented at the compiler level through try...catch blocks as shown in Example 3.16.
Example 3.16. A try...catch Block
1 try {
2 // Do stuff here
3 }
4 catch(...){
5 // Handle exception here
6 }
7 __finally {
8 // Handle cleanup here
9 }
Any exception that is raised during the try block is handled in the matching catch block. If the catch block is unable to handle the exception, it is passed back to the prior scope block. The __finally keyword is a Microsoft extension to the C/C++ language and is used to denote a block of code that is called to clean up anything instantiated by the try block. The keyword is called regardless of how the try block exits.
For structured exception handling, Windows implements special support for per-thread exception handlers. Compiler-generated code writes the address of a pointer to an EXCEPTION_REGISTRATION structure to the address referenced by the fs segment register. This structure is defined in the assembly language struc definition in EXSUPP.INC in the Visual C++ runtime source and contains the two data elements shown in Example 3.17.
Example 3.17. EXCEPTION_REGISTRATION struc Definition
1 _EXCEPTION_REGISTRATION struc
2 prev dd ?
3 handler dd ?
4 _EXCEPTION_REGISTRATION ends
In this structure, prev is a pointer to the previous EXCEPTION_HANDLER structure in the chain, and handler is a pointer to the actual exception handler function.
Windows enforces several rules on the exception handler to ensure the integrity of the exception handler chain and the system:
1. The EXCEPTION_REGISTRATION structure must be located on the stack.
2. The prev EXCEPTION_REGISTRATION structure must be at a higher stack address.
3. The EXCEPTION_REGISTRATION structure must be aligned on a doubleword boundary.
4. If the executable image header lists SAFE SEH handler addresses,5 the handler address must be listed as a SAFE SEH handler. If the executable image header does not list SAFE SEH handler addresses, any structured exception handler may be called.
5. Microsoft Visual Studio .NET compilers support building code with SAFE SEH support, but this check is enforced only in Windows XP Service Pack 2.
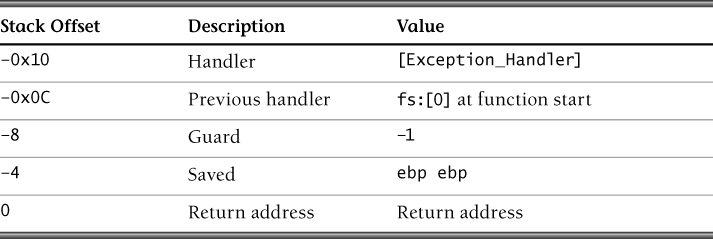
The compiler initializes the stack frame in the function prologue. A typical function prologue for Visual C++ is shown in Example 3.18. This code establishes the stack frame shown in Table 3.1. The compiler reserves space on the stack for local variables. Because the local variables are immediately followed by the exception handler address, the exception handler address could be overwritten by an arbitrary value resulting from a buffer overflow in a stack variable.
Example 3.18. Stack Frame Initialization
1 push ebp
2 mov ebp, esp
3 and esp, 0FFFFFFF8h
4 push 0FFFFFFFFh
5 push ptr [Exception_Handler]
6 mov eax, dword ptr fs:[00000000h]
7 push eax
8 mov dword ptr fs:[0], esp
In addition to overwriting individual function pointers, it is also possible to replace the pointer in the thread environment block (TEB) that references the list of registered exception handlers. The attacker needs to mock up a list entry as part of the payload and modify the first exception handler field using an arbitrary memory write. While recent versions of Windows have added validity checking for the list entries, Litchfield has demonstrated successful exploits in many of these cases [Litchfield 2003a].
System Default Exception Handling
Windows provides a global exception filter and handler for the entire process that is called if no previous exception handler can handle the exception. Many programmers implement an unhandled exception filter for the entire process to gracefully handle unexpected error conditions and for debugging.
An unhandled exception filter function is assigned using the SetUnhandledExceptionFilter() function. This function is called as the last level of exception handler for a process. However, if an attacker overwrites specific memory addresses through an arbitrary memory write, the unhandled exception filter can be redirected to run arbitrary code. However, Windows XP Service Pack 2 encodes pointer addresses, which makes this a nontrivial operation. In a real-world situation, it would be difficult for an attacker to correctly encode the pointer value without having detailed information about the process.
3.11. Mitigation Strategies
The best way to prevent pointer subterfuge is to eliminate the vulnerabilities that allow memory to be improperly overwritten. Pointer subterfuge can occur as a result of overwriting object pointers (as shown in this chapter), common errors in managing dynamic memory (Chapter 4), and format string vulnerabilities (Chapter 6). Eliminating these sources of vulnerabilities is the best way to eliminate pointer subterfuge. There are other mitigation strategies that can help but cannot be relied on to solve the problem.
Stack Canaries
In Chapter 2 we examined strategies for mitigating vulnerabilities resulting from flawed string manipulation and stack-smashing attacks, including stack canaries. Unfortunately, canaries are useful only against exploits that overflow a buffer on the stack and attempt to overwrite the stack pointer or other protected region. Canaries do not protect against exploits that modify variables, object pointers, or function pointers. Canaries do not prevent buffer overflows from occurring in any location, including the stack segment.
W^X
One way to limit the exposure from some of these targets is to reduce the privileges of the vulnerable processes. The W^X policy described in Chapter 2 allows a memory segment to be writable or executable, but not both. This policy cannot prevent overwriting targets such as those required by atexit() that need to be both writable at runtime and executable. Furthermore, this policy is not widely implemented.
Encoding and Decoding Function Pointers
Instead of storing a function pointer, the program can store an encrypted version of the pointer. An attacker would need to break the encryption to redirect the pointer to other code. Similar approaches are recommended for dealing with sensitive or personal data, such as encryption keys or credit card numbers.
Thomas Plum and Arjun Bijanki [Plum 2008] proposed adding encode_pointer() and decode_pointer() to the C11 standard at the WG14 meeting in Santa Clara in September 2008. These functions are similar in purpose, but slightly different in details, from two functions in Microsoft Windows (EncodePointer() and DecodePointer()), which are used by Visual C++’s C runtime libraries.
The proposed encode_pointer() function has the following specification:
Synopsis
#include <stdlib.h>
void (*)() encode_pointer(void(*pf)());
Description
The encode_pointer() function performs a transformation on the pf argument, such that the decode_pointer() function reverses that transformation.
The result of the transformation.
The proposed decode_pointer() function has the following specification:
Synopsis
#include <stdlib.h>
void (*)() decode_pointer(void(*epf)());
Description
The decode_pointer() function reverses the transformation performed by the encode_pointer() function.
Returns
The result of the inverse transformation.
These two functions are defined such that any pointer to function pfn used in the following expression:
decode_pointer(encode_pointer((void(*)())pfn));
then converted to the type of pfn equals pfn.
However, this inverse relationship between encode_pointer and decode_pointer() is not valid if the invocations of encode_pointer() and decode_pointer() take place under certain implementation-defined conditions. For example, if the invocations take place in different execution processes, then the inverse relationship is not valid. In that implementation, the transformation method could encode the process number in the encode/decode algorithm.
The process of pointer encoding does not prevent buffer overruns or arbitrary memory writes, but it does make such vulnerabilities more difficult to exploit. Furthermore, the proposal to the WG14 was rejected because it was felt that pointer encryption and decryption were better performed by the compiler than in the library. Consequently, pointer encryption and decryption were left as a “quality of implementation” concern.
CERT is not currently aware of any compilers that perform function pointer encryption and decryption, even as an option. Programmers developing code for Microsoft Windows should use EncodePointer() and DecodePointer() to encrypt function pointers. Microsoft uses these functions in its system code to prevent arbitrary memory writes, but to be effective, all pointers (including function pointers) must be protected in your application. For other platforms, the capability must first be developed.
3.12. Summary
Buffer overflows can be used to overwrite function or object pointers in the same fashion that a stack-smashing attack is used to overwrite a return address. The ability to overwrite a function or object pointer depends on the proximity of the buffer overflow to the target pointer, but targets of opportunity often exist in the same memory segment.
Clobbering a function pointer allows an attacker to directly transfer control to arbitrary, attacker-supplied code. The ability to modify an object pointer and assigned value creates an arbitrary memory write.
Regardless of the environment, there are many opportunities for transferring control to arbitrary code given an arbitrary memory write. Some of these targets are the result of C Standard features (for example, longjmp(), atexit()), and some are specific to particular compilers (for example, .dtors section) or operating systems (for example, on_exit()). In addition to the targets described in this chapter, there are numerous other targets (both known and unknown).
Arbitrary memory writes can easily defeat canary-based protection schemes. Write-protecting targets is difficult because of the number of targets and because there is a requirement to modify many of these targets (for example, function pointers) at runtime. One mitigation strategy is to store only encrypted versions of pointers.
Buffer overflows occurring in any memory segment can be exploited to execute arbitrary code, so moving variables from the stack to the data segment or heap is not a solution. The best approach to preventing pointer subterfuge resulting from buffer overflows is to eliminate possible buffer overflow conditions.
The next chapter examines heap-based vulnerabilities and exploits that allow an attacker to overwrite an address at an arbitrary location. These exploits result from buffer overflows in the heap, writing to freed memory, and double-free vulnerabilities.
3.13. Further Reading
Pointer subterfuge attacks were developed largely in response to the introduction of stack canary checking in StackGuard and other products. Rafal Wojtczuk discusses overwriting the GOT entry to defeat Solar Designer’s nonexecutable stack patch [Wojtczuk 1998]. Matt Conover’s 1999 paper on heap exploitation includes several examples of pointer subterfuge attacks [Conover 1999]. Bulba and Gerardo Richarte also describe pointer subterfuge exploits to defeat StackShield and StackGuard protection schemes [Bulba 2000, Richarte 2002]. David Litchfield discusses exception-handler hijacking [Litchfield 2003a, 2003b]. rix describes “Smashing C++ VPTRs” in Phrack 56 [rix 2000]. J. Pincus provides a good overview of pointer subterfuge attacks [Pincus 2004].