
5.2. Non-Partitioning Techniques
Non-partitioning techniques place data over all the disk drives present in a heterogeneous, multi-node storage system [174], [27], [188]. Therefore, they are generally not affected by changing access patterns. A number of techniques exist and they differ in how they place data and schedule disk bandwidth. In its simplest form, such a technique is based on the bandwidth ratio of the different devices leading to the concept of virtual disks. A variation of the technique considers capacity constraints as well. These decisions impact how much of the available disk bandwidth and storage space can be utilized, and how much memory is required to support a fixed number of simultaneous displays.
We first assume a disk platter that is location independent, with a constant average transfer rate for each disk model, even though most modern disks are multi-zone drives that provide a different transfer rate for each zone. Section 5.3 describes one technique by which this simplifying assumption can be eliminated.
5.2.1. Optimization Criterion: Bandwidth, Space, or Both
The two most important parameters of disk drives for SM storage applications are their bandwidth and storage space. If a storage array is homogeneous, then a data placement technique such as round-robin or random will result in an equal amount of data on each disk drive. Consequently, each disk drive will be accessed equally frequently during data retrievals. As a result, load balancing is achieved for both storage space and disk bandwidth.
If a storage system is heterogeneous, load balancing is not guaranteed any longer. Consider a simple example of two disk drives. Assume that disk 2 has fs-times more storage space and fb-times more bandwidth than disk 1. If we are lucky and fs = fb = f then we can adjust our data placement technique to place f-times more data on disk 2 compared with disk 1. This will result in an equal utilization of space and bandwidth on both disks. However, most of the time fs ≠ fb (among commercial disk generations storage space tends to increase faster than disk bandwidth). Therefore, the algorithm designer is now faced with a choice: should she aim for balanced space or bandwidth utilization? If a configuration fully utilizes the disk bandwidth some storage space may be unused, or conversely, if all of the space is allocated then some bandwidth may be idle. The techniques described in the next few sections will address this question in different ways.
One might wonder if there is a way to fully utilize all the disk space and all the disk bandwidth. The only possible solution is to consider a third parameter when designing the data placement algorithm: the access frequency to each stored object. Since generally some objects are more popular than others, the amount of bandwidth that they require per stored data byte is also different. This factor can be used to optimize both the disk space and retrieval bandwidth at the same time.
However, there are several disadvantages to such an approach. Objects can no longer be declustered across the complete disk array; they must be stored on a subset of the available disks. Therefore, load balancing can only be guaranteed if the access pattern to all objects does not significantly change over time. Any such change will result in hotspots on some disks and underutilization of others. This unpredictability may result in a worse overall bandwidth utilization than a technique that does not consider the object access frequency, and hence will waste a fixed portion of the overall bandwidth.
5.2.2. Bandwidth-to-Space-Ratio (BSR) Media Placement
As mentioned in the previous section, one way to fully utilize the bandwidth and space of all devices in a heterogeneous storage system is to consider the access frequency as well. One such technique considers the Bandwidth-to-Space-Ratio (BSR) of the disks plus the expected bandwidth of every object (based on its access frequency) [35]. The BSR policy may or may not utilize striping. In its simplest case it places each object completely on a single device. As a result, it may create several replicas of an object on different disks to meet the client demands.
The BSR technique works as follows. First it computes the bandwidth to space ratio of all the storage devices. Second, it computes the expected load of every video object. The expected load is based on the popularity of the object, i.e., how often it will be accessed. The policy then decides how many replicas of each object need to be created and on which devices these copies must be placed. The BSR policy is an online policy, hence it will periodically re-compute both the number of replicas and their placement. As a result of this step additional replicas may be created or existing ones deleted.
Recall that the performance of a technique such as BSR depends on how quickly access frequency changes can be detected and remedied. If such changes are infrequent then very good performance can be achieved. With frequently changing loads, however, hotspots and bottlenecks may develop and the creation and movement of replicas will waste part of the available bandwidth.
5.2.3. Grouping Techniques
Grouping techniques combine physical disks into logical ones and assume a uniform characteristic for all logical disks. To illustrate, the six physical disks of Figure 5.1 are grouped to construct two homogeneous logical disks. In this figure, a larger physical disk denotes a newer disk model that provides both a higher storage capacity and a higher performance[1]. The blocks of a movie X are assigned to the logical disks in a round-robin manner to distribute the load of a display evenly across the available resources [142], [12], [126], [52]. A logical block is declustered across the participating physical disks [71]. Each piece is termed a fragment (e.g., X0.0 in Figure 5.1). The size of each fragment is determined such that the service time (TService) of all physical disks is identical (for an example see Figure 5.2).
[1] While this conceptualization might appear reasonable at first glance, it is in contradiction with the current trend in the physical dimensions of disks that calls for a comparable volume when the same form factor is used (e.g., 3.5" platters). For example, the ST31200WD holding 1 GByte of data has approximately the same physical dimensions as compared with the ST34501WD holding 4 GBytes.
Figure 5.1. Disk Grouping.

Figure 5.2. Mechanical positioning overhead (seek and rotational delay) when retrieving blocks from three different disk models. (The block sizes correspond to the configuration shown in Table 5.1.) The retrieval block sizes have been adjusted to equalize the overall service time. Note that at first the Cheetah 4LP model seems to have the lowest overhead. However, this is only the case because of its large block size. For small block sizes the Cheetah wastes a higher percentage of its bandwidth. This trend is common for newer disk models.

| Disk Model (Seagate) | Fragment Size [KByte] | Fragment display time [sec] | Number of Fragments | % Space for traditional data |
|---|---|---|---|---|
| ND = 48, Dl = 2, N = 96 | ||||
| ST34501WD | B2 = 687.4 | 1.534 | 6,463 | 17.4% |
| ST32171WD | B1 = 395.4 | 0.883 | 5,338 | 0% |
| ST31200WD | B0 = 166.0 | 0.371 | 6,206 | 14.0% |
With a fixed storage capacity and pre-specified fragment sizes for each physical disk, one can compute the number of fragments that can be assigned to a physical disk. The storage capacity of a logical disk (number of logical blocks it can store) is constrained by the physical disk that can store the fewest fragments. For example, to support 96 simultaneous displays of MPEG-2 streams (Rc = 3.5 Mb/s), the fragment sizes[2] of Table 5.1 enable each logical disk to store only 5,338 blocks. The remaining space of the other two physical disks (ST34501WD and ST31200WD) can be used to store traditional data types, e.g., text, records, etc. During off-peak times, the idle bandwidth of these disks can be employed to service requests that reference this data type.
[2] Fragment sizes are approximately proportional to the disk transfer rates, i.e., the smallest fragment is assigned to the disk with the slowest transfer rate. However, different seek overheads may result in significant variations (see Figure 5.2).
When the system retrieves a logical block into memory on behalf of a client, all physical disks are activated simultaneously to stage their fragments into memory. This block is then transmitted to the client.
To guarantee a hiccup-free display, the display time of a logical block must be equivalent to the duration of a time period:
Equation 5.1
![]()
Moreover, if a logical disk services ND simultaneous displays then the duration of each time period must be greater or equal to the service time to read ND fragments from every physical disk i (![]() ) that is part of the logical disk.
) that is part of the logical disk.
Thus, the following constraint must be satisfied:
Equation 5.2

Substituting TP with its definition from Equation 5.1 plus the additional constraint that the time period must be equal for all physical disk drives (K) that constitute a logical disk, we obtain the following system of equations (note: we use ![]() as an abbreviated notation for
as an abbreviated notation for ![]() ):
):
Equation 5.3

Solving Equation Array 5.3 yields the individual fragment sizes Bi for each physical disk type i:
Equation 5.4

with

Figure 5.2 illustrates how each fragment size Bi computed with Equation 5.4 accounts for the difference in seek times and data transfer rates to obtain identical service times for all disk models.
To support ND displays with one logical disk, the system requires 2 × ND memory buffers. Each display necessitates two buffers for the following reason: One buffer contains the block whose data is being displayed (it was staged in memory during the previous time period), while a second is employed by the read command that is retrieving the subsequent logical block into memory[3]. The system toggles between these two frames as a function of time until a display completes. As one increases the number of logical disks (Dl), the total number of displays supported by the system (N = Dl × ND) increases, resulting in a higher amount of required memory by the system:
[3] With off-the-shelf disk drives and device drivers, a disk read command requires the address of a memory frame to store the referenced block. The amount of required memory can be reduced by employing specialized device drivers that allocate and free memory on demand [120].
Equation 5.5
![]()
In the presence of N − 1 active displays, we can compute the maximum latency that a new request might observe. In the worst case scenario, a new request might arrive referencing a clip X whose first fragment resides on logical disk 0 (![]() ) and miss the opportunity to utilize the time period with sufficient bandwidth to service this request. Due to a round-robin placement of data and activation of logical disks, this request must wait for Dl time periods before it can retrieve x0. Thus, the maximum latency
) and miss the opportunity to utilize the time period with sufficient bandwidth to service this request. Due to a round-robin placement of data and activation of logical disks, this request must wait for Dl time periods before it can retrieve x0. Thus, the maximum latency ![]() is:
is:
Equation 5.6

These equations quantify the resource requirement of a system with this technique.
Staggered Grouping
Staggered Grouping is an extension of the grouping technique of the previous section. It minimizes the amount of memory required to support ND simultaneous displays based on the following observation: Not all fragments of a logical block are needed at the same time. Assuming that each fragment is a contiguous chunk of a logical block, fragment X0.0 is required first, followed by X0.1 and X0.2 during a single time period. Staggered Grouping orders the physical disks that constitute a logical disk based on their transfer rate and assumes that the first portion of a block is assigned to the fastest disk, second portion to the second fastest disk, etc. The explanation for this constrained placement is detailed in the next paragraph. Next, it staggers the retrieval of each fragment as a function of time. Once a physical disk is activated, it retrieves ND fragments of blocks referenced by the ND active displays that require these fragments (Figure 5.3). The duration of this time is termed a sub-period (![]() ) and is identical in length for all physical disks. Due to the staggered retrieval of the fragments, the display of an object X can start at the end of the first sub-period (as opposed to the end of a time period as is the case for Disk Grouping).
) and is identical in length for all physical disks. Due to the staggered retrieval of the fragments, the display of an object X can start at the end of the first sub-period (as opposed to the end of a time period as is the case for Disk Grouping).

The ordered assignment and activation of the fastest disk first is to guarantee a hiccup-free display. In particular, for slower disks, the duration of a sub-period might exceed the display time of the fragment retrieved from those disks. Fragment sizes are approximately proportional to a disk's bandwidth and consequently slower disks are assigned smaller fragments. As an example, with the parameters of Table 5.1, each sub-period is 0.929 seconds long (a time period is 2.787 seconds long) with each disk retrieving 16 fragments: the two logical disks read 48 blocks each to support N = 96 displays, hence, 16 fragments are retrieved during each of the three sub-periods. The third column of this table shows the display time of each fragment. More data is retrieved from the Seagate ST34501WD (with a display time of 1.534 seconds) to compensate for the bandwidth of the slower ST31200WD disk (with a display time of 0.371 seconds). If the first portion of block X (X0.0) is assigned to the ST31200WD then the client referencing X might suffer from a display hiccup after 0.371 seconds because the second fragment is not available until 0.929 seconds (one sub-period) later. By assigning the first portion to the fastest disk (Seagate ST34501WD), the system prevents the possibility of hiccups. Recall that an amount of data equal to a logical block is consumed during a time period.
The amount of memory required by the system is a linear function of the peak memory (denoted ![]() ) required by a display during a time period, ND and Dl, i.e., M = ND × Dl ×
) required by a display during a time period, ND and Dl, i.e., M = ND × Dl × ![]() . For a display, the peak memory can be determined using the simple dynamic computation of Figure 5.4. This figure computes the maximum of two possible peaks: one that corresponds to when a display is first started (labeled (1) in Figure 5.5) and a second that is reached while a display is in progress (labeled (2) in Figure 5.5). Consider each in turn. When a retrieval is first initiated, its memory requirement is the sum of the first and second fragment of a block, because the display of the first fragment is started at the end of the first sub-period (and the block for the next fragment must be allocated in order to issue the disk read for B1). For an in-progress display, during each time period that consists of K sub-periods, the display is one sub-period behind the retrieval. Thus, at the end of each time period, one sub-period worth of data remains in memory (the variable termed Consumed in Figure 5.4). At the beginning of the next time period, the fragment size of b0 is added to the memory requirement because this much memory must be allocated to activate the disk. Next, from the combined value, the amount of data displayed during a sub-period is subtracted and the size of the next fragment is added, i.e., the amount of memory required to read this fragment. This process is repeated for all sub-periods that constitute a time period. Figure 5.5 illustrates the resulting memory demand as a function of time. Either of the two peaks could be highest depending on the characteristics and the number of physical disks involved. In the example of Figure 5.3 (and with the fragment sizes of Table 5.1), the peak amount of required memory is 1,103.7 KBytes, which is reached at the beginning of each time period (peak (2) in Figure 5.5). This compares favorably with the two logical blocks (2.44 MBytes) per display required by Disk Grouping. If no additional optimization is employed then the maximum value of either peak (1) or (2) specifies the memory requirement of a display.
. For a display, the peak memory can be determined using the simple dynamic computation of Figure 5.4. This figure computes the maximum of two possible peaks: one that corresponds to when a display is first started (labeled (1) in Figure 5.5) and a second that is reached while a display is in progress (labeled (2) in Figure 5.5). Consider each in turn. When a retrieval is first initiated, its memory requirement is the sum of the first and second fragment of a block, because the display of the first fragment is started at the end of the first sub-period (and the block for the next fragment must be allocated in order to issue the disk read for B1). For an in-progress display, during each time period that consists of K sub-periods, the display is one sub-period behind the retrieval. Thus, at the end of each time period, one sub-period worth of data remains in memory (the variable termed Consumed in Figure 5.4). At the beginning of the next time period, the fragment size of b0 is added to the memory requirement because this much memory must be allocated to activate the disk. Next, from the combined value, the amount of data displayed during a sub-period is subtracted and the size of the next fragment is added, i.e., the amount of memory required to read this fragment. This process is repeated for all sub-periods that constitute a time period. Figure 5.5 illustrates the resulting memory demand as a function of time. Either of the two peaks could be highest depending on the characteristics and the number of physical disks involved. In the example of Figure 5.3 (and with the fragment sizes of Table 5.1), the peak amount of required memory is 1,103.7 KBytes, which is reached at the beginning of each time period (peak (2) in Figure 5.5). This compares favorably with the two logical blocks (2.44 MBytes) per display required by Disk Grouping. If no additional optimization is employed then the maximum value of either peak (1) or (2) specifies the memory requirement of a display.
Figure 5.5. Memory requirement for Staggered Grouping.

Figure 5.4. Algorithm for the dynamic computation of the peak memory requirement with Staggered Grouping.

We now derive equations that specify the remaining parameters of this technique analogous to the manner in the previous section. The sub-periods ![]() are all equal in length and collectively add up to the duration of a time period TP:
are all equal in length and collectively add up to the duration of a time period TP:
Equation 5.7
![]()
Equation 5.8

The total block size Bl retrieved must be equal to the consumed amount of data:
Equation 5.9
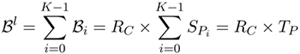
Furthermore, the sub-period Sp must satisfy the following inequality for the block size Bi on each physical disk i
![]() :
:
Equation 5.10

Solving for the fragment sizes Bi leads to a system of equations similar to the Disk Grouping Equation 5.3 with the difference of Tp being substituted by Sp. As a consequence of the equality Tp = K × SP, every instance of ND is replaced by the expression ND × K. The solution (i.e., the individual block size Bi) of this system of equations is analogous to Equation 5.4 where, again, every instance of ND is replaced with ND × K (and hence, for notational convenience ![]() is equivalent to
is equivalent to ![]() ).
).
The total number of streams for a Staggered Grouping system can be quantified as:
Equation 5.11
![]()
Recall that there is no closed form solution for the peak memory requirement (see Figure 5.4 for its algorithmic computation). Hence, the total amount of memory M at the server side is derived as:
Equation 5.12
![]()
Consequently, the maximum latency ![]() is given by:
is given by:
Equation 5.13

5.2.4. Logical/Virtual Homogeneous Disks
This technique separates the concept of logical disk from the physical disks all together. Moreover, it forms logical disks from fractions of the available bandwidth and storage capacity of the physical disks, as shown in Figure 5.6. These two concepts are powerful abstractions that enable this technique to utilize an arbitrary mix of physical disk models. To illustrate, consider the following example.

Example 5.2.1:
Assume the six physical disk drives of the storage system shown in Figure 5.6 are configured such that the physical disks d0 and d3 each support 1.8 logical disks. Because of their higher performance the physical disks d1 and d4 realize 4.0 logical disks each and the disks d2 and d5 support 6.2 logical disks. Note that fractions of logical disks (e.g., 0.8 of d0 and 0.2 of d2) are combined to form additional logical disks (e.g., ![]() , which contains block X1 in Figure 5.6). The total number of logical disks adds up to [(2 × 1.8) + (2 × 4.0) + (2 × 6.2)] = 24. Assuming ND = 4 MPEG-2 (3.5 Mb/s) streams per logical disk, the maximum throughput that can be achieved is 96 streams (24 × ND = 24 × 4). □
, which contains block X1 in Figure 5.6). The total number of logical disks adds up to [(2 × 1.8) + (2 × 4.0) + (2 × 6.2)] = 24. Assuming ND = 4 MPEG-2 (3.5 Mb/s) streams per logical disk, the maximum throughput that can be achieved is 96 streams (24 × ND = 24 × 4). □
The detailed design of this technique is as follows. First, it selects how many logical disks should be mapped to each of the slowest physical disks and denotes this factor with P0[4]. With no loss of generality, for Disk Merging we index the types in order of increasing performance. For example, in Figure 5.6, the two slowest disks d0 and d3 each represent 1.8 logical disks, i.e., p0 = 1.8.
[4] Subscripts for pi indicate a particular disk type, not individual disks.
Next, the time period Tp and the block size necessary to support p0 logical disks on a physical disk can be established by extending Equation 5.2 and solving for the block size Bl as follows:
Equation 5.14

Equation 5.15

As with the two previously introduced techniques, all the logical disks in the system must be identical. Therefore, TP and Bl obtained from Equations 5.14 and 5.15 determine how many logical disks map to the other, faster disk types i, 1 ≤ i ≤ m − l, in the system. Each factor pi must satisfy the following constraint:
Equation 5.16

To compute the values for pi from the above equation we must first quantify the number of seeks, i.e., #seek(pi), that are induced by pi. The function #seek(pi) consists of two components:
Equation 5.17
![]()
Because the disk heads need to seek to a new location prior to retrieving a chunk of data of any size—be that a full logical block or just a fraction thereof—the number of seeks is at least ![]() . However, there are scenarios when
. However, there are scenarios when ![]() underestimates the necessary number of seeks because the fractions of logical disks no longer add up to 1.0. In these cases, the expression (ni - 1) denotes any additional seeks that are needed. To illustrate, if there are two physical disk types with p0 = 3.7 and p1 = 5.6 then it is impossible to directly combine the fractions 0.7 and 0.6 to form complete logical disks. Hence, one of the fractions must be further divided into parts, termed sub-fragments. However, this process will introduce additional seeks. Specifically, assuming yi sub-fragments, the number of seeks will increase by (yi — 1). Because seeks are wasteful operations, it is important to find an optimal division for the fragments to minimize the total overhead. For large storage systems employing a number of different disk types, it is a challenge to find the best way to divide the fragments.
underestimates the necessary number of seeks because the fractions of logical disks no longer add up to 1.0. In these cases, the expression (ni - 1) denotes any additional seeks that are needed. To illustrate, if there are two physical disk types with p0 = 3.7 and p1 = 5.6 then it is impossible to directly combine the fractions 0.7 and 0.6 to form complete logical disks. Hence, one of the fractions must be further divided into parts, termed sub-fragments. However, this process will introduce additional seeks. Specifically, assuming yi sub-fragments, the number of seeks will increase by (yi — 1). Because seeks are wasteful operations, it is important to find an optimal division for the fragments to minimize the total overhead. For large storage systems employing a number of different disk types, it is a challenge to find the best way to divide the fragments.
Further complicating matters is the phenomenon that the value of yi depends on pi and, conversely, pi might change once yi is calculated. Because of this mutual dependency, there is no closed form solution for pi from Equation 5.16. However, numerical solutions can easily be found. An initial estimate for pi may be obtained from the bandwidth ratio of disk types i and 0 ![]() . When iteratively refined, this value converges rapidly towards the correct ratio.
. When iteratively refined, this value converges rapidly towards the correct ratio.
Based on the number of physical disks in the storage system and the pi values for all the types the total number of logical disks (Dl) is defined as[5]:
[5] m denotes the number of different disk types employed and #diski refers to the number of disks of type i.
Equation 5.18

Once a homogeneous collection of logical disks is formed, the block size Bl of a logical disk determines the total amount of required memory, the maximum startup latency, and the total number of simultaneous displays. The equations for these are an extension of those described in Chapter 2 and are as follows.
The total number of streams a system can sustain is proportional to the number of logical disks and the number of streams each logical disk can support:
Equation 5.19
![]()
The total amount of memory M is:
Equation 5.20
![]()
While the maximum latency ![]() is no more than:
is no more than:
Equation 5.21

The overall number of logical disks constructed primarily depends on the initial choice of p0. Figure 5.7 shows possible configurations for a system based on two disks each of type ST31200WD, ST32171WD, and ST34501WD. In Figure 5.7a, system throughputs are marked in the configuration space for various sample values of p0. A lower value of p0 results in fewer, higher performing logical disks. For example, if p0 = 1.8 then each logical disk can support up to 4 displays simultaneously (ND ≤ 4). Figure 5.7a shows the total throughput for each ND = 1,2,3, 4. As p0 is increased, more logical disks are mapped to a physical disk and the number of concurrent streams supported by each logical disk decreases. For example, a value of p0 = 7.2 results in logical disks that can support just one stream (ND = 1). However, the overall number of logical disks also roughly increases four-fold. The maximum value of the product p0 × ND is approximately constant[6] and limited by the upper bound of ![]() . In Figure 5.7 this limit is
. In Figure 5.7 this limit is ![]() = 7.93. Paris of 〈p0, ND 〉 that approach this maximum will yield the highest possible throughput (e.g., 〈3.6, 2〉 or 〈7.8, 1〉). However, the amount of memory required to support such a high number of streams increases exponentially (see Figure 5.7b). The most economical configurations with the lowest cost per stream (i.e., approximately 100 streams, see Figure 5.7c) can be achieved with a number of different, but functionally equivalent, 〈p0, ND〉 combinations.
= 7.93. Paris of 〈p0, ND 〉 that approach this maximum will yield the highest possible throughput (e.g., 〈3.6, 2〉 or 〈7.8, 1〉). However, the amount of memory required to support such a high number of streams increases exponentially (see Figure 5.7b). The most economical configurations with the lowest cost per stream (i.e., approximately 100 streams, see Figure 5.7c) can be achieved with a number of different, but functionally equivalent, 〈p0, ND〉 combinations.
[6] It is interesting to note that, as a result of this property, the perceived improvement of the average seek distance d from
(Equation 5.2) to
(Equation 5.16) does not lower the seek overhead.
Figure 5.7. Sample system configurations for different values of p0 (1.0 ≤ p0 7.8 with increments of Δp0 = 0.2) for a storage system with 6 physical disks (2 × ST31200WD, 2 × ST32171WD, and 2 × ST34501WD). Streams are of type MPEG-2 with a consumption rate of RC = 3.5 Mb/s.
Figure 5.7a: Con .guration space

Figure 5.7b: Memory

Figure 5.7c: Cost

The number of possible configurations in the two-dimensional space shown in Figure 5.7a will increase if p0 is incremented in smaller deltas than Δp0 = 0.2. Hence, for any but the smallest storage configurations it becomes difficult to manually find the minimum cost system based on the performance objectives for a given application. However, an automated configuration planner can rapidly search through all configurations to find the ones that are most appropriate.
5.2.5. Random Disk Merging (RDM)
The previously introduced technique of Disk Merging can also be termed Deterministic Disk Merging (DDM) because it is based on round-robin data placement which results in an orderly, round-robin retrieval of blocks for streams that are sequentially viewed. This allows the DDM technique to provide a guaranteed retrieval time for each block.
For applications that require non-sequential access to data blocks such as interactive games or visualization applications the round-robin data placement does not provide any benefits. In those cases random data placement has been found to be more suitable [116], [144].
If data blocks are randomly placed on different disk drives, then the number of block retrievals per disk drive is not known exactly in advance but only statistically. Hence, such a scheme cannot make any absolute guarantees for the retrieval time of a specific block. However, on average the block retrieval times will be comparable to the round-robin case.
Because Equations 5.1 through 5.16 essentially partition the effective bandwidth of all the physical disk drives into equal amounts (equaling the data rate of one logical disk drive) we can still use those equations in our configuration planner for systems that employ random data placement in conjunction with cycle-based scheduling (for example RIO [116]).
One aspect that does not apply to systems with random block placement is the declustering of data blocks into fragments. For example, if a logical disk drive was allocated across three physical disk drives according to 20%, 30%, and 50% of its bandwidth, one would randomly distribute 20%, 30%, and 50% of the data blocks assigned to this logical disk to the respective physical drives. There would be no need to decluster each block into 20%, 30%, and 50% fragments because no absolute guarantees about the retrieval time are made. Without declustering the number of seek operations is reduced and more of the disk transfer rate can be harnessed.
Furthermore, allocating blocks randomly on the surface of a multi-zoned physical disk drive will automatically result in a disk data rate that approximates the average transfer rate of all the zones. Hence, no explicit technique to address multi-zoning needs to be employed.
Because of the previous observations we can simplify the seek function for systems that use random placement to
Equation 5.22
![]()
In essence we count fractional numbers of seek operations because, for example, 20% of a logical disk will result in one complete seek operation approximately 20% of the time this logical disk is accessed.
The description of RDM in this section is based on an average case analysis. A worst case analysis requires statistical and queuing models and will not be presented here. Note that because the worst and average case are identical for DDM it will outperform RDM in a worst case scenario. Hence, it is application-dependent whether RDM or DDM are most appropriate under any specific circumstances.
Storage Space Considerations
Utilizing most of the bandwidth of the physical disks in a system to lower the cost per stream CPS is certainly a compelling aspect of selecting a system configuration (i.e., p0 and ND). However, for some applications the available storage space is equally or more important. With Disk Merging the storage space associated with each logical disk may vary depending onto which physical disk it is mapped. For example, Table 5.2 shows two possible configurations for the same physical disk subsystem. Because the round-robin assignment of blocks results in a close to uniform space allocation of data, the system will be limited by the size of the smallest logical disk. Both sample configurations support N = 96 streams. While one fails to utilize 14.4% of the total disk space in support of SM (W = 14.4%), the other wastes 16.5% of the disk space (W = 16.5%). In general, this space is not wasted and can be used to store traditional data, such as text and records, that are accessed during off-peak hours. Alternatively, the number of logical disks can purposely be decreased on some of the physical disks to equalize the disk space. The latter approach will waste some fraction of the disk bandwidth. In summary, if a configuration fully utilizes the disk bandwidth some storage space may be unused, or conversely, if all of the space is allocated then some bandwidth may be idle.
| Disk Model (Seagate) | Pi | Logical block size [MB] | Logical disk size [MB] | % Space for traditional data | Overall % space for traditional data |
|---|---|---|---|---|---|
| ND =1,Dl =96,N=96 | |||||
| ST34501WD | p2 = 25.2 | 172.2 | 23.3% | ||
| ST32171WD | P1 = 15.6 | 0.554 | 132.1 | 0% | W = 14.4% |
| ST3120OWD | P0 = 7.2 | 139.7 | 5.4% | ||
| ND =4,Dl =24, N = 96 | |||||
| ST34501WD | P2 = 6.2 | 699.8 | 26.4% | ||
| ST32171WD | P1 = 4.0 | 0.780 | 515.3 | 0% | W = 16.5% |
| ST3120OWD | P0 = 1.8 | 558.9 | 7.8% | ||
5.2.6. Configuration Planner for Disk Merging
The same hardware configuration can support a number of different system parameter sets depending on the selected value of p0, see Figure 5.7. The total number of streams, the memory requirement, the amount of storage space unusable for continuous media, and ultimately the cost per stream are all affected by the choice of a value of p0. The value of p0 is a real number and theoretically an infinite number of values are possible. But even if p0 is incremented by some discrete step size to bound the search space, it would be very time consuming and tedious to manually find the best value of p0 for a given application. To alleviate this problem this section presents a configuration planner that can select an optimal value for p0 based on the performance objective desired by a system.
Figure 5.8 shows the schematic structure of the configuration planner. It works in two stages: Stage 1 enumerates all the possible configuration tuples based on a user supplied description of the disk subsystem under consideration. The calculations are based on the analytical models of Section 5.2.4. Stage 2 filters the output of Stage 1 by removing configurations that do not meet the performance objectives of the application. The result of Stage 2 is a set of proposed configurations that provide the lowest cost per stream or, alternatively, make the best use of the available storage space.

Operation
The detailed operation of the planner is as follows. The number and type of disks of the storage system under consideration are input parameters into Stage 1. This information is used to access a database that stores the detailed physical characteristics of these disk types. (This information is similar to the examples listed in Tables 2.1 and 2.2.) With p0 = 1 the analytical models of Section 5.2.4 are then employed (by iterating over values of ND) to produce output values for the total number of streams N, the number of logical disks Dl, the memory required M, the maximum latency ![]() (for DDM), the logical block size Bl, the storage space usable for continuous media S, the percentage of the total storage space that cannot be used for continuous media W, the cost per stream CPS (see Equation 5.23), and pi, i ≥ 1. When ND reaches its upper bound of
(for DDM), the logical block size Bl, the storage space usable for continuous media S, the percentage of the total storage space that cannot be used for continuous media W, the cost per stream CPS (see Equation 5.23), and pi, i ≥ 1. When ND reaches its upper bound of ![]() , the value of p0 is incremented by a user specified amount, termed the step size and denoted with Δp0, and the iteration over ND is restarted. This process is repeated until the search space is exhausted. Stage 1 produces all possible tuples Q = 〈N, Dl, M,
, the value of p0 is incremented by a user specified amount, termed the step size and denoted with Δp0, and the iteration over ND is restarted. This process is repeated until the search space is exhausted. Stage 1 produces all possible tuples Q = 〈N, Dl, M, ![]() , Bl, S, W,
CPS, p0, p1,
... ,pm−1〉 for a given storage subsystem. Table 5.3 shows an example output for a 30 disk storage system with three disk types.
, Bl, S, W,
CPS, p0, p1,
... ,pm−1〉 for a given storage subsystem. Table 5.3 shows an example output for a 30 disk storage system with three disk types.
| N | Dl | M [MB] | Lmax [s] | B [MB] | S [MB] | W [%] | CPS [$] | PO | P1 | P2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 49 | 49 | 1.916 | 2.190 | 0.0196 | 49294.0 | 33.440 | 306.16 | 1.0 | 1.5a | 2.4 |
| 98 | 49 | 7.416 | 4.238 | 0.0378 | 49294.0 | 33.440 | 153.14 | 1.0 | 1.5a | 2.4 |
| 156 | 52 | 19.827 | 7.553 | 0.0635 | 52312.0 | 29.365 | 96.28 | 1.0 | 1.6b | 2.6 |
| 220 | 55 | 45.037 | 12.868 | 0.1024 | 55330.0 | 25.290 | 68.39 | 1.0 | 1.7c | 2.8 |
| 285 | 57 | 94.771 | 21.662 | 0.1663 | 57342.0 | 22.574 | 52.96 | 1.0 | 1.8d | 2.9 |
| 366 | 61 | 215.046 | 40.961 | 0.2938 | 61366.0 | 17.140 | 41.57 | 1.0 | 1.9e | 3.2 |
| 455 | 65 | 632.904 | 103.331 | 0.6955 | 63792.9 | 13.863 | 34.36 | 1.0 | 2.1 | 3.4 |
| 104 | 104 | 10.132 | 11.579 | 0.0487 | 63042.4 | 14.877 | 144.33 | 1.5a | 3.4 | 5.5 |
| 214 | 107 | 49.150 | 28.085 | 0.1148 | 63007.7 | 14.923 | 70.32 | 1.5a | 3.5 | 5.7 |
| 318 | 106 | 147.867 | 56.330 | 0.2325 | 62418.9 | 15.719 | 47.63 | 1.5f | 3.5 | 5.6 |
| 420 | 105 | 445.231 | 127.209 | 0.5300 | 63648.5 | 14.058 | 36.77 | 1.5 | 3.4 | 5.6 |
| 525 | 105 | 3062.561 | 700.014 | 2.9167 | 63648.5 | 14.058 | 34.40 | 1.5 | 3.4 | 5.6 |
| 90 | 90 | 6.811 | 7.784 | 0.0378 | 45270.0 | 38.874 | 166.74 | 2.0 | 2.7 | 4.3 |
| 210 | 105 | 42.989 | 24.565 | 0.1024 | 52815.0 | 28.686 | 71.63 | 2.0 | 3.2 | 5.3 |
| 366 | 122 | 215.046 | 81.922 | 0.2938 | 61366.0 | 17.140 | 41.57 | 2.0 | 3.9g | 6.3 |
| 173 | 173 | 31.018 | 35.449 | 0.0896 | 63670.2 | 14.029 | 86.88 | 2.5f | 5.6 | 9.2 |
| 332 | 166 | 163.513 | 93.436 | 0.2463 | 63356.7 | 14.452 | 45.67 | 2.5a | 5.4 | 8.7 |
| 519 | 173 | 2490.946 | 948.932 | 2.3998 | 63670.2 | 14.029 | 33.70 | 2.5f | 5.6 | 9.2 |
| 146 | 146 | 18.556 | 21.207 | 0.0635 | 48958.7 | 33.893 | 102.87 | 3.0 | 4.4 | 7.2 |
| 364 | 182 | 213.871 | 122.212 | 0.2938 | 61030.7 | 17.593 | 41.80 | 3.0 | 5.8h | 9.4 |
| 212 | 212 | 46.600 | 53.258 | 0.1099 | 60934.9 | 17.722 | 70.97 | 3.5a | 6.7 | 11.0 |
| 478 | 239 | 900.622 | 514.641 | 0.9421 | 63151.2 | 14.730 | 33.26 | 3.5 | 7.8i | 12.6 |
| 210 | 210 | 42.989 | 49.131 | 0.1024 | 52815.0 | 28.686 | 71.63 | 4.0 | 6.5 | 10.5 |
| 292 | 292 | 109.716 | 125.389 | 0.1879 | 64022.6 | 13.553 | 51.75 | 4.5a | 9.4 | 15.3 |
| 281 | 281 | 93.441 | 106.789 | 0.1663 | 56537.2 | 23.660 | 53.71 | 5.0 | 8.8j | 14.3 |
| 360 | 360 | 213.857 | 244.408 | 0.2970 | 63415.4 | 14.373 | 42.26 | 5.5a | 11.7 | 18.8 |
| 364 | 364 | 213.871 | 244.424 | 0.2938 | 61030.7 | 17.593 | 41.80 | 6.0 | 11.6k | 18.8 |
| 425 | 425 | 429.615 | 490.988 | 0.5054 | 63936.1 | 13.670 | 36.30 | 6.5 | 13.7 | 22.3 |
| 456 | 456 | 634.295 | 724.909 | 0.6955 | 63933.1 | 13.674 | 34.29 | 7.0 | 14.71 | 23.9 |
| 515 | 515 | 1928.946 | 2204.510 | 1.8728 | 63557.8 | 14.181 | 32.87 | 7.5 | 16.7 | 27.3 |
| a through 1: Fractions of logical disks must sometimes be divided into parts such that complete logical disks can be assembled (see Section 5.2.4 and [185]). For example, fractions of 10 x 0.7 and 10 x 0.8 become useful when 0.7 is divided into two parts, 0.2+0.5. Then 5 disks can be assembled from the 0.5 fragments and 10 disks from a combination of the 0.2+0.8 fragments. The configuration planner automatically finds such divisions if they are necessary. For this table the complete list is as follows: a0.2+0.3, b0.2+0.4, 10.2+0.5, d0.1+0.2+0.5, 10.1+0.8, f0.1+0.4, 90.2+0.7, h0.2+0.6, '0.2+0.2+0.4,'0.1+0.7, k0.2+0.2+0.2 and 10.1+0.1+0.5. | ||||||||||
To provide the output of Stage 1 in a more useful and abbreviated form the data is fed into Stage 2, which eliminates tuples Q that fail to satisfy the performance objectives of the application, and then orders the remaining tuples according to an optimization criterion. The input parameters to Stage 2 are (a) the minimum desired number of streams, (b) the maximum desired cost per stream, and (c) a hypothetical cost per MByte of disk space that cannot be utilized by CM applications. Stage 2 operates as follows. First, all tuples Q that do not provide the minimum number of streams desired are discarded. Second, an optimization component calculates the logical cost CPS' per stream for each remaining tuple Q' according to Equation 5.24,
Equation 5.23

Equation 5.24
![]()
where $MB is the cost per MByte of memory, $Diski is the cost of each physical disk drive i, and $W is the cost per MByte of unused storage space.
By including a hypothetical cost for each MByte of storage that cannot be utilized for CM (input parameter (c)), Stage 2 can optionally optimize for (i) the minimum cost per stream, or (ii) the maximum storage space for continuous media, or (iii) a weighted combination of (i) and (ii).
The final, qualifying tuples Q' will be output by Stage 2 in sorted order of ascending total cost per stream C' as shown in Table 5.4. For many applications the lowest cost configuration will also be the best one. In some special cases, however, a slightly more expensive solution might be advantageous. For example, the startup latency ![]() of a stream is a linear function of the number of logical disk drives in the system (see Equation 5.21). Hence, a designer might choose, for example, the second configuration from the top in Table 5.4 at a slightly higher cost per stream but for a drastically reduced initial latency (103 seconds versus 491 seconds, maximum). Alas, in some cases the final decision for a certain configuration is application-specific, but the planner will always provide a comprehensive list of candidates to select from.
of a stream is a linear function of the number of logical disk drives in the system (see Equation 5.21). Hence, a designer might choose, for example, the second configuration from the top in Table 5.4 at a slightly higher cost per stream but for a drastically reduced initial latency (103 seconds versus 491 seconds, maximum). Alas, in some cases the final decision for a certain configuration is application-specific, but the planner will always provide a comprehensive list of candidates to select from.
| N | Dl | M [MB] | Lmax [s] | B [MB] | W [%] | CPS [$] | CPS' [$] | p0 | p1 | p2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 425 | 425 | 429.615 | 490.988 | 0.5054 | 13.670 | 36.30 | 542.50 | 6.5 | 13.7 | 22.3 |
| 455 | 65 | 632.904 | 103.331 | 0.6955 | 13.863 | 34.36 | 547.72 | 1.0 | 2.1 | 3.4 |
| 519 | 173 | 2490.946 | 948.932 | 2.3998 | 14.029 | 33.70 | 553.19 | 2.5 | 5.6 | 9.2 |
| 525 | 105 | 3062.561 | 700.014 | 2.9167 | 14.058 | 34.40 | 554.98 | 1.5 | 3.4 | 5.6 |
| 420 | 105 | 445.231 | 127.209 | 0.5300 | 14.058 | 36.77 | 557.35 | 1.5 | 3.4 | 5.6 |
| 515 | 515 | 1928.946 | 2204.510 | 1.8728 | 14.181 | 32.87 | 557.98 | 7.5 | 16.7 | 27.3 |
| 360 | 360 | 213.857 | 244.408 | 0.2970 | 14.373 | 42.26 | 574.49 | 5.5 | 11.7 | 18.8 |
| 478 | 239 | 900.622 | 514.641 | 0.9421 | 14.730 | 33.26 | 578.71 | 3.5 | 7.8 | 12.6 |
| 332 | 166 | 163.513 | 93.436 | 0.2463 | 14.452 | 45.67 | 580.84 | 2.5 | 5.4 | 8.7 |
| 318 | 106 | 147.867 | 56.330 | 0.2325 | 15.719 | 47.63 | 629.69 | 1.5 | 3.5 | 5.6 |
| 366 | 61 | 215.046 | 40.961 | 0.2938 | 17.140 | 41.57 | 676.27 | 1.0 | 1.9 | 3.2 |
| 364 | 182 | 213.871 | 122.212 | 0.2938 | 17.593 | 41.80 | 693.26 | 3.0 | 5.8 | 9.4 |
Search Space Size
It is helpful to quantify the search space that the planner must traverse. If it is small then an exhaustive search is possible. Otherwise, heuristics must be employed to reduce the time or space complexity. The search space is defined by Stage I of the planner. The algorithm consists of two nested loops, as illustrated in Figure 5.9.
Figure 5.9. The two nested loops that define the configuration planner search space.

Figure 5.9 also shows the three parameters that define the size of the search space: the disk bandwidth of the slowest disk drive ![]() , the bandwidth requirements of the media RC, and the step size Δp0. The outer loop, iterating over p0, is terminated by its upper bound of
, the bandwidth requirements of the media RC, and the step size Δp0. The outer loop, iterating over p0, is terminated by its upper bound of ![]() . This upper bound describes into how many logical disks the slowest physical disk can be divided. The inner loop iterates over ND to describe the number of streams supported by one logical disk. Hence, the upper bound of the inner loop is dependent on the outer loop. A low value of p0 results in fewer, higher performing logical disks. As p0 is increased, more logical disks are mapped to a physical disk and the number of concurrent streams ND supported by each logical disk decreases. Therefore the maximum value of the product p0 × ND is approximately constant at a value of
. This upper bound describes into how many logical disks the slowest physical disk can be divided. The inner loop iterates over ND to describe the number of streams supported by one logical disk. Hence, the upper bound of the inner loop is dependent on the outer loop. A low value of p0 results in fewer, higher performing logical disks. As p0 is increased, more logical disks are mapped to a physical disk and the number of concurrent streams ND supported by each logical disk decreases. Therefore the maximum value of the product p0 × ND is approximately constant at a value of ![]() . The total number of executions of the program block enclosed by the two loops can be estimated at:
. The total number of executions of the program block enclosed by the two loops can be estimated at:
Equation 5.25
![]()
Equation 5.26
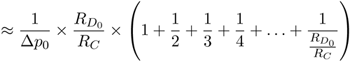
There is no closed form solution of Equation 5.25. However, since the number of terms enclosed by the parenthesis is ![]() , a loose upper bound for E#loaps is:
, a loose upper bound for E#loaps is:
Equation 5.27

Table 5.5 shows two sample disk configurations, both with approximately the same aggregate disk bandwidth (200 MB/s) but with a different number of disk types. In Configuration A the slowest disk is of type ST31200WD which limits the ratio ![]() to 7.93. The actual number of configuration points produced by the planner is 139 (see Table 5.6). The estimated search space size (using Equation 5.25) is E#loops = 160, or about 15.1% higher. The same calculation for Configuration B yields E#loops = 580 (with 469 actual points, an over-estimation of 23.7%, see Table 5.6). Note that the number of possible configuration points depends on the ratio between the media bandwidth requirements and the disk drive production rate for the slowest disk in the system. It does not depend on the overall number of disk drives. Table 5.6 shows a few additional configuration spaces and estimates. Note that at each configuration point, for all disk types other than the slowest one, pi must be iteratively computed.
to 7.93. The actual number of configuration points produced by the planner is 139 (see Table 5.6). The estimated search space size (using Equation 5.25) is E#loops = 160, or about 15.1% higher. The same calculation for Configuration B yields E#loops = 580 (with 469 actual points, an over-estimation of 23.7%, see Table 5.6). Note that the number of possible configuration points depends on the ratio between the media bandwidth requirements and the disk drive production rate for the slowest disk in the system. It does not depend on the overall number of disk drives. Table 5.6 shows a few additional configuration spaces and estimates. Note that at each configuration point, for all disk types other than the slowest one, pi must be iteratively computed.
| Configuration | A | B |
|---|---|---|
| Aggregate disk bandwidth | 200 MB/s | 200 MB/s |
| Number of different disk types | 3 | 2 |
| Total number of disks | 33 | 20 |
| Number of disks of type ST34501WD | 5 | 8 |
| Number of disks of type ST32171WD | 8 | 12 |
| Number of disks of type ST3120OWD | 20 | − |
| Slowest disk type | Search space | ||
|---|---|---|---|
| Model | Bandwidth | Planner | Estimate (E#loops) |
| ST3120OWD | (3.47 MB/s) | 139 | 160 (+15.1%) |
| ST32171WD | (7.96 MB/s) | 469 | 580 (+23.7%) |
| ST34501WD | (12.97 MB/s) | 898 | 1030 (+14.7%) |
The upper bound illustrated in Equation 5.27 is less than quadratic and the examples of Table 5.6 indicate that the exponent is approximately 1.4 (a five-fold increase in the disk bandwidth results in a ten-fold increase in the search space, i.e., ![]() = 5.21.4 = 10 =
= 5.21.4 = 10 = ![]() ).
).
However, to find an optimal configuration if DDM is employed the planner must consider that fragments sometimes need to be divided into sub-fragments (see Section 5.2.4). Unfortunately, the runtime of the algorithm to find the best fragment division is exponential [185]. For storage systems up to approximately 1,000 disk drives it is still feasible to execute an exhaustive search. (This was done for all our experiments, see see Section 5.2.6 and Figure 5.11.) However, for much larger configurations heuristics need to be employed. For example, the exponential algorithm might be modified to take advantage of a polynomial-time approximation [94].
Figure 5.11. Planner execution times with m = 2 and m = 5 disk types for Deterministic Disk Merging (DDM) and Random Disk Merging (RDM). Measurements were obtained from a Sun Enterprise Server 450 with two Spare II (300 MHz) processors, Solaris 2.6 and the gcc v2.8.1 C compiler, Δp0 = 0.2.

Step Size Δp0
Ideally the value for p0 is a real number and infinitely many values are possible within a specified interval. The smaller the step size Δp0, the closer this ideal is approximated. However, a disk subsystem can only support a finite number of streams N and the number of streams is a discrete value. Because of this constraint, many values of p0 will map to very similar final configurations. Since the step size Δp0 is directly related to the execution time of the planner, it should be chosen sufficiently small to generate all possible configurations but large enough to avoid excessive and wasteful computations. Figure 5.10a shows the optimal number of streams supported for a storage system with 5 x ST31200WD, 10 x ST32171WD, and 15 x ST34501WD disk drives for a decreasing value of Δp0- For Δp0 < 0.2 the throughput improvement is marginal while the planner execution time becomes very long as illustrated in Figure 5.10b. As mentioned earlier, the fragment combination that is performed by the planner is a very expensive algorithm (see Section 5.2.6 for a discussion). Furthermore, the smaller Δp0, the more possible fragment combinations there are (e.g., for Δp0 = 0.5 there is only one fragment combination "0.5+0.5" while for Δp0 = 0.1 there are 29 [185]). From these results we conclude that values of 0.1 or 0.2 result in an efficient and complete search space traversal.
Figure 5.10. Decreasing the step size Δp0 results in an improved, more optimal system throughput (i.e., number of streams, Fig. 5.10a) with the same hardware configuration. However, the configuration planner execution time increases dramatically, see Fig. 5.10b. For Δp0 < 0.2 the throughput improvement is marginal while the planner execution time becomes very long. (Configuration of 5 x ST3f 200WD, 10 × ST32171WD, and 15 × ST34501WD disk drives.)
Fig. 5.10a. Number of streams at the lowest cost.

Fig. 5.10b. Runtime of the configuration planner.

Planner Execution Runtime
The runtime of the planner increases with both the number of physical disk drives D and the number of different disk drive types m. The time complexity for Deterministic Disk Merging (DDM) is much larger than for the random version (RDM) due to the fragment combination problem as described in Section 5.2.4.
The runtime of the DDM planner is exponential in the number of different disk drive types m for an exhaustive search. However, m is typically small (less than twenty) even for large storage system. If too many generations of disk drives with extraordinary performance differences are employed it becomes increasingly difficult to utilize all the resources (bandwidth and storage space). Still, because the runtime of the fragment combination algorithm is of the order O(f3) execution times become large with an increasing number of fragments f. Figure 5.11 shows some sample execution times for the algorithm compiled with a gcc v2.8.1 C compiler on a Sun Enterprise Server 450 with two Spare II (300 MHz) processors running Solaris 2.6.
Further illustrated in Figure 5.11 are the results for Random Disk Merging (RDM) which requires very little computation time and is only dependent on the number of disk types m and not the total number of physical disk drives D. For most of our measurements the execution time of the planner for RDM was below 100 milliseconds. Hence, the configuration planner can be used to configure very large RDM storage systems.
Planner Extension to p0 < 1
Thus far, an implicit assumption for Disk Merging has been that a physical disk would be divided into one or more logical disks, i.e., p0 ≥ 1. However, we have already investigated how to combine block fragments into complete logical disks. By generalizing this idea we can extend the Disk Merging technique to include p0 values that are finer in granularity, i.e., 0 < p0 ≤ 1. Consider Example 5.2.6.
Proof: Figure 5.12 shows a storage subsystem with five physical disk drives. Assume that disks d3, and d4 are approximately 62% faster than the disks d0, d1, and d2. Then a possible configuration is p0 = 0.8 and p1 = 1.3 for a total of five logical drives. The physical disks d0, d1, and d2 each store data in chunks of 0.8 logical blocks Bl. This necessitates that either d3 or d4 must be activated whenever a complete logical block is retrieved from either do, d1, or d2. These fragment should be 0.2 x Bl in size. However, because disks d3 and d4 are partitioned into 1.3 logical disks, the fragment for one of the slower disks is divided in half (0.1+0.1) and assigned to both d3 and d4. □
Figure 5.12. A Disk Merging example configuration where the smallest physical drives support less than one full logical disk, i.e., p0 < 1.
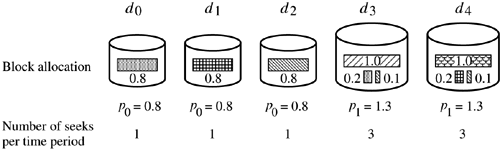
There are tradeoffs associated with choosing p0 to be less than 1.0. First, such a configuration can reduce the number of logical disks in the system which in turn reduces the worst case latency. The number of logical disks in Example 5.2.6 is five whereas, with values of p0 ≥ 1, the planner would have constructed at least six logical disks. Second, when the value of p0 is set to very small values, then several physical disks are combined to support just one logical disk. A logical block Bl is effectively declustered across several disk drives. In its purest form, all physical disks form just one logical disk. Each block retrieval then activates all the disks in parallel. This is a special case of the Disk Grouping technique with all the disks forming just one group. Small values of p0 can result in large logical block sizes Bl. And in turn, large blocks translate into a large memory requirement and potentially increased cost.
These tradeoffs can automatically be quantified by extending the configuration planner to operate for values of p0 less than 1.0. Table 5.7 shows a sample output of the planner for a 30 disk storage system. The table has been abbreviated to show just the configurations for p0 = 0.8.
| N | Dl | M [MB] | Lmax [s] | B [MB] | S [MB] | W [%] | CPS [$] | P0 | P1 | P2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 130 | 65 | 16.515 | 9.437 | 0.0635 | 60893.2 | 17.779 | 115.51 | 0.8 | 2.2 | 3.5 |
| 195 | 65 | 39.922 | 15.209 | 0.1024 | 60893.2 | 17.779 | 77.13 | 0.8 | 2.2 | 3.5 |
| 252 | 63 | 76.834 | 21.953 | 0.1524 | 61830.0 | 16.514 | 59.83 | 0.8 | 2.1 | 3.4 |
| 310 | 62 | 137.677 | 31.469 | 0.2221 | 60848.6 | 17.839 | 48.83 | 0.8 | 2.1 | 3.3 |
| 360 | 60 | 235.093 | 44.780 | 0.3265 | 61830.0 | 16.514 | 42.32 | 0.8 | 2.0 | 3.2 |
| 441 | 63 | 634.061 | 103.520 | 0.7189 | 61830.0 | 16.514 | 35.45 | 0.8 | 2.1 | 3.4 |
DDM and RDM Comparison
Table 5.8 compares the most cost-effective solutions produced by the configuration planner for a fixed, 30-disk storage system with the use of either DDM or RDM (the results are representative of other storage system sizes as well). As expected, DDM results in a lower number of streams at a slightly higher price as compared with RDM. Recall that DDM uses track-pairing to achieve the average transfer rate of a multi-zone disk drive. Track-pairing results in two seeks for each data transfer and hence the overhead is increased. RDM places blocks in random locations on each disk platter and thus achieves the average disk transfer rate. For comparison purposes Table 5.8 shows an additional column that illustrates the performance of DDM without track-pairing (i.e., hypothetically assuming single-zone disks). Under such circumstances the performance of DDM and RDM would be very similar. The remaining difference is due to block fragmentation. No block fragmentation is required for RDM: if a disk supports 0.2 of a logical disk then simply 20% of the blocks assigned to that logical disk are stored there. These differences result in a slightly better resource utilization for RDM than for DDM with the same physical storage system. All configurations achieve a high overall throughput utilization of 86.8% to 93.7% (the bandwidth of the total number of streams supported relative to the maximum bandwidth of the storage system, assuming no overhead: ![]() . Note that only statistical guarantees can be made for the disruption-free stream playback based on RDM. Hence, it depends on the application whether RDM or DDM is more appropriate.
. Note that only statistical guarantees can be made for the disruption-free stream playback based on RDM. Hence, it depends on the application whether RDM or DDM is more appropriate.
| Storage Configuration | Parameter | DDM | DDM without Track-Pairing | RDM |
|---|---|---|---|---|
| 10 × {ST31200WD, ST32171WD, ST34501WD} | Streams N Blocksize Bl Throughput % Total Cost Total Memory | 497 @ $32.73 1.2737 MB 89.5% $16,266.81 1,266.1 MB | 515 @ $31.22 1.0491 MB 92.8% $16,078.30 1,080.6 MB | 520 @ $31.21 1.1808 MB 93.7% $16,229.20 1,227.9 MB |
| 10 × {ST32171WD, ST34501WD, ST39102LW} | Streams N Blocksize Bl Throughput % Total Cost Total Memory | 772 @ $21.78 1.1727 MB 86.8% $16,814.16 1,810.6 MB | 800 @ $20.52 0.8846 MB 90.0% $16,416.00 1,415.4 MB | 805 @ $20.50 0.9312 MB 90.6% $16,502.50 1,499.2 MB |
5.2.7. Validation
The purpose of a configuration planner is to guide a system designer when implementing a real system. To be useful, it must reveal and predict the behavior of a real system reliably and accurately. With the configuration planner, as with any non-trivial software program, the determination of correctness is a challenge. We have employed multiple strategies to provide compelling evidence that the planner indeed closely models an actual system.
The analytical models developed in Section 5.2.4 were the first tool used to evaluate the performance of the planner. These models have the advantage of being relatively simple to compute and easy to verify. However, they cannot encompass the full complexity of a storage system and hence are based on some arguable simplifying assumptions. Used in conjunction with other methods, however, their point estimates provide compelling evidence and reinforcement for the accuracy and correctness of our methodology.
The primary tool to evaluate the planner was a simulator. It included a detailed disk model that was calibrated with parameters extracted from commercially available disk drives. The file system was the same as the one used in the implementation of our prototype, Mitra [76]. The benefits of this approach were two-fold. First, any influence that the file system might have on the results gathered from the simulation would be identical to the effects experienced in a real implementation. Second, there was high confidence that the code was largely bug-free because it had been tested with a number of different storage system configurations on platforms running for extended periods of time on either UNIX (HP-UX™ and OSF/1™) or Windows NT™. To model user behavior, the simulator included a module to generate synthetic workloads based on various Poisson and Zipf distributions [190]. A detailed description of the simulation infrastructure is provided in Section 5.2.7. The main advantage of the simulator was that it allowed us to model some of the complexities in more detail than in the analytical models.
The third tool to substantiate the results provided by both, the simulator and the analytical models, was an actual implementation of the storage subsystem. The strategy of using the file system of Mitra in the simulator made it possible to replace the modules that encapsulated a model of the magnetic disk drives with actual physical devices. Hence, results such as individual disk utilizations could be measured directly from real devices and the resulting statistics can be expected to match the real performance of a heterogeneous CM storage system closely. Two disadvantages limited the use of this implementation. First, the workload had to execute in real-time. This was substantially (i.e., several orders of magnitude) slower than using simulated disk drives. Second, we were restricted to the actual hardware devices at hand. Hence, we used the implementation primarily to validate the simulator with some specific configurations.
Simulation Infrastructure
The simulator was implemented using the C programming language on an HP 9000 735/125 workstation running HP-UX™. Other than the standard libraries no external support is needed. The simulator was implemented in a modular fashion and consists of the following components:
The disk emulation module imitates the response and behavior of a magnetic disk drive. The level of detail of such a model depends largely upon the desired accuracy of the results. Several studies have investigated disk modeling in great detail [139], [180], [75]. Our model includes mechanical positioning delays (seeks and rotational latency) as well as variable transfer rates due to the common zone-bit-recording technique. The disk emulation module can be simultaneously instantiated multiple times for various parameter sets describing different disk models in a disk array.
The logical-to-physical disk mapping layer translates read and write requests directed to logical disks into corresponding operations mapped onto the actual, physical devices.
The file system module provides the abstraction of files on top of the disk models and is responsible for the allocation of blocks and the maintenance of the free space. We selected the Everest file system (developed for our CM server prototype Mitra) for its ability to minimize disk space fragmentation, to provide guaranteed contiguous block allocation, and for its real-time performance [63].
The loader module generates a synthetic set of continuous media objects that are stored in the file system as part of the initialization phase of the simulator. The parameters for this module include the total number of objects produced, their display time length, and their consumption rate (for example 1.5 Mb/s as required by MPEG-1 or 3.5 Mb/s for MPEG-2).
The scheduler module translates a user request into a sequence of real-time block retrievals. It implements the concept of a time period and enables the round-robin migration of consecutive block reads on behalf of each stream. Furthermore, it ensures that all real-time deadlines are met. To simulate a partitioned system consisting of multiple sub-servers, the scheduler can be instantiated multiple times, each copy configured with its own parameter set (time period, block size, etc.).
Finally, the workload generator models user behavior and produces a synthetic trace of access requests to be executed against the stored objects. Both the distribution of the request arrivals as well as the distribution of the object access frequency can be individually specified. For the purpose of our simulations, the request inter-arrival times were Poisson distributed while the object access frequency was modeled according to Zipf's law [190].
The storage system chosen for the comparison was influenced by the physical devices at hand. The setup included two different disk models and a total of five disks: four Seagate Hawk 1LP (ST31200WD) drives and one Seagate Cheetah 4LP (ST34501WD) drive. Based on this storage system the configuration planner computed a total of 78 possible configurations. We selected one of them—its parameters are shown in Table 5.10—to illustrate the results.
| N | D1 | M [MB] | Lmax [Sec] | B [MB] | S [MB] | W [%] | CPS [$] | p0 | p1 |
|---|---|---|---|---|---|---|---|---|---|
| 55 | 11 | 125.814 | 28.758 | 1.1438 | 7377.3 | 11.786 | 75.01 | 1.5 | 5.4 |
For this particular configuration, the planner predicted the maximum number of concurrent streams to be N = 55. The metric used to compare the analytical, simulation, and implementation results was the disk utilization as defined by:
Equation 5.28

In the case of servicing the maximum number of streams, i.e., N, the disk utilization q was expected to reach 100%. The continuous media clips selected for our experiments were 5 minutes long. (Table 5.9 summarizes the parameters used for the comparison.) Hence, a request arrival rate λ5min = 55 per five minutes or equivalently λ = 660 per hour, would achieve 100% utilization. We tested and compared the analytical, simulation, and implementation results for a projected load of 20% (λ = 132), 40% (λ = 264), 60% (λ = 396), and 80% (λ = 528).
| Metric | Value |
|---|---|
| Number of video clips Bandwidth of video clips Length of a video clip User request distribution Access frequency distribution | 50 3.5 Mb/s (e.g., MPEG-2) 5 minutes ≡ 131.25 MB Poisson Zipf with parameter 0.271 |
| Disk drives Total CM storage capacity Allocated CM storage capacity | 4x ST31200WD, 1 x ST34501 WD 7,377.3 MB 6,562.5 MB (89%) |
| Simulation time Target disk utilization | 12 hours 20%, 40%, 60%, and 80% |
Figures 5.13, 5.14, 5.15, and 5.16 show the resulting disk utilization for the analytical model (i.e., predicted by the planner), the simulation, and the implementation. Overall the results are a very close match. Specifically, for the four ST31200WD disks ![]() ,...
,... ![]() , the simulated utilization is slightly less than predicted, but the difference is no more than -1.5% in the worst case. Equally impressive are the implementation results which are within +3.0% of the predicted values.
, the simulated utilization is slightly less than predicted, but the difference is no more than -1.5% in the worst case. Equally impressive are the implementation results which are within +3.0% of the predicted values.
Figure 5.13. Verification results for 20% load (λ = 132).




To interpret the results for the ![]() physical disk (ST34501WD), we must describe an additional consideration. Note that the analytical disk utilization for this disk has been adjusted by a factor of
physical disk (ST34501WD), we must describe an additional consideration. Note that the analytical disk utilization for this disk has been adjusted by a factor of ![]() = 0.926. The reason for this is as follows. The number of logical disks in Table 5.10 is Dl = 11. However, the planner actually computed the possible number of disks to be (4 × p0) + (1 × p1) = (4 × 1.5) + 5.4 = 11.4, i.e., 5.4 logical disks were mapped to the ST34501WD disk drive. Naturally, only complete disks can be used in the final storage assignment and hence, 0.4 logical disks must be left idle on one of the physical disks. We chose this to be the case on disk
= 0.926. The reason for this is as follows. The number of logical disks in Table 5.10 is Dl = 11. However, the planner actually computed the possible number of disks to be (4 × p0) + (1 × p1) = (4 × 1.5) + 5.4 = 11.4, i.e., 5.4 logical disks were mapped to the ST34501WD disk drive. Naturally, only complete disks can be used in the final storage assignment and hence, 0.4 logical disks must be left idle on one of the physical disks. We chose this to be the case on disk ![]() . Therefore, the predicted load on this disk is reduced by a factor of
. Therefore, the predicted load on this disk is reduced by a factor of ![]() . Note that this rounding adjustment only plays a perceptible role in this case because of the small number of logical disks involved. For all but the smallest storage configurations this effect quickly becomes negligible as the number of logical disks increases. With the described adjustment, the difference in disk utilization for
. Note that this rounding adjustment only plays a perceptible role in this case because of the small number of logical disks involved. For all but the smallest storage configurations this effect quickly becomes negligible as the number of logical disks increases. With the described adjustment, the difference in disk utilization for ![]() is less than -6.9% for the simulation and less than -1.9% for the implementation.
is less than -6.9% for the simulation and less than -1.9% for the implementation.
Finally we evaluated our techniques by comparing the non-partitioning Disk Merging scheme with a simple partitioning technique, i.e., a configuration where identical physical disks were grouped into independent subservers. In this case each subserver was configured optimally for a given load.
Similar to a real system, our simulation modeled shifts in the user access pattern as a function of time. Tests were conducted at system loads of 70%, 80%, and 90%, respectively. The 90% load revealed the fundamental problem of any partitioned system: some resources became a bottleneck while others remained idle, waiting for work. As expected in the case of the partitioned CM server, one of the three subservers became overloaded and as a result the average startup latency for all users increased. Disk Merging was able to handle the situation more gracefully. It was sensitive to neither the frequency of access to clips nor their assignment. As a result the latency increase was much less dramatic. (See [185] for a detailed description of these results.)
One disadvantage of non-partitioning schemes as compared with partitioned systems is their increased vulnerability to disk failures. However, as part of our research we have investigated fault-tolerance and high availability techniques and their application to heterogeneous storage systems. Our investigation resulted in the design of a non-overlapping parity technique termed HERA that can be successfully applied to Disk Merging [189].