
Chapter 8. Managing Incidents and Problems
Again, if the campaign is protracted, the resources of the State will not be equal to the strain.
—Sun Tzu
Recurring incidents are the enemy of scalability. Recurring incidents steal time away from our teams—time that could be used to create new functionality and greater shareholder value. This chapter considers how to keep incidents from recurring and how to create a learning organization.
Our past performance is the best indicator we have of our future performance, and our past performance is best described by the incidents we have experienced and the underlying problems that caused those incidents. To the extent that we currently have problems scaling our systems to meet end-user demand, or concerns about our ability to scale these systems in the future, our recent incidents and problems are very likely great indications of our current and future limitations. By defining appropriate processes to capture and resolve incidents and processes, we can significantly improve our ability to scale. Failing to recognize and resolve our past problems means failing to learn from our past mistakes in architecture, engineering, and operations. Failing to recognize past mistakes and learn from them with the intent of ensuring that we do not repeat them is disastrous in any field or discipline. For that reason, we’ve dedicated a chapter to incident and problem management.
Throughout this chapter, we will rely upon the United Kingdom’s Office of Government Commerce (OGC) Information Technology Infrastructure Library (ITIL) for definitions of certain words and processes. The ITIL and the Control Objectives for Information and Related Technology (COBIT) created by the Information Systems Audit and Control Association are the two most commonly used frameworks for developing and maturing processes related to managing the software, systems, and organizations within information technology. This chapter is not meant to be a comprehensive review or endorsement of either ITIL or COBIT. Rather, we will summarize some of the most important aspects of the parts of these systems as they relate to managing incidents and their associated problems and identify the portions that you absolutely must have regardless of the size or complexity of your organization or company.
Whether you work at a large company that expects to complete a full implementation of either ITIL or COBIT or a small company that is looking for a fast and lean process to help identify and eliminate recurring scalability-related issues, the following activities are absolutely necessary:
• Recognize the difference between incidents and problems and track them accordingly.
• Follow an incident management life cycle (such as DRIER [identified shortly]) to properly catalog, close, report on, and track incidents.
• Develop a problem management tracking system and life cycle to ensure that you are appropriately closing and reacting to scalability-related problems.
• Implement a daily incident and problem review to support your incident and problem management processes.
• Implement a quarterly incident review to learn from past mistakes and help identify issues repeatedly impacting your ability to scale.
• Implement a robust postmortem process to get to the heart of all problems.
What Is an Incident?
The ITIL definition of an incident is “Any event which is not part of the standard operation of a service and which causes, or may cause, an interruption to, or a reduction in, the quality of that service.” That definition has a bit of “government-speak” in it. Let’s give this term a more easily understood definition: “any event that reduces the quality of our service.”1 An incident here could be a downtime-related event, an event that causes slowness in response time to end users, or an event that causes incorrect or unexpected results to be returned to end users.
1. “ITIL Open Guide: Incident Management.” http://www.itilibrary.org/index.php?page=incident_management.
Issue management, as defined by the ITIL, is “to restore normal operations as quickly as possible with the least possible impact on either the business or the user, at a cost-effective price.” Thus, management of an issue really becomes the management of the impact of the issue. We love this definition and love the approach, because it separates cause from impact. We want to resolve an issue as quickly as possible, but that does not necessarily mean understanding its root cause. Therefore, rapidly resolving an incident is critical to the perception of scale. Once a scalability-related incident occurs, it starts to cause the perception (and, of course, the reality) of a lack of scalability.
Now that we understand that an incident is an unwanted event in our system that affects our availability or service levels and that incident management has to do with the timely and cost-effective resolution of incidents to force the system into the perceived normal behavior, let’s discuss problems and problem management.
What Is a Problem?
The ITIL defines a problem as “the unknown cause of one or more incidents, often identified as a result of multiple similar incidents.” It further defines a “known error” as an identified root cause of a problem. Finally, “The objective of Problem Management is to minimize the impact of problems on the organization.”2
2. “ITIL Open Library.” http://www.itilibrary.org/index.php?page=problem_management.
Again, we can see the purposeful separation of events (incidents) and their causes (problems). This simple separation of definition for incident and problem helps us in our everyday lives by forcing us to think about their resolution differently. If for every incident we attempt to find root cause before restoring service, we will very likely have lower availability than if we separate the restoration of service from the identification of cause. Furthermore, the skills necessary to restore service and manage a system back to proper operation may very well be different from those necessary to identify the root cause of any given incident. If that is the case, serializing the two processes not only wastes engineering time, but also further destroys shareholder value.
For example, assume that a Web site makes use of a monolithic database structure and is unavailable in the event that the database fails. This Web site has a database failure where the database simply crashes and all processes running the database die during its peak traffic period from 11 a.m. to 1 p.m. One very conservative approach to this problem might be to say that you never restart your database until you know why it failed. Making this determination could take hours and maybe even days while you go through log and core files and bring in your database vendor to help you analyze everything. The intent behind this approach is obvious—you don’t want to cause any data corruption when you restart the database.
In reality, most databases these days can recover from nearly any crash without significant data hazards. A quick examination could tell you that no processes are running, that you have several core and log files, and that a restart of the database might actually help you understand which type of problem you are experiencing. Perhaps you can start up the database and run a few quick “health checks,” like the insertion and updating of some dummy data to verify that things are likely to work well, and then put the database back into service. Obviously, this approach, assuming the database will restart, is likely to result in less downtime associated with scalability-related events than serializing the management of the problem (identifying the root cause) and the management of the incident (restoration of service).
We’ve just highlighted a very real conflict between these two processes that we’ll address later in this chapter. Specifically, incident management (the restoration of service) and problem management (the identification and resolution of the root cause) are often in conflict with each other. The rapid restoration of service often conflicts with the forensic data gathering necessary for problem management. Perhaps the restart of servers or services really will cause the destruction of critical data. We’ll discuss how to handle this situation later. For now, recognize that there is a benefit in thinking about the differences in actions necessary for the restoration of service and the resolution of problems.
The Components of Incident Management
The ITIL defines the activities essential to the incident management process as follows:
• Incident detection and recording
• Classification and initial support
• Investigation and diagnosis
• Resolution and recovery
• Incident closure
• Incident ownership, monitoring, tracking, and communication
Implicit in this list is an ordering such that nothing can happen before incident detection, classification comes before investigation and diagnosis, resolution and recovery must happen only after initial investigation, and so on. We completely agree with this list of necessary actions. However, if your organization is not strictly governed by the OGC and you do not require any OGC-related certification, there are some simple changes you can make to this order that will accelerate issue recovery. First, we wish to create our own simplified definitions of the preceding activities.
Incident detection and recording is the activity of identifying that an incident is affecting users or the operation of the system and then recording it. Both elements are very important, and many companies have quite a bit they can do to make both actions better and faster. Incident detection is all about monitoring your systems. Do you have customer experience monitors in place to identify problems before the first customer complaint arrives? Do they measure the same things customers do? In our experience, it is very important to perform actual customer transactions within your system and measure them over time both for the expected results (are they returning the right data?) and for the expected response times (are they operating as quickly as you would expect?).
Note that our first step here is not just issue identification but also the recording of the issues. Many companies that correctly identify issues don’t immediately record them before taking other actions or don’t have systems implemented that will record the problems. The best approach is to have an automated system that will immediately record the issue and its timestamp, leaving operators free to handle the rest of the process.
The ITIL identifies classification and initial support as the next step, but we believe that in many companies this can really just be the step of “getting the right people involved.” Classification is an activity that can happen in hindsight in our estimation—after the issue is resolved.
Investigation and diagnosis is followed by resolution and recovery. Put simply, these activities identify what has failed and then take the appropriate steps to put that service back into proper working order. As an example, they might determine that application server #5 is not responding (investigation and diagnosis), at which point we immediately attempt a reboot (a resolution step) and the system recovers (recovery).
Incident closure is the logging of all information associated with the incident. The final steps include assigning an owner for follow-up, communication, tracking, and monitoring.
We often recommend an easily remembered acronym when implementing incident management (see Figure 8.1). Our acronym supports ITIL implementations and for smaller companies can be adopted with or without an ITIL implementation. This acronym, DRIER, stands for
• Detect an incident through monitoring or customer contact.
• Report the incident, or log it into the system responsible for tracking all incidents, failures, or other events.
• Investigate the incident to determine what should be done.
• Escalate the incident if it is not resolved in a timely fashion.
• Resolve the incident by restoring end-user functionality and log all information for follow-up.
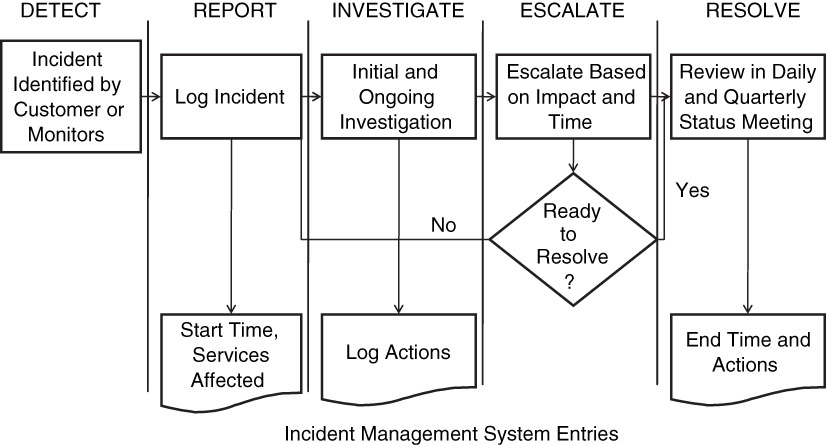
In developing DRIER, we’ve attempted to make it easier for our clients to understand how issue management can be effectively implemented. Note that although we’ve removed the classification of issues from our acronym, we still expect that these activities will be performed to develop data from the system and help inform other processes. We recommend that the classification of issues happen within the daily incident management meeting (discussed later in this chapter).
The Components of Problem Management
The ITIL-defined components of problem management are a little more difficult to navigate than those for incident management. The ITIL definitions define a number of processes that control other processes. For anything but a large organization, this can be a bit cumbersome. This section attempts to boil these processes down to something more manageable. Remember that problems are the causes of incidents and are likely culprits for a large number of scalability problems.
Problems in our model start concurrently with an issue and last until the root cause of an incident is identified. As such, most problems last longer than most incidents. A problem can be the cause of many incidents.
Just as with incidents, we need a type of workflow that supports our problem resolutions. We need a system or place to keep all of the open problems and to ensure that they can be associated with the incidents they cause. We also need to track these problems to closure. Our reasoning underlying this definition of “closure” is that a problem exists until it no longer causes incidents.
Problems vary in size. Small problems can be handed to a single person. When they are ready for closure, validation is done in QA and by meeting the required testing criteria. A problem is then confirmed as closed by the appropriate management or owner of the system experiencing the incidents and problems. Larger problems are more complex and need specialized processes to help ensure their rapid resolution. A large problem may be the subject of a postmortem (described later in this chapter), which in turn will drive additional investigative or resolution action items to individuals. The outcome of these action items should be reviewed on a periodic basis by one of the following methods: (1) a dedicated team of project managers responsible for problem resolution, (2) a manager with responsibility for tracking problem resolution, or (3) within the confines of a meeting dedicated to handling incident tracking and problem resolution, such as our recommended daily incident meeting.
Resolving Conflicts Between Incident and Problem Management
We previously mentioned an obvious and very real tension between incident management and problem management. Very often, the actions necessary to restore a system to service will potentially destroy evidence necessary to determine the root cause (problem resolution). Our experience is that incident resolution (the restoration of service) should always trump root cause identification unless an incident will continue to have a high frequency of recurrence without root cause and problem resolution.
That said, we also believe it is important to think through your approach and protocol before you face the unenviable position of needing to make calls on when to restore service and when to continue root cause analysis. We have some suggestions:
• Determine what needs to be collected by the system before system restoration.
• Determine how long you are willing to collect diagnostic information before restoration.
• Determine how many times you will allow a system to fail before you require root cause analysis to be more important than system restoration.
• Determine who should make the decision as to when systems should be restored if there is a conflict (who is the R and who is the A).
In some instances, due to a lack of forensic data, the problem management process may not yield a clear set of root causes. In these cases, it is wise to make the preceding determinations for that incident and ensure you clearly identify all of the people who should be involved, if the incident reoccurs, to capture better diagnostics more quickly.
Incident and Problem Life Cycles
There is an implied life cycle and relationship between incidents and problems. An incident is open or ongoing until the system is restored. This restoration of the system may cause the incident to be closed in some life cycles, or it may move the incident to “resolved” status in other life cycles. Problems are related to incidents and are likely opened at the time that an incident happens, potentially “resolved” after the root cause is determined, and “closed” after the problem is corrected and verified within the production environment. Depending on your particular approach, incidents might be closed after service is restored, or several incidents associated with a single problem might not be finally closed until their associated problems are fixed.
Regardless of which words you associate with stages in the life cycles, we often recommend the following simple phases be tracked to collect good data about incidents, problems, and their production costs:
Incident Life Cycle
Open Upon an incident or when an event happens in production
Resolved When service is restored
Closed When the associated problems have been closed in production
Problem Life Cycle
Open When associated to an incident
Identified When a root cause of the problem is known
Closed When the problem has been “fixed” in production and verified
Our approach here is intended to ensure that incidents remain open until the problems that cause them have their root causes identified and fixed in the production environment. Note that these life cycles don’t address the other data we would like to see associated with incidents and problems, such as the classifications we suggest adding in the daily incident meeting.
We recommend against reopening incidents, as doing so makes it more difficult to query your incident tracking system to identify how often an incident reoccurs. That said, having a way to “reopen” a problem is useful as long as you can determine how often you take this step. Having a problem reoccur after it was thought to be closed is an indication that you are not truly finding its root cause and is an important data point to any organization. Consistent failure to correctly identify the root cause results in continued incidents and is disastrous to your scalability initiatives, because it steals valuable time away from your organization. Ongoing fruitless searches for root causes lead to repeated failures for your customers, dilute shareholder wealth, and stymie all other initiatives having to do with high availability and quality of service for your end users.
Implementing the Daily Incident Meeting
The daily incident meeting (also called the daily incident management meeting) is a meeting and process we encourage all of our clients to adopt as quickly as possible. This meeting occurs daily in most high-transaction, rapid-growth companies and serves to tie together the incident management process and the problem management process.
During this meeting, all incidents from the previous day are reviewed to assign ownership of problem management to an individual, or if necessary to a group. The frequency with which a problem occurs and its resulting impact serve to prioritize the problems to be subjected to root cause analysis and fixed. We recommend that incidents be given classifications meaningful to the company within this meeting. Such classifications may take into account severity, systems affected, customers affected, and so on. Ultimately, the classification system employed should be meaningful in future reviews of incidents to determine impact and areas of the system causing the company the greatest pain. This last point is especially important to identify scalability-related issues throughout the system.
Additionally, the open problems are reviewed. Open problems are problems associated with incidents that may be in the open or identified state but not completely closed (i.e., the problem has not been put through root cause analysis and fixed in the production environment). The problems are reviewed to ensure that they are prioritized appropriately, that progress is being made in identifying their causes, and that no help is required by the owners assigned the problems. It may not be possible to review all problems in a single day; if that is the case, a rotating review of problems should start with the highest-priority problems (those with the greatest impact) being reviewed most frequently. Problems should also be classified in a manner consistent with business need and indicative of the type of problem (e.g., internal versus vendor related), subsystem (e.g., storage, server, database, login application, buying application), and type of impact (e.g., scalability, availability, response time). This last classification is especially important if the organization is to be able to pull out meaningful data to help inform its scale efforts in processes. Problems should inherit the impact determined by their incidents, including the aggregate downtime, response time issues, and so on.
Let’s pause to review the workflow we’ve discussed thus far in this section. We’ve identified the need to associate incidents with systems and other classifications, the need to associate problems with incidents and still more classifications, and the need to review data over time. Furthermore, owners should be assigned to problems and potentially to incidents, and status needs to be maintained for everything until closed. Most readers have probably figured out that a system to aid in this collection of information would be really useful. Most open source and third-party “problem ticketing” solutions offer a majority of this functionality enabled with some small configuration right out of the box. We don’t think you should wait to implement an incident management process, a problem management process, and a daily meeting until you have a tracking system. However, it will certainly help if you put a tracking system in place shortly after the implementation of these processes.
Implementing the Quarterly Incident Review
No set of incident and problem management processes would be complete without a process for reviewing their effectiveness and ensuring that they are successful in eliminating recurring incidents and problems.
In the “Incident and Problem Life Cycles” section, we mentioned that you may find yourself incorrectly identifying root causes for some problems. This is almost guaranteed to happen to you at some point, and you need to have a way for determining when it is happening. Is the same person incorrectly identifying the root causes? This failure may require coaching of the individual, a change in the person’s responsibilities, or removal of the person from the organization. Is the same subsystem consistently being misdiagnosed? If so, perhaps you have insufficient training or documentation on how the system really behaves. Are you consistently having problems with a single partner or vendor? If so, you might need to implement a vendor scorecard process or give the vendor other performance-related feedback.
Additionally, to ensure that your scalability efforts are applied to the right systems, you need to review past system performance and evaluate the frequency and impact of past events on a per-system or per-subsystem basis. This evaluation helps to inform the prioritization for future architectural work and becomes an input to processes such as the headroom process or 10× process that we describe in Chapter 11, Determining Headroom for Applications.
The output of the quarterly incident review also provides the data that you need to define the business case for scalability investments, as described in Chapter 6, Relationships, Mindset, and the Business Case. Showing the business leaders where you will put your effort and why, prioritized by impact, is a powerful persuasive tool when you are seeking to secure the resources necessary to run your systems and maximize shareholder wealth. Furthermore, using that data to paint the story of how your efforts are resulting in fewer scalability-associated outages and response time issues will make the case that past investments are paying dividends and helps give you the credibility you need to continue doing a good job.
The Postmortem Process
Earlier in this chapter, we noted that some large problems require a special approach to help resolve them. Most often, these large problems will require a cross-functional brainstorming meeting, often referred to as a postmortem or after-action review meeting. Although the postmortem meeting is valuable in helping to identify root causes for a problem, if run properly, it can also assist in identifying issues related to process and training. It should not be used as a forum for finger pointing.
The first step in developing a postmortem process is to determine the size of incident or group of incidents for which a postmortem should be required. Although postmortems are very useful, they take multiple people away from their assigned tasks and put them on the special duty of helping to determine what failed and what can work better within a system, process, or organization. To get the most out of these meetings, you must make sure you are maximizing the participants’ time and learning everything possible from the incident. In terms of the metrics and measurements discussed in Chapter 5, Management 101, the assignment of people to postmortem duty reduces the engineering efficiency metric, as these individuals would be spending hours away from their responsibilities of creating product and scaling systems.
The attendees of the postmortem should consist of a cross-functional team from software engineering, systems administration, database administration, network engineering, operations, and all other technical organizations that could have valuable input, such as capacity planning. A manager who is trained in facilitating meetings and also has some technical background should be assigned to run the meeting.
The input to the postmortem process comprises a timeline that includes data and timestamps leading up to the end-user incident, the time of the actual customer incident, all times and actions taken during the incident, and everything that happened up until the time of the postmortem. Ideally, all actions and their associated timestamps will have been logged in a system during the restoration of the service, and all post-incident actions will have been logged either in the same system or in other places to cover what has been done to collect diagnostics and fix the root cause. Logs should be parsed to grab all meaningful data leading up to the incidents with timestamps associated to the collected data. Figure 8.2 introduces the process that the team should cover during the postmortem meeting.
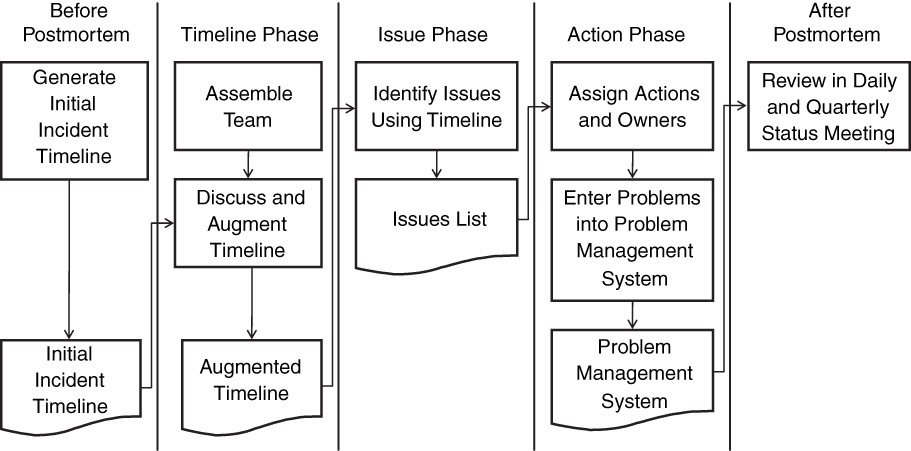
In the first step in the postmortem process, which we call the Timeline Phase, the participants review the initial timeline and ensure that it is complete. Attendees of the postmortem might identify that critical dates, times, and actions are missing. For instance, the team might notice that an alert from an application was thrown and not acted upon two hours before the first item identified in the initial incident timeline. Note that during this phase of the process, only times, actions, and events should be recorded; no problems or issues should be identified or debated.
The next step in the postmortem meeting—the Issue Phase—examines the timeline and identifies issues, mistakes, problems, or areas where additional data would be useful. Each of these areas is logged as an issue, but no discussion over what should happen to fix the issue happens until the entire timeline is discussed and all of the issues are identified. During this phase, the facilitator of the meeting needs to create an environment in which participants are encouraged to voice all ideas and concerns over what might be issues without concern for retribution or retaliation. The facilitator should also ensure that no reference to ownership is made. For instance, it is inappropriate in a postmortem to say, “John ran the wrong command there.” Instead, the reference should be “At 10:12 a.m., command A was incorrectly issued.” Management can address individual accountability later if someone is found to have violated company policy, repeatedly makes the same mistake, or simply needs some coaching. The postmortem is not meant to be a public flogging of an individual. In fact, if it is used as such a forum, the efficacy of the process will be destroyed.
After a first run through the timeline is made and an issues list generated, a second pass through the timeline should be made with an eye toward determining whether actions were taken in a timely manner. For instance, suppose a system starts to exhibit high CPU utilization at 10 a.m. and no action is taken. At noon, customers start to complain about slow response times. A second pass through the timeline might result in someone noting that the early indication of CPU might be correlated with slow response times later and an issue generated in regard to this relationship.
After a complete list of issues is generated from at least one pass (and preferably two passes) through the timeline, we are ready to begin the Action Phase—that is, the creation of the task list. The task list is generated from the issues list, with at least one task identified for each issue. If the team cannot agree on a specific action to fix some issue, an analysis task can be created to identify additional tasks to solve the issue.
We strongly believe that there are always multiple root causes for an incident. The emphasis here is on the word “multiple.” Put another way, no incident is ever triggered by a single cause. We encourage our clients to have strict exit criteria on postmortems that include tasks to address people, process, and technology causes for any incident. Furthermore, we recommend that tasks be associated with minimization of time to detect the incident, time to resolve the incident, ways to keep the incident from occurring, and ways to minimize the risk of the incident.
By following this postmortem process and paying attention to our desired outcomes of having tasks associated with people, process, and technology, we might come up with a list of issues that looks something like this:
• People/Time to Resolve: Team unaware of the load balancer’s capability to detect failures and remove the app server from rotation.
• People/Time to Resolve: Outage extended because the on-call engineer was not available or did not answer the alert.
• Process/Time to Resolve: Network Operations Center personnel did not have access or training to remove the failed app server from the load balancer upon failure of the app server.
• Technology/Ability to Avoid: Load balancer did not have a test to determine the health of the app server and remove it from rotation.
• Technology/Time to Detect: Alerts for a failed ping test on the app server did not immediately show up in Network Operations Center.
• Technology/Ability to Avoid: Single drive failure in the app server should not result in app server failure.
After the task list is created, owners should be assigned for each task. Where necessary, use the RASCI methodology to clearly identify who is responsible for completing each task, who is the approver of each task, and so on. Also use the SMART criteria when defining the tasks, making them specific, measurable, aggressive/attainable, realistic, and timely. Although initially intended for goals, the SMART acronym can also help ensure that we put time limits on our tasks. Ideally, these items will be logged into a problem management system or database for future follow-up.
Putting It All Together
Collectively, the components of issue management, process management, the daily incident management meeting, and the quarterly incident review, plus a well-defined postmortem process and a system to track and report on all systems and problems, will give us a good foundation for identifying, reporting, prioritizing, and taking action to address past scalability issues.
Any given incident will follow the DRIER process of detecting the issue, reporting on the issue, investigating the issue, escalating the issue, and resolving the issue. The issue is immediately entered into a system developed to track incidents and problems. Investigation leads to a set of immediate actions, and if help is needed, we escalate the situation according to our escalation processes. Resolving the issue changes the issue status to “resolved” but does not close the incident until its root cause is identified and fixed within our production environment.
The problem is assigned to an individual or organization during the daily status review unless it is of such severity that it needs immediate assignment. During that daily review, we also review incidents and their status from the previous day and the high-priority problems that remain open in the system. In addition, we validate the closure of problems and assign categories for both incidents and problems in the daily meeting.
Problems, when assigned, are worked by the team or individual assigned to them in priority order. After root causes are determined, the problem moves to “identified” status; when fixed and validated in production, it is designated as “closed.” Large problems go through a well-defined postmortem process that focuses on identifying all possible issues within the process and technology stacks. Problems are tracked within the same system and reviewed in the daily meeting.
On a quarterly basis, we review incidents and problems to determine whether our processes are correctly closing problems and to determine the most common occurrences of incidents. This data is collected and used to prioritize architectural, organizational, and process changes to aid in our mission of increasing scalability. Additional data is collected to determine where we are doing well in reducing scale-related problems and to help create the business case for scale initiatives.
Conclusion
One of the most important processes within any technology organization is the process of resolving, tracking, and reporting on incidents and problems. Incident resolution and problem management should be envisioned as two separate and sometimes competing processes. In addition, some sort of system is needed to help manage the relationships and the data associated with these processes.
A few simple meetings can help meld the incident and problem management processes. The daily incident management meeting helps the organization manage incident and problem resolution and status, whereas the quarterly incident review helps team members create a continual process improvement cycle. Finally, supportive processes such as the postmortem process can help drive major problem resolution.
Key Points
• Incidents are issues in the production environment. Incident management is the process focused on timely and cost-effective restoration of service in the production environment.
• Problems are the cause of incidents. Problem management is the process focused on determining root cause of and correcting problems.
• Incidents can be managed using the acronym DRIER, which stands for detect, report, investigate, escalate, and resolve.
• There is a natural tension between incident and problem management. Rapid restoration of service may cause some forensic information to be lost that would otherwise be useful in problem management. Thinking through how much time should be allowed to collect data and which data should be collected will help ease this tension for any given incident.
• Incidents and problems should have defined life cycles. For example, an incident may be opened, resolved, and closed, whereas a problem may be open, identified, and closed.
• A daily incident meeting should be organized to review incidents and problem status, assign owners, and assign meaningful business categorizations.
• A quarterly incident review is an opportunity to look back at past incidents and problems so as to validate proper first-time closure of problems and thematically analyze both problems and incidents to help prioritize scalability-related architecture, process, and organization work.
• The postmortem process is a brainstorming process used for large incidents and problems to help drive their closure and identify supporting tasks.
• Postmortems should always focus on the identification of multiple causes (problems) for any incident. These causes may address all dimensions of the product development process: people, process, and technology. Ideally, the output of the postmortem will identify how to avoid such an incident in the future, how to detect the incident more quickly, and how to drive to incident resolution faster.