
9.1 Introduction
In a conventional audio production and transmission chain, the audio content is first produced for playback using a certain reproduction system (for example two-loudspeaker stereophony), and is subsequently encoded, transmitted or stored, and decoded. The specific order of production and encoding/decoding makes it very difficult to enable user interactivity to modify the ‘mix’ produced by, for example, a studio engineer.
There are however several applications that may benefit from user control in mixing and rendering parameters. For example, in a teleconferencing application, individual users may want to control the spatial position and the loudness of each individual talker. For radio and television broadcasts, users may want to enhance the level of a voice-over for maximum speech intelligibility. Younger people may want to make a ‘re-mix’ of a music track they recently acquired, with control of various instruments and vocals present in the mix.
Conventional ‘object-based’ audio systems require storage/transmission of the audio sources such that they can be mixed at the decoder side as desired. Also wave field synthesis systems are often driven with audio source signals. ISO/IEC MPEG-4 [139, 146, 230] addresses a general object-based coding scenario. It defines the scene description (= mixing parameters) and uses for each (‘natural’) source signal a separate mono audio coder. However, when a complex scene with many sources is to be coded the bitrate becomes high since the bitrate scales with the number of sources. An object-based audio system is illustrated in Figure 9.1. A number of audio source signals are coded and stored/transmitted. The receiver mixes the decoded audio source signals to generate stereo [28, 227], surround [150, 227], wavefield synthesis [16, 17, 264], or binaural signals [14, 26] based on mixing parameters.
It would be desirable to have an efficient coding paradigm for audio sources that will be mixed after decoding. However, from an information theoretic point of view, there is no additional coding gain when jointly coding independent sources compared with independently coding them. For example, given a number of independent instrument signals the best one can do with conventional wisdom is to apply to each instrument signal one coder (e.g. a perceptual audio coder such as AAC [137], AC-3 [88], ATRAC [258], MP3 [136], or PAC [243]).
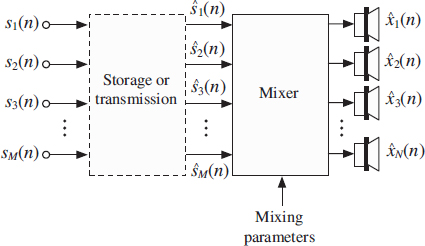
Figure 9.1 The general problem that is addressed–coding of a number of source signals for the purpose of mixing stereo, multi-channel, wavefield synthesis, or binaural audio signals with the decoded source signals.
The scheme outlined in this chapter provides means for joint coding in a more efficient manner than independent coding of individual source signals. Sources are joint-coded for the purpose of mixing after decoding. In this case, considering properties of the source signals, the mixing process, and knowledge on spatial perception it is possible to reduce the bitrate significantly. The source signals are represented as a single mono sum (down-mix) signal plus about 3 kb/s side information per source. Conventional coding would require about 10 × 80 = 800 kb/s for 10 sources, assuming a bit budget of 80 kb/s for each source. The described technique requires only about 80 + 10 × 3 = 110 kb/s and thus is significantly more efficient than conventional coding.
The scheme for joint-coding of audio source signals is illustrated in Figure 9.2. It is based on coding the sum of all audio source signals accompanied by additional parametric side information. This side information represents the statistical properties of the source signals which are the most important factors determining the perceptual spatial cues of the mixer output signals. These properties are temporally evolving spectral envelopes and autocorrelation functions. About 3 kb/s of side information is required per source signal. A conventional audio or speech coder is used to efficiently represent the sum signal.
At the receiving end, the source signals are recovered such that the before mentioned statistical properties approximate the corresponding properties of the original source signals. A stereo, surround, wavefield synthesis, or binaural mixer is applied after decoding of the source signals to generate the output signal.
Conceptually, the aim of the scheme is not to recover the clean source signals and it is not intended that one listens to these source signals separately prior to mixing. The goal is that the mixed output signal perceptually approximates the reference signal (i.e. the signal generated with the same mixer supplied with the original source signals).
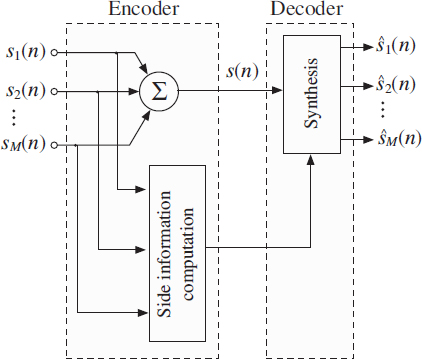
Figure 9.2 A number of source signals are stored or transmitted as sum signal plus side information. The side information represents statistical properties of the source signals. At the receiver the source signals are recovered.