
3
Multi-Criteria Decision-Making Recommender System Based on Users’ Reviews
3.1. Introduction
Due to the frequent accumulation of web resources, finding useful and relevant information is becoming an increasingly difficult task to manage. RSs have been integrated into the online information systems (e.g. e-commerce platforms, social media sites, etc.) to solve the increasing information overload problem by providing users with new items that may interest them. Most of the existing recommendation systems (Al-Ghuribi and Mohd Noah 2019) focus on the historical data of users’ preferences on the overall representation of items considering that all its criteria have the same importance. This restricted vision cannot present the evaluation of the users’ interests correctly. For instance, when choosing a restaurant, we can consider food quality as a primary criterion and the remaining ones (e.g. service, ambiance and price) may not be a big concern for them even if they are highly rated. Recently, many research works (Yang et al. 2016; Zheng 2019; Briki et al. 2020) have proposed applying multi-criteria decision-making (MCDM) methods to consider the multi-faceted representation of items and users’ preference in the recommendation generation process. They prove a considerable progress in the recommendation performance. Most of these works consider the numerical ratings on the different criteria of items to generate recommendations. However, the available databases correspond, generally, to a huge volume of unstructured data in the form of textual data derived from several sources (e.g. comments from shared publications on social networks, replies to registration questionnaires, etc.). The users’ reviews, comments and experiences may be a powerful source of information that can be exploited in RS in order to model the users’ profiles. At this point, text mining analysis techniques (e.g. categorization, entity extraction, sentiment analysis and natural language processing) are used to find the hidden knowledge in text content and revealing useful patterns, trends and insights.
Our objective in this chapter is to improve the recommendation task by using text mining techniques in order to capture the multi-criteria of users’ interests from the users’ reviews. The main idea consists of defining the criteria of the items, and then creating the corpus of information of each criterion. On this basis, we analyze the active user’s reviews in order to identify their primary criterion. Finally, we analyze all the reviews of each unseen item in order to capture the ones that match the active user’s primary criterion.
Throughout this work, we have implemented two algorithms, namely the primary criterion-based recommendation system (PCRS) and the multi-criteria text mining-based recommendation system (MCTMRS). The PCRS consists of taking advantage of text mining techniques to analyze the active user’s reviews and to determine their primary criterion. The MCTMRS consists of using the weighted sum method (WSM) (Pohekar and Ramachandran 2004) as it is the most commonly used method in the multi-criteria decision-making (MCDM) field to compute the best decision alternative with respect to the weight of each criterion.
The rest of this chapter is organized as follows: section 3.2 is devoted to the multi-criteria decision-making methods, section 3.3 describes the basics of RS and related works, section 3.4 details the proposed solution and section 3.5 presents the conclusions emerged from the experiments.
3.2. Multi-criteria decision-making
Multi-criteria decision-making (MCDM) is a branch of operational research dealing with finding optimal results in complex scenarios including various indicators, conflicting objectives and criteria. Applications of MCDM include areas such as integrated manufacturing systems, evaluations of technology investment, and water and agriculture management. Several methods have been introduced in the multi-criteria decision-making field to enable users to make decisions with respect to different features/parameters. The most commonly used methods are the following:
– The weighted sum method (WSM) (Pohekar and Ramachandran 2004) is used for evaluating a number of alternatives in accordance with the different criteria, which are expressed in the same unit. For instance, let M be the set of alternatives and N be the set of decision criteria; the WSM score is computed as the weighted sum of the performance value of each criteria j on the alternative i. The best alternative is the one having the highest WSM score.
where i = 1, 2 … M, j = 1, 2 … N, ![]() is the performance value of the
is the performance value of the ![]() alternative in terms of the
alternative in terms of the ![]() criterion and
criterion and ![]() is the relative weight of importance of the
is the relative weight of importance of the ![]() criterion.
criterion.
– The weighted product method (WPM) (Pohekar and Ramachandran 2004) selects the most important alternative from a set of alternatives ![]() with respect to a set of criteria
with respect to a set of criteria ![]() Every alternative
Every alternative ![]() is compared with the other alternative
is compared with the other alternative ![]() by multiplying the powered ratios of the first and the second performance values with respect to every criterion. If
by multiplying the powered ratios of the first and the second performance values with respect to every criterion. If ![]() is greater than 1, then the alternative
is greater than 1, then the alternative ![]() is more desirable than the alternative
is more desirable than the alternative ![]() is the best alternative if it is greater than all the other alternatives. Formally, this product is computed as follows:
is the best alternative if it is greater than all the other alternatives. Formally, this product is computed as follows:
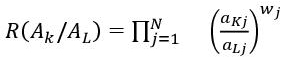
where ![]() is the performance value of the
is the performance value of the ![]() alternative in terms of the
alternative in terms of the ![]() criterion and
criterion and ![]() is the relative weight of importance of the
is the relative weight of importance of the ![]() criterion.
criterion.
– The analytical hierarchy process (AHP) (Saaty 1985) constructs at first a logical hierarchy of criteria by defining the objective at the top of the hierarchy, criteria and sub-criteria at levels and sub-levels of the hierarchy, and decision alternatives at the bottom of the hierarchy. Each alternative has its own values of associated criteria. Then, a pairwise comparison matrix is created to give the relative importance of various criteria with respect to the main objective. In the final step of the process, numerical priorities are calculated for each of the decision alternatives.
3.3. Basics of recommendation systems and related work
We recall in this section the basic concepts of recommender systems. Then, we expose text mining-based recommendations and their related works.
3.3.1. Recommender systems
Due to the huge amount of resources accessible via the Internet, finding relevant information becomes a challenging task. As a response, recommender systems (RSs) have been introduced to achieve personalization and increase users’ satisfaction by recommending items that fit their needs and tastes. These systems have been widely used in various domains and diverse applications and have drawn increasing attention from different research communities such as machine learning, electronic commerce and information retrieval. The main task of recommender systems is to analyze as much as possible users’ feedback in order to learn the users’ preferences. RSs rely on different types of input data such as:
– explicit feedback, which is the information we obtain by directly questioning the user about the proposed items;
– implicit feedback, which is the information we obtain by analyzing the behavior of the user such as clicks/queries/watches.
The output of RS can be twofold (Vozalis and Margaritis 2003):
– a prediction expressed as a numerical value, ![]() which represents the anticipated opinion of active user
which represents the anticipated opinion of active user ![]() for item
for item ![]() This predicted value should necessarily be within the same numerical scale (e.g. 1 – bad and 5 – excellent) as the input referring to the opinions provided initially by active user
This predicted value should necessarily be within the same numerical scale (e.g. 1 – bad and 5 – excellent) as the input referring to the opinions provided initially by active user ![]() This form of recommendation system’s output is also known as individual scoring;
This form of recommendation system’s output is also known as individual scoring;
– a recommendation expressed as a list of ![]() items, where
items, where ![]() which the active user is expected to like the most. The usual approach in that case requires this list to include only items that the active user has not already purchased, seen or rated. This form of recommendation system’s output is known as top-N recommendation or ranked scoring.
which the active user is expected to like the most. The usual approach in that case requires this list to include only items that the active user has not already purchased, seen or rated. This form of recommendation system’s output is known as top-N recommendation or ranked scoring.
The use of efficient and accurate recommendation methods is very important for a system that will provide good and useful recommendations to its users. This process explains the importance of understanding the features and the potentials of the different recommendation approaches. The recommendation methods are classified into three main classes, including content-based, collaborative filtering and hybrid. First, the collaborative filtering approach (Breese et al. 1998) relies on a matrix of user-item ratings to predict unknown matrix entries, and thus to decide which items to recommend. There are two main CF approaches: item-based (Sarwar et al. 2001), where the recommendations are generated based on similar items that the active user has liked in the past, and user-based (Shardanand, and Maes 1995), where the recommendations are computed based on the opinions of similar users. Second, the content-based approach (Soboroff and Nicholas 1999) uses the contents of the items that the active user has liked in the past and suggests items having similar features to them. And third, the hybrid approach (Chu and Tsai 2017) combines content-based filtering and collaborative filtering in order to take advantage of the representation of the content and the rating information of users to produce recommendations.
Most of the RS algorithms consider the quantitative preferences of users, which are generally expressed on a numerical scale. However, the quantitative notes may not be consistent. In fact, they can be affected by many key factors including the user’s mood when one user may react differently with the same item according to their situation, the limited scale when the user may give the same rating to two items that they appreciate differently since the scale of possible values is generally reduced, etc. Thus, numerical data of users are not reliable and cannot represent the precise degree of users’ liking. For these reasons, many works highlight the use of textual data as it may be a strong support to consider in the recommendation process.
3.3.2. Text mining-based recommendation systems
Text mining is a process to extract interesting and significant patterns to explore knowledge from textual data sources. It is a multidisciplinary field based on information retrieval, data mining, machine learning, statistics, and computational linguistics (Talib et al. 2016). Several works have used the text mining techniques in ![]() to analyze the users’ personal reviews and online behavior and capture their interests. For instance, Li et al. (2015) proposed an
to analyze the users’ personal reviews and online behavior and capture their interests. For instance, Li et al. (2015) proposed an ![]() based on opinion mining. The idea consists of taking advantage of the text mining methods in order to detect the opinion-related information from the massive users’ reviews and find the most suitable products for customers. Ziani et al. (2017) presented a basic tool that can be used to analyze Algerian reviews and comments and detect their polarity in order to generate meaningful recommendations for users.
based on opinion mining. The idea consists of taking advantage of the text mining methods in order to detect the opinion-related information from the massive users’ reviews and find the most suitable products for customers. Ziani et al. (2017) presented a basic tool that can be used to analyze Algerian reviews and comments and detect their polarity in order to generate meaningful recommendations for users.
Ganu et al. (2009) proposed a restaurant recommendation system that exploits the users’ comments in order to find out their relative topics and sentiment information. In fact, they used the regression model to estimate scaled sentiment points instead of the two bipolar classes: positive or negative. The authors in Lin et al. (2015) developed a personalized hotel recommendation approach based on both textual and contextual data. They identified the user’s preferred aspects through tracking the browsing behavior on the mobile devices. The authors in Naw and Hlaing (2013) proposed a content-based recommendation method that helps users who want to buy a car by providing them with relevant car information. They implemented a key extraction algorithm to identify the items’ features from the users’ reviews.
All these works have exploited users’ reviews and the textual-related information in order to understand its semantics, and then capture the users’ profiles. However, they are unable to deeply treat the multi-criteria aspect of users’ preferences that is a crucial feature to consider when building user profiles and generating recommendations.
3.3.3. Multi-criteria recommender systems
The multi-criteria aspect is introduced in the context of RS to detect the multi-faceted representation of users’ interests and to correctly build the users’ profiles. In fact, the MCDM methods have been used to make more effective recommendations, in numerous application domains. There are two categories of multi-criteria recommender systems. The first category focuses on using the multi-criteria ratings in order to model a user’s utility for an item as a vector of ratings along several criteria.
For instance, Hdioud et al. (2017) proposed an objective weight determination method called ![]() to determine the criteria with the most important impact on the decision-making process. The main idea consists of computing the overall assessment value of each item as the weighted sum of the performance value over all the criteria; then, they removed one attribute at a time from the set of criteria and considering its correlation with the overall assessment of items without the inclusion of this removed attribute. The alternative with a small correlation should be given a very important weight. In Zheng (2019), the authors developed a utility-based multi-criteria recommender system that computes a utility function of each item based on the multi-criteria ratings. The utility score is defined using the similarity between the vector of the user’s evaluations and the vector of the user’s expectations. In fact, the user’s expectation vector is learned using three optimization learning-to-rank methods (i.e. pointwise ranking, pairwise ranking and listwise ranking).
to determine the criteria with the most important impact on the decision-making process. The main idea consists of computing the overall assessment value of each item as the weighted sum of the performance value over all the criteria; then, they removed one attribute at a time from the set of criteria and considering its correlation with the overall assessment of items without the inclusion of this removed attribute. The alternative with a small correlation should be given a very important weight. In Zheng (2019), the authors developed a utility-based multi-criteria recommender system that computes a utility function of each item based on the multi-criteria ratings. The utility score is defined using the similarity between the vector of the user’s evaluations and the vector of the user’s expectations. In fact, the user’s expectation vector is learned using three optimization learning-to-rank methods (i.e. pointwise ranking, pairwise ranking and listwise ranking).
The second category focuses on analyzing the unstructured textual reviews of users and items’ descriptions to determine the criteria of users’ preferences and to generate recommendations.
In Yashvardhan et al. (2015), the authors implemented a multi-criteria recommendation system for hotel recommendations. The proposed algorithm used various ![]() approaches on a hotel review corpus and the user’s reviews in order to construct a user-item-feature database. The latter is exploited to compute the rating of a hotel from previous users’ preferences with respect to different features. In Yang et al. (2016), the authors proposed a collaborative filtering framework that incorporates both user opinions and preferences on different aspects. The first step consists of analyzing the users’ reviews to extract the opinion words and then computing a score for each aspect. In the second step, the aspect weight is computed using a tensor factorization approach. Finally, the scores and the weights of multiple aspects are used to infer the overall rating, which measures the user’s satisfaction about the item. In Ebadi and Krzyzak (2016), the authors proposed a highly accurate hotel recommender system, which uses the multi-aspect rating system and the large-scale data of different types to suggest hotels for users. In fact, it employs the
approaches on a hotel review corpus and the user’s reviews in order to construct a user-item-feature database. The latter is exploited to compute the rating of a hotel from previous users’ preferences with respect to different features. In Yang et al. (2016), the authors proposed a collaborative filtering framework that incorporates both user opinions and preferences on different aspects. The first step consists of analyzing the users’ reviews to extract the opinion words and then computing a score for each aspect. In the second step, the aspect weight is computed using a tensor factorization approach. Finally, the scores and the weights of multiple aspects are used to infer the overall rating, which measures the user’s satisfaction about the item. In Ebadi and Krzyzak (2016), the authors proposed a highly accurate hotel recommender system, which uses the multi-aspect rating system and the large-scale data of different types to suggest hotels for users. In fact, it employs the ![]() and the topic modeling techniques to assess the sentiment of the users’ reviews and extract implicit items criteria. Then, each aspect of the subject problem is treated using a specific sub-recommender system.
and the topic modeling techniques to assess the sentiment of the users’ reviews and extract implicit items criteria. Then, each aspect of the subject problem is treated using a specific sub-recommender system.
Most of these works have shown that when exploiting the textual data to determine the users’ profiles, the recommendation accuracy can be improved. However, most of them focus on the reviews given, one for each specific feature/criteria to infer the criteria weights; then, they use the users’ preferences to compute the overall rating, which cannot accurately reflect the users’ preferences. In fact, the users’ reviews could not contain positive terms/words because they are not completely satisfied by the most interesting criteria for them. Hence, we need to dive deep into the user’s reviews to determine the most interesting criteria for them and to exploit the users’ reviews to capture the item that meets with their expectation.
3.4. New multi-criteria text-based recommendation system
Our objective is to use the text mining techniques on the users’ reviews to compute the users’ interests on different items’ criteria and to find out the items that meet the selected criteria. We assume that by analyzing the users’ reviews, we could reveal much hidden information about users’ preferences on multiple criteria/features and detect the prinicpal/most interesting criterion for them. To this end, we propose two algorithms, the primary criterion-based recommendation system ![]() and the multi-criteria text mining-based recommendation system
and the multi-criteria text mining-based recommendation system ![]() Both these algorithms should proceed with a pre-processing phase that consists of defining the decision criteria (e.g. the decision criteria for a mobile phone are the price, the storage space, the camera quality and the look/design) and creating the information corpus of each criterion. The information corpus is a collection of linguistic data, words and sentences used in the context of the relative criterion. It is commonly used to perform a statistical analysis for different concepts. For example, for the criteria “service”, we created a list of words (i.e. verbs, adjectives, etc.) that can be related or that can describe the relation between clients and persons who work in a restaurant.
Both these algorithms should proceed with a pre-processing phase that consists of defining the decision criteria (e.g. the decision criteria for a mobile phone are the price, the storage space, the camera quality and the look/design) and creating the information corpus of each criterion. The information corpus is a collection of linguistic data, words and sentences used in the context of the relative criterion. It is commonly used to perform a statistical analysis for different concepts. For example, for the criteria “service”, we created a list of words (i.e. verbs, adjectives, etc.) that can be related or that can describe the relation between clients and persons who work in a restaurant.
3.4.1. Primary criterion-based recommendation system
This algorithm is based on two main steps. The first step consists of using the information corpus of each criterion and the active user’s reviews to compute the user’s interests on each criterion. In this algorithm, we will consider just the most interesting criterion for the user, the so-called primary criterion. We assume that by managing only the primary criterion to create the user’s profile, a more focused representation of the user’s preferences is provided.
Formally, given the users’ reviews, we start by putting all the active user’s comments in one sentence denoted as ![]() The
The ![]() is defined as the union of all the active user’s reviews. Formally,
is defined as the union of all the active user’s reviews. Formally, ![]() is:
is:
where ![]() is the number of the active user’s reviews and
is the number of the active user’s reviews and ![]() is the current review.
is the current review.
Then, to find the primary criterion of the active user, we compute the percentage of the existence of each criterion ![]() in the active user’s reviews denoted by
in the active user’s reviews denoted by ![]() The criterion with the highest
The criterion with the highest ![]() value is selected as the primary criterion of the active user. Formally,
value is selected as the primary criterion of the active user. Formally, ![]() is:
is:
where ![]() is the number of criteria,
is the number of criteria, ![]() is the current criterion and
is the current criterion and ![]() is the information corpus of the current criterion.
is the information corpus of the current criterion.
The second step consists of analyzing the users’ reviews of all the unseen items to capture the ones that may satisfy the primary criterion of the active user. Formally, let ![]() be the number of all the items not yet seen by the active user. Given the users’ reviews, we put all the comments of each unseen item in one sentence denoted as
be the number of all the items not yet seen by the active user. Given the users’ reviews, we put all the comments of each unseen item in one sentence denoted as ![]() which is defined as the union of all the reviews given to item
which is defined as the union of all the reviews given to item ![]() Formally,
Formally, ![]() is:
is:
where ![]() is the number of all the reviews to item
is the number of all the reviews to item ![]() and
and ![]() is the
is the ![]() review to item
review to item ![]()
Finally, to find out the items matching the primary criterion of the active user, we compute the percentage of each criterion i in the review content of the unseen item ![]() denoted by
denoted by ![]() Formally,
Formally, ![]() is:
is:
where ![]() is the number of criteria,
is the number of criteria, ![]() is the current criterion and
is the current criterion and ![]() is the current unseen item.
is the current unseen item.
The items having the highest IPEC value with the active user’s primary criterion are then selected for the recommendation list. To better explain this, we have summarized the process of this solution in Figure 3.1.
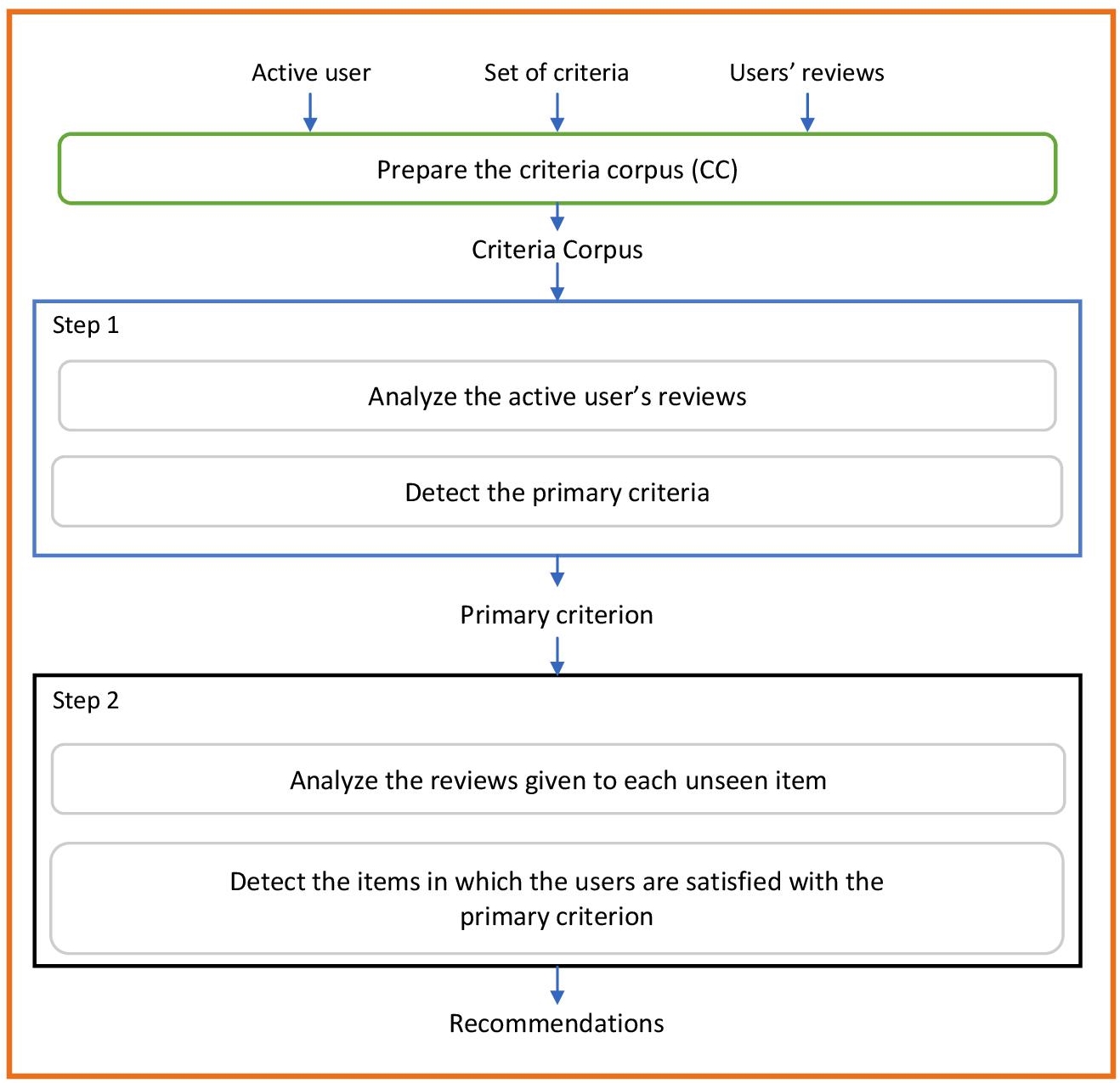
Figure 3.1 Main steps of primary criterion-based recommendation system.
Algorithm 3.1 presents the pseudocode of the primary criterion-based recommendation system algorithm.
Table 3.1. Reviews of Anthony Rodreguez of Example 3.1
| Review | |
|---|---|
| Review 1 | Very nice discovery. Pleasant cuisine and a warm welcome. Originality of the champagne glasses and delicacy of the minced chicken with asparagus. All accompanied by fries. |
| Review 2 | The welcome is always warm and the dishes well chosen. The menu is a bit expensive compared to the usual restaurant prices. We will come back |
| Review 3 | You have to find the powered farm in Herlies in the north. A real farm of quality products and traditional menus. The prices are reasonable. The welcome is warm and friendly. We spend a good time in an airy and well-decorated space. |
The next step consists of analyzing the ![]() which is defined as the union of all the active user’s reviews. Table 3.1 shows all the reviews of Anthony Rodreguez. The
which is defined as the union of all the active user’s reviews. Table 3.1 shows all the reviews of Anthony Rodreguez. The ![]() of criterion service (respectively service, price, view and ambiance) is 22% (respectively 8%, 6%, 3% and 3%). Thus, the primary criterion for Anthony is the food quality. In the last step, we compute the
of criterion service (respectively service, price, view and ambiance) is 22% (respectively 8%, 6%, 3% and 3%). Thus, the primary criterion for Anthony is the food quality. In the last step, we compute the ![]() of each unseen item and we recommend to Anthony “212 steak house” and “kobe beef” restaurants, as the users were very satisfied with their food quality.
of each unseen item and we recommend to Anthony “212 steak house” and “kobe beef” restaurants, as the users were very satisfied with their food quality.
3.4.2. Multi-criteria text mining-based recommendation system
The multi-criteria text mining-based recommendation system uses the text mining techniques on both the active user’s reviews to detect the weight of importance of each criterion and the users’ reviews of each unseen item to capture the score of satisfaction of users for each criterion. Then, a multi-criteria decision-making method is applied to compute the overall rating for all the unseen items with respect to multi-criteria preferences. The items with the highest ratings are returned to the user. In this work, we use the weighted sum method ![]() as it is the most commonly used multi-criteria decision-making method.
as it is the most commonly used multi-criteria decision-making method.
Algorithm 3.2 presents the pseudo-code of the multi-criteria text mining-based recommendation system algorithm.
3.5. Experimental study
To evaluate the accuracy of the proposed algorithm, we conduct experiments on a real-world dataset, namely TripAdvisor. All the experiments are implemented in Python 3.7 on a Windows 7-based PC with an Intel Core i3 processor having a speed of 2.40 GHz and 4 GB of RAM and compiled in Eclipse framework. In the following, we first describe the dataset and the evaluation metrics. Then, we present the experimental results.
3.5.1. Dataset and metrics
TripAdvisor is an American website that offers tourists advice from consumers on hotels, restaurants, cities and regions, places of leisure, etc. It also provides accommodation and airline ticket booking tools that compare hundreds of websites to find the best deals. Each week hundreds of users visit TripAdvisor to rate and receive recommendations for new restaurants. The users’ preferences can be expressed in two forms: the explicit ratings and the unstructured textual reviews.
We start by using the WebCrawler technique to extract the data used to test the performance of our proposed algorithms. In fact, this technique is generally designed to explore the Web. This robot is generally designed to collect resources (e.g. web pages, images, videos, Word documents, PDF, etc.) and allows a search engine to index them.
The extracted data is saved in an Excel file. In the following, we present the textual and the statistical description of the data:
1) Textual description of the database: the database extracted is a corpus of comments on restaurants in the Lille region. This dataset contains 47,168 comments and ratings collected from 10,000 users of the site on 1,000 restaurants, from 18/11/2007 to 01/11/2016. Five criteria are considered, including food, service, ambience and price. The rating is given in five discrete levels from 1 to 5.
2) Statistical description of the database: a statistical description allows us to better analyze the database by providing statistics that can enable us to better align our contribution. Table 3.2 presents a statistical description of the TripAdvisor dataset.
Table 3.2. Description of TripAdvisor dataset
| Number of distinct users | 10,000 |
| Number of distinct restaurants | 1,000 |
| Average of reviews’ number per user | 5 |
| Average of reviews’ number per restaurant | 5 |
| Number of users with 1 review | 4,241 |
| Number of users with 3 reviews | 1,410 |
| Number of users with 4 reviews | 2,115 |
| Number of users with more than 4 reviews | 39,362 |
The dataset has been divided into two subsets: training set and testing set. In the training set, we are interested in the users’ reviews to detect the primary criterion of the active user, detect the items that match this criterion and finally generate recommendations. The testing set is used to evaluate the effectiveness of the generated recommendations with regard to the real defined rating of the user. To this end, we first split the data chronologically into testing (20% of the recent instances) and training set (the remaining old instances).
3.5.2. Evaluation metrics
Recommendation systems research has used several types of measures for evaluating the quality of the provided recommendation. The evaluation metrics can be categorized into three classes, including predictive accuracy metrics, classification accuracy metrics and rank accuracy metrics (Herlocker et al. 2004). In this work, we are interested in classifying metrics because they are most commonly used in natural language processing and easier to interpret directly (Herlocker et al. 2004). In fact, these metrics measure how many times a recommendation system makes correct or incorrect decisions about whether an item is good. Table 3.3 shows the possible categorization of items, where N is the number of items in the database and how the items are categorized.
Table 3.3. Items’ categorization
| Suggested | Non-suggested | Total | |
| Relevant | |||
| Irrelevant | |||
| Total |
We can conclude that recommended items can be either successful recommendations (i.e. relevant) or unsuccessful recommendations (i.e. non-relevant) and the relevant items can be either suggested in the recommendation list or not. Precision, recall and F-measure (Basu et al. 1998) are the most popular metrics for evaluating information retrieval systems.
– Precision is used to evaluate the validity of a given recommendation list, and it is defined as the ratio of relevant items selected by the active user relative to the number of items recommended to them:
– Recall computes the portion of favored items that were suggested for the active user relative to the total number of the objects actually collected by them:
– F-measure is a measure of a statistic test accuracy. It considers both precision and recall measures of the test to compute the score. We could interpret it as a weighted average of the precision and recall, where the best F-measure has its value at 1 and worst score at the value 0:
3.5.3. Experimental protocol
We used the text mining techniques to clean and transform the users’ reviews as follows:
1) eliminate special characters from user comments;
2) create a list of stop words and add an extension. We use the latter to eliminate the stop words from the comments of the users;
3) concatenate all the comments of a single user/item in one sentence;
4) use the tokenization library to have a list of words that builds a sentence;
5) use the stemmatization library to extract the origin of the words from the obtained sentence.
Once the comments are extracted and cleaned, we move to the exploitation step, which consists of determining the user’s interests on the different criteria by computing how many words and terms contain the reviews from each criterion corpus.
We choose to compare our proposed algorithms with the multi-criteria algorithms, including the multi-criteria weighted average-based recommendation system (Lee and Teng 2007) that uses users’ ratings in the multi-criteria aspect to provide a recommendation and reviews the similarity-based recommendation system (Naw and Hlaing 2013) that uses text mining techniques and the Jaccard similarity measure in order to find similarity between reviews to make the recommendation. To go further, we perform an experiment to test the effect of the sparse data on the effectiveness of all the above algorithms. We tested with different numbers of comments that each user has made (i.e. 3, 4 and more than 4 comments). The results of the different algorithms are listed in Tables 3.4 and 3.5.
3.5.4. Experimental results
It can be noted from Table 3.4 that the recommendations performance of the criterion’s weighted average-based recommendation system is the worst. In fact, the users should give ratings for each feature of the item regardless of whether they are interested in the features or otherwise. Moreover, the numeric scale cannot be very reliable since it can be interpreted differently. This confirms what is stated in Lee and Teng (2007). Researchers note that the algorithm that is based on computing the average of the criteria is defined as a traditional way to rank multiple items.
Comparing the reviews similarity-based recommendation system with the criterion’s weighted average-based recommendation system, we record an improvement that can be explained by the potential of the textual data (e.g. opinions and reviews) in the users’ preferences determination.
Table 3.4 shows that this algorithm has the best results regarding the F-measure evaluation metric than all the other algorithms. This improvement is due to the exploitation of the unstructured textual data not only to detect the active user’s interests on different criteria but also to detect the items that satisfy the multi-criteria preference of the active user. This can only be a good sign towards the use of text mining techniques and multi-criteria decision-making aspect. Table 3.5 shows that the greater the number of reviews to be analyzed for a user, the better the quality of the recommendation. We could mention that the algorithm multi-criteria text mining-based recommendation system is always the most efficient even with sparse data.
Table 3.4. Evaluation metrics results for 1,000 users
| Algorithm | Precision | Recall | F-measure | Response time (sec) |
| Weighted average | 0.034 | 0.035 | 0.021 | 0.265564 |
| Sentence similarity | 0.048 | 0.113 | 0.040 | 0.291961 |
| PCRS | 0.223 | 0.753 | 0.218 | 158.294949 |
| MCTMRS | 0.232 | 0.772 | 0.235 | 183.132370 |
Table 3.5. F-measure results depending on the number of users’ reviews
| Algorithm | 3 reviews | 4 reviews | >= 5 reviews |
| Weighted average | 0.026 | 0.054 | 0.133 |
| Sentence similarity | 0.065 | 0.098 | 0.171 |
| PCRS | 0.211 | 0.226 | 0.270 |
| MCTMRS | 0.223 | 0.221 | 0.290 |
3.6. Conclusion
In this chapter, we investigate the effects of both the multi-criteria aspect of users’ interests and the users’ review content analysis on understanding the users’ behaviors. The proposed solution (Briki et al. 2020) is implemented based on three steps: the first step consists of the use of information extraction techniques to obtain users’ comments from the data source and to create the information corpus of each criterion. The second step consists of the use of text mining techniques to clean and to analyze the users’ reviews. The third step consists of identifying the primary criterion of the active user and generate recommendations accordingly. In this work, we have been through two improvement versions that we tested on a real database extracted from the TripAdvisor website. The experimental study shows that our proposed solution provides motivating results compared with the existing works. Future research consists of exploiting the ontology to describe the multi-criteria content and their relationships. The latter can be used to analyze in depth the users’ reviews and to increase the performance of recommendation systems.
3.7. References
- Al-Ghuribi, S.M. and Mohd Noah, S.A. (2019). Multi-criteria review-based recommender system-the state of the art. IEEE Access, 7, 169446–169468.
- Basu, C., Hirsh, H., Cohen, W. (1998). Recommendation as classification: Using social and content-based information in recommendation. Proc. of the Fifteenth National Conference on Artificial Intelligence, July 26–30.
- Breese, J.S., Heckerman, D., Kadie, K. (1998). Empirical analysis of predictive algorithms for collaborative filtering. Proc. 40th Conference on Uncertainty in Artificial Intelligence, UAI’98, 43–52.
- Briki, M., Ben Abdrabbah, S., Ben Amor, N. (2020). Highlighting the users’ primary criterion in text mining-based recommendation systems. OCTA Multi-Conference Proceedings: Information Systems and Economic Intelligence (SIIE), 208, February, Tunis, Tunisia [Online]. Available at: https://multiconference-octa.loria.fr/multiconference-program/.
- Chu, W.T. and Tsai, Y.L. (2017). A hybrid recommendation system considering visual information for predicting favorite restaurants. World Wide Web, 20, 1313–1331.
- Ebadi, A. and Krzyzak, A. (2016). A hybrid multi-criteria hotel recommender system using explicit and implicit feedbacks. Proc. 18th International Conference on Applied Science in Information Systems and Technology (ICASIST), Amsterdam, The Netheralnds.
- Ganu, G., Elhadad, N., Marian, A. (2009). Beyond the stars: Improving rating predictions using review text contents. Proc. 12th International Workshop on the Web and Databases, WebDB’09, June 28.
- Hdioud, F., Frikh, B., Ouhbi, B., Khalil, I. (2017). Multi-criteria recommender systems: A survey and a method to learn new user’s profile. International Journal of Mobile Computing and Multimedia Communications, 8(4), 20–48.
- Herlocker, J.L., Konstan, J.A, Terveen, L.G., Riedl, J.T. (2004). Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems, 22(1), 5–53.
- Lee, H.H. and Teng, W.G. (2007). Incorporating multi-criteria ratings in recommendation systems. IEEE International Conference on Information Reuse and Integration, 273–278.
- Li, X., Wang, H., Yan, X. (2015). Accurate recommendation based on opinion mining. Genetic and Evolutionary Computing, 329, 399–408.
- Lin, K.P., Lai, C.Y., Chen, P.C., Hwang, S.Y. (2015). Personalized hotel recommendation using text mining and mobile browsing tracking. Proc. IEEE International Conference on Systems, Man, and Cybernetics (SMC), 191–196.
- Naw, N. and Hlaing, E.E. (2013). Relevant words extraction method for recommendation system. Bulletin of Electrical Engineering and Informatics, 2.
- Pohekar, S.D. and Ramachandran, M. (2004). Application of multi-criteria decision making to sustainable energy planning – A review. Renewable and Sustainable Energy Review, 8, 365–381
- Saaty, T.L. (1985). Decision making for leaders. IEEE Transactions on Systems, Man, and Cybernetics, 15(3), 450–452.
- Sarwar, B., Karypis, G., Konstan, J., Riedl, J. (2001). Item-based collaborative filtering recommendation algorithms. The 10th International Conference on World Wide Web, 285–295.
- Shardanand, U. and Maes, P. (1995). Social information filtering: Algorithms for automating “word of mouth”. Proc. the Sigchi Conference on Human Factors in Computing Systems, 210–217.
- Soboroff, I. and Nicholas, C. (1999). Combining content and collaborative in text filtering. IJCAI’99 Workshop: Machine Learning for Information Filtering, Stockholm, Sweden.
- Talib, R., Hanif, M., Ayesha, S., Fatima, F. (2016). Text mining: Techniques, applications and issues. International Journal of Advanced Computer Science and Applications, 7(11), 414–418.
- Vozalis, E. and Margaritis, K. (2003). Analysis of recommender systems algorithms. 6th Hellenic European Conference on Computer Mathematics & Its Applications, 732–745.
- Yang, C., Yu, X., Liu, Y., Nie, Y., Wang, Y. (2016). Collaborative filtering with weighted opinion aspects. Neurocomputing, 210, 185–196.
- Yashvardhan, S., Jigar, B., Rachit, M. (2015). A multi-criteria review-based hotel recommendation system. IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing, 687–691.
- Zheng, Y. (2019). Utility-based multi-criteria recommender systems. Proc. of the 34th ACM/SIGAPP Symposium on Applied Computing, 2529–253.
- Ziani, A., Azizi, N., Schwab, D., Aldwairi, M., Chekkai, N., Zenakhra, D., Cheriguene, S. (2017). Recommender system through sentiment analysis. Proc. 2nd International Conference on Automatic Control, Telecommunications and Signals (ICATS), December.
Note
- Chapter written by Mariem BRIKI, Sabrine BEN ABDRABBAH and Nahla BEN AMOR.