
Chapter 8. File I/O
1. David Riley is a professor of computer science at the University of Wisconsin–LaCrosse. David Svoboda is a member of the technical staff for the SEI’s CERT.
But, when I came,—some minute ere the time Of her awakening,—here untimely lay The noble Paris and true Romeo, dead.
—William Shakespeare, Romeo and Juliet, act V, scene 3
C and C++ programs commonly read and write to files as part of their normal operations. Numerous vulnerabilities have resulted from irregularities in how these programs interact with the file system—the operation of which is defined by the underlying operating system. Most commonly, these vulnerabilities result from file identification issues, poor privilege management, and race conditions. Each of these topics is discussed in this chapter.
8.1. File I/O Basics
Performing file I/O securely can be a daunting task, partly because there is so much variability in interfaces, operating systems, and file systems. For example, both the C and POSIX standards define separate interfaces for performing file I/O in addition to implementation-specific interfaces. Linux, Windows, and Mac OS X all have their peculiarities. Most of all, a wide variety of file systems are available for each operating system. Because of the heterogeneous systems that exist in enterprises, each operating system supports multiple file systems.
File Systems
Many UNIX and UNIX-like operating systems use the UNIX file system (UFS). Vendors of some proprietary UNIX systems, such as SunOS/Solaris, System V Release 4, HP-UX, and Tru64 UNIX, have adopted UFS. Most of them adapted UFS to their own uses, adding proprietary extensions that may not be recognized by other vendors’ versions of UNIX.
When it comes to file systems, Linux has been called the “Swiss Army knife” of operating systems [Jones 2007]. Linux supports a wide range of file systems, including older file systems such as MINIX, MS-DOS, and ext2. Linux also supports newer journaling file systems such as ext4, Journaled File System (JFS), and ReiserFS. Additionally, Linux supports the Cryptographic File System (CFS) and the virtual file system /proc.
Mac OS X provides out-of-the-box support for several different file systems, including Mac OS Hierarchical File System Extended Format (HFS+), the BSD standard file system format (UFS), the Network File System (NFS), ISO 9660 (used for CD-ROM), MS-DOS, SMB (Server Message Block [Windows file sharing standard]), AFP (AppleTalk Filing Protocol [Mac OS file sharing]), and UDF (Universal Disk Format).
Many of these file systems, such as NFS, AFS (Andrew File System), and the Open Group DFS (distributed file system), are distributed file systems that allow users to access shared files stored on heterogeneous computers as if they were stored locally on the user’s own hard drive.
Neither the C nor the C++ standard defines the concept of directories or hierarchical file systems. POSIX [ISO/IEC/IEEE 9945:2009] states:
Files in the system are organized in a hierarchical structure in which all of the non-terminal nodes are directories and all of the terminal nodes are any other type of file.
Hierarchical file systems are common, although flat file systems also exist. In a hierarchical file system, files are organized in a hierarchical treelike structure with a single root directory that is not contained by any other directory; all of the non-leaf nodes are directories, and all of the leaf nodes are other (nondirectory) file types. Because multiple directory entries may refer to the same file, the hierarchy is properly described as a directed acyclic graph (DAG).
A file consists of a collection of blocks (usually on a disk). In UFS, each file has an associated fixed-length record called an i-node, which maintains all attributes of the file and keeps addresses of a fixed number of blocks. A sample i-node is shown in Figure 8.1. The last address in the i-node is reserved for a pointer to another block of addresses.

Directories are special files that consist of a list of directory entries. A directory entry includes the names of the files in the directory and the number of the associated i-nodes.
Files have names. File naming conventions vary, but because of MS-DOS, the 8.3 file naming convention is widely supported. Frequently, a path name is used in place of a file name. A path name includes the name of a file or directory but also includes information on how to navigate the file system to locate the file. Absolute path names begin with a file separator character,2 meaning that the predecessor of the first file name in the path name is the root directory of the process. On MS-DOS and Windows systems, this separation character can also be preceded by a drive letter, for example, C:. If the path name does not begin with a file separator character, it is called a relative path name, and the predecessor of the first file name of the path name is the current working directory of the process. Multiple path names may resolve to the same file.
2. Typically a forward slash, “/”, on POSIX systems and a backward slash, “”, on Windows systems.
Figure 8.2 shows the components of a path name. The path name begins with a forward slash, indicating it is an absolute path name. Nonterminal names in the path refer to directories, and the terminal file name may refer to either a directory or a regular file.

Special Files
We mentioned in the introduction to this section that directories are special files. Special files include directories, symbolic links, named pipes, sockets, and device files.
Directories contain only a list of other files (the contents of a directory). They are marked with a d as the first letter of the permissions field when viewed with the ls –l command:
drwxr-xr-x /
Directories are so named as a result of Bell Labs’ involvement with the Multics project. Apparently, when the developers were trying to decide what to call something in which you could look up a file name to find information about the file, the analogy with a telephone directory came to mind.
Symbolic links are references to other files. Such a reference is stored as a textual representation of the file’s path. Symbolic links are indicated by an l in the permissions string:
lrwxrwxrwx termcap -> /usr/share/misc/termcap
Named pipes enable different processes to communicate and can exist anywhere in the file system. Named pipes are created with the command mkfifo, as in mkfifo mypipe. They are indicated by a p as the first letter of the permissions string:
prw-rw---- mypipe
Sockets allow communication between two processes running on the same machine. They are indicated by an s as the first letter of the permissions string:
srwxrwxrwx X0
Device files are used to apply access rights and to direct operations on the files to the appropriate device drivers. Character devices provide only a serial stream of input or output (indicated by a c as the first letter of the permissions string):
crw------- /dev/kbd
Block devices are randomly accessible (indicated by a b):
brw-rw---- /dev/hda
8.2. File I/O Interfaces
File I/O in C encompasses all the functions defined in <stdio.h>. The security of I/O operations depends on the specific compiler implementation, operating system, and file system. Older libraries are generally more susceptible to security flaws than are newer versions.
Byte or char type characters are used for character data from a limited character set. Byte input functions perform input into byte characters and byte strings: fgetc(), fgets(), getc(), getchar(), fscanf(), scanf(), vfscanf(), and vscanf().
Byte output functions perform output from byte characters and byte strings: fputc(), fputs(), putc(), putchar(), fprintf(), fprintf(), vfprintf(), and vprintf().
Byte input/output functions are the union of the ungetc() function, byte input functions, and byte output functions.
Wide or wchar_t type characters are used for natural-language character data.
Wide-character input functions perform input into wide characters and wide strings: fgetwc(), fgetws(), getwc(), getwchar(), fwscanf(), wscanf(), vfwscanf(), and vwscanf().
Wide-character output functions perform output from wide characters and wide strings: fputwc(), fputws(), putwc(), putwchar(), fwprintf(), wprintf(), vfwprintf(), and vwprintf().
Wide-character input/output functions are the union of the ungetwc() function, wide-character input functions, and wide-character output functions. Because the wide-character input/output functions are newer, some improvements were made over the design of the corresponding byte input/output functions.
Data Streams
Input and output are mapped into logical data streams whose properties are more uniform than the actual physical devices to which they are attached, such as terminals and files supported on structured storage devices.
A stream is associated with an external file by opening a file, which may involve creating a new file. Creating an existing file causes its former contents to be discarded. If the caller is not careful in restricting which files may be opened, this might result in an existing file being unintentionally overwritten, or worse, an attacker exploiting this vulnerability to destroy files on a vulnerable system.
Files that are accessed through the FILE mechanism provided by <stdio.h> are known as stream files.
At program start-up, three text streams are predefined and need not be opened explicitly:
• stdin: standard input (for reading conventional input)
• stdout: standard output (for writing conventional output)
• stderr: standard error (for writing diagnostic output)
The text streams stdin, stdout, and stderr are expressions of type pointer to FILE. When initially opened, the standard error stream is not fully buffered. The standard input and standard output streams are fully buffered if the stream is not an interactive device.
Opening and Closing Files
The fopen() function opens the file whose name is the string pointed to by the file name and associates a stream with it. The fopen() function has the following signature:
1 FILE *fopen(
2 const char * restrict filename,
3 const char * restrict mode
4 );
The argument mode points to a string. If the string is valid, the file is open in the indicated mode; otherwise, the behavior is undefined.
C99 supported the following modes:
• r: open text file for reading
• w: truncate to zero length or create text file for writing
• a: append; open or create text file for writing at end-of-file
• rb: open binary file for reading
• wb: truncate to zero length or create binary file for writing
• ab: append; open or create binary file for writing at end-of-file
• r+: open text file for update (reading and writing)
• w+: truncate to zero length or create text file for update
• a+: append; open or create text file for update, writing at end-of-file
• r+b or rb+: open binary file for update (reading and writing)
• w+b or wb+: truncate to zero length or create binary file for update
• a+b or ab+: append; open or create binary file for update, writing at end-of-file
CERT proposed, and WG14 accepted, the addition of an exclusive mode for C11. Opening a file with exclusive mode (x as the last character in the mode argument) fails if the file already exists or cannot be created. Otherwise, the file is created with exclusive (also known as nonshared) access to the extent that the underlying system supports exclusive access.
• wx: create exclusive text file for writing
• wbx: create exclusive binary file for writing
• w+x: create exclusive text file for update
• w+bx or wb+x: create exclusive binary file for update
The addition of this mode addresses an important security vulnerability dealing with race conditions that is described later in this chapter.
A file may be disassociated from a controlling stream by calling the fclose() function to close the file. Any unwritten buffered data for the stream is delivered to the host environment to be written to the file. Any unread buffered data is discarded.
The value of a pointer to a FILE object is indeterminate after the associated file is closed (including the standard text streams). Referencing an indeterminate value is undefined behavior.
Whether a file of zero length (on which no characters have been written by an output stream) actually exists is implementation defined.
A closed file may be subsequently reopened by the same or another program execution and its contents reclaimed or modified. If the main() function returns to its original caller, or if the exit() function is called, all open files are closed (and all output streams are flushed) before program termination. Other paths to program termination, such as calling the abort() function, need not close all files properly. Consequently, buffered data not yet written to a disk might be lost. Linux guarantees that this data is flushed, even on abnormal program termination.
POSIX
In addition to supporting the standard C file I/O functions, POSIX defines some of its own. These include functions to open and close files with the following signatures:
int open(const char *path, int oflag, ...);
int close(int fildes);
Instead of operating on FILE objects, the open() function creates an open file description that refers to a file and a file descriptor that refers to that open file description. The file descriptor is used by other I/O functions, such as close(), to refer to that file.
A file descriptor is a per-process, unique, nonnegative integer used to identify an open file for the purpose of file access. The value of a file descriptor is from 0 to OPEN_MAX. A process can have no more than OPEN_MAX file descriptors open simultaneously. A common exploit is to exhaust the number of available file descriptors to launch a denial-of-service (DoS) attack.
An open file description is a record of how a process or group of processes is accessing a file. A file descriptor is just an identifier or handle; it does not actually describe anything. An open file description includes the file offset, file status, and file access modes for the file. Figure 8.3 shows an example of two separate processes that are opening the same file or i-node. The information stored in the open file description is different for each process, whereas the information stored in the i-node is associated with the file and is the same for each process.
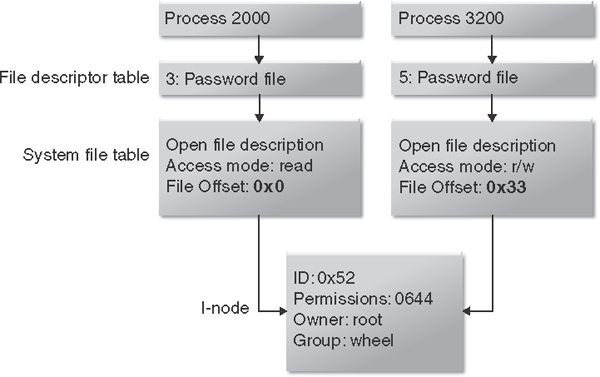
On POSIX systems, streams usually contain a file descriptor. You can call the POSIX fileno() to get the file descriptor associated with a stream. Inversely, you can call the fdopen() function to associate a stream with a file descriptor.
Table 8.1 summarizes the differences between the fopen() and open() functions.

File I/O in C++
C++ provides the same system calls and semantics as C, only the syntax is different. The C++ <iostream> library includes <cstdio>, which is the C++ version of <stdio.h>. Consequently, C++ supports all the C I/O function calls as well as <iostream> objects.
Instead of using FILE for file streams in C++, use ifstream for file-based input streams, ofstream for file-based output streams, and iofstream for file streams that handle both input and output. All of these classes inherit from fstream and operate on characters (bytes).
For wide-character I/O, using wchar_t, use wifstream, wofstream, wiofstream, and wfstream.
C++ provides the following streams to operate on characters (bytes):
• cin for standard input; replaces stdin
• cout for standard output; replaces stdout
• cerr for unbuffered standard error; replaces stderr
• clog for buffered standard error; useful for logging
For wide-character streams, use wcin, wcout, wcerr, and wclog.
Example 8.1 is a simple C++ program that reads character data from a file named test.txt and writes it to standard output.
Example 8.1. Reading and Writing Character Data in C++
01 #include <iostream>
02 #include <fstream>
03
04 using namespace std;
05
06 int main(void) {
07 ifstream infile;
08 infile.open("test.txt", ifstream::in);
09 char c;
10 while (infile >> c)
11 cout << c;
12 infile.close();
13 return 0;
14 }
8.3. Access Control
Most exploits involving the file system and file I/O involve attackers performing an operation on a file for which they lack adequate privileges. Different file systems have different access control models.
Both UFS and NFS use the UNIX file permissions model. This is by no means the only access control model. AFS and DFS, for example, use access control lists (ACLs). The purpose of this chapter is to describe an example of an access control model to establish a context for discussing file system vulnerabilities and exploits. Consequently, only the UNIX file permissions model is covered in this chapter.
The terms permission and privilege have similar but somewhat different meanings, particularly in the context of the UNIX file permissions model. A privilege is the delegation of authority over a computer system. Consequently, privileges reside with users or with a user proxy or surrogate such as a UNIX process. A permission is the privilege necessary to access a resource and is consequently associated with a resource such as a file.
Privilege models tend to be system specific and complex. They often present a “perfect storm,” as errors in managing privileges and permissions often lead directly to security vulnerabilities.
The UNIX design is based on the idea of large, multiuser, time-shared systems such as Multics.3 The basic goal of the access control model in UNIX is to keep users and programs from maliciously (or accidentally) modifying other users’ data or operating system data. This design is also useful for limiting the damage that can be done as a result of security compromise. However, users still need a way to accomplish security-sensitive tasks in a secure manner.
3. The relationship of UNIX to Multics is multifaceted, and especially ironic when it comes to security. UNIX rejected the extensive protection model of Multics.
Users of UNIX systems have a user name, which is identified with a user ID (UID). The information required to map a user name to a UID is maintained in /etc/passwd. The super UID (root) has a UID of 0 and can access any file. Every user belongs to a group and consequently has a group ID, or GID. Users can also belong to supplementary groups.
Users authenticate to a UNIX system by providing their user name and password. The login program examines the /etc/passwd or shadow file /etc/shadow to determine if the user name corresponds to a valid user on that system and if the password provided corresponds to the password associated with that UID.
UNIX File Permissions
Each file in a UNIX file system has an owner (UID) and a group (GID). Ownership determines which users and processes can access files. Only the owner of the file or root can change permissions. This privilege cannot be delegated or shared. The permissions are
Read: read a file or list a directory’s contents
Write: write to a file or directory
Execute: execute a file or recurse a directory tree
These permissions can be granted or revoked for each of the following classes of users:
User: the owner of the file
Group: users who are members of the file’s group
Others: users who are not the owner of the file or members of the group
File permissions are generally represented by a vector of octal values, as shown in Figure 8.4. In this case, the owner is granted read, write, and execute permissions; users who are members of the file’s group and other users are granted read and execute permissions.

The other way to view permissions is by using the ls –l command on UNIX:
drwx------ 2 usr1 cert 512 Aug 20 2003 risk management
lrwxrwxrwx 1 usr1 cert 15 Apr 7 09:11 risk_m->risk mngmnt
-rw-r--r-- 1 usr1 cert 1754 Mar 8 18:11 words05.ps
-r-sr-xr-x 1 root bin 9176 Apr 6 2012 /usr/bin/rs
-r-sr-sr-x 1 root sys 2196 Apr 6 2012 /usr/bin/passwd
The first character in the permissions string indicates the file type: regular -, directory d, symlink l, device b/c, socket s, or FIFO f/p. For example, the d in the permission string for risk management indicates that this file is a directory. The remaining characters in the permission string indicate the permissions assigned to user, group, and other. These can be r (read), w (write), x (execute), s (set.id), or t (sticky). The file words05.ps, for example, has read and write permissions assigned to the owner and read-only permissions assigned to the group and others.
When accessing a file, the process’s effective user ID (EUID) is compared against the file’s owner UID. If the user is not the owner, the GIDs are compared, and then others are tested.
The restricted deletion flag or sticky bit is represented by the symbolic constant S_ISVTX defined in the POSIX <sys/stat.h> header. If a directory is writable and the S_ISVTX mode bit is set on the directory, only the file owner, directory owner, and root can rename or remove a file in the directory. If the S_ISVTX mode bit is not set on the directory, a user with write permission on the directory can rename or remove files even if that user is not the owner. The sticky bit is normally set for shared directories, such as /tmp. If the S_ISVTX mode bit is set on a nondirectory file, the behavior is unspecified.
Originally, the sticky bit had meaning only for executable files. It meant that when the program was run, it should be locked in physical memory and not swapped out to disk. That is how it got the name “sticky.” Virtual memory systems eventually became smarter than human beings at determining which pages should reside in physical memory. Around the same time, security needs suggested the current use for the bit on directories.
Files also have a set-user-ID-on-execution bit, which is represented by the symbolic constant S_ISUID. This bit can be set on an executable process image file and indicates that the process runs with the privileges of the file’s owner (that is, the EUID and saved set-user-ID of the new process set to the file’s owner ID) and not the privileges of the user.
The set-group-ID-on-execution bit (S_ISGID) is similar. It is set on an executable process image file and indicates that the process runs with the privileges of the file’s group owner (that is, the effective group ID and saved set-group-ID of the new process set to the file’s GID) and not the privileges of the user’s group.
Process Privileges
The previous section introduced several different kinds of process user IDs without explaining them. The first of these is the real user ID (RUID). The RUID is the ID of the user who started the process, and it is the same as the user ID of the parent process unless it was changed. The effective user ID (EUID) is the actual ID used when permissions are checked by the kernel, and it consequently determines the permissions for the process. If the set-user-ID mode bit of the new process image file is set, the EUID of the new process image is set to the user ID of the new process image file. Finally, the saved set-user-ID (SSUID) is the ID of the owner of the process image file for set-user-ID-on-execution programs.
In addition to process user IDs, processes have process group IDs that mostly parallel the process user IDs. Processes have a real group ID (RGID) that is the primary group ID of the user who called the process. Processes also have an effective group ID (EGID), which is one of the GIDs used when permissions are checked by the kernel. The EGID is used in conjunction with the supplementary group IDs. The saved set-group-ID (SSGID) is the GID of the owner of the process image file for set-group-ID-on-execution programs. Each process maintains a list of groups, called the supplementary group IDs, in which the process has membership. This list is used with the EGID when the kernel checks group permission.
Processes instantiated by the C Standard system() call or by the POSIX fork() and exec() system calls inherit their RUID, RGID, EUID, EGID, and supplementary group IDs from the parent process.
In the example shown in Figure 8.5, file is owned by UID 25. A process running with an RUID of 25 executes the process image stored in the file program. The program file is owned by UID 18. However, when the program executes, it executes with the permissions of the parent process. Consequently, the program runs with an RUID and EUID of 25 and is able to access files owned by that UID.

In the example shown in Figure 8.6, a process running with RUID 25 can read and write a file owned by that user. The process executes the process image stored in the file program owned by UID 18, but the set-user-ID-on-execution bit is set on the file. This process now runs with an RUID of 25 but an EUID of 18. As a result, the program can access files owned by UID 18 but cannot access files owned by UID 25 without setting the EUID to the real UID.

The saved set-user-ID capability allows a program to regain the EUID established at the last exec() call. Otherwise, a program might have to run as root to perform the same functions. Similarly, the saved set-group-ID capability allows a program to regain the effective group ID established at the last exec() call.
To permanently drop privileges, set EUID to RUID before a call to exec() so that elevated privileges are not passed to the new program.
Changing Privileges
The principle of least privilege states that every program and every user of the system should operate using the least set of privileges necessary to complete the job [Saltzer 1974, 1975]. This is a wise strategy for mitigating vulnerabilities that has withstood the test of time. If the process that contains a vulnerability is not more privileged than the attacker, then there is little to be gained by exploiting the vulnerability.
If your process is running with elevated privileges and accessing files in shared directories or user directories, there is a chance that your program might be exploited to perform an operation on a file for which the user of your program does not have the appropriate privileges. Dropping elevated privileges temporarily or permanently allows a program to access files with the same restrictions as an unprivileged user. Elevated privileges can be temporarily rescinded by setting the EUID to the RUID, which uses the underlying privilege model of the operating system to prevent users from performing any operation they do not already have permission to perform. However, this approach can still result in insecure programs with a file system that relies on a different access control mechanism, such as AFS.
A privilege escalation vulnerability occurred in the version of OpenSSH distributed with FreeBSD 4.4 (and earlier). This version of OpenSSH runs with root privileges but does not always drop privileges before opening files:
1 fname = login_getcapstr(lc,"copyright",NULL,NULL);
2 if (fname != NULL && (f=fopen(fname,"r")) != NULL) {
3 while (fgets(buf, sizeof(buf), f) != NULL)
4 fputs(buf, stdout);
5 fclose(f);
6 }
This vulnerability allows an attacker to read any file in the file system by specifying, for example, the following configuration option in the user’s ~/.login_conf file:
copyright=/etc/shadow
To eliminate vulnerabilities of this kind, processes with elevated privileges may need to assume the privileges of a normal user, either permanently or temporarily. Temporarily dropping privileges is useful when accessing files with the same restrictions as an unprivileged user, but it is not so useful for limiting the effects of vulnerabilities (such as buffer overflows) that allow the execution of arbitrary code, because elevated privileges can be restored.
Processes without elevated privileges may need to toggle between the real user ID and the saved set-user-ID.
Although dropping privileges is an effective mitigation strategy, it does not entirely eliminate the risk of running with elevated privileges to begin with. Privilege management functions are complex and have subtle portability differences. Failure to understand their behavior can lead to privilege escalation vulnerabilities.
Privilege Management Functions
In general, a process is allowed to change its EUID to its RUID (the user who started the program) and the saved set-user-ID, which allows a process to toggle effective privileges. Processes with root privileges can, of course, do anything.
The C Standard does not define an API for privilege management. The POSIX seteuid(), setuid(), and setreuid() functions and the nonstandard setresuid() function can all be used to manipulate the process UIDs. These functions have different semantics on different versions of UNIX that can lead to security problems in portable applications. However, they are needed for utilities like login and su that must permanently change the UID to a new value, generally that of an unprivileged user.
The seteuid() function changes the EUID associated with a process and has the following signature:
int seteuid(uid_t euid);
Unprivileged user processes can only set the EUID to the RUID or the SSUID. Processes running with root privileges can set the EUID to any value. The setegid() function behaves the same for groups.
Suppose that a user named admin has a UID of 1000 and runs a file owned by the bin user (UID = 1) with the set-user-ID-on-execution bit set on the file. Say, for example, a program initially has the following UIDs:
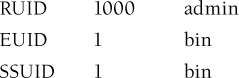
To temporarily relinquish privileges, it can call seteuid(1000):

To regain privileges, it can call seteuid(1):
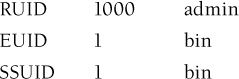
The setuid() function changes the EUID associated with a process:
int setuid(uid_t uid);
The setuid() function is primarily used for permanently assuming the role of a user, usually for the purpose of dropping privileges. It is needed for applications that are installed with the set-user-ID-on-execution bit and need to perform operations using the RUID. For example, lpr needs an elevated EUID to perform privileged operations, but jobs should be printed with the user’s actual RUID.
When the caller has appropriate privileges, setuid() sets the calling process’s RUID, EUID, and saved set-user-ID. When the caller does not have appropriate privileges, setuid() only sets the EUID.
So what exactly does “appropriate privileges” mean? On Solaris, it means that the EUID is 0 (that is, the process is running as root). On Linux, it means that the process has CAP_SETUID capability, and the EUID must be a member of the set { 0,RUID,SSUID }. On BSD, all users always have “appropriate privileges.”
Figure 8.7 shows a finite-state automaton (FSA) describing a setuid() implementation for Linux.

The behavior of setuid() varies, reflecting the behavior of different historical implementations. Consequently, Solaris 8 and FreeBSD 4.4 have different but equally complex graphs for setuid(). In contrast, the seteuid() graphs are quite simple. For these reasons, you should use seteuid() instead of setuid() whenever possible.
The setresuid() function is used to explicitly set the RUID, EUID, and SSUID:
1 int setresuid(
2 uid_t ruid, uid_t euid, uid_t siud
3 );
The setresuid() function sets all three UIDs and returns 0 if successful or –1 if an error occurs. If any of the ruid, euid, or siud arguments is –1, the corresponding RUID, EUID, or SSUID of the current process is unchanged. Superusers can set the IDs to any values they like. Unprivileged users can set any of the IDs to the value of any of the three current IDs.
The setreuid() function sets the RUID and EUID of the current process to the values specified by the ruid and euid arguments:
int setreuid(uid_t ruid, uid_t euid);
If either the ruid or euid argument is –1, the corresponding effective or real user ID of the current process is unchanged. A process with “appropriate privileges” can set either ID to any value. An unprivileged process can set the EUID only if the euid argument is equal to the RUID, EUID, or SSUID of the process. It is unspecified whether a process without appropriate privileges is permitted to change the RUID to match the current real, effective, or saved set-user-ID of the process.
If possible, you should prefer using either the setresuid() or seteuid() functions. The setresuid() function has the clearest semantics of all the POSIX privilege management functions and is implemented the same way on all systems that support it (Linux, FreeBSD, HP-UX, and OpenBSD 3.3 and later). Unfortunately, it is not supported on Solaris. It also has the cleanest semantics in that it explicitly sets all three UIDs to values specified; never sets one or two, always sets none or all three; and always works if either EUID = 0 or each UID matches any of the three previous UID values.
The seteuid() function sets just the EUID. It is available on more platforms than setresuid(), including Linux, BSD, and Solaris. Its semantics are almost as clean as those of setresuid(): it sets EUID and never affects RUID or SUID, and it always works if EUID = 0. However, if the EUID is not 0, it works on Linux and Solaris only if the new EUID matches any of the three old UIDs, and it works on BSD only if the new EUID matches the old RUID or SSUID.
Managing Privileges
This is a good place to stop and review for a moment before proceeding and also to clarify some terminology, as it can be confusing to understand what it means when someone says a program is a “setuid program” or a “setgid program.” Setuid programs are programs that have their set-user-ID-on-execution bit set. Similarly, setgid programs are programs that have their set-group-ID-on-execution bit set. Not all programs that call setuid() or setgid() are setuid or setgid programs. Setuid programs can run as root (set-user-ID-root) or with more restricted privileges.
Nonroot setuid and setgid programs are typically used to perform limited or specific tasks. These programs are limited to changing EUID to RUID and SSUID. When possible, systems should be designed using this approach instead of creating set-user-ID-root programs.
A good example of a setgid program is the wall program, used to broadcast a message to all users on a system by writing a message to each user’s terminal device. A regular (nonroot) user cannot write directly to another user’s terminal device, as it would allow users to spy on each other or to interfere with one another’s terminal sessions. The wall program can be used to perform this function in a controlled, safe fashion.
The wall program is installed as setgid tty and runs as a member of the tty group:
-r-xr-sr-x 1 root tty [...] /usr/bin/wall
The terminal devices that the wall program operates on are set as group writable:
crw--w---- 1 usr1 tty 5, 5 [...] /dev/ttyp5
This design allows the wall program to write to these devices on behalf of an unprivileged user but prevents the unprivileged user from performing other unprivileged operations that might allow an attacker to compromise the system.
Set-user-ID-root programs are used for more complex privileged tasks. The passwd program is run by a user to change that user’s password. It needs to open a privileged file and make a controlled change without allowing the user to alter other users’ passwords stored in the same file. Consequently, the passwd program is defined as a set-user-ID-root program:
$ ls -l /usr/bin/passwd
-r-sr-xr-x 1 root bin [...] /usr/bin/passwd
The ping program is a computer network administration utility used to test the reachability of a host on an Internet Protocol (IP) network and to measure the round-trip time for messages sent from the originating host to a destination computer. The ping program is also a set-user-ID-root program:
$ ls -l /sbin/ping
-r-sr-xr-x 1 root bin [...] /sbin/ping
This is necessary because the implementation of the ping program requires the use of raw sockets. Fortunately, this program does the “right thing” and drops elevated privileges when it no longer needs them, as shown in Example 8.2.
Example 8.2. ping Program Fragment
01 setlocale(LC_ALL, "");
02
03 icmp_sock = socket(AF_INET, SOCK_RAW, IPPROTO_ICMP);
04 socket_errno = errno;
05
06 uid = getuid();
07 if (setuid(uid)) {
08 perror("ping: setuid");
09 exit(-1);
10 }
Setuid programs carry significant risk because they can do anything that the owner of the file is allowed to do, and anything is possible if the owner is root. When writing a setuid program, you must be sure not to take action for an untrusted user or return privileged information to an untrusted user. You also want to make sure that you follow the principle of least privilege and change the EUID to the RUID when root privileges are no longer needed.
What makes setuid programs particularly dangerous is that they are run by the user and operate in environments where the user (for example, an attacker) controls file descriptors, arguments, environment variables, current working directory, resource limits, timers, and signals. The list of controlled items varies among UNIX versions, so it is difficult to write portable code that cleans up everything. Consequently, setuid programs have been responsible for a number of locally exploitable vulnerabilities.
The program fragment from the sample ping implementation in Example 8.2 creates a raw socket and then permanently drops privileges. The principle of least privilege suggests performing privileged operations early and then permanently dropping privileges as soon as possible. The setuid(getuid()) idiom used in this example serves the purpose of permanently dropping privileges by setting the calling process’s RUID, EUID, and saved set-user-ID to the RUID—effectively preventing the process from ever regaining elevated privileges.
However, other situations require that a program temporarily drop privileges and later restore them. Take, for example, a mail transfer agent (MTA) that accepts messages from one (untrusted, possibly remote) user and delivers them to another user’s mailbox (a file owned by the user). The program needs to be a long-running service that accepts files submitted by local users and, for access control and accounting, knows which UID (and GID) submitted each file. Because the MTA must write into the mailboxes owned by different users, it needs to run with root privileges. However, working in shared or user directories when running with elevated privileges is very dangerous, because the program can easily be tricked into performing an operation on a privileged file. To write into the mailboxes owned by different users securely, the MTA temporarily assumes the normal user’s identity before performing these operations. This also allows MTAs to minimize the amount of time they are running as root but still be able to regain root privileges later.
The privilege management solution in this case is that the MTA executable is owned by root, and the set-user-ID-on-execution bit is set on the executable process image file. This solution allows the MTA to run with higher privileges than those of the invoking user. Consequently, set-user-ID-root programs are frequently used for passwords, mail messages, printer data, cron scripts, and other programs that need to be invoked by a user but perform privileged operations.
To drop privileges temporarily in a set-user-ID-root program, you can remove the privileged UID from EUID and store it in SSUID, from where it can be later restored, as shown in Example 8.3.
Example 8.3. Temporarily Dropping Privileges
1 /* perform a restricted operation */
2 setup_secret();
3 uid_t uid = /* unprivileged user */
4 /* Drop privileges temporarily to uid */
5 if (setresuid( -1, uid, geteuid()) < 0) {
6 /* handle error */
7 }
8 /* continue with general processing */
9 some_other_loop();
To restore privileges, you can set the EUID to the SSUID, as shown in Example 8.4.
Example 8.4. Restoring Privileges
01 /* perform unprivileged operation */
02 some_other_loop();
03 /* Restore dropped privileges.
04 Assumes SSUID is elevated */
05 uid_t ruid, euid, suid;
06 if (getresuid(&ruid, &euid, &suid) < 0) {
07 /* handle error */
08 }
09 if (setresuid(-1, suid, -1) < 0) {
10 /* handle error */
11 }
12 /* continue with privileged processing */
13 setup_secret();
To drop privileges permanently, you can remove the privileged UID from both EUID and SSUID, after which it will be impossible to restore elevated privileges, as shown in Example 8.5.
Example 8.5. Permanently Dropping Privileges
01 /* perform a restricted operation */
02 setup_secret();
03 /*
04 * Drop privileges permanently.
05 * Assumes RUID is unprivileged
06 */
07 if (setresuid(getuid(), getuid(), getuid()) < 0) {
08 /* handle error */
09 }
10 /* continue with general processing */
11 some_other_loop();
The setgid(), setegid(), and setresgid() functions have similar semantics to setuid(), seteuid(), and setresuid() functions but work on group IDs. Some programs have both the set-user-ID-on-execution and set-group-ID-on-execution bits set, but more frequently programs have just the set-group-ID-on-execution bit set.
If a program has both the set-user-ID-on-execution and set-group-ID-on-execution bits set, the elevated group privileges must also be relinquished, as shown in Example 8.6.
Example 8.6. Relinquishing Elevated Group Privileges
01 /* perform a restricted operation */
02 setup_secret();
03
04 uid_t uid = /* unprivileged user */
05 gid_t gid = /* unprivileged group */
06 /* Drop privileges temporarily to uid & gid */
07 if (setresgid( -1, gid, getegid()) < 0) {
08 /* handle error */
09 }
10 if (setresuid( -1, uid, geteuid()) < 0) {
11 /* handle error */
12 }
13
14 /* continue with general processing */
15 some_other_loop();
It is important that privileges be dropped in the correct order. Example 8.7 drops privileges in the wrong order.
Example 8.7. Dropping Privileges in the Wrong Order
1 if (setresuid(-1, uid, geteuid()) < 0) {
2 /* handle error */
3 }
4 if (setresgid(-1, gid, getegid()) < 0) {
5 /* will fail because EUID no longer 0! */
6 }
Because root privileges are dropped first, the process may not have adequate privileges to drop group privileges. An EGID of 0 does not imply root privileges, and consequently, the result of the setresgid() expression is OS dependent. For more information, see The CERT C Secure Coding Standard [Seacord 2008], “POS36-C. Observe correct revocation order while relinquishing privileges.”
You must also be sure to drop supplementary group privileges as well. The setgroups() function sets the supplementary group IDs for the process. Only the superuser may use this function. The following call clears all supplement groups:
setgroups(0, NULL);
Inadequate privilege management in privileged programs can be exploited to allow an attacker to manipulate a file in a manner for which the attacker lacks permissions. Potential consequences include reading a privileged file (information disclosure), truncating a file, clobbering a file (that is, size always 0), appending to a file, or changing file permissions. Basically, the attacker can exploit any operation executing as part of a privileged process if that program fails to appropriately drop privileges before performing that operation. Many of these vulnerabilities can lead, in one way or another, to the attacker acquiring full control of the machine.
Each of the privilege management functions discussed in this section returns 0 if successful. Otherwise, –1 is returned and errno set to indicate the error. It is critical to test the return values from these functions and take appropriate action when they fail. When porting setuid programs, you can also use getuid(), geteuid(), and related functions to verify that your UID values have been set correctly. For more information, see The CERT C Secure Coding Standard [Seacord 2008], “POS37-C. Ensure that privilege relinquishment is successful.”
Poor privilege management has resulted in numerous vulnerabilities. The existing APIs are complex and nonintuitive, and they vary among implementations. Extreme care must be taken when managing privileges, as almost any mistake in this code will result in a vulnerability.
Managing Permissions
Managing process privileges is half the equation. The other half is managing file permissions. This is partly the responsibility of the administrator and partly the responsibility of the programmer.
Sendmail is an e-mail routing system with a long history of vulnerability:
• Alert (TA06-081A), “Sendmail Race Condition Vulnerability,” March 22, 2006
• CERT Advisory CA-2003-25, “Buffer Overflow in Sendmail,” September 18, 2003
• CERT Advisory CA-2003-12, “Buffer Overflow in Sendmail,” March 29, 2003
• CERT Advisory CA-2003-07, “Remote Buffer Overflow in Sendmail,” March 3, 2003
• CERT Advisory CA-1997-05, “MIME Conversion Buffer Overflow in Sendmail Versions 8.8.3 and 8.8.4,” January 28, 1997
• CERT Advisory CA-1996-25, “Sendmail Group Permissions Vulnerability,” December 10, 1996
• CERT Advisory CA-1996-24, “Sendmail Daemon Mode Vulnerability,” November 21, 1996
• CERT Advisory CA-1996-20, “Sendmail Vulnerabilities,” September 18, 1996
Because of this history, Sendmail is now quite particular about the modes of files it reads or writes. For example, it refuses to read files that are group writable or in group-writable directories on the grounds that they might have been tampered with by someone other than the owner.
Secure Directories
When a directory is writable by a particular user, that user is able to rename directories and files that reside within that directory. For example, suppose you want to store sensitive data in a file that will be placed into the directory /home/myhome/stuff/securestuff. If the directory /home/myhome/stuff is writable by another user, that user could rename the directory securestuff. The result would be that your program would no longer be able to find the file containing its sensitive data.
In most cases, a secure directory is a directory in which no one other than the user, or possibly the administrator, has the ability to create, rename, delete, or otherwise manipulate files. Other users may read or search the directory but generally may not modify the directory’s contents in any way. For example, other users must not be able to delete or rename files they do not own in the parent of the secure directory and all higher directories. Creating new files and deleting or renaming files they own are permissible. Performing file operations in a secure directory eliminates the possibility that an attacker might tamper with the files or file system to exploit a file system vulnerability in a program.
These vulnerabilities often exist because there is a loose binding between the file name and the actual file (see The CERT C Secure Coding Standard [Seacord 2008], “FIO01-C. Be careful using functions that use file names for identification”). In some cases, file operations can—and should—be performed securely. In other cases, the only way to ensure secure file operations is to perform the operation within a secure directory.
To create a secure directory, ensure that the directory and all directories above it are owned by either the user or the superuser, are not writable by other users, and may not be deleted or renamed by any other users. The CERT C Secure Coding Standard [Seacord 2008], “FIO15-C. Ensure that file operations are performed in a secure directory,” provides more information about operating in a secure directory.
Permissions on Newly Created Files
When a file is created, permissions should be restricted exclusively to the owner. The C Standard has no concept of permissions, outside of Annex K where they “snuck in.” Neither the C Standard nor the POSIX Standard defines the default permissions on a file opened by fopen().
On POSIX, the operating system stores a value known as the umask for each process it uses when creating new files on behalf of the process. The umask is used to disable permission bits that may be specified by the system call used to create files. The umask applies only on file or directory creation—it turns off permission bits in the mode argument supplied during calls to the following functions: open(), openat(), creat(), mkdir(), mkdirat(), mkfifo(), mkfifoat(), mknod(), mknodat(), mq_open(), and sem_open(). The chmod() and fchmod() functions are not affected by umask settings.
The operating system determines the access permissions by computing the intersection of the inverse of the umask and the permissions requested by the process. In Figure 8.8, a file is being opened with mode 777, which is wide-open permissions. The umask of 022 is inversed and then ANDed with the mode. The result is that the permission bits specified by the umask in the original mode are turned off, resulting in file permissions of 755 in this case and disallowing “group” or “other” from writing the file.

A process inherits the value of its umask from its parent process when the process is created. Normally, when a user logs in, the shell sets a default umask of
• 022 (disable group- and world-writable bits), or
• 02 (disable world-writable bits)
Users may change the umask. Of course, the umask value as set by the user should never be trusted to be appropriate.
The C Standard fopen() function does not allow specification of the permissions to use for the new file, and, as already mentioned, neither the C Standard nor the POSIX Standard defines the default permissions on the file. Most implementations default to 0666.
The only way to modify this behavior is either to set the umask before calling fopen() or to call fchmod() after the file is created. Using fchmod() to change the permissions of a file after it is created is not a good idea because it introduces a race condition. For example, an attacker can access the file after it has been created but before the permissions are modified. The proper solution is to modify the umask before creating the file:
1 mode_t old_umask = umask(~S_IRUSR);
2 FILE *fout = fopen("fred", "w");
3 /* . . . */
4 fclose(fout);
Neither the C Standard nor the POSIX Standard specifies the interaction between these two functions. Consequently, this behavior is implementation defined, and you will need to verify this behavior on your implementation.
Annex K of the C Standard, “Bounds-checking interfaces,” also defines the fopen_s() function. The standard requires that, when creating files for writing, fopen_s() use a file permission that prevents other users from accessing the file, to the extent that the operating system supports it. The u mode can be used to create a file with the system default file access permissions. These are the same permissions that the file would have had it been created by fopen().
For example, if the file fred does not yet exist, the following statement:
if (err = fopen_s(&fd, "fred", "w") != 0)
creates the file fred, which is accessible only by the current user.
The POSIX open() function provides an optional third argument that specifies the permissions to use when creating a file.
For example, if the file fred does not yet exist, the following statement:
fd = open("fred", O_RDWR|O_CREAT|O_EXCL, S_IRUSR);
creates the file fred for writing with user read permission. The open() function returns a file descriptor for the named file that is the lowest file descriptor not currently open for that process.
Other functions, such as the POSIX mkstemp() function, can also create new files. Prior to POSIX 2008, mkstemp() required calling umask() to restrict creation permissions. As of POSIX 2008, the mkstemp() function creates the file as if by the following call to open():
1 open(
2 filename,
3 O_RDWR|O_CREAT|O_EXCL,
4 S_IRUSR|S_IWUSR
5 )
The POSIX 2008 version of the mkstemp() function is also further restricted by the umask() function.
For more information, see The CERT C Secure Coding Standard [Seacord 2008], “FIO03-C. Do not make assumptions about fopen() and file creation.”
8.4. File Identification
Many file-related security vulnerabilities result from a program accessing an unintended file object because file names are only loosely bound to underlying file objects. File names provide no information regarding the nature of the file object itself. Furthermore, the binding of a file name to a file object is reasserted every time the file name is used in an operation. File descriptors and FILE pointers are bound to underlying file objects by the operating system. The CERT C Secure Coding Standard [Seacord 2008], “FIO01-C. Be careful using functions that use file names for identification,” describes this problem further.
Section 8.1, “File I/O Basics,” described the use of absolute and relative path names and also pointed out that multiple path names may resolve to the same file. Path name resolution is performed to resolve a path name to a particular file in a file hierarchy. Each file name in the path name is located in the directory specified by its predecessor. For absolute path names (path names that begin with a slash), the predecessor of the first file name in the path name is the root directory of the process. For relative path names, the predecessor of the first file name of the path name is the current working directory of the process. For example, in the path name fragment a/b, file b is located in directory a. Path name resolution fails if a specifically named file cannot be found in the indicated directory.
Directory Traversal
Inside a directory, the special file name “.” refers to the directory itself, and “..” refers to the directory’s parent directory. As a special case, in the root directory, “..” may refer to the root directory itself. On Windows systems, drive letters may also be provided (for example, C:), as may other special file names, such as “...”—which is equivalent to “../.. ”.
A directory traversal vulnerability arises when a program operates on a path name, usually supplied by the user, without sufficient validation. For example, a program might require all operated-on files to live only in /home, but validating that a path name resolves to a file within /home is trickier than it looks.
Accepting input in the form of ../ without appropriate validation can allow an attacker to traverse the file system to access an arbitrary file. For example, the following path:
/home/../etc/shadow
resolves to
/etc/shadow
An example of a real-world vulnerability involving a directory traversal vulnerability in FTP clients is described in VU#210409 [Lanza 2003]. An attacker can trick users of affected FTP clients into creating or overwriting files on the client’s file system. To exploit these vulnerabilities, an attacker must convince the FTP client user to access a specific FTP server containing files with crafted file names. When an affected FTP client attempts to download one of these files, the crafted file name causes the client to write the downloaded files to the location specified by the file name, not by the victim user. The FTP session in Example 8.8 demonstrates the vulnerability.
Example 8.8. Directory Traversal Vulnerability in FTP Session
CLIENT> CONNECT server
220 FTP4ALL FTP server ready. Time is Tue Oct 01, 2002 20:59.
Name (server:username): test
331 Password required for test.
Password:
230-Welcome, test – Last logged in Tue Oct 01, 2002 20:15 !
CLIENT> pwd
257 "/" is current directory.
CLIENT> ls -l
200 PORT command successful.
150 Opening ASCII mode data connection for /bin/ls.
total 1
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 ...FAKEME5.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 ../../FAKEME2.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 ../FAKEME1.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 ....FAKEME4.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 ..FAKEME3.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 /tmp/ftptest/FAKEME6.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 C: empFAKEME7.txt
-rw-r----- 0 nobody nogroup 54 Oct 01 20:10 FAKEFILE.txt
-rw-r----- 0 nobody nogroup 0 Oct 01 20:11 misc.txt
226 Directory listing completed.
CLIENT> GET *.txt
Opening ASCII data connection for FAKEFILE.txt...
Saving as "FAKEFILE.txt"
Opening ASCII data connection for ../../FAKEME2.txt...
Saving as "../../FAKEME2.txt"
Opening ASCII data connection for /tmp/ftptest/FAKEME6.txt...
Saving as "/tmp/ftptest/FAKEME6.txt"
A vulnerable client will save files outside of the user’s current working directory. Table 8.2 lists some vulnerable products and specifies the directory traversal attacks to which they are vulnerable. Not surprisingingly, none of the vulnerable clients, which are all UNIX clients, are vulnerable to directory traversal attacks that make use of Windows-specific mechanisms.

Many privileged applications construct path names dynamically incorporating user-supplied data.
For example, assume the following program fragment executes as part of a privileged process used to operate on files in a specific directory:
1 const char *safepath = "/usr/lib/safefile/";
2 size_t spl = strlen(safe_path);
3 if (!strncmp(fn, safe_path, spl) {
4 process_libfile(fn);
5 }
6 else abort();
If this program takes the file name argument fn from an untrusted source (such as a user), an attacker can bypass these checks by supplying a file name such as
/usr/lib/safefiles/../../../etc/shadow
A sanitizing mechanism can remove special file names such as “.” and “../” that may be used in a directory traversal attack. However, an attacker can try to fool the sanitizing mechanism into cleaning data into a dangerous form. Suppose, for example, that an attacker injects a “.” inside a file name (for example, sensi.tiveFile) and the sanitizing mechanism removes the character, resulting in the valid file name sensitiveFile. If the input data is now assumed to be safe, then the file may be compromised. Consequently, sanitization may be ineffective or dangerous if performed incorrectly. Assuming that the replace() function replaces each occurrence of the second argument with the third argument in the path name passed as the first argument, the following are examples of poor data sanitation techniques for eliminating directory traversal vulnerabilities:
Attempting to strip out “../” by the following call:
path = replace(path, "../", "");
results in inputs of the form “....//” being converted to “../”. Attempting to strip out “../” and “./” using the following sequence of calls:
path = replace(path, "../", "");
path = replace(path, "./", "");
results in input of the form “.../....///” being converted to “../”.
A uniform resource locator (URL) may contain a host and a path name, for example:
http://host.name/path/name/file
Many Web servers use the operating system to resolve the path name. The problem in this case is that “.” and “..” can be embedded in a URL. Relative path names also work, as do hard links and symbolic links, which are described later in this section.
Equivalence Errors
Path equivalence vulnerabilities occur when an attacker provides a different but equivalent name for a resource to bypass security checks. There are numerous ways to do this, many of which are frequently overlooked. For example, a trailing file separation character on a path name could bypass access rules that don’t expect this character, causing a server to provide the file when it normally would not.
The EServ password-protected file access vulnerability (CVE-2002-0112) is the result of an equivalence error. This vulnerability allows an attacker to construct a Web request that is capable of accessing the contents of a protected directory on the Web server by including the special file name “.” in the URL:
http://host/./admin/
which is functionally equivalent to
http://host/admin/
but which, unfortunately in this case, circumvents validation.
Another large class of equivalence errors comes from case sensitivity issues. For example, the Macintosh HFS+ is case insensitive, so
/home/PRIVATE == /home/private
Unfortunately, the Apache directory access control is case sensitive, as it is designed for UFS (CAN-2001-0766), so that
/home/PRIVATE != /home/private
This is a good example of an equivalence error that occurs because the developers assumed a particular operating system and file system and hadn’t considered other operating environments. A similar equivalence error involves Apple file system forks. HFS and HFS+ are the traditional file systems on Apple computers. In HFS, data and resource forks are used to store information about a file. The data fork provides the contents of the file, and the resource fork stores metadata such as file type. Resource forks are accessed in the file system as
sample.txt/..namedfork/rsrc
Data forks are accessed in the file system as
sample.txt/..namedfork/data
This string is equivalent to sample.txt and can be used to bypass access control on operating systems that recognize data forks. For example, CVE-2004-1084 describes a vulnerability for Apache running on an Apple HFS+ file system where a remote attacker may be able to directly access file data or resource fork contents. This might allow an attacker, for example, to read the source code of PHP, Perl, and other programs written in server-side scripting languages, resulting in unauthorized information disclosure.
Other equivalence errors include leading or trailing white space, leading or trailing file separation characters, internal spaces (for example, file□name), or asterisk wildcard (for example, pathname*).
Symbolic Links
Symbolic links are a convenient solution to file sharing. Symbolic links are frequently referred to as “symlinks” after the POSIX symlink() system call. Creating a symlink creates a new file with a unique i-node. Symlinks are special files that contain the path name to the actual file.
Figure 8.9 illustrates an example of a symbolic link. In this example, a directory with an i-node of 1000 contains two file entries. The first file entry is for fred1.txt, which refers to i-node 500, a normal file with various attributes and containing data of some kind. The second file entry is fred2.txt, which refers to i-node 1300, a symbolic link file. A symbolic link is an actual file, but the file contains only a reference to another file, which is stored as a textual representation of the file’s path. Understanding this structure is very helpful in understanding the behavior of functions on symbolic links.
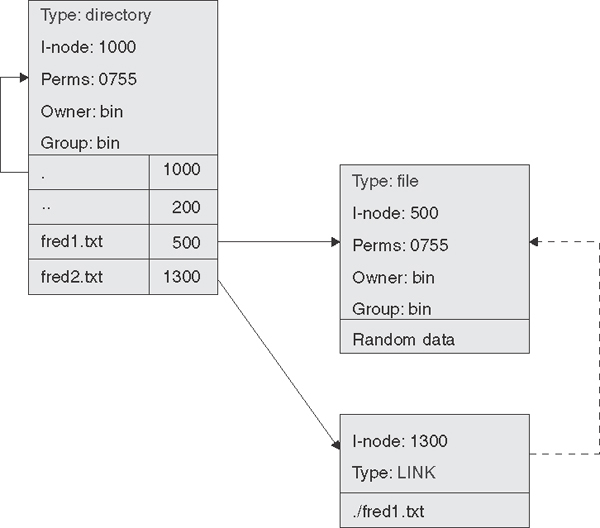
If a symbolic link is encountered during path name resolution, the contents of the symbolic link replace the name of the link. For example, a path name of /usr/tmp, where tmp is a symbolic link to ../var/tmp, resolves to /usr/../var/tmp, which further resolves to /var/tmp.
Operations on symbolic links behave like operations on regular files unless all of the following are true: the link is the last component of the path name, the path name has no trailing slash, and the function is required to act on the symbolic link itself.
The following functions operate on the symbolic link file itself and not on the file it references:

For the period from January 2008 through March 2009, the U.S. National Vulnerability Database lists at least 177 symlink-related vulnerabilities that allow an attacker to either create or delete files or modify the content or permissions of files [Chari 2009]. For example, assume the following code runs as a set-user-ID-root program with effective root privileges:
1 fd = open("/home/rcs/.conf", O_RDWR);
2 if (fd < 0) abort();
3 write(fd, userbuf, userlen);
Assume also that an attacker can control the data stored in userbuf and written in the call to write(). An attacker creates a symbolic link from .conf to the /etc/shadow authentication file:
% cd /home/rcs
% ln –s /etc/shadow .conf
and then runs the vulnerable program, which opens the file for writing as root and writes attacker-controlled information to the password file:
% runprog
This attack can be used, for example, to create a new root account with no password. The attacker can then use the su command to switch to the root account for root access:
% su
#
Symbolic links can be powerful tools for either good or evil. You can, for example, create links to arbitrary files, even in file systems you can’t see, or to files that don’t exist yet. Symlinks can link to files located across partition and disk boundaries, and symlinks continue to exist after the files they point to have been renamed, moved, or deleted. Changing a symlink can change the version of an application in use or even an entire Web site.
Symlink attacks are not a concern within a secure directory such as /home/me (home directories are usually set by default with secure permissions). You are at risk if you operate in a shared directory such as /tmp or if you operate in a nonsecure directory with elevated privileges (running an antivirus program as administrator, for example).
Canonicalization
Unlike the other topics covered in this section so far, canonicalization is more of a solution than a problem, but only when used correctly. If you have read this section carefully to this point, you should know that path names, directory names, and file names may contain characters that make validation difficult and inaccurate. Furthermore, any path name component can be a symbolic link, which further obscures the actual location or identity of a file.
To simplify file name validation, it is recommended that names be translated into their canonical form. Canonical form is the standard form or representation for something. Canonicalization is the process that resolves equivalent forms of a name to a single, standard name. For example, /usr/../home/rcs is equivalent to /home/rcs, but /home/rcs is the canonical form (assuming /home is not a symlink).
Canonicalizing file names makes it much easier to validate a path, directory, or file name by making it easier to compare names. Canonicalization also makes it much easier to prevent many of the file identification vulnerabilities discussed in this chapter, including directory traversal and equivalence errors. Canonicalization also helps with validating path names that contain symlinks, as the canonical form does not include symlinks.
Canonicalizing file names is difficult and involves an understanding of the underlying file system. Because the canonical form can vary among operating systems and file systems, it is best to use operating-system-specific mechanisms for canonicalization. The CERT C Secure Coding Standard [Seacord 2008], “FIO02-C. Canonicalize path names originating from untrusted sources,” recommends this practice.
The POSIX realpath() function can assist in converting path names to their canonical form [ISO/IEC/IEEE 9945:2009]:
The realpath() function shall derive, from the pathname pointed to by file_name, an absolute pathname that names the same file, whose resolution does not involve ‘.’, ‘..’, or symbolic links.
Further verification, such as ensuring that two successive slashes or unexpected special files do not appear in the file name, must be performed.
Many manual pages for the realpath() function come with an alarming warning, such as this one from the Linux Programmer’s Manual [Linux 2008]:
Avoid using this function. It is broken by design since (unless using the non-standard resolved_path == NULL feature) it is impossible to determine a suitable size for the output buffer, resolved_path. According to POSIX a buffer of size PATH_MAX suffices, but PATH_MAX need not be a defined constant, and may have to be obtained using pathconf(3). And asking pathconf(3) does not really help, since on the one hand POSIX warns that the result of pathconf(3) may be huge and unsuitable for mallocing memory. And on the other hand pathconf(3) may return –1 to signify that PATH_MAX is not bounded.
The libc4 and libc5 implementations contain a buffer overflow (fixed in libc-5.4.13). As a result, set-user-ID programs like mount(8) need a private version.
The realpath() function was changed in POSIX.1-2008. Older versions of POSIX allow implementation-defined behavior in situations where the resolved_name is a null pointer. The current POSIX revision and many current implementations (including the GNU C Library [glibc] and Linux) allocate memory to hold the resolved name if a null pointer is used for this argument.
The following statement can be used to conditionally include code that depends on this revised form of the realpath() function:
#if _POSIX_VERSION >= 200809L || defined (linux)
Consequently, despite the alarming warnings, it is safe to call realpath() with resolved_name assigned the value NULL (on systems that support it).
It is also safe to call realpath() with a non-null resolved_path provided that PATH_MAX is defined as a constant in <limits.h>. In this case, the realpath() function expects resolved_path to refer to a character array that is large enough to hold the canonicalized path. If PATH_MAX is defined, allocate a buffer of size PATH_MAX to hold the result of realpath().
Care must still be taken to avoid creating a time-of-check, time-of-use (TOCTOU) condition by using realpath() to check a file name.
Calling the realpath() function with a non-null resolved_path when PATH_MAX is not defined as a constant is not safe. POSIX.1-2008 effectively forbids such uses of realpath() [ISO/IEC/IEEE 9945:2009]:
If resolved_name is not a null pointer and PATH_MAX is not defined as a constant in the <limits.h> header, the behavior is undefined.
The rationale from POSIX.1-2008 explains why this case is unsafe [ISO/IEC/IEEE 9945:2009]:
Since realpath() has no length argument, if PATH_MAX is not defined as a constant in <limits.h>, applications have no way of determining the size of the buffer they need to allocate to safely to pass to realpath(). A PATH_MAX value obtained from a prior pathconf() call is out-of-date by the time realpath() is called. Hence the only reliable way to use realpath() when PATH_MAX is not defined in <limits.h> is to pass a null pointer for resolved_name so that realpath() will allocate a buffer of the necessary size.
PATH_MAX can vary among file systems (which is the reason for obtaining it with pathconf() and not sysconf()). A PATH_MAX value obtained from a prior pathconf() call can be invalidated, for example, if a directory in the path is replaced with a symlink to a different file system or if a new file system is mounted somewhere along the path.
Canonicalization presents an inherent race condition between the time you validate the canonical path name and the time you open the file. During this time, the canonical path name may have been modified and may no longer be referencing a valid file. Race conditions are covered in more detail in Section 8.5. You can securely use a canonical path name to determine if the referenced file name is in a secure directory.
In general, there is a very loose correlation between a file name and files. Avoid making decisions based on a path, directory, or file name. In particular, don’t trust the properties of a resource because of its name or use the name of a resource for access control. Instead of file names, use operating-system-based mechanisms, such as UNIX file permissions, ACLs, or other access control techniques.
Canonicalization issues are even more complex in Windows because of the many ways of naming a file, including universal naming convention (UNC) shares, drive mappings, short (8.3) names, long names, Unicode names, special files, trailing dots, forward slashes, backslashes, shortcuts, and so forth. The best advice is to try to avoid making decisions at all (for example, branching) based on a path, directory, or file name [Howard 2002].
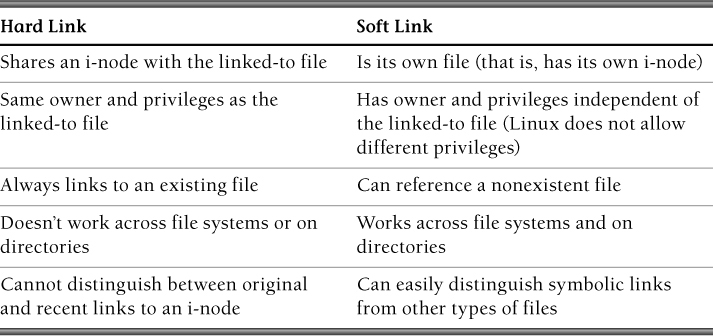
Hard Links
Hard links can be created using the ln command. For example, the command
ln /etc/shadow
increments the link counter in the i-node for the shadow file and creates a new directory entry in the current working directory.
Hard links are indistinguishable from original directory entries but cannot refer to directories4 or span file systems. Ownership and permissions reside with the i-node, so all hard links to the same i-node have the same ownership and permissions. Figure 8.10 illustrates an example of a hard link. This example contains two directories with i-nodes of 1000 and 854. Each directory contains a single file. The first directory contains fred1.txt with an i-node of 500. The second directory contains fred2.txt, also with an i-node of 500. This illustration shows that there is little or no difference between the original file and a hard link and that it is impossible to distinguish between the two.
4. A notable exception to this is Mac OS X version 10.5 (Leopard) and newer, which uses hard links on directories for the Time Machine backup mechanism only.

Deleting a hard link doesn’t delete the file unless all references to the file have been deleted. A reference is either a hard link or an open file descriptor; the i-node can be deleted (data addresses cleared) only if its link counter is 0. Figure 8.11 shows a file that is shared using hard links. Prior to linking (a), owner C owns the file, and the reference count is 1. After the link is created (b), the reference count is incremented to 2. After the owner removes the file, the reference count is reduced to 1 because owner B still has a hard link to the file. Interestingly, the original owner cannot free disk quota unless all hard links are deleted. This characteristic of hard links has been used to exploit vulnerabilities. For example, a malicious user on a multiuser system learns that a privileged executable on that system has an exploit at roughly the same time as the system administrator. Knowing that the system administrator will undoubtedly remove this executable and install a patched version of the program, the malicious user will create a hard link to the file. This way, when the administrator removes the file, he or she removes only the link to the file. The malicious user can then exploit the vulnerability at leisure. This is one of many reasons why experienced system administrators use a secure delete command, which overwrites the file (often many times) in addition to removing the link.

Table 8.3 contrasts hard links and soft links. Although less frequently cited as attack vectors, hard links pose their own set of vulnerabilities that must be mitigated. For example, assume the following code runs in a setuid root application with effective root privileges:
1 stat stbl;
2 if (lstat(fname, &stb1) != 0)
3 /* handle error */
4 if (!S_ISREG(stbl.st_mode))
5 /* handle error */
6 fd = open(fname, O_RDONLY);
The call to lstat() in this program file collects information on the symbolic link file and not the referenced file. The test to determine if the file referenced by fname is a regular file will detect symbolic links but not hard links (because hard links are regular files). Consequently, an attacker can circumvent this check to read the contents of whichever file fname is hard-linked to.
One solution to this problem is to check the link count to determine if there is more than one path to the file:
1 stat stbl;
2 if ( (lstat(fname, &stbl) == 0) && // file exists
3 (!S_ISREG(stbl.st_mode)) && // regular file
4 (stbl.st_nlink <= 1) ) { // no hard links
5 fd = open(fname, O_RDONLY);
6 }
7 else {
8 /* handle error */
9 }
However, this code also has a race condition, which we examine in more detail in Section 8.5.
Because hard links cannot span file systems, another mitigation is to create separate partitions for sensitive files and user files. Doing so effectively prevents hard-link exploits such as linking to /etc/shadow. This is good advice for system administrators, but developers cannot assume that systems are configured in this manner.
Device Files
The CERT C Secure Coding Standard [Seacord 2008] contains rule “FIO32-C. Do not perform operations on devices that are only appropriate for files.” File names on many operating systems, including Windows and UNIX, may be used to access special files, which are actually devices. Reserved MS-DOS device names include AUX, CON, PRN, COM1, and LPT1. Device files on UNIX systems are used to apply access rights and to direct operations on the files to the appropriate device drivers.
Performing operations on device files that are intended for ordinary character or binary files can result in crashes and denial-of-service attacks. For example, when Windows attempts to interpret the device name as a file resource, it performs an invalid resource access that usually results in a crash [Howard 2002].
Device files in UNIX can be a security risk when an attacker can access them in an unauthorized way. For example, if attackers can read or write to the /dev/kmem device, they may be able to alter the priority, UID, or other attributes of their process or simply crash the system. Similarly, access to disk devices, tape devices, network devices, and terminals being used by other processes all can lead to problems [Garfinkel 1996].
On Linux, it is possible to lock certain applications by attempting to open devices rather than files. A Web browser that failed to check for devices such as /dev/mouse, /dev/console, /dev/tty0, and/dev/zero would allow an attacker to create a Web site with image tags such as <IMG src = "file:///dev/mouse"> that would lock the user’s mouse.
POSIX defines the O_NONBLOCK flag to open(), which ensures that delayed operations on a file do not hang the program [ISO/IEC/IEEE 9945:2009]:
When opening a FIFO with O_RDONLY or O_WRONLY set:
If O_NONBLOCK is set, an open() for reading-only shall return without delay. An open() for writing-only shall return an error if no process currently has the file open for reading.
If O_NONBLOCK is clear, an open() for reading-only shall block the calling thread until a thread opens the file for writing. An open() for writing-only shall block the calling thread until a thread opens the file for reading.
When opening a block special or character special file that supports non-blocking opens:
If O_NONBLOCK is set, the open() function shall return without blocking for the device to be ready or available. Subsequent behavior of the device is device-specific.
If O_NONBLOCK is clear, the open() function shall block the calling thread until the device is ready or available before returning.
Otherwise, the behavior of O_NONBLOCK is unspecified.
Once the file is open, programmers can use the POSIX lstat() and fstat() functions to obtain information about a named file and the S_ISREG() macro to determine if the file is a regular file.
Because the behavior of O_NONBLOCK on subsequent calls to read() or write() is unspecified, it is advisable to disable the flag after it has been determined that the file in question is not a special device, as shown in Example 8.9.
Example 8.9. Preventing Operations on Device Files
01 #ifdef O_NOFOLLOW
02 #define OPEN_FLAGS O_NOFOLLOW | O_NONBLOCK
03 #else
04 #define OPEN_FLAGS O_NONBLOCK
05 #endif
06
07 /* ... */
08
09 struct stat orig_st;
10 struct stat open_st;
11 int fd;
12 int flags;
13 char *file_name;
14
15 if ((lstat(file_name, &orig_st) != 0)
16 || (!S_ISREG(orig_st.st_mode))) {
17 /* handle error */
18 }
19
20 fd = open(file_name, OPEN_FLAGS | O_WRONLY);
21 if (fd == -1) {
22 /* handle error */
23 }
24
25 if (fstat(fd, &open_st) != 0) {
26 /* handle error */
27 }
28
29 if ((orig_st.st_mode != open_st.st_mode) ||
30 (orig_st.st_ino != open_st.st_ino) ||
31 (orig_st.st_dev != open_st.st_dev)) {
32 /* file was tampered with */
33 }
34
35 /* Optional: drop the O_NONBLOCK now that
36 * we are sure this is a regular file
37 */
38 if ((flags = fcntl(fd, F_GETFL)) == -1) {
39 /* handle error */
40 }
41
42 if (fcntl(fd, F_SETFL, flags & ~O_NONBLOCK) != 0) {
43 /* handle error */
44 }
45
46 /* operate on file */
47
48 close(fd);
Both the initial stat() and the O_NONBLOCK are needed. Dropping the stat() and just relying on O_NONBLOCK is insufficient because
1. POSIX states that open() with O_NONBLOCK doesn’t block for a device “that supports non-blocking opens.” This leaves open the possibility that devices can exist that don’t support nonblocking opens, and open() would block despite being called with O_NONBLOCK.
2. Just opening some devices may cause something to happen.
3. Solaris has device files in the /dev/fd directory that, when opened, cause an open file descriptor to be duplicated (as if by dup()). For example, open("/dev/fd/3", O_WRONLY) is equivalent to dup(3). Performing an fstat() on the new fd reports the file type of the file that was open on the duplicated fd, not the file type of the /dev/fd/3 file. Assume that the application has a database open on fd 3 and then opens and writes to an output file. If the initial stat() is not performed and the application can be made to use /dev/fd/3 (or any device file with the same major and minor numbers) as the name of the output file, then fstat() will report that the file is a regular file, and the output will be written to the database, corrupting it.
For Windows systems, the GetFileType() function can be used to determine if the file is a disk file, as shown in Example 8.10.
Example 8.10. Using GetFileType() in Windows
01 HANDLE hFile = CreateFile(
02 pFullPathName, 0, 0, NULL, OPEN_EXISTING, 0, NULL
03 );
04 if (hFile == INVALID_HANDLE_VALUE) {
05 /* handle error */
06 }
07 else {
08 if (GetFileType(hFile) != FILE_TYPE_DISK) {
09 /* handle error */
10 }
11 /* operate on file */
12 }
File Attributes
Files can often be identified by other attributes in addition to the file name, for example, by comparing file ownership or creation time. Information about a file that has been created and closed can be stored and then used to validate the identity of the file when it is reopened. Comparing multiple attributes of the file increases the likelihood that the reopened file is the same file that had been previously operated on.
The POSIX stat() function can be used to obtain information about a file. After the call to stat() in the following example, the st structure contains information about the file "good.txt":
1 struct stat st;
2 if (stat("good.txt", &st) == -1) {
3 /* handle error */
4 }
The fstat() function works like stat() but takes a file descriptor. You can use fstat() to collect information about a file that is already open. The lstat() function works like stat(), but if the file is a symbolic link, lstat() reports on the link and stat() reports on the linked-to file. The stat(), fstat(), and lstat() functions all return 0 if successful or −1 if an error occurs.
The structure returned by stat() includes at least the following members:

The structure members st_mode, st_ino, st_dev, st_uid, st_gid, st_atime, st_ctime, and st_mtime should all have meaningful values for all file types on POSIX-compliant systems. The st_ino field contains the file serial number. The st_dev field identifies the device containing the file. Taken together, st_ino and st_dev uniquely identify the file. The st_dev value is not necessarily consistent across reboots or system crashes, however, so you may not be able to use this field for file identification if there is a possibility of a system crash or reboot before you attempt to reopen a file.
As Example 8.11 shows, the fstat() function can also be used to compare the st_uid and st_gid with information about the real user obtained by the getuid() and getgid() functions.
Example 8.11. Restricting Access to Files Owned by the Real User
01 struct stat st;
02 char *file_name;
03
04 /* initialize file_name */
05
06 int fd = open(file_name, O_RDONLY);
07 if (fd == -1) {
08 /* handle error */
09 }
10
11 if ((fstat(fd, &st) == -1) ||
12 (st.st_uid != getuid()) ||
13 (st.st_gid != getgid())) {
14 /* file does not belong to user */
15 }
16
17 /*... read from file ...*/
18
19 close(fd);
20 fd = -1;
By matching the file owner’s user and group IDs to the process’s real user and group IDs, this program restricts access to files owned by the real user of the program. This solution can verify that the owner of the file is the one the program expects, reducing opportunities for attackers to replace configuration files with malicious ones, for example.
More information about this problem and other solutions can be found in The CERT C Secure Coding Standard [Seacord 2008], “FIO05-C. Identify files using multiple file attributes.”
File identification is less of an issue if applications maintain their files in secure directories, where they can be accessed only by the owner of the file and (possibly) by a system administrator.
8.5. Race Conditions
Race conditions can result from trusted or untrusted control flows. Trusted control flows include tightly coupled threads of execution that are part of the same program. An untrusted control flow is a separate application or process, often of unknown origin, that executes concurrently.
Any system that supports multitasking with shared resources has the potential for race conditions from untrusted control flows. Files and directories commonly act as race objects. File access sequences where a file is opened, read from or written to, closed, and perhaps reopened by separate functions called over a period of time are fertile regions for race windows. Open files are shared by peer threads, and file systems can be manipulated by independent processes.
A subtle race condition was discovered in the GNU file utilities [Purczynski 2002]. The essence of the software fault is captured by the code in Example 8.12. This code relies on the existence of a directory with path /tmp/a/b/c. As indicated by the comment, the race window is between lines 4 and 6. An exploit consists of the following shell command, if executed during this race window:
mv /tmp/a/b/c /tmp/c
The programmer who wrote this code assumed that line 6 would cause the current directory to be set to /tmp/a/b. However, following the exploit, the execution of line 6 sets the current directory to /tmp. When the code continues to execute line 8, it may delete files unintentionally. This is particularly dangerous if the process is running with root or other elevated privileges.
Example 8.12. Race Condition from GNU File Utilities (Version 4.1)
01 ...
02 chdir("/tmp/a");
03 chdir("b");
04 chdir("c");
05 // race window
06 chdir("..");
07 rmdir("c");
08 unlink("*");
09 ...
Time of Check, Time of Use (TOCTOU)
TOCTOU race conditions can occur during file I/O. TOCTOU race conditions form a race window by first testing (checking) some race object property and then later accessing (using) the race object.
A TOCTOU vulnerability could be a call to stat() followed by a call to open(), or it could be a file that is opened, written to, closed, and reopened by a single thread; or it could be a call to access() followed by fopen(), as shown in Example 8.13. In this example, the access() function is called on line 7 to check if the file exists and has write permission. If these conditions hold, the file is opened for writing on line 9. In this example, the call to the access() function is the check, and the call to fopen() is the use.
Example 8.13. Code with TOCTOU Condition on File Open
01 #include <stdio.h>
02 #include <unistd.h>
03
04 int main(void) {
05 FILE *fd;
06
07 if (access("a_file", W_OK) == 0) {
08 puts("access granted.");
09 fd = fopen("a_file", "wb+");
10 /* write to the file */
11 fclose(fd);
12 }
13 ...
14 return 0;
15 }
The race window in this code is small—just the code between lines 7 and 9 after the file has been tested by the call to access() but before it has been opened. During that time, it is possible for an external process to replace a_file with a symbolic link to a privileged file during the race window. This might be accomplished, for example, by a separate (untrusted) user executing the following shell commands during the race window:
rm a_file
ln –s /etc/shadow a_file
If the process is running with root privileges, the vulnerable code can be exploited to write to any file of the attacker’s choosing. The TOCTOU condition in this example can be mitigated by replacing the call to access() with logic that drops privileges to the real UID, opens the file with fopen(), and checks to ensure that the file was opened successfully. This approach effectively combines the check for file permission with the file open into an atomic operation. The Windows API functional equivalents of _tfopen() and _wfopen() should be treated the same as fopen().
Part of the reason symbolic links are widely used in exploits is that their creation is not checked to ensure that the owner of the link has permissions for the target file, nor is it even necessary that the target file exist. The attacker need only have write permissions for the directory in which the link is created.
Windows supports a concept called shortcuts that is similar to symbolic linking. However, the symlink attacks rarely work on Windows programs, largely because the API includes primarily file functions that depend on file handles rather than file names and because many programmatic Windows functions do not recognize shortcuts as links.
Create without Replace
Both the C Standard fopen() function and the POSIX open() function will open an existing file or create a new file if the specified file doesn’t already exist. One way to prevent an attacker from operating on an existing file is to open a file only if the file doesn’t already exist. This makes perfect sense if the goal is to create a new file and not to open an existing file—why take the chance an attacker will exploit a vulnerability to operate on a restricted file instead? To eliminate any potential race condition, both the test to determine if the file exists, and the open operation, must both be performed automatically.
The following code, for example, opens a file for writing using the POSIX open() function:
01 char *file_name;
02 int new_file_mode;
03
04 /* initialize file_name and new_file_mode */
05
06 int fd = open(
07 file_name, O_CREAT | O_WRONLY, new_file_mode
08 );
09 if (fd == -1) {
10 /* handle error */
11 }
If file_name already exists at the time the call to open() executes, then that file is opened and truncated. Furthermore, if file_name is a symbolic link, then the target file referenced by the link is truncated. All an attacker needs to do is create a symbolic link at file_name before this call. Assuming the vulnerable process has appropriate permissions, the targeted file will be overwritten.
One solution using the open() function is to use the O_CREAT and O_EXCL flags. When used together, these flags instruct the open() function to fail if the file specified by file_name already exists:
01 char *file_name;
02 int new_file_mode;
03
04 /* initialize file_name and new_file_mode */
05
06 int fd = open(
07 file_name, O_CREAT | O_EXCL | O_WRONLY, new_file_mode
08 );
09 if (fd == -1) {
10 /* handle error */
11 }
The check for the existence of the file and the creation of the file if it does not exist is atomic with respect to other threads executing open() that name the same file name in the same directory with O_EXCL and O_CREAT set. Additionally, if O_EXCL and O_CREAT are set, and file_name is a symbolic link, open() fails and sets errno to [EEXIST] regardless of the contents of the symbolic link. If O_EXCL is set and O_CREAT is not set, the result is undefined. Care should be taken when using O_EXCL with remote file systems because it does not work with NFS version 2. NFS version 3 added support for O_EXCL mode in open(). IETF RFC 1813 defines the EXCLUSIVE value to the mode argument of CREATE [Callaghan 1995]:
EXCLUSIVE specifies that the server is to follow exclusive creation semantics, using the verifier to ensure exclusive creation of the target. No attributes may be provided in this case, since the server may use the target file metadata to store the createverf3 verifier.
Prior to C11, the fopen() call did not provide any mechanism to ensure that a file would be created only if it did not already exist. The C11 fopen() function specification added an exclusive mode (x as the last character in the mode argument), which replicates the behavior of O_CREAT | O_EXCL in open(). If exclusive mode is specified, the open fails if the file already exists or cannot be created. Otherwise, the file is created with exclusive (nonshared) access to the extent that the underlying system supports exclusive access. The fopen_s() functions specified in Annex K can also be used to open files with exclusive (nonshared) access:
1 errno_t res = fopen_s(&fp, file_name, "wx");
2 if (res != 0) {
3 /* handle error */
4 }
The CERT C Secure Coding Standard [Seacord 2008], “FIO03-C. Do not make assumptions about fopen() and file creation,” contains several additional solutions.
Example 8.14 shows a common idiom in C++ for testing for file existence before opening a stream. Presumably the flawed thinking behind this code is that if a file can be opened for reading, it must exist. Of course, there are other reasons a file cannot be opened for reading that have nothing to do with file existence. This code also contains a TOCTOU vulnerability because both the test for file existence on line 9 and the file open on line 13 use file names. Once again, the code can be exploited by the creation of a symbolic link with the same file name during the race window between the execution of lines 9 and 13.
Example 8.14. Code with TOCTOU Vulnerability in File Open
01 #include <iostream>
02 #include <fstream>
03
04 using namespace std;
05
06 int main(void) {
07 char *file_name /* = initial value */;
08
09 ifstream fi(file_name);// attempt to open as input file
10 if (!fi) {
11 // file doesn't exist; so it's safe [sic] to
12 // create it and write to it
13 ofstream fo(file_name);
14 // write to file_name
15 // ...
16 }
17 else { // file exists; close and handle error
18 fi.close();
19 // handle error
20 }
21 }
Some C++ implementations support the ios::noreplace and ios::nocreate flags. The ios::noreplace flag behaves similarly to O_CREAT | O_EXCL in open(); if the file already exists and you try to open it, this operation would fail because it cannot create a file of the same name in the same location. The ios::nocreate flag will not create a new file. Unfortunately, stream functions have no atomic equivalent in the C++ Standard, because not all platforms supported these capabilities. Currently, the only way to perform an atomic open in C++ is to use one of the C language solutions already described. The CERT C++ Secure Coding Standard [SEI 2012b] contains a similar rule, “FIO03-CPP. Do not make assumptions about fopen() and file creation.”
Exclusive Access
Race conditions from independent processes cannot be resolved by synchronization primitives because the processes may not have shared access to global data (such as a mutex variable).
Annex K of the C Standard, “Bounds-checking interfaces,” includes the fopen_s() function. To the extent that the underlying system supports the concepts, files opened for writing are opened with exclusive (also known as nonshared) access. You will need to check the documentation for your specific implementation to determine to what extent your system supports exclusive access and provide an alternative solution for environments that lack such a capability.
Concurrent control flows can also be synchronized using a file as a lock. Example 8.15 contains two functions that implement a Linux file-locking mechanism. A call to lock() is used to acquire the lock, and the lock is released by calling unlock().
Example 8.15. Simple File Locking in Linux
01 int lock(char *fn) {
02 int fd;
03 int sleep_time = 100;
04 while (((fd=open(fn, O_WRONLY | O_EXCL |
05 O_CREAT, 0)) == -1) && errno == EEXIST) {
06 usleep(sleep_time);
07 sleep_time *= 2;
08 if (sleep_time > MAX_SLEEP)
09 sleep_time = MAX_SLEEP;
10 }
11 return fd;
12 }
13 void unlock(char *fn) {
14 if (unlink(fn) == -1) {
15 err(1, "file unlock");
16 }
17 }
Both lock() and unlock() are passed the name of a file that serves as the shared lock object. The sharing processes must agree on a file name and a directory that can be shared. A lock file is used as a proxy for the lock. If the file exists, the lock is captured; if the file doesn’t exist, the lock is released.
One disadvantage of this lock mechanism implementation is that the open() function does not block. Therefore, the lock() function must call open() repeatedly until the file can be created. This repetition is sometimes called a busy form of waiting or a spinlock. Unfortunately, spinlocks consume computing time, executing repeated calls and condition tests. The code from Example 8.15 arbitrarily selects an initial sleep time of 100 microseconds. This time doubles after each check of the lock (up to some user-determined constant time of MAX_SLEEP) in an attempt to reduce wasted computing time.
A second deficiency with this type of locking [Viega 2003] is that a file lock can remain indefinitely if the process holding the lock fails to call unlock(). This could occur, for example, because of a process crash. A common fix is to modify the lock() function to write the locking process’s ID (PID) in the lock file. Upon discovering an existing lock, the new version of lock() examines the saved PID and compares it to the active process list. In the event the process that locked the file has terminated, the lock is acquired and the lock file updated to include the new PID.
While it might sound like a good idea to use this technique to clean up after crashed processes, there are at least three risks to this approach:
1. It is possible that the PID of the terminated process has been reused.
2. Unless carefully implemented, the fix may contain race conditions.
3. The shared resource guarded by the lock may have also been corrupted by a crash.
In Windows, a better alternative for synchronizing across processes is the named mutex object. Named mutexes have a namespace similar to the file system. A call to CreateMutex() is passed the mutex name. CreateMutex() creates a mutex object (if it didn’t already exist) and returns the mutex handle. Acquire and release are accomplished by WaitForSingleObject() (a blocking form of acquire) and ReleaseMutex(). In the event that a process terminates while holding a mutex, the mutex is released. It is possible for any blocked processes to test for such an unanticipated release.
Similar functionality can be achieved with POSIX named semaphores.
Thread synchronization primitives, with the synchronization objects residing in shared memory, can also be used to synchronize processes. However, care must be taken to ensure that the synchronization objects are multiprocess aware, such as by setting the pshared attribute in POSIX threads.
The greatest deficiency with synchronizing processes, regardless of whether shared memory thread synchronization primitives, a named semaphore, a named mutex, or a file is used as a lock, is that this technique is purely voluntary. Two largely independent processes might use this technique to cooperate and effectively avoid race conditions for shared files or network sockets. However, attackers are notoriously uncooperative.
A concept that is closely related but does not suffer from being voluntary is that of a file lock. Files, or regions of files, are locked to prevent two processes from concurrent access. Windows supports file locking of two types: shared locks prohibit all write access to the locked file region, while allowing concurrent read access to all processes; exclusive locks grant unrestricted file access to the locking process while denying access to all other processes. A call to LockFile() obtains shared access; exclusive access is accomplished via LockFileEx(). In either case the lock is removed by calling UnlockFile().
Both shared locks and exclusive locks eliminate the potential for a race condition on the locked region. The exclusive lock is similar to a mutual exclusion solution, and the shared lock eliminates race conditions by removing the potential for altering the state of the locked file region (one of the required properties for a race).
These Windows file-locking mechanisms are called mandatory locks, because every process attempting access to a locked file region is subject to the restriction. Linux implements both mandatory locks and advisory locks. An advisory lock is not enforced by the operating system, which severely diminishes its value from a security perspective. Unfortunately, the mandatory file lock in Linux is also largely impractical for the following reasons: (1) mandatory locking works only on local file systems and does not extend to network file systems (NFS and AFS); (2) file systems must be mounted with support for mandatory locking, and this is disabled by default; and (3) locking relies on the group ID bit that can be turned off by another process (thereby defeating the lock).
Shared Directories
When two or more users, or a group of users, have write permission to a directory, the potential for sharing and deception is far greater than it is for shared access to a few files. The vulnerabilities that result from malicious restructuring via hard and symbolic links suggest that it is best to avoid shared directories. See “Controlling Access to the Race Object” later in this section for ways to reduce access in the event that shared directories must be used.
Programmers frequently create temporary files in directories that are writable by everyone (examples are /tmp and /var/tmp on UNIX and C:TEMP on Windows) and may be purged regularly (for example, every night or during reboot).
Temporary files are commonly used for auxiliary storage for data that does not need to, or otherwise cannot, reside in memory and also as a means of communicating with other processes by transferring data through the file system. For example, one process will create a temporary file in a shared directory with a well-known name or a temporary name that is communicated to collaborating processes. The file then can be used to share information among these collaborating processes.
This is a dangerous practice because a well-known file in a shared directory can be easily hijacked or manipulated by an attacker. Mitigation strategies include the following:
• Use other low-level IPC (interprocess communication) mechanisms such as sockets or shared memory.
• Use higher-level IPC mechanisms such as remote procedure calls.
• Use a secure directory or a jail that can be accessed only by application instances (making sure that multiple instances of the application running on the same platform do not compete).
There are many different IPC mechanisms, some of which require the use of temporary files and others of which do not. An example of an IPC mechanism that uses temporary files is the POSIX mmap() function. Berkeley Sockets, POSIX Local IPC Sockets, and System V Shared Memory do not require temporary files. Because the multiuser nature of shared directories poses an inherent security risk, the use of shared temporary files for IPC is discouraged.
There is no completely secure way to create temporary files in shared directories. To reduce the risk, files can be created with unique and unpredictable file names, opened only if the file doesn’t already exist (atomic open), opened with exclusive access, opened with appropriate permissions, and removed before the program exits.
Unique and Unpredictable File Names
Privileged programs that create temporary files in world-writable directories can be exploited to overwrite restricted files. An attacker who can predict the name of a file created by a privileged program can create a symbolic link (with the same name as the file used by the program) to point to a protected system file. Temporary file names must be both unique (so they do not conflict with existing file names) and unpredictable by an attacker. Even the use of random number generators in file naming is potentially unsafe if the attacker can discover the random number generator’s algorithm and seed.
Create without Replace
Temporary files should be created only if the file doesn’t already exist. The test to determine if the file exists and the open must be performed as an atomic operation to eliminate any potential race condition.
Exclusive Access
Exclusive access grants unrestricted file access to the locking process while denying access to all other processes and eliminates the potential for a race condition on the locked region.
Appropriate Privileges
Temporary files should be opened with the minimum set of privileges necessary to perform the required operations (typically reading and writing by the owner of the file).
Removal before Termination
Removing temporary files when they are no longer required allows file names and other resources (such as secondary storage) to be recycled. In the case of abnormal termination, there is no sure method that can guarantee the removal of orphaned files. For this reason, temporary file cleaner utilities, which are invoked manually by a system administrator or periodically run by a daemon to sweep temporary directories and remove old files, are widely used. However, these utilities are themselves vulnerable to file-based exploits and often require the use of shared directories. During normal operation, it is the responsibility of the program to ensure that temporary files are removed either explicitly or through the use of library routines, such as tmpfile_s(), which guarantee temporary file deletion upon program termination.
Table 8.4 lists common temporary file functions and their respective conformance to these criteria.
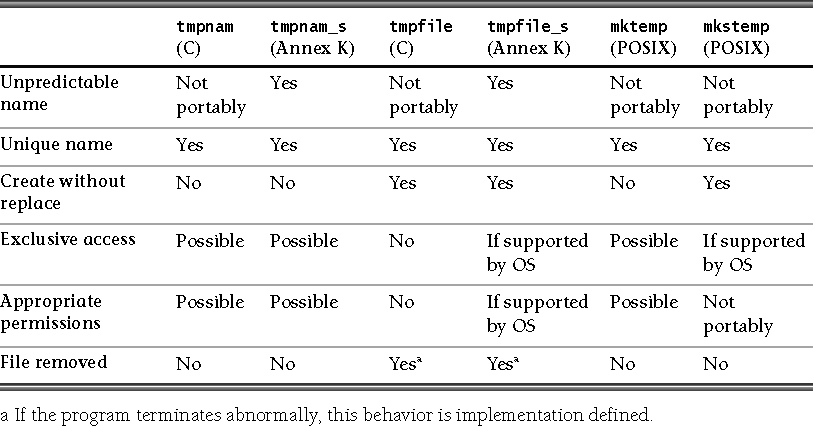
Securely creating temporary files is error prone and dependent on the version of the C runtime library used, the operating system, and the file system. Code that works for a locally mounted file system, for example, may be vulnerable when used with a remotely mounted file system. Moreover, none of these functions are without problems. The only secure solution is not to create temporary files in shared directories. The CERT C Secure Coding Standard [Seacord 2008], “FIO43-C. Do not create temporary files in shared directories,” contains many examples of the insecure use of the functions listed in Table 8.4 as well as some less insecure solutions for creating temporary files in shared directories in the unlikely case there is no better alternative.
8.6. Mitigation Strategies
Fortunately, checking for the existence of symbolic or hard links is mostly unnecessary if your program manages privileges correctly. If the user passes you a symbolic link or a hard link, as long as he or she has permission to modify the file, who cares? Creating a hard link or a symbolic link will not alter the permissions for the actual file. A setuid program that wants to prevent users from overwriting protected files, for example, should (temporarily) drop privileges and perform the I/O with the real user ID.
Mitigation strategies for race-related vulnerabilities can be classified according to the three essential properties for a race condition (introduced in Chapter 7). This section examines
1. Mitigations that essentially remove the concurrency property
2. Techniques for eliminating the shared object property
3. Ways to mitigate by controlling access to the shared object to eliminate the change state property.
Some of these strategies were mentioned earlier in the chapter and are revisited in these sections. Software developers are encouraged to adopt defense in depth and combine applicable mitigation strategies where appropriate.
Closing the Race Window
Race condition vulnerabilities exist only during the race window, so the most obvious mitigation is to eliminate the race window whenever possible. This section suggests several techniques intended to eliminate race windows.
Mutual Exclusion Mitigation
UNIX and Windows support many synchronization primitives capable of implementing critical sections within a single multithreaded application. Among the alternatives are mutex variables, semaphores, pipes, named pipes, condition variables, CRITICAL_SECTION objects, and lock variables. Once two or more conflicting race windows have been identified, they should be protected as mutually exclusive critical sections. Using synchronization primitives requires that care be taken to minimize the size of critical sections.
An object-oriented alternative for removing race conditions relies on the use of decorator modules to isolate access to shared resources [Behrends 2004]. This approach requires all access of shared resources to use wrapper functions that test for mutual exclusion.
When race conditions result from distinct processes, thread synchronization primitives can be used only if the synchronization objects are located in shared memory and are multiprocess aware. A common mitigation for implementing mutual exclusion in separate processes uses Windows named mutex objects or POSIX named semaphores. A less satisfying approach in UNIX is to use a file as a lock. Each of these strategies is explored in more detail in Section 8.5, “Race Conditions.” All synchronization of separate processes is voluntary, so these alternatives work only with cooperating processes.
As previously mentioned, synchronizing threads can introduce the potential for deadlock. An associated livelock problem exists when a process is starved from being able to resume execution. The standard avoidance strategy for deadlock is to require that resources be captured in a specific order. Conceptually, all resources that require mutual exclusion can be numbered as r1, r2, . . . rn. Deadlock is avoided as long as no process may capture resource rk unless it first has captured all resources rj, where j < k.
Thread-Safe Functions
In a multithreaded application, it is insufficient to ensure that there are no race conditions within the application’s own instructions. It is also possible that invoked functions could be responsible for race conditions.
When a function is advertised to be thread-safe, it means that the author believes this function can be called by concurrent threads without the function being responsible for any race condition. Not all functions, even those provided by operating system APIs, should be presumed thread-safe. When a function must be thread-safe, it is wise to consult its documentation. If a non-thread-safe function must be called, then it should be treated as a critical region with respect to all other calls of conflicting code.
Use of Atomic Operations
Synchronization primitives rely on operations that are atomic (indivisible). When either EnterCriticalRegion() or pthread_mutex_lock() is called, it is essential that the function not be interrupted until it has run to completion. If the execution of one call to EnterCriticalRegion() is allowed to overlap with the execution of another (perhaps invoked by a different thread) or to overlap with a LeaveCriticalRegion() call, then there could be race conditions internal to these functions. It is this atomic property that makes these functions useful for synchronization.
Reopening Files
Reopening a file stream should generally be avoided but may be necessary in long-running applications to avoid depleting available file descriptors. Because the file name is reassociated with the file each time it is opened, there are no guarantees that the reopened file is the same as the original file.
One solution, shown in Example 8.16, is to use a check-use-check pattern. In this solution, the file is opened using the open() function. If the file is opened successfully, the fstat() function is used to read information about the file into the orig_st structure. After the file is closed and then reopened, information about the file is read into the new_st structure, and the st_dev and st_ino fields in orig_st and new_st are compared to improve identification.
Example 8.16. Check-Use-Check Pattern
01 struct stat orig_st;
02 struct stat new_st;
03 char *file_name;
04
05 /* initialize file_name */
06
07 int fd = open(file_name, O_WRONLY);
08 if (fd == -1) {
09 /* handle error */
10 }
11
12 /*... write to file ...*/
13
14 if (fstat(fd, &orig_st) == -1) {
15 /* handle error */
16 }
17 close(fd);
18 fd = -1;
19
20 /* ... */
21
22 fd = open(file_name, O_RDONLY);
23 if (fd == -1) {
24 /* handle error */
25 }
26
27 if (fstat(fd, &new_st) == -1) {
28 /* handle error */
29 }
30
31 if ((orig_st.st_dev != new_st.st_dev) ||
32 (orig_st.st_ino != new_st.st_ino)) {
33 /* file was tampered with! */
34 }
35
36 /*... read from file ...*/
37
38 close(fd);
39 fd = -1;
This enables the program to recognize if an attacker has switched files between the first close() and the second open(). The program does not recognize whether the file has been modified in place, however. This solution is described in more detail in The CERT C Secure Coding Standard [Seacord 2008], “FIO05-C. Identify files using multiple file attributes.”
Checking for Symbolic Links
Another use of the check-use-check pattern, shown in Example 8.17, is to check for symbolic links. The POSIX lstat() function collects information about a symbolic link rather than its target. The example uses the lstat() function to collect information about the file, checks the st_mode field to determine if the file is a symbolic link, and then opens the file if it is not a symbolic link.
Example 8.17. Checking for Symbolic Links with Check-Use-Check
01 char *filename = /* file name */;
02 char *userbuf = /* user data */;
03 unsigned int userlen = /* length of userbuf string */;
04
05 struct stat lstat_info;
06 int fd;
07 /* ... */
08 if (lstat(filename, &lstat_info) == -1) {
09 /* handle error */
10 }
11
12 if (!S_ISLNK(lstat_info.st_mode)) {
13 fd = open(filename, O_RDWR);
14 if (fd == -1) {
15 /* handle error */
16 }
17 }
18 if (write(fd, userbuf, userlen) < userlen) {
19 /* handle error */
20 }
This code contains a TOCTOU race condition between the call to lstat() and the subsequent call to open() because both functions operate on a file name that can be manipulated asynchronously to the execution of the program.
The check-use-check pattern can be applied by
1. Calling lstat() on the file name
2. Calling open() to open the file
3. Calling fstat() on the file descriptor returned by open()
4. Comparing the file information returned by the calls to lstat() and fstat() to ensure that the files are the same
This solution is shown in Example 8.18.
Example 8.18. Detecting Race Condition with Check-Use-Check
01 char *filename = /* file name */;
02 char *userbuf = /* user data */;
03 unsigned int userlen = /* length of userbuf string */;
04
05 struct stat lstat_info;
06 struct stat fstat_info;
07 int fd;
08 /* ... */
09 if (lstat(filename, &lstat_info) == -1) {
10 /* handle error */
11 }
12
13 fd = open(filename, O_RDWR);
14 if (fd == -1) {
15 /* handle error */
16 }
17
18 if (fstat(fd, &fstat_info) == -1) {
19 /* handle error */
20 }
21
22 if (lstat_info.st_mode == fstat_info.st_mode &&
23 lstat_info.st_ino == fstat_info.st_ino &&
24 lstat_info.st_dev == fstat_info.st_dev) {
25 if (write(fd, userbuf, userlen) < userlen) {
26 /* handle error */
27 }
28 }
Although this code does not eliminate the race condition, it can detect any attempt to exploit the race condition to replace a file with a symbolic link. Because fstat() is applied to file descriptors, not file names, the file passed to fstat() must be identical to the file that was opened. The lstat() function does not follow symbolic links, but open() does. Comparing modes using the st_mode field is sufficient to check for a symbolic link.
Comparing i-nodes, using the st_ino fields, and devices, using the st_dev fields, ensures that the file passed to lstat() is the same as the file passed to fstat(). This solution is further described by The CERT C Secure Coding Standard [Seacord 2008], “POS35-C. Avoid race conditions while checking for the existence of a symbolic link.”
Some systems provide the O_NOFOLLOW flag to help mitigate this problem. The flag is required by the POSIX.1-2008 standard and so will become more portable over time. If the flag is set and the supplied file_name is a symbolic link, then the open will fail.
Example 8.19. Using O_NOFOLLOW Flag
1 char *file_name = /* something */;
2 char *userbuf = /* something */;
3 unsigned int userlen = /* length of userbuf string */;
4
5 int fd = open(file_name, O_RDWR | O_NOFOLLOW);
6 if (fd == -1) {
7 /* handle error */
8 }
9 write(fd, userbuf, userlen);
This solution completely eliminates the race window. Neither of the solutions described in this section checks for or solves the problem of hard links. This problem and its solutions are further described by The CERT C Secure Coding Standard [Seacord 2008], “POS01-C. Check for the existence of links when dealing with files.” Checking for the existence of symbolic links is generally unnecessary, and the problem is better solved by using the mechanisms provided by the operating system to control access to files. Checking for the existence of symbolic links should be necessary only when your application has assumed responsibility for security—for example, an HTTP server that needs to keep its users from compromising each other.
Eliminating the Race Object
Race conditions exist in part because some object (the race object) is shared by concurrent execution flows. If the shared object(s) can be eliminated or its shared access removed, there cannot be a race vulnerability. This section suggests commonsense security practices based on the concept of mitigating race condition vulnerabilities by removing the race object.
Know What Is Shared
In the same way that young children are taught the dangers of sharing someone else’s drinking glass, programmers need to be aware of the inherent dangers in sharing software resources. Resources that are capable of maintaining state are of concern with respect to race conditions. Determining what is shared begins by identifying the source of the concurrency (that is, the actors who are involved in sharing).
Any two concurrent execution flows of the same computer share access to that computer’s devices and various system-supplied resources. Among the most important and most vulnerable shared resources is the file system. Windows systems have another key shared resource: the registry.
System-supplied sharing is easy to overlook because it is seemingly distant from the domain of the software. A program that creates a file in one directory may be impacted by a race condition in a directory several levels closer to the root. A malicious change to a registry key may remove a privilege required by the software. Often the best mitigation strategies for system-shared resources have more to do with system administration than software engineering—system resources should be secured with minimal access permissions and system security patches installed regularly.
Software developers should also minimize vulnerability exposure by removing unnecessary use of system-supplied resources. For example, the Windows ShellExecute() function may be a convenient way to open a file, but this command relies on the registry to select an application to apply to the file. It is preferable to call CreateProcess(), explicitly specifying the application, than to rely on the registry.
In general, process-level concurrency increases the number of shared objects. Concurrent processes typically inherit global variables and system memory, including settings such as the current directory and process permissions, at the time of child process creation. This inheritance does not produce race objects, so long as there is no way for the child and parent to mutate a shared object. Most global variables, for example, can’t be race objects among processes, because global variables are duplicated, not shared.
The process inheritance mechanism does, however, cause any open object shared by its handle, most notably files, to become a candidate as a race object among related processes. This exposure is potentially greater than for unopened files, because the child process inherits the parent’s access permissions for files that are open when a child is created. Another potential vulnerability associated with inheriting open files is that this may unnecessarily populate the file descriptor table of a child process. In a worst case these unnecessary entries could cause the child’s file descriptor table to fill, resulting in a denial of service. All of these reasons suggest that it is best to close all open files, except perhaps stdin, stdout, and stderr, before forking child processes.
The UNIX ptrace() function also raises serious concerns about shared resources. A process that executes ptrace() essentially has unlimited access to the resources of the trace target. This includes access to all memory and register values. Programmers would be well advised to avoid the use of ptrace() except for applications like debugging, in which complete control over the memory of another process is essential.
Concurrency at the thread level leads to the greatest amount of sharing and correspondingly the most opportunity for race objects. Peer threads share all system-supplied and process-supplied shared objects, but they also share all global variables, dynamic memory, and system environment variables. For example, changing the PATH variable or the current directory within a thread must be viewed in the context of all peer threads. Minimizing the use of global variables, static variables, and system environment variables in threads minimizes exposure to potential race objects.
Use File Descriptors, Not File Names
The race object in a file-related race condition is often not the file but the file’s directory. A symlink exploit, for example, relies on changing the directory entry, or perhaps an entry higher in the directory tree, so that the target of a file name has been altered. Once a file has been opened, the file is not vulnerable to a symlink attack as long as it is accessed through its file descriptor and not the file name’s directory that is the object of the race. Many file-related race conditions can be eliminated by using fchown() rather than chown(), fstat() rather than stat(), and fchmod() rather than chmod() [Wheeler 2003]. POSIX functions that have no file descriptor counterpart, including link(), unlink(), mkdir(), rmdir(), mount(), unmount(), lstat(), mknod(), symlink(), and utime(), should be used with caution and regarded as potentially creating race conditions. File-related race conditions are still possible in Windows, but they are much less likely because the Windows API encourages the use of file handles rather than file names.
Controlling Access to the Race Object
The change state property for race conditions states, “At least one of the (concurrent) control flows must alter the state of the race object (while multiple flows have access).” This suggests that if many processes have only concurrent read access to a shared object, the object remains unchanged and there is no race condition (although there might be confidentiality concerns unrelated to a race). Other techniques for reducing the exposure to the change state property are examined in this section.
Principle of Least Privilege
Sometimes a race condition can be eliminated by reducing process privilege, and other times reducing privilege just limits exposure; but the principle of least privilege is still a wise strategy for mitigating race conditions as well as other vulnerabilities.
Race condition attacks generally involve a strategy whereby the attacker causes the victim code to perform a function for which the attacker wouldn’t (or shouldn’t) normally have permission. The ultimate prize, of course, is when the victim has root privileges. On the other hand, if the process executing a race window has no more privilege than the attacker, then there is little to be gained by an exploit.
There are several ways the principle of least privilege can be applied to mitigate race conditions:
• Whenever possible, avoid running processes with elevated privileges.
• When a process must use elevated privileges, these privileges should normally be dropped using the POSIX privilege management functions, or else CreateRestrictedToken() or AdjustTokenPrivileges() (Windows), before acquiring access to shared resources.
• When a file is created, permissions should be restricted exclusively to the owner. (If necessary, the file’s permissions can be adjusted later by way of the file descriptor.) Some functions, such as fopen() and mkstemp(), require first invoking umask() to establish creation permissions.
Secure Directories
An algorithm for verifying file access permissions must examine not only the permissions of the file itself but also those of every containing directory from the parent directory back to the root of the file system. John Viega and Matt Messier [Viega 2003] propose such an algorithm for UNIX. Their code avoids interprocess race conditions by using the check-use-check pattern to ensure the integrity of every advance of the current directory up the directory tree. Such use of the current directory requires care to avoid race conditions in a multithreaded application but is otherwise a sound approach to verify directory trust. The CERT C Secure Coding Standard [Seacord 2008], “FIO15-C. Ensure that file operations are performed in a secure directory,” also contains a solution for verifying that a specified directory is secure.
Chroot Jail
Another technique for providing a secure directory structure, the chroot jail, is available in most UNIX systems. Calling chroot() effectively establishes an isolated file directory with its own directory tree and root. The new tree guards against “..”, symlink, and other exploits applied to containing directories. The chroot jail requires some care to implement securely [Wheeler 2003]. Calling chroot() requires superuser privileges, and the code executing within the jail must not execute as root lest it be possible to circumvent the isolation directory.
Container Virtualization
Containers provide lightweight virtualization that lets you isolate processes and resources without the need to provide instruction-interpretation mechanisms and other complexities of full virtualization. Containers can be viewed as an advanced version of jails that isolate the file system; separate process IDs, network namespaces, and so forth; and confine resource usage such as memory and CPUs.
This form of virtualization usually imposes little or no overhead, because programs in a virtual partition use the operating system’s normal system call interface and do not need to be subject to emulation or run in an intermediate virtual machine, as is the case with whole-system virtualization, such as VMware.
Container virtualization is available for Linux (lxc, OpenVZ), Windows (Virtuozzo), and Solaris. Standard Linux support is still maturing and contains known security holes. Commercial versions or OpenVZ (fork of Linux) are more advanced.
Exposure
Avoid exposing your file system directory structure or file names through your user interface or other APIs. A better approach might be to let the user specify a key as an identifier. This key can then be mapped through a hash table or other data structure to a specific file in the file system without exposing your file system directly to an attacker.
Race Detection Tools
Race conditions have been studied extensively, and a number of tools have been proposed and developed for their detection and prevention. This section surveys three categories of race condition tools, offering a brief representative examination of tools and some key characteristics.
Static Analysis
A static analysis tool analyzes software for race conditions without actually executing the software. The tool parses the source code (or, in some cases, the binary executable), sometimes relying on user-supplied search information and criteria. Static analysis tools report apparent race conditions, sometimes ranking each reported item according to perceived risk.
Race condition detection has been shown to be an NP-complete problem [Netzer 1990]. Therefore, static race detection tools provide an approximate identification. Additionally, C and C++ are difficult languages to analyze statically, partially because of pointers and pointer arithmetic in C and such features as dynamic dispatch and templates in C++. As a result, all static analysis algorithms are prone to some false negatives (vulnerabilities not identified) and frequent false positives (incorrectly identified vulnerabilities). False positives require software developer investigation.
Dynamic Analysis
Dynamic race detection tools overcome some of the problems with static tools by integrating detection with the actual program’s execution. The advantage of this approach is that a real runtime environment is available to the tool. Analyzing only the actual execution flow has the additional benefit of producing fewer false positives that the programmer must consider. The main disadvantages of dynamic detection are (1) a dynamic tool fails to consider execution paths not taken, and (2) there is often a significant runtime overhead associated with dynamic detection.
A well-known commercial tool is Thread Checker from Intel Corporation. Thread Checker performs dynamic analysis for thread races and deadlocks on both Linux and Windows C++ code. Helgrind is one of the tools of the Valgrind package. It catches errors involving the POSIX threads library but can be confounded by usage of other thread primitives (for example, the futex() system call in Linux). Helgrind works on programs written in C, C++, and Fortran. Helgrind can degrade performance by a factor of 100; consequently, it is useful only for testing purposes and not as a runtime protection scheme.
8.7. Summary
File I/O is a fertile area for vulnerabilities. Many of these vulnerabilities allow unprivileged and unauthorized users to perform operations on privileged files. This can easily lead to unintentional information loss and, in more serious cases, can allow an attacker to gain root privileges on a vulnerable machine.
Performing file I/O securely is extremely difficult and requires an in-depth understanding of the file system, operating system, and APIs. What makes file I/O even more complex is that you may not know in advance which file systems are in use on the platforms on which your software is deployed and that portable APIs tend to be insecure, as security features vary among platforms and file systems.
Race conditions are among the most subtle, difficult-to-discover, and frequently exploitable file I/O vulnerabilities. Their subtlety lies in their source: concurrency. Concurrent code is simply more intellectually complex than sequential code. It is more difficult to write, more difficult to comprehend, and more difficult to test. The subtleties of race conditions have been known for many years and researched extensively, but there are no “silver bullets” for avoiding race conditions.
The vulnerabilities of race conditions can be divided into two major groups: (1) those that are caused by the interactions of the threads (trusted control flows) within a multithreaded process and (2) vulnerabilities from concurrent execution (untrusted flows) outside the vulnerable software. The primary mitigation strategy for vulnerability to trusted threads is to eliminate race conditions using synchronization primitives.
Race conditions from untrusted processes are the source of many well-known file-related vulnerabilities, such as symlink vulnerabilities and vulnerabilities related to temporary files. Synchronization primitives are of little value for race vulnerabilities from untrusted processes. Instead, mitigation requires strategies designed to eliminate the presence of shared race objects and/or carefully restrict access to those race objects.
Many tools have been developed for locating race conditions either statically or dynamically. Most of these tools have serious deficiencies. It is not computationally feasible to accurately identify all race conditions, so most static tools produce significant numbers of false positives and false negatives. Dynamic tools, on the other hand, have a large execution-time cost and are incapable of discovering race conditions outside the actual execution flow. Many detection tools, both static and dynamic, are incapable of detecting race conditions from untrusted processes.
Deficiencies aside, many race detection tools have proven their ability to uncover race conditions even in heavily tested code.