
Chapter 21. Creating Fault-Isolative Architectural Structures
The natural formation of the country is the soldier’s best ally.
—Sun Tzu
In the days before full-duplex and 10-gigabit Ethernet, when repeaters and hubs were used within CSMA/CD (carrier sense multiple access with collision detection) networks, collisions among transmissions were common. Collisions reduced the speed and effectiveness of the network, as collided packets would likely not be delivered on their first attempt. Although the Ethernet protocol (then an implementation of CSMA/CD) used collision detection and binary exponential back-off to protect against congestion in such networks, network engineers also developed the practice of segmenting networks to allow for fewer collisions and a faster overall network. This segmentation into multiple collision domains also created a fault-isolative infrastructure wherein a bad or congested network segment would not necessarily propagate its problems to each and every other peer or sibling network segment. With this approach, collisions were reduced, overall speed of delivery in most cases was increased, and failures in any given segment would not bring the entire network down.
Examples of fault isolation exist all around us, including the places where you live and work. Circuit breakers in modern electrical infrastructure (and fuses in older infrastructures) exist to isolate faults and protect the underlying electrical circuit and connected components from damage. This general approach can be applied to not just networks and electrical circuits, but every other component of your product architecture.
Fault-Isolative Architecture Terms
In our practice, we often refer to fault-isolative architectures as swim lanes. We believe this term paints a vivid picture of what we wish to achieve in fault isolation. For swimmers, the swim lane represents both a barrier and a guide. The barrier exists to ensure that the waves that a swimmer produces do not cross over into another lane and interfere with another swimmer. In a race, this helps to ensure that no interference happens to unduly influence the probability that any given swimmer will win the race.
Swim lanes in architecture protect your systems in a similar fashion. Operations of a set of systems within a swim lane are meant to stay within the guide ropes of that swim lane and not cross into the operations of other swim lanes. Furthermore, swim lanes provide guides for architects and engineers who are designing new functionality to help them decide which set of functionality should be placed in which type of swim lane to make progress toward the architectural goal of high scalability.
Swim lane, however, is not the only fault-isolative term used within the technical community. Terms like pod are often used to define fault-isolative domains representing a group of customers or set of functionality. Podding is the act of splitting some set of data and functionality into several groups for fault isolation purposes. Sometimes pods are used to represent groups of services; at other times they are used to represent separation of data. Thinking back to our definition of fault isolation as applied to either components or systems, the separation of data or services alone would be fault isolation at a component level only. Although this has benefits to the overall system, it is not a complete fault isolation domain from a systems perspective and as such only protects you for the component in question.
Shard is yet another term that is often used within the technical community. Most often, it describes a database structure or storage subsystem (or the underlying data as in “shard that data set”). Sharding is the splitting of these systems into failure domains so that the failure of a single shard does not bring the remainder of the system down as a whole. Usually “sharding” is used when considering methods of performing transactions on segmented sets of data in parallel with the purpose of speeding up some computational exercise. This is also sometimes called horizontal partitioning. A storage system consisting of 100 shards may have a single failure that allows the other 99 shards to continue to operate. As with pods, however, this does not mean that the systems addressing those remaining 99 shards will function properly. We will discuss this concept in more detail later in this chapter.
Slivers, chunks, clusters, and pools are also terms with which we have become familiar over time. Slivers is often used as a replacement for shards. Chunks is often used as a synonym for pods. Clusters is sometimes used interchangeably with pools—especially when there is a shared notion of session or state within the pool—but at other times is used to refer to an active–passive high-availability solution. Pools most often references a group of servers that perform similar tasks. This is a fault isolation term but not in the same fashion as swim lanes (as we’ll discuss later). Most often, these are application servers or Web servers performing some portion of functionality for your platform. All of these terms most often represent components of your overall system design, though they can easily be extended to mean the entire system or platform rather than just its subcomponent.
Ultimately, there is no single “right” answer regarding what you should call your fault-isolative architecture. Choose whatever word you like the most or make up your own descriptive word. There is, however, a “right” approach—designing to allow for scale and graceful failure under extremely high demand.
Benefits of Fault Isolation
Fault-isolative architectures offer many benefits within a platform or product. These benefits range from the obvious benefits of increased availability and scalability to the less obvious benefits of decreased time to market and cost of development. Companies find it easier to roll back releases, as we described in Chapter 18, Barrier Conditions and Rollback, and push out new functionality while the site, platform, or product is “live” and serving customers.
Fault Isolation and Availability: Limiting Impact
As the name would seem to imply, fault isolation greatly benefits the availability of your platform or product. Circuit breakers are great examples of fault isolation. When a breaker trips, only a portion of your house is impacted. Similarly, when a fault isolation domain or swim lane fails at the platform or systems architecture level, you lose only the functionality, geography, or set of customers that the swim lane serves. Of course, this assumes that you have architected your swim lane properly and that other swim lanes are not making calls to the swim lane in question. A poor choice of a swim lane in this case can result in no net benefit for your availability, so the architecting of swim lanes becomes very important. To explain this, let’s look at a swim lane architecture that supports high availability and contrast it with a poorly architected swim lane.
Salesforce, a well-known Software as a Service (SaaS) company that is often credited with having coined the term “pods,” was one of AKF Partners’ first clients. Tom Keeven, one of our firm’s managing partners, was a member of the technical advisory board for Salesforce for a number of years. Tom describes the Salesforce architecture as being multitenant, but not all-tenant. Customers (i.e., companies that use the Salesforce service) are segmented into one of many pods of functionality. Each pod comprises a fault-isolated grouping of customers with nearly all of the base functionality and data embedded within that pod to service the customers it supports. Because multiple customers are in a single pod and occupy that pod’s database structure, the solution is multitenant. But because not every customer is in a single database structure for the entire Salesforce solution, it is not “all-tenant.” Figure 21.1 depicts what this architecture might look like. This graphic is not an exact replica of the Salesforce.com architecture, but rather is meant to be illustrative of how Web, application, and database servers are dedicated to customer segments.
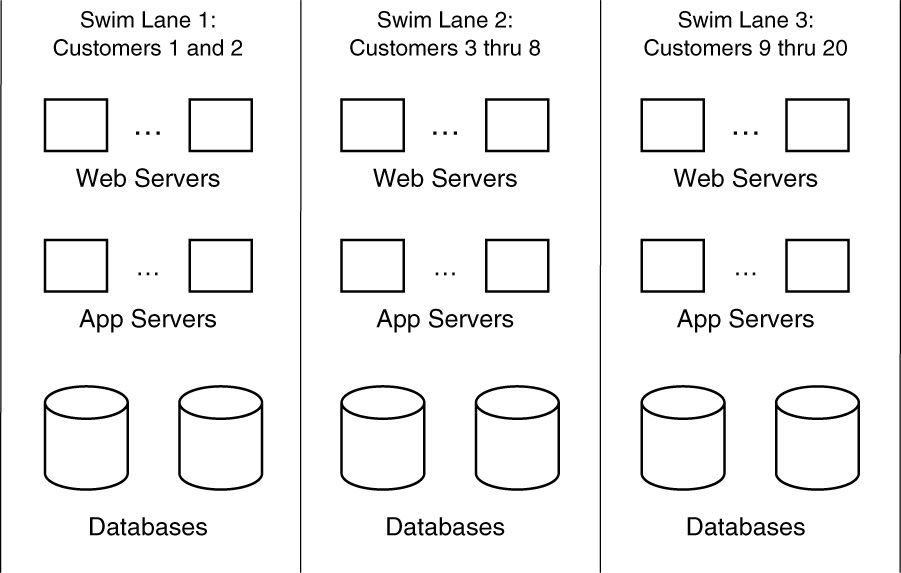
A fault-isolated architecture like that shown in Figure 21.1 gives companies a great deal of choice as to how they operate their solutions. Want to put a swim lane (or pod) in Europe to meet the expectations of European privacy laws? No problem—the segmentation of data allows this to happen easily. Want to spread swim lanes throughout the United States to have faster response time from a U.S. end user’s perspective? Also no problem—each swim lane again is capable of operating independently. Want to create an architecture that allows for easy, risk-free migration to an Infrastructure as a Service (IaaS) offering such as Amazon Web Services (AWS)? The fault-isolated swim lane approach allows you to move one or multiple swim lanes anywhere you would like, with each running on a different underlying infrastructure architecture. An interesting side benefit of these strategies is that should you ever experience a geographically localized event, such as an earthquake, terrorist attack, or data center fire, only the portion of your customers in the pods within that region will be impacted.
Contrast the preceding customer segmentation approach with an approach where fault isolation domains are created on a services level. The Patient Protection and Affordable Care Act (PPACA), often referred to as just the Affordable Care Act (ACA), was signed into law in the United States on March 23, 2010. Shortly there-after, the U.S. government embarked upon an initiative to create a healthcare exchange through which people in the United States could purchase health insurance. The initial architecture created an interrelated mesh of services behind a single portal (Web site) that would serve the needs of most Americans. Shortly after the launch of this site, however, both the government and consumers were surprised with the lack of responsiveness and general nonavailability of the system. AKF Partners was asked to contribute to the troubleshooting to help get this initiative back on track, and as good, nonpartisan Americans we agreed to do so on a pro bono basis.
The Time magazine article “Obama’s Trauma Team” does a great job of laying out all the reasons for the “failure to launch” in the initial go-live of Healthcare.gov. In many respects, it serves as a reason for why we wrote the first edition of this book: The failures were legion. The government initially failed to integrate and manage multiple independent contractors; no single person or entity seemingly was in charge of the entire solution. The government also failed to put into place the processes and management that would oversee the successful operation of the solution post launch. Finally, and most informative for this chapter’s discussion, the government never thought to bring in appropriately experienced architects to design a fault-isolated and scalable solution.1 Healthcare.gov was made up of a number of services, each of which was interrelated and relied upon the others for some number of transactions. Data services were separated from interaction services. The functioning of the system relied on several third-party systems outside the control of the Healthcare.gov team, such as interactions with Veterans Administration services, Social Security services, and credit validation services. Loosely speaking, when one service calls another service and then hangs waiting for a synchronous response, it creates a serial synchronous chain. Such services act similarly to old-fashioned Christmas tree light strings: When one bulb blows, the whole string goes “lights out.” The more bulbs you have in a series, the higher the probability that one of them will blow and cause a complete system failure. This effect is called the “multiplicative effect of failure of systems in series.”
1. Brill, Steven. Obama’s trauma team. Time, February 27, 2014. http://time.com/10228/obamas-trauma-team/.
This is a common fault with many service-oriented designs in general, and with the initial implementation of Healthcare.gov in particular. If services rely on each synchronously, faults will propagate along the synchronous chain. This isn’t an indictment of service-oriented architectures, but rather a warning about how one should think about architecting them. Interacting synchronous services are the opposite of fault isolation—they will, by definition, lower your overall availability.
The Healthcare.gov design team experienced a type of failure common in many engineering organizations: They didn’t ask the question, “How will this solution fail?” Healthcare.gov, upon launch, experienced multiple sources of slowness throughout its environment. Each one ultimately could slow down the entire solution given how the solution components were interrelated.
How could the team have gotten around this problem? The simplest solution would be to create fault isolation zones along state boundaries. The ACA initiative allowed for states to run their own independent exchanges. Connecticut, for example, was one of the first states to successfully implement such an exchange.2 Had the federal system implemented exchanges for each of the states that decided not to implement its own independent exchange, it could have significantly reduced the impact of any failure or slowness of the Healthcare.gov site. Furthermore, it could have put the state exchanges closest to the states they served to significantly reduce customer response times. With this approach, data would have been partitioned to further reduce query times, and overall response times per interaction would have decreased significantly. Scalability would have increased. The overall complexity of the system and difficulty in troubleshooting would have been reduced, leading to improved mean time to restore service and defect resolution times.
2. Cohen, Jeff, and Diane Webber. Healthcare.gov recruits leader of successful Connecticut effort. NPR, August 8, 2014. http://www.npr.org/blogs/health/2014/08/26/343431515/healthcare-gov-recruits-leader-of-successful-connecticut-effort.
We have not offered an example of the Healthcare.gov architecture because of our concerns that doing so may aid people of nefarious intent. As indicated, we do not use Healthcare.gov here to demonstrate that service-oriented isolation approaches should never be used. Quite the contrary—these approaches are an excellent way to isolate code bases, speed time to market through this isolation, and reduce the scalability requirements for caching for action-specific services. But putting such services in series and having them rely on synchronous responses is a recipe for disaster. You can either ensure that the first-order service (the first one to be called before any other service can be used, such as a login) is so highly available and redundant as to minimize the risk, or you can perform multiple splits to further isolate failures.
The first approach—making the service even more highly available—can be accomplished by adding significantly greater capacity than is typically needed. In addition, the incorporation of markdown functionality (see the sidebar “Markdown Logic Revisited” or Chapter 18 for a review) on a per-company basis might help us isolate certain problems.
The second approach—performing multiple splits to isolate failures—is our preferred method of addressing both scalability and availability. If it used this method, Healthcare.gov could have combined the splits of services and splits of customers on a state basis. Using geo-location services, the government could have routed customers to the appropriate state swim lane (the swim lane in which the individual’s data lived). In the event that a customer moved to another state, his or her data could be moved as well. Remember that such an issue exists anyway, as some states decided to implement their own separate exchanges.
We will discuss these types of splits in greater detail in Chapter 22, Introduction to the AKF Scale Cube; Chapter 23, Splitting Applications for Scale; and Chapter 24, Splitting Databases for Scale. In these chapters, we introduce the AKF Scale Cube and explain how to apply it to services, databases, and storage structures.
Fault Isolation and Availability: Incident Detection and Resolution
Fault isolation also increases availability by making incidents easier to detect, identify, and resolve. If you have several swim lanes, each dedicated to a group of customers, and only a single swim lane goes down, you know quite a bit about the failure immediately—it is limited to the swim lane servicing a set of customers. As a result, your questions to resolve the incident are nearly immediately narrowed. More than likely, the issue is a result of systems or services that are servicing that set of customers alone. Maybe it’s a database unique to that customer swim lane. You might ask, “Did we just roll code out to that swim lane or pod?” or more broadly, “What were the most recent changes to that swim lane or pod?”
As the name implies, fault isolation has incredible benefits for incident detection and resolution. Not only does it prevent the incident from propagating throughout your platform, but it also focuses your incident resolution process like a laser and shaves critical time off the restoration of service.
Fault Isolation and Scalability
This is a book on scalability and it should come as no surprise, given that we’ve included it as a topic, that fault isolation somehow benefits your scalability initiatives. The precise means by which fault isolation affects scalability has to do with how you split your services, as we’ll discuss in Chapters 22 through 24, and relates to the architectural principle of scaling out rather than up. The most important thing to remember is that a swim lane must not communicate synchronously with any other swim lane. It can make asynchronous calls with the appropriate timeouts and discard mechanisms to other swim lanes, but you cannot have connection-oriented communication to any other service outside of the swim lane. We’ll discuss how to construct and test swim lanes later in this chapter.
Fault Isolation and Time to Market
Creating architectures that allow you to isolate code into service-oriented or resource-oriented systems gives you the flexibility of focus and the ability to dedicate engineers to those services. For a small company, this approach probably doesn’t make much sense. As the company grows, however, the lines of code, number of servers, and overall complexity of its system will grow. To handle this growth in complexity, you will need to focus your engineering staff. Failing to specialize and focus your staff will result in too many engineers having too little information on the entire system to be effective.
If you run an ecommerce site, you might have code, objects, methods, modules, servers, and databases focused on checkout, finding, comparing, browsing, shipping, inventory management, and so on. By dedicating teams to these areas, each team will become an expert on a code base that is itself complex, challenging, and growing. The resulting specialization will allow for faster new-feature development and a faster time to resolve known or current incidents and problems. Collectively, this increase in speed to delivery may result in a faster time to market for bug fixes, incident resolution, and new-feature development.
Additionally, this isolation of development—and ideally isolation of systems or services—will reduce the merge conflicts that would happen within monolithic systems development. Here, we use the term “monolithic systems development” to identify a source that is shared across all set of functions, objects, procedures, and methods within a given product. Duplicate checkouts for a complex system across many engineers will result in an increase in merge conflicts and errors. Specializing the code and the engineering teams will reduce these conflicts.
This is not to say that code reuse should not be a focus for the organization; it absolutely should be a focus. Develop shared libraries, and consider creating a dedicated team that is responsible for governing their development and usage. These libraries can be implemented as services to services, as shared dynamically loadable libraries, or compiled and/or linked during the build of the product. Our preferred approach is to dedicate shared libraries to a team. In the case where a non-shared-library team develops a useful and potentially sharable component, that component should be moved to the shared-library team. This approach is somewhat analogous to that applied in an open source project, where you use the open source code and share it back with the project and owning organization.
Recognizing that engineers like to continue to be challenged, you might be concerned that engineers will not want to spend a great deal of time on a specific area of your site. You can slowly rotate engineers to ensure all of them obtain a better understanding of the entire system and in so doing stretch and develop them over time. Additionally, through this process, you start to develop potential future architects with a breadth of knowledge regarding your system or fast-reaction SWAT team members who can easily dig into and resolve incidents and problems.
Fault Isolation and Cost
In the same ways and for the same reason that fault isolation reduces time to market, it can also reduce cost. In the isolation by services example, as you get greater throughput for each hour and day spent on a per-engineer basis, your per-unit cost goes down. For instance, if it normally took you 5 engineering days to produce the average story or use case in a complex monolithic system, it might now take you 4.5 engineering days to produce the average story or use-case in a disaggregated system with swim lanes. The average per-unit cost of your engineering endeavors was just reduced by 10%!
You can do one of two things with this per-unit cost reduction, both of which impact net income and as a result shareholder wealth. You might decide to reduce your engineering staff by 10% and produce exactly the same amount of product enhancements, changes, and bug fixes at a lower absolute cost than before. This reduction in cost increases net income without any increase in revenue.
Alternatively, you might decide that you will keep your current cost structure and attempt to develop more products at the same cost. The thought here is that you will make great product choices that increase your revenues. If you are successful, you also increase net income and as a result your shareholders will become wealthier.
You may believe that additional sites usually end up costing more capital than running out of a single site and that operational expenses will increase with a greater number of sites. Although this is true, most companies aspire to have products capable of weathering geographically isolated disasters and invest to varying levels in disaster recovery initiatives that help mitigate the effects of such disasters. As we will discuss in Chapter 32, Planning Data Centers, assuming you have an appropriately fault-isolated architecture, the capital and expenses associated with running three or four properly fault-isolated data centers can be significantly less than the costs associated with running two completely redundant data centers.
Another consideration in justifying fault isolation is the effect that it has on revenue. Referring back to Chapter 6, Relationships, Mindset, and the Business Case, you can attempt to calculate the lost opportunity (lost revenue) over some period of time. Typically, this will be the easily measured loss of a number of transactions on your system added to the future loss of a higher than expected customer departure rate and the resulting reduction in revenue. This loss of current and future revenues can be used to determine if the cost of implementing a fault-isolated architecture is warranted. In our experience, some measure of fault isolation is easily justified through the increase in availability and the resulting decrease in lost opportunity.
How to Approach Fault Isolation
The most fault-isolative systems are those that make absolutely no calls and have no interaction with anything outside of their functional or data boundaries. The best way to envision this situation is to think of a group of lead-lined concrete structures, each with a single door. Each door opens into a long isolated hallway that has a single door at each end; one door accesses the lead-lined concrete structure and one door accesses a shared room with an infinite number of desks and people. In each of these concrete structures is a piece of information that any one individual sitting at the many desks might want. To get that information, he has to travel the long hallway dedicated to the room with the information he needs and then walk back to his desk. After that journey, he may decide to get a second piece of information from the room he just entered, or he might travel down another hallway to another room. It is impossible for a person to cross from one room to the next; he must always make the long journey down the hallway. If too many people get caught up attempting to get to the same room down the same hallway, it will be immediately apparent to everyone in the room; in such a case, they can decide to either travel to another room or simply wait.
In this example, we’ve not only illustrated how to think about fault-isolative design, but also demonstrated two benefits of such a design. The first benefit is that a failure in capacity of the hallway does not keep anyone from moving on to another room. The second benefit is that everyone knows immediately which room has the capacity problem. Contrast this with an example where each of the rooms is connected to a shared hallway and there is only one entrance to this shared hallway from our rather large room. Although each of the rooms is isolated, should people back up into the hallway, it becomes both difficult to determine which room is at fault and impossible to travel to the other rooms. This example also illustrates our first principle of fault-isolative architecture.
Principle 1: Nothing Is Shared
The first principle of fault-isolative design or architecture is that absolutely nothing is shared. Of course, this is the extreme case and may not be financially feasible in some companies, but it is nevertheless the starting point for fault-isolative design. If you want to ensure that capacity or system failure does not cause problems for multiple systems, you need to isolate system components. This may be very difficult in several areas, like border or gateway routers. That said, and recognizing both the financial and technical barriers in some cases, the more thoroughly you apply this principle, the better your results will be.
One often-overlooked area is URIs/URLs. For instance, consider using different subdomains for different groups. If grouping by customers, consider cust1.allscale.com to custN.allscale.com. If grouping by services, consider view.allscale.com, update.allscale.com, input.allscale.com, and so on. The domain grouping ideally should reference isolated Web and app servers as well as databases and storage unique to that URI/URL. If financing allows and demand is appropriate, dedicated load balancers, DNS, and access switches should be used.
If you identify two swim lanes and have them communicate to a shared database, they are really the same swim lane, not two different ones. You may have two smaller fault isolation zones from a service’s perspective (for instance, the application servers), which will help when one application server fails. Should the database fail, however, it will bring down both of these service swim lanes.
Principle 2: Nothing Crosses a Swim Lane Boundary
This is another important principle in designing fault-isolative systems. If you have systems communicating synchronously, they can cause a potential fault. For the purposes of fault isolation, “synchronous” means any transaction that must wait for a response to complete. It is possible, for instance, to have a service use an asynchronous communication method but block waiting for the response to a request. To be asynchronous from a fault isolation perspective, a service must not care about whether it receives a response. The transaction must be “fire and forget” (such as a remote write that can be lost without issue) or “fire and hope.” “Fire and hope” requests follow a pattern of notifying a service that you would like a response and then polling (to some configurable number of times) for a response. The ideal number here is 1 so that you do not create long queue depths of transactions and stall other requests.
Overall, we prefer no communication to happen outside a fault isolation zone and we never allow synchronous communication. Think back to our room analogy: The room and its hallway were the fault isolation zone or domain; the large shared room was the Internet. There was no way to move from one room to the next without traveling back to the area of the desk (our browser) and then starting down another path. As a result, we know exactly where bottlenecks or problems are happening immediately when they occur, and we can figure out how to handle those problems.
Any communication between zones—or paths between rooms in our scenario—can cause problems with our fault isolation. A backup of people in one hallway may be the cause in the hallway connected to that room or any of a series of rooms connected by other hallways. How can we tell easily where the problem lies without a thorough diagnosis? Conversely, a backup in any room may have an unintended effect in some other room; as a result, our room availability goes down.
Principle 3: Transactions Occur Along Swim Lanes
Given the name and the previous principle, this principle should go without saying—but we learned long ago not to assume anything. In technology, assumption is the mother of catastrophe. Have you ever seen swimmers line up facing the length of a pool, but seen the swim lane ropes running widthwise? Of course not, but the competition in the resulting water obstacle course would probably be great fun to watch.
The same is true for technical swim lanes. It is incorrect to say that you’ve created a swim lane of databases, for instance. How would transactions get to the databases? Communication would have to happen across the swim lane, and per Principle 2, that should never happen. In this case, you may well have created a pool, but because transactions cross a line, it is not a swim lane as we define it.
When to Implement Fault Isolation
Fault isolation isn’t free and it’s not necessarily cheap. Although it has a number of benefits, attempting to design every single function of your platform to be fault isolative would likely be cost prohibitive. Moreover, the shareholder return just wouldn’t be there. And that’s the response to the preceding heading. After 20 and a half chapters, you probably can sense where we are going.
You should implement just the right amount of fault isolation in your system to generate a positive shareholder return. “OK, thanks, how about telling me how to do that?” you might ask.
The answer, unfortunately, will depend on your particular needs, the rate of growth and unavailability, the causes of unavailability in your system, customer expectations with respect to availability, contractual availability commitments, and a whole host of things that result in a combinatorial explosion, which make it impossible for us to describe for you precisely what you need to do in your environment.
That said, there are some simple rules to apply to increase your scalability and availability. We present some of the most useful here to help you in your fault isolation endeavors.
Approach 1: Swim Lane the Money-Maker
Whatever you do, always make sure that the thing that is most closely related to making money is appropriately isolated from the failures and demand limitations of other systems. If you are operating a commerce site, this might be your purchase flow from the “buy” button and checkout process through the processing of credit cards. If you are operating a content site and you make your money through proprietary advertising, ensure that the advertising system functions separately from everything else. If you are operating a recurring registration fee–based site, ensure that the processes from registration to billing are appropriately fault isolated.
It stands to reason that you might have some subordinate flows that are closely tied to the money-making functions of your site, and you should consider these for swim lanes as well. For instance, in an ecommerce site, the search and browse functionality might need to be in swim lanes. In content sites, the most heavily trafficked areas might need to be in their own swim lanes or several swim lanes to help with demand and capacity projections. Social networking sites may create swim lanes for the most commonly hit profiles or segment profile utilization by class.
Approach 2: Swim Lane the Biggest Sources of Incidents
If in your recurring quarterly incident review (Chapter 8, Managing Incidents and Problems) you identify that certain components of your site are repeatedly causing other incidents, you should absolutely consider these for future headroom projects (Chapter 11, Determining Headroom for Applications) and isolate these areas. The whole purpose of the quarterly incident review is to learn from past mistakes. Thus, if demand-related issues are causing availability problems on a recurring basis, we should isolate those areas from impacting the rest of our product or platform.
Approach 3: Swim Lane Along Natural Barriers
This is especially useful in multitenant SaaS systems and most often relies upon the z-axis of scale discussed later in Chapters 22 to 24. The sites and platforms needing the greatest scalability often have to rely on segmentation along the z-axis, which is most often implemented on customer boundaries. Although this split is typically first accomplished along the storage or database tier of architecture, it follows that we should create an entire swim lane from request to data storage or database and back.
Very often, multitenant indicates that you are attempting to get cost efficiencies from common utilization. In many cases, this approach means that you can design the system to run one or many “tenants” in a single swim lane. If this is true for your platform, you should make use of it. If a particular tenant is very busy, assign it to a swim lane. A majority of your tenants have very low utilization? Assign them all to a single swim lane. You get the idea.
How to Test Fault-Isolative Designs
The easiest way to test a fault-isolative design is to draw your platform at a high level on a whiteboard. Add dotted lines for any communication between systems, and solid lines indicating where you believe your swim lanes do exist or should exist. Anywhere a dotted line crosses a solid line indicates a violation of a swim lane. From a purist perspective, it does not matter if that communication is synchronous or asynchronous, although synchronous transactions and communications are a more egregious violation from both a scalability and an availability perspective. This test will identify violations of the first and second principles of fault-isolative designs and architectures.
To test the third principle, simply draw an arrow from the user to the last system on your whiteboard. The arrow should not cross any lines for any swim lane; if it does, you have violated the third principle.
Conclusion
In this chapter, we discussed the need for fault-isolative architectures, principles of implementation, approaches for implementation, and finally a design test. We most commonly use swim lanes to identify a completely fault-isolative component of an architecture, although terms like “pods” and “slivers” are often used to mean the same thing.
Fault-isolative designs increase availability by ensuring that subsets of functionality do not diminish the overall functionality of your entire product or platform. They further aid in increasing availability by allowing for immediate detection of the areas causing problems within the system. They lower both time to market and costs by allowing for dedicated, deeply experienced resources to focus on the swim lanes and by reducing merge conflicts and other barriers and costs to rapid development. Scalability is increased by allowing for scale in multiple dimensions as discussed in Chapters 22 through 24.
The principles of swim lane construction address sharing, swim lane boundaries, and swim lane direction. The fewer things that are shared within a swim lane, the more isolative and beneficial that swim lane becomes to both scalability and availability. Swim lane boundaries should never have lines of communication drawn across them. Swim lanes always move in the direction of communication and customer transactions and never across them.
Always address the transactions making the company money first when considering swim lane implementation. Then, move functions causing repetitive problems into swim lanes. Finally, consider the natural layout or topology of the site for opportunities to swim lane, such as customer boundaries in a multitenant SaaS environment.
Key Points
• A swim lane is a fault-isolative architecture construct in which a failure in the swim lane is not propagated and does not affect other platform functionality.
• “Pod,” “shard,” and “chunk” are often used in place of the term “swim lane,” but they may not represent a “full system” view of functionality and fault isolation.
• Fault isolation increases availability and scalability while decreasing time to market and costs of development.
• The less you share in a swim lane, the greater that swim lane’s benefit to availability and scalability.
• No communication or transaction should ever cross a swim lane boundary.
• Swim lanes go in the direction of—and never across—transaction flow.
• Swim lane the functions that directly impact revenue, followed by those that cause the most problems and any natural boundaries that can be defined for your product.