
Earlier in this chapter, we discussed some of the attributes of a Web application that is considered "scalable." Those attributes included the ability to address increased user load or data, the promise of being always available and fault tolerant, and the quality of being operationally manageable and maintainable. These attributes or principles of scalability are serious commitments to a high-quality, robust, and flexible application architecture that users of high availability and broadly used Web applications have come to expect. In this section, we will review specific tactics for ensuring scalable application and infrastructure designs, redundancy, fault tolerance, and operational manageability.
While the recommendations discussed in this chapter do not represent the entire scope of research and development that has gone into this subject, they do provide a good overview of the key areas that developers should consider when designing for scale. There are several best practices for improving the scalability of a Web application, which have been categorized into four basic principles below. These principles are intended to help organize very specific, tactical best practices into simple, high-level concepts. They include choosing scalable application designs, designing application infrastructure to scale effectively, defending against application failure, and ensuring manageability and maintainability of the application. We will review each of these thematically in the following sections.
Note
Scalability represents a subject matter that has been explored by many industry leaders. There are a multitude of books, papers, and blog articles about the subject from many seasoned technical people. For a more in-depth perspective on designing scalable Internet applications, I recommend reviewing James Hamilton’s paper titled "Designing and Deploying Internet-Scale Services" at http://mvdirona.com/jrh/talksAndPapers/JamesRH_AmazonDev.pdf.
An application’s design is perhaps the most critical component to achieving scalability. Without the right design, applications will not scale effectively, and the quality of the application delivery will be poor. Achieving a scalable application design involves making some early decisions about how the application will be constructed, how the application might be deployed from a hardware perspective, and how data will be stored and accessed. Let us review each of these in greater detail.
Application developers should strive to implement simple application architectures. Adding additional complexity within application designs by implementing overly complicated business logic, algorithms, or configurations increases the difficulty of debugging, deploying, and maintaining the application. Developers have a tendency to want to demonstrate their technical prowess with abstract, complex designs that are challenging to manage. Instead, they should consider optimizing their designs to be as simple and scalable as possible, so that the eventual expansion of the application use does not inhibit the application’s manageability or maintenance costs.
As discussed earlier in this chapter, scaling out is a better choice for addressing increased user demand for your application. Compared with scaling up, it is a more cost effective, manageable, flexible, and lower risk solution. This model not only allows us to scale the application easily by simply lighting up additional hardware, it also allows us the flexibility to enable and disable different nodes in the infrastructure to either address problems or perform maintenance without user impact.
Application designs should ensure that the overall structure and architecture of the application will adhere to a scale out strategy. This requires that applications be able to scale linearly across multiple servers. Therefore, application code should be written to accommodate that objective. This can be accomplished by structuring application logic to allow deployment of the application to a single server or multiple servers respectively, without depending on complex interactions between servers of the same role. For example, an application that is running on all Web servers within a cluster or pod should not depend on other servers in that cluster for a particular component or service. This ensures that all servers are equal participants in handling the work load, and any server can be removed or added to the cluster at any time without affecting users of the application.
Ideally, application developers will always be able to build applications that scale linearly. This is, however, not always practical. In some cases, our application designs may require portions of our application to perform tasks, such as aggregating information from multiple application server nodes, which do not scale well linearly. It is important to structure as much of the application code as possible in a way that allows the application to scale linearly. In cases where portions of the application will not scale linearly, it may make sense to isolate that functionality and pursue a scale up model for that portion of the application. For example, if an application has a requirement to aggregate data across multiple database partitions into a data warehouse for reporting, it might make sense to separate the aggregation portion of the application onto a larger, single machine.
Scaling out the database tier of an application is perhaps the most complex portion of the application design. As previously mentioned, this requires a combination of federating member databases across multiple servers and partitioning the data in a way that is most effective for the application being developed. Inevitably, most of the effort expended to achieve these goals will be spent designing the partitioning scheme. This is clearly the most important aspect of successfully scaling application data across machines.
When partitioning databases, application developers should take great care to ensure that partitions are adjustable, granular, and not bound to any specific entity such as the letter of a person’s last name or a company name. Inevitably, this will lead to an uneven distribution of data across multiple servers and, therefore, not scale effectively. It is widely recommended to pursue a partitioning scheme that uses a mid-tier lookup service that maps data to an available partition. An example of such a design was illustrated in 5-3. A mid-tier lookup service allows a finer granularity of control over partitioning and the distribution of data, which leads to better management and data scalability control.
We have discussed some specific recommendations for how best to write application code to be scalable, but the key to achieving scalable application architecture is to actually design the hardware infrastructure to support the application. As mentioned, the most common approaches to scaling applications are scaling up and scaling out. Because scaling up involves continuing to add more powerful hardware as demand increases, the hardware infrastructure requirements are much simpler. However, scaling out involves adding servers as load increases, which requires a more complex hardware infrastructure to keep up with the continuous addition of machines. Earlier, we recommended choosing a scale out approach to expand the capacity of your Web application. Hence, the following specific infrastructure recommendations will largely be biased toward that recommendation. Let us review each of these infrastructure recommendations in more detail.
Scaling out a Web application requires a solution for balancing the incoming HTTP traffic across the multiple servers that are managing the load. Typically, requests for a Web application communicate with the primary Uniform Resource Identifier (URI) of the application, such as Contoso.com. Because Contoso.com ultimately translates into an IP address, a solution is required that spreads the incoming requests to Contoso.com across multiple machines that each have a unique IP address. There are several options for accomplishing this. There is software available that could accomplish this requirement, or application developers could use DNS to load balance requests, as well. However, the best possible solution for balancing traffic across multiple servers is to implement a hardware appliance that specializes in distributing HTTP requests across an available pool of servers.
Hardware load balancing is a relatively simple concept to explain but can be tedious to implement. Essentially, load balancing with hardware requires the implementation of a specific network appliance that functions as the gatekeeper for all requests. The appliance is represented by the primary IP address of Contoso.com on the network and returns virtual IP (VIP) addresses of individual servers that it is managing through a routing table whenever Contoso.com is requested. The pool of servers available to handle traffic is managed through configuration of the load balancer, which is usually equipped with configuration software. 5-4 illustrates how load balancing with hardware is accomplished.
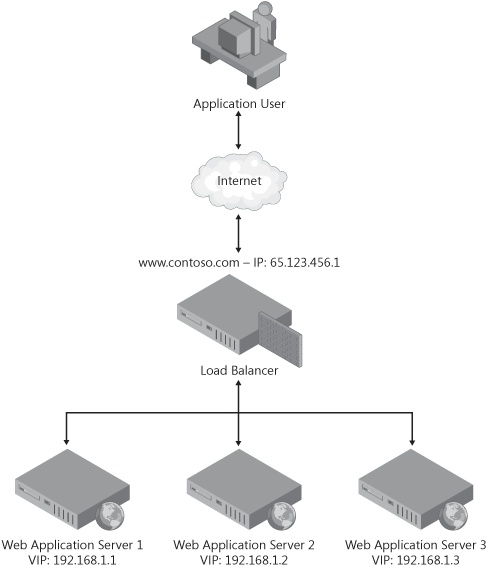
The benefit to load balancing a Web application with a hardware device is primarily manageability. Once configured, the device allows management of the server pool dynamically so that servers can be added or removed on the fly. Additionally, when servers fail, traffic is automatically routed to a healthy server in the pool, which provides a high degree of resiliency in the application. These are quite obviously important benefits to the overall application architecture and manageability. The downside of load balancing with hardware, however, is the cost associated with the purchase of the device. The equipment tends to be 5 to 10 times the cost of an actual server and, for redundancy, is generally purchased in pairs. While this can be prohibitive from a financial perspective, the benefits far outweigh the drawbacks.
Note
There are a variety of load balancers available in the market today, and most ship with additional capabilities like caching, HTTP compression, HTTPS acceleration, and denial of service protection. It is definitely worth doing some homework before purchasing one of these devices. A clear understanding of present and future application architecture requirements will help to identify the appropriate device for your application.
Choosing the right hardware for your Web application can be driven by many factors. If your hardware purchase is in the range of dozens to a few hundred servers, then your decision may largely be driven by the quality of the machine, its useful life, and its ability to be upgraded or repaired. However, if your application (and there are not many) requires hundreds or even thousands of servers, then choosing commodity hardware is probably the way to go.
Some experts in the field of running large-scale Internet facing applications recommend choosing the cheapest, most power conservative servers available. This approach has a positive effect on cost factors like power consumption, but it generally assumes that this type of hardware will fail fairly often, requiring partial or full replacement. While there are some very interesting economics associated with the decision to purchase and run commodity hardware, this often only affects a relatively small number of organizations in the world.
When scaling out a Web application, it is important to choose servers that are small and relatively inexpensive so that adding additional machines is fairly economical. Small servers are generally more cost effective in terms of power consumption, overall price, and maintenance but also perform well enough to handle the needs of most Web applications. Additionally, when clustered together, they individually do not serve a large number of users and therefore will only affect a small number of users if they should fail.
Finally, choosing the right hardware should almost always include choosing the same hardware for all servers of a particular type within the application. Standardizing on equipment not only saves money when bulk purchases are involved, but it also minimizes troubleshooting and maintenance issues.
When deploying several servers, the more commonality and standardization that exists across the equipment, the more manageable and maintainable the infrastructure becomes. Managing large numbers of servers can be challenging in and of itself without the unnecessary complexities of mismatched software versions and configurations in the infrastructure. It is important that all machines in the infrastructure be properly maintained to minimize the introduction of problems with the application. Ensuring that items like the version of the .NET Framework, machine.config, and security settings are consistent across machines helps to alleviate malfunctioning code or other potential quality issues in the application infrastructure. In many cases, these items can be validated through operational monitoring or probing scripts that periodically profile and validate consistency across machines.
In addition to choosing a scalable application design and the appropriate infrastructure, another key principle to developing scalable Web applications is application availability and fault tolerance. All applications will inevitably fail for a variety of different reasons. In some cases, the network may go down, a Web server may crash, an API may not be available, or a database connection may time out. Failures at the component, network, or hardware level are generally unpredictable and even infrequent but never acceptable to users of the applications.
How failures occur within applications is critically important, but even more important is the way by which our applications recover from those failures. Application developers need to make certain that their applications are resilient enough to gracefully handle failures of component-level dependencies or infrastructure and smart enough to catalog the details of the issues for future analysis and understanding. This level of fault tolerance and resiliency ensures that end users only experience what appears to be a healthy and functioning application, rather than obnoxious exception messages or application time-outs. Let us review a few ways that application developers can insulate application functionality from failures.
Adding fault tolerance to your application enables the continued function of the service even when a key component has failed. Generally, this implies that, during a failure of a critical component, the application is able to continue to operate in a degraded mode. A typical example of an application feature that is fault tolerant is that of an order-processing application. In the event that one area of the order processing workflow, which is normally real-time, is unavailable, the application may utilize a work queue for processing additional incoming requests. This allows the application to continue to service user requests, queue the work, and preserve the inbound orders—but with less throughput or responsiveness. Examples such as this demonstrate how fault tolerance is important to business-critical components of an application.
Implementing fault tolerance into components of an application can be a costly endeavor and should be applied to the more mission-critical features of the application. While the value of fault tolerance is obvious, the hidden downside to any implementation is the additional effort required to develop, test, and maintain the code as well as any additional hardware requirements to support fault tolerance for the feature. Clearly, under the right circumstances, these are not insurmountable issues, but they are worth noting as potential scope and economic drivers for the development of the application.
Application failures can have a broad range of impacts on the end users of the software. These failures could range from component-level issues or network-level failures that result in simple error messages to complete datacenter outages, which would render the service unavailable. Hardening applications against such failures requires specific mitigation strategies that should be incorporated into the overall application design. Typically, these mitigation strategies are applied toward significant failure cases such as hardware- or network-level failures, rather than component issues.
The biggest problem addressed by a redundancy strategy is hardware failure. This can occur with various types of hardware, including but not limited to disk storage, Web servers, network switches, or even hardware load balancers. In some cases, minimal hardware failures like disk storage could be mitigated by the appropriate disk striping implementation, which is pretty common with server hardware. Failures of complete Web servers may result in the load balancing of traffic to additional servers in the pool that have capacity to handle the increased load. To ensure that resources are available to accommodate complete failover, it is recommended that capacity planning efforts account for having additional hardware resources standing by. In many cases, this level of redundancy is fairly easy to attain, given many of the previously discussed practices for scaling applications effectively. However, addressing catastrophic failures such as complete cluster or even total datacenter outages are a much more challenging problem to solve, and they require a more significant investment in strategy, process, and equipment. An example of a catastrophic failure could be as simple as a long-term power loss due to a significant weather event or something as devastating as an earthquake that might destroy the datacenter or render it offline. Failures of this caliber are very rare, but they can and do occur. Most organizations that are technically mature understand this and will apply the most applicable level of redundancy to their infrastructure.
For application developers, choosing the right level of redundancy is something generally left up to the individuals who manage risk for your organization. After all, the appropriate level of redundancy is an expenditure that is often decided by analyzing the risk associated with the loss and determining the cost benefit to the business as a whole. However, it is important for developers to not only design applications with redundancy in mind but also to help inform those decision makers about the importance of having redundant application infrastructure and the various options available for implementation.
Oftentimes the applications that we build are being implemented on top of a platform, shared set of code, third-party components, or common services. Architecturally speaking, it makes perfect sense to build application-specific business logic on top of generic components or services that other applications share. This is inarguably a good practice for many reasons. However, it does present challenges for user-facing applications that experience failures from the various platform assets that the application is built on.
It is critically important for application developers to design their applications with mitigation strategies for dependency failures. This principle is very similar to that of being fault tolerant, but it is more specifically targeting shared application code or services. For example, if an application was depending on a shared subsystem to perform an access control list check every time a user wanted to access a piece of data, then the application should ensure that the access control list data is always available to its respective method invocations. Applying a simple caching strategy on a separate machine, or set of machines, for access control data might be one way to insulate against a failure of the access control subsystem. This ensures that users do not experience any issues with their experience when a critical subsystem is unavailable. Application users inherently do not understand the complexities and depth of the applications they are using. As application developers, it is our job to ensure that the software always appears to be healthy and functional, regardless of what may be going on behind the scenes. In some cases, this may require temporary degradation to the application in terms of functionality, but this is often better than displaying a failure message to the user.
Thus far we have discussed tactics to address two of the three principles outlined in the previous section. Those tactics enumerated specific and actionable recommendations for how to design applications to address scalability and availability in your applications. While both of those goals and their respective tactics for achieving them are critically important, they are complemented by the third and equally important principle that applications be manageable and maintainable from an operational perspective.
As applications begin to scale out to accommodate more users, the complexity of the application infrastructure, live site issues, and management overhead can increase, as well. This can lead to potential quality problems with the delivery of the application, which will negatively affect users while simultaneously driving up the cost of maintenance. Live site bugs, capacity issues, and general server reliability problems are just a few examples of issues that may arise unexpectedly and require diagnosis and supportive action. It is important that application developers consider the necessary features that enable their applications to be supported and managed by individuals who may not have actually written the executing application code. Adding instrumentation, interfaces for connecting monitoring tools, and application health reporting are just a few examples of features that help to paint a clear picture of how the application is working in the live production environment. This will inevitably lead to an improvement in managing the application, as well as diagnosing and addressing issues on the live site even as the application scales to accommodate additional users.
Unfortunately, addressing manageability and maintainability within application designs is often not the first priority for development teams. As application developers, we tend to gravitate toward the set of "problems" that are most interesting for us to solve from an architectural and business perspective. This generally means that the set of work required to ensure that the application can be operationally managed and maintained is prioritized lower than design work for other parts of the application. Therefore, the correct level of development investment in areas of manageability and maintainability is not always made during the design of the application. For small applications, it may make sense to shrink the investment in these areas, but for applications that intend to scale to large user communities, early investment in the right features and processes can make all the difference in the quality of service in the long run. Let us review a few tactics for addressing any potential manageability or maintenance issues with your application.
Operational management of Web applications can be challenging work. This is especially true when the first tier of incident support is the systems engineers who generally have limited knowledge of the running application code. In the event of an incident in the live production environment, it is critically important to be able to detect, identify, understand, and solve the problem as quickly as possible. To do this effectively, the application code needs to provide diagnostic information about its execution state at all times. This can be accomplished in a variety of different ways, including but not limited to simple logging, writing to the system event logs, or building a custom service that aggregates instrumentation data from the running application. Once diagnostic information is available from the application code, real-time monitoring and alerting systems can then be integrated with the application.
Run-time instrumentation data from an application is quite powerful information for many reasons. As suggested, it can be used for real-time monitoring and alerting, but it can also be used for other analysis purposes such as issue tracking or trending, or just understanding overall system health metrics. The most important thing is that application developers instrument the code to enable this type of data collection and provide documentation to the service engineers that illustrates recovery steps for the instrumented error detection. This not only requires a commitment to write the instrumentation code but also the upfront analysis to determine what needs to be monitored, tracked, and reported downstream. Ideally, application developers should instrument and capture as much data as possible and choose which data points should be monitored in real time versus getting archived directly. A typical example of an approach such as this might result in instrumentation data flowing into two different endpoints, where one endpoint is a real-time monitoring system and the other a data warehouse of instrumentation data. This approach is illustrated in 5-5.
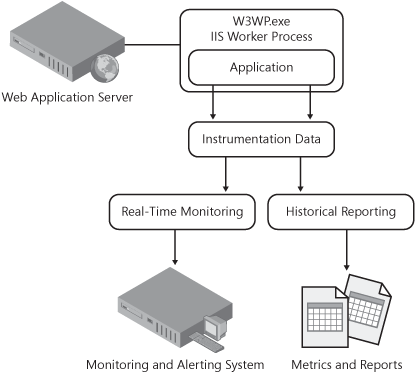
During design, application developers should ensure that their designs account for an approach to instrumentation and monitoring that will provide operational data that can be used for diagnostics, troubleshooting, or just understanding the run-time behavior of the application. As previously mentioned, this can be accomplished in a variety of ways, including simple logging to a file, adding performance counters, or writing to the event viewer. The selection of an instrumentation methodology is going to vary from application to application, but the important thing is to choose a mechanism that will scale well with the application. For example, as the scope of features increases, adding and maintaining a large number of performance counters might be too challenging, and simple logs might be a better choice. Regardless of the chosen implementation, the main goal should be to instrument as much of the application as possible so that run-time behavior can be better understood and diagnosed. These investments in instrumentation also allow operational tools and infrastructure to be integrated with the application to further enable real-time monitoring and historical reporting.
Once the application is properly instrumented, the obvious next step is to apply the appropriate level of health monitoring to the live application. There are various ways to accomplish this with both Microsoft and third-party tooling, but the most important thing is that application development teams invest in getting the appropriate tools in place prior to releasing the application. This work goes hand in hand with the instrumentation effort discussed in the previous section, and it is important to understanding the end-to-end run-time health of the application. Leveraging the tools and infrastructure available from Microsoft is a great way to pursue a health monitoring strategy. Management applications such as Microsoft System Center Operations Manager (SCOM) are available out of the box with a variety of ways to hook into an application’s instrumentation solution and conduct real-time monitoring. There will inevitably be effort expended on tuning the overall monitoring solution, but generally this is something that can be fine tuned over time. As mentioned, the key is to ensure that a solution is prioritized and implemented prior to the application being launched.
As the application gets designed to scale out to the projected user load, it is important that application developers work with their Program Management, Operations, and Test counterparts to establish the metrics and goals for the health of the running product. Establishing metrics and goals adds a level of accountability for the quality of the product that helps to ensure that the application always performs and operates as expected. Oftentimes these metrics are drivers for much of the data getting collected through the instrumentation mechanism that was previously discussed. Typically, metrics such as site availability and reliability are used to indicate what percentage of time the users of the application experience problems. This is generally expressed in terms of a percentage of transactions that result in a positive outcome, with most major services on the Internet setting their goals above 99.9 percent.
A big part of managing a live Web application is knowing when to expand the infrastructure to accommodate user load, as well as what to do when everything comes crashing down in failure. While this description represents a dichotomy of run-time circumstances, it does represent the reality of Web application manageability. Application developers and their stakeholder counterparts in Program Management, Operations, and Test should work together to establish the process for addressing both scenarios.
Under the best possible circumstances, applications will remain healthy and user load will increase steadily. Success for your application will be assured, provided that it can keep up with the demand your users place upon it. Conversely, if your application infrastructure cannot keep up with user demand, users of the application are not likely to be satisfied with their experience and will take their business elsewhere. It is important to understand when your application needs more capacity so that infrastructure can be made available to accommodate it. Typically, this type of planning can be accomplished by analyzing the application run-time data that is collected using the instrumented code within the application. This data allows certain variables like ASP.NET requests per second, CPU consumption, or available memory to be analyzed and used to understand the resources being utilized by the application. With this information, application developers can predict when additional hardware might be required to meet the needs of the growing application.
In the event application health reaches a suboptimal state and users experience major failures across the service, a proper recovery plan must be executed to ensure a rapid and successful restoration of the application to a completely healthy state. Problems of this nature could range from minor to catastrophic, as we discussed earlier in this chapter. Minor failures might require a server reboot, while catastrophic failures may induce full failover to a separate data center. Failures are certainly unpredictable but can be planned for. Live site outages require very specific, tactical processes for achieving a smooth recovery. Without those processes, recovery could be chaotic and subsequently result in additional downtime. Typically, operational teams and their application development counterparts establish procedures for dealing with outages of a predefined severity level so that the recovery time can be minimized. These processes generally ensure a more coordinated and calculated recovery effort and ensure that roles, procedures, and responsibilities are very clearly defined. While it is not necessary that processes of this nature be established during the application design cycle, it is important that they get established prior to the application being deployed.