
Since the engine has a mode of acting peculiar to itself, it will in every particular case be necessary to arrange the series of calculations conformably to the means which the machine possesses; for such or such a process which might be very easy for a [human] calculator may be long and complicated for the engine, and vice versâ.
—L. F. Menabrea, describing Charles Babbage’s Analytical Engine, 1842
(Translated by Ada Lovelace)
Design Is Compromise
In programming, there is always a tension between abstraction and efficiency . Code that has a higher level of abstraction is less likely to define the minimum number of operations needed to achieve the correct result in a specific situation. Conversely, code that is written at a lower level will often be faster but will be less widely applicable, leading to more repetition and sometimes worse maintainability. As a language that encourages you to work at a relatively high level of abstraction, F# can sometimes leave you at the wrong end of this trade-off. This chapter aims to give you the tools to recognize common performance bottlenecks in F# code and the skills needed to resolve these to a reasonable degree, without fatally compromising the readability of your code.
Getting from correct code to correct, efficient code is one of the coding tasks that I find the most satisfying. I hope that by the end of this chapter, you’ll feel the same way.
Some Case Studies
.NET performance, and code performance generally, is a huge topic. Rather than getting lost in a sea of performance-related issues, I’m going to focus on a few case studies that represent mistakes I commonly see being made (often by me). Incidentally, you might notice that I haven’t included asynchronous code in these case studies: this topic was covered in Chapter 10. For each case study, I’m going to present some correctly functioning but inefficient code. Then I’ll help you identify why it’s inefficient and show you the steps you can go through to make it relatively fast, but still correct and maintainable.
But before we can embark on the case studies, we need a framework for measuring and comparing performance. Enter “BenchmarkDotNet.”
BenchmarkDotNet
Through most of this book, I’ve avoided using third-party libraries, as I wanted to focus on the language itself. But in the case of performance, we need something that can provide a fair measure of execution speed, which includes running our code a number of times and performing back-to-back comparisons of different versions. BenchmarkDotNet does exactly this and works nicely with F#.
Create a command-line F# project.
Add the package “BenchmarkDotNet.”
Dummy functions to benchmark (Dummy.fs)
Executing the benchmarks (Program.fs)
The code in Listing 12-2, Program.fs, is the “boiler plate” we need to get BenchmarkDotNet to call our code repeatedly to measure its performance.
Dummy benchmark output
The “Method” column contains the names of the methods in the Harness class that we used to call our actual test-subject functions. As we are going to be back-to-back testing original vs. performance-enhanced versions, I’ve called these “Old” and “New.” The “Mean” column shows the average time needed to execute the functions we are testing. Not surprisingly, the “Old” function (slowFunction()) takes more time than the “New” function (fastFunction()). The difference in means is roughly 10:1, reflecting the fact that the slow dummy function sleeps for ten times as long. (It’s not exactly 10:1 because of other overheads that are the same for each version.)
The “Error,” “StdDev,” and “Median” columns give other relevant statistical measures of runtimes. The “Allocated” column shows how much managed memory – if any – was allocated per invocation of the functions under test. For the purposes of this chapter we’ll focus mainly on the “Mean” column. If the function being tested causes garbage collections, there will be additional columns in the table showing how many Generation 0, 1, and 2 collections occurred.
Case Study: Inappropriate Collection Types
Now that we have some nice benchmarking infrastructure in place, it’s time to look at common performance antipatterns and their remedies. We’ll start with what happens if you use an inappropriate collection type or access it inappropriately.
First cut of a sample function
We want to generate an F# list, so we use a list comprehension (the whole body of the function is in []). We use a for loop with a skip value of interval as the sampling mechanism. Items are returned from the input list using the -> operator (a shortcut for yield in for-loops) together with indexed access to the list, that is, data.[i]. Seems reasonable – but does it perform?
Integrating a function with benchmarking
In Listing 12-5, we declare modules Old and New to hold baseline and (in the future) improved versions of our function-under-test. At this stage, the Old and New implementations of sample are the same.
Modifying the test harness
In Listing 12-6, we create some test data, called list, for the test functions to work on, and we link up the Old and New benchmark functions to the Old and New implementations in the InappropriateCollectionType module.
BenchmarkDotNet offers ways to ensure that time-consuming initializations occur only once globally, or once per iteration. Search online for “benchmarkdotnet setup and cleanup” for details. I haven’t done this here for simplicity. This won’t greatly affect the measurements, but it will have some impact on the time the overall benchmarking process takes to run.
Baseline timings
The key points are that the Old and New methods take similar times (to be expected as they are currently calling identical functions) and that the amount of time per iteration, at over a second, is significant. We have a baseline from which we can optimize!
Avoiding Indexed Access to Lists
One red flag in this code is that it uses indexed access into an F# list: data.[i]. Indexed access into arrays is fine – the runtime can calculate an offset from the beginning of the array using the index and retrieve the element directly from the calculated memory location. (The situation might be a little more complex for multidimensional arrays.) But indexed access to an F# list is a really bad idea. The runtime will have to start at the head of the list and repeatedly get the next item until it has reached the n’th item. This is an inherent property of linked lists such as F# lists.
Indexed access to an F# list element is a so-called O(n) operation; that is, the time it takes on average is directly proportional to the length of the list. By contrast, indexed access to an array element is an O(1) operation: the time it takes on average is independent of the size of the array. Also, it takes no longer to retrieve the last element of an array than the first (ignoring any effects of the low-level caching that might go on in the processor).
First attempt at optimization
In Listing 12-8, we use List.indexed to make a copy of the original list but containing tuples of an index and the original value, for example, [(0, 1.23); (1, 0.98); ...]. Then we use List.filter to pick out the values whose indexes are a multiple of the required interval. Finally, we use List.map snd to recover just the element values as we no longer need the index values.
I had low expectations of this approach, as it involves making a whole additional list (the one with the indexes tupled in); filtering it (with some incidental pattern matching), which will create another list; and mapping to recover the filtered values, which will create a third list. Also, a bit more vaguely, this version is very functional, and we’ve been conditioned over the years to expect that functional code is inherently less efficient than imperative code.
Results of first optimization attempt
The good – and perhaps surprising – news is that this is very nearly an order of magnitude faster: 134ms vs. 1,100ms. The takeaway here is that indexed access to F# lists is a disaster for performance. But the fix has come at a cost: there is a great deal of garbage collection going on, and in all three generations. This aspect should not be a surprise: as we just said, the code in Listing 12-8 creates no less than three lists to do its work, only one of which is needed in the final result.
Using Arrays Instead of Lists
Directly replacing lists with arrays
Providing an array in the test harness
Results of using arrays instead of lists
Again, perhaps this isn’t too surprising: array creation might be a bit more efficient than list creation, but we are still creating three arrays and using two of them only for a brief moment.
Use Sequences Instead of Arrays
Using sequences instead of arrays
Retrieving the sequence
Results of using sequences instead of lists
We reduced the average elapsed time by 70% compared with the previous iteration, and although there is still a lot of garbage collection going on, there is less of it and it is almost all in Generation 0, with none at all in Generation 2. Compared with the original baseline, our code is now more than 50 times faster!
Avoiding Collection Functions
We’ve spent quite a long time tweaking a collection-function-based implementation of sample . The current implementation has the advantage that it is highly idiomatic and has a reasonable degree of motivational transparency. But is it really the best we can do?
Array comprehension instead of list comprehension
In Listing 12-16, I’ve highlighted all the differences from Listing 12-4: all we have to do is use array clamps ( [|...|] ) instead of list brackets ( [...] ) to enclose the comprehension, and Array.length instead of List.length to measure the length of the data. You’ll also need to undo the changes to Program.fs we made in Listing 12-14, as we’re back to accepting and returning an array rather than a sequence, as in Listing 12-11.
Results of using array comprehension instead of list comprehension
Note that in Listing 12-17, the measurements are now shown in microseconds (us) rather than milliseconds (ms) because the New measurement is too small to measure in milliseconds. This is impressive: we’ve now improved execution time from the baseline by an astonishing factor of 80,000, nearly five orders of magnitude. It’s as if we found a shortcut on the journey from New York to Paris that shortened the distance from 6000 kilometers to less than 100 meters. And we’ve done so using only functional constructs: an array comprehension and a yielding-for-loop. I’ve sometimes encountered people who consider this style nonfunctional, but I disagree. There is no mutation, no declare-then-populate patterns, and it’s very concise.
Avoiding Loops Having Skips
Avoiding a skipping for-loop
Results of avoiding a skipping loop
It lowers the motivational transparency of the code, by making it a little bit less obvious what the author was intending to do.
It’s a true microoptimization, with effects that could easily change between architectures or compiler versions. By working at this level, we deny ourselves any potential improvements in the way the compiler and runtime work with respect to skipping loops.
The code is much riskier, with a complicated calculation for defining the upper bound of the loop. (It took me no less than six attempts to get it right!) In going down this route, we are laying ourselves open to off-by-one errors and other silly bugs: exactly the kind of thing that idiomatic F# code excels at avoiding.
Inappropriate Collection Types – Summary
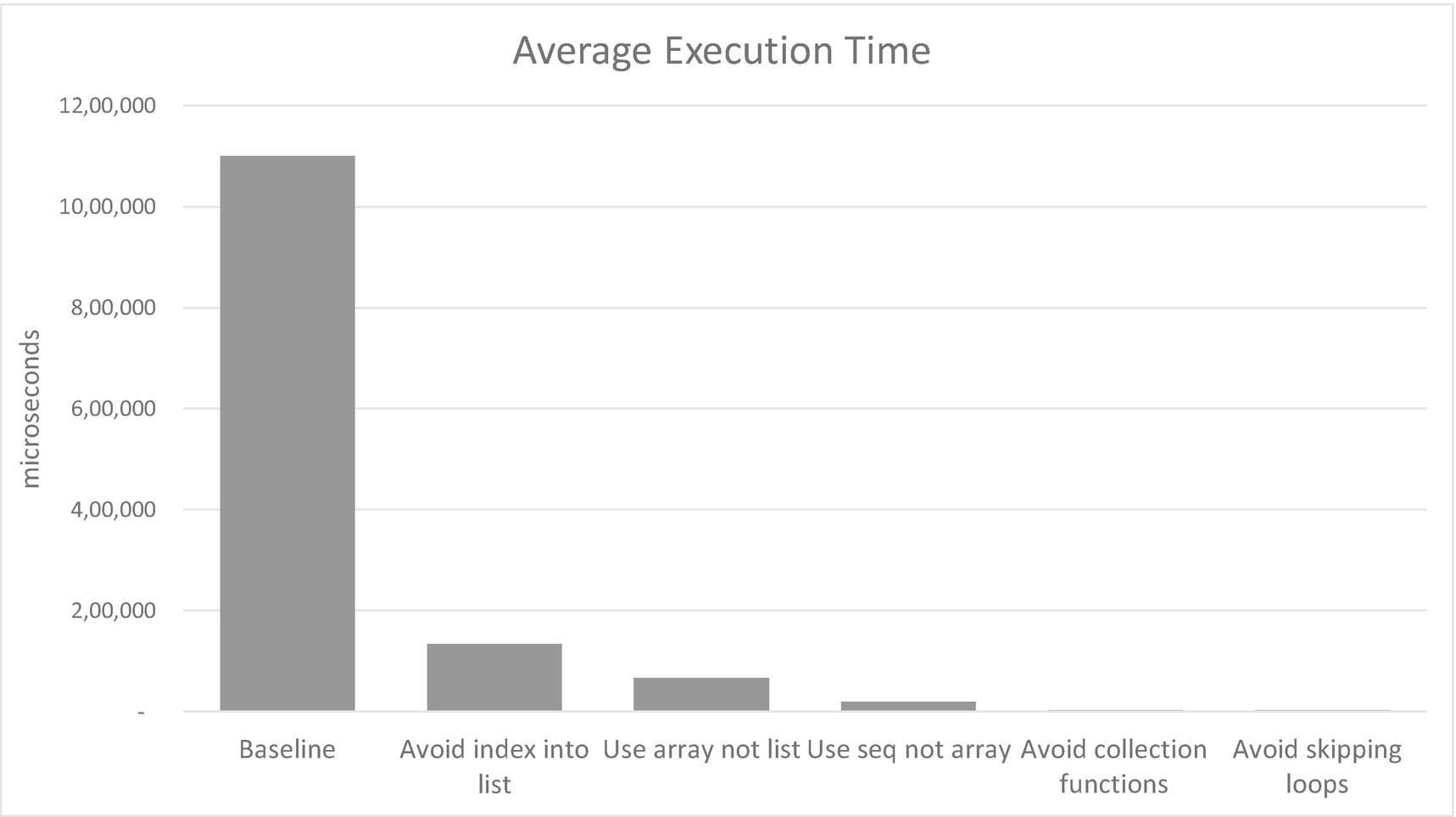
Impact of various improvements to collection usage
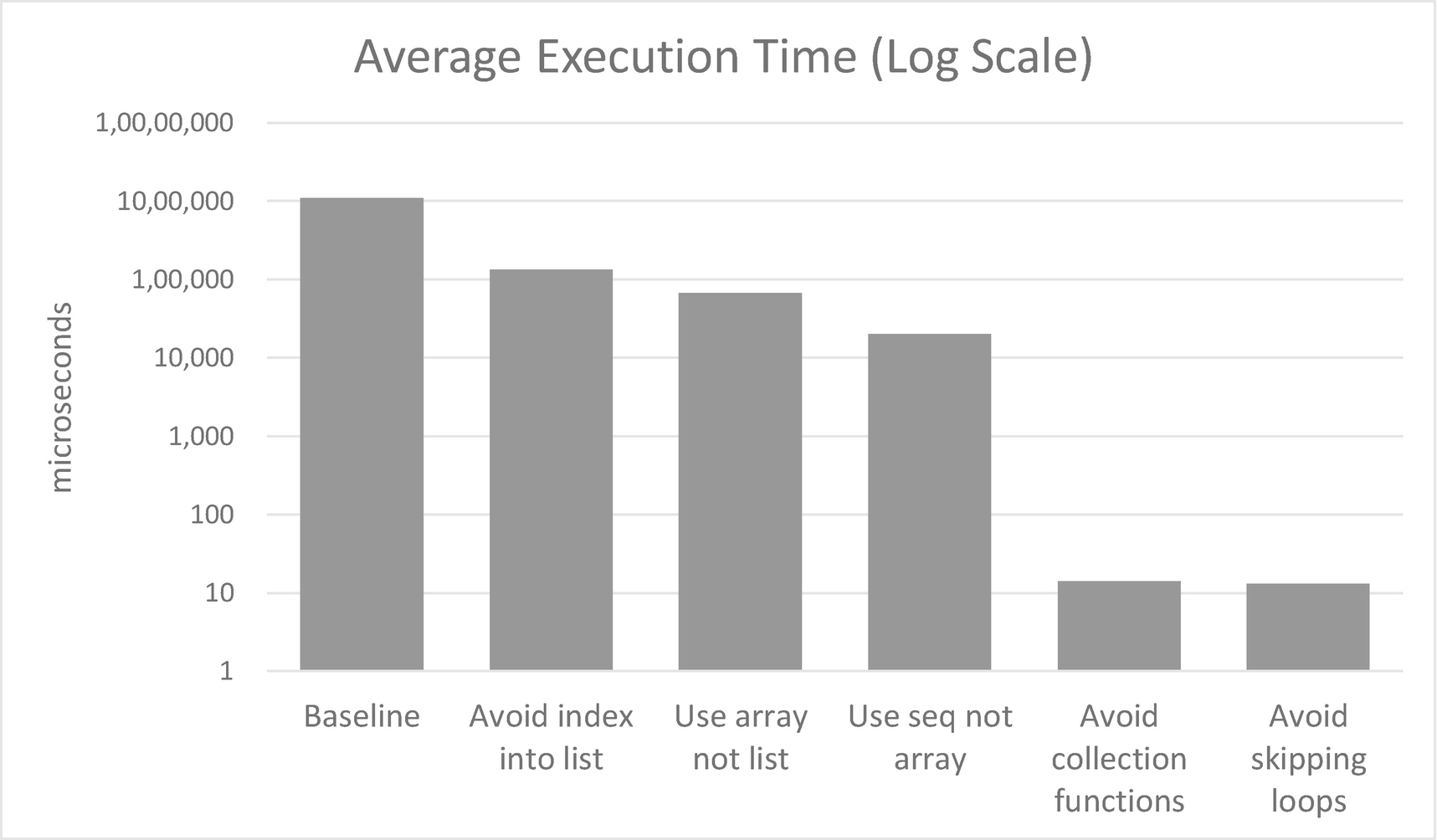
Impact of various improvements to collection usage on a log scale
Don’t do indexed access into F# lists – that is, myList.[i]. Either use a different collection type or find another way of processing the list.
Be familiar with the performance characteristics of the collection data structures and functions that you are using. At the time of writing, these functions are somewhat patchily documented regarding their time complexity (O(n), O(1), etc.), so you may have to do a little online searching or experimentation to pin this down. Don’t default to using F# lists just because they might be considered more idiomatic. Unless you are playing to the strengths of lists (which boils down to use of the head::tail construct), arrays are often the better choice.
Pipelines of collection functions (.filter, .map, and so forth) can have decent performance, provided you choose the right collection type in the first place.
Sequences (and functions in the Seq module) can sometimes be a way of expressing your logic in terms of pipelines of collection functions, without the overhead of creating and destroying short-lived collection instances.
Comprehensions (e.g., placing code in array clamps and using yield or a for...-> loop) can have stellar performance. Don’t be fooled into thinking such code is in some way “not functional” just because the for keyword is involved.
Beware of low-level microoptimizations: Are you denying yourself the benefits of potential future compiler or platform improvements? Have you introduced unnecessary risk into the code?
Case Study: Short-Term Objects
An oft-quoted dictum in .NET programming is that you shouldn’t unnecessarily create and destroy large numbers of reference types because of the overhead of allocating them and later garbage collecting them. How true is this in practice, and how can we avoid it?
The required API for a point-searching function
A 3D point class that can do distance calculations
The type from Listing 12-21 can do the required distance calculation, but you might notice it contains other things – a mutable Description field and a ToString override – which we don’t particularly need for the requirement. This is pretty typical in an object-oriented scenario: the functionality you need is coupled with a certain amount of other stuff you don’t need.
First cut of the withinRadius function
As in the previous section, the Old and New implementations are the same initially. Note also that we use a type alias (type Float3 = (float * float * float)) to avoid repeating the tuple of three floats throughout the code.
We do the required selection by mapping the incoming array of tuples into Point3d instances and filtering the result using the DistanceFrom instance method. Finally, we map back to an X, Y, Z tuple, as the requirement states we have to return tuples, not Point3d instances.
Integrating the 3D distance calculation with benchmarking
Results of a baseline run
The statistics in Listing 12-24 aren’t as bad as I’d feared – the average execution time works out at about 0.17 microseconds per input position. Not terrible, though of course that depends entirely on your objectives. Over 50Mb of memory is being allocated during processing, which might have an effect on the wider system, and there are garbage collection “survivors” into Generations 1 and 2. The .NET garbage collector is pretty good at collecting so-called “Generation 0” items, but for every extra generation that an object survives, it will have been marked and copied, and all pointers to it will have been updated. This is costly! So can we improve on our baseline?
Sequences Instead of Arrays
Using sequences instead of arrays
Results of using sequences instead of arrays
Avoiding Object Creation
Maybe it’s time to question the whole approach of creating Point3d instances just so we can use one of Point3d’s methods. Even if you didn’t have access to Point3d’s source code, you’d probably be able to code the calculation for a 3D distance yourself, based on the widely known formula √((x1–x2)2 + (y1-y2)2 + (z1-z2)2).
Avoiding object creation
Results of avoiding object creation
Reducing Tuples
Reducing tuples
Result of reducing tuples
Using Struct Tuples
Using struct tuples
Providing struct tuples
Results of moving to struct tuples
Operator Choice
We seem to be scraping the bottom of the barrel in relation to memory management. Does anything else stand out as being capable of improvement? What is the code doing most?
Using pown instead of the ** operator
Results of using pown instead of the ** operator
Part of the compiler logic behind the ** operator
Avoiding using pown for squaring
Results of avoiding using pown
We’ve now achieved a gain of 98% over the original implementation. It’s probably time to stop scraping the barrel.
Short-Term Objects – Summary
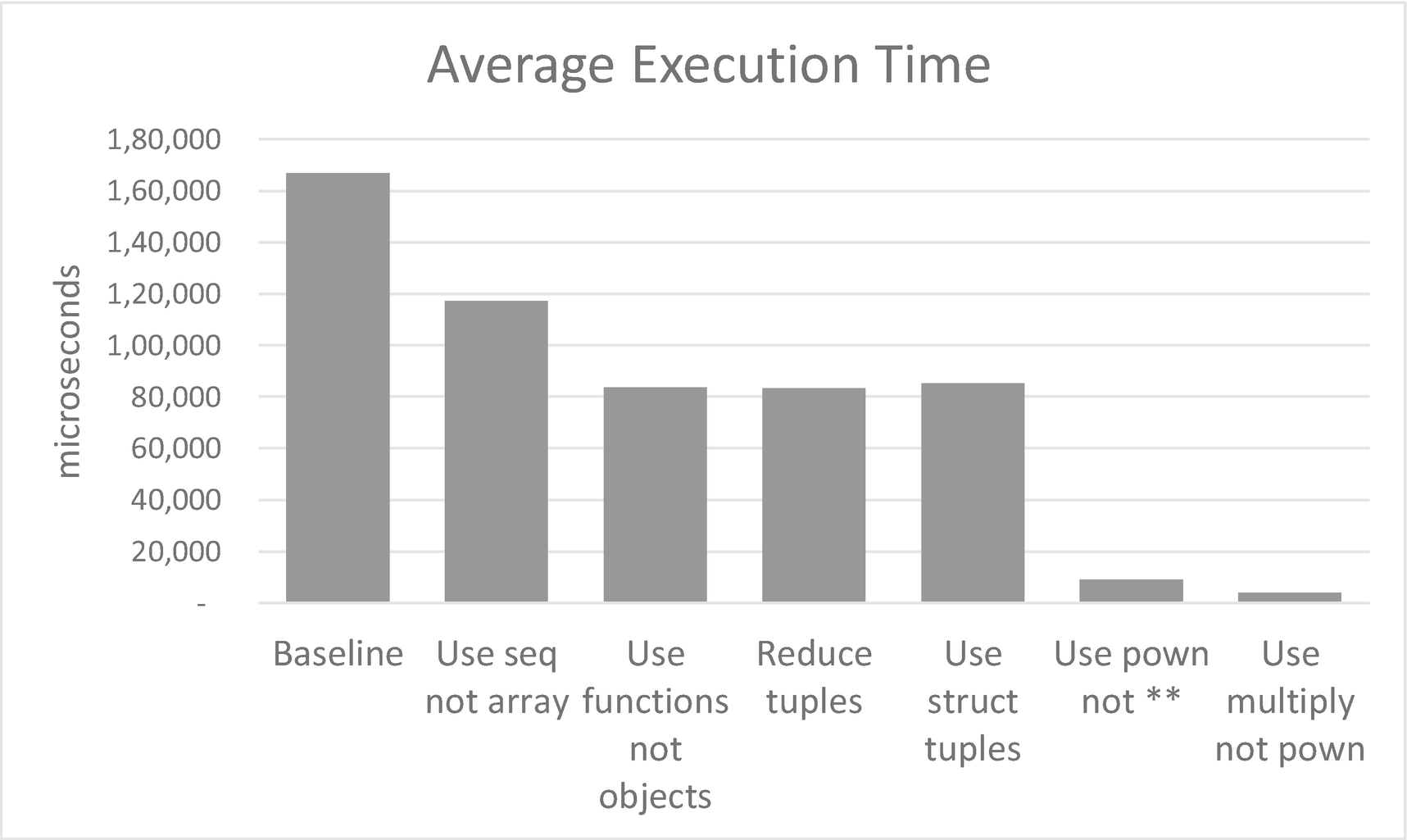
Impact of various improvements to object usage
The results are dominated by one kind of change: not the way we use objects or collections, but our choice of operator to do the distance calculation.
If many reference objects are placed into collections, the collections and their functions can have a bearing on performance over and above the cost of the objects themselves. For example, when dealing with long lists of reference type instances, pipelines of sequence functions can be better than pipelines of array functions.
Think about why you are creating objects. Could the methods you are calling be factored out into stand-alone functions, meaning that the whole object-instantiation/collection issue goes away (unless those functions themselves allocate memory)? Refactoring into independent functions has additional benefits in terms of conciseness, decoupling, and testability.
Concerns about allocation of tuples, and the possible gains from using struct tuples, can be important, but quick wins are not guaranteed.
Though discussions of performance in .NET languages often focus on memory management, this is far from being the whole story. Consider algorithms and operators as well.
Only use ** for raising to noninteger exponents. Use pown when raising to integer exponents, and also consider simple self-multiplication when the exponent is known in advance (e.g., squaring, cubing, etc.). More generally, remember there is a trade-off between how generic and general-purpose things are (such as the generic ** operator) and how efficient they are.
Case Study: Naive String Building
As developers, we often find ourselves building up strings, for example, for formatting values in UIs or data exports, or sending messages to other servers. It’s easy to get wrong on .NET – but fortunately not too hard to get right either.
For this section, we’ll imagine we’ve been tasked with formatting a two-dimensional array of floating-point values as a single CSV (comma-separated values) string, with line ends between each row of data. For simplicity, we’ll assume that F#’s default floating-point formatting (with the "%f" format specifier) is sufficient. We’ll further assume that the array, while not trivial, fits in memory and that its CSV also fits in memory, so we don’t need a fancy streaming approach.
First cut of a CSV builder
Integrating CSV generation with benchmarking
Results of naive CSV string building
This is not good. Building the CSV for our relatively modest 500 x 500 array takes over a second and allocates an astonishing 3GB of memory. There is garbage collection going on in all three generations. Imagine you’d put this code on a web server for, say, generating client downloads for scientific or banking customers. You would not be popular! The reason things are so bad is the level at which we are mutating things. Every time we do a result <- sprintf..., we are discarding the string object that was previously referred to by the label result (making it available for garbage collection in due course) and creating another string object. This means allocating and almost immediately freeing vast amounts of memory.
StringBuilder to the Rescue
Using StringBuilder for string concatenation
Result of using StringBuilder for string concatenation
Using String.Join
It’s too much code for what must surely be a commonly required operation: joining a set of strings together with some separator at the joins.
At the end of the string building process, we have to go back and trim off the final separator.
Using String.Join
Result of using String.Join
Using Array.Parallel.map
Using Array.Parallel.map
Result of using Array.Parallel.map
A couple of things to be aware of when using Array.Parallel.map. First, its impact will obviously be very dependent on the number of available cores. It’s not uncommon for cheaper cloud instances (e.g., on Microsoft Azure) to have fewer cores than a typical developer machine, so the in-production speedup may be disappointing. You may have to experiment with running your benchmarks on a cloud instance to clarify this. And second, try not to nest Array.Parallel operations. You will rapidly bump into the law of diminishing returns.
Using String Interpolation
Using Seq.map instead of Array.map.
Using String.Format instead of F#’s sprintf to format the floating-point values into strings:
let cols = data |> Array.Parallel.map (fun x -> String.Format("{0}", x))
Using F# string interpolation.
Using string interpolation
Result of using string interpolation
Overall, we’ve achieved approximately a 72-fold improvement in performance and two orders of magnitude less memory allocation.
Naive String Building – Summary
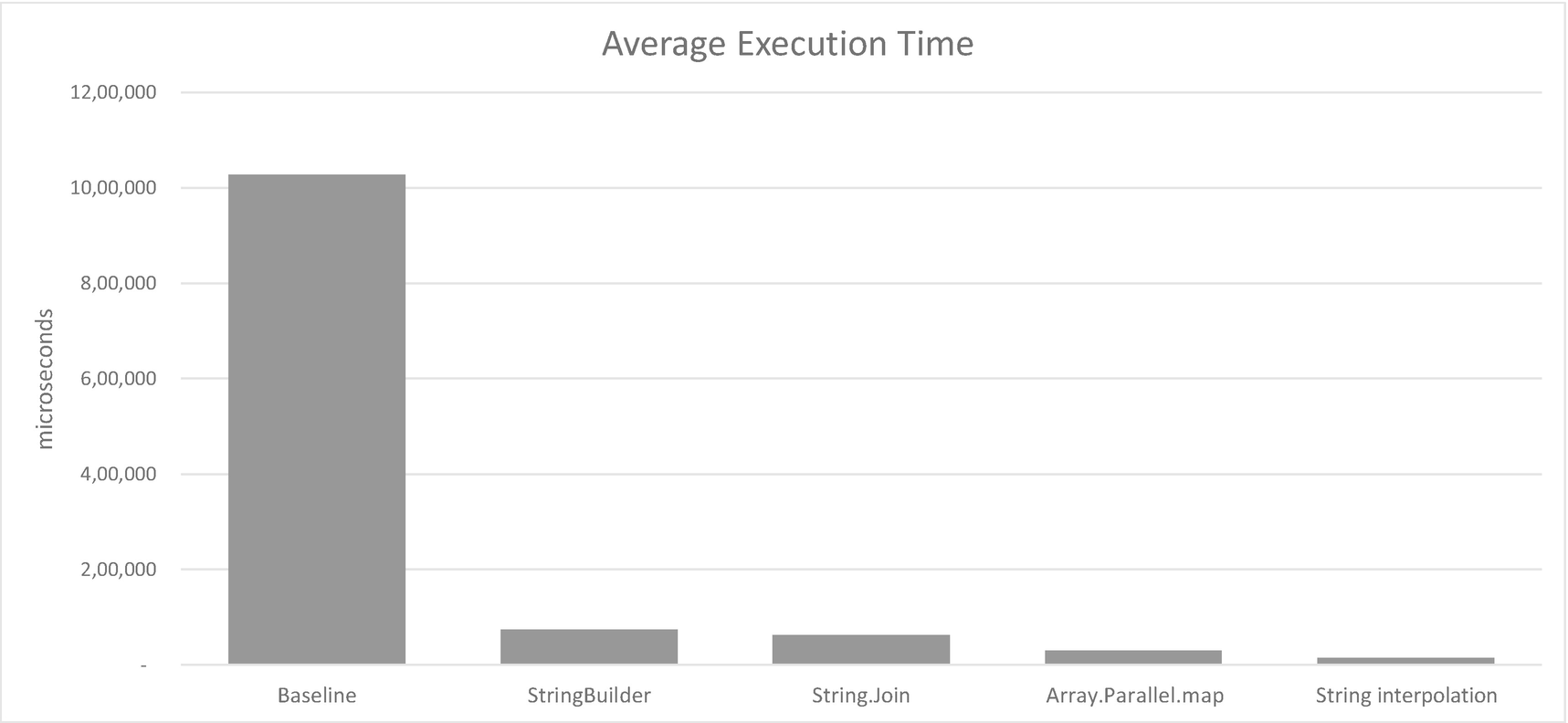
Impact of various improvements to string building
Mutating string instances really means discarding and replacing the entire instance with another one. This is a disaster for performance.
The .NET StringBuilder class is optimized for exactly this requirement and can offer a huge speed and memory efficiency boost.
When joining strings together with a separator, String.Join gives good performance with minimal code.
Using Array.Parallel.map gives a great low-code-impact speed boost. Bear in mind the number of cores on the machine where the code will be running live. Nest Array.Parallel.map operations at your peril.
It’s well worth experimenting with alternatives to sprintf for formatting values. In this case, string interpolation halved our execution time.
Other Common Performance Issues
I should mention a few other common performance issues. We don’t have room for case studies for these, but a brief description should be enough to help you avoid them.
Searching Large Collections
If you find yourself repeatedly searching through large collections using Array.find, Array.tryFind, Array.contains, and so forth, consider making the collection an F# Map, a .NET Dictionary, or some other collection optimized for lookup.
Comparison Operators and DateTimes
If you need to do large numbers of less-than, greater-than, or equality comparisons with DateTime or DateTimeOffset instances, consider using DateTime.CompareTo or DateTimeOffset.CompareTo. At the time of writing, this works about five times faster (in a brief informal test) than =, >, >=, <, and <=.
Concatenating Lists
The @ operator concatenates two F# lists. This is a relatively expensive operation, so you may want to avoid doing it in performance critical code. Building up lists using the cons operator (::) is OK (assuming that a list is otherwise suitable for what you are doing) because that’s what linked lists are optimized for.
For-Loop with Unexpected List Creation
A right way and a wrong way to write a simple indexed for-loop
The first is a simple for-loop and is correct. The second instantiates a list instance with 10,000 elements and iterates over the list. The body of the loops could be the same, and the second would perform much more slowly and would use more memory.
F# and Span Support
System.Span<T> is a new value type at the heart of .NET. It enables the representation of contiguous regions of arbitrary memory, regardless of whether that memory is associated with a managed object, is provided by native code via interop, or is on the stack. And it does so while still providing safe access with performance characteristics like that of arrays.
Usage of Span is too low level an undertaking to go into detail here, but if you are really struggling for performance and you think working directly with a range of memory might help, you can do so using F#’s support for Span.
The Importance of Tests
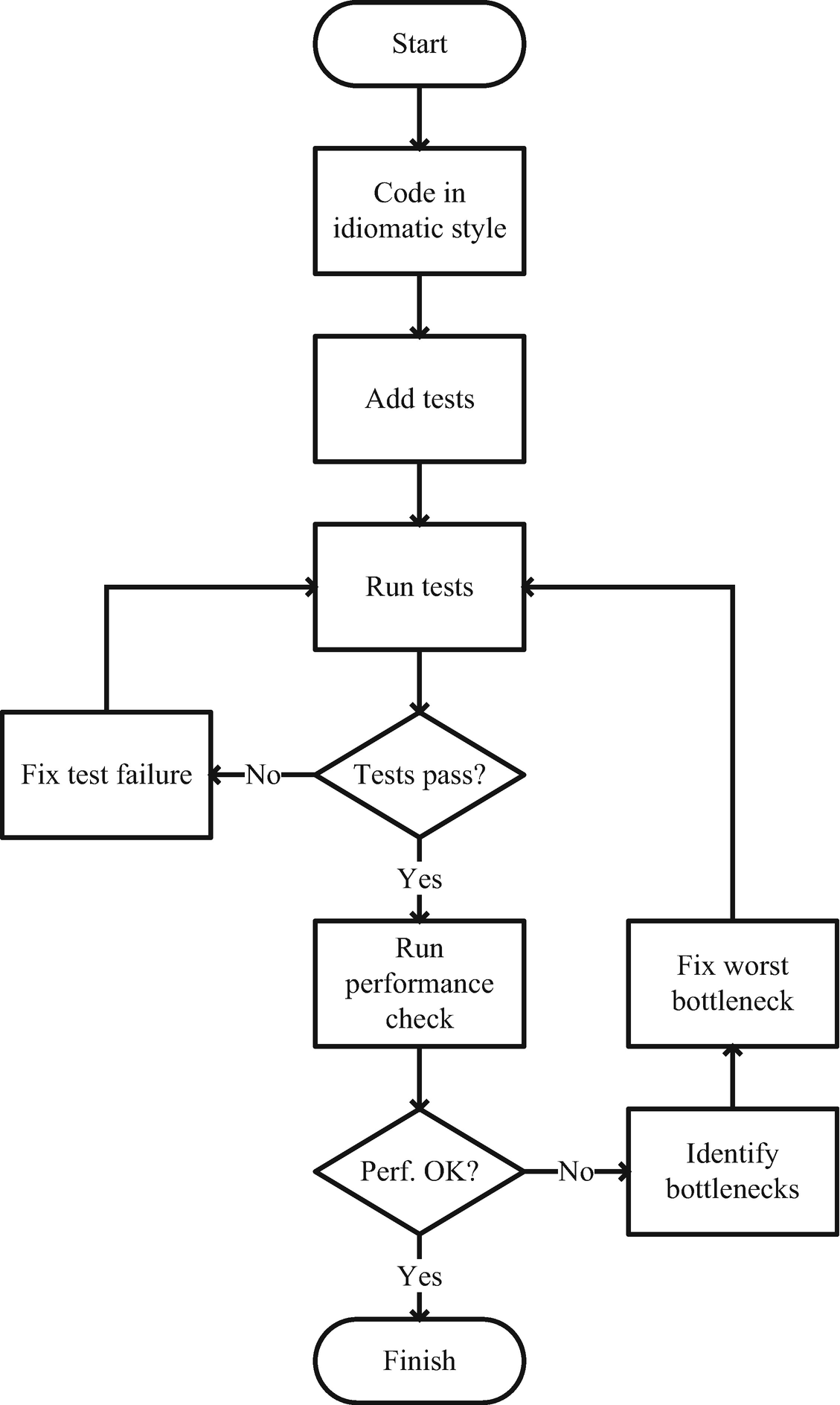
Workflow for running tests and checking performance
You might shortcut the process a bit by doing several performance optimization passes before rerunning tests. But the important thing is that nothing gets included in your product that doesn’t both pass functional tests and have acceptable performance.
This is especially true when replacing pipelines of collection functions with more handcrafted logic. The lower the level of abstraction you are working at, the more potential there is for silly off-by-one errors and so forth: just the kinds of things that one avoids if one sticks to using collection functions.
Recommendations
When performance is important, have a method for measuring it in a simple and repeatable way. BenchmarkDotNet is a good choice.
Be keenly aware of the performance characteristics of any collection types and functions you are using. Indexed access into F# lists and list concatenation with @ are traps that are particularly easy to fall into.
Instantiating and later destroying reference values (i.e., classes) have a cost. Be mindful of whether those objects need to exist – could a function do the work instead?
When instances are in a collection, the type of collection used can also affect memory behavior. Using sequence functions instead of concrete collection functions for intermediate steps in a pipeline can sometimes help (e.g., Seq.map instead of Array.map).
Although discussion of .NET performance often focuses on the memory footprint and life cycles of objects, other considerations, such as the choice of operators, can sometimes have a greater impact. Remember the impact of using ** vs. pown or simple multiplication.
Naive string building is a common source of performance problems. StringBuilder and String.Join can help. String interpolation can be faster than sprintf.
Array.Parallel.map can have a big impact on performance when multiple cores are available. Add it as a last step when you are sure the mapping function itself is efficient.
When dealing with DateTimes and DateTimeOffsets, CompareTo is currently faster than comparison operators such <, >, and =.
Don’t use for x in [y..z] unless you really did intend to create a collection of values to iterate over. Omit the brackets.
You can get great improvements in performance without moving away from a functional, immutable style. Beware of microoptimizations that make your code less reliable, less maintainable, and less likely to benefit from future compiler or platform enhancements.
Summary
Optimizing F# code can be a pleasure rather than a chore, provided you set up good benchmarks and code with a degree of mechanical sympathy. Code a baseline version that works, bearing in mind the principles of motivational transparency and semantic focus. While you should avoid obvious howlers (like indexed access into F# lists), you shouldn’t worry overly much about performance during this step. Ensure tests and benchmarks are in place for this baseline version. Then tackle bottlenecks. You can often achieve improvements of several orders of magnitude without compromising the clarity and maintainability of your code.
Finally, I want to say a big thanks to the authors and maintainers of BenchmarkDotNet. It’s an awesome library, and we’ve only skimmed the surface of its capabilities here.
In the next chapter, we’ll move our focus back from the computer to the human and discuss how to use code layout and naming to maximize the readability and hence the revisability of our code.
Exercises
Assuming that the old and new transaction collections don’t have to be F# lists, how could you speed up the system with minimal code changes?
Would you expect this to improve performance? Why/why not?
What impact does doing this have on performance?
You can get rid of the buildLine function in your new version.
Remember there is an Array2D module.
You won’t be able to work in parallel.
Exercise Solutions
Generally speaking, the suggested change would be slower. This is because the Array.Parallel.map operation creates a whole new array, which we then filter.
I found the performance results were considerably worse than the prior (Listing 12-46) version, taking 78ms when run in a notebook, rather than 38ms.
This is at least partly because we are no longer doing an Array.Parallel.map to generate the string representations. There is no Array2D.Parallel.map.