
IF YOU WANT TO ship a great product quickly, you must be able to ask insightful questions, provide good directional guidance, and make smart technical decisions about what you must build now and what you can build later. You must also be able to evaluate and hire engineering managers. Therefore, you must understand your technology at least as well as you understand the oil in your car. You know the oil doesn’t make the car go, but you also know that you had better keep it filled up or your Dodge Dart will become an oversized doorstop. That’s all you really need to know to get home.
While you need to be technical enough to address these issues, I believe you don’t need a computer science degree to achieve shipping greatness. You can achieve shipping greatness if you understand the systems approach I take in this chapter. In fact, I’m convinced that if you understand these things, you can coast gracefully through the technical part of a lead-level interview at Google, Amazon, or Microsoft. If you want to ace an interview or gracefully handle a product development process, you need to know the four S’s: servers, services, speed, and scaling. Once you understand these four basic elements, you’ll be able to ask your team the right questions.
Don’t buy servers if you can help it. First, you’ll have to learn a lot about servers, and anything you learn will be obsolete in six months, which is frustrating and inefficient. Second, you’ll have to do tons of maintenance, like applying service packs, installing upgrades, and performing other tedious chores. What’s even more frustrating about specifying and maintaining your own servers is that your engineering team will frequently have to do the work. It’s not what they’re best at, because they’ve learned the same lesson I just gave you: anything they learn about servers is obsolete in six months, so the good engineers try to learn how to avoid maintenance chores.
Save yourself a headache and the bottle of scotch you’ll inevitably have to buy a surly dev to make up for the late-night trip to the network operations center—use a hosted solution. Use Amazon’s EC2 or Google’s AppEngine or a similar service. You’ll give up a lot of control you didn’t want anyway, and you’ll save yourself a lot of pain.
If you must have your own systems for some strange reason, then lease them through a provider. Don’t worry about where the provider is located. Instead, worry about whether you can get someone technical on the phone when the virtual IP goes haywire. How will you know if the virtual IP has gone haywire, since you didn’t complete that PhD in CS? The properly selected provider will have a proper engineer on staff. If it doesn’t, it’s your fault—you picked the wrong vendor. Always check references (see Chapter 8 on how to build a team for more on this).
Your systems will typically have a three-tier architecture, as shown in Figure 9-1. This architecture may sound complicated, but it is actually dirt simple.
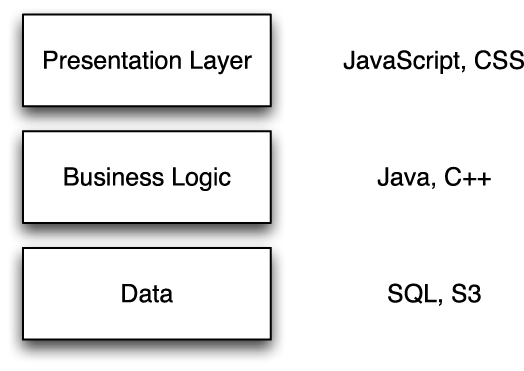
The data layer is typically a database where your data lives—things like customer records and so forth. You’ll retrieve the data using some kind of syntax that is similar to SQL (Structured Query Language). If you’ve ever used Microsoft Access at a moderately advanced level, you’ve encountered SQL.
The business logic is the brains of your operation. It’s where all the tricky calculations happen and where the IF {Charlie said no;} THEN {kill Charlie;} type statements go. Your engineers will build this in Java or C++ or something similar.
The presentation layer is generally HTML and JavaScript. It formats the output of your business logic so the data looks pretty. JavaScript allows users to interact in real time.
AJAX (Asynchronous JavaScript and XML) is nothing more than allowing JavaScript to submit mini-page requests to your business logic, rather than requiring the user to submit a whole form. Instead of the server returning HTML and JavaScript, it returns just a tiny bit of data in the form of XML. So AJAX has nothing to do with a three-tier architecture.
It is possible to flatten this three-tier architecture into two tiers and allow your engineering team to write one file that contains both business logic and presentation logic. Shudder to think. Some frameworks will even hook up with databases in such a way that the database can return XML that can be used directly by frontend JavaScript! These and other great time savers are lovely initially but will haunt you for years after, just like that bad job you did on the grout in the shower. They’re great for internal projects but will probably not survive the sale of your business.
A service-oriented architecture (SOA) doesn’t have much to do with a three-tier architecture—but you had better believe you want one! An SOA breaks down the middle tier that contains your business logic into a collection of independent services. These services may run on the same server, but they are built, versioned, and run independently. Figure 9-2 shows an example SOA.
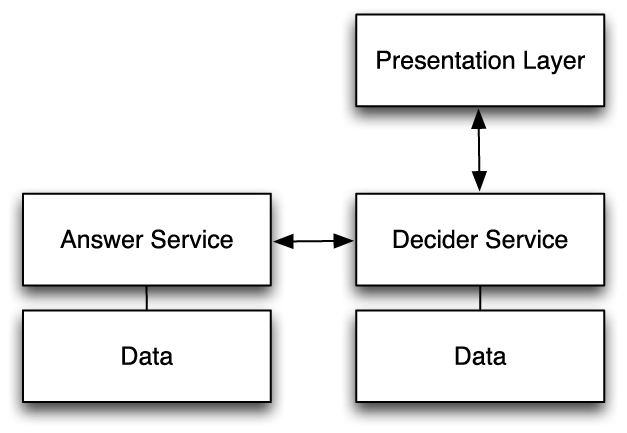
In the SOA shown in Figure 9-2, your engineering team will put the system that figures out Charlie’s response into the answer service. The logic for deciding what to do with Charlie’s answer lives in the decider service.
These services are connected through application programming interfaces (APIs). While not identical, for your purposes these are the same as remote procedure calls (RPCs). So don’t let anyone fool you: APIs and RPCs enable a service to talk to another service. The decider asks the answer service, “What’s Charlie’s answer?” though an API. That API might look like this:
whatIsTheAnswer(Charlie)
The answer service returns an answer to the decider, which can choose what to do with Charlie. These are the kinds of APIs you want to write into your product requirements document. The boundaries of which bits of your system should be in which service aren’t particularly important. In fact, you can even use services outside your company, like a credit card processor to clear transactions or Amazon’s S3 to store data. What is important is that your system is fast and scalable.
If you want a fast system, avoid service chaining at all costs. I know you’d just convinced yourself that services were going to save the world (Amazon certainly did when I was there!), but look at the SOA in Figure 9-3.
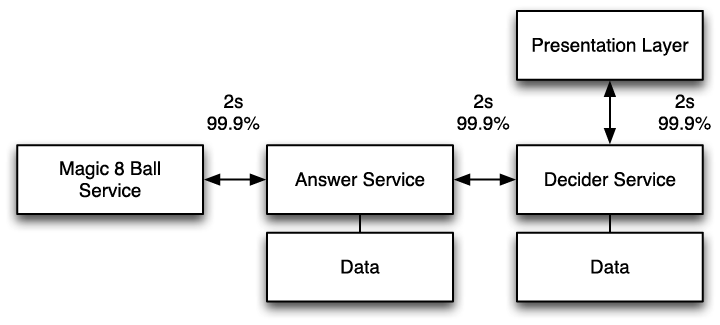
In Figure 9-3, we’ve decided to outsource some of our answers, the ones we really care about, to a new Magic 8 Ball service. Since you’re so passionate about speed and believe that users will leave if you don’t provide a response to the user in two seconds or less, you’ve convinced the engineering team to meet a two-second 99.9% service-level agreement (SLA). Your SLA means that only one out of a thousand responses takes more than two seconds. That’s pretty good, right?
It would be fine if performance were dependent only on the Magic 8 Ball service. Unfortunately, the decider depends on the answer service, which also has a two-second SLA. Therefore, some users are going to have to wait up to six seconds to get a response, because they have to wait for each service in the chain to return a result. What’s worse, most of these systems deliver responses in a normal distribution, meaning you’re probably looking at an average response time of nearly two seconds to the user—on average, not at the peak. Never chain services if you can help it. Look for alternatives.
Steve Yegge, a staff software engineer at Google and a former senior engineer at Amazon, wrote a terrific rant about why Amazon’s internal SOA is profoundly better than Google’s collection of more disorganized systems. He points out a few things to pay attention to:
When you have a lot of services and the customer sees a problem, you may have to trace the customer-facing problem through many services before you find the one service that’s responsible. Good monitoring can help mitigate this problem.
Interteam dependencies become more of an issue, and if a team fails to tell you that they’re changing their API, they can easily break your system. Each team must therefore maintain backward compatibility and communicate to consumers proactively, which is hard.
It’s hard to build a great sandbox, or testing environment, because every one of your systems must exist in that sandbox so that you don’t pollute production systems with garbage data. Even if you do have every one of your systems in a sandbox, establishing data consistency (e.g., order and shipping information are consistent between the ordering service and shipping service) is hard when sandboxed systems continually delete their data.
In spite of this, Steve and I believe that a service-oriented approach is the right approach to follow if you want scalability, extensibility, and general goodness.
We have established that service chaining decreases speed and that service-oriented architectures are nice. So why not just have your two services connect at the presentation layer, the top tier of a three-tier architecture, as shown in Figure 9-4?
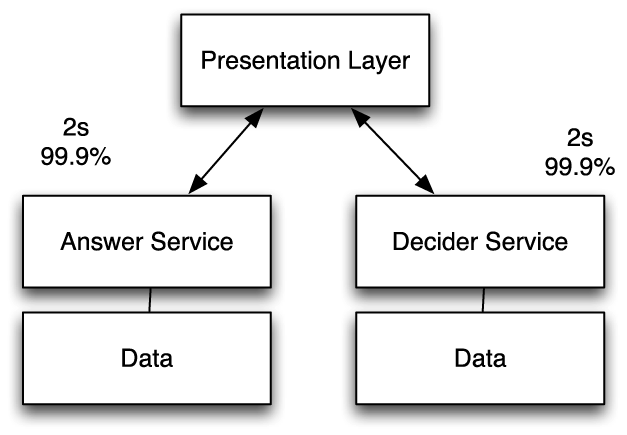
You can do this, but it’s not generally a good idea. Asking JavaScript to perform multiple requests is what AJAX is good at, and the worst-case latency in this scenario is two seconds 99.9% of the time. Unfortunately, APIs that are expected in JavaScript tend to be weak in the real world. What’s more, you end up with a lot of different dependencies all reflected in a myriad of JavaScript files, and such a system can be difficult to manage.
One way to work around these complexity-management challenges is to load independent parts of your application separately. Put another way, if you have two disjoint features, you can make them completely separate parts of the software, such that the JavaScript files are independent, they can load in parallel, and they can be revised in parallel. The independence of the files and services will help you scale and modify your services quickly. The difference between this approach and the approach where your JavaScript loads everything all at once is encapsulation. You want to encapsulate whole functions together so they can work independently.
Caching is another way to solve the service-chaining speed problem. A cache is a copy of a data source. You can have a cache of web pages, a cache of XML, or a cache of a hard disk. You can have a cache of just about anything. Content delivery networks like Akamai are simply caches. Caches have some interesting and valuable properties that you can exploit to increase your system’s speed.
A cache may or may not have a copy of all of the data from its backing store. A system that has all of its data in a cache is considered “cache complete” and has wonderful resiliency properties, because if that backing data store (i.e., a relational database) fails, you can still read your data from the cache.
Cache completeness is nice, but sometimes you want a partial cache. For example, if 90% of your requests are for 10% of your data, you can deploy 100 tiny caches with only that 10% of your data, and you’ll get performance comparable to having 100 servers 90% of the time. You’ll get this performance increase at a tiny fraction of the cost of full servers because caches have very tiny brains. When your service needs something that’s not in the cache, it’s called a “cache miss”; a good caching scheme will “read through” to the backing store and deliver a value, albeit more slowly than a cache hit will. A bad caching scheme will give you nothing. That’s why it’s bad.
A smart caching strategy not only reads through to the backing store, but also stores the retrieved value in the cache. This method will either help keep the cache complete or at least keep a count of requests so that the correct 10% of your data lives in the cache. An even simpler approach is to enable the read-through cache to store the value that it retrieved and eject the least recently used cache entry to make space for the new value. Caches designed in this way perform well for content sites like blogs, where new content gets the majority of hits and older content gets less and less traffic over time.
Caches take time to update. When a value in your data store changes, it must be written to the backing store and then the backing store must update all of the caches. In some badly designed environments, this can lead to cache inconsistency, in which a user sees two different values for the same thing. If you can establish stickiness between a user and a cache, then you can implement a write-through cache, in which the value is written first to the cache and then to the backing store.
Caches are either filled up by reading through or by “warming” them. Empty read-through caches produce very bad performance the first time a given value is requested; if you don’t want to tolerate this, you need to prefill the cache with your data, which is sometimes called “warming” the cache. You’ll have to write additional software to do this.
This is just a cursory explanation of caching, and the good news is that you don’t need to know everything about caching to know that it is very important. You now know enough to ask your engineering team intelligent questions about your caching scheme. Or at least you know enough to be suspicious when you find out that you don’t have one.
Sometimes caches are not sufficient, however. Sometimes you acquire more users and need your systems to do more than just retrieve additional data—they need to do more thinking. That means you need to provision more servers. One of the great things about third-party hosted services like Amazon’s S3 or Google’s AppEngine is that they solve many of these problems for you. If you aren’t building on these systems, read on.
Before you can scale by adding more servers, you need to understand that your servers look like one server to the user because they’ll be behind a virtual IP, or VIP. A VIP allows you to present a single Internet address for all the servers you own. VIP addresses are managed by a tricky piece of hardware that allocates each user to a free server and keeps them stuck there. You can buy or lease VIP hardware. They’re really, really expensive—you just have to pay. Or, you could follow my previous advice and use a fully hosted stack and avoid this complexity entirely. Now that you can scale by adding more servers, you’re going to eventually hear about systems that scale “linearly” or “horizontally.” Really geeky dudes may say “constant time” or “N.” These all mean the same thing (save for “constant time,” which means “I’m smarter than you”): you can add more capacity by adding more servers, and each additional server gives you nearly one full server of additional capacity. In many systems you’ll still hit bottlenecks, such as at the VIP—it will only be able to handle so many connections before you have to add a second VIP. One of the nice aspects of service-oriented architectures is that you can scale each service independently, so if the decider service takes more horsepower and the answerer takes more disk space, you can allocate the correct types of hardware and scale them appropriately.
For such a design to work properly, data must be stored so that you can easily spread it across an increasing number of servers. Creating an algorithm to do this can be tricky. Take people’s names, for example. You could arrange people’s names across 26 servers, one for each letter of the alphabet. This scheme fails because users looking up “Smith” will constantly hammer the S server, and the X, Y, and Z servers will be sitting around wasting space. Luckily, there are less naïve approaches, and you need to make sure that your engineering team is following one of them. One slightly less painful approach is to create a monotonically increasing customer ID for each user and store the data according to customer ID. This allows you to add servers as you add customers.
There are, of course, many ways of storing data on multiple servers so that you scale better. Take your database, for example. Systems that are backed by a single database don’t scale horizontally, because they assume that all data exists in a single place, rather than being distributed across multiple servers. Therefore, if you need to scale, you need to buy a bigger server to replace your previous server, which means writing a big check to Oracle and raising your credit limit with Dell. If you have systems like this, you may reach the point where you have more data than you have memory, and results can no longer be cached. Things slow down quickly at this point. Such a system could be said to scale exponentially, or “badly” if it happens to you.
If you’re in this pickle, you might want to look at a database technology like NoSQL, which refers to a class of database systems where the data is inherently well distributed across servers. However, because you didn’t design the whole storage infrastructure, you can’t really define where the data will live or where queries will go. This means that when the data in the database changes, the changes must propagate through the servers, and if you make two queries during this propagation interval you might get inconsistent results. Or, put another way, if you update your system to say I owe you five bucks, you might see that I owe you five bucks and I might see that I owe you nothing. This is not good, but what is good is that the results came back quickly and eventually the propagation phase will end. We call this eventual consistency. Eventual consistency is probably just fine for things like changes to your résumé, but it’s probably not OK for recording bets in a poker game.
You can also work around some kinds of performance bottlenecks by building indexes. Indexes help you find the data you need quickly by representing your data in a way that differs from the way it is stored. For example, let’s say a user wants to search for “Roger Smith” quickly, but your data is organized on your servers according to customer ID. Without an index, you have to inspect each and every record, which is wildly inefficient. This is referred to as a table scan, and if you have these you should start looking to hire a new engineering lead. With an index, you have a list of users sorted by their names, and you can skip right to “Roger Smith” and find his information. Indexes are not free because you must store them and you must update them, but they’re worth the cost for common operations.
A few pages on architectures does not a CS degree make. Do not attempt to design a system with only the explanations in this book because you will hurt yourself and others. However, you now know enough to ask your engineering team some important questions and understand most of their answers. The parts you didn’t understand were probably Star Wars references. You have to ask some of these questions because they will expose potential problems and help your team think through their design. You might believe that your team already thought through the design, considering that they refer to it as a “design.” You’d be surprised. Here are some questions you can ask:
- Can you please draw me a systems diagram?
Your goal is to understand what all the boxes in this systems diagram do. Start with the box closest to the customer and ask what data lives on it, what it does, and what data is sent to and from it. Work your way through all the boxes until you understand what they do. Look for the things we discussed in this chapter, like service isolation, service chaining, indexes, and scaling.
- What’s the latency for results to be delivered from this box to that box?
You should be able to go through the diagram and identify instances of service chaining, question the necessity for that design, and understand what the total response time will be, worst case. If you find a place in the diagram where the latency of a response is really slow, ask how you can improve that by caching, scaling that service horizontally, or separating out some of its logic into other services.
- Will this scale for N?
Since you’re reading this book, it’s safe to assume that you’ll be wildly successful and therefore the N to which you must scale is a Very Large Number. Ask about what happens when you make this number very large. By “very large,” I mean 10,000 requests per second, or 100 million customer records, or 1 million orders per day. What will your engineering team need to do? Can they just add more of box A, or will they need to call Oracle and have the bosses write a painful check?
- What happens if I remove box B?
Part of understanding your system is understanding how it will fail and (hopefully) recover. Make sure you understand which parts of the system can create catastrophic failures, and help the engineering team prioritize investments in the stability of those parts.
- Are we architected around organizational boundaries or systems boundaries?
Sometimes you’ll find that your SOA reflects the way your company is run, rather than the way your data or application is structured. Since your company’s organizational structure was not designed to respect Moore’s Law, avoid such designs.[5] Some teams have a hard time working together and build redundant or dysfunctional systems; check for this and work against it.
- What can we cache to improve performance?
We spent a lot of time on caches because they are important. They increase performance, increase robustness, and decrease operational costs. Identify static data and common lookups and discuss caching them. Don’t forget to ask about cache completeness.
- What can be loaded independently to improve performance?
Just as we discussed having the answer service and the decider service return results independently, you too should ask if there are parts of the system that can be decoupled. For example, if you can load the advertising separately, such that those systems can function fully independently, you’ll have a much more resilient system, and users will be able to complete their primary task even if the advertising system is broken.