
Data models are becoming an essential part of the App developer's toolkit. They help developers design and maintain the semantic knowledge of their data. Semantic knowledge can be described as the underlying knowledge of the meaning and assessment of the data that is being consumed. This knowledge is typically known only to subject matter experts, but it can be transferred to the end user in the form of data models. These data models can then be summarized and accelerated as needed with Splunk Enterprise. Data models are also the driving force behind the Pivot feature of Splunk Enterprise. They define how data is related and/or broken down. They are created using searches that are tiered into different sections. For example, your root event may be tag=web_logs (which says that you want all web logs, including IIS or Apache), and the second tier may be Errors, which will constrain the child search to only web log errors (for example, status = 500). This gives the end user the ability to choose the web log errors and then use Pivot to drill down to any remaining attributes (also known as fields).
A data model starts with one or more objects. Here is a quick list of facts about these objects that can be found at http://docs.splunk.com/Documentation/Splunk:
- An object is a specification for a dataset. Each data model object corresponds in some manner to a set of data in an index. You can apply data models to different indexes and get different datasets.
- Objects can be broken down into four types: event objects, search objects, transaction objects, and child objects.
- Objects are hierarchical. Objects in data models can be arranged hierarchically in parent-child relationships. The top-level event, search, and transaction objects in data models are collectively referred to as root objects.
- Child objects have inheritance. Data model objects are defined by characteristics that mostly break down into constraints and attributes. Child objects inherit constraints and attributes from their parent objects and have additional constraints and attributes of their own.
The first object defined in a data model is called the root object. There can be more than one root object, and each can be of a different type. The three types are event, transaction, and search. Let's take a quick look at each of them.
The first type of object is the root event. These objects are the most commonly used by developers. Each event object represents a type of event, very similar to the event type configurations in Splunk, as we saw in Chapter 3, Enhancing Applications. Root event objects are defined using simple constraints, which are basically the first part of a typical search, before any other search command.
The second type of object is the root transaction. These give the developer the ability to create transactions across a subset of data. A transaction is defined as a related group of events that cross time. Before you can create a root transaction object, you must have either an event or a search root object defined in the data model.
The last type of object is the root search. This object can be almost any Splunk search, including other commands. This gives you the ability to transform events and fields within the data model, which can then be further constrained by child objects.
Data models can be accelerated, making them perfect for use within an App for performance reasons. However, only root event objects can be accelerated. If you have a very large transforming search, you will most likely want to find the equivalent simple constraint search for use with acceleration.
Object constraints (used with each type of data model object) help filter events into a schema or dataset. A root event object will have a simple search as its constraint, which means that there are no transforming or streaming commands in the search string. A root search object uses the base search string and can include transformations within the string. A root transaction object is constrained by the transaction definition. These definitions must identify group objects and one or more group by fields. This is similar in configuration and usage to the transaction command used in the search bar.
Each object also has object attributes. These are essentially fields that have been extracted or presented in some way. There are five different types of attributes found at http://docs.splunk.com/Documentation/Splunk, which are as follows:
- Auto-extracted: This is a field that Splunk Enterprise derives at search time. You can add auto-extracted attributes to root objects only. Child objects can only inherit them, and they cannot add new auto-extracted attributes of their own. Auto-extracted attributes can be any of the following:
- Fields that Splunk Enterprise recognizes and extracts automatically, such as
uriorversion. This includes fields indexed through structured data inputs, such as fields extracted from the headers of indexed CSV files. - Field extractions, lookups, or calculated fields that you have defined in Settings or configured in
inprops.conf. - Fields that you have manually added to the attribute because they aren't currently in the object dataset, but should be in the future. This can include fields that are added to the object dataset by generating commands such as
inputcsvordbinspect.
- Fields that Splunk Enterprise recognizes and extracts automatically, such as
- Eval expression: This is a field derived from an eval expression that you enter in the attribute definition. Eval expressions often involve one or more extracted fields.
- Lookup: This is a field that is added to the events in the object dataset with the help of a lookup that you configure in the attribute definition. Lookups add fields from external data sources, such as CSV files and scripts. When you define a lookup attribute, you can use any lookup that you have defined in Settings and associate it with any other attribute that has already been associated with the same object.
- Regular expression: This attribute type represents a field that is extracted from the object event data using a regular expression that you provide in the attribute definition. A regular expression attribute definition can use a regular expression that extracts multiple fields. Each field will appear in the object attribute list as a separate regular expression attribute.
- Geo IP: This is a specific type of lookup that adds geographical attributes, such as latitude, longitude, country, and city, to events in the object dataset that have valid IP address fields. It is useful for map-related visualizations.
Attributes can be inherited, extracted, or calculated. Inherited attributes drop through different objects. Child attributes inherit attributes from the parent object, making it necessary for each parent to have the attributes required by each child. Extracted attributes are those that are auto-extracted from the search results. Finally, calculated attributes are configured through calculation or lookup within the data model.
Data models can be quite complex or they can be really simple. The extensibility of a data model gives you flexibility to define your data and present it to the end user as a structured schema based on unstructured data. You can create and manage data models on the management page, found in Data Models under Settings. Let's navigate there now, so we can create a simple one, just to get an idea of what's going on.
Once you are at the Data Models manager, click on Create New. This will load a quick form to enter your data model name, as shown in the following screenshot:
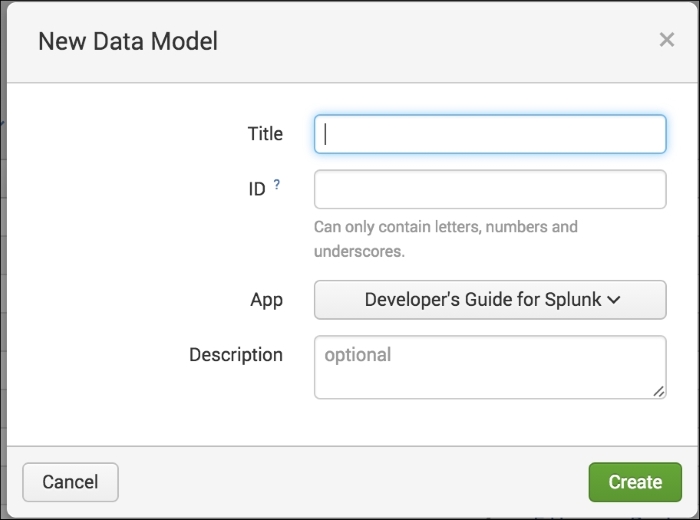
Once you have created the base data model, you need to add objects, as we discussed earlier in the chapter. You can do this by using the drop-down menu and then choosing your root item:
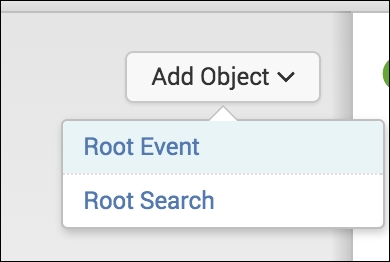
Then, it's as simple as filling in the items that are required and choosing the fields you want to add into that object:
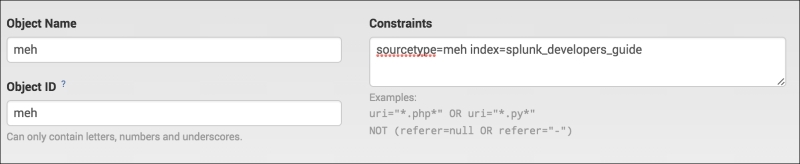
This will be the base of the data model. You can put literally any search here that you want to use as long as it is a base search only. Any other search commands cannot be placed here. Once you have your events, choose your fields!
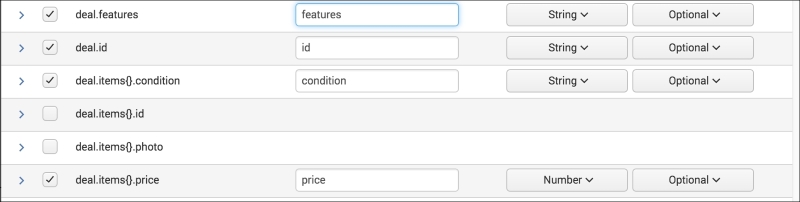
It's that simple! Once you have built the root objects, add the child objects. The child objects are just more searches that narrow down the scope of the data model. A child object may then look like this:
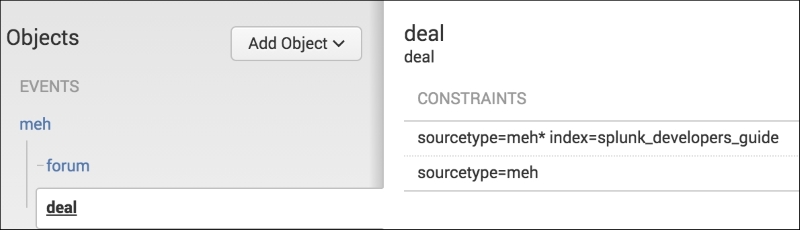
As you can see, data models can help you narrow down large datasets into more manageable chunks, which then can be used in searches. Accelerate a data model, and you've got a fast and easy way of referencing large datasets.