
The previous two chapters discussed multicasting on a single network. In this chapter we look at multicasting across an entire internet. We describe the operation of the mrouted program, which computes the multicast routing tables, and the kernel functions that forward multicast datagrams between networks.
Technically, multicast packets are forwarded. In this chapter we assume that every multicast packet contains an entire datagram (i.e., there are no fragments), so we use the term datagram exclusively. Net/3 forwards IP fragments as well as IP datagrams.
Figure 14.1 shows several versions of mrouted and how they correspond to the BSD releases. The mrouted releases include both the user-level daemons and the kernel-level multicast code.
IP multicast technology is an active area of research and development. This chapter discusses version 2.0 of the multicast software, which is included in Net/3 but is considered an obsolete implementation. Version 3.3 was released too late to be discussed fully in this text, but we will point out various 3.3 features along the way.
Because commercial multicast routers are not widely deployed, multicast networks are often constructed using multicast tunnels, which connect two multicast routers over a standard IP unicast internet. Multicast tunnels are supported by Net/3 and are constructed with the Loose Source Record Route (LSRR) option (Section 9.6). An improved tunneling technique encapsulates the IP multicast datagram within an IP unicast datagram and is supported by version 3.3 of the multicast code but is not supported by Net/3.
As in Chapter 12, we use the generic term transport protocols to refer to the protocols that send and receive multicast datagrams, but UDP is the only Internet protocol that supports multicasting.
The three files listed in Figure 14.2 are discussed in this chapter.
The global variables used by the multicast routing code are shown in Figure 14.3.
Table 14.3. Global variables introduced in this chapter.
Variable | Datatype | Description |
|---|---|---|
|
| one-behind cache for multicast routing |
|
| multicast group for one-behind cache |
|
| mask for multicast group for one-behind cache |
|
| multicast routing statistics |
|
| hash table of pointers to multicast routes |
|
| number of enabled multicast interfaces |
|
| array of virtual multicast interfaces |
All the statistics collected by the multicast routing code are found in the mrtstat structure described by Figure 14.4. Figure 14.5 shows some sample output of these statistics, from the netstat -gs command.
Table 14.4. Statistics collected in this chapter.
| Description | Used by SNMP |
|---|---|---|
| #multicast route lookups | |
| #multicast route cache misses | |
| #group address lookups | |
| #group address cache misses | |
| #multicast route lookup failures | |
| #packets with malformed tunnel options | |
| #packets with no room for tunnel options |
Table 14.5. Sample IP multicast routing statistics.
|
|
|---|---|
multicast routing:
329569328 multicast route lookups
9377023 multicast route cache misses
242754062 group address lookups
159317788 group address cache misses
65648 datagrams with no route for origin
0 datagrams with malformed tunnel options
0 datagrams with no room for tunnel options | mrts_mrt_lookups mrts_mrt_misses mrts_grp_lookups mrts_grp_misses mrts_no_route mrts_bad_tunnel mrts_cant_tunnel |
These statistics are from a system with two physical interfaces and one tunnel interface. These statistics show that the multicast route is found in the cache 98% of the time. The group address cache is less effective with only a 34% hit rate. The route cache is described with Figure 14.34 and the group address cache with Figure 14.21.
There is no standard SNMP MIB for multicast routing, but [McCloghrie and Farinacci 1994a] and [McCloghrie and Farinacci 1994b] describe some experimental MIBs for multicast routers.
In Section 12.15 we described how an interface is selected for an outgoing multicast datagram. We saw that ip_output is passed an explicit interface in the ip_moptions structure, or ip_output looks up the destination group in the routing tables and uses the interface returned in the route entry.
If, after selecting an outgoing interface, ip_output loops back the datagram, it is queued for input processing on the interface selected for output and is considered for forwarding when it is processed by ipintr. Figure 14.6 illustrates this process.
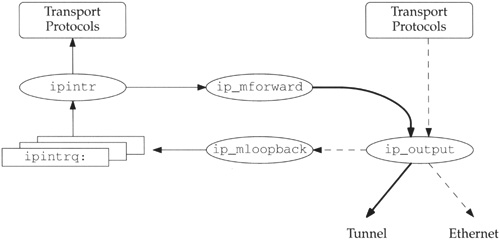
In Figure 14.6 the dashed arrows represent the original outgoing datagram, which in this example is multicast on a local Ethernet. The copy created by ip_mloopback is represented by the thin arrows; this copy is passed to the transport protocols for input. The third copy is created when ip_mforward decides to forward the datagram through another interface on the system. The thickest arrows in Figure 14.6 represents the third copy, which in this example is sent on a multicast tunnel.
If the datagram is not looped back, ip_output passes it directly to ip_mforward, where it is duplicated and also processed as if it were received on the interface that ip_output selected. This process is shown in Figure 14.7.

Whenever ip_mforward calls ip_output to send a multicast datagram, it sets the IP_FORWARDING flag so that ip_output does not pass the datagram back to ip_mforward, which would create an infinite loop.
ip_mloopback was described with Figure 12.42. ip_mforward is described in Section 14.8.
Multicast routing is enabled and managed by a user-level process: the mrouted daemon, mrouted implements the router portion of the IGMP protocol and communicates with other multicast routers to implement multicast routing between networks. The routing algorithms are implemented in mrouted, but the multicast routing tables are maintained in the kernel, which forwards the datagrams.
In this text we describe only the kernel data structures and functions that support mrouted w e do not describe mrouted itself. We describe the Truncated Reverse Path Broadcast (TRPB) algorithm [Deering and Cheriton 1990], used to select routes for multicast datagrams, and the Distance Vector Multicast Routing Protocol (DVMRP), used to convey information between multicast routers, in enough detail to make sense of the kernel multicast code.
RFC 1075 [Waitzman, Partridge, and Deering 1988] describes an old version of DVMRP. mrouted implements a newer version of DVMRP, which is not yet documented in an RFC. The best documentation for the current algorithm and protocol is the source code release for mrouted. Appendix B describes where the source code can be obtained.
The mrouted daemon communicates with the kernel by setting options on an IGMP socket (Chapter 32). The options are summarized in Figure 14.8.
Table 14.8. Multicast routing socket options.
|
| Function | Description |
|---|---|---|---|
|
|
| |
|
|
| |
|
|
| add virtual interface |
|
|
| delete virtual interface |
|
|
| add multicast group entry for an interface |
|
|
| delete multicast group entry for an interface |
|
|
| add multicast route |
|
|
| delete multicast route |
The socket options shown in Figure 14.8 are passed to rip_ctloutput (Section 32.8) by the setsockopt system call. Figure 14.9 shows the portion of rip_ctloutput that handles the DVMRP_xxx options.
Table 14.9. rip_ctloutput function: DVMRP_xxx socket options.
---------------------------------------------------------------------- raw_ip.c 173 case DVMRP_INIT: 174 case DVMRP_DONE: 175 case DVMRP_ADD_VIF: 176 case DVMRP_DEL_VIF: 177 case DVMRP_ADD_LGRP: 178 case DVMRP_DEL_LGRP: 179 case DVMRP_ADD_MRT: 180 case DVMRP_DEL_MRT: 181 if (op == PRCO_SETOPT) { 182 error = ip_mrouter_cmd(optname, so, *m); 183 if (*m) 184 (void) m_free(*m); 185 } else 186 error = EINVAL; 187 return (error); ---------------------------------------------------------------------- raw_ip.c |
173-187
When setsockopt is called, op equals PRCO_SETOPT and all the options are passed to the ip_mrouter_cmd function. For the getsockopt system call, op equals PRCO_GETOPT and EINVAL is returned for all the options.
Figure 14.10 shows the ip_mrouter_cmd function.
Table 14.10. ip_mrouter_cmd function.
---------------------------------------------------------------------- ip_mroute.c 84 int 85 ip_mrouter_cmd(cmd, so, m) 86 int cmd; 87 struct socket *so; 88 struct mbuf *m; 89 { 90 int error = 0; 91 if (cmd != DVMRP_INIT && so != ip_mrouter) 92 error = EACCES; 93 else 94 switch (cmd) { 95 case DVMRP_INIT: 96 error = ip_mrouter_init(so); 97 break; 98 case DVMRP_DONE: 99 error = ip_mrouter_done(); 100 break; 101 case DVMRP_ADD_VIF: 102 if (m == NULL || m->m_len < sizeof(struct vifctl)) 103 error = EINVAL; 104 else 105 error = add_vif(mtod(m, struct vifctl *)); 106 break; 107 case DVMRP_DEL_VIF: 108 if (m == NULL || m->m_len < sizeof(short)) 109 error = EINVAL; 110 else 111 error = del_vif(mtod(m, vifi_t *)); 112 break; 113 case DVMRP_ADD_LGRP: 114 if (m == NULL || m->m_len < sizeof(struct lgrplctl)) 115 error = EINVAL; 116 else 117 error = add_lgrp(mtod(m, struct lgrplctl *)); 118 break; 119 case DVMRP_DEL_LGRP: 120 if (m == NULL || m->m_len < sizeof(struct lgrplctl)) 121 error = EINVAL; 122 else 123 error = del_lgrp(mtod(m, struct lgrplctl *)); 124 break; 125 case DVMRP_ADD_MRT: 126 if (m == NULL || m->m_len < sizeof(struct mrtctl)) 127 error = EINVAL; 128 else 129 error = add_mrt(mtod(m, struct mrtctl *)); 130 break; 131 case DVMRP_DEL_MRT: 132 if (m == NULL || m->m_len < sizeof(struct in_addr)) 133 error = EINVAL; 134 else 135 error = del_mrt(mtod(m, struct in_addr *)); 136 break; 137 default: 138 error = EOPNOTSUPP; 139 break; 140 } 141 return (error); 142 } ---------------------------------------------------------------------- ip_mroute.c |
These “options” are more like commands, since they cause the kernel to update various data structures. We use the term command throughout the rest of this chapter to emphasize this fact.
84-92
The first command issued by mrouted must be DVMRP_INIT. Subsequent commands must come from the same socket as the DVMRP_INIT command. EACCES is returned when other commands are issued on a different socket.
94-142
Each case in the switch checks to see if the right amount of data was included with the command and then calls the matching function. If the command is not recognized, EOPNOTSUPP is returned. Any error returned from the matching function is posted in error and returned at the end of the function.
Figure 14.11 shows ip_mrouter_init, which is called when mrouted issues the DVMRP_INIT command during initialization.
Table 14.11. ip_mrouter_init function: DVMRP_INIT command.
---------------------------------------------------------------------- ip_mroute.c 146 static int 147 ip_mrouter_init(so) 148 struct socket *so; 149 { 150 if (so->so_type != SOCK_RAW || 151 so->so_proto->pr_protocol != IPPROTO_IGMP) 152 return (EOPNOTSUPP); 153 if (ip_mrouter != NULL) 154 return (EADDRINUSE); 155 ip_mrouter = so; 156 return (0); 157 } ---------------------------------------------------------------------- ip_mroute.c |
146-157
If the command is issued on something other than a raw IGMP socket, or if DVMRP_INIT has already been set, EOPNOTSUPP or EADDRINUSE are returned respectively. A pointer to the socket on which the initialization command is issued is saved in the global ip_mrouter. Subsequent commands must be issued on this socket. This prevents the concurrent operation of more than one instance of mrouted.
The remainder of the DVMRP_xxx commands are described in the following sections.
When operating as a multicast router, Net/3 accepts incoming multicast datagrams, duplicates them and forwards the copies through one or more interfaces. In this way, the datagram is forwarded to other multicast routers on the internet.
An outgoing interface can be a physical interface or it can be a multicast tunnel. Each end of the multicast tunnel is associated with a physical interface on a multicast router. Multicast tunnels allow two multicast routers to exchange multicast datagrams even when they are separated by routers that cannot forward multicast datagrams. Figure 14.12 shows two multicast routers connected by a multicast tunnel.

In Figure 14.12, the source host HS on network A is multicasting a datagram to group G. The only member of group G is on network B, which is connected to network A by a multicast tunnel. Router A receives the multicast (because multicast routers receive all multicasts), consults its multicast routing tables, and forwards the datagram through the multicast tunnel.
The tunnel starts on the physical interface on router A identified by the IP unicast address Ts. The tunnel ends on the physical interface on router B identified by the IP unicast address, Te. The tunnel itself is an arbitrarily complex collection of networks connected by IP unicast routers that implement the LSRR option. Figure 14.13 shows how an IP LSRR option implements the multicast tunnel.
The first line of Figure 14.13 shows the datagram sent by HS as a multicast on network A. Router A receives the datagram because multicast routers receive all multicasts on their locally attached networks.
To send the datagram through the tunnel, router A inserts an LSRR option in the IP header. The second line shows the datagram as it leaves A on the tunnel. The first address in the LSRR option is the source address of the tunnel and the second address is the destination group. The destination of the datagram is Te the other end of the tunnel. The LSRR offset points to the destination group.
The tunneled datagram is forwarded through the internet until it reaches the other end of the tunnel on router B.
The third line of the figure shows the datagram after it is processed by ip_dooptions on router B. Recall from Chapter 9 that ip_dooptions processes the LSRR option before the destination address of the datagram is examined by ipintr. Since the destination address of the datagram (Te) matches one of the interfaces on router B, ip_dooptions copies the address identified by the option offset (G in this example) into the destination field of the IP header. In the option, G is replaced with the address returned by ip_rtaddr, which normally selects the outgoing interface for the datagram based on the IP destination address (G in this case). This address is irrelevant, since ip_mforward discards the entire option. Finally, ip_dooptions advances the option offset.
The fourth line in Figure 14.13 shows the datagram after ipintr calls ip_mforward, where the LSRR option is recognized and removed from the datagram header. The resulting datagram looks like the original multicast datagram and is processed by ip_mforward, which in our example forwards it onto network B as a multicast datagram where it is received by HG.
Multicast tunnels constructed with LSRR options are obsolete. Since the March 1993 release of mrouted, tunnels have been constructed by prepending another IP header to the IP multicast datagram. The protocol in the new IP header is set to 4 to indicate that the contents of the packet is another IP packet. This value is documented in RFC 1700 as the “IP in IP” protocol. LSRR tunnels are supported in newer versions of mrouted for backward compatibility.
For both physical interfaces and tunnel interfaces, the kernel maintains an entry in a virtual interface table, which contains information that is used only for multicasting. Each virtual interface is described by a vif structure (Figure 14.14). The global variable viftable is an array of these structures. An index to the table is stored in a vifi_t variable, which is an unsigned short integer.
Table 14.14. vif structure.
---------------------------------------------------------------------- ip_mroute.h 105 struct vif { 106 u_char v_flags; /* VIFF_ flags */ 107 u_char v_threshold; /* min ttl required to forward on vif */ 108 struct in_addr v_lcl_addr; /* local interface address */ 109 struct in_addr v_rmt_addr; /* remote address (tunnels only) */ 110 struct ifnet *v_ifp; /* pointer to interface */ 111 struct in_addr *v_lcl_grps; /* list of local grps (phyints only) */ 112 int v_lcl_grps_max; /* malloc'ed number of v_lcl_grps */ 113 int v_lcl_grps_n; /* used number of v_lcl_grps */ 114 u_long v_cached_group; /* last grp looked-up (phyints only) */ 115 int v_cached_result; /* last look-up result (phyints only) */ 116 }; ---------------------------------------------------------------------- ip_mroute.h |
105-110
The only flag defined for v_flags is VIFF_TUNNEL. When set, the interface is a tunnel to a remote multicast router. When not set, the interface is a physical interface on the local system. v_threshold is the multicast threshold, which we described in Section 12.9. v_lcl_addr is the unicast IP address of the local interface associated with this virtual interface. v_rmt_addr is the unicast IP address of the remote end of an IP multicast tunnel. Either v_lcl_addr or v_rmt_addr is nonzero, but never both. For physical interfaces, v_ifp is nonnull and points to the ifnet structure of the local interface. For tunnels, v_ifp is null.
111-116
The list of groups with members on the attached interface is kept as an array of IP multicast group addresses pointed to by v_lcl_grps, which is always null for tunnels. The size of the array is in v_lcl_grps_max, and the number of entries that are used is in v_lcl_grps_n. The array grows as needed to accommodate the group membership list. v_cached_group and v_cached_result implement a one-entry cache, which contain the group and result of the previous lookup.
Figure 14.15 illustrates the viftable, which has 32 (MAXVIFS) entries. viftable[2] is the last entry in use, so numvifs is 3. The size of the table is fixed when the kernel is compiled. Several members of the vif structure in the first entry of the table are shown. v_ifp points to an ifnet structure, v_lcl_grps points to an array of in_addr structures. The array has 32 (v_lcl_grps_max) entries, of which only 4 (v_lcl_grps_n) are in use.

mrouted maintains viftable through the DVMRP_ADD_VIF and DVMRP_DEL_VIF commands. Normally all multicast-capable interfaces on the local system are added to the table when mrouted begins. Multicast tunnels are added when mrouted reads its configuration file, usually /etc/mrouted.conf. Commands in this file can also delete physical interfaces from the virtual interface table or change the multicast information associated with the interfaces.
A vifctl structure (Figure 14.16) is passed by mrouted to the kernel with the DVMRP_ADD_VIF command. It instructs the kernel to add an interface to the table of virtual interfaces.
Table 14.16. vifctl structure.
---------------------------------------------------------------------- ip_mroute.h 76 struct vifctl { 77 vifi_t vifc_vifi; /* the index of the vif to be added */ 78 u_char vifc_flags; /* VIFF_ flags (Figure 14.14) */ 79 u_char vifc_threshold; /* min ttl required to forward on vif */ 80 struct in_addr vifc_lcl_addr; /* local interface address */ 81 struct in_addr vifc_rmt_addr; /* remote address (tunnels only) */ 82 }; ---------------------------------------------------------------------- ip_mroute.h |
76-82
vifc_vifi identifies the index of the virtual interface within viftable. The remaining four members, vifc_flags, vifc_threshold, vifc_lcl_addr, and vifc_rmt_addr, are copied into the vif structure by the add_vif function.
Figure 14.17 shows the add_vif function.
Table 14.17. add_vif function: DVMRP_ADD_VIF command.
---------------------------------------------------------------------- ip_mroute.c 202 static int 203 add_vif(vifcp) 204 struct vifctl *vifcp; 205 { 206 struct vif *vifp = viftable + vifcp->vifc_vifi; 207 struct ifaddr *ifa; 208 struct ifnet *ifp; 209 struct ifreq ifr; 210 int error, s; 211 static struct sockaddr_in sin = 212 {sizeof(sin), AF_INET}; 213 if (vifcp->vifc_vifi >= MAXVIFS) 214 return (EINVAL); 215 if (vifp->v_lcl_addr.s_addr != 0) 216 return (EADDRINUSE); 217 /* Find the interface with an address in AF_INET family */ 218 sin.sin_addr = vifcp->vifc_lcl_addr; 219 ifa = ifa_ifwithaddr((struct sockaddr *) &sin); 220 if (ifa == 0) 221 return (EADDRNOTAVAIL); 222 s = splnet(); 223 if (vifcp->vifc_flags & VIFF_TUNNEL) 224 vifp->v_rmt_addr = vifcp->vifc_rmt_addr; 225 else { 226 /* Make sure the interface supports multicast */ 227 ifp = ifa->ifa_ifp; 228 if ((ifp->if_flags & IFF_MULTICAST) == 0) { 229 splx(s); 230 return (EOPNOTSUPP); 231 } 232 /* 233 * Enable promiscuous reception of all IP multicasts 234 * from the interface. 235 */ 236 satosin(&ifr.ifr_addr)->sin_family = AF_INET; 237 satosin(&ifr.ifr_addr)->sin_addr.s_addr = INADDR_ANY; 238 error = (*ifp->if_ioctl) (ifp, SIOCADDMULTI, (caddr_t) & ifr); 239 if (error) { 240 splx(s); 241 return (error); 242 } 243 } 244 vifp->v_flags = vifcp->vifc_flags; 245 vifp->v_threshold = vifcp->vifc_threshold; 246 vifp->v_lcl_addr = vifcp->vifc_lcl_addr; 247 vifp->v_ifp = ifa->ifa_ifp; 248 /* Adjust numvifs up if the vifi is higher than numvifs */ 249 if (numvifs <= vifcp->vifc_vifi) 250 numvifs = vifcp->vifc_vifi + 1; 251 splx(s); 252 return (0); 253 } ---------------------------------------------------------------------- ip_mroute.c |
202-216
If the table index specified by mrouted in vifc_vifi is too large, or the table entry is already in use, EINVAL or EADDRINUSE is returned respectively.
217-221
ifa_ifwithaddr takes the unicast IP address in vifc_lcl_addr and returns a pointer to the associated ifnet structure. This identifies the physical interface to be used for this virtual interface. If there is no matching interface, EADDRNOTAVAIL is returned.
222-224
For a tunnel, the remote end of the tunnel is copied from the vifctl structure to the vif structure in the interface table.
225-243
For a physical interface, the link-level driver must support multicasting. The SIOCADDMULTI command used with INADDR_ANY configures the interface to begin receiving all IP multicast datagrams (Figure 12.32) because it is a multicast router. Incoming datagrams are forwarded when ipintr passes them to ip_mforward.
244-253
The remaining interface information is copied from the vifctl structure to the vif structure. If necessary, numvifs is updated to record the number of virtual interfaces in use.
The function del_vif, shown in Figure 14.18, deletes entries from the virtual interface table. It is called when mrouted sets the DVMRP_DEL_VIF command.
Table 14.18. del_vif function: DVMRP_DEL_VIF command.
---------------------------------------------------------------------- ip_mroute.c 257 static int 258 del_vif(vifip) 259 vifi_t *vifip; 260 { 261 struct vif *vifp = viftable + *vifip; 262 struct ifnet *ifp; 263 int i, s; 264 struct ifreq ifr; 265 if (*vifip >= numvifs) 266 return (EINVAL); 267 if (vifp->v_lcl_addr.s_addr == 0) 268 return (EADDRNOTAVAIL); 269 s = splnet(); 270 if (!(vifp->v_flags & VIFF_TUNNEL)) { 271 if (vifp->v_lcl_grps) 272 free(vifp->v_lcl_grps, M_MRTABLE); 273 satosin(&ifr.ifr_addr)->sin_family = AF_INET; 274 satosin(&ifr.ifr_addr)->sin_addr.s_addr = INADDR_ANY; 275 ifp = vifp->v_ifp; 276 (*ifp->if_ioctl) (ifp, SIOCDELMULTI, (caddr_t) & ifr); 277 } 278 bzero((caddr_t) vifp, sizeof(*vifp)); 279 /* Adjust numvifs down */ 280 for (i = numvifs - 1; i >= 0; i--) 281 if (viftable[i].v_lcl_addr.s_addr != 0) 282 break; 283 numvifs = i + 1; 284 splx(s); 285 return (0); 286 } ---------------------------------------------------------------------- ip_mroute.c |
257-268
If the index passed to del_vif is greater than the largest index in use or it references an entry that is not in use, EINVAL or EADDRNOTAVAIL is returned respectively.
269-278
For a physical interface, the local group table is released, and the reception of all multicast datagrams is disabled by SIOCDELMULTI. The entry in viftable is cleared by bzero.
279-286
The for loop searches for the first active entry in the table starting at the largest previously active entry and working back toward the first entry. For unused entries, the s_addr member of v_lcl_addr (an in_addr structure) is 0. numvifs is updated accordingly and the function returns.
Chapter 13 focused on the host part of the IGMP protocol. mrouted implements the router portion of this protocol. For every physical interface, mrouted must keep track of which multicast groups have members on the attached network. mrouted multicasts an IGMP_HOST_MEMBERSHIP_QUERY datagram every 120 seconds and compiles the resulting IGMP_HOST_MEMBERSHIP_REPORT datagrams into a membership array associated with each network. This array is not the same as the membership list we described in Chapter 13.
From the information collected, mrouted constructs the multicast routing tables. The list of groups is also used to suppress multicasts to areas of the multicast internet that do not have members of the destination group.
The membership array is maintained only for physical interfaces. Tunnels are point-to-point interfaces to another multicast router, so no group membership information is needed.
We saw in Figure 14.14 that v_lcl_grps points to an array of IP multicast groups. mrouted maintains this list with the DVMRP_ADD_LGRP and DVMRP_DEL_LGRP commands. An Igrplctl (Figure 14.19) structure is passed with both commands.
87-90
The {interface, group} pair is identified by lgc_vifi and lgc_gaddr. The interface index (lgc_vifi, an unsigned short) identifies a virtual interface, not a physical interface.
When an IGMP_HOST_MEMBERSHIP_REPORT datagram is received, the functions shown in Figure 14.20 are called.
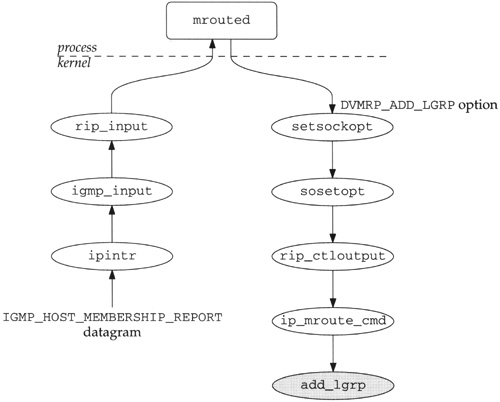
mrouted examines the source address of an incoming IGMP report to determine which subnet and therefore which interface the report arrived on. Based on this information, mrouted sets the DVMRP_ADD_LGRP command for the interface to update the membership table in the kernel. This information is also fed into the multicast routing algorithm to update the routing tables. Figure 14.21 shows the add_lgrp function.
Table 14.21. add_lgrp function: process DVMRP_ADD_LGRP command.
---------------------------------------------------------------------- ip_mroute.c 291 static int 292 add_lgrp(gcp) 293 struct lgrplctl *gcp; 294 { 295 struct vif *vifp; 296 int s; 297 if (gcp->lgc_vifi >= numvifs) 298 return (EINVAL); 299 vifp = viftable + gcp->lgc_vifi; 300 if (vifp->v_lcl_addr.s_addr == 0 || (vifp->v_flags & VIFF_TUNNEL)) 301 return (EADDRNOTAVAIL); 302 /* If not enough space in existing list, allocate a larger one */ 303 s = splnet(); 304 if (vifp->v_lcl_grps_n + 1 >= vifp->v_lcl_grps_max) { 305 int num; 306 struct in_addr *ip; 307 num = vifp->v_lcl_grps_max; 308 if (num <= 0) 309 num = 32; /* initial number */ 310 else 311 num += num; /* double last number */ 312 ip = (struct in_addr *) malloc(num * sizeof(*ip), 313 M_MRTABLE, M_NOWAIT); 314 if (ip == NULL) { 315 splx(s); 316 return (ENOBUFS); 317 } 318 bzero((caddr_t) ip, num * sizeof(*ip)); /* XXX paranoid */ 319 bcopy((caddr_t) vifp->v_lcl_grps, (caddr_t) ip, 320 vifp->v_lcl_grps_n * sizeof(*ip)); 321 vifp->v_lcl_grps_max = num; 322 if (vifp->v_lcl_grps) 323 free(vifp->v_lcl_grps, M_MRTABLE); 324 vifp->v_lcl_grps = ip; 325 splx(s); 326 } 327 vifp->v_lcl_grps[vifp->v_lcl_grps_n++] = gcp->lgc_gaddr; 328 if (gcp->lgc_gaddr.s_addr == vifp->v_cached_group) 329 vifp->v_cached_result = 1; 330 splx(s); 331 return (0); 332 } ---------------------------------------------------------------------- ip_mroute.c |
291-301
If the request identifies an invalid interface, EINVAL is returned. If the interface is not in use or is a tunnel, EADDRNOTAVAIL is returned.
302-326
If the new group won’t fit in the current group array, a new array is allocated. The first time add_lgrp is called for an interface, an array is allocated to hold 32 groups.
Each time the array fills, add_lgrp allocates a new array of twice the previous size. The new array is allocated by malloc, cleared by bzero, and filled by copying the old array into the new one with bcopy. The maximum number of entries, v_lcl_grps_max, is updated, the old array (if any) is released, and the new array is attached to the vif entry with v_lcl_grps.
The “paranoid” comment points out there is no guarantee that the memory allocated by malloc contains all 0s.
327-332
The new group is copied into the next available entry and if the cache already contains the new group, the cache is marked as valid.
The lookup cache contains an address, v_cached_group, and a cached lookup result, v_cached_result. The grplst_member function always consults the cache before searching the membership array. If the given group matches v_cached_group, the cached result is returned; otherwise the membership array is searched.
Group information is expired for each interface when no membership report has been received for the group within 270 seconds. mrouted maintains the appropriate timers and issues the DVMRP_DEL_LGRP command when the information expires. Figure 14.22 shows del_lgrp.
Table 14.22. del_lgrp function: process DVMRP_DEL_LGRP command.
---------------------------------------------------------------------- ip_mroute.c 337 static int 338 del_lgrp(gcp) 339 struct lgrplctl *gcp; 340 { 341 struct vif *vifp; 342 int i, error, s; 343 if (gcp->lgc_vifi >= numvifs) 344 return (EINVAL); 345 vifp = viftable + gcp->lgc_vifi; 346 if (vifp->v_lcl_addr.s_addr == 0 || (vifp->v_flags & VIFF_TUNNEL)) 347 return (EADDRNOTAVAIL); 348 s = splnet(); 349 if (gcp->lgc_gaddr.s_addr == vifp->v_cached_group) 350 vifp->v_cached_result = 0; 351 error = EADDRNOTAVAIL; 352 for (i = 0; i < vifp->v_lcl_grps_n; ++i) 353 if (same(&gcp->lgc_gaddr, &vifp->v_lcl_grps[i])) { 354 error = 0; 355 vifp->v_lcl_grps_n--; 356 bcopy((caddr_t) & vifp->v_lcl_grps[i + 1], 357 (caddr_t) & vifp->v_lcl_grps[i], 358 (vifp->v_lcl_grps_n - i) * sizeof(struct in_addr)); 359 error = 0; 360 break; 361 } 362 splx(s); 363 return (error); 364 } ---------------------------------------------------------------------- ip_mroute.c |
337-347
If the request identifies an invalid interface, EINVAL is returned. If the interface is not in use or is a tunnel, EADDRNOTAVAIL is returned.
348-350
If the group to be deleted is in the cache, the lookup result is set to 0 (false).
351-364
EADDRNOTAVAIL is posted in error in case the group is not found in the membership list. The for loop searches the membership array associated with the interface. If same (a macro that uses bcmp to compare the two addresses) is true, error is cleared and the group count is decremented. bcopy shifts the subsequent array entries down to delete the group and del_lgrp breaks out of the loop.
If the loop completes without finding a match, EADDRNOTAVAIL is returned; otherwise 0 is returned.
During multicast forwarding, the membership array is consulted to avoid sending datagrams on a network when no member of the destination group is present. grplst_member, shown in Figure 14.23, searches the list looking for the given group address.
Table 14.23. grplst_member function.
---------------------------------------------------------------------- ip_mroute.c 368 static int 369 grplst_member(vifp, gaddr) 370 struct vif *vifp; 371 struct in_addr gaddr; 372 { 373 int i, s; 374 u_long addr; 375 mrtstat.mrts_grp_lookups++; 376 addr = gaddr.s_addr; 377 if (addr == vifp->v_cached_group) 378 return (vifp->v_cached_result); 379 mrtstat.mrts_grp_misses++; 380 for (i = 0; i < vifp->v_lcl_grps_n; ++i) 381 if (addr == vifp->v_lcl_grps[i].s_addr) { 382 s = splnet(); 383 vifp->v_cached_group = addr; 384 vifp->v_cached_result = 1; 385 splx(s); 386 return (1); 387 } 388 s = splnet(); 389 vifp->v_cached_group = addr; 390 vifp->v_cached_result = 0; 391 splx(s); 392 return (0); 393 } ---------------------------------------------------------------------- ip_mroute.c |
368-379
If the requested group is located in the cache, the cached result is returned and the membership array is not searched.
As we mentioned at the start of this chapter, we will not be presenting the TRPB algorithm implemented by mrouted, but we do need to provide a general overview of the mechanism to describe the multicast routing table and the multicast routing functions in the kernel. Figure 14.24 shows the sample multicast network that we use to illustrate the algorithms.
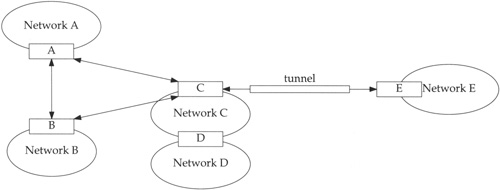
In Figure 14.24, routers are shown as boxes and the ellipses are the multicast networks attached to the routers. For example, router D can multicast on network D and C. Router C can multicast to network C, to routers A and B through point-to-point interfaces, and to E through a multicast tunnel.
The simplest approach to multicast routing is to select a subset of the internet topology that forms a spanning tree. If each router forwards multicasts along the spanning tree, every router eventually receives the datagram. Figure 14.25 shows one spanning tree for our sample network, where host S on network A represents the source of a multicast datagram.

For a discussion of spanning trees, see [Tanenbaum 1989] or [Perlman 1992].
We constructed the tree based on the shortest reverse path from every network back to the source in network A. In Figure 14.25, the link between routers B and C is omitted to form the spanning tree. The arrows between the source and router A, and between router C and D, emphasize that the multicast network is part of the spanning tree.
If the same spanning tree were used to forward a datagram from network C, the datagram would be forwarded along a longer path than needed to get to a recipient on network B. The algorithm described in RFC 1075 computes a separate spanning tree for each potential source network to avoid this problem. The routing tables contain a network number and subnet mask for each route, so that a single route applies to any host within the source subnet.
Because each spanning tree is constructed to provide the shortest reverse path to the source of the datagram, and every network receives every multicast datagram, this process is called reverse path broadcasting or RPB.
The RPB protocol has no knowledge of multicast group membership, so many datagrams are unnecessarily forwarded to networks that have no members in the destination group. If, in addition to computing the spanning trees, the routing algorithm records which networks are leaves and is aware of the group membership on each network, then routers attached to leaf networks can avoid forwarding datagrams onto the network when there is no member of the destination group present. This is called truncated reverse path broadcasting (TRPB), and is implemented by version 2.0 of mrouted with the help of IGMP to keep track of membership in the leaf networks.
Figure 14.26 shows TRPB applied to a multicast sent from a source on network C and with a member of the destination group on network B.

We’ll use Figure 14.26 to illustrate the terms used in the Net/3 multicast routing table. In this example, the shaded networks and routers receive a copy of the multicast datagram sent from the source on network C. The link between A and B is not part of the spanning tree and C does not have a link to D, since the multicast sent by the source is received directly by C and D.
In this figure, networks A, B, D, and E are leaf networks. Router C receives the multicast and forwards it through the interfaces attached to routers A, B, and E even though sending it to A and E is wasted effort. This is a major weakness of the TRPB algorithm.
The interface associated with network C on router C is called the parent because it is the interface on which router C expects to receive multicasts originating from network C. The interfaces from router C to routers A, B, and E, are child interfaces. For router A, the point-to-point interface is the parent for the source packets from C and the interface for network A is a child. Interfaces are identified as a parent or as a child relative to the source of the datagram. Multicast datagrams are forwarded only to the associated child interfaces, and never to the parent interface.
Continuing with the example, networks A, D, and E are not shaded because they are leaf networks without members of the destination group, so the spanning tree is truncated at the routers and the datagram is not forwarded onto these networks. Router B forwards the datagram onto network B, since there is a member of the destination group on the network. To implement the truncation algorithm, each multicast router that receives the datagram consults the group table associated with every virtual interface in the router’s viftable.
The final refinement to the multicast routing algorithm is called reverse path multicasting (RPM). The goal of RPM is to prune each spanning tree and avoid sending datagrams along branches of the tree that do not contain a member of the destination group. In Figure 14.26, RPM would prevent router C from sending a datagram to A and E, since there is no member of the destination group in those branches of the tree. Version 3.3 of mrouted implements RPM.
Figure 14.27 shows our example network, but this time only the routers and networks reached when the datagram is routed by RPM are shaded.
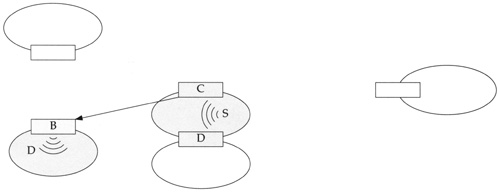
To compute the routing tables corresponding to the spanning trees we described, the multicast routers communicate with adjacent multicast routers to discover the multicast internet topology and the location of multicast group members. In Net/3, DVMRP is used for this communication. DVMRP messages are transmitted as IGMP datagrams and are sent to the multicast group 224.0.0.4, which is reserved for DVMRP communication (Figure 12.1).
In Figure 12.39, we saw that incoming IGMP packets are always accepted by a multicast router. They are passed to igmp_input, to rip_input, and then read by mrouted on a raw IGMP socket. mrouted sends DVMRP messages to other multicast routers on the same raw IGMP socket.
For more information about RPB, TRPB, RPM, and the DVMRP messages that are needed to implement these algorithms, see [Deering and Cheriton 1990] and the source code release of mrouted.
There are other multicast routing protocols in use on the Internet. Proteon routers implement the MOSPF protocol described in RFC 1584 [Moy 1994]. PIM (Protocol Independent Multicasting) is implemented by Cisco routers, starting with Release 10.2 of their operating software. PIM is described in [Deering et al. 1994].
We can now describe the implementation of the multicast routing tables in Net/3. The kernel’s multicast routing table is maintained as a hash table with 64 entries (MRTHASHSIZ). The table is kept in the global array mrttable, and each entry points to a linked list of mrt structures, shown in Figure 14.28.
Table 14.28. mrt structure.
---------------------------------------------------------------------- ip_mroute.h 120 struct mrt { 121 struct in_addr mrt_origin; /* subnet origin of multicasts */ 122 struct in_addr mrt_originmask; /* subnet mask for origin */ 123 vifi_t mrt_parent; /* incoming vif */ 124 vifbitmap_t mrt_children; /* outgoing children vifs */ 125 vifbitmap_t mrt_leaves; /* subset of outgoing children vifs */ 126 struct mrt *mrt_next; /* forward link */ 127 }; ---------------------------------------------------------------------- ip_mroute.h |
120-127
mrtc_origin and mrtc_originmask identify an entry in the table. mrtc_parent is the index of the virtual interface on which all multicast datagrams from the origin are expected. The outgoing interfaces are identified within mrtc_children, which is a bitmap. Outgoing interfaces that are also leaves in the multicast routing tree are identified in mrtc_leaves, which is also a bitmap. The last member, mrt_next, implements a linked list in case multiple routes hash to the same array entry.
Figure 14.29 shows the organization of the multicast routing table. Each mrt structure is placed in the hash chain that corresponds to return value from the nethash function shown in Figure 14.31.

The multicast routing table maintained by the kernel is a subset of the routing table maintained within mrouted and contains enough information to support multicast forwarding within the kernel. Updates to the kernel table are sent with the DVMRP_ADD_MRT command, which includes the mrtctl structure shown in Figure 14.30.
Table 14.30. mrtctl structure.
---------------------------------------------------------------------- ip_mroute.h 95 struct mrtctl { 96 struct in_addr mrtc_origin; /* subnet origin of multicasts */ 97 struct in_addr mrtc_originmask; /* subnet mask for origin */ 98 vifi_t mrtc_parent; /* incoming vif */ 99 vifbitmap_t mrtc_children; /* outgoing children vifs */ 100 vifbitmap_t mrtc_leaves; /* subset of outgoing children vifs */ 101 }; ---------------------------------------------------------------------- ip_mroute.h |
95-101
The five members of the mrtctl structure carry the information we have already described (Figure 14.28) between mrouted and the kernel.
The multicast routing table is keyed by the source IP address of the multicast datagram. nethash (Figure 14.31) implements the hashing algorithm used for the table. It accepts the source IP address and returns a value between 0 and 63 (MRTHASHSIZ—1).
Table 14.31. nethash function.
---------------------------------------------------------------------- ip_mroute.c 398 static u_long 399 nethash(in) 400 struct in_addr in; 401 { 402 u_long n; 403 n = in_netof(in); 404 while ((n & 0xff) == 0) 405 n >>= 8; 406 return (MRTHASHMOD(n)); 407 } ---------------------------------------------------------------------- ip_mroute.c |
398-407
in_netof returns in with the host portion set to all 0s leaving only the class A, B, or C network of the sending host in n. The result is shifted to the right until the low-order 8 bits are nonzero. MRTHASHMOD is
#define MRTHASHMOD(h) ((h) & (MRTHASHSIZ - 1))
The low-order 8 bits are logically ANDed with 63, leaving only the low-order 6 bits, which is an integer in the range 0 to 63.
Doing two function calls (
nethashandin_netof) to calculate a hash value is an expensive algorithm to compute a hash for a 32-bit address.
The mrouted daemon adds and deletes entries in the kernel’s multicast routing table through the DVMRP_ADD_MRT and DVMRP_DEL_MRT commands. Figure 14.32 shows the del_mrt function.
Table 14.32. del_mrt function: process DVMRP_DEL_MRT command.
---------------------------------------------------------------------- ip_mroute.c 451 static int 452 del_mrt(origin) 453 struct in_addr *origin; 454 { 455 struct mrt *rt, *prev_rt; 456 u_long hash = nethash(*origin); 457 int s; 458 for (prev_rt = rt = mrttable[hash]; rt; prev_rt = rt, rt = rt->mrt_next) 459 if (origin->s_addr == rt->mrt_origin.s_addr) 460 break; 461 if (!rt) 462 return (ESRCH); 463 s = splnet(); 464 if (rt == cached_mrt) 465 cached_mrt = NULL; 466 if (prev_rt == rt) 467 mrttable[hash] = rt->mrt_next; 468 else 469 prev_rt->mrt_next = rt->mrt_next; 470 free(rt, M_MRTABLE); 471 splx(s); 472 return (0); 473 } ---------------------------------------------------------------------- ip_mroute.c |
451-462
The for loop starts at the entry identified by hash (initialized in its declaration from nethash). If the entry is not located, ESRCH is returned.
463-473
If the entry was stored in the cache, the cache is invalidated. The entry is unlinked from the hash chain and released. The if statement is needed to handle the special case when the matched entry is at the front of the list.
The add_mrt function is shown in Figure 14.33.
Table 14.33. add_mrt function: process DVMRP_ADD_MRT command.
---------------------------------------------------------------------- ip_mroute.c 411 static int 412 add_mrt(mrtcp) 413 struct mrtctl *mrtcp; 414 { 415 struct mrt *rt; 416 u_long hash; 417 int s; 418 if (rt = mrtfind(mrtcp->mrtc_origin)) { 419 /* Just update the route */ 420 s = splnet(); 421 rt->mrt_parent = mrtcp->mrtc_parent; 422 VIFM_COPY(mrtcp->mrtc_children, rt->mrt_children); 423 VIFM_COPY(mrtcp->mrtc_leaves, rt->mrt_leaves); 424 splx(s); 425 return (0); 426 } 427 s = splnet(); 428 rt = (struct mrt *) malloc(sizeof(*rt), M_MRTABLE, M_NOWAIT); 429 if (rt == NULL) { 430 splx(s); 431 return (ENOBUFS); 432 } 433 /* 434 * insert new entry at head of hash chain 435 */ 436 rt->mrt_origin = mrtcp->mrtc_origin; 437 rt->mrt_originmask = mrtcp->mrtc_originmask; 438 rt->mrt_parent = mrtcp->mrtc_parent; 439 VIFM_COPY(mrtcp->mrtc_children, rt->mrt_children); 440 VIFM_COPY(mrtcp->mrtc_leaves, rt->mrt_leaves); 441 /* link into table */ 442 hash = nethash(mrtcp->mrtc_origin); 443 rt->mrt_next = mrttable[hash]; 444 mrttable[hash] = rt; 445 splx(s); 446 return (0); 447 } ---------------------------------------------------------------------- ip_mroute.c |
411-427
If the requested route is already in the routing table, the new information is copied into the route and add_mrt returns.
428-447
An mrt structure is constructed in a newly allocated mbuf with the information from mrtctl structure passed with the add request. The hash index is computed from mrtc_origin, and the new route is inserted as the first entry on the hash chain.
The multicast routing table is searched with the mrtfind function. The source of the datagram is passed to mrtfind, which returns a pointer to the matching mrt structure, or a null pointer if there is no match.???
Table 14.34. mrtfind function.
---------------------------------------------------------------------- ip_mroute.c 477 static struct mrt * 478 mrtfind(origin) 479 struct in_addr origin; 480 { 481 struct mrt *rt; 482 u_int hash; 483 int s; 484 mrtstat.mrts_mrt_lookups++; 485 if (cached_mrt != NULL && 486 (origin.s_addr & cached_originmask) == cached_origin) 487 return (cached_mrt); 488 mrtstat.mrts_mrt_misses++; 489 hash = nethash(origin); 490 for (rt = mrttable[hash]; rt; rt = rt->mrt_next) 491 if ((origin.s_addr & rt->mrt_originmask.s_addr) == 492 rt->mrt_origin.s_addr) { 493 s = splnet(); 494 cached_mrt = rt; 495 cached_origin = rt->mrt_origin.s_addr; 496 cached_originmask = rt->mrt_originmask.s_addr; 497 splx(s); 498 return (rt); 499 } 500 return (NULL); 501 } ---------------------------------------------------------------------- ip_mroute.c |
477-488
The given source IP address (origin) is logically ANDed with the origin mask in the cache. If the result matches cached_origin, the cached entry is returned.
Multicast forwarding is implemented entirely in the kernel. We saw in Figure 12.39 that ipintr passes incoming multicast datagrams to ip_mforward when ip_mrouter is nonnull, that is, when mrouted is running.
We also saw in Figure 12.40 that ip_output can pass multicast datagrams that originate on the local host to ip_mforward to be routed to interfaces other than the one interface selected by ip_output.
Unlike unicast forwarding, each time a multicast datagram is forwarded to an interface, a copy is made. For example, if the local host is acting as a multicast router and is connected to three different networks, multicast datagrams originating on the system are duplicated and queued for output on all three interfaces. Additionally, the datagram may be duplicated and queued for input if the multicast loopback flag was set by the application or if any of the outgoing interfaces receive their own transmissions.
Figure 14.35 shows a multicast datagram arriving on a physical interface.

In Figure 14.35, the interface on which the datagram arrived is a member of the destination group, so the datagram is passed to the transport protocols for input processing. The datagram is also passed to ip_mforward, where it is duplicated and forwarded to a physical interface and to a tunnel (the thick arrows), both of which must be different from the receiving interface.
Figure 14.36 shows a multicast datagram arriving on a tunnel.

In Figure 14.36, the datagram arriving on a physical interface associated with the local end of the tunnel is represented by the dashed arrows. It is passed to ip_mforward, which as we’ll see in Figure 14.37 returns a nonzero value because the packet arrived on a tunnel. This causes ipintr to not pass the packet to the transport protocols.
Table 14.37. ip_mforward function: tunnel arrival.
---------------------------------------------------------------------- ip_mroute.c 516 int 517 ip_mforward(m, ifp) 518 struct mbuf *m; 519 struct ifnet *ifp; 520 { 521 struct ip *ip = mtod(m, struct ip *); 522 struct mrt *rt; 523 struct vif *vifp; 524 int vifi; 525 u_char *ipoptions; 526 u_long tunnel_src; 527 if (ip->ip_hl < (IP_HDR_LEN + TUNNEL_LEN) >> 2 || 528 (ipoptions = (u_char *) (ip + 1))[1] != IPOPT_LSRR) { 529 /* Packet arrived via a physical interface. */ 530 tunnel_src = 0; 531 } else { 532 /* 533 * Packet arrived through a tunnel. 534 * A tunneled packet has a single NOP option and a 535 * two-element loose-source-and-record-route (LSRR) 536 * option immediately following the fixed-size part of 537 * the IP header. At this point in processing, the IP 538 * header should contain the following IP addresses: 539 * 540 * original source - in the source address field 541 * destination group - in the destination address field 542 * remote tunnel end-point - in the first element of LSRR 543 * one of this host's addrs - in the second element of LSRR 544 * 545 * NOTE: RFC-1075 would have the original source and 546 * remote tunnel end-point addresses swapped. However, 547 * that could cause delivery of ICMP error messages to 548 * innocent applications on intermediate routing 549 * hosts! Therefore, we hereby change the spec. 550 */ 551 /* Verify that the tunnel options are well-formed. */ 552 if (ipoptions[0] != IPOPT_NOP || 553 ipoptions[2] != 11 || /* LSRR option length */ 554 ipoptions[3] != 12 || /* LSRR address pointer */ 555 (tunnel_src = *(u_long *) (&ipoptions[4])) == 0) { 556 mrtstat.mrts_bad_tunnel++; 557 return (1); 558 } 559 /* Delete the tunnel options from the packet. */ 560 ovbcopy((caddr_t) (ipoptions + TUNNEL_LEN), (caddr_t) ipoptions, 561 (unsigned) (m->m_len - (IP_HDR_LEN + TUNNEL_LEN))); 562 m->m_len -= TUNNEL_LEN; 563 ip->ip_len -= TUNNEL_LEN; 564 ip->ip_hl -= TUNNEL_LEN >> 2; 565 } ---------------------------------------------------------------------- ip_mroute.c |
ip_mforward strips the tunnel options from the packet, consults the multicast routing table, and, in this example, forwards the packet on another tunnel and on the same physical interface on which it arrived, as shown by the thin arrows. This is OK because the multicast routing tables are based on the virtual interfaces, not the physical interfaces.
In Figure 14.36 we assume that the physical interface is a member of the destination group, so ip_output passes the datagram to ip_mloopback, which queues it for processing by ipintr (the thick arrows). The packet is passed to ip_mforward again, where it is discarded (Exercise 14.4). ip_mforward returns 0 this time (because the packet arrived on a physical interface), so ipintr considers and accepts the datagram for input processing.
We show the multicast forwarding code in three parts:
tunnel input processing (Figure 14.37),
forwarding eligibility (Figure 14.39), and
forward to outgoing interfaces (Figure 14.40).
516-526
The two arguments to ip_mforward are a pointer to the mbuf chain containing the datagram; and a pointer to the ifnet structure of the receiving interface.
527-530
To distinguish between a multicast datagram arriving on a physical interface and a tunneled datagram arriving on the same physical interface, the IP header is examined for the characteristic LSRR option. If the header is too small to contain the option, or if the options don’t start with a NOP followed by an LSRR option, it is assumed that the datagram arrived on a physical interface and tunnel_src is set to 0.
531-558
If the datagram looks as though it arrived on a tunnel, the options are verified to make sure they are well formed. If the options are not well formed for a multicast tunnel, ip_mforward returns 1 to indicate that the datagram should be discarded. Figure 14.38 shows the organization of the tunnel options.
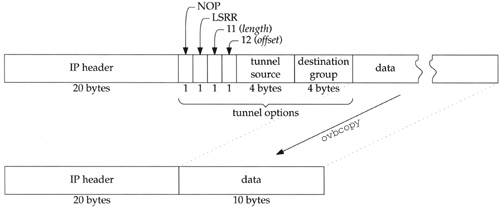
In Figure 14.38 we assume there are no other options in the datagram, although that is not required. Any other IP options will appear after the LSRR option, which is always inserted before any other options by the multicast router at the start of the tunnel.
559-565
If the options are OK, they are removed from the datagram by shifting the remaining options and data forward and adjusting m_len in the mbuf header and ip_len and ip_hl in the IP header (Figure 14.38).
ip_mforward often uses tunnel_source as its return value, which is only nonzero when the datagram arrives on a tunnel. When ip_mforward returns a nonzero value, the caller discards the datagram. For ipintr this means that a datagram that arrives on a tunnel is passed to ip_mforward and discarded by ipintr. The forwarding code strips out the tunnel information, duplicates the datagram, and sends the datagrams with ip_output, which calls ip_mloopback if the interface is a member of the destination group.
The next part of ip_mforward, shown in Figure 14.39, discards the datagram if it is ineligible for forwarding.
Table 14.39. ip_mforward function: forwarding eligibility checks.
---------------------------------------------------------------------- ip_mroute.c 566 /* 567 * Don't forward a packet with time-to-live of zero or one, 568 * or a packet destined to a local-only group. 569 */ 570 if (ip->ip_ttl <= 1 || 571 ntohl(ip->ip_dst.s_addr) <= INADDR_MAX_LOCAL_GROUP) 572 return ((int) tunnel_src); 573 /* 574 * Don't forward if we don't have a route for the packet's origin. 575 */ 576 if (!(rt = mrtfind(ip->ip_src))) { 577 mrtstat.mrts_no_route++; 578 return ((int) tunnel_src); 579 } 580 /* 581 * Don't forward if it didn't arrive from the parent vif for its origin. 582 */ 583 vifi = rt->mrt_parent; 584 if (tunnel_src == 0) { 585 if ((viftable[vifi].v_flags & VIFF_TUNNEL) || 586 viftable[vifi].v_ifp != ifp) 587 return ((int) tunnel_src); 588 } else { 589 if (!(viftable[vifi].v_flags & VIFF_TUNNEL) || 590 viftable[vifi].v_rmt_addr.s_addr != tunnel_src) 591 return ((int) tunnel_src); 592 } ---------------------------------------------------------------------- ip_mroute.c |
566-572
If ip_ttl is 0 or 1, the datagram has reached the end of its lifetime and is not forwarded. If the destination group is less than or equal to INADDR_MAX_LOCAL_GROUP (the 224.0.0.x groups, Figure 12.1), the datagram is not allowed beyond the local network and is not forwarded. In either case, tunnel_src is returned to the caller.
Version 3.3 of
mroutedsupports administrative scoping of certain destination groups. An interface can be configured to discard datagrams addressed to these groups, similar to the automatic scoping of the 224.0.0.x groups.
573-579
If mrtfind cannot locate a route based on the source address of the datagram, the function returns. Without a route, the multicast router cannot determine to which interfaces the datagram should be forwarded. This might occur, for example, when the multicast datagrams arrive before the multicast routing table has been updated by mrouted.
580-592
If the datagram arrived on a physical interface but was expected to arrive on a tunnel or on a different physical interface, ip_mforward returns. If the datagram arrived on a tunnel but was expected to arrive on a physical interface or on a different tunnel, ip_mforward returns. A datagram may arrive on an unexpected interface when the routing tables are in transition because of changes in the group membership or in the physical topology of the network.
The final part of ip_mforward (Figure 14.40) sends the datagram on each of the outgoing interfaces specified in the multicast route entry.
Table 14.40. ip_mforward function: forwarding.
---------------------------------------------------------------------- ip_mroute.c 593 /* 594 * For each vif, decide if a copy of the packet should be forwarded. 595 * Forward if: 596 * - the ttl exceeds the vif's threshold AND 597 * - the vif is a child in the origin's route AND 598 * - ( the vif is not a leaf in the origin's route OR 599 * the destination group has members on the vif ) 600 * 601 * (This might be speeded up with some sort of cache -- someday.) 602 */ 603 for (vifp = viftable, vifi = 0; vifi < numvifs; vifp++, vifi++) { 604 if (ip->ip_ttl > vifp->v_threshold && 605 VIFM_ISSET(vifi, rt->mrt_children) && 606 (!VIFM_ISSET(vifi, rt->mrt_leaves) || 607 grplst_member(vifp, ip->ip_dst))) { 608 if (vifp->v_flags & VIFF_TUNNEL) 609 tunnel_send(m, vifp); 610 else 611 phyint_send(m, vifp); 612 } 613 } 614 return ((int) tunnel_src); 615 } ---------------------------------------------------------------------- ip_mroute.c |
593-615
For each interface in viftable, a datagram is sent on the interface if
the datagram’s TTL is greater than the multicast threshold for the interface,
the interface is a child interface for the route, and
the interface is not connected to a leaf network.
If the interface is a leaf, the datagram is output only if there is a member of the destination group on the network (i.e., grplst_member returns a nonzero value).
tunnel_send forwards the datagram on tunnel interfaces; phyint_send is used for physical interfaces.
To send a multicast datagram on a physical interface, phyint_send (Figure 14.41) specifies the output interface explicitly in the ip_moptions structure it passes to ip_output.
Table 14.41. phyint_send function.
---------------------------------------------------------------------- ip_mroute.c 616 static void 617 phyint_send(m, vifp) 618 struct mbuf *m; 619 struct vif *vifp; 620 { 621 struct ip *ip = mtod(m, struct ip *); 622 struct mbuf *mb_copy; 623 struct ip_moptions *imo; 624 int error; 625 struct ip_moptions simo; 626 mb_copy = m_copy(m, 0, M_COPYALL); 627 if (mb_copy == NULL) 628 return; 629 imo = &simo; 630 imo->imo_multicast_ifp = vifp->v_ifp; 631 imo->imo_multicast_ttl = ip->ip_ttl - 1; 632 imo->imo_multicast_loop = 1; 633 error = ip_output(mb_copy, NULL, NULL, IP_FORWARDING, imo); 634 } ---------------------------------------------------------------------- ip_mroute.c |
616-634
m_copy duplicates the outgoing datagram. The ip_moptions structure is set to force the datagram to be transmitted on the selected interface. The TTL value is decremented, and multicast loopback is enabled.
The datagram is passed to ip_output. The IP_FORWARDING flag avoids an infinite loop, where ip_output calls ip_mforward again.
To send a datagram on a tunnel, tunnel_send (Figure 14.43) must construct the appropriate tunnel options and insert them in the header of the outgoing datagram. Figure 14.42 shows how tunnel_send prepares a packet for the tunnel.???

Table 14.43. tunnel_send function: verify and allocate new header.
---------------------------------------------------------------------- ip_mroute.c 635 static void 636 tunnel_send(m, vifp) 637 struct mbuf *m; 638 struct vif *vifp; 639 { 640 struct ip *ip = mtod(m, struct ip *); 641 struct mbuf *mb_copy, *mb_opts; 642 struct ip *ip_copy; 643 int error; 644 u_char *cp; 645 /* 646 * Make sure that adding the tunnel options won't exceed the 647 * maximum allowed number of option bytes. 648 */ 649 if (ip->ip_hl > (60 - TUNNEL_LEN) >> 2) { 650 mrtstat.mrts_cant_tunnel++; 651 return; 652 } 653 /* 654 * Get a private copy of the IP header so that changes to some 655 * of the IP fields don't damage the original header, which is 656 * examined later in ip_input.c. 657 */ 658 mb_copy = m_copy(m, IP_HDR_LEN, M_COPYALL); 659 if (mb_copy == NULL) 660 return; 661 MGETHDR(mb_opts, M_DONTWAIT, MT_HEADER); 662 if (mb_opts == NULL) { 663 m_freem(mb_copy); 664 return; 665 } 666 /* 667 * Make mb_opts be the new head of the packet chain. 668 * Any options of the packet were left in the old packet chain head 669 */ 670 mb_opts->m_next = mb_copy; 671 mb_opts->m_len = IP_HDR_LEN + TUNNEL_LEN; 672 mb_opts->m_data += MSIZE - mb_opts->m_len; ---------------------------------------------------------------------- ip_mroute.c |
635-652
If there is no room in the IP header for the tunnel options, tunnel_send returns immediately and the datagram is not forwarded on the tunnel. It may be forwarded on other interfaces.
653-672
In the call to m_copy, the starting offset for the copy is 20 (IP_HDR_LEN). The resulting mbuf chain contains the options and data for the datagram but not the IP header. mb_opts points to a new datagram header allocated by MGETHDR. The datagram header is prepended to mb_copy. Then m_len and m_data are adjusted to accommodate an IP header and the tunnel options.
The second half of tunnel_send, shown in Figure 14.44, modifies the headers of the outgoing packet and sends the packet.
Table 14.44. tunnel_send function: construct headers and send.
---------------------------------------------------------------------- ip_mroute.c 673 ip_copy = mtod(mb_opts, struct ip *); 674 /* 675 * Copy the base ip header to the new head mbuf. 676 */ 677 *ip_copy = *ip; 678 ip_copy->ip_ttl--; 679 ip_copy->ip_dst = vifp->v_rmt_addr; /* remote tunnel end-point */ 680 /* 681 * Adjust the ip header length to account for the tunnel options. 682 */ 683 ip_copy->ip_hl += TUNNEL_LEN >> 2; 684 ip_copy->ip_len += TUNNEL_LEN; 685 /* 686 * Add the NOP and LSRR after the base ip header 687 */ 688 cp = (u_char *) (ip_copy + 1); 689 *cp++ = IPOPT_NOP; 690 *cp++ = IPOPT_LSRR; 691 *cp++ = 11; /* LSRR option length */ 692 *cp++ = 8; /* LSSR pointer to second element */ 693 *(u_long *) cp = vifp->v_lcl_addr.s_addr; /* local tunnel end-point */ 694 cp += 4; 695 *(u_long *) cp = ip->ip_dst.s_addr; /* destination group */ 696 error = ip_output(mb_opts, NULL, NULL, IP_FORWARDING, NULL); 697 } ---------------------------------------------------------------------- ip_mroute.c |
673-679
The original IP header is copied from the original mbuf chain into the newly allocated mbuf header. The TTL in the header is decremented, and the destination is changed to be the other end of the tunnel.
680-664
ip_h1 and ip_len are adjusted to accommodate the tunnel options. The tunnel options are placed just after the IP header: a NOP, followed by the LSRR code, the length of the LSRR option (11 bytes), and a pointer to the second address in the option (8 bytes). The source route consists of the local tunnel end point followed by the destination group (Figure 14.13).
665-697
ip_output sends the datagram, which now looks like a unicast datagram with an LSRR option since the destination address is the unicast address of the other end of the tunnel. When it reaches the other end of the tunnel, the tunnel options are stripped off and the datagram is forwarded at that point, possibly through additional tunnels.
When mrouted shuts down, it issues the DVMRP_DONE command, which is handled by the ip_mrouter_done function shown in Figure 14.45.
Table 14.45. ip_mrouter_done function: DVMRP_DONE command.
---------------------------------------------------------------------- ip_mroute.c 161 int 162 ip_mrouter_done() 163 { 164 vifi_t vifi; 165 int i; 166 struct ifnet *ifp; 167 int s; 168 struct ifreq ifr; 169 s = splnet(); 170 /* 171 * For each phyint in use, free its local group list and 172 * disable promiscuous reception of all IP multicasts. 173 */ 174 for (vifi = 0; vifi < numvifs; vifi++) { 175 if (viftable[vifi].v_lcl_addr.s_addr != 0 && 176 !(viftable[vifi].v_flags & VIFF_TUNNEL)) { 177 if (viftable[vifi].v_lcl_grps) 178 free(viftable[vifi].v_lcl_grps, M_MRTABLE); 179 satosin(&ifr.ifr_addr)->sin_family = AF_INET; 180 satosin(&ifr.ifr_addr)->sin_addr.s_addr = INADDR_ANY; 181 ifp = viftable[vifi].v_ifp; 182 (*ifp->if_ioctl) (ifp, SIOCDELMULTI, (caddr_t) & ifr); 183 } 184 } 185 bzero((caddr_t) viftable, sizeof(viftable)); 186 numvifs = 0; 187 /* 188 * Free any multicast route entries. 189 */ 190 for (i = 0; i < MRTHASHSIZ; i++) 191 if (mrttable[i]) 192 free(mrttable[i], M_MRTABLE); 193 bzero((caddr_t) mrttable, sizeof(mrttable)); 194 cached_mrt = NULL; 195 ip_mrouter = NULL; 196 splx(s); 197 return (0); 198 } ---------------------------------------------------------------------- ip_mroute.c |
161-186
This function runs at splnet to avoid any interaction with the multicast forwarding code. For every physical multicast interface, the list of local groups is released and the SIOCDELMULTI command is issued to stop receiving multicast datagrams (Exercise 14.3). The entire viftable array is cleared by bzero and numvifs is set to 0.
187-198
Every active entry in the multicast routing table is released, the entire table is cleared with bzero, the cache is cleared, and ip_mrouter is reset.
Each entry in the multicast routing table may be the first in a linked list of entries. This code introduces a memory leak by releasing only the first entry in the list.
In this chapter we described the general concept of internetwork multicasting and the specific functions within the Net/3 kernel that support it. We did not discuss the implementation of mrouted, but the source is readily available for the interested reader.
We described the virtual interface table and the differences between a physical interface and a tunnel, as well as the LSRR options used to implement tunnels in Net/3.
We illustrated the RPB, TRPB, and RPM algorithms and described the kernel tables used to forward multicast datagrams according to TRPB. The concept of parent and leaf networks was also discussed.
14.1 | In Figure 14.25, how many multicast routes are needed? |
14.1 | Five. One each for networks A through E. |
14.2 | Why is the update to the group membership cache in Figure 14.23 protected by |
14.2 |
|
14.3 | What happens when |
14.3 | The |
14.4 | When a datagram arrives on a tunnel and is accepted by |
14.4 | Only one virtual interface is considered to be the parent interface for a multicast spanning tree. If the packet is accepted on the tunnel, then the physical interface cannot be the parent and |
14.5 | Redesign the group address cache to increase its effectiveness. |