
8
From Human and Social Indexing to Automatic Indexing in the Era of Big Data and Open Data
8.1. Introduction
Today, information occupies a central place in our daily life. It represents a source of knowledge and power. In the era of Big Data and Open Data, a huge amount of information, documents, multimedia content and social tags are created, managed and stored electronically, which explains the exponential growth of data flows from a wide variety of fields that have led to the creation of an unprecedented amount of data. With this huge amount of data, it is becoming increasingly difficult to respond to user queries that are looking for relevant document results (Khemiri and Sidhom 2020). This is why new methods and algorithms have emerged to better represent the information collected from heterogeneous sources. In order to make these documents usable, a human (i.e. manual or intellectual) and/or an automatic indexing process allows us to create a document representation by a list of metadata, descriptors and social tags. These representations are used to find relevant information in a scalable collection of documents, to respond to user requests (information needs). In this context, numerous research works have been carried out to put forward indexing approaches. The ultimate goal of these different approaches is to better represent content (documents, electronic content, Big Data and Open Data) to effectively identify those that are most relevant when searching for information. This chapter presents a state of the art of approaches and methodologies ranging from manual and automatic indexing to algorithmic methods in the era of Big Data and Open Data.
8.2. Indexing definition
Indexing is a process of representing information which consists of identifying the significant elements to characterize multimedia documents (i.e. audio, images, text, video). This process analyzes documents to assign or extract a list of descriptors, metadata and social tags. These representations will subsequently facilitate the search for information in a collection of documents. With this in mind, an information retrieval system (IRS) must be composed of three principal functions (see Figure 1):
– representing document content;
– representing user information needs (user request or query);
– comparing these two representations in order to find documents, ordering the search results by relevance and returning the documents to the user.
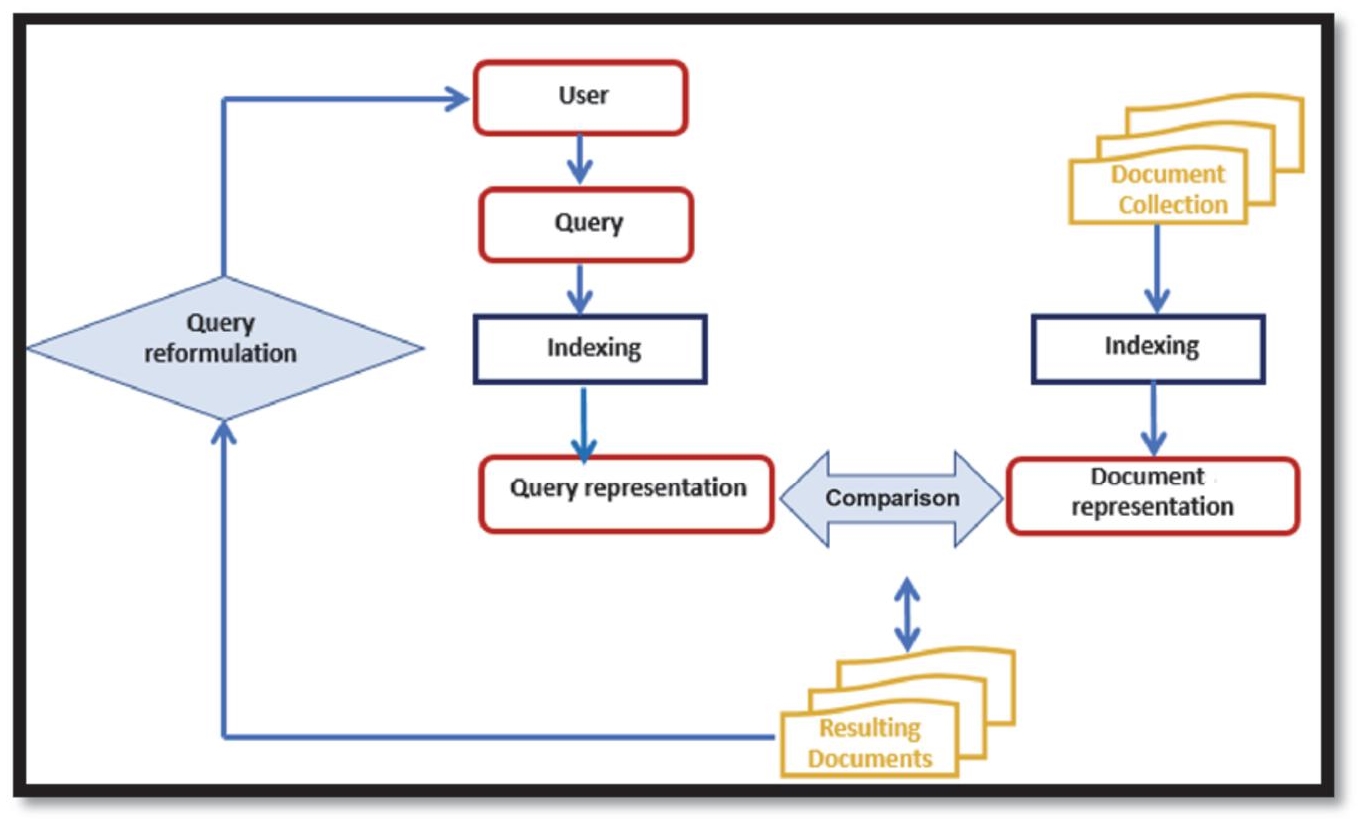
Consequently, the performance of the IRS depends on the choice of the representation model and the matching process. There are three approaches that can be distinguished: the manual indexing approach, the automatic indexing approach and the semi-automatic indexing approach (combining an automatic approach with a manual approach).
8.3. Manual indexing
Manual indexing (i.e. intellectual or human indexing) is based on associations between words in a document with controlled vocabulary terms (manually assigned indexing terms). The choice of terms that represent each document (descriptors) depends on the know-how of the indexer, their knowledge and practical experience in the field of indexing. The human indexer uses a documentary language such as the thesaurus which provides a hierarchical dictionary (controlled vocabulary) of pre-established monolingual or multilingual standard terminologies to index documents. This type of approach allows classification and research by concepts (subjects or themes) in a collection of documents. Manual indexing is the result of document content analysis which is based on the following four steps:
– Documentary analysis (document analysis): the indexer must have global knowledge of the document to be analyzed. To analyze a document, they first consult the title, the table of contents, the summary, the introduction, the introductions and conclusions of the chapters (if they exist) and the conclusion. This speed-reading allows the indexer to identify the main subject or theme discussed or described in the document.
– The choice of concepts (keywords): to define the main concepts that best characterize a document, the indexer must answer a certain number of questions, those that a user would ask when searching for information such as: who and what is the document about? Where and when?
– Conversion of concepts into descriptors: the indexer chooses the appropriate index terms (the descriptors) from a controlled vocabulary list. A controlled vocabulary is a finite set of index terms from which all index terms must be selected. Only the approved terms can be used by the indexer to describe the document which ensures uniformity in the representation of the document (Chaumier and Dejean 1990).
– Proofreading and revision: during this step, the indexer decides to retain or reject some descriptors.
Human indexing has several disadvantages. It is costly in terms of money, vocabulary building time and assignment of concepts (index terms) to documents. It is subjective, since the choice of indexing terms depends on the indexer and their level of knowledge of the target domain. Although indexers follow the same steps, different concepts can be selected to characterize the same document. Also, controlled documentary language is difficult to maintain since the terminology is constantly evolving. When there is a high volume of documents, manual indexing becomes tedious and practically inapplicable (Clavel et al. 1993). Given the limits of manual indexing, the time and performance requirements, some documentary functions such as manual indexing should be automated.
8.4. Automatic indexing
With the advent of computers, researchers have realized that they can use automatic techniques and software methods to index a collection of documents in order to facilitate searching for information and obtain precise results with a reduced time and resources. Several factors have encouraged computer scientists, library and information science researchers to find new automatic methods that try to enrich or replace manual indexing. The automation of indexing has helped to overcome the limits and inadequacies of intellectual indexing approaches such as cost and subjectivity. Unlike human indexing, automatic indexing uses a free vocabulary formed by extracting key terms (a single word or a group of words) characterizing documents. Many statistical and/or linguistic indexing methods have been proposed to automatically extract the representative terms of a document.
8.4.1. Statistical indexing methods
Statistical methods of automatic indexing are based on purely mathematical and statistical calculations in order to define the weight of a word, according to different criteria such as:
– Word frequency: the weight of a word is calculated according to the number of occurrences (how many times a word appears in a document). The most frequent words in the document are the most significant and will serve as a descriptor. We can eliminate unimportant words (i.e. stop words, grammatical words). Stop words are basically a set of commonly used words in any language. Determinants, pronouns, prepositions, conjunctions and grammatical adverbs are stop words. We should rather focus on the important words (i.e. content words, open-class words and lexical words) those that have meaning. Nouns, adjectives, verbs and adverbs are content words;
– Word density: the density of a word is calculated according to the ratio between its occurrence in the document and the size of this document.
– Word position in a document: the word position in a document can have an influence on its weighting. For example, the position of the word in the title is more advantageous than at the end of the document.
– Word writing style: give the advantage to words in capital letters and in bold in the weighting.
– Etc.
In information retrieval, there is a multitude of similarity measures in the literature. The best-known are TF-IDF (Term Frequency-Inverse Document Frequency) (Salton and McGill 1983), Dice similarity (Sneath and Sokal 1973), Jaccard similarity (Grefenstette 1994), character n-gram similarity (Shannon 1984), hidden Markov models (Baum and Petrie 1966), Levenshtein distance (Levenshtein 1965) and the Jaro–Winkler measure (Jaro 1989).
8.4.2. Linguistic indexing methods
Linguistic methods of automatic indexing are a subdomain of natural language processing (NLP). NLP is a multidisciplinary field that combines linguistics, computer science, information engineering and artificial intelligence. These methods use different levels of analysis:
– Morphological analysis is made up of three steps:
- 1) Segmenting (tokenization) the text into sentences: a sentence is a string of characters located between a capital letter and a strong punctuation mark: full stop (period or full point), question mark and exclamation mark. The full stop as a sentence separator can present ambiguities. It can be an abbreviation marker or titles prefixing the name of a person (e.g. Mr, Mrs, Mrs, Dr, etc.), part of an acronym (e.g. I.S.K.O.).
- 2) Segmenting sentences into words: a word is a single distinct meaningful element of speech or writing, used with others (or sometimes alone) to form a sentence. The separators are spaces, numbers and weak punctuation marks (usually: comma, semicolon, colon, parentheses, ellipsis (also called suspension points), dash, brackets and quotation marks).
- 3) Lexical analysis is composed of lexical and inflectional morphological analysis: lexical morphological analysis consists of studying the form of words which can be simple, complex (compounds), variable (nouns, verbs, determiners, pronouns and qualifying adjectives) or invariable (adverbs, prepositions and coordinating conjunctions). Inflectional morphological analysis consists of studying the variation of lexical units as a function of grammatical factors. It represents the relationship between the different parts of a sentence and can concern a verb (conjugation) or a nominal group which depends on its grammatical category, and whether it is singular or plural.
– Syntactic analysis (or parsing) allows us to highlight the syntactic structure of a sentence by explaining the dependency relationships between words. The purpose of this phase is to represent the structure of sentences using syntax trees. Syntactic analysis identifies syntactic groups such as noun phrases, verb phrases, prepositional phrase, etc. These phrase groups are the basis of several indexing approaches (Chevallet and Haddad 2001; SIDHOM 2002; Bellila Heddaji 2005).
8.4.3. Semantic indexing
The problem of indexing documents by words, or groups of words, is not using semantic relationships between descriptors such as synonymy, homonymy, polysemy relationships, etc. With the emergence of terminological resources such as ontologies (Jonquet et al. 2010), semantics has become a major challenge to consider. Semantic indexing (Hamadi 2014; Yengui 2016) uses the concepts and their relationships to represent documents and queries.
8.4.4. Social indexing
Social indexing is a Web 2.0 technology, also known as social tagging, collaborative tagging, collaborative indexing social classification and Folksonomy. It involves a community of users freely creating and managing personalized tags (a keyword or term) assigned to a web resource for the purposes of collaborative categorization and classification. “Users are also actively involved in content creation, feedback and enrichment” (Rückemann 2012). Social indexing can create a shared content collaborative enrichment web and creating new communities. There are several research studies on social indexing such as recommendations in social networks (Dahimene 2014; Beldjoudi et al. 2016; Jelassi et al. 2016), improving information retrieval (Badache 2016), information monitoring (Pirolli 2011), etc.
8.5. Indexing methods for Big Data and Open Data
The rise of Big Data (or massive data, huge data) has followed the evolution of data storage and processing systems, notably with the advent of the technology of cloud computing (virtualization) and supercomputers. Big Data is also data but of a huge size. Big Data is a term used to describe a heterogeneous data set that is huge in volume and yet growing exponentially with time. These data sets are so voluminous and complex that none of the traditional data management tools are able to store and manage them efficiently. Doug Laney (Laney 2001) uses three properties or dimensions to define Big Data usually called the 3 Vs of Big Data (volume, variety and velocity). Volume refers to the growing volume of data generated through social media, websites, portals, online applications and connected objects (smart objects). Variety refers to the many types of data that are available which can be structured, semi-structured or unstructured, such as multimedia documents. Multimedia documents require additional preprocessing and a classification of the incoming data into various categories. Velocity refers to the speed with which data is being generated, received, stored, processed, analyzed and exploited in real time. Big Data comes from various sources, such as published content on Internet, messages exchanged on social media, data transmitted by connected objects, climate data, demographic data, scientific and medical data, data from sensors, e-commerce transactions, company data, etc.
Open Data is an important source of data; it refers to digital data whose access, use, re-use and redistribution (sharing) are public and free of rights (there should be no discrimination against persons or groups). They can be from the public or private sector, produced and published by the government, a public service, a community or by a company. The operation of this data offers numerous opportunities and new perspectives to improve the performance of companies and to extend human knowledge in many fields.
The huge volume of data, the variety of structures and types of multimedia documents from heterogeneous sources are the biggest problems when it comes to indexing. To overcome these problems, all indexed documents must be stored in the same format. The NoSQL (Not Only Structured Query Language) databases (Moniruzzaman and Hossain 2013; Bathla et al. 2018) are flexible and increasingly used with the rise of Big data to improve the performance of processing and analysis of distributed data. This data can have variable data structures different from those used by default in traditional relational databases. NoSQL databases do not use the rows/columns/table format. The most common types of NoSQL databases are key-value, wide column, document and graph:
– Key-value store: a key-value database, or key-value store, is a data storage paradigm designed for storing data in unique key-value pairs where each key is associated only with one value in a collection.
– Wide-column store: wide-column databases are designed for storing data as sections of columns where each key is associated only with a set of columns.
– Document store: document databases use common notation formats like JavaScript object notation (JSON) or extensible markup language (XML) to store documents. Each key is associated with a collection of key-value pairs stored in documents. This type of database is used to store structured and semi-structured documents.
– Graph store: the graph database uses graph theory to model data with nodes (entities or objects) and relationships (edges). Both nodes and relationships can have properties. This database type can store and analyze complex, dynamic and interconnected data. Many emerging problems such as social network analysis, network routing, trend prediction, product recommendation and fraud detection can be represented using graph models and solved using graph algorithms (Skhiri and Jouili 2013).
8.6. Conclusion
Indexing is a process used to extract descriptive elements from documents and user requests. The aim of indexing is to improve searching for information by finding relevant documents in a collection of documents in a reduced search time (Khemiri and Sidhom 2020). Several studies have been developed to suggest indexing approaches and methodologies ranging from manual and automatic methods to the emerging indexing methods for Big Data. This variety of methods must adapt and take advantage of continuous technological evolution. In recent years, the emergence of Big Data, Open Data and NoSQL databases have opened up a new technological era and new research areas. The purpose of these indexing methods is to allow the exploitation of huge digital data produced daily by humans and connected objects.
8.7. References
- Bathla, G., Rani, R., Aggarwal, H. (2018). Comparative study of NoSQL databases for big data storage. International Journal of Engineering & Technology, 7. DOI: 10.14419/ijet.v7i2.6.10072.
- Baum, L.E. and Petrie, T. (1966). Statistical inference for probabilistic functions of finite state Markov chains. Annals of Mathematical Statistics, 37(6), 1554–1563. DOI: 10.1214/aoms/1177699147.
- Beldjoudi, S., Seridi, H., Benzine, A. (2016). Améliorer la recommandation de ressources dans les folksonomies par l’utilisation de linked open data. IC2016: Ingénierie des Connaissances, Montpellier, June.
- Bellia Heddadji, Z. (2005). Modélisation et classification de textes : application aux plaintes liées à des situations de pollution de l’air intérieur. Doctoral thesis, Université Paris Descartes.
- Chaumier, J. and Dejean, M. (1990). L’indexation documentaire, de l’analyse conceptuelle à l’analyse morphosyntaxique. Documentaliste, 27(6), 275–279.
- Chevallet, J.-P. and Haddad, H. (2001). Proposition d’un modèle relationnel d’indexation syntagmatique : mise en œuvre dans le système iota. INFORSID 2001, Genève-Martigny.
- Clavel, G., Walther, F., Walther, J. (1993). Indexation automatique de fonds bibliothéconomie. ARBIDO-R8, 14–19.
- Dahimene, M.R. (2014). Filtrage et recommandation sur les réseaux sociaux. Doctoral thesis, École Doctorale Informatique, Télécommunication et Électronique, Paris.
- Grefenstette, G. (1994). Exploration in Automatic Thesaurus Discovery. Kluwer Academic Publishers, London.
- Hamadi, A. (2014). Utilisation de contexte pour l’indexation sémantique des images et vidéos. Thesis, Université Joseph Fourrier Grenoble.
- Ismail, B. (2016). Recherche d’information sociale : exploitation des signaux sociaux pour améliorer la recherche d’information. Université Paul Sabatier – Toulouse III.
- Jaro, M.A. (1998). Advances in record-linkage methodology as applied to matching the 1985 census of Tampa, Florida. Journal of the American Statistical Association, 89, 414–420.
- Jelassi, M.N., Benyahia, S., Engelbert, M.N. (2016). Étude du profil utilisateur pour la recommandation dans les folksonomies. IC2016 : Ingénierie des Connaissances, Montpellier, June.
- Jonquet, C., Coulet, A., Shah, N., Musen, M. (2010). Indexation et intégration de ressources textuelles à l’aide d’ontologies : application au domaine biomédical. 21èmes Journées Francophones d’Ingénierie des Connaissances, Bordeaux.
- Khemiri, N. and Sidhom, S. (2002). De l’indexation intellectuelle à l’indexation automatique à l’ère des Big Data et Open Data : un état de l’art. OCTA Multi-conference Proceedings: International Society for Knowledge Organization (ISKO-Maghreb), 170, February, Tunis [Online]. Available at: https://multiconference-octa.loria.fr/multiconference-program/.
- Laney, D. (2001). 3D data management: Controlling data volume, velocity and variety. META Group Research Note, 6.
- Levenshtein, V.I. (1965). Binary codes capable of correcting deletions, insertions, and reversals. Doklady Akademii Nauk SSSR, 163(4), 845–848.
- Moniruzzaman, A.B.M. and Hossain, S. (2013). NoSQL database: New era of databases for big data analytics – Classification, characteristics and comparison. International Journal of Database Theory and Application, 6.
- Pirolli, F. (2011). Pratiques d’indexation sociale et démarches de veille informationnelle. Études de communication, 53–66. DOI: 10.4000/edc.2615.
- Rückemann, C.P. (2012). Integrated information and computing systems for natural, spatial, and social sciences. Information Science Reference, 543.
- Salton, G. and McGill, M.J. (1983). Introduction to Modern Information Retrieval. McGraw-Hill Book Co., New York.
- Shannon, C.E.A. (1984). Mathematical theory of communication. Bell System Technical Journal, 27(3), 379–423.
- Sidhom, S. (2002). Plateforme d’analyse morpho-syntaxique pour l’indexation automatique et la recherche d’information : de l’écrit vers la gestion des connaissances. Doctoral Thesis, Université Claude Bernard, Lyon.
- Skhiri, S. and Jouili, S. (2013). Large graph MINING: Recent developments, challenges and potential solutions. Business Intelligence, 103–124.
- Sneath, P.H. and Sokal, R.R. (1973). Numerical Taxonomy: The Principles and Practice of Numerical Classification. W.H. Freeman and Company, San Francisco.
- Yengui, A. (2016). Système de recherche d’information sémantique pour les bases de visioconférences médicales à travers les graphes conceptuels. Research paper, Faculté des sciences économiques et de gestion Sfax, Tunisia.
Note
- Chapter written by Nabil KHEMIRI and Sahbi SIDHOM.