
Chapter 12. Establishing Architectural Principles
He wins his battles by making no mistakes. Making no mistakes is what establishes the certainty of victory, for it means conquering an enemy that is already defeated.
—Sun Tzu
Corporate “values” statements are often posted in workplaces and serve to remind employees of the desired behavior and culture within their companies. In this chapter, we present the scalability analog to these corporate values—architectural principles. These principles both guide the actions of technology teams and form the criteria against which technology architectures are evaluated.
Principles and Goals
Upon reviewing the high-level goal tree that was originally defined in Chapter 5, Management 101, and reproduced in Figure 12.1, you might recall that the tree indicates two general themes: the creation of more monetization opportunities and greater revenue at a reduced cost base. These themes are further broken out into topics such as quality, availability, cost, time to market (TTM), and efficiency. Furthermore, these topics are each assigned specific SMART goals.
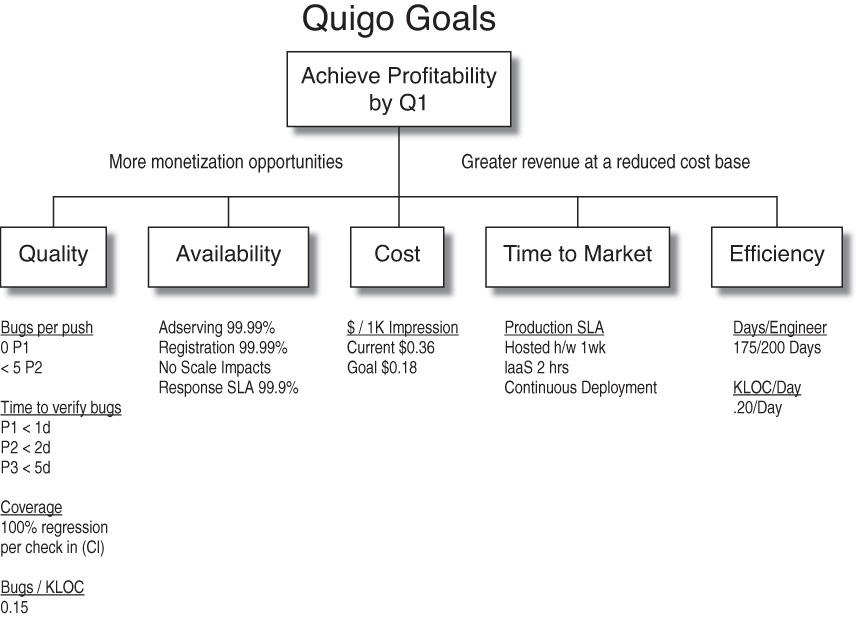
Ideally, our architectural principles will be based on our high-level goal tree topics and not on specific goals. Our goals are likely to change over time, so our principles should broadly support both future goals and current ones.
Our clients often find it useful to begin a principle-setting session by brainstorming. For example, you might start by taking the goal tree from Figure 12.1 and writing each theme on a whiteboard. Ensure that the goal tree stays prominently displayed throughout the session for reference. For each topic (e.g., quality, availability, cost, TTM, and efficiency), focus on finding broad principles that can serve as a “test” for any given initiative—that is, principles with which you can determine whether a suggested architectural design change meets the selected criteria. Principles that are so lofty and nebulous that they cannot be used practically in a design or architecture review (e.g., “design to be scalable”) won’t assist in driving cost-effective, scalable, and highly available architectures. Likewise, principles that are aspirational in nature but are often cast aside in practice in favor of expediency or for other reasons are not useful.
When we facilitate these sessions, we keep our clients focused on principle exploration—writing down as many principles as possible under each topic. Discussion is valuable, because each person should be able explain the meaning of a proposed principle. Oftentimes these discussions improve the phrasing of the principle itself. For instance, a principle that is presented as “horizontal scalability” may start a discussion about whether that principle is meant to keep the team from implementing “vertical scalability” (the ability to use a larger solution or server). The team may then decide to change the title “horizontal scalability” to “scale out, not up” to show the desire to limit vertical scalability wherever possible in favor of horizontal scalability.
When conducting an exercise similar to the one described here, an experientially diverse team is important. Recall from Chapter 3, Designing Organizations, that experiential diversity increases the level of cognitive conflict, and hence the innovation and strategic value of the results. Brainstorming sessions, then, should include members with backgrounds in software development, general architecture, infrastructure, DevOps, quality assurance, project management, and product ownership. Questions that appear initially driven by a session participant’s lack of experience in a particular area frequently uncover valuable insights.
It is important that each of the candidate principles embody as many of the SMART characteristics discussed in Chapter 4, Leadership 101, as possible. One notable exception is that principles are not really “time bounded.” When speaking of architectural principles, the “T” in the SMART acronym means the principle can be used to “test” a design and validate that it meets the required intent. Lofty nebulous principles don’t meet this criterion.
One often-used lofty—and therefore unfortunate—architectural principle is “infinitely scalable.” Infinite scalability is simply not achievable and would require infinite cost. Furthermore, this principle does not allow for testing. (How would you test against a principle that by definition has no limit?) No deployment architecture can meet the defined goal. Finally, we must consider the role of principles in guiding organizational work habits. Principles should ideally help inform design and indicate a path toward success. Lofty and aspirational principles like “infinite design” don’t offer a map to a destination, making them useless as a guide.
Principle Selection
We can all cite examples where we worked on a problem for an extended period of time but just couldn’t get to the right solution, and then magically, with just a bit of sleep, the solution came to us. Brainstorming exercises often follow a similar pattern. For that reason when facilitating principle-setting sessions, we like to perform the principle exploration exercise (the whiteboard exercise described previously) on day 1 and the principle selection exercise on day 2. These exercises do not need to take a full day each. For small companies, a few hours each day may suffice. For larger and more complex companies, given the high value that the principles will return, it makes sense to allocate more time and effort to these activities.
At the beginning of the second day, review the principles you wrote on the whiteboard and have the team recap the discussions from the previous day. One way to do so is to have participants present each of the principles on the board and invite a brief discussion of its merits. Kicking off the second day in this fashion will stimulate the collective memory of the team and jumpstart the value creation effort for the remainder of the day.
When selecting principles (during the latter portion of the second day), we like to use a crowd sourcing technique. Our approach is to allow each of the participants in the meeting to vote for a constrained number of principles. Using this technique, each participant walks to the whiteboard and casts up to his or her quota of votes. Principles are best kept to an easily memorized and easy-to-use number (say, 8 to 15); we generally limit votes per person to roughly half the number of desired principles. Having fewer than 8 principles isn’t likely to cover the entire spectrum necessary to achieve the desired effect. Conversely, having more than 15 principles tends to be too cumbersome for reviews and makes it too hard to remember the principles as means to drive daily efforts. Choosing half the number of principles as a vote quota usually makes it easy to narrow the number of candidate principles to a manageable size.
After the team voting is complete, you will likely end up with clear winners and a number of principles that are “ties” or are close in terms of total votes. It is common to have more than your desired number of principles, in which case you might decide to invite some discussion and debate (cognitive conflict) to narrow the list down to your desired number. Once the voting is finished, it’s time to think of your “principle go to market” strategy.
We like to present the principles in a fashion that is easily distributed on a single page and that makes explicit the causal roadmap between the principle and what it is expected to achieve. One way to do so is to bundle the principles into the areas they are expected to support in a Venn diagram. We are big fans of Venn diagrams for presenting principles because so many of the principles are likely to affect multiple areas.
Returning to the earlier example, Quigo’s goal tree topics include efficiency, time to market, availability, cost, and quality. When developing the principles at Quigo, we decided that efficiency and cost were tightly correlated and could be presented within one region of the Venn diagram (higher levels of efficiency are correlated with lower costs). While scalability was not part of the goal tree, it is highly correlated with availability and deserved a place in our diagram. Quality is also clearly highly correlated with availability; thus, quality, availability, and scalability are presented together. With these relationships, we reduced our Venn diagram to three regions: availability/scalability/quality, cost/efficiency, and TTM (time to market). Figure 12.2 shows a potential outcome of such a Venn diagram plot.
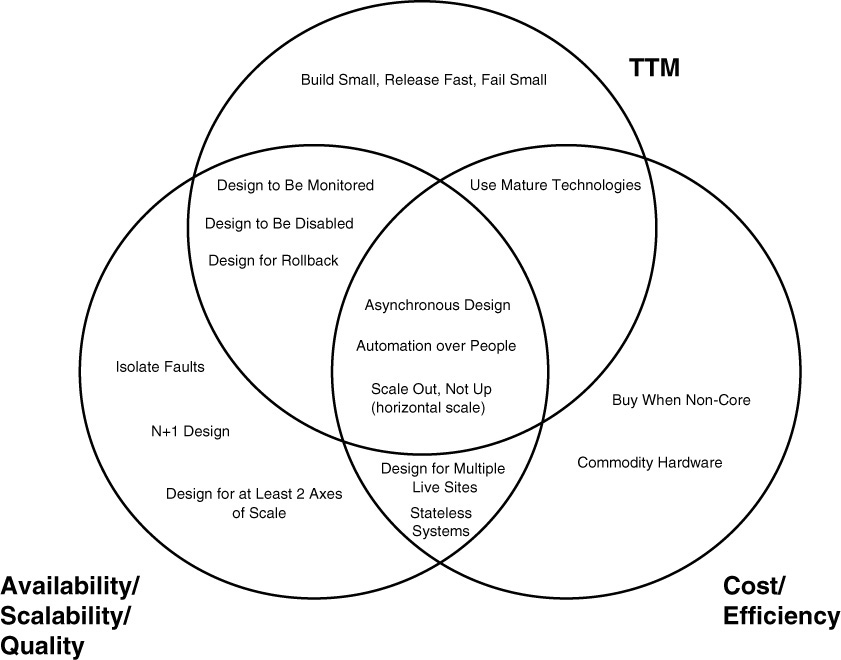
AKF’s Most Commonly Adopted Architectural Principles
In this section, we introduce the 15 most commonly adopted architectural principles from our client base. Many times during engagements, we will “seed” the architectural principle gardens of our clients with these 15 principles. We then ask them to conduct their own process, taking as many as they like, discarding any that do not work, and adding as many as needed. We also update this list if our clients come up with an especially ingenious or useful principle. The Venn diagram shown in Figure 12.2 depicts our principles as they relate to scalability, availability, and cost. We will discuss each of the principles at a high level and then dig more deeply into those that are identified as having an impact on scalability.
N + 1 Design
Simply stated, this principle expresses the need to ensure that anything you develop has at least one additional instance of that system in the event of failure. Apply the rule of three (which we will discuss in Chapter 32, Planning Data Centers), or what we sometimes call ensuring that you build one for you, one for the customer, and one to fail. This principle holds true for everything from large data center design to Web services implementations.
Design for Rollback
This is a critical principle for Web services, Web 2.0, or Software as a Service (SaaS) companies. Whatever you build, ensure that it is backward compatible. In other words, make sure that you can roll it back if you find yourself in a position of spending too much time “fixing it forward.” Some companies offer that they can roll back within a specific window of time—say, the first few hours after a change is made. Unfortunately, some of the worst and most disastrous failures won’t show up for several days, especially when those failures involve customer data corruption. In the ideal case, you will design to allow something to be rolled, pushed, or deployed while your product or platform is still “live.” The rollback process is covered in more detail in Chapter 18, Barrier Conditions and Rollback.
Design to Be Disabled
When designing systems, especially very risky systems that communicate to other systems or services, make them capable of being “marked down” or disabled. This will give you additional time to “fix forward” or ensure that your system doesn’t go down as a result of a bug that introduces strange, out-of-bounds demand characteristics to the system.
Design to Be Monitored
Monitoring, when done well, goes beyond the typical actions of identifying services that are alive or dead, examining or polling log files, collecting system-related data over time, and evaluating end-user response times. When done well, applications and systems are designed from the ground up to be if not self-healing, then at least self-diagnosing. If a system is designed to be monitored and logs the correct information, you can more easily determine the headroom remaining for the system and take the appropriate action to correct scalability problems earlier.
For instance, at the time of design of any system, you know which services and systems it will need to interact with. Perhaps the service in question repeatedly makes use of a database or some other data store. Potentially, the service makes a call, preferably asynchronously, to another service. You also know that from time to time you will be writing diagnostic information and potentially errors to some sort of volatile or stable storage system. You can apply all of this knowledge to design a system that can give you more information about future scale needs and thereby increase the system’s availability.
We argue that you should build systems that will help you identify potential or future issues. Returning to our example system and its calls to a database, we should log the response time of that database over time, the amount of data obtained, and maybe the rate of errors. Rather than just reporting on that data, our system could be designed to show “out of bounds” conditions plotted from a mean of the last 30 Tuesdays (assuming today is Tuesday) for our five-minute time of day. Significant standard deviations from the mean could be “alerted” for future or immediate action depending on the value. This approach leverages a control chart from statistical process control.
We could do the same with our rates of errors, the response time from other services, and so on. We could then feed this information into our capacity planning process to help us determine where demand versus supply problems might arise. In turn, we can identify which systems are likely candidates for future architectural changes.
Design for Multiple Live Sites
Having multiple sites is a must to assure your shareholders that you can weather any geographically isolated disaster or crisis. The time to start thinking about strategies for running your data centers isn’t when you are deploying those data centers, but rather when you are designing them. All sorts of design tradeoffs will impact whether you can easily serve data out of more than one geographically dispersed data center while your system is live. Does your application need or expect that all data will exist in a monolithic database? Does your application expect that all reads and writes will occur within the same database structures? Must all customers reside within the same data structures? Are other services called in synchronous fashion, and are they intolerant to latency?
Ensuring that your product designs allow services to be hosted in multiple locations and operate independently of one another is critical to achieving rapid deployment. Such designs also allow companies to avoid the constraints of power and space within a single facility and enable cloud infrastructure deployments. You may have an incredibly scalable application and platform, but if your physical environment and your operating contracts keep you from scaling, you are just as handicapped as if you had nearly infinite space and a platform that needs to be re-architected for scale. Scalability is about more than just system design; it is about ensuring that the business environment in which you operate, including contracts, partners, and facilities, is also scalable. Therefore, your architecture must allow you to make use of several facilities (both existing and potentially new) on an on-demand basis.
Use Mature Technologies
We all love to play with and implement the newest and sexiest technologies available. Oftentimes the use of such technology can be useful in helping to reduce our costs, decrease time to market, decrease costs of development, increase ease of scalability, and decrease end-user response times. In many cases, new technology can even create a short-lived competitive advantage. Unfortunately, new technology, by definition, also tends to have a higher rate of failure; thus, if it is implemented in critical portions of your architecture, it may result in significant hits to availability. When availability is important within a solution or service, you should base it on technology that is proven and reliable.
In many cases, you may be tempted by the competitive edge promised by a new vendor technology. Be cautious here: As an early adopter, you will also be on the leading edge of finding bugs with that software or system. If availability and reliability are important to you and your customers, try to be an early majority or late majority adopter of systems that are critical to the operation of your service, product, or platform. Implement newer technology for new features that are less critical to the availability of your solution, and port that technology to mission-critical areas once you’ve proven it can reliably handle the daily traffic volume.
Asynchronous Design
Simply put, synchronous systems have a higher failure rate than those designed to act asynchronously. Furthermore, the scalability of a synchronous system is limited by the slowest and least scalable system in the chain of communications. If one system or service slows, the entire chain slows, lowering throughput. Thus, synchronous systems are more difficult to scale in real time.
Asynchronous systems are far more tolerant of slowdowns. As an example, consider the case where a synchronous system can serve 40 simultaneous requests. When all 40 requests are in flight, no more can be handled until at least one completes. In contrast, asynchronous systems can handle the new request and do not block for the response. They have a service that waits for the response while handling the next request. Although throughput is roughly the same, they are more tolerant to slowness, as requests can continue to be processed. Responses may be slowed in some circumstances, but the entire system does not grind to a halt. Thus, if you have only a periodic slowness, an asynchronous system will allow you to work through that slowness without stopping the entire system. This approach may buy you several days to “fix” a scale bottleneck, unlike the immediate action required with a synchronous system.
In many places, however, you are seemingly “forced” to use a synchronous system. For instance, many database calls would be hampered and the results potentially flawed if subjected to an asynchronous passing of messages. Imagine two servers requesting similar data from a database—for example, both of them asking for the current bid price on a car, as depicted in Figure 12.3.

In Figure 12.3, system A makes a request, after which system B makes a request. B receives the data first and then makes a bid on the car, thereby changing the car’s price. System A then receives data that is already out of date. Although this seems undesirable, we can make a minor change to our logic that allows this to happen without significant impact to the entire process.
We need merely change the case in which A subsequently makes a bid. If the bid value by A is less than the bid made by B, we simply indicate that the value of the car has changed and display the now-current value. A can then make up her mind as to whether she wants to continue bidding. In this way, we take something that most people would argue needs to be synchronous and make it asynchronous.
Stateless Systems
Stateful systems are those in which operations are performed within the context of previous and subsequent operations. As such, information on the past operations of any given thread of execution or series of requests must be maintained somewhere. In maintaining state for a series of transactions, engineering teams typically start to gather and keep a great deal of information about the requests. State costs money, processing power, availability, and scalability. Although there are many cases where statefulness is valuable, it should always be closely evaluated for return on investment. State often implies the need for additional systems and synchronous calls that would otherwise not be required. Furthermore it makes designing a system for multiple live data centers more difficult: How can you possibly handle a transaction with state-related information stored in data center X in data center Y without replicating state between data centers? The replication would not only need to occur in near real time (implying a further requirement that data centers be relatively close), but also doubles the space needed to store relatively transient data.
Whenever possible, avoid developing stateful products. Where necessary, consider storing state with the end user rather than within your system. If that is not possible, consider a centralized state caching mechanism that keeps state data off of the application servers and allows for its distribution across multiple servers. If the state needs to be multitenant for any reason, attempt to segment the state information by customer or transaction class to facilitate distribution across multiple data centers, and try to maintain persistency for that customer or class of transaction within a single data center, with only the data that is necessary for failover being replicated.
Scale Out, Not Up
A good portion of this book deals with the need to scale horizontally. If you want to achieve near-infinite scale, you must disaggregate your systems, organization, and processes to allow for that scale. Forcing transactions through a single person, computer, or process is a recipe for disaster. Many companies rely on Moore’s law for their scale and as a result continue to force requests into a single system (or sometimes two systems to eliminate single points of failures), relying upon faster and faster systems to scale. Moore’s law isn’t so much a law as it is a prediction that the number of transistors that can be placed on an integrated circuit will double roughly every two years. The expected result is that the speed and capacity of these transistors (in our case, a CPU and memory) will double within the same time period. But what if your company grows faster than this rate, as did eBay, Yahoo, Google, Facebook, MySpace, and so on? Do you really want to become the company that is limited in growth when Moore’s law no longer holds true?
Could Google, Amazon, Yahoo, or eBay run on a single system? Could any of them possibly run on a single database? Many of these companies started out that way, but the technology of the day simply could not keep up with the demands that their users placed on them. Some of them faced crises of scale associated with attempting to rely upon bigger, faster systems. All of them would have faced those crises had they not started to scale out rather than up.
The ability to scale out, rather than up, is essential when designing to leverage the elasticity and auto-scaling features present within many Infrastructure as a Service (IaaS) providers. If one cannot easily add read copies of databases, or additional Web and application servers, the benefits of renting capacity within “the cloud” (IaaS) cannot be fully realized. There may be no other principle as important to scaling a product as the ensuring that one can always scale horizontally (or out, rather than up).
Design for at Least Two Axes of Scale
Leaders, managers, and architects are paid to think into the future. You are not designing just for today, but rather attempting to piece together a system that can be used, with some modification, in the future. As such, we believe that you should always consider how you will execute your next set of horizontal splits even before that need arrives. In Chapter 22, we introduce the AKF Scale Cube for this purpose. For now, suffice it to say there are multiple ways to split up both your application and databases. Each of these approaches will help you scale differently.
“Scaling out, not up” speaks to the implementation of the first set of splits. Perhaps you are splitting transaction volume across cloned systems. You might have five application servers with five duplicate read-only caches consisting of startup information and nonvolatile customer information. With this configuration, you might be able to scale to 1 million transactions per hour across 1,000 customers and service 100% of all your transactions from login to logout and everything in between. But what will you do when you have 75 million customers? Will the application’s startup times suffer? Will memory access times begin to degrade? More worrisome, can you even keep all of the customer information within memory?
For any service, you should consider how you will perform your next type of split. In this case, you might divide your customers into N separate groups and service customers out of N separate pools of systems, with each pool handling 1/Nth of your customers. Or perhaps you might move some of the transactions (e.g., login and logout, updating account information) to separate pools if that will lower the number of startup records needed within the cache. Whatever you decide to do, for major systems implementations, you should think about it during the initial design even if you implement only one axis of scale.
Buy When Non-Core
We will discuss this principle a bit more in Chapter 15, Focus on Core Competencies: Build Versus Buy. Although “Buy when non-core” is a cost initiative, it also affects scalability and availability as well as productivity. The basic premise is that regardless of how smart you and your team are, you simply aren’t the best at everything. Furthermore, your shareholders expect you to focus on the things that really create competitive differentiation and, therefore, enhance shareholder value. So build things only when you are really good at it and it makes a significant difference in your product, platform, or system.
Use Commodity Hardware
We often get a lot of pushback on this principle, but it fits in well with the rest of the principles we’ve outlined. It is similar to the principle of using mature technologies. Hardware, especially servers, moves rapidly toward commoditization, a trend characterized by the market buying predominately based on cost. If you can develop your architecture such that you can scale horizontally with ease, you should buy the cheapest hardware you can get your hands on, assuming the cost of ownership for that hardware (including the cost of handling higher failure rates) is lower than the cost for higher-end hardware.
Build Small, Release Small, Fail Fast
Small releases have a lower probability of causing failures because the probability of failure is directly correlated to the number of changes in any given solution. Building small and making fast iterations also helps us understand if and how we need to change course with our product and architectural initiatives before we spend a great deal of money on them. When our initiatives don’t work, the cost of failure is small and we can walk away from an initiative that does not work without great damage to our shareholders. While we can and should think big, we must have a principle that forces us to implement in small and iterative ways.
Isolate Faults
This principle is so important that it has an entire chapter dedicated to it (Chapter 21, Creating Fault-Isolative Architectural Structures). At its heart, it recognizes that while engineers are great at defining how things should work, we often spend too little time thinking about how things should fail. A great example of fault isolation exists in the electrical system of your house or apartment. What happens when your hair dryer draws too many amps? In well-designed homes, a circuit breaker pops, and the power outlets and electrical devices on that circuit cease to function. The circuit typically serves a single area within a location of the house, making troubleshooting relatively easy. One circuit, for example, does not typically serve your refrigerator, a single power outlet in a bathroom, and a light within the living room; rather, it covers contiguous areas. The circuit breaker serves to protect the remainder of the appliances and electrical devices in your house from harm and to keep greater harm from coming to the house.
The principle of isolating faults (i.e., creating fault isolation zones) is analogous to building an electrical system with circuit breakers. Segment your product such that the failure of a service or subservice does not affect multiple other services. Alternatively, segment your customers such that failures for some customers do not affect failures for your customer base in its entirety.
Automation over People
People frequently make mistakes; even more frustratingly, they tend to make the same mistake in different ways multiple times. People are also prone to attention deficiencies that cause them to lose track or interest in menial projects. Finally, while incredibly valuable and crucial to any enterprise, good people are costly.
Automation, by comparison, is comparatively cheap and will always make the same mistakes or have the same successes in exactly the same way each time. As such, it is easy to tune and easy to rely upon automation for simple repetitive tasks. For these reasons, we believe all systems should be built with automation in mind at the beginning. Deployment, builds, testing, monitoring and even alerting should be automated.
Conclusion
In this chapter, we discussed architectural principles and saw how they impact the culture of an organization. Your principles should be aligned with the vision, mission, and goals of your unique organization. They should be developed with your team to create a sense of shared ownership. These principles will serve as the foundation for scalability-focused processes such as the joint architecture design process and the Architecture Review Board.
Key Points
• Principles should be developed from your organization’s goals and aligned to its vision and mission.
• Principles should be broad enough that they are not continually revised, but should also be SMART and thematically bundled or grouped.
• To ensure ownership and acceptance of your principles, consider having your team help develop them.
• Ensure that your team understands the RASCI of principle development and modification.
• Keep your principles to a number that is easily memorized by the team to increase utilization of the principles. We suggest having no more than 15 principles.