
2.1. Modern Disk Drives
The magnetic disk drive technology has benefited from more than two decades of research and development. It has evolved to provide a low latency (in the order of milliseconds) and a low cost per megabyte (MByte) of storage (a few cents per MByte at the time of this writing in 2003). It has become commonplace with annual sales in excess of 30 billion dollars [124]. Magnetic disk drives are commonly used for a wide variety of storage purposes in almost every computer system. To facilitate their integration and compatibility with a wide range of host hardware and operating systems, the interface that they present to the rest of the system is well defined and hides a lot of the complexities of the actual internal operation. For example, the popular SCSI (Small Computer System Interface, see [8], [43]) standard presents a magnetic disk drive to the host system as a linear vector of storage blocks (usually of 512 bytes each). When an application requests the retrieval of one or several blocks the data will be returned after some (usually short) time, but there is no explicit mechanism to inform the application exactly how long such an operation will take. In many circumstances such a "best effort" approach is reasonable because it simplifies program development by allowing the programmer to focus on the task at hand instead of the physical attributes of the disk drive. However, for a number of data intensive applications, such as SM servers, exact timing information is crucial to satisfy the real-time constraints imposed by the requirement for a hiccup-free delivery of audio and video streams. Fortunately, with a model that imitates the internal operation of a magnetic disk drive it is possible to predict service times at the level of accuracy that is needed to design and configure SM server storage systems.
2.1.1. Internal Operation
We will first give an overview of the internal operation of modern magnetic disk drives. Next, we will introduce a model that allows an estimation of the service time of a disk drive. This will build the basis for our introduction of techniques that provide SM services on top of disk storage systems.
A magnetic disk drive is a mechanical device, operated by its controlling electronics. The mechanical parts of the device consist of a stack of platters that rotate in unison on a central spindle (see [139] for details). Presently, a single disk contains one, two, or as many as fourteen platters [2] (see Figure 2.1 for a schematic illustration). Each platter surface has an associated disk head responsible for reading and writing data. The minimum storage unit on a surface is a sector (which commonly holds 512 bytes of user data). The sectors are arranged in multiple, concentric circles termed tracks. A single stack of tracks across all the surfaces at a common distance from the spindle is termed a cylinder. To access the data stored in a series of sectors, the disk head must first be positioned over the correct track. The operation to reposition the head from the current track to the target track is termed a seek. Next, the disk must wait for the desired data to rotate under the head. This time is termed rotational latency.
[2] This is the case, for example, for the Elite series from Seagate Technology™, LLC.
Figure 2.1. Disk drive internals.

In their quest to improve performance, disk manufacturers have introduced the following state-of-the-art designs features into their most recent products:
Zone-bit recording (ZBR). To meet the demands for a higher storage capacity, more data is recorded on the outer tracks than on the inner ones (tracks are physically longer towards the outside of a platter). Adjacent tracks with the same data capacity are grouped into zones. The tighter packing allows more storage space per platter compared with a uniform amount of data per track [173]. Moreover, it increases the data transfer rate in the outer zones (see the sector ratio in Table 2.1). Section 2.5 details how multi-zoning can be incorporated in SM server designs.
Table 2.1. Parameters for four commercial disk drives. Each drive was considered high performance when it was first introduced. Model Series Manufacturer ST3120OWD Hawk 1LP ST32171WD Barracuda 4LP ST34501WD Cheetah 4LP ST336752LC Cheetah X15 Seagate TechnologyTM, LLC Capacity C 1.006 GByte 2.061 GByte 4.339 GByte 34.183 GByte Avg. transfer rate RD 3.47 MB/s 7.96 MB/s 12.97 MB/s 49.28 MB/s Spindle speed 5,400 rpm 7,200 rpm 10,033 rpm 15,000 rpm Avg. rotational latency 5.56 msec 4.17 msec 2.99 msec 2.0 msec Worst case seek time 21 msec 19 msec 16 msec 6.9 msec Surfaces 9 5 8 8 Cylinders #cyl 2,697 5,177 6,582 18,479 Number of Zones Z 23 11 7 9 Sector size 512 bytes 512 bytes 512 bytes 512 bytes Sectors per Track ST 59 - 106 119 - 186 131 - 195 485 (avg.) Sector ratio 

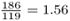

Introduction year 1990 1993 1996 2000 Statistical analysis of the signals arriving from the read/write heads, referred to as partial-response maximum-likelihood (PRML) method [81], [177], [51]. This digital signal processing technique allows higher recording densities because it can filter and regenerate packed binary signals better than the traditional peak-detection method. For example, the switch to PRML in Quantum Corporation's Empire product series allowed the manufacturer to increase the per-disk capacity from 270 MBytes to 350 MBytes [51].
High spindle speeds. Currently, the most common spindle speeds are 5,400 and 7,200 rpm. However, high performance disks use 10,000 and 15,000 rpm (see Table 2.1). All other parameters being equal, this results in a data transfer rate increase of 39%, or 108% respectively, over a standard 7,200 rpm disk.
Some manufacturers also redesigned disk internal algorithms to provide uninterrupted data transfer (e.g., to avoid lengthy thermal recalibrations) specifically for SM applications. Many of these technological improvements have been introduced gradually with new disk generations entering the marketplace every year. To date (i.e., in 2003) disk drives of many different performance levels with capacities ranging from 20 up to 200 gigabytes are commonly available[3].
[3] The highest capacity disk drives currently available with 200 GByte of storage space are the WD Caviar 200 GB models from Western Digital Corporation.
The next section details disk modelling techniques to identify the physical characteristics of a magnetic disk in order to estimate its service time. These estimates have been applied to develop and implement Yima, a scalable SM server [160] presented as a case study in Chapter 10. Our techniques employ no proprietary information and are quite successful in developing a methodology to estimate the service time of a disk.
2.1.2. Disk Drive Modelling
Disk drive simulation models can be extremely helpful to investigate performance enhancements or tradeoffs in storage subsystems. Hence, a number of techniques to estimate disk service times have been proposed in the literature [178], [17], [139], [181], [75]. These studies differ in the level of detail that they incorporate into their models. The level of detail should depend largely on the desired accuracy of the results. More detailed models are generally more accurate, but they require more implementation effort and more computational power [55]. Simple models may assume a fixed time for I/O, or they may select times from a uniform distribution. However, to yield realistic results in simulations that imitate real-time behavior, more precise models are necessary. The most detailed models include all the mechanical positioning delays (seeks, rotational latency), as well as on-board disk block caching, I/O bus arbitration, controller overhead, and defect management. In the next few paragraphs we will outline our model and which aspects we chose to include.
On-Board Cache
Originally, the small buffers of on-board memory implemented with the device electronics were used for speed-matching purposes between the media data rate and the (usually faster) I/O bus data transfer rate. They have more recently progressed into dynamically managed, multi-megabyte caches that can significantly affect performance for traditional I/O workloads [139]. In the context of SM servers, however, data is retrieved mostly in sequential order and the chance of a block being re-requested within a short period of time is very low. Most current disk drives also implement aggressive read-ahead algorithms which continue to read data into the cache once the read/write head reaches the final position of an earlier transfer request. It is the assumption that an application has a high chance of requesting these data in the cache because of spatial locality. Such a strategy works very well in a single-user environment, but has a diminishing effect in a multiprogramming context because disk requests from multiple applications may be interleaved and thus requests may be spatially disbursed[4]. In a SM server environment, a single disk may serve dozens of requests in a time period on behalf of different streams with each request being rather large in size. It has been our observation that disk caches today are still not large enough to provide any benefits under these circumstances. Hence, our model does not incorporate caching strategies.
[4] This problem can be alleviated to some extent with the implementation of segmented caches.
Data Layout
To make a disk drive self-contained and present a clean interface to the rest of the system, its storage is usually presented to the host system as an addressable vector of data blocks (see Section 2.1). The logical block number (LBN) of each vector element must internally be mapped to a physical media location (i.e., sector, cylinder, and surface). Commonly, the assignment of logical numbers starts at the outermost cylinder, covering it completely before moving on to the next cylinder. This process is repeated until the whole storage area has been mapped.
This LBN-to-PBN mapping is non-contiguous in most disk drives because of techniques used to improve performance and failure resilience. For example, some media data blocks may be excluded from the mapping to store internal data needed by the disk's firmware. For defect management some tracks or cylinders in regular intervals across the storage area may be skipped initially by the mapping process to allow the disk firmware later to relocate sectors that became damaged during normal operation to previously unused areas.
As a result, additional seeks may be introduced when a series of logically contiguous blocks are retrieved by an application. It is possible to account for these anomalies when scheduling data retrievals, because most modern disk drives can be queried as to their exact LBN-to-PBN function. The effects of using accurate and complex mapping information versus a simple, linear approximation have been investigated and quantified in [180]. This study reports possible marginal improvements of less than 2% in combination with seek-reducing scheduling algorithms.
Scheduling Algorithms
Scheduling algorithms that attempt to reduce mechanical positioning delays can drastically improve the performance of magnetic disk drives. Figure 2.2 shows the seek and rotational latency overhead incurred by three different disk drive types when retrieving a data block that requires the read/write heads to move across half of the total number of cylinders. As illustrated, the overhead may waste a large portion of a disk's potential bandwidth. Furthermore, it is interesting to note that newer disk models spend a proportionally larger amount of time on wasteful operations (e.g., the Cheetah 4LP model is newer than the Barracuda 4LP, which in turn is newer than the Hawk 1LP). The reasons can be found in the technological trends which indicate that the media data rate is improving at a rate of approximately 40% per year while the mechanical positioning delays lag with an annual decrease of only 5%. Hence, seek-reducing algorithms are essential in conjunction with modern, high-performance disk drives.
Figure 2.2. Mechanical positioning overhead as a function of the retrieval block size for three disk drive models. The overhead includes the seek time for the disk heads to traverse over half of the total number of cylinders plus the average rotational latency, i.e.,  (for details see Equation 2.2 and Table 2.2). The technological trends are such that the data transfer rate is improving faster than the delays due to mechanical positioning are reduced. Hence the wasteful overhead is increasing, relatively speaking, and seek-reducing scheduling algorithms are becoming more important.
(for details see Equation 2.2 and Table 2.2). The technological trends are such that the data transfer rate is improving faster than the delays due to mechanical positioning are reduced. Hence the wasteful overhead is increasing, relatively speaking, and seek-reducing scheduling algorithms are becoming more important.

| Metric | Disk Model | |||
|---|---|---|---|---|
| Hawk 1LP ST3120OWD | Barracuda 4LP ST32171WD | Cheetah 4LP ST34501WD | Cheetah X15 ST336752LC | |
| Seek constant c1 [msec] | 3.5 + 5.56[a] | 3.0 + 4.17[a] | 1.5 + 2.99[a] | 1.5 + 2.0[a] |
| Seek constant c2 [msec] | 0.303068 | 0.232702 | 0.155134 | 0.029411 |
| Seek constant c3 [msec] | 7.2535 + 5.56[a] | 7.2814 + 4.17[a] | 4.2458 + 2.99[a] | 2.4 + 2.0[a] |
| Seek constant c4 [msec] | 0.004986 | 0.002364 | 0.001740 | 0.000244 |
| Switch-over point z | 300 cyl. | 600 cyl. | 600 cyl. | 924 cyl. |
| Total size #cyl | 2,697 cyl. | 5,177 cyl. | 6,578 cyl. | 18,479 cyl. |
[a] Average rotational latency based on the spindle speed: 5,400 rpm, 7,200 rpm, 10,033 rpm, and 15,000 rpm respectively.
More than 30 years of research have passed since Denning first analyzed the Shortest Seek Time First (SSTF) and the SCAN or elevator[5] policies [44], [138]. Several variations of these algorithms have been proposed in the literature, among them Cyclical SCAN (C-SCAN) [151], LOOK [113], and C-LOOK [180] (a combination of C-SCAN and LOOK). Specifically designed with SM applications in mind was the Grouped Sweeping Scheme (GSS) [183].
[5] This algorithm first serves requests in one direction across all the cylinders and then reverses itself.
There are various tradeoffs associated with choosing a disk scheduling algorithm. For SM retrieval it is especially important that a scheduling algorithm is fair and starvation-free so that real-time deadlines can be guaranteed. A simplistic approach to guarantee a hiccup-free continuous display would be to assume the worst case seek time for each disk type, i.e., setting the seek distance d equal to the total number of cylinders, d = #cyl. However, if multiple displays (N) are supported simultaneously, then N fragments need to be retrieved from each disk during a time period. In the worst case scenario, the N requests might be evenly scattered across the disk surface. By ordering the fragments according to their location on the disk surface (i.e., employing the SCAN algorithm), an optimized seek distance of ![]() can be obtained, reducing both the seek and the service time. This scheduling technique was employed in all our analytical models and simulation experiments.
can be obtained, reducing both the seek and the service time. This scheduling technique was employed in all our analytical models and simulation experiments.
Bus Interface
We base our observations on the SCSI I/O bus because it is most commonly available on today's high performance disk drives. The SCSI standard is both a bus specification and a command set to efficiently use that bus (see [8], [43]). The host adapter (also called initiator) provides a bridge between the system bus (based on any standard or proprietary bus; e.g., PCI[6]) and the SCSI I/O bus. The individual storage devices (also called targets in SCSI terminology) are directly attached to the SCSI bus and share its resources.
[6] Peripheral Component Interconnect, a local bus specification developed for 32-bit or 64-bit computer system interfacing.
There is overhead associated with the operation of the SCSI bus. For example, the embedded controller on a disk drive must interpret each received SCSI command, decode it, and initiate its execution through the electronics and mechanical components of the drive. This controller overhead is usually less than 1 millisecond for high performance drives ([139] cite 0.3 to 1.0 msec, [181] measured an average of 0.7 msec, and [121] reports 0.5 msec for a cache miss and 0.1 msec with a cache hit). As we will see in the forthcoming sections, SM retrieval requires large block retrievals to reduce the wasted disk bandwidth. Hence, we consider the controller overhead negligible (less than 1% of the total service time) and do not include it in our model.
The issue of the limited bus bandwidth should be considered as well. The SCSI I/O bus supports a peak transfer rate of 10, 20, 40, 80, 160, or 320 MB/s depending on the SCSI version implemented on both the controller and all the disk devices. Current variations of SCSI are termed Fast, Fast&Wide, Ultra, Ultra&Wide, Ultra2&Wide, Ultra160, or Ultra320 respectively. If the aggregate bandwidth of all the disk drives attached to a SCSI bus exceeds its peak transfer rate, then bus contention occurs and the service time for the disks with lower priorities[7] will increase. This situation may arise with today's high performance disk drives. For example, SCSI buses that implement the wide option (i.e., 16-bit parallel data transfers) allow up to 15 individual devices per bus, which together can transfer data in excess of 600 MB/s. Furthermore, if multiple disks want to send data over this shared bus, arbitration takes place by the host bus adapter to decide which request has higher priority. In an earlier study we investigated these scalability issues and concluded that bus contention has a negligible effect on the service time if the aggregate bandwidth of all attached devices is less than approximately 75% of the bus bandwidth (see Figure 2.3 [75]). We assume that this rule is observed to accomplish a balanced design.
[7] Every SCSI device has a fixed priority that directly corresponds to its SCSI ID. This number ranges from 0 to 7 for narrow (8-bit) SCSI. The host bus adapter is usually assigned ID number 7 because this corresponds to the highest priority. The wide SCSI specification was introduced after the narrow version. Consequently, the priorities in terms of SCSI IDs are 7 … 0, 15 … 8, with 7 being the highest and 8 the lowest.
Figure 2.3. Example SCSI bus scalability with a Fast&Wide bus that can sustain a maximum transfer rate of 20 megabytes per second (MB/s). The graphs show read requests issued to both the innermost and outermost zones for varying numbers of disks. The bandwidth scales linearly up to about 15 MB/s (75%) and then starts to flatten out as the bus becomes a bottleneck.

Mechanical Positioning Delays and Data Transfer Time
The disk service time (denoted TService) is composed of the data transfer time (desirable) and the mechanical positioning delays (undesirable), as introduced earlier in this chapter. For notational simplicity in our model, we will subsume all undesirable overhead into the expression for the seek time (denoted TSeek). Hence, the composition of the service time is as follows:
Equation 2.1
![]()
The transfer time (TTransfer) is a function of the amount of data retrieved and the data transfer rate of the disk: ![]() . The seek time (TSeek) is a non-linear function of the number of cylinders traversed by the disk heads to locate the proper data sectors. A common approach (see [139], [181], [75], [121]) to model such a seek profile is a first-order-of-approximation with a combination of a square-root and linear function as follows:
. The seek time (TSeek) is a non-linear function of the number of cylinders traversed by the disk heads to locate the proper data sectors. A common approach (see [139], [181], [75], [121]) to model such a seek profile is a first-order-of-approximation with a combination of a square-root and linear function as follows:
Equation 2.2
![]()
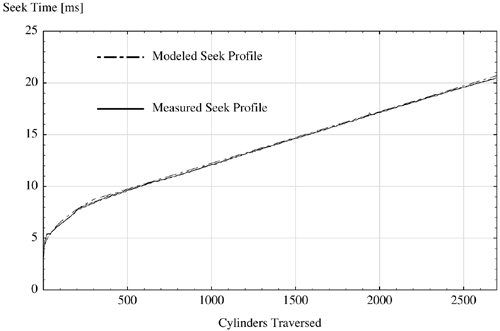
where d is the seek distance in cylinders. In addition, the disk heads need to wait on average half a platter rotation—once they have reached the correct cylinder—for the data to move underneath the heads. Recall that this time is termed rotational latency and we include it in our model of TSeek (see c1 and c3 in Table 2.2). Every disk type has its own distinct seek profile. Figure 2.4 illustrates the measured and modelled seek profile for a Seagate ST31200WD disk drive (shown without adding the rotational latency) and Table 2.2 lists the corresponding constants used in Equation 2.2. These empirical results have been obtained with the embedded differential Fast&Wide SCSI I/O interface of an HP 9000 735/125 workstation.
Figure 2.5. Sample code fragment to send the SCSI command INQUIRY to the controller electronics of a SCSI device under Linux. The code utilizes the Linux SCSI Generic (sg) driver. More information is available online at http://gear.torque.net/sg/.
Figure 2.4. Example measured and modelled seek profile for a disk type ST31200WD.
2.1.3. Low-Level SCSI Programming Interface
Information about disk characteristics such as the seek profile or the detailed zone layout is not generally available. Hence, it is necessary to device methods to measure these parameters. The SCSI standard specifies many useful commands that allow device interrogation. However, SCSI devices are normally controlled by a device driver, which shields the application programmer from all the low-level device details and protects the system from faulty programs. In many operating systems, for example Linux and Windows NT™, it is possible to explicitly send SCSI commands to a device through specialized system calls. Great care must be taken when issuing such commands because the usual error detection mechanisms are bypassed.
The format to initiate a SCSI command is operating system dependent. For example, Linux utilizes variations of the ioctl(), read() and write() system calls while Windows NT provides the advanced SCSI programming interface (ASPI)[8]. The syntax and semantics of the actual SCSI commands are defined in the SCSI standard document [8]. Three types of SCSI commands can be distinguished according to their command length: 6, 10, and 12 bytes. The first byte of each command is called operation code and uniquely identifies the SCSI function. The rest of the bytes are used to pass parameters. The standard also allows vendor-specific extensions for some of the commands, which are usually described in the vendor's technical manuals of the device in question.
[8] ASPI was defined by Seagate Technology, LLC.
Figure 2.5 shows a sample code fragment that illustrates how a SCSI command is sent to a device under Linux. In the example, the SCSI command INQUIRY is transmitted to the device to obtain vendor and product information. The shown SCSI command is 6 bytes in length and its command code is 0x12. Each SCSI command has its own input and output data format that is described in the SCSI standard document [8]. SCSI commands to read and write data exist together with a host of other functions. For example, to translate a linear logical block address into its corresponding physical location of the form ‐head/cylinder/sector‐ one may use the SEND DIAGNOSTICS command to pass the translate request to the device (the translate request is identified through the XLATE-PAGE code in the parameter structure). By translating a range of addresses of a magnetic disk drive, track and cylinder sizes as well as zone boundaries can be identified.