
Writing System Variation and Text Entry
10.1 INTRODUCTION
Through Parts I, II, and IV of this book, the default language used for text entry tasks is English. This is because computers were first developed for the U.S. market and so the English interface was incorporated by default. However, in many parts of the world, text entry on computers, mobile phones, and PDAs is not done in English but in languages such as Arabic, Chinese, Hindi, and Russian, through scripts that are dissimilar to that of English. Given the variety of languages and scripts used throughout the world, such variation should be taken into consideration when designing devices and related software. Part III is therefore dedicated to a discussion of language and script variation as it pertains to text entry.
Part III is structured as follows. In this chapter, we describe the typology for writing systems proposed by Daniels (1996); in this typology, scripts can be categorized into six types of systems—logosyllabary, syllabary, abjad, alphabet, abugida, and featural—each of which raises a different set of text entry issues. The second half of this chapter examines issues in an alphabetic writing system. Since English is an alphabetic writing system, one assumes that text entry problems have been more than adequately covered in other chapters, but scripts such as Cyrillic (for Russian) also fall within this group, presenting small but not trivial problems for text entry.
The remaining chapters in Part III cover the five nonalphabetic writing systems. Chapter 11 is concerned with the logosyllabary in Chinese, Japanese, and Korean. Although Japanese uses syllabaries and Korean is primarily a featural system, the scripts used to write these languages cannot be discussed without considering their use of Chinese characters (a logosyllabary), which is why they are included in Chap. 11. Chapters 12 and 13 cover the two remaining writing systems—abugidas and abjads, respectively.
10.2 VARIATION IN WRITING SYSTEMS
Any discussion of text entry has to separate languages from scripts. Since languages can be classified according to similarities based on historical evolution, structure, or geographical proximity, and writing can be defined as “a set of visible or tactile signs used to represent units of language” (Coulmas, 1996), it may seem that a script typology would follow the language classification. The perception that writing is secondary to speech is reinforced by many linguists following Saussure (1993) and Bloomfield (1933) (for alternative views, see Harris, 1995, 2000; Vachek, 1989). However, scripts do not always map onto language classifications. For example, although Farsi, which is spoken in Iran, belongs to the Indo-European language family, like English, it is written in the Arabic script; on the other hand, Turkish, which does not belong to the Indo-European language family, uses the Roman script. Languages as diverse as Vietnamese in Vietnam and Bahasa in Indonesia have adopted the Roman script for their languages. Hence, we need to distinguish between languages and scripts.
In reality, several factors affect the choice of script for a language. This is best seen in examples of digraphia, where two scripts may be used for the same language (Grivelet, 2001). A language like Serbo-Croat is written in the Cyrillic script by Serbians, who are Orthodox, whereas Croatians, who are Catholic, use the Roman script (Magner, 2001). Similar instances of dual scripts for the same language can be found in South Asia, where languages like Sindhi and Punjabi are written in the Perso-Arabic script in Pakistan, but in India abugidas, such as Devanagari and Gurmukhi, are used. In these cases, the primary factor in script choice is religious affiliation but other factors can also dictate which script is used. Geographical location can affect script choice, as is the case with Konkani, an Indian language; since Konkani did not have a script of its own, speakers would write it in the script of the neighboring state, which could be Devanagari, Kannada, or the Roman script. Yet another factor is education: in north India, women were taught Hindi in the Devanagari script, whereas men used the Perso-Arabic script.
The arbitrary link between language and script is so great that whole systems are artificially replaceable. For example, as a result of government policy, the writing system in Turkey was changed from Arabic to Roman, and Hangeul was introduced as the Korean writing system in the 15th century.
Since text entry concerns language, it might be possible to construct intelligent text entry software by considering the linguistic characteristics of the languages. However, text entry above all is concerned with the writing system, because text entry is used to produce written text. Thus, any discussion of language variation regarding text entry should be based on a typology of scripts or writing systems rather than a language typology.
Given the large number of scripts in the world, it is necessary to group them so that they can be studied in a systematic manner. Scripts are usually classified based on the linguistic unit that the symbols represent. In the typology proposed by Saussure (1993), writing systems are divided into two categories: those using ideograms and those using phonograms. The most popular classification of scripts is a tripartite division that Daniels (1996) ascribes to Taylor (1883), but which has been popularized by Gelb (1952). In this classification, writing systems can be divided into three types: logography, syllabary, and alphabet. Although this classification added syllabaries as a separate writing system, it excluded large sets of scripts, namely, the Semitic scripts (Arabic and Hebrew), the scripts of South and Southeast Asia (e.g., Devanagari and Thai), and Korean Hangeul.
Gelb’s focus was the evolution of writing systems from the logography through the syllabary to the alphabet, and these other scripts were positioned between syllabaries and alphabets. Hebrew and Arabic were considered “consonantal syllabaries,” while South Asian and Southeast Asian scripts were “quasisyllabaries” (Gelb, 1952). There is hence considerable confusion about both the status of and the labels for these scripts. So, for example, the scripts in South and Southeast Asia have been variously termed “semialphabetic” (Vaid & Gupta, 2002), “semi-syllabic” (Vaid & Padakannaya, 2004), and “alphasyllabaries” (Bright, 1999). Since these labels imply a subsidiary status for these writing systems, Daniels (1992, 1996) resurrected the terms “abjad” and “abugida” for the Semitic and South/Southeast Asian writing systems, respectively. In addition, he created a typology for writing systems that is not evolution-based but lists six main writing systems, according them equivalent status. Part III of this book is, therefore, based on the typology set up by Daniels (1996), which recognizes the following six types of writing systems.
Logosyllabary—The primary example is the Chinese writing system. Japanese and Korean are also logosyllabaries to a certain degree because they incorporate Chinese characters in the written language. In a logosyllabary, a character denotes individual morphemes or a word. Due to this feature, thousands of characters are used in writing systems of this type.
Syllabary—Examples are the Japanese kana, Cree and Cherokee in North America, and Vai in Africa. In a syllabary, a character represents a syllable, but phonetically similar syllables do not have a similar graphical shape. For example, in Japanese kana, there is no graphical similarity between the syllables ![]() (ka) and
(ka) and ![]() (ki), even though they share the same consonant (/k/).
(ki), even though they share the same consonant (/k/).
Abugida—Examples are Devanagari and Thai, used in India and Southeast Asia, respectively. In this writing system, the consonant character contains an inherent vowel (such as a schwa) and the other vowels are indicated by modifying the base consonant character. Creating a character can be a complex matter of adding other consonants, vowels, and tones. For example, the following is a character in Khmer produced from six key presses, in which each part is produced by a stroke chained by the operator “+”:
![]()
Abjad—This type of writing system is a consonantary, such as Arabic, which is used not just in the Middle East but in a wide swathe from Albania to Malaysia because of religious links with Islam. The writing system has two characteristics. First, the consonants are represented by symbols but vowels play a secondary role. A second distinct characteristic is that the reading/writing direction is from right to left.
Featural—An example is Korean Hangeul. The phonogram letters are combined into a syllable block and the character shapes are related to distinctive features of the sound. For example, Hangeul jamos of similar shape, such as ![]() , and
, and ![]() , both represent apical sounds.
, both represent apical sounds.
Alphabet—Examples are English, Russian, and Turkish. The characters denote consonants and vowels.
Although alphabetic writing systems might seem dominant, millions of people write using nonalphabetic systems. In terms of sheer numbers, World Internet Statistics (2006) reports that Asia ranks the highest, with 380 million users (56.4% of the population), while the highest usage growth is seen in the Middle East (454.2% growth). China ranks second worldwide, with 123 million users, who represent 10.9% of Internet users, while Japan is third, with 86 million users (8.4%), followed by India with 50 million users (5%). The need to support languages other than alphabetic languages is clearly substantial.
10.3 TEXT ENTRY PROBLEMS IN DIFFERENT WRITING SYSTEMS
Text entry hardware and software in any writing system should address at least the following questions.
Input device—What is the best device for entering the script? How can a script be entered on an existing device?
Standards and compatibility—What is the character standard? If there are multiple standards, are they compatible?
Environmental settings—How can a user configure the language environment? Can the user easily switch between different languages and scripts?
Accuracy and efficiency—Is the resulting text accurate? For example, are accents retained? How efficient is the entry method?
Answers to these questions are readily available for English (and related scripts) because it is the default language for current interfaces. In languages and scripts that are different from English, text entry becomes an issue. For example, the Qwerty keyboard that was specifically designed to input English characters on the typewriter is easily adapted to other alphabetic scripts, such as Cyrillic, but the same method cannot be adopted for Chinese, which uses thousands of characters.
Of the six types of writing systems, this difficulty is especially severe for three categories: logosyllabary, abugidas, and abjads. The problems are summarized below and the solutions applied in each of these categories are discussed in more detail in Chaps. 11, 12, and 13.
Logosyllabary—discussed in Chap. 11.
Since Chinese and Japanese use thousands of characters that do not fit on the standard keyboard, a text entry system that enables the user to produce numerous characters had to be devised. The earliest solution consisted of a machine that used a combination of trays for the characters and levers to manipulate the trays. The modern solution is predictive entry, and predictive methods of all kinds have been mostly developed in East Asia.
Abugida—discussed in Chap. 12.
Although abugidas have a limited number of base symbols (about 50 to 70), the individual symbols change their shapes when combined with other symbols. The number of combinations can run into hundreds of different resulting block shapes. For tonal languages especially, such as Thai and Lao, the number of combinations increases because tones are explicitly incorporated in the symbols. On early typewriters, the normal and shift modes together were used to accommodate the basic symbols and diacritics, but sufficient block combinations could not be provided on the keyboard, therefore each component was shown linearly as an approximation. With the use of computers, this problem has been solved, but as seen in the Khmer example given in the previous section, multiple keystrokes are still required to produce a character.
Abjad—discussed in Chap. 13.
Abjads also have a limited number of characters. For example, Arabic has 28 characters, Farsi adds 4 consonants to the Arabic alphabet, and Urdu adds 8. There are three major problems in abjads concerning text entry software. The first is the appearance of the resulting text. Some Arabic letters are cursive and thus have to be joined. Character shapes depend on the position of the character, which can be initial, medial, final, or isolated. The second problem is the writing direction. Characters are written from right to left, but numerals are written from left to right. The third problem is the consonantary feature. The resulting text lacks information about vowels and the ambiguity of a chunk remains high. This poses problems when incorporating language technology. For example, if predictive entry is to be used, a lack of proper disambiguation will prevent precise prediction of the following word.
In the three remaining writing systems—alphabet, syllabary, and featural—text entry does not present the same degree of difficulty and, hence, they are discussed in conjunction with other writing systems. Alphabetic writing systems are taken up in the second half of this chapter, starting with the next section. Text entry in both syllabaries and featural writing systems is incorporated in Chap. 11, because the most prominent cases of a language using syllabary and featural writing systems with respect to advanced entry techniques are Japanese and Korean, respectively, and they cannot be explained without reference to their use of Chinese characters. Briefly, the text entry solution for syllabary and featural writing systems can be considered similar to that for an alphabet. Thus, Chap. 11 provides concrete examples of solutions for syllabary and featural systems along with those for a logosyllabary. Consequently, entry problems regarding language variation—both general issues and specific examples—are covered in Part III based on Daniels’ typology.
If an entry system has to be constructed for a new script, this can be done by referring to an example from another script that belongs to the same writing system. For example, Vai and Japanese kana belong to the same writing system (syllabary), so the entry methods used for the two scripts can influence each other.
In addition, it would be interesting to apply an entry method developed for one type of writing system to another type. For example, predictive methods developed for logosyllabary writing systems are now used worldwide because the emergence of mobile devices has made the “too many characters for too few keys” a common problem regardless of the script. Similarly, an abugida writing system uses hundreds of combinations of resulting blocks, so predictive entry is a useful solution. This problem exists in other writing systems; Korean, a featural writing system, also combines Hangeul blocks and, as we will explain in Section 10.4.1, the same problem arises in alphabetic scripts that use diacritics.
10.4 ALPHABETIC SCRIPTS
The area where alphabetic writing systems are used is vast: in addition to Europe and North and South America, it includes Turkey, Russia, parts of Asia such as the Philippines and Vietnam, and parts of Africa such as places where the Comorian and Mandinka languages are used. Since the default linguistic features of most user interfaces for computer keyboards, mobile phones, and PDAs are currently based on English, with some modifications, the interface can be adapted to other scripts that are based on the Roman alphabet; in addition to East and West European languages, this includes languages for which the Roman script has been introduced as the national writing standard, such as Turkish and Vietnamese. Moreover, although scripts such as Cyrillic (for Russian), Armenian, and Greek look very different from the Latin alphabet, they belong to the same writing system, namely the alphabet, although the symbols may differ. Consequently, a large number of people use an alphabetic writing system.
Alphabetic scripts have the following characteristics.
![]() Each written symbol corresponds to a consonant or a vowel.
Each written symbol corresponds to a consonant or a vowel.
![]() The alphabet therefore consists of a limited number of characters.
The alphabet therefore consists of a limited number of characters.
![]() Characters are written in a linear sequence (in contrast to abugidas and abjads in which markers can appear nonlinearly).
Characters are written in a linear sequence (in contrast to abugidas and abjads in which markers can appear nonlinearly).
The limited number of characters fits easily onto a standard Qwerty keyboard, which was originally designed for English typewriters. The conventional keyboard is sufficient for both upper- and lowercase letters, as well as numbers, punctuation marks, and special symbols. Also, since the symbols can be written only linearly, the sole task of the text entry software is to translate the signal into the character code before rendering the symbols on the screen.
Computer encoding of this type of writing system for the English (i.e., Roman) alphabet plus diacritics has used 8-bit character encoding under ISO-8859, making use of the 8th bit saved in the ASCII code. The most popular is the encoding known as Latin 1, still popular in Western Europe. Similar versions, namely, Latin 2, 3, and 4, include other diacritics. Recently, all characters have been equally incorporated into Unicode in the form of 2-byte characters.
Consequently, there have been no significant problems concerning text entry within alphabetic systems compared with logosyllabaries, abugidas, and abjads. An English interface can be easily converted for other alphabetic systems through slight modifications. All the technologies introduced in Parts I, II, and IV of this book can be similarly accommodated to fit other alphabetic scripts.
Still, adapting an English interface to another alphabetic language can involve two issues. One is how to accommodate diacritics, such as the tilde in Spanish or the accents in French. The other concerns languages with different sets of symbols, such as Russian. These two types of scripts are examined in the next two subsections.
10.4.1 Roman Scripts with Diacritics
French, German, and Spanish are alphabetic scripts that use the Roman alphabet but modify some letters through diacritics, such as accents, umlauts, tildes, and cedillas. A diacritical mark or a diacritic is added to a letter to alter the pronunciation of a word or to distinguish between similar words; it can appear above or below the letter to which it is added or in another position. However, such marks are not always diacritical. For example, in English, the tittle (dot) in the letters i and j is not a diacritical mark, but part of the letter itself. Further, a mark may be diacritical in one language, but not in another; for example, in Catalan, Portuguese, and Spanish, u and ü are considered the same letter, while in German, Estonian, Hungarian, and Turkish, they are considered separate letters.
Under the norms of text entry, such modification can be handled in two ways:
![]() A character with a diacritic can be considered a different character from the original character without the diacritic. If only a few characters have a diacritic, these characters can be considered as an addition to the normal alphabet. For text entry, this approach means that each character with a diacritic is assigned to a particular key of the keyboard.
A character with a diacritic can be considered a different character from the original character without the diacritic. If only a few characters have a diacritic, these characters can be considered as an addition to the normal alphabet. For text entry, this approach means that each character with a diacritic is assigned to a particular key of the keyboard.
![]() A character with a diacritic can be treated as a combination of a Latin character and a diacritic. In this case, diacritics can be assigned to separate keys and a character with a diacritic can be entered through multiple keystrokes. This method becomes similar to that for an abugida in which the resultant character is built from components.
A character with a diacritic can be treated as a combination of a Latin character and a diacritic. In this case, diacritics can be assigned to separate keys and a character with a diacritic can be entered through multiple keystrokes. This method becomes similar to that for an abugida in which the resultant character is built from components.
For most languages, the first solution is generally used for two reasons: first, each character with a diacritic can be encoded separately, and second, it is easier from the developer’s perspective. However, there are exceptions, like in Czech, which contains many characters with diacritics: all vowels plus the consonants C, D, N, R, S, T, and Z can have diacritics. In the default text entry method for Czech, such characters are entered by first typing the diacritic and then the alphabetic symbol. Also, even in languages with direct entry, nonnative speakers prefer to use a combination of a diacritic mark and alphabetic symbol because they are not familiar with the keyboard layout for characters with diacritics. For example, the French é can be obtained by entering an apostrophe (′) after e.
To illustrate how text entry works in a Roman script with diacritics, we have used the example of Turkish. Although Turkish is structurally different from English, the language is represented well by the Roman script. Turkish uses 29 letters, of which 8 are vowels. The alphabet differs slightly from the English: it does not include w, q, or x, but uses ç, ![]() , ö,
, ö, ![]() , ü, and 1 (i without a dot). Thus, the entire alphabet is Aa Bb Cc Dd Ee Ff Gg
, ü, and 1 (i without a dot). Thus, the entire alphabet is Aa Bb Cc Dd Ee Ff Gg ![]() Hh Ii Ïï Jj Kk Ll Mm Nn Oo Öö Pp Rr Ss
Hh Ii Ïï Jj Kk Ll Mm Nn Oo Öö Pp Rr Ss ![]()
![]() Tt Uu Üü Vv Yy Zz.
Tt Uu Üü Vv Yy Zz.
The standard keyboard layout for the Turkish alphabet for entry on a PDA’s soft keyboard is shown in Fig. 10.1. We see how similar it is to the English keyboard, with only slight modifications to accommodate Turkish characters with diacritics. Note that the character set includes w, q, and x so that entry in English is possible.

For mobile phones, SMS is popular in Turkey. The assignment of letters on a mobile phone depends on the brand. However, for all current products, the Turkish letters are available, assigned in alphabetical order to the 2 to 9 buttons, with three to five letters assigned to each digit. A layout example is shown in Fig. 10.2. The standard method for entering text is by the multitap method. For example, to type the letter ü, a user clicks on the 8 button three times: first t appears, then u, and then ü. Some recent mobile phones also offer a predictive function such as one-key with disambiguation and word completion.

Thus, even in a language as different as Turkish, the text entry technologies developed for English can be applied. The same applies to other Latin alphabetic scripts that use diacritics.
10.4.2 Non-roman scripts
Although Russian and Greek use a set of symbols different from that of English, text entry in these scripts does not present much of a problem. Since these scripts are based on an alphabetic writing system, there is a limited set of symbols that can be accommodated on a standard keyboard designed for English. In fact, it may be easier to deal with an entirely different set of symbols than to design input devices for scripts that include characters with diacritics, when the diacritics increase the number of characters to be accommodated. In an alphabetic script that uses a different set of symbols, the alphabet can be redefined to best fit the language. Therefore, the number of characters usually remains small and all characters can be handled uniquely. The main issue for text entry is to change the character mapping given the entry signal.
One major difference between scripts with diacritics and non-Roman scripts lies in their encoding. In non-Roman scripts, all characters are encoded by 2 bytes, whereas Roman scripts that use diacritics are encoded by 1 byte as Latin 1 to 4. However, with the emergence of other characters to be encoded, for which every encoding requires at least 2 bytes, no technical problems remain with respect to 2-byte encoding.
Russian is representative of a non-Roman alphabetic script. The Cyrillic alphabet now consists of 33 letters. (The number of characters in the alphabet defined as the national standard has changed historically as rarely used characters have been removed.) The current alphabet on a standard Russian keyboard is shown in Fig. 10.3; again, this is a PDA’s soft keyboard. Note how this assignment is completely different from the layout for English on the Qwerty keyboard; for example, the Cyrillic A is not assigned to the same key as the English A but is based on the convention for Russian typewriters. This phonetically different assignment of two languages onto the standard full keyboard does not cause a major problem, and there are many expert touch-typists who can switch between typing in Russian and English. Although there is a keyboard that maps Cyrillic symbols to English symbols, the most popular keyboard layout has become the one shown in Fig. 10.3.

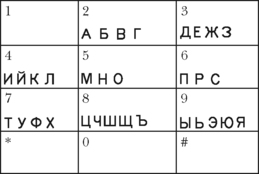
Regarding mobile phones, SMS is popular throughout Russian-speaking areas. The characters are assigned to each digit from 2 to 9 in alphabetical order, just as for English. The keyboard layout on a mobile phone keypad depends on the product, but a popular assignment is shown in Fig. 10.4; in this case, 32 characters are accommodated (Ë, a rarely used character, has been dropped from digit 3). Here, as the number of characters assigned to each digit ranges from 3 to 5, several key presses are needed for a character. This problem is alleviated by an alternative key assignment, such as that in a Motorola mobile phone, on which only three or four characters are assigned to each digit.
Similar solutions have been used in Greece and for other alphabetic scripts that use non-Roman symbols. As we have explained, while text entry solutions have tended to be developed around English norms, the technologies for English text entry systems can be easily applied to such scripts.
10.5 CONCLUDING REMARKS
Convenient text entry is the key to modern electronic communication. To enable this, the differences among scripts must be taken into consideration so that devices are designed to accommodate the language of each user. Even though languages and scripts might seem to vary as much as people, Daniels suggests that all scripts can be grouped under six categories. Such a typology provides a useful bird’s-eye view and will help to generate a more universal technology.
10.6 ACKNOWLEDGMENTS
The parts of this section concerning the Turkish, Russian, and Czech languages were written based on the kind comments provided by Ms. Ye![]() im Yaz1c1 (Project Chief, HP Pelzer Pimsa Otomotiv A.
im Yaz1c1 (Project Chief, HP Pelzer Pimsa Otomotiv A.![]() .), Associate Professor Vitaly Klyuev (Aizu University), and Associate Professor Vladislav Kubon (Charles University Prague), respectively. We are grateful for their help.
.), Associate Professor Vitaly Klyuev (Aizu University), and Associate Professor Vladislav Kubon (Charles University Prague), respectively. We are grateful for their help.
REFERENCES
Bloomfield L. Language. New York: Rinehart & Winston; 1933.
Bright W. A matter of typology: Alphasyllabaries and abugidas. Written Language and Literacy. 1999;2:45–55.
Coulmas F. The Blackwell encyclopedia of writing systems. Oxford: Blackwell; 1996.
Daniels P. The syllabic origin of writing and the segmental origin of the alphabet. In: Downing P., Lima S., Noonan M., eds. The linguistics of literacy. Amsterdam: John Benjamins; 1992:83–110.
Daniels P. The study of writing systems. In: Daniels P., Bright W., eds. The world’s writing systems. New York: Oxford University Press; 1996:3–17.
Gelb I. A study of writing. Chicago: University of Chicago Press; 1952.
Grivelet S. Introduction to digraphia: Writing systems and society. International Journal of the Sociology of Language. 2001;150:1–10.
Harris R. Signs of writing. London: Routledge; 1995.
Harris R. Rethinking writing. Bloomington: Indiana University Press; 2000.
Magner M. Digraphia in the territories of the Croats and Serbs. International Journal of the Sociology of Language. 2001;150:11–26.
Saussure F. 3eme Cours de Linguistique Générate (2de partie: la langue) de Ferdinand Saussure, notes taken by E. Constantin. Elmsford, NY: Pergamon; 1993.
Taylor I. The alphabet: An account of the origin and development of letters. London: Kegan Paul, Trench; 1883.
Vachek J. Written language revisited. Amsterdam: John Benjamins; 1989.
Vaid J., Gupta A. Exploring word recognition in a semi-alphabetic script: The case of Devanagari. Brain and Language. 2002;81:679–690.
Vaid J., Padakannaya P. Introduction to the special issue of Reading and Writing: An Interdisciplinary Journal. Reading and Writing: An Interdisciplinary Journal. 2004;17:1–6.