
Mystification is simple; clarity is the hardest thing of all.
—Julian Barnes, English Novelist
Why a Style Guide?
In this chapter, I will talk a little about why we as F# developers need a style guide and what such a guide should look like. I’ll also outline a few principles that, independent of language, great developers follow. These principles will be our guiding light in the many decisions we’ll examine in future chapters.
One of the most common issues for developers beginning their journey into F# is that the language is neither old enough nor corporate enough to have acquired universally accepted and comprehensive idioms. There simply isn’t the same depth of “best practice” and “design patterns” as there is in older languages such as C# and Java. Newcomers are often brought to a standstill by the openness of the choices before them and by a lack of mental tools for making those choices.
Traditionally, teams and language communities have dealt with this kind of problem by adopting “coding standards,” together with tools to support and enforce them, such as “StyleCop” and “ReSharper.” But I must admit to having a horror of anything so prescriptive. For me, they smack too much of the “human wave” approach to software development, in which a large number of programmers are directed toward a coding task, and “standards” are used to try and bludgeon them into some approximation of a unified team. It can work, but it’s expensive and depressing. This is not the F# way!
Understanding Beats Obedience
So how are we to assist the budding F# developer, in such a way that their creativity and originality are respected and utilized, while still giving them a sense of how to make choices that will be understood and supported by their peers? The answer, I believe, is to offer not coding standards, but a style guide. I mean “guide” in the truest sense of the word: something that suggests rather than mandates and something that gives the reader the tools to understand when and why certain choices might be for the best and when perhaps the developer should strike out on their own and do something completely original.
In coming to this conclusion, I’ve been inspired by Steven Pinker’s superb guide to writing in English, The Sense of Style (Penguin Books, 2014). The book is a triumph of guidance over prescription, and my hope is to set the same tone here. Pinker makes the point that stylish writing isn’t merely an aesthetic exercise: it is also a means to an end, that end being the spread of ideas. Exactly the same is true of stylish coding, in F# or any other computer language. The aim is not to impress your peers, to adhere slavishly to this or that “best practice,” or to wring every possible drop of processing power out of the computer. No, the aim is to communicate. The only fundamental metric is how effectively we communicate using our language of choice. Therefore, the measure of the usefulness of a style guide is how much it improves the reader’s ability to communicate with peers, and with the computer, via the code they write.
Good Guidance from Bad Code
Let’s begin by defining what kinds of communication problems we are trying to avoid. We can get to the bottom of this by looking at the common characteristics of code bases which everyone would agree are bad. Avoid those characteristics and we can hope that our code can indeed communicate well!
Regardless of the era or technology involved, hard-to-work-with code bases tend to have the following characteristics in common.
Characteristic 1: It’s hard to work out what’s going on when looking closely at any particular piece of code.
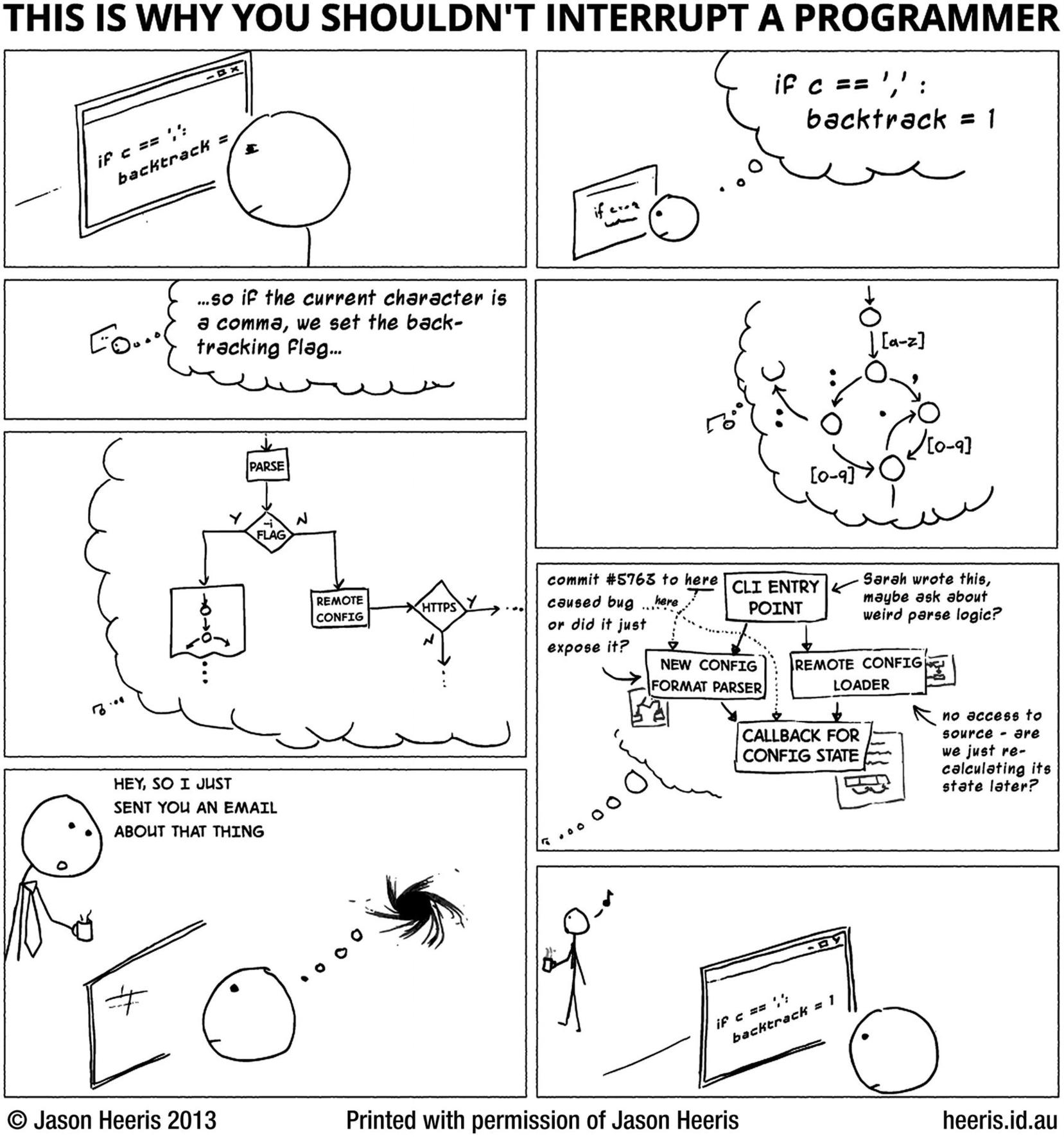
This is why you shouldn’t interrupt a programmer
Interrupting busy programmers is bad, but the whistling coffee carrier isn’t the only villain in this cartoon. The other is the code, which requires the developer to keep so much context in their personal working memory. When we write such code, we fail to communicate with people (including our future selves) who will have to maintain and extend it.
I’ll describe the kind of code that isn’t readable with minimum context as having poor semantic focus. In other words, relevant meaning isn’t concentrated in a particular place but is spread about the code base.
Code with bad semantic focus
It is literally impossible to predict the behavior of this code without looking at other code elsewhere. What are checkRate and checkAmount doing? Is it OK that the value interestType can be any value from 2 upward with the same result? What happens when any of the parameters is negative? Or are some or all of the invalid range cases prevented elsewhere, or within checkRate and checkAmount? Could those protections ever get changed by accident?
And you can bet that when you see code like this, then the other code you then have to look at, such as the bodies of checkRate and checkAmount, is going to have similar issues. The number of “what if?” questions increases – literally exponentially – as one explores the call chain.
By the way, when I was writing this example, part of me was thinking “no professional would ever do this,” and a larger part of me was remembering all the times when I had seen code exactly like it.
Characteristic 2: It’s hard to be sure that any change will have the effects one wants, and only those effects.
Can I refactor with confidence, or does the mess I’m looking at conceal some special cases that won’t be caught properly by apparently cleaner code?
Can I extend the code to handle circumstances it wasn’t originally designed for and be confident that both the old circumstances and the new circumstances are all correctly handled?
Could the code here be undermined in the future by some change elsewhere?
Again, this is fundamentally a failure of communication with a human audience.
I’ll describe code that is difficult to change safely as having poor revisability because the consequences of any local revision are not readily predictable.
I’ll give some specific examples in Chapter 5, but I’ll bet that if you’ve been in the industry more than 5 minutes, you can provide plenty of your own!
Characteristic 3: It’s hard to be certain of the author’s intent.
What did the author mean by a particular section of code? Does the code actually do what they apparently think it should do? Is that even the right thing in the context of the system as a whole?
If there appear to be gaps in the logic in the code, did the author realize they were there? Who is wrong, the author or the reader?
If there are logic gaps, are the circumstances where they could manifest themselves prevented from occurring, or are the resulting errors handled elsewhere? Or have they never happened due to good luck? Or do they sometimes happen, but no one noticed or complained?
As if reading code wasn’t hard enough, the maintainer is now placed in a position of having to read the mind of the original author, or worse still, the minds of every author who has touched the code. Not the recipe for a good day at work and another failure to communicate.
I’ll describe the kind of code where the author’s intentions are unclear as having poor motivational transparency. We can’t readily tell what the author was thinking and whether they were right when they were thinking it.
Code with bad motivational transparency
My problem with this code is that request is used both as an object embodying a client request and as a sort of break marker, used to transport to the end of the loop the fact that response.IsTruncated has become true. Thus, it forces you to carry two distinct meanings of the label "request" in your head.
This immediately makes the reader start wondering, “Is there some reason why the author did this, something which I’m not understanding when I’m reading the code? For example, will any resources allocated when request was instantiated be released promptly when the assignment to null occurs? Was this therefore an attempt at prompt disposal?” (Would you know, without googling it, if resources are disposed promptly on assignment to null? I have googled it and I still don’t know.) This is on top of the mental overhead caused by the way the code has to transport state (KeyMarker and VersionIdMarker) from the response to the request. Admittedly, this isn’t the sample author’s fault as it is part of the API design, but with some careful coding, it might have been possible to mitigate the issue.
All in all, reading this code starts a great many mental threads in the user’s head, for no good reason. We can do better.
Characteristic 4: It's hard to tell without experimentation whether the code will be efficient.
Any algorithm can be expressed in myriad ways, but only a very few of these will make decent use of the available hardware and runtime resources. If you’re looking at code with a tangle of flags, special cases, and ill-thought-out data structures, it is going to be very difficult to keep efficiency and performance in mind. You’ll end up getting to the end of a hard day fiddling with such code and thinking: “Oh well, at least it works!” As data volumes and user expectations grow exponentially, this will come back to bite you – hard!
I’ll describe code that isn’t obviously efficient as having poor mechanical sympathy.
Again, it’s a failure of communication. The code should be written in a way that satisfies both the human and electronic audiences, so the human maintainer can understand it, and the computer can execute it efficiently. I’ll give some bad and good examples in Chapter 12.
Generally, the term “mechanical sympathy” means the ability to get the best out of a machine by having some insight into how the machine operates. In a world of perfect abstractions (such as perfect automatic gearboxes or perfect computer languages), we wouldn’t need mechanical sympathy. But we do not yet live in such a world. Incidentally, the term is sometimes attributed to racing driver Jackie Stewart, but although he used it, a quick glance at Google Ngrams suggests it predates him as a well-used phrase.
What About Testability?
If you are worrying that I have missed out another characteristic of bad code, poor testability, don’t worry. Testability is always at the forefront of my mind, but it’s my belief that it would be hard to write code that had good semantic focus, good revisability, good motivational transparency, and good mechanical sympathy, without it automatically turning out to have good testability. Test-driven design aficionados would put the cart and the horse the other way around, which is fine by me, but it’s not the way I want to tackle things in this book.
Complexity Explosions
Everyone would agree that maintaining bad, poorly communicating code is an unpleasant experience for the individual. But why does this matter in a broader sense for software engineering? Why should we spend extra time polishing code when we could be rushing on to the next requirement?
Duplicating code, because that feels safer then generalizing existing code to handle both old and new cases
Programming by coincidence, in which one keeps changing code until it “seems to work,” because the code is just too hard to reason about comprehensively
Avoiding refactoring, because it seems too risky or time consuming in the short term to be worth doing
The reason why I refer to such situations as explosions is because these bad practices lead to further uncertainty, which leads to more widespread bad practice, and so forth. Complexity explosions are the reason why, when joining a team working on an established code base, the new developer is so often tempted to say, “Shouldn’t we just rewrite the whole thing?” Complexity explosions are expensive and hard to recover from! To prevent them, it’s important to write code that doesn’t put others (or your future self) into a position where the sins look more tempting than the path of righteousness.
Everything about this book is designed to help you minimize the risk of complexity explosions. If any of the techniques I suggest seem a little hard at first, consider the cost and pain of the alternative!
Summary
I hope I’ve convinced you that writing good code is a worthwhile investment of time and that I’ve helped you spot some of the characteristics of bad code so that you can see the practical advantages of every recommendation in this book.
The great news is that the F# language makes it easier than ever to avoid writing bad code, by making it easy to write programs that are semantically focused, revisable, motivationally transparent, and mechanically sympathetic. In the following chapters, you’ll learn to write such great code and to enjoy doing it. For once in life, the path to righteousness is downhill!