
In this chapter we describe the IP fragmentation and reassembly processing that we postponed in Chapter 8.
IP has an important capability of being able to fragment a packet when it is too large to be transmitted by the selected hardware interface. The oversized packet is split into two or more IP fragments, each of which is small enough to be transmitted on the selected network. Fragments may be further split by routers farther along the path to the final destination. Thus, at the destination host, an IP datagram can be contained in a single IP packet or, if it was fragmented in transit, it can arrive in multiple IP packets. Because individual fragments may take different paths to the destination host, only the destination host has a chance to see all the fragments. Thus only the destination host can reassemble the fragments into a complete datagram to be delivered to the appropriate transport protocol.
Figure 8.5 shows that 0.3% (72, 786/27, 881, 978) of the packets received were fragments and 0.12% (260, 484/(29, 447, 726—796, 084)) of the datagrams sent were fragmented. On world.std.com, 9.5% of the packets received were fragments. world has more NFS activity, which is a common source of IP fragmentation.
Three fields in the IP header implement fragmentation and reassembly: the identification field (ip_id), the flags field (the 3 high-order bits of ip_off), and the offset field (the 13 low-order bits of ip_off). The flags field is composed of three 1-bit flags. Bit 0 is reserved and must be 0, bit 1 is the “don’t fragment” (DF) flag, and bit 2 is the “more fragments” (MF) flag. In Net/3, the flag and offset fields are combined and accessed by ip_off, as shown in Figure 10.1.

Net/3 accesses the DF and MF bits by masking ip_off with IP_DF and IP_MF respectively. An IP implementation must allow an application to request that the DF bit be set in an outgoing datagram.
Net/3 does not provide application-level control over the DF bit when using UDP or TCP.
A process may construct and send its own IP headers with the raw IP interface (Chapter 32). The DF bit may be set by the transport layers directly such as when TCP performs path MTU discovery.
The remaining 13 bits of ip_off specify the fragment’s position within the original datagram, measured in 8-byte units. Accordingly, every fragment except the last must contain a multiple of 8 bytes of data so that the following fragment starts on an 8-byte boundary. Figure 10.2 illustrates the relationship between the byte offset within the original datagram and the fragment offset (low-order 13 bits of ip_off) in the fragment’s IP header.
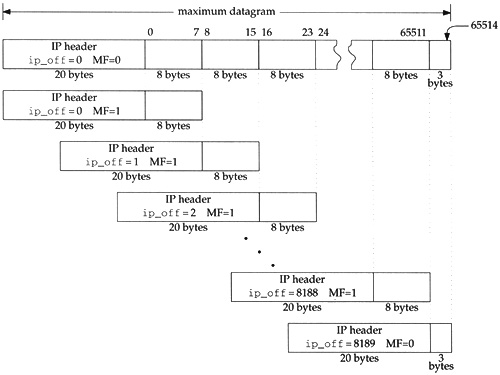
Figure 10.2 shows a maximally sized IP datagram divided into 8190 fragments. Each fragment contains 8 bytes except the last, which contains only 3 bytes. We also show the MF bit set in all the fragments except the last. This is an unrealistic example, but it illustrates several implementation issues.
The numbers above the original datagram are the byte offsets for the data portion of the datagram. The fragment offset (ip_off) is computed from the start of the data portion of the datagram. It is impossible for a fragment to include a byte beyond offset 65514 since the reassembled datagram would be larger than 65535 bytes t he maximum value of the ip_len field. This restricts the maximum value of ip_off to 8189 (8189 × 8 = 65512), which leaves room for 3 bytes in the last fragment. If IP options are present, the offset must be smaller still.
Because an IP internet is connectionless, fragments from one datagram may be interleaved with those from another at the destination. ip_id uniquely identifies the fragments of a particular datagram. The source system sets ip_id in each datagram to a unique value for all datagrams using the same source (ip_src), destination (ip_dst), and protocol (ip_p) values for the lifetime of the datagram on the internet.
To summarize, ip_id identifies the fragments of a particular datagram, ip_off positions the fragment within the original datagram, and the MF bit marks every fragment except the last.
The reassembly data structures appear in a single header. Reassembly and fragmentation processing is found in two C files. The three files are listed in Figure 10.3.
Only one global variable, ipq, is described in this chapter.???
The statistics modified by the fragmentation and reassembly code are shown in Figure 10.5. They are a subset of the statistics included in the ipstat structure described by Figure 8.4.
Table 10.5. Statistics collected in this chapter.
| Description |
|---|---|
| #datagrams not sent because fragmentation was required but was prohibited by the DF bit |
| #output packets dropped because of a memory shortage |
| #fragments transmitted |
| #packets fragmented for output |
We now return to ip_output and describe the fragmentation code. Recall from Figure 8.25 that if a packet fits within the MTU of the selected outgoing interface, it is transmitted in a single link-level frame. Otherwise the packet must be fragmented and transmitted in multiple frames. A packet may be a complete datagram or it may itself be a fragment that was created by a previous system. We describe the fragmentation code in three parts:
determine fragment size (Figure 10.6),
Table 10.6.
ip_outputfunction: determine fragment size.----------------------------------------------------------------------- ip_output.c 253 /* 254 * Too large for interface; fragment if possible. 255 * Must be able to put at least 8 bytes per fragment. 256 */ 257 if (ip->ip_off & IP_DF) { 258 error = EMSGSIZE; 259 ipstat.ips_cantfrag++; 260 goto bad; 261 } 262 len = (ifp->if_mtu - hlen) & ~7; 263 if (len < 8) { 264 error = EMSGSIZE; 265 goto bad; 266 } ----------------------------------------------------------------------- ip_output.c
construct fragment list (Figure 10.7), and
Table 10.7.
ip_outputfunction: construct fragment list.----------------------------------------------------------------------- ip_output.c 267 { 268 int mhlen, firstlen = len; 269 struct mbuf **mnext = &m->m_nextpkt; 270 /* 271 * Loop through length of segment after first fragment, 272 * make new header and copy data of each part and link onto chain. 273 */ 274 m0 = m; 275 mhlen = sizeof(struct ip); 276 for (off = hlen + len; off < (u_short) ip->ip_len; off += len) { 277 MGETHDR(m, M_DONTWAIT, MT_HEADER); 278 if (m == 0) { 279 error = ENOBUFS; 280 ipstat.ips_odropped++; 281 goto sendorfree; 282 } 283 m->m_data += max_linkhdr; 284 mhip = mtod(m, struct ip *); 285 *mhip = *ip; 286 if (hlen > sizeof(struct ip)) { 287 mhlen = ip_optcopy(ip, mhip) + sizeof(struct ip); 288 mhip->ip_hl = mhlen >> 2; 289 } 290 m->m_len = mhlen; 291 mhip->ip_off = ((off - hlen) >> 3) + (ip->ip_off & ~IP_MF); 292 if (ip->ip_off & IP_MF) 293 mhip->ip_off |= IP_MF; 294 if (off + len >= (u_short) ip->ip_len) 295 len = (u_short) ip->ip_len - off; 296 else 297 mhip->ip_off |= IP_MF; 298 mhip->ip_len = htons((u_short) (len + mhlen)); 299 m->m_next = m_copy(m0, off, len); 300 if (m->m_next == 0) { 301 (void) m_free(m); 302 error = ENOBUFS; /* ??? */ 303 ipstat.ips_odropped++; 304 goto sendorfree; 305 } 306 m->m_pkthdr.len = mhlen + len; 307 m->m_pkthdr.rcvif = (struct ifnet *) 0; 308 mhip->ip_off = htons((u_short) mhip->ip_off); 309 mhip->ip_sum = 0; 310 mhip->ip_sum = in_cksum(m, mhlen); 311 *mnext = m; 312 mnext = &m->m_nextpkt; 313 ipstat.ips_ofragments++; 314 } ----------------------------------------------------------------------- ip_output.c
construct initial fragment and send fragments (Figure 10.8).
Table 10.8. ip_output function: send fragments.
----------------------------------------------------------------------- ip_output.c 315 /* 316 * Update first fragment by trimming what's been copied out 317 * and updating header, then send each fragment (in order). 318 */ 319 m = m0; 320 m_adj(m, hlen + firstlen - (u_short) ip->ip_len); 321 m->m_pkthdr.len = hlen + firstlen; 322 ip->ip_len = htons((u_short) m->m_pkthdr.len); 323 ip->ip_off = htons((u_short) (ip->ip_off | IP_MF)); 324 ip->ip_sum = 0; 325 ip->ip_sum = in_cksum(m, hlen); 326 sendorfree: 327 for (m = m0; m; m = m0) { 328 m0 = m->m_nextpkt; 329 m->m_nextpkt = 0; 330 if (error == 0) 331 error = (*ifp->if_output) (ifp, m, 332 (struct sockaddr *) dst, ro->ro_rt); 333 else 334 m_freem(m); 335 } 336 if (error == 0) 337 ipstat.ips_fragmented++; 338 } ----------------------------------------------------------------------- ip_output.c |
253-261
The fragmentation algorithm is straightforward, but the implementation is complicated by the manipulation of the mbuf structures and chains. If fragmentation is prohibited by the DF bit, ip_output discards the packet and returns EMSGSIZE. If the datagram was generated on this host, a transport protocol passes the error back to the process, but if the datagram is being forwarded, ip_forward generates an ICMP destination unreachable error with an indication that the packet could not be forwarded without fragmentation (Figure 8.21).
Net/3 does not implement the path MTU discovery algorithms used to probe the path to a destination and discover the largest transmission unit supported by all the intervening networks. Sections 11.8 and 24.2 of Volume 1 describe path MTU discovery for UDP and TCP.
262-266
len, the number of data bytes in each fragment, is computed as the MTU of the interface less the size of the packet’s header and then rounded down to an 8-byte boundary by clearing the low-order 3 bits (& ~7). If the MTU is so small that each fragment contains less than 8 bytes, ip_output returns EMSGSIZE.
Each new fragment contains an IP header, some of the options from the original packet, and at most len data bytes.
The code in Figure 10.7, which is the start of a C compound statement, constructs the list of fragments starting with the second fragment. The original packet is converted into the initial fragment after the list is created (Figure 10.8).
267-269
The extra block allows mhlen, firstlen, and mnext to be declared closer to their use in the function. These variables are in scope until the end of the block and hide any similarly named variables outside the block.
270-276
Since the original mbuf chain becomes the first fragment, the for loop starts with the offset of the second fragment: hlen + len. For each fragment ip_output takes the following actions:
277-284Allocate a new packet mbuf and adjust its
m_datapointer to leave room for a 16-byte link-layer header (max_linkhdr). Ifip_outputdidn’t do this, the network interface driver would have to allocate an additional mbuf to hold the link header or move the data. Both are time-consuming tasks that are easily avoided here.285-290Copy the IP header and IP options from the original packet into the new packet. The former is copied with a structure assignment.
ip_optcopycopies only those options that get copied into each fragment (Section 10.4).291-297Set the offset field (
ip_off) for the fragment including the MF bit. If MF is set in the original packet, then MF is set in all the fragments. If MF is not set in the original packet, then MF is set for every fragment except the last.298Set the length of this fragment accounting for a shorter header (
ip_optcopymay not have copied all the options) and a shorter data area for the last fragment. The length is stored in network byte order.299-305Copy the data from the original packet into this fragment.
m_copyallocates additional mbufs if necessary. Ifm_copyfails,ENOBUFSis posted. Any mbufs already allocated are discarded atsendorfree.306-314Adjust the mbuf packet header of the newly created fragment to have the correct total length, clear the new fragment’s interface pointer, convert
ip_offto network byte order, compute the checksum for the new fragment, and link the fragment to the previous fragment throughm_nextpkt.
In Figure 10.8, ip_output constructs the initial fragment and then passes each fragment to the interface layer.
315-325
The original packet is converted into the first fragment by trimming the extra data from its end, setting the MF bit, converting ip_len and ip_off to network byte order, and computing the new checksum. All the IP options are retained in this fragment. At the destination host, only the IP options from the first fragment of a datagram are retained when the datagram is reassembled (Figure 10.28). Some options, such as source routing, must be copied into each fragment even though the option is discarded during reassembly.
326-338
At this point, ip_output has either a complete list of fragments or an error has occurred and the partial list of fragments must be discarded. The for loop traverses the list either sending or discarding fragments according to error. Any error encountered while sending fragments causes the remaining fragments to be discarded.
During fragmentation, ip_optcopy (Figure 10.9) copies the options from the incoming packet (if the packet is being forwarded) or from the original datagram (if the datagram is locally generated) into the outgoing fragments.
Table 10.9. ip_optcopy function.
----------------------------------------------------------------------- ip_output.c 395 int 396 ip_optcopy(ip, jp) 397 struct ip *ip, *jp; 398 { 399 u_char *cp, *dp; 400 int opt, optlen, cnt; 401 cp = (u_char *) (ip + 1); 402 dp = (u_char *) (jp + 1); 403 cnt = (ip->ip_hl << 2) - sizeof(struct ip); 404 for (; cnt > 0; cnt -= optlen, cp += optlen) { 405 opt = cp[0]; 406 if (opt == IPOPT_EOL) 407 break; 408 if (opt == IPOPT_NOP) { 409 /* Preserve for IP mcast tunnel's LSRR alignment. */ 410 *dp++ = IPOPT_NOP; 411 optlen = 1; 412 continue; 413 } else 414 optlen = cp[IPOPT_OLEN]; 415 /* bogus lengths should have been caught by ip_dooptions */ 416 if (optlen > cnt) 417 optlen = cnt; 418 if (IPOPT_COPIED(opt)) { 419 bcopy((caddr_t) cp, (caddr_t) dp, (unsigned) optlen); 420 dp += optlen; 421 } 422 } 423 for (optlen = dp - (u_char *) (jp + 1); optlen & 0x3; optlen++) 424 *dp++ = IPOPT_EOL; 425 return (optlen); 426 } ----------------------------------------------------------------------- ip_output.c |
395-422
The arguments to ip_optcopy are: ip, a pointer to the IP header of the outgoing packet; and jp, a pointer to the IP header of the newly created fragment. ip_optcopy initializes cp and dp to point to the first option byte in each packet and advances cp and dp as it processes each option. The first for loop copies a single option during each iteration stopping when it encounters an EOL option or when it has examined all the options. NOP options are copied to preserve any alignment constraints in the subsequent options.
The Net/2 release discarded NOP options.
If IPOPT_COPIED indicates that the copied bit is on, ip_optcopy copies the option to the new fragment. Figure 9.5 shows which options have the copied bit set. If an option length is too large, it is truncated; ip_dooptions should have already discovered this type of error.
423-426
The second for loop pads the option list out to a 4-byte boundary. This is required, since the packet’s header length (ip_hlen) is measured in 4-byte units. It also ensures that the transport header that follows is aligned on a 4-byte boundary. This improves performance since many transport protocols are designed so that 32-bit header fields are aligned on 32-bit boundaries if the transport header starts on a 32-bit boundary. This arrangement increases performance on CPUs that have difficulty accessing unaligned 32-bit words.
Figure 10.10 illustrates the operation of ip_optcopy.

In Figure 10.10 we see that ip_optcopy does not copy the timestamp option (its copied bit is 0) but does copy the LSRR option (its copied bit is 1). ip_optcopy has also added a single EOL option to pad the new options to a 4-byte boundary.
Now that we have described the fragmentation of a datagram (or of a fragment), we return to ipintr and the reassembly process. In Figure 8.15 we omitted the reassembly code from ipintr and postponed its discussion. ipintr can pass only entire datagrams up to the transport layer for processing. Fragments that are received by ipintr are passed to ip_reass, which attempts to reassemble fragments into complete datagrams. The code from ipintr is shown in Figure 10.11.
Table 10.11. ipintr function: fragment processing.
------------------------------------------------------------------------ ip_input.c 271 ours: 272 /* 273 * If offset or IP_MF are set, must reassemble. 274 * Otherwise, nothing need be done. 275 * (We could look in the reassembly queue to see 276 * if the packet was previously fragmented, 277 * but it's not worth the time; just let them time out.) 278 */ 279 if (ip->ip_off & ~IP_DF) { 280 if (m->m_flags & M_EXT) { /* XXX */ 281 if ((m = m_pullup(m, sizeof(struct ip))) == 0) { 282 ipstat.ips_toosmall++; 283 goto next; 284 } 285 ip = mtod(m, struct ip *); 286 } 287 /* 288 * Look for queue of fragments 289 * of this datagram. 290 */ 291 for (fp = ipq.next; fp != &ipq; fp = fp->next) 292 if (ip->ip_id == fp->ipq_id && 293 ip->ip_src.s_addr == fp->ipq_src.s_addr && 294 ip->ip_dst.s_addr == fp->ipq_dst.s_addr && 295 ip->ip_p == fp->ipq_p) 296 goto found; 297 fp = 0; 298 found: 299 /* 300 * Adjust ip_len to not reflect header, 301 * set ip_mff if more fragments are expected, 302 * convert offset of this to bytes. 303 */ 304 ip->ip_len -= hlen; 305 ((struct ipasfrag *) ip)->ipf_mff &= ~1; 306 if (ip->ip_off & IP_MF) 307 ((struct ipasfrag *) ip)->ipf_mff |= 1; 308 ip->ip_off <<= 3; 309 /* 310 * If datagram marked as having more fragments 311 * or if this is not the first fragment, 312 * attempt reassembly; if it succeeds, proceed. 313 */ 314 if (((struct ipasfrag *) ip)->ipf_mff & 1 || ip->ip_off) { 315 ipstat.ips_fragments++; 316 ip = ip_reass((struct ipasfrag *) ip, fp); 317 if (ip == 0) 318 goto next; 319 ipstat.ips_reassembled++; 320 m = dtom(ip); 321 } else if (fp) 322 ip_freef(fp); 323 } else 324 ip->ip_len -= hlen; ------------------------------------------------------------------------ ip_input.c |
271-279
Recall that ip_off contains the DF bit, the MF bit, and the fragment offset. The DF bit is masked out and if either the MF bit or fragment offset is nonzero, the packet is a fragment that must be reassembled. If both are zero, the packet is a complete datagram, the reassembly code is skipped and the else clause at the end of Figure 10.11 is executed, which excludes the header length from the total datagram length.
280-286
m_pullup moves data in an external cluster into the data area of the mbuf. Recall that the SLIP interface (Section 5.3) may return an entire IP packet in an external cluster if it does not fit in a single mbuf. Also m_devget can return the entire packet in a cluster (Section 2.6). Before the mtod macros will work (Section 2.6), m_pullup must move the IP header from the cluster into the data area of an mbuf.
287-297
Net/3 keeps incomplete datagrams on the global doubly linked list, ipq. The name is somewhat confusing since the data structure isn’t a queue. That is, insertions and deletions can occur anywhere in the list, not just at the ends. We’ll use the term list to emphasize this fact.
ipintr performs a linear search of the list to locate the appropriate datagram for the current fragment. Remember that fragments are uniquely identified by the 4-tuple: {ip_id, ip_src, ip_dst, ip_p}. Each entry in ipq is a list of fragments and fp points to the appropriate list if ipintr finds a match.
Net/3 uses linear searches to access many of its data structures. While simple, this method can become a bottleneck in hosts supporting large numbers of network connections.
298-303
At found, the packet is modified by ipintr to facilitate reassembly:
304ipintrchangesip_lento exclude the standard IP header and any options. We must keep this in mind to avoid confusion with the standard interpretation ofip_len, which includes the standard header, options, and data.ip_lenis also changed if the reassembly code is skipped because this is not a fragment.305-307ipintrcopies the MF flag into the low-order bit ofipf_mff, which overlaysip_tos(&= ~1clears the low-order bit only). Notice thatipmust be cast to a pointer to anipasfragstructure beforeipf_mffis a valid member. Section 10.6 and Figure 10.14 describe theipasfragstructure.Although RFC 1122 requires the IP layer to provide a mechanism that enables the transport layer to set
ip_tosfor every outgoing datagram, it only recommends that the IP layer passip_tosvalues to the transport layer at the destination host. Since the low-order bit of the TOS field must always be 0, it is available to hold the MF bit whileip_off(where the MF bit is normally found) is used by the reassembly algorithm.ip_offcan now be accessed as a 16-bit offset instead of 3 flag bits and a 13-bit offset.308ip_offis multiplied by 8 to convert from 8-byte to 1-byte units.
ipf_mff and ip_off determine if ipintr should attempt reassembly. Figure 10.12 describes the different cases and the corresponding actions. Remember that fp points to the list of fragments the system has previously received for the datagram. Most of the work is done by ip_reass.
Table 10.12. IP fragment processing in ipintr and ip_reass.
|
|
| Description | Action |
|---|---|---|---|---|
0 | false | null | complete datagram | no assembly required |
0 | false | nonnull | complete datagram | discard the previous fragments |
any | true | null | fragment of new datagram | initialize new fragment list with this fragment |
any | true | nonnull | fragment of incomplete datagram | insert into existing fragment list, attempt reassembly |
nonzero | false | null | tail fragment of new datagram | initialize new fragment list |
nonzero | false | nonnull | tail fragment of incomplete datagram | insert into existing fragment list, attempt reassembly |
309-322
If ip_reass is able to assemble a complete datagram by combining the current fragment with previously received fragments, it returns a pointer to the reassembled datagram. If reassembly is not possible, ip_reass saves the fragment and ipintr jumps to next to process the next packet (Figure 8.12).
323-324
This else branch is taken when a complete datagram arrives and ip_hlen is modified as described earlier. This is the normal flow, since most received datagrams are not fragments.
If a complete datagram is available after reassembly processing, it is passed up to the appropriate transport protocol by ipintr (Figure 8.15):
(*inetsw[ip_protox[ip->ip_p]].pr_input) (m, hlen);
ipintr passes ip_reass a fragment to be processed, and a pointer to the matching reassembly header from ipq. ip_reass attempts to assemble and return a complete datagram or links the fragment into the datagram’s reassembly list for reassembly when the remaining fragments arrive. The head of each reassembly list is an ipq structure, show in Figure 10.13.
Table 10.13. ipq structure.
-------------------------------------------------------------------------- ip_var.h 52 struct ipq { 53 struct ipq *next, *prev; /* to other reass headers */ 54 u_char ipq_ttl; /* time for reass q to live */ 55 u_char ipq_p; /* protocol of this fragment */ 56 u_short ipq_id; /* sequence id for reassembly */ 57 struct ipasfrag *ipq_next, *ipq_prev; 58 /* to ip headers of fragments */ 59 struct in_addr ipq_src, ipq_dst; 60 }; -------------------------------------------------------------------------- ip_var.h |
52-60
The four fields required to identify a datagram’s fragments, ip_id, ip_p, ip_src, and ip_dst, are kept in the ipq structure at the head of each reassembly list. Net/3 constructs the list of datagrams with next and prev and the list of fragments with ipq_next and ipq_prev.
The IP header of incoming IP packets is converted to an ipasfrag structure (Figure 10.14) before it is placed on a reassembly list.
Table 10.14. ipasfrag structure.
------------------------------------------------------------------------- ip_var.h 66 struct ipasfrag { 67 #if BYTE_ORDER == LITTLE_ENDIAN 68 u_char ip_hl:4, 69 ip_v:4; 70 #endif 71 #if BYTE_ORDER == BIG_ENDIAN 72 u_char ip_v:4, 73 ip_hl:4; 74 #endif 75 u_char ipf_mff; /* XXX overlays ip_tos: use low bit 76 * to avoid destroying tos; 77 * copied from (ip_off&IP_MF) */ 78 short ip_len; 79 u_short ip_id; 80 short ip_off; 81 u_char ip_ttl; 82 u_char ip_p; 83 u_short ip_sum; 84 struct ipasfrag *ipf_next; /* next fragment */ 85 struct ipasfrag *ipf_prev; /* previous fragment */ 86 }; ------------------------------------------------------------------------- ip_var.h |
66-86
ip_reass collects fragments for a particular datagram on a circular doubly linked list joined by the ipf_next and ipf_prev members. These pointers overlay the source and destination addresses in the IP header. The ipf_mff member overlays ip_tos from the ip structure. The other members are the same.
Figure 10.15 illustrates the relationship between the fragment header list (ipq) and the fragments (ipasfrag).

Down the left side of Figure 10.15 is the list of reassembly headers. The first node in the list is the global ipq structure, ipq. It never has a fragment list associated with it. The ipq list is a doubly linked list used to support fast insertions and deletions. The next and prev pointers reference the next or previous ipq structure, which we have shown by terminating the arrows at the corners of the structures.
Each ipq structure is the head node of a circular doubly linked list of ipasfrag structures. Incoming fragments are placed on these fragment lists ordered by their fragment offset. We’ve highlighted the pointers for these lists in Figure 10.15.
Figure 10.15 still does not show all the complexity of the reassembly structures. The reassembly code is difficult to follow because it relies so heavily on casting pointers to three different structures on the underlying mbuf. We’ve seen this technique already, for example, when an ip structure overlays the data portion of an mbuf.
Figure 10.16 illustrates the relationship between an mbuf, an ipq structure, an ipasfrag structure, and an ip structure.

A lot of information is contained within Figure 10.16:
All the structures are located within the data area of an mbuf.
The
ipqlist consists ofipqstructures joined bynextandprev. Within the structure, the four fields that uniquely identify an IP datagram are saved (shaded in Figure 10.16).Each
ipqstructure is treated as anipasfragstructure when accessed as the head of a linked list of fragments. The fragments are joined byipf_nextandipf_prev, which overlay theipqstructures’ipq_nextandipq_prevmembers.Each
ipasfragstructure overlays theipstructure from the incoming fragment. The data that arrived with the fragment follows the structure in the mbuf. The members that have a different meaning in theipasfragstructure than they do in theipstructure are shaded.
Figure 10.15 showed the physical connections between the reassembly structures and Figure 10.16 illustrated the overlay technique used by ip_reass. In Figure 10.17 we show the reassembly structures from a logical point of view: this figure shows the reassembly of three datagrams and the relationship between the ipq list and the ipasfrag structures.

The head of each reassembly list contains the id, protocol, source, and destination address of the original datagram. Only the ip_id field is shown in the figure. Each fragment list is ordered by the offset field, the fragment is labeled with MF if the MF bit is set, and missing fragments appear as shaded boxes. The numbers within each fragment show the starting and ending byte offset for the fragment relative to the data portion of the original datagram, not to the IP header of the original datagram.
The example is constructed to show three UDP datagrams with no IP options and 1024 bytes of data each. The total length of each datagram is 1052 (20 + 8 + 1024) bytes, which is well within the 1500-byte MTU of an Ethernet. The datagrams encounter a SLIP link on the way to the destination, and the router at that link fragments the datagrams to fit within a typical 296-byte SLIP MTU. Each datagram arrives as four fragments. The first fragment contain a standard 20-byte IP header, the 8-byte UDP header, and 264 bytes of data. The second and third fragments contain a 20-byte IP header and 272 bytes of data. The last fragment has a 20-byte header and 216 bytes of data (1032 = 272 × 3 + 216).
In Figure 10.17, datagram 5 is missing a single fragment containing bytes 272 through 543. Datagram 6 is missing the first fragment, bytes 0 through 271, and the end of the datagram starting at offset 816. Datagram 7 is missing the first three fragments, bytes 0 through 815.
Figure 10.18 lists ip_reass. Remember that ipintr calls ip_reass when an IP fragment has arrived for this host, and after any options have been processed.
Table 10.18. ip_reass function: datagram reassembly.
------------------------------------------------------------------------ ip_input.c 337 /* 338 * Take incoming datagram fragment and try to 339 * reassemble it into whole datagram. If a chain for 340 * reassembly of this datagram already exists, then it 341 * is given as fp; otherwise have to make a chain. 342 */ 343 struct ip * 344 ip_reass(ip, fp) 345 struct ipasfrag *ip; 346 struct ipq *fp; 347 { 348 struct mbuf *m = dtom(ip); 349 struct ipasfrag *q; 350 struct mbuf *t; 351 int hlen = ip->ip_hl << 2; 352 int i, next; 353 /* 354 * Presence of header sizes in mbufs 355 * would confuse code below. 356 */ 357 m->m_data += hlen; 358 m->m_len -= hlen; /* reassembly code */ 465 dropfrag: 466 ipstat.ips_fragdropped++; 467 m_freem(m); 468 return (0); 469 } ------------------------------------------------------------------------ ip_input.c |
343-358
When ip_reass is called, ip points to the fragment and fp either points to the matching ipq structure or is null.
Since reassembly involves only the data portion of each fragment, ip_reass adjusts m_data and m_len from the mbuf containing the fragment to exclude the IP header in each fragment.
465-469
When an error occurs during reassembly, the function jumps to dropfrag, which increments ips_fragdropped, discards the fragment, and returns a null pointer.
Dropping fragments usually incurs a serious performance penalty at the transport layer since the entire datagram must be retransmitted. TCP is careful to avoid fragmentation, but a UDP application must take steps to avoid fragmentation on its own. [Kent and Mogul 1987] explain why fragmentation should be avoided.
All IP implementations must to be able to reassemble a datagram of up to 576 bytes. There is no general way to determine the size of the largest datagram that can be reassembled by a remote host. We’ll see in Section 27.5 that TCP has a mechanism to determine the size of the maximum datagram that can be processed by the remote host. UDP has no such mechanism, so many UDP-based protocols (e.g., RIP, TFTP, BOOTP, SNMP, and DNS) are designed around the 576-byte limit.
We’ll show the reassembly code in seven parts, starting with Figure 10.19.
Table 10.19. ip_reass function: create reassembly list.
----------------------------------------------------------------------- ip_input.c 359 /* 360 * If first fragment to arrive, create a reassembly queue. 361 */ 362 if (fp == 0) { 363 if ((t = m_get(M_DONTWAIT, MT_FTABLE)) == NULL) 364 goto dropfrag; 365 fp = mtod(t, struct ipq *); 366 insque(fp, &ipq); 367 fp->ipq_ttl = IPFRAGTTL; 368 fp->ipq_p = ip->ip_p; 369 fp->ipq_id = ip->ip_id; 370 fp->ipq_next = fp->ipq_prev = (struct ipasfrag *) fp; 371 fp->ipq_src = ((struct ip *) ip)->ip_src; 372 fp->ipq_dst = ((struct ip *) ip)->ip_dst; 373 q = (struct ipasfrag *) fp; 374 goto insert; 375 } ----------------------------------------------------------------------- ip_input.c |
359-366
When fp is null, ip_reass creates a reassembly list with the first fragment of the new datagram. It allocates an mbuf to hold the head of the new list (an ipq structure), and calls insque to insert the structure in the list of reassembly lists.
Figure 10.20 lists the functions that manipulate the datagram and fragment lists.
Table 10.20. Queueing functions used by ip_reass.
Function | Description |
|---|---|
| Insert node just after prev. void insque(void *node, void *prev); |
| Remove node from list. void remque(void *node); |
| Insert fragment p just after fragment prev. void ip_enq(struct ipasfrag *p, struct ipasfrag *prev); |
| Remove fragment p. void ip_deq(struct ipasfrag *p); |
The functions
insqueandremqueare defined inmachdep.cfor the 386 version of Net/3. Each machine has its ownmachdep.cfile in which customized versions of kernel functions are defined, typically to improve performance. This file also contains architecture-dependent functions such as the interrupt handler support, cpu and device configuration, and memory management functions.insqueandremqueexist primarily to maintain the kernel’s run queue. Net/3 can use them for the datagram reassembly list because both lists have next and previous pointers as the first two members of their respective node structures. These functions work for any similarly structured list, although the compiler may issue some warnings. This is yet another example of accessing memory through two different structures.In all the kernel structures the next pointer always precedes the previous pointer (Figure 10.14, for example). This is because the
insqueandremquefunctions were first implemented on the VAX using theinsqueandremquehardware instructions, which require this ordering of the forward and backward pointers.The fragment lists are not joined with the first two members of the
ipasfragstructures (Figure 10.14) so Net/3 callsip_enqandip_deqinstead ofinsqueandremque.
367
The time-to-live field (ipq_ttl) is required by RFC 1122 and limits the time Net/3 waits for fragments to complete a datagram. It is different from the TTL field in the IP header, which limits the amount of time a packet circulates in the internet. The IP header TTL field is reused as the reassembly timeout since the header TTL is not needed once the fragment arrives at its final destination.
In Net/3, the initial value of the reassembly timeout is 60 (IPFRAGTTL). Since ipq_ttl is decremented every time the kernel calls ip_slowtimo and the kernel calls ip_slowtimo every 500 ms, the system discards an IP reassembly list if it hasn’t assembled a complete IP datagram within 30 seconds of receiving any one of the datagram’s fragments. The reassembly timer starts ticking on the first call to ip_slowtimo after the list is created.
RFC 1122 recommends that the reassembly time be between 60 and 120 seconds and that an ICMP time exceeded error be sent to the source host if the timer expires and the first fragment of the datagram has been received. The header and options of the other fragments are always discarded during reassembly and an ICMP error must contain the first 64 bits of the erroneous datagram (or less if the datagram was shorter than 8 bytes). So, if the kernel hasn’t received fragment 0, it can’t send an ICMP message.
Net/3’s timer is a bit too short and Net/3 neglects to send the ICMP message when a fragment is discarded. The requirement to return the first 64 bits of the datagram ensures that the first portion of the transport header is included, which allows the error message to be returned to the application that generated it. Note that TCP and UDP purposely put their port numbers in the first 8 bytes of their headers for this reason.
368-375
ip_reass saves ip_p, ip_id, ip_src, and ip_dst in the ipq structure allocated for this datagram, points the ipq_next and ipq_prev pointers to the ipq structure (i.e., it constructs a circular list with one node), points q at this structure, and jumps to insert (Figure 10.25) where it inserts the first fragment, ip, into the new reassembly list.
The next part of ip_reass, shown in Figure 10.21, is executed when fp is not null and locates the correct position in the existing list for the new fragment.
Table 10.21. ip_reass function: find position in reassembly list.
----------------------------------------------------------------------- ip_input.c 376 /* 377 * Find a fragment which begins after this one does. 378 */ 379 for (q = fp->ipq_next; q != (struct ipasfrag *) fp; q = q->ipf_next) 380 if (q->ip_off > ip->ip_off) 381 break; ----------------------------------------------------------------------- ip_input.c |
376-381
Since fp is not null, the for loop searches the datagram’s fragment list to locate a fragment with an offset greater than ip_off.
The byte ranges contained within fragments may overlap at the destination. This can happen when a transport-layer protocol retransmits a datagram that gets sent along a route different from the one followed by the original datagram. The fragmentation pattern may also be different resulting in overlaps at the destination. The transport protocol must be able to force IP to use the original ID field in order for the datagram to be recognized as a retransmission at the destination.
Net/3 does not provide a mechanism for a transport protocol to ensure that IP ID fields are reused on a retransmitted datagram.
ip_outputalways assigns a new value by incrementing the global integerip_idwhen preparing a new datagram (Figure 8.22). Nevertheless, a Net/3 system could receive overlapping fragments from a system that lets the transport layer retransmit IP datagrams with the same ID field.
Figure 10.22 illustrates the different ways in which the fragment may overlap with existing fragments. The fragments are numbered according to the order in which they arrive at the destination host. The reassembled fragment is shown at the bottom of Figure 10.22 The shaded areas of the fragments are the duplicate bytes that are discarded.
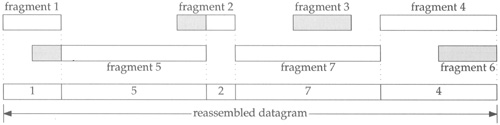
In the following discussion, an earlier fragment is a fragment that previously arrived at the host.
The code in Figure 10.23 trims or discards incoming fragments.
Table 10.23. ip_reass function: trim incoming packet.
------------------------------------------------------------------------ ip_input.c 382 /* 383 * If there is a preceding fragment, it may provide some of 384 * our data already. If so, drop the data from the incoming 385 * fragment. If it provides all of our data, drop us. 386 */ 387 if (q->ipf_prev != (struct ipasfrag *) fp) { 388 i = q->ipf_prev->ip_off + q->ipf_prev->ip_len - ip->ip_off; 389 if (i > 0) { 390 if (i >= ip->ip_len) 391 goto dropfrag; 392 m_adj(dtom(ip), i); 393 ip->ip_off += i; 394 ip->ip_len -= i; 395 } 396 } ------------------------------------------------------------------------ ip_input.c |
382-396
ip_reass discards bytes that overlap the end of an earlier fragment by trimming the new fragment (the front of fragment 5 in Figure 10.22) or discarding the new fragment (fragment 6) if all its bytes arrived in an earlier fragment (fragment 4).
The code in Figure 10.24 trims or discards existing fragments.
Table 10.24. ip_reass function: trim existing packets.
----------------------------------------------------------------------- ip_input.c 397 /* 398 * While we overlap succeeding fragments trim them or, 399 * if they are completely covered, dequeue them. 400 */ 401 while (q != (struct ipasfrag *) fp && ip->ip_off + ip->ip_len > q->ip_off) { 402 i = (ip->ip_off + ip->ip_len) - q->ip_off; 403 if (i < q->ip_len) { 404 q->ip_len -= i; 405 q->ip_off += i; 406 m_adj(dtom(q), i); 407 break; 408 } 409 q = q->ipf_next; 410 m_freem(dtom(q->ipf_prev)); 411 ip_deq(q->ipf_prev); 412 } ----------------------------------------------------------------------- ip_input.c |
397-412
If the current fragment partially overlaps the front of an earlier fragment, the duplicate data is trimmed from the earlier fragment (the front of fragment 2 in Figure 10.22). Any earlier fragments that are completely overlapped by the arriving fragment are discarded (fragment 3).
In Figure 10.25, the incoming fragment is inserted into the reassembly list.
Table 10.25. ip_reass function: insert packet.
----------------------------------------------------------------------- ip_input.c 413 insert: 414 /* 415 * Stick new fragment in its place; 416 * check for complete reassembly. 417 */ 418 ip_enq(ip, q->ipf_prev); 419 next = 0; 420 for (q = fp->ipq_next; q != (struct ipasfrag *) fp; q = q->ipf_next) { 421 if (q->ip_off != next) 422 return (0); 423 next += q->ip_len; 424 } 425 if (q->ipf_prev->ipf_mff & 1) 426 return (0); ----------------------------------------------------------------------- ip_input.c |
413-426
After trimming, ip_enq inserts the fragment into the list and the list is scanned to determine if all the fragments have arrived. If any fragment is missing, or the last fragment in the list has ipf_mff set, ip_reass returns 0 and waits for more fragments.
When the current fragment completes a datagram, the entire list is converted to an mbuf chain by the code shown in Figure 10.26.
Table 10.26. ip_reass function: reassemble datagram.
------------------------------------------------------------------------ ip_input.c 427 /* 428 * Reassembly is complete; concatenate fragments. 429 */ 430 q = fp->ipq_next; 431 m = dtom(q); 432 t = m->m_next; 433 m->m_next = 0; 434 m_cat(m, t); 435 q = q->ipf_next; 436 while (q != (struct ipasfrag *) fp) { 437 t = dtom(q); 438 q = q->ipf_next; 439 m_cat(m, t); 440 } ------------------------------------------------------------------------ ip_input.c |
427-440
If all the fragments for the datagram have been received, the while loop reconstructs the datagram from the fragments with m_cat.
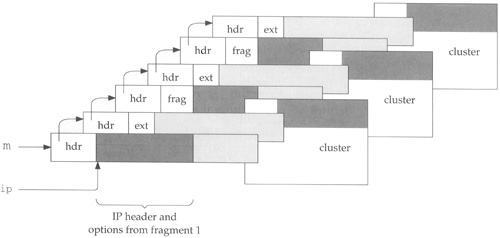
Figure 10.27 shows the relationships between mbufs and the ipq structure for a datagram composed of three fragments.

The darkest areas in the figure mark the data portions of a packet and the lighter shaded areas mark the unused portions of the mbufs. We show three fragments each contained in a chain of two mbufs; a packet header, and a cluster. The m_data pointer in the first mbuf of each fragment points to the packet data, not the packet header. Therefore, the mbuf chain constructed by m_cat includes only the data portion of the fragments.
This is the typical scenario when a fragment contains more than 208 bytes of data (Section 2.6). The “frag” portion of the mbufs is the IP header from the fragment. The m_data pointer of the first mbuf in each chain points beyond “opts” because of the code in Figure 10.18.
Figure 10.28 shows the reassembled datagram using the mbufs from all the fragments. Notice that the IP header and options from fragments 2 and 3 are not included in the reassembled datagram.
The header of the first fragment is still being used as an ipasfrag structure. It is restored to a valid IP datagram header by the code shown in Figure 10.29.
Table 10.29. ip_reass function: datagram reassembly.
----------------------------------------------------------------------- ip_input.c 441 /* 442 * Create header for new ip packet by 443 * modifying header of first packet; 444 * dequeue and discard fragment reassembly header. 445 * Make header visible. 446 */ 447 ip = fp->ipq_next; 448 ip->ip_len = next; 449 ip->ipf_mff &= ~1; 450 ((struct ip *) ip)->ip_src = fp->ipq_src; 451 ((struct ip *) ip)->ip_dst = fp->ipq_dst; 452 remque(fp); 453 (void) m_free(dtom(fp)); 454 m = dtom(ip); 455 m->m_len += (ip->ip_hl << 2); 456 m->m_data -= (ip->ip_hl << 2); 457 /* some debugging cruft by sklower, below, will go away soon */ 458 if (m->m_flags & M_PKTHDR) { /* XXX this should be done elsewhere */ 459 int plen = 0; 460 for (t = m; m; m = m->m_next) 461 plen += m->m_len; 462 t->m_pkthdr.len = plen; 463 } 464 return ((struct ip *) ip); ----------------------------------------------------------------------- ip_input.c |
441-456
ip_reass points ip to the first fragment in the list and changes the ipasfrag structure back to an ip structure by restoring the length of the datagram to ip_len, the source address to ip_src, the destination address to ip_dst; and by clearing the low-order bit in ipf_mff. (Recall from Figure 10.14 that ipf_mff in the ipasfrag structure overlays ipf_tos in the ip structure.)
ip_reass removes the entire packet from the reassembly list with remque, discards the ipq structure that was the head of the list, and adjusts m_len and m_data in the first mbuf to include the previously hidden IP header and options from the first fragment.
457-464
The code here is always executed, since the first mbuf for the datagram is always a packet header. The for loop computes the number of data bytes in the mbuf chain and saves the value in m_pkthdr.len.
The purpose of the copied bit in the option type field should be clear now. Since the only options retained at the destination are those that appear in the first fragment, only options that control processing of the packet as it travels toward its destination are copied. Options that collect information while in transit are not copied, since the information collected is discarded at the destination when the packet is reassembled.
As shown in Section 7.4, each protocol in Net/3 may specify a function to be called every 500 ms. For IP, that function is ip_slowtimo, shown in Figure 10.30, which times out the fragments on the reassembly list.
Table 10.30. ip_slowtimo function.
------------------------------------------------------------------------------ ip_input.c 515 void 516 ip_slowtimo(void) 517 { 518 struct ipq *fp; 519 int s = splnet(); 520 fp = ipq.next; 521 if (fp == 0) { 522 splx(s); 523 return; 524 } 525 while (fp != &ipq) { 526 --fp->ipq_ttl; 527 fp = fp->next; 528 if (fp->prev->ipq_ttl == 0) { 529 ipstat.ips_fragtimeout++; 530 ip_freef(fp->prev); 531 } 532 } 533 splx(s); 534 } ------------------------------------------------------------------------------ ip_input.c |
515-534
ip_slowtimo traverses the list of partial datagrams and decrements the reassembly TTL field. ip_freef is called if the field drops to 0 to discard the fragments associated with the datagram. ip_slowtimo runs at splnet to prevent the lists from being modified by incoming packets.
ip_freef is shown in Figure 10.31.
Table 10.31. ip_freef function.
----------------------------------------------------------------------- ip_input.c 474 void 475 ip_freef(fp) 476 struct ipq *fp; 477 { 478 struct ipasfrag *q, *p; 479 for (q = fp->ipq_next; q != (struct ipasfrag *) fp; q = p) { 480 p = q->ipf_next; 481 ip_deq(q); 482 m_freem(dtom(q)); 483 } 484 remque(fp); 485 (void) m_free(dtom(fp)); 486 } ----------------------------------------------------------------------- ip_input.c |
470-486
ip_freef removes and releases every fragment on the list pointed to by fp and then releases the list itself.
In Figure 7.14 we showed that IP defines ip_drain as the function to be called when the kernel needs additional memory. This usually occurs during mbuf allocation, which we described with Figure 2.13. ip_drain is shown in Figure 10.32.
Table 10.32. ip_drain function.
-------------------------------------------------------------- ip_input.c 538 void 539 ip_drain() 540 { 541 while (ipq.next != &ipq) { 542 ipstat.ips_fragdropped++; 543 ip_freef(ipq.next); 544 } 545 } -------------------------------------------------------------- ip_input.c |
538-545
The simplest way for IP to release memory is to discard all the IP fragments on the reassembly list. For IP fragments that belong to a TCP segment, TCP eventually retransmits the data. IP fragments that belong to a UDP datagram are lost and UDP-based protocols must handle this at the application layer.
In this chapter we showed how ip_output splits an outgoing datagram into fragments if it is too large to be transmitted on the selected network. Since fragments may themselves be fragmented as they travel toward their final destination and may take multiple paths, only the destination host can reassemble the original datagram.
ip_reass accepts incoming fragments and attempts to reassemble datagrams. If it is successful, the datagram is passed back to ipintr and then to the appropriate transport protocol. Every IP implementation must reassemble datagrams of up to 576 bytes. The only limit for Net/3 is the number of mbufs that are available. ip_slowtimo discards incomplete datagrams when all their fragments haven’t been received within a reasonable amount of time.
10.1 | Modify |
10.2 | The recorded route in a fragmented datagram may be different in each fragment. When a datagram is reassembled at the destination host, which return route is available to the transport protocols? |
10.2 | After reassembly, only the options from the initial fragment are available to the transport protocols. |
10.3 | Draw a picture showing the mbufs involved in the |
10.3 | The fragment is read into a cluster since the data length (204 + 20) is greater than 208 (Figure 2.16).
 |
10.4 | [Auerbach 1994] suggests that after fragmenting a datagram, the last fragment should be sent first. If the receiving system gets that last fragment first, it can use the offset to allocate an appropriately sized reassembly buffer for the datagram. Modify
|
10.5 | Use the statistics in Figure 8.5 to answer the following questions. What is the average number of fragments per reassembled datagram? What is the average number of fragments created when an outgoing datagram is fragmented? |
10.5 | The average number of received fragments per datagram is The average number of fragments created for an outgoing datagram is |
10.6 | What happens to a packet when the reserved bit in |
10.6 | In Figure 10.11 the packet is initially processed as a fragment. The reserved bit is discarded when |