
2.9
Rating Scales and Verbalization
Graduation and granulation play key roles in the ways in which humans deal with complexity and imprecision
—Lotfi A. Zadeh
In human reasoning, everything is a matter of degree, and that holds for human percepts of truth, suitability, importance, simultaneity, value, and so on. The most natural way we use to express our percepts are words (i.e., verbalization). To express the intensity of our percepts, we naturally use verbalized rating scales. Therefore, rating scales provide necessary units of measurement for all percepts that are a matter of degree, and graded logic is directly related to the design and use of rating scales.
In the area of evaluation, we are primarily interested in granular verbalization of three fundamental soft computing variables: (1) suitability, (2) andness/orness (the degree of simultaneity or substitutability), and (3) importance. For each of them, we can create an appropriate rating scale. Both the suitability and the andness/orness belong to interval [0,1], and the endpoints of their scales (scale anchors) correspond to the extreme values 0 and 1. The corresponding anchor labels can be “lowest”/“highest” or “minimum”/“maximum,” or “unacceptable”/“excellent.” If the size of granule is ![]() then the percepts of suitability and andness/orness can be numerically labeled with G labels (from 0 to
then the percepts of suitability and andness/orness can be numerically labeled with G labels (from 0 to ![]() ), as illustrated in Fig. 2.9.1 for the granularity
), as illustrated in Fig. 2.9.1 for the granularity ![]() .
.

Figure 2.9.1 Difference in labeling of suitability/andness/orness and importance.
The case of verbalizing importance is different because we assume the sum‐normalized importance weights that use the interval]0,1[. Indeed, the importance cannot be 0 (since irrelevant attributes are not included in evaluation) and it cannot be 1 (because that would exclude all other attributes in a given group). Consequently, if the size of importance granule is ![]() , then the percepts of importance can be numerically labeled using
, then the percepts of importance can be numerically labeled using ![]() labels (from 1 to
labels (from 1 to ![]() or in the range from “least important” to “most important” or from “very low” to “very high”), as illustrated in Fig. 2.9.1. The verbal expression of strength of the importance scale anchors must be less than the verbal expression of strength of the suitability/andness/orness scale anchors. In other words, the label “very high” should not be replaced with “maximum” or “highest” of “extreme.”
or in the range from “least important” to “most important” or from “very low” to “very high”), as illustrated in Fig. 2.9.1. The verbal expression of strength of the importance scale anchors must be less than the verbal expression of strength of the suitability/andness/orness scale anchors. In other words, the label “very high” should not be replaced with “maximum” or “highest” of “extreme.”
In this chapter, we investigate methods for design of rating scales for suitability, andness/orness, and importance. In addition, we analyze some of popular rating scales from the standpoint of their conformity with general principles of rating scale design.
2.9.1 Design of Rating Scales
Let us now focus on design and use of rating scales, first for a general population (i.e., professionally unprepared respondents) and then for professional evaluators (professionally prepared decision analysts/engineers).
Rating scales for general population (voters, consumers, customers, medical patients, etc.) are extensively studied in business (marketing), economics, psychometrics, politics, and medicine [FRI99, PRE00, NUN67, COX80, SMI13, KRO10, ROH07, HER06]. A recent survey [SMI13] identified significantly more than 100 publications devoted to the rating scales for polling general population.
Properties of rating scales primarily depend on their specific application areas, and, in this chapter, we are interested only in the magnitude scaling of the intensity of percept and not in other forms of scaling. More precisely, we are primarily interested in scaling the intensity of andness/orness, suitability, and importance. The term magnitude scaling is used here to denote a verbalized scaling of the percept of intensity of a selected attribute in a range from a given minimum to a given maximum value. The magnitude scaling can be applied to attributes such as intensity, frequency, probability and others. Of course, the type of attribute determines appropriate linguistic labels. For example, the frequency scaling includes labels such as [never < sometimes < often], the probability scaling includes labels such as [unlikely < possibly < likely], and intensity scaling includes labels such as [low < medium < high], or, in the case of quality, [poor < average < excellent]. We use symbol “<” to denote increasing ordering of scales. So, in the case of suitability, we can use both the [low < medium < high] and the [poor < average < excellent] style of labels. For andness, orness, and importance, however, the appropriate labeling is in the style of [low < medium < high], or [weak < average < strong].
In evaluation logic the verbalization with rating scales should have the following five fundamental properties: (1) strict monotonicity of linguistic labeling, (2) linearity, (3) balance, (4) sufficient cardinality, and (5) hybrid (numeric and linguistic) labeling.
2.9.1.1 Strict Monotonicity of Linguistic Labeling
In the area of evaluation, the linguistic labels such as “large,” “small,” “low,” “high,” “good,” “poor,” and others are primarily used to verbally express the percept of the degree of suitability, which is a value in the interval [0,1] or [0,100%]. Suppose that we experiment with human subjects, and that each respondent is given a numeric scale with n equidistant points (usually 11, numerically denoted as 0,1,2,…,10 or 0%, 10%, 20%,…,100%). These points are interpreted as numeric expressions of magnitude, from the lowest to the highest. Then, the respondents are given a specific linguistic label (e.g., “large”). Of course, everybody has a perception of magnitude specified by the given label and everybody (thinking of T‐shirts) agrees that [small < medium < large < extra‐large]. This is a strictly monotonic scale. We define strict monotonicity as labeling where there is no ambiguity in label ordering. For example, a respondent can perceive the label “large” as a verbal expression of the magnitude of 80%. Other respondents may perceive that “large” corresponds to 90% or 70%, or to other values. However, for strictly monotonic scales, the ordering of labels should never be questionable (all respondents should perceive the same ordering of labels).
If we collect perceptions from sufficiently large number of respondents ![]() , we will have a large array of numeric values x1, x2, …, xm distributed between the minimum value
, we will have a large array of numeric values x1, x2, …, xm distributed between the minimum value ![]() and the maximum value
and the maximum value ![]() . In such a case we can create a continuous probabilistic model based on the cumulative probability distribution function
. In such a case we can create a continuous probabilistic model based on the cumulative probability distribution function ![]() . Then, the most reasonable numeric equivalent of the given linguistic label would be the mean value of this distribution
. Then, the most reasonable numeric equivalent of the given linguistic label would be the mean value of this distribution ![]() .
.
In the case of linguistic labels that denote magnitude (such as “large,” “high,” “strong,” etc.) the mean value ![]() can also have a straightforward logic interpretation as the degree of truth of the assertion that the analyzed label denotes the highest magnitude. For example, if for the label “high quality” we compute
can also have a straightforward logic interpretation as the degree of truth of the assertion that the analyzed label denotes the highest magnitude. For example, if for the label “high quality” we compute ![]() , then 0.8 denotes the degree of truth that “high quality” is the best possible (i.e., equivalent to “maximum quality”).
, then 0.8 denotes the degree of truth that “high quality” is the best possible (i.e., equivalent to “maximum quality”).
Linguistic labels of magnitude always come with a degree of uncertainty. They are fuzzy and can naturally by interpreted as generators of type‐1 fuzzy sets. Consequently, for a given label (e.g., “high”), we need the membership function ![]() of the “high fuzzy set” (we obviously assume
of the “high fuzzy set” (we obviously assume ![]() ). The maximum value of μ(x) corresponds to the value of x where the density of respondents’ answers reaches the maximum value. For the analyzed linguistic label the membership of x in the fuzzy set identified with that label must be directly proportional to the fraction of respondents who voted for the numeric equivalent x. A high degree of membership of any value x can only be achieved by the high fraction of respondents who supported that value. The simplest way to satisfy these conditions is to use
). The maximum value of μ(x) corresponds to the value of x where the density of respondents’ answers reaches the maximum value. For the analyzed linguistic label the membership of x in the fuzzy set identified with that label must be directly proportional to the fraction of respondents who voted for the numeric equivalent x. A high degree of membership of any value x can only be achieved by the high fraction of respondents who supported that value. The simplest way to satisfy these conditions is to use ![]() (i.e., the membership function coincides with the probability density function).
(i.e., the membership function coincides with the probability density function).
The next approach to modeling uncertainty of respondents would be to assume that (due to high uncertainty) the respondents cannot select the most appropriate numeric value that corresponds to the linguistic label but can select an interval that they believe contains the desired numeric equivalent. Of course, we might ask what kind of reasoning is behind the selection of the interval. A rather natural interpretation of this process would be that people select their favorite value—say, 80%—and then start investigating the degree of uncertainty they feel is associated with their estimate of 80%. Then they select the width of “uncertainty zone” around their central estimate—say, 10%—and then report that the interval is [70%, 90%]. Less uncertain respondents might take the uncertainty zone of 5% and select the interval [75%, 85%], while more uncertain respondents with the uncertainty zone of 15% could select the interval [65%, 95%].
It is possible to argue that if in most cases people indeed apply the method
interval = [ favorite value – uncertainty zone, favorite value + uncertainty zone],
then in most cases we don’t need intervals because respondents who are asked to declare intervals also know the favorite value because it is centrally located inside the interval (as a midrange or centroid). In such cases, the use of intervals for assessment of numeric equivalents of linguistic labels can be considered a deliberate specification of uncertainty rather than a provable need. The singleton approach (selection of a single favorite value) yields type‐1 fuzzy models of uncertainty (Figs. 2.2.7, 2.2.9) and the alternative (but not necessarily superior) interval approach yields the type‐2 fuzzy models of uncertainty (Fig. 2.2.8).
The singleton approach to magnitude scaling is experimentally investigated in the research of Rohrmann [ROH07], and the interval approach to magnitude scaling is experimentally investigated in the research of Mendel and his collaborators [MEN01, LIU08, MEN10, WU12]. In both cases, the respondents were given the 11‐point scale (0–10) and a set of linguistic labels. In the singleton case, they were asked to select a single most appropriate value from the scale, and in the interval approach they were asked to select two values that define an interval associated with the label. Rohrmann’s research appears in the context of linguistics and social sciences. Mendel's 16‐words and 32‐words codebooks are applied in the context of computing with words.
Professional evaluation is primarily done with numbers, not with words, but the results of Rohrmann and Mendel are applicable in the area of evaluation in all cases that need linguistic labels, and that includes the following: (1) rating scales for andness/orness, (2) rating scales for importance, (3) rating scales for suitability/preference, (4) rating scales for direct suitability assessment in elementary criteria, and (5) verbalizing evaluation results for stakeholders and for general population of LSP users. So, our study of verbalized rating scales is limited to those five areas of application.
Generally, the points on a rating scale can be labeled in three ways: (1) strictly with linguistic labels (worded scale), (2) strictly with numeric values/labels (numbered scale), and (3) combining linguistic and numeric labels (hybrid, or labeled numeric scale). For example, the scale [low < medium < high] is strictly linguistic; we have not assigned numeric interpretation of labels “low,” “medium” and “high.” Strictly numeric scales are usually based on the following question: On a scale of 1 to G, with 1 being “poor” and G being “excellent,” how would you rate a selected object of evaluation? A main advantage of simple numbered scales is in their simplicity and cultural independence, but in some cases, for general population, numeric scales can be less reliable than worded scales.
The combination of numbered and worded scale can be exemplified using medical scales for pain sensation (whoever had a serious surgery knows them very well). Medical pain scales used in clinical practice have 11 levels. Patients are asked to identify the level of pain using a number from 0 to 10 associated with one of three verbal interpretations shown in Table 2.9.1. Selected numeric values are described (or “anchored”) with linguistic labels. The first two columns show verbal interpretations of some selected pain levels and are used to help patients understand the meaning of numeric values. The third column shows an interpretation that covers all levels using three intensities in each of the three main pain categories (mild, moderate, and severe). This is a labeled numeric scale, and the patient must eventually provide a numeric value of the level of pain sensation.
Table 2.9.1 Three labeled numeric scales of pain sensation.
 |
Table 2.9.2 shows examples of various linguistic labels for strictly monotonic magnitude scaling. The labels used as descriptors of points on a scale should be selected so that (a) ordering of labels is strictly monotonic and (b) the perceived psychological distance between adjacent labels is always the same (linearity). The condition (a) is rather easy to satisfy, particularly for magnitude scales with smaller number of points. On the other hand, satisfying the linearity condition (b) is a difficult problem and requires experimental proofs.
Table 2.9.2 Numeric and linguistic labels for magnitude scaling with cardinality 3 ≤ G ≤ 11.
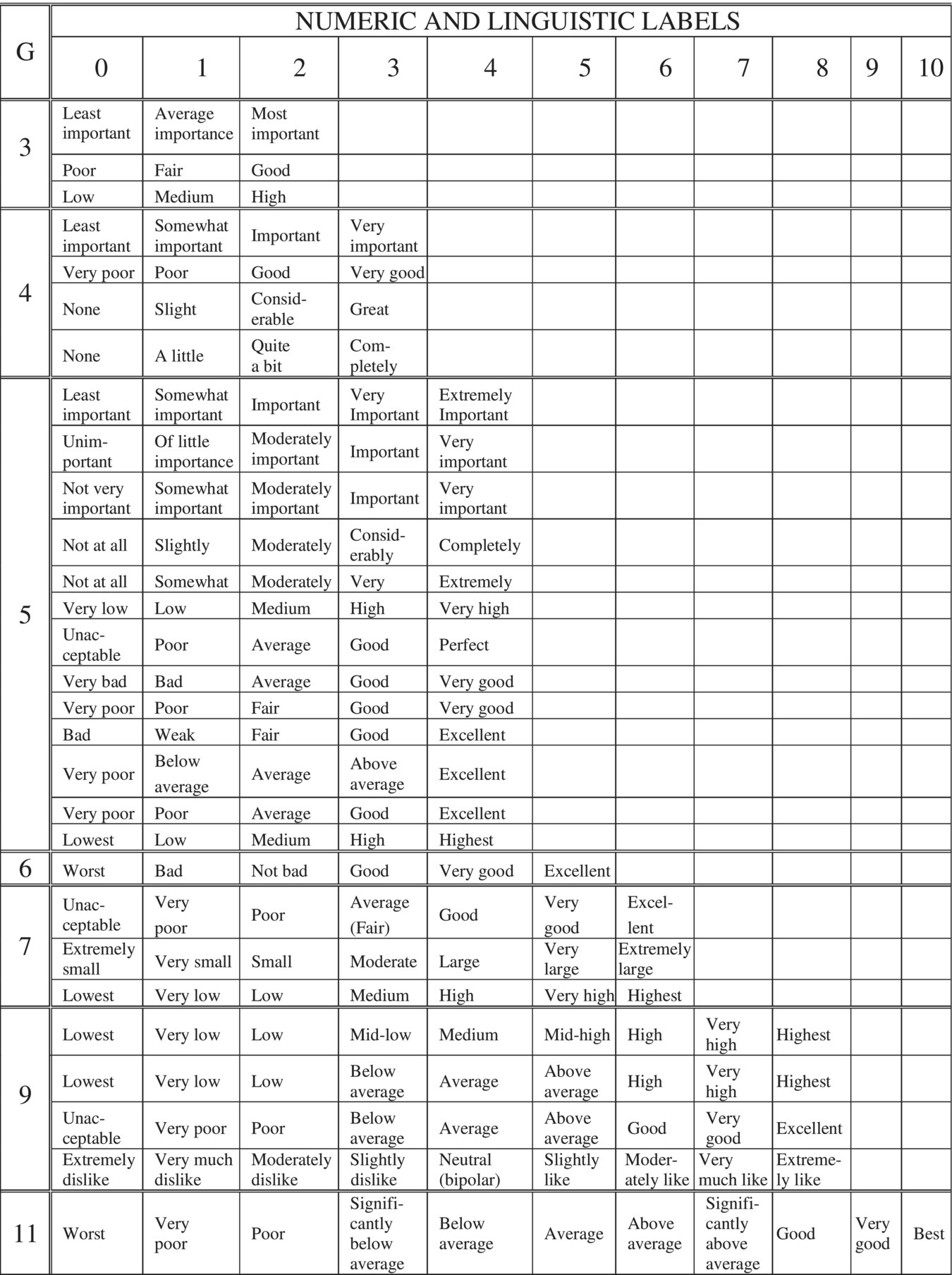 |
To prove strict monotonicity, it is necessary to pass the following strict monotonicity test: take all adjacent pairs of labels and for each pair, taken out of context, ask respondents to verify the ordering. If and only if all respondents verify the same ordering, the scale is strictly monotonic. For example, for the scale [low < medium < high] there is no doubt that low < medium, and medium < high. When the cardinality of a scale increases, it is difficult to pass the strict monotonicity test. For cardinality up to 7 the scales in Table 2.9.2 are strictly monotonic. The scales with cardinality 9 and 11 in Table 2.9.2 look reasonably ordered, but out of context, some adjacent pairs (e.g., poor < significantly below average) might have difficulties in passing the strict monotonicity test.
The fuzziness of linguistic labels is clearly visible in each thesaurus. For example, the word processor suggests that synonyms for “good” are: “high‐quality,” “good quality,” “first‐class,” “first‐rate,” “superior,” “fine,” and “excellent.” Obviously, there are significant differences between some of these labels (e.g., instead of good ≈ excellent, it is rather clear that good < excellent).
The rating scales literature includes variety of examples of human imprecision and inconsistent use of linguistic labels and rating scales. It is important to emphasize that all results reported in the literature describe the behavior of general population of respondents and not the way how the rating scales should be designed and used by trained professionals (e.g., decision analysts). Sample problems reported in the case of general population include the following [FRI99]:
- The interpretation of linguistic labels is not the same for all professions of respondents.
- The inverted scales [most negative < … < most positive] and [most positive > … > most negative] do not generate the same results. Respondents prefer scales that start with the most positive label.
- Respondents are more willing to select positive labels than negative labels. So, to get a uniform coverage, the negative extreme of scale should use labels with lesser strength.
- In some cases, linguistic labels are preferred to numeric labels, but there are also cases where the opposite is true.
- Grammatically balanced scales can generate unbalanced results (e.g., “dissatisfied” and “satisfied” in Table 2.9.3 are not symmetric with respect to “medium” in the middle of the scale).
- The results of numeric scales depend on the range of numbers used as labels, and a general suggestion is to avoid negative numbers.
- Weaker and stronger “anchor values” (labels used for two extremes of each scale) produce different results because respondents are reluctant to use extremely strong labels (e.g., the anchor “very bad” is used more often than the anchor “terrible”).
Table 2.9.3 Rohrmann's verbalization measurements [ROH07] compared to [MEN10].
 |
2.9.1.2 Linearity of Rating Scales
Rating scales can be linear or nonlinear. The predominant forms of scales are linear scales, i.e., interval scales where respondents perceive intervals/granules of equal size. That yields the equal difference between adjacent labeled points on the scale. The nonlinear scales have different sizes of intervals and their applicability in the area of evaluation is less significant. For example, consider the following scale:
frequency of an event = [never < rarely < occasionally < sometimes < usually < always]
The scale seems to be strictly monotonic, but that is not a proof that distances between adjacent labels are the same. In linear scales, we would like to have equidistant labels and additional experiments are necessary to verify the desired linearity.
The linearity of magnitude rating scales means equal perceived psychological distance between all pairs of adjacent labels. Linearity must be experimentally proved using a representative population of respondents. The first step in experiments with linearity is to establish the relationship between linguistic labels and the corresponding numeric interpretation of such labels. A simple method to investigate this relationship for magnitude scaling consists of taking a numbered 0–10 scale, and a randomly selected label (e.g., “medium” or “poor”) and ask respondents to indicate what intensity on the scale best corresponds to the selected label [ROH07] (a singleton approach), or what interval on the scale best corresponds to the selected label [MEN01] (an interval approach). The corresponding distributions can be used to develop type‐1 or type‐2 fuzzy set membership functions. In addition, the mean value of the distribution represents an estimate of the numeric equivalent of the linguistic label.
Rohrmann's study [ROH07] includes (among other quantifiers) empirical results for the “intensity” and “quality” indicators, which can be interpreted in evaluation problems as importance and suitability. The respondents were asked to locate the appropriate position of a randomized linguistic label on a 0–10 scale. Table 2.9.3 shows the sorted mean values of numeric equivalents of selected labels normalized using the interval [0,100%]. The values in one column are computed (for identical or almost identical labels) as normalized mean points of intervals (midrange) reported by Mendel [MEN10] in his 32‐word codebook/vocabulary. Taking into account completely different populations used independently by Rohrmann and Mendel, the agreement of Rohrmann’s and Mendel’s results is excellent, and indicates that some linguistic labels might have rather stable interpretation in a given language (in this case, English). On the other hand, it is rather easy to find labels that mean different things to different people and have significant standard deviation when analyzed on the 0–10 scale.
The labels “average,” “medium,” “moderate,” and “fair” represent the middle region of most magnitude scales [ROH07, MEN01]. All scales are assumed to be “anchored,” i.e., their endpoints represent opposite extreme cases (e.g., lowest vs. highest, worst vs. best, very poor vs. very good, least important vs. most important, etc.). According to [FRI99], the labels most frequently used for the negative extreme include “extremely poor” and “exceptionally poor,” as well as “horrible,” “terrible,” and “awful.” Similarly, the labels used for the positive extreme include “excellent” and “superb,” as well as “superior,” “fantastic,” and “tremendous.”
If we want to create a linear five‐point rating scale, then we need labels located at 0%, 25%, 50%, 75%, and 100%, or convincingly close to these values. The corresponding candidate labels are shown in Table 2.9.3 denoted with Roman numerals I, II, III, IV, and V (note that Rohrmann's quality labels are selected so that they cannot represent granules I and II of the five‐point rating scale).
The label “moderately,” located in the middle of the scale, is two times stronger than the label “slightly,” and the label “considerably” is three times stronger than the label “slightly.” In other words, the distance between the labels “slightly” and “moderately” is practically the same as the distance between the labels “moderately” and “considerably.” Consequently, Rohrmann's measurements indicate (or practically prove) that the rating scale [not at all < slightly < moderately < considerably < completely] is almost perfectly linear, because it is based on almost perfectly equidistant labels (0, 25%, 50%, 76%, 98%).
Measurements reported in [ROH07, MEN01, LIU08, MEN10, WU12, HAO16] show that linguistic labels are fuzzy and nonuniformly distributed. Except in very rare cases and for very low cardinality, it is not possible to create strictly monotonic and linear worded rating scales. This conclusion is graphically illustrated in Figs. 2.9.2 and 2.9.3.

Figure 2.9.2 Sorted magnitudes for Mendel’s scale (top) and Rohrmann’s scale (bottom).

Figure 2.9.3 Mendel’s scale (top, 32 points) and Rohrmann’s scale (bottom, 23 points).
The sorted magnitudes of Mendel’s 32‐point scale (centers of centroids of labels reported in [MEN10]) and Rohrmann’s 23‐point scale are shown in Fig. 2.9.2; it is easy to see nonuniform distances between adjacent labels. That is even more obvious in Fig. 2.9.3, where both scales have nonuniform distribution of points, multiple points with the same magnitude, and visible gaps (e.g., the biggest gap is shown in the upper scale between 27.6% and 45%). It should be noted that the presented magnitude scales are the two most carefully designed and most carefully studied scales with the highest cardinality. So, these scales show the best linearity that can be achieved with worded scales. For example, if we want to create a strictly monotone linear 11‐point scale, then, for each of 11 vertical lines shown in Fig. 2.9.3, we must find a point that is located either strictly on the line or in its immediate vicinity. This is obviously not possible. The conclusion is that if we want strict monotonicity and linearity (and we do), the scale must be hybrid.
2.9.1.3 Balance of Rating Scales
One of the fundamental requirements that rating scales must satisfy is the balance, which is defined as the symmetry between favorable (superior) options and unfavorable (inferior) options. For normalized intervals between 0 and 100% the rating scale is balanced if the number of options below 50% is equal to the number of options above 50% (the middle point of 50% can be included in the scale, or not included).
The scale [low < medium < high] is obviously balanced because medium is defined as a central point and low and high are antonyms (semantically symmetric concepts). However, the frequently used five‐point scale [poor < fair < good < very good < excellent] is positively unbalanced because “fair” is the central label and there are three favorable and only one unfavorable option. Such unbalanced scales are used in cases where the analyst wants to provoke an apparently positive response; of course, such scales are considered unethical in all cases where favorable and unfavorable answers naturally occur with equal probability. The rating scales can also be negatively unbalanced, e.g., [good > fair > poor > very poor > awful].
Some authors claim that unbalanced scales are justified if the probability of specific (e.g., favorable) responses is much higher than the probability of other responses, and consequently there is no reason to offer many options in the area where there will be no responses [FRI99]. The sample scales shown in Table 2.9.2 are all balanced.
Both Rohrmann's and Mendels’s measurements can be used to prove the balance of a general magnitude rating scale. Following are two typically worded and numbered magnitude rating scales based on Rohrmann's measurements:
[poor < average < good < very good < outstanding] = [15 < 49 < 72 < 85 < 99]
[not at all < slightly < moderately < considerably < completely] = [0 < 25 < 50 < 76 < 98]
The mean value of the first scale is 64% (which is significantly above 50%) and the mean value of the second scale is 49.8% (which is an almost perfect result). Therefore, the first scale is positively unbalanced while the second one is balanced.
Unbalanced scales with nonlinear verbalization where granules have different (usually strictly decreasing) sizes, are frequently used for evaluation of candidates for admission in various graduate schools. A good example of reasonable nonlinear verbalization is the graduate admission evaluation scale used by UC San Diego:
| Below average | = Below 40% |
| Average | = 40%–60% |
| Above average | = Top 40% |
| Very good | = Top 20% |
| Outstanding | = Top 10% |
| Superior | = Top 5% |
| Extraordinary | = Top 1% |
A good example of extremely nonlinear verbalization, following is a nonlinear scale with labels that reflect excessive elitism, used at UC Berkeley:
| Below average | = Lower 50% |
| Average | = 51%–70% |
| Somewhat above average | = 71%–80% |
| Good | = 81%–90% |
| Superior | = 91%–95% |
| Outstanding | = 96%–99% |
| Truly exceptional | = Top 1% |
The definition of label “average” seems bizarre, since its range is completely above the mathematical average expressed as the median of 50% (which means “located in the middle of a sorted list of candidates”). Then, the actual median of 50% is considered “below average.”1 Most likely, candidates who outperform 80% of other candidates would not agree to be classified as “somewhat above average,” and candidates who outperform 90% of other candidates certainly feel that they are something more than “good.”
These examples show that in many cases, there is no consensus in interpreting even the most common labels, such as “average,” “good,” and “outstanding,” even in cases where that is done by similar officials working inside a similar system. For example, in the case of UCSD outstanding < superior and in the case of UCB superior < outstanding. It is rather clear that words mean different things to different people [MEN01].
The example of inconsistent labeling at USCD and UCB illustrates an important property that is useful in the area of evaluation: for hybrid scales (combination of numeric and linguistic labels), numeric labels are automatically accepted as primary specifiers of granule identity, while fuzzy linguistic labels are used only as auxiliary (supplemental) verbal descriptors of the selected numeric values. This is useful for creating perfectly linear hybrid rating scales (Section 2.9.1.5).
2.9.1.4 Cardinality of Rating Scales
Each scale contains a finite set of labels and cardinality (or granularity, G) is the number of elements in the set. The researchers of rating scales intended for use by the general population are mostly focused on the study of imperfection of human perceptions. So, they are primarily interested in simple rating scales with no more than 11 points. A more precise professional labeling system with 16 levels was developed by Mendel in [MEN01], followed by a 32‐level system proposed in [LIU08, MEN10, WU12]. In the case of andness/orness, the initially proposed 9‐level scale [DUJ74a] was expanded to 17 levels [DUJ75a] and this is the most frequently used andness/orness scale (in Part Three we also use high precision scales with cardinality 23 and 25).
The fundamental questions related to cardinality are: (1) what is the justifiable (maximum acceptable) cardinality, and (2) should the cardinality be even or odd. The cardinality is constrained by human limitation to reliably distinguish and categorize magnitudes of unidimensional stimuli. The most influential paper in this area is [MIL56] where G. A. Miller suggests the cardinality ![]() (a.k.a., “the magical number seven plus or minus two”) (i.e., from 5 to 9). This result is verified and confirmed many times [COX80], and sometimes extended to the range from 3 to 11 [FRI99, PRE00, KRO10]. Reliability of correct selection of a point in a scale decreases when the cardinality increases above some threshold value, and this value is frequently between 5 and 9.
(a.k.a., “the magical number seven plus or minus two”) (i.e., from 5 to 9). This result is verified and confirmed many times [COX80], and sometimes extended to the range from 3 to 11 [FRI99, PRE00, KRO10]. Reliability of correct selection of a point in a scale decreases when the cardinality increases above some threshold value, and this value is frequently between 5 and 9.
Regarding the even/odd cardinality, the most frequently used scales in research papers and in practice are based on cardinality ![]() . The reason for odd cardinality is simple: If the number of points is odd, then the scale includes the middle point at the level of 50%. This point is usually labeled “medium,” “fair,” or “average.” Such labels are very clear and precise and serve as anchors that help respondents better understand the meaning of other labels below and above of the middle point. Of course, there are situations where an even number of points in a scale can be convenient, but such cases are less frequent (some of them are included in Table 2.9.2).
. The reason for odd cardinality is simple: If the number of points is odd, then the scale includes the middle point at the level of 50%. This point is usually labeled “medium,” “fair,” or “average.” Such labels are very clear and precise and serve as anchors that help respondents better understand the meaning of other labels below and above of the middle point. Of course, there are situations where an even number of points in a scale can be convenient, but such cases are less frequent (some of them are included in Table 2.9.2).
It is important to note that all scales studied in business, psychology, and medical literature are flat—just a sequence of points where each respondent must select one among available ordered (sorted) options. The general population is never given a search algorithm (i.e., a method how to process a scale in multiple steps, segment by segment). Not surprisingly, flat scales restrict cardinality to modest values and limit the accuracy that can be provided by a single respondent or a small team. In addition, the rating scales for general population are only used as an input instrument (i.e., for collecting data from respondents).
In soft computing, the rating scales can be used as either input or output. The worded magnitude scales with high cardinality (like the 32‐word flat codebook in [MEN10]) are not linear, and are very difficult as an input instrument since they are not strictly monotonic (different people would interpret ordering of numerous linguistic labels in different ways). So, the expected reliability of correct selection of one among 32 linguistic labels is certainly low. However, if the same 32‐word flat codebook is used as an output instrument, for converting numeric results to verbalized form and delivering results of decision models to stakeholders, management, and general population, then the precision of such a high granularity instrument can be fully utilized.
The cardinality of andness/orness rating scales can be increased if we have an efficient selection method that can select the most appropriate label with good accuracy. In Section 2.9.2, we present a rating scale stepwise refinement method that combines good cardinality and good precision for andness/orness rating scales.
2.9.1.5 Hybrid Rating Scales
Hybrid scales are defined as rating scales that identify granules using simultaneously numbers and words. Hybrid scales are predominant in professional applications. Their use with general population is less frequent. The basic property of hybrid scales is that whenever we have a labeled numeric value (e.g., in Table 2.9.3, good = 72%, very good = 85%), then the crisp numeric value is automatically accepted as the primary and precise descriptor of specific granule, and the linguistic label, which is fuzzy, plays the role of supplemental fuzzy descriptor. The descriptor is just a symbolic name, and there is plenty of freedom in selecting the name. Therefore, the basic advantage of hybrid scales is that they can be imprecisely verbalized, but at the same time strictly monotonic, balanced, and perfectly linear.
As an example of harmless inconsistencies in labeling, suppose that we use a seven‐point scale [unacceptable < very poor < poor < average < good < very good < excellent]. Now, good = 66.7% (level = 4/6) and very good = 83.3% (level = 5/6). Similarly, if we use a nine‐point scale [unacceptable < very poor < poor < below average < average < above average < good < very good < excellent] then good = 75% (level = 6/8), and very good = 87.5% (level = 7/8). These numeric values are different from the natural (respondent‐generated) values good = 72%, very good = 85%, but both the seven‐point and the nine‐point hybrid scales, numerically labeled 1, …, G, or ![]() , or
, or ![]() ,
, ![]() will be easily accepted by decision makers with the redefined interpretation of labels “good” and “very good.”
will be easily accepted by decision makers with the redefined interpretation of labels “good” and “very good.”
An interesting hybrid unbalanced rating scale, developed for scoring NIH grant proposals [NIH13], is presented in Table 2.9.4. In the light of Rohrmann's and Mendel's interpretation of linguistic labels, this example provides five observations:
- Based on descriptors, the NIH rating scale is highly unbalanced because the descriptor “fair” is proved to have the same meaning as “medium” and “average.” Consequently, score 7 is the middle point of the scale and there are six favorable and only two unfavorable scores.
- The guidelines for users [NIH13] claim “5 is considered an average score” and “a score of 5 is a good, medium‐impact application.” In other words, “good” and “average” are considered equivalent and located at 50% of the overall impact. Unfortunately, this is not correct because both Rohrmann and Mendel proved that “good” > ”average.” In [ROH07], “good” is located at 72% and in [MEN10] “good amount” has center of centroid range located at 65%.
- According to [ROH07], descriptors “exceptional,” “outstanding,” and “excellent” are all located in the top 3%. It seems strange that NIH expects that “high overall impact” means only top 3%.
- According to the rating scales theory, NIH descriptors are wrong. However, the NIH scoring system is essentially a hybrid scale. Descriptors are just a “supporting component” because the evaluators are focused on numeric scores and not on their verbal descriptors. Thus, in hybrid (numbered and worded) scales, the primary carriers of information are numbers and not words. Numbers are precise and not subject to interpretation. Words are imprecise, and various linguistic labels can be attached to a given number without serious negative consequences. Indeed, labels are only auxiliary descriptors and not the primary information carriers. Since each linguistic label is just a name of a numeric object, it does not affect the object itself. It is desirable but not necessary to have the best possible naming of objects. If each descriptor is interpreted as a fuzzy set, then a value from that fuzzy set can be associated with the descriptor even in cases of non‐maximum membership. Humans are flexible and easily adjust the interpretation of a linguistic label as a descriptor of a given numeric score in the context of a specific evaluation process.
- In the case of NIH scale, the scale is positively unbalanced, and a possible justification for that can be based on the fact that most proposals have significant merits and belong in the region above the average value. So, more points are needed above the average than below the average.
Table 2.9.4 NIH scoring system.
 |
The only method for creating rating scales that are strictly monotonic, strictly linear, and balanced consists of using the hybrid scales. In hybrid scales, numeric labeling provides monotonicity, linearity, and balance, while the linguistic labeling is used for symbolic identification of numeric values. Since all magnitude scale labels have their “natural values” that are assigned by a carefully selected population of human respondents, it is desirable that linguistic labels in hybrid scales are selected close to their natural values.
2.9.2 Stepwise Refinement of Rating Scales for Andness and Orness
High cardinality is a necessary (but not sufficient) condition for precision in the use of magnitude rating scales. The accurate selection of the most appropriate among many options remains a problem that needs an algorithmic solution. Strict monotonicity, linearity, and balance are provided by numerical labeling of hybrid scales for magnitude rating. To achieve precision, we would like to have high cardinality, but without problems caused by going beyond the “magical number seven.” This can be achieved using a stepwise refinement method presented in this section.
The idea of stepwise refinement of magnitude rating scale for andness/orness is based on a ternary selection algorithm presented in Figs. 2.9.4 and 2.9.5. In each refinement step we select one of the three offered options. Of course, such selection is easy, and it can be done with accuracy and confidence. We repeat the ternary selection steps four times until we select the most appropriate among 17 levels of andness/orness, used by WPM.17 and GGCD.17 versions of the GCD aggregator (see Fig. 3.4.1). We start with the question Q1 about the type of aggregator: pure conjunction or pure disjunction of partial conjunction/disjunction. After selecting the partial conjunction/disjunction as the type of GCD aggregator, we continue with the second ternary choice: in question Q2 we select among three characteristic forms of GCD: neutrality, partial conjunction, or partial disjunction. In question Q3 we select the range of andness or orness that can be below average, or above the average, or average. Finally, question Q4 determines the level of andness/orness inside the selected group: low, medium, or high. The ternary stepwise refinement process can also be visualized and verbalized as shown in Fig. 2.9.6.

Figure 2.9.4 Flowchart of the ternary search in the case of a 17‐point andness/orness scale.

Figure 2.9.5 Ternary selection of GCD in the case of a 17‐level andness/orness scale.

Figure 2.9.6 A ternary stepwise refinement of GCD and selection of symbolic labels.
The systematic sequence of simple ternary decision steps provides a way to select the most appropriate level of andness/orness by a top‐down stepwise refinement process. The basic benefit is that each step is simple and it is easy to justify each of ternary decisions. The result of this process is a justifiable selection of the most appropriate aggregator in Table 2.9.5 without problems related to the accuracy of verbal labeling of 17 levels of the resulting linear and balanced andness/orness rating scale.
Table 2.9.5 Alternative ways of verbalizing andness and orness for granularity G = 17.
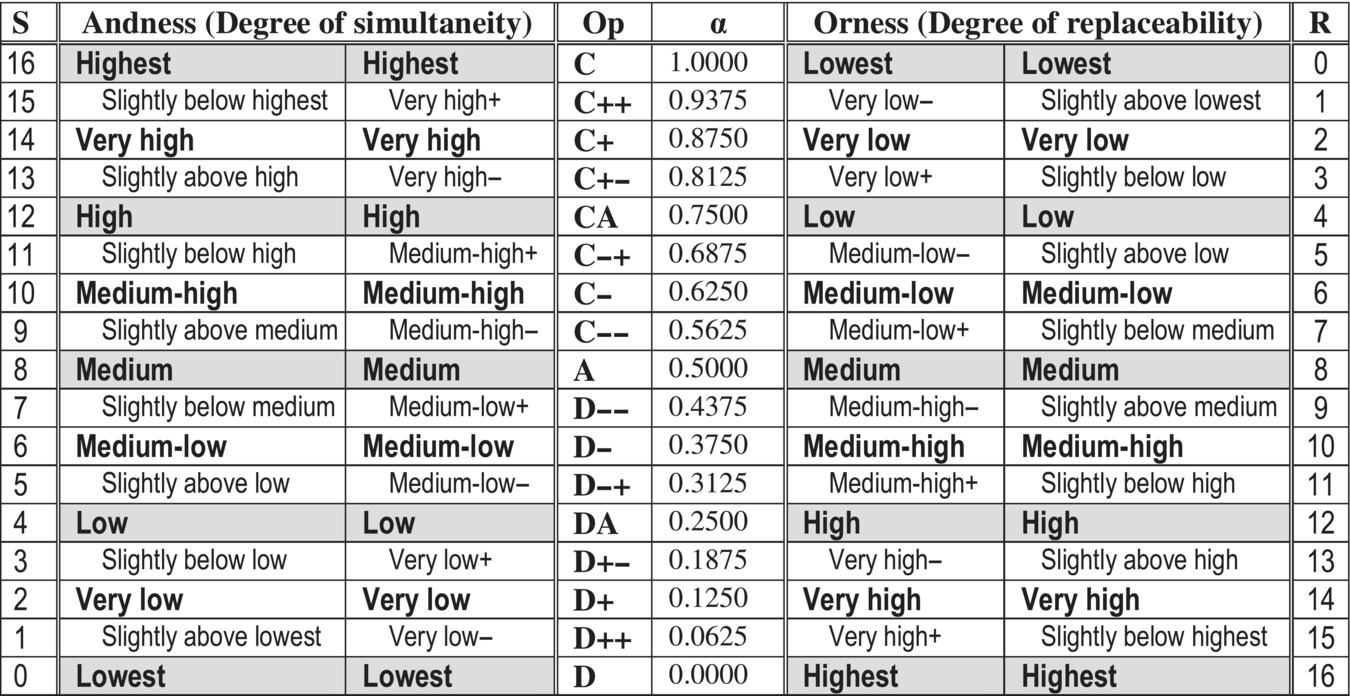 |
The ternary selection algorithm described in Figs. 2.9.4 to 2.9.6 primarily shows the background reasoning that justifies the process of andness/orness adjustment. Of course, after some training and practice evaluators quickly connect and aggregate individual steps and easily and directly select the version of GCD (WPM.17 or GGCD.17) that best reflects their percept of simultaneity or substitutability.
The presented 17‐level rating scale is based on bisection of intervals between adjacent points in the rating scale. That is clearly visible in Fig. 2.9.6, where we create a sequence of rating scales with granularity ![]() . It is easy to see that these scales provide symmetry between week (below average) and strong (above average) aggregators, but cannot provide symmetry of hard and soft aggregators: the number of hard aggregators is always different from the number of soft aggregators, and it is not possible to have a symmetric uniform GCD (denoted UGCD.G in the case of granularity G).
. It is easy to see that these scales provide symmetry between week (below average) and strong (above average) aggregators, but cannot provide symmetry of hard and soft aggregators: the number of hard aggregators is always different from the number of soft aggregators, and it is not possible to have a symmetric uniform GCD (denoted UGCD.G in the case of granularity G).
The stepwise refinement method for generating UGCD aggregators can be developed as shown in Fig. 2.9.7. We again use four decision steps. The first step is the selection of the type of GCD aggregator: conjunctive, disjunctive, or neutral. The second step is the binary choice of form, which can be full or partial. In most cases, the selected form is partial. The third step is the binary choice of mode, which can be hard or soft. These three steps are extremely simple and can be easily justified and performed without errors. The final fourth step is also simple and consists of selecting the intensity/strength of aggregator within the selected mode. In Fig. 2.9.7 we offer n = 1,…,7 degrees of precision. That yields granularity in the wide range from 7 to 31.

Figure 2.9.7 Stepwise refinement of UGCD in the case of cardinality 7, 11,…,31.
In the simplest possible case (n = 1, suitable for initial educational experiences), there is nothing to select in the fourth step. The aggregator is automatically located inside the corresponding interval, in a way that provides the strict linearity of rating scale, i.e., the uniform distribution of points inside [0,1] with step 1/6. This approach yields 7 degrees of andness: α = 0, 1/6, 1/3, 1/2, 2/3, 5/6, 1. Note that an alternative approach would be to locate aggregators in the middle of each of four characteristic intervals and the resulting sequence of andness would be α = 0, 1/8, 3/8, ½, 5/8, 7/8, 1. However, this scale is not linear and consequently not desirable.
The granularity (and precision) can be increased by using ![]() . For example, if n = 3, in the fourth step of the selection process the user decides between three degrees of intensity denoted low, medium, and high. The corresponding scale has the cardinality G = 15 and the andness is incremented with the step 1/14. Figs. 2.9.8 and 2.9.9 summarize the results of the stepwise refinement algorithm for GCD (G = 17) and UGCD (G = 15). Note that in the case of GCD, we can select any of the PC aggregators to serve as the threshold andness aggregator. Similarly, any PD aggregator can be used as the threshold orness aggregator. The border between soft and hard aggregators is adjustable, and aggregators are identified as either weak or strong. In the case of UGCD, the border between soft and hard aggregators is fixed (both the threshold andness and the threshold orness are 75%). Consequently, all UGCD aggregators are identified as either soft or hard. The selection of GCD aggregators for LSP criteria is discussed in Sections 3.1.4 and 3.4.1.
. For example, if n = 3, in the fourth step of the selection process the user decides between three degrees of intensity denoted low, medium, and high. The corresponding scale has the cardinality G = 15 and the andness is incremented with the step 1/14. Figs. 2.9.8 and 2.9.9 summarize the results of the stepwise refinement algorithm for GCD (G = 17) and UGCD (G = 15). Note that in the case of GCD, we can select any of the PC aggregators to serve as the threshold andness aggregator. Similarly, any PD aggregator can be used as the threshold orness aggregator. The border between soft and hard aggregators is adjustable, and aggregators are identified as either weak or strong. In the case of UGCD, the border between soft and hard aggregators is fixed (both the threshold andness and the threshold orness are 75%). Consequently, all UGCD aggregators are identified as either soft or hard. The selection of GCD aggregators for LSP criteria is discussed in Sections 3.1.4 and 3.4.1.

Figure 2.9.8 The medium precision GCD andness/orness rating scale (G = 17).
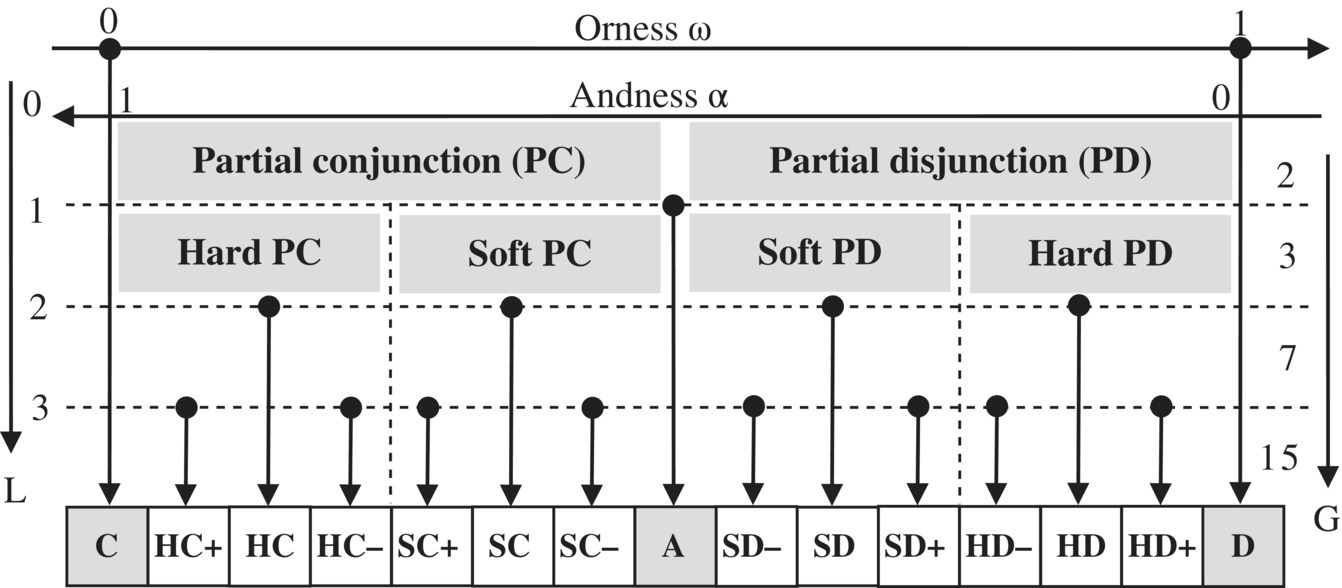
Figure 2.9.9 The medium precision UGCD andness/orness rating scale (G = 15).
2.9.3 Scaling and Verbalizing Degrees of Importance
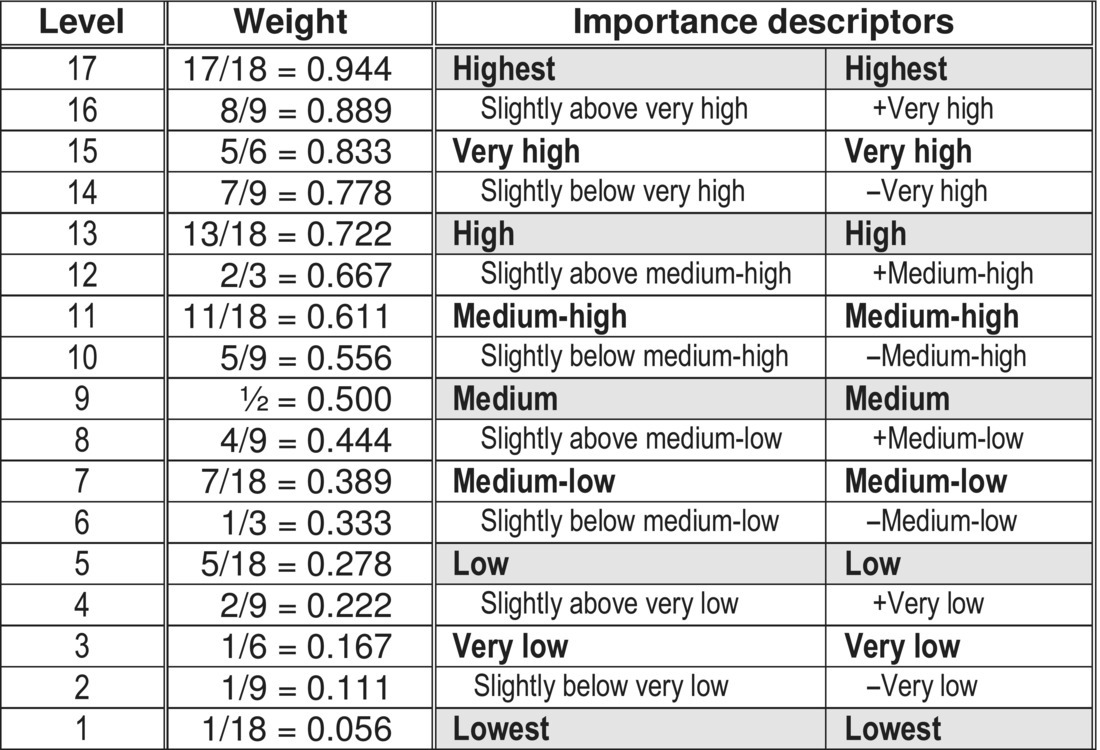
In the case of verbalizing degrees of importance, we assume N discrete levels denoted 1, 2, …, N. The extreme values 0 and 1 are excluded from importance rating scales, as shown in Fig. 2.9.1 and Table 2.9.6. The importance at level L is expressed using weights ![]() . Importance rating scales are hybrid and the importance is primarily expressed using the numeric weight. This is the reason why a given linguistic label can be assigned to multiple numeric values (e.g., in Table 2.9.6 VL describes 1/6, 1/8, and 0.2). The binary approach to verbalization (inserting new values in the middle of existing intervals) can be used in the case of importance, as shown in Table 2.9.7 for N = 17.
. Importance rating scales are hybrid and the importance is primarily expressed using the numeric weight. This is the reason why a given linguistic label can be assigned to multiple numeric values (e.g., in Table 2.9.6 VL describes 1/6, 1/8, and 0.2). The binary approach to verbalization (inserting new values in the middle of existing intervals) can be used in the case of importance, as shown in Table 2.9.7 for N = 17.
Table 2.9.6 Assigning linguistic labels to various degrees of importance.
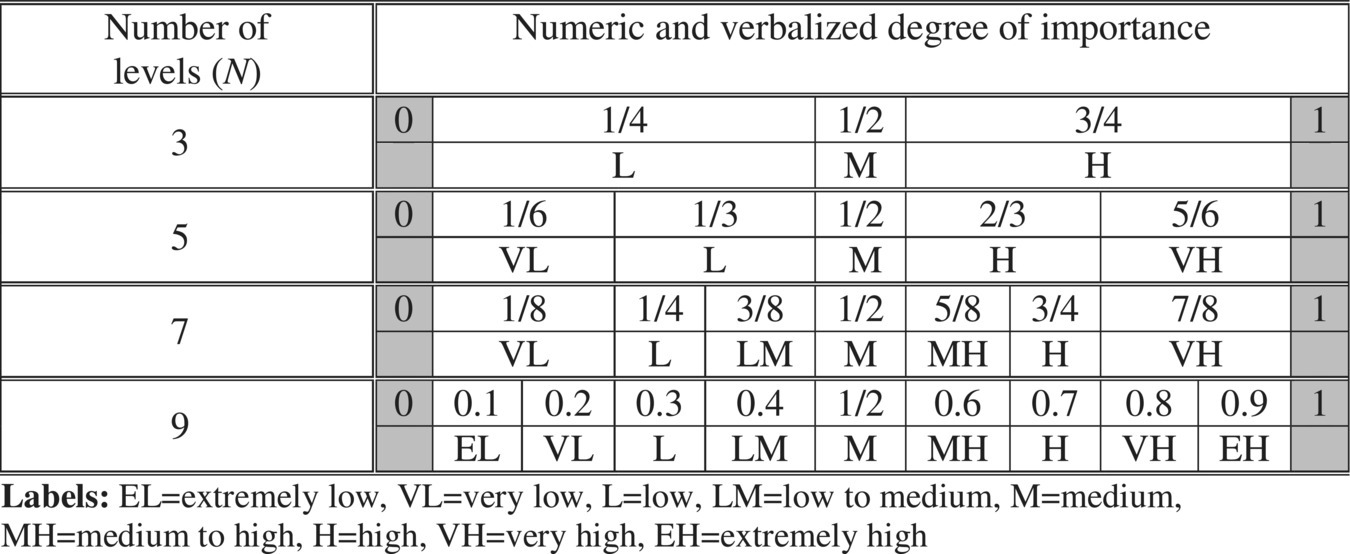 |
Table 2.9.7 Verbalizing 17 levels of importance.
 |
2.9.4 Scaling and Verbalizing Degrees of Suitability/Preference
Verbalization of suitability is exemplified in Table 2.9.8. For a 17‐point scale, the levels of suitability are denoted L = 0,…,16. Each level corresponds to a range of suitability. If the maximum level is N (in Table 2.9.8, N = 16), then the level that corresponds to suitability X can be computed as follows:
Table 2.9.8 Verbalizing 17 levels of suitability/preference.
 |
For example, let us verbalize the suitability X = 0.84. In the case of a 17‐point scale, ![]() and we have
and we have ![]() , what can be verbalized as “slightly above good” (or “slightly below very good”). However, if we decide to use a less precise nine‐point scale [(0) inadequate < (1) very poor < (2) poor < (3) below average < (4) average < (5) above average < (6) good < (7) very good < (8) excellent], then N = 8 and
, what can be verbalized as “slightly above good” (or “slightly below very good”). However, if we decide to use a less precise nine‐point scale [(0) inadequate < (1) very poor < (2) poor < (3) below average < (4) average < (5) above average < (6) good < (7) very good < (8) excellent], then N = 8 and ![]() , what is verbalized as “very good.” However, if X = 0.85, then
, what is verbalized as “very good.” However, if X = 0.85, then ![]() ,
, ![]() , and in both cases the suitability of 85% is verbalized as “very good” or “very high satisfaction of requirements.” The level for verbalization
, and in both cases the suitability of 85% is verbalized as “very good” or “very high satisfaction of requirements.” The level for verbalization ![]() is presented in Fig. 2.9.10. This form of verbalization can be compared with a similar fuzzy verbalization shown in Fig. 2.2.9.
is presented in Fig. 2.9.10. This form of verbalization can be compared with a similar fuzzy verbalization shown in Fig. 2.2.9.

Figure 2.9.10 Level for verbalization L8 as a function of suitability.