
Overview
In this chapter, you will learn more flexible ways to work with collections. When the problem you need to solve does not fit the patterns that we've looked at so far. We will also use doseq for loops with side effects and see how you can avoid writing some loops by using specialized repetition functions such as repeat and iterate. You will use recur for recursive looping and identify when this is possible, work with the loop macro, and solve complex problems with recursion.
By the end of this chapter, you will be able to implement different aspects of recursion and see how they can replace traditional loops.
Introduction
Data in our programs doesn't always take the nice, linear form for which functions such as map or reduce are particularly adapted. None of the techniques we've discussed in the last two chapters will work for traversing non-linear structures such as trees or graphs. And while it's possible to do a lot by being creative with reduce, the strong guard rails that reduce provides can sometimes get in the way of writing expressive code. There are situations that call for tools that give the programmer more control. Clojure has other resources for these kinds of problems and that is what we are going to look at in this chapter.
Recursion plays a major role when functions such as map and reduce are no longer adapted to the task at hand. Thinking recursively is an important Clojure skill to learn. Because functional programming languages tend to emphasize recursion, this might seem unfamiliar if your background is in more procedural languages. Most programming languages do actually support recursion, so the concept is not necessarily that foreign. Additionally, some of the things that we have already done with reduce are actually recursive, so even if you've never used recursion very much before, the learning curve should not be that steep.
Having said that, there are some aspects of recursion that may require you to think in new ways if you do not have much experience with functional programming. Compared to map and filter, or even reduce, recursive approaches are far more flexible. And by "flexible," we mean powerful but easy to get wrong. When trying to get a recursive function to do just what we want, we make mistakes and end up in infinite loops, blowing the call stack (we'll discuss what that means shortly) or getting other kinds of errors that would simply not be possible otherwise. This is why "looping," whether it's with the loop macro or with recursive functions, should always be what you turn to when the other options just won't work.
Clojure's Most Procedural Loop: doseq
Before we get started with recursion, let's take a look at the doseq macro. It is arguably the most procedural of Clojure's looping alternatives. At least, it looks a lot like the foreach loop found in other languages. Here's a very simple use of doseq:
user> (doseq [n (range 5)]
(println (str "Line " n)))
Line 0
Line 1
Line 2
Line 3
Line 4
nil
Translated into English, we might say: "For each integer from 0 to 5, print out a string with the word 'Line' and the integer." You might ask: "What is that nil doing there?" Good question. doseq always returns nil. In other words, doseq doesn't collect anything. The sole purpose of doseq is to perform side effects, such as printing to the REPL, which is what println does here. The strings that appear in your REPL—Line 0, Line 1, and so on—are not returned values; they are side effects.
Note
In Clojure, like in many languages in the Lisp family, functions that produce side effects often have names that end with an exclamation point. While it's not a firm rule, this convention does make code easier to read and helps to remind us to be careful of side effects. Clojure developers often use an exclamation point to indicate that a function modifies a mutable data structure, writes to a file or a database, or performs any kind of operation that produces a lasting effect outside the scope of the function.
So, why not just use map? Well, there are a couple of good reasons. The first is that map does not guarantee that the entire sequence will be executed. The map function is lazy, and doseq is not.
Generally, with map, filter, reduce, and all the other sequence-manipulating functions, you should always try to use pure functions, that is, functions without side effects. The exception to this rule is debugging, in which case a carefully placed println statement can be a lifesaver. (Remember, though, that println returns nil, so you have to be careful not to place it at the end of a function where it would mask the return value). With sequential data of some sort, it's important to use doseq when you want to produce side effects, and only then. By being strict about this, you also make your code easier to read and maintain. doseq is a flag in your source code that says: "Be careful, there are side effects here!" It is also a clear signal that we are not interested in the return value, since doseq always returns nil. This practice encourages developers to isolate code with side effects in specific parts of a program.
But what if we only wanted to print something on odd-numbered lines in the previous example? Here's one way we could do that:
(doseq [n (range 5)]
(when (odd? n)
(println (str "Line " n))))
There is nothing wrong with this code per se. As a general rule, though, it would be preferable to remove as much logic as possible from the body of doseq, perhaps doing something like this:
(doseq [n (filter odd? (range 5))]
(println (str "Line " n)))
By enforcing the separation between the place where we shape our data and the place where the data is consumed, not only have we removed a conditional, but we've also organized our code in a way that opens the door to better practices. Maybe in the future, we will need to choose differently which lines to print. If that happens, our code is already in the right place, written in the clear vocabulary of Clojure sequence handling, and possibly benefiting from lazy evaluation. Remember: shape the data, and then use the data.
Looping Shortcuts
Generally, it is best to avoid writing real loops. Clojure provides some interesting functions that can help in some simple cases where what you really want is just a repetition of some kind. Unlike most of the techniques in this chapter, these functions return lazy sequences. We mention them here because many times, when a loop might seem necessary at first, these functions provide a simpler solution.
The simplest possible example is the repeat function, which is so simple that it barely qualifies as a looping construct. However, it can still come in handy from time to time. repeat simply repeats whatever value it is called with, returning a lazy sequence of that value. Here's an easy way to repeat yourself:
user> (take 5 (repeat "myself"))
("myself" "myself" "myself" "myself" "myself")
Yes, it's that simple. Still, it can be useful if you need to quickly load default values into a map. Imagine a game where each player is represented by a map. You need to initialize the player with default values for various counters and most of them have a default of 0. One way to do this is to use repeat. Since repeat returns a lazy sequence, it will supply just as many zeros as you need:
user> (zipmap [:score :hits :friends :level :energy :boost] (repeat 0))
{:score 0, :hits 0, :friends 0, :level 0, :energy 0, :boost 0}
The next step beyond repeat is the repeatedly function. Instead of taking a value, repeatedly takes a function and returns a lazy sequence of calls to that function. The function provided to repeatedly cannot take any arguments, which limits its usefulness to impure functions, that is, functions whose return values do not depend on inputs, perhaps consulting some kind of external data store or sensor. Otherwise, if the function always returned the same value, repeatedly would return a list of identical values just like repeat.
Probably the most common use of repeatedly is producing a sequence of random values. A call to rand-int potentially varies every time we call it (unless, of course, you call (rand-int 1), which can only ever return 0.) Here's a good way of producing a list of random integers from 0 to 100, where repeatedly simply calls rand-int 10 times. The output from rand-int is different nearly every time it's called, so the resulting sequence is a series of random integers:
user> (take 10 (repeatedly (partial rand-int 100)))
(21 52 38 59 86 73 53 53 60 90)
As a convenience, repeatedly can take an integer argument that limits the number of values returned. We could write the previous expression without calling take, like this:
user> (repeatedly 10 (partial rand-int 100))
(55 0 65 34 64 19 21 63 25 94)
In the next exercise, we'll try a more complex scenario using repeatedly to generate random test data.
The next step beyond repeatedly is a function called iterate. Like repeatedly, iterate calls a function over and over again, returning the resulting lazy sequence. Unlike repeatedly, though, the function provided to iterate takes arguments, and the result of each call is passed on to the next iteration.
Let's say we have a bank account that returns an annual rate of 1% and we want to project what the balance will be each month for the next year. We could write a function like this:
user> (defn savings [principal yearly-rate]
(let [monthly-rate (+ 1 (/ yearly-rate 12))]
(iterate (fn [p] (* p monthly-rate)) principal)))
To predict the balances over the next 12 months, we have will ask for 13 months, since the first value returned is the starting balance:
user> (take 13 (savings 1000 0.01))
(1000
1000.8333333333333
1001.667361111111
1002.5020839120368
1003.3375023152968
1004.1736169005594
1005.0104282479765
1005.847936938183
1006.6861435522981
1007.5250486719249
1008.3646528791514
1009.2049567565506
1010.045960887181)
By compounding the interest every month, you have already earned almost 5 cents more than the annual rate!
Functions such as repeatedly and iterate can be used in very specific situations where they perfectly match what you need. The real world is often just a little bit more complicated though. Sometimes, the task at hand will require writing customized ways of moving through your data. It's time to move on to recursion.
Exercise 6.01: An Endless Stream of Groceries
Your employer is building a system to automatically handle groceries coming down a conveyor belt. As part of their research, they want you to build a simulator. The goal is to have an endless stream of random groceries. Your job is to write a function to do this:
- Create a new directory in a convenient place; add a deps.edn file containing just an empty map and start a new REPL.
- Open a new file with an expressive name such as groceries.clj and include the corresponding namespace declaration:
(ns groceries)
Before we start, we need to build our grocery store simulator. The first step is to define all the possible articles. (This store doesn't offer a lot of choices, but at least it has them in infinite supply.) Copy the grocery-articles variable from https://packt.live/2tuSvd1 into your REPL and evaluate it:
grocery_store.clj
3 (def grocery-articles [{:name "Flour"
4 :weight 1000 ; grams
5 :max-dimension 140 ; millimeters
6 }
7 {:name "Bread"
8 :weight 350
9 :max-dimension 250}
10 {:name "Potatoes"
11 :weight 2500
12 :max-dimension 340}
13 {:name "Pepper"
14 :weight 85
15 :max-dimension 90}
The full file is available at https://packt.live/35r3Xng.
- Define a function that will return long lists of randomly ordered grocery articles:
(defn article-stream [n]
(repeatedly n #(rand-nth grocery-articles)))
rand-nth returns a randomly selected item from grocery-articles each time it is called. repeatedly creates a lazy sequence of calls to rand-nth. The n argument tells repeatedly how many random articles to return.
- Test the function by asking for some articles:
groceries> (article-stream 12)
({:name "Olive oil", :weight 400, :max-dimension 280}
{:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Green beans", :weight 300, :max-dimension 120}
{:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Flour", :weight 1000, :max-dimension 140}
{:name "Ice cream", :weight 450, :max-dimension 200}
{:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Green beans", :weight 300, :max-dimension 120}
{:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Ice cream", :weight 450, :max-dimension 200}
{:name "Pepper", :weight 85, :max-dimension 90}
{:name "Bread", :weight 350, :max-dimension 250})
- Try again to make sure that the results are random:
groceries> (article-stream 5)
({:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Green beans", :weight 300, :max-dimension 120}
{:name "Bread", :weight 350, :max-dimension 250}
{:name "Olive oil", :weight 400, :max-dimension 280}
{:name "Pepper", :weight 85, :max-dimension 90})
It seems to work. This shows how functions can be combined in cases where, in other languages, it might seem more natural to write a for loop. In JavaScript once again, we might write a function like this (assuming that groceryArticles is an array of objects):
function randomArticles (groceryArticles, n) {
var articles = [];
for (var i = 0; i < n.length; i++) {
articles.push(
groceryArticles[Math.random(groceryArticles.length – 1)]
);
}
return articles;
}
A function such as repeatedly provides a concise way to express this and saves us the trouble of writing all this iterative logic.
Recursion at Its Simplest
As we said before, a recursive function is a function that, as part of its execution, calls itself. Visually, recursion can be imagined as something like one of those pictures you've probably seen, where, inside the main picture, there is a smaller version of the original picture. Since the second picture is identical to the first, it also contains a very small, third version of the picture. After that, any further pictures are usually hard to represent as something bigger than a tiny dot. However, even if we can't see them, we can imagine the process going on for basically forever… or at least down to the molecular level. Recursion works in a similar way. And the problem of a recursive process that just keeps going on and on, like in the picture, is also a very real issue. However, before we look at the pitfalls of recursion, let's take a look at some simple examples.
To start out, we'll do something you already know how to do: find the sum of a collection of numbers. In real life, you would never use recursion for this, but the problem is deliberately simple so that we can point out some of the mechanisms of recursion:
(defn recursive-sum [so-far numbers]
(if (first numbers)
(recursive-sum
(+ so-far (first numbers))
(next numbers))
so-far))
A call to this function would look like this:
user> (recursive-sum 0 [300 25 8])
333
This probably looks familiar to you because this is quite similar to the functions we passed to reduce. This isn't too surprising. We could even think of reduce as a framework for "controlled recursion," or "recursion with guardrails," which is why it's generally best to use reduce when you can, and recursion only when you must.
There are some important differences here though, so let's take a closer look at how this function works. The first thing to notice is the conditional with two branches: (if (first numbers)). When we first call the function, (first numbers) returns 300. That's truthy, so we keep going, and right away our functions call recursive-sum again (we warned you, there's going to be a lot of this in recursion.) The function gets called again but with different arguments: (first numbers) gets added to so-far, our accumulator, and instead of using numbers again as the second argument, we have (next numbers).
With each call to recursive-sum, one more integer is shifted from the input sequence to the output integer:
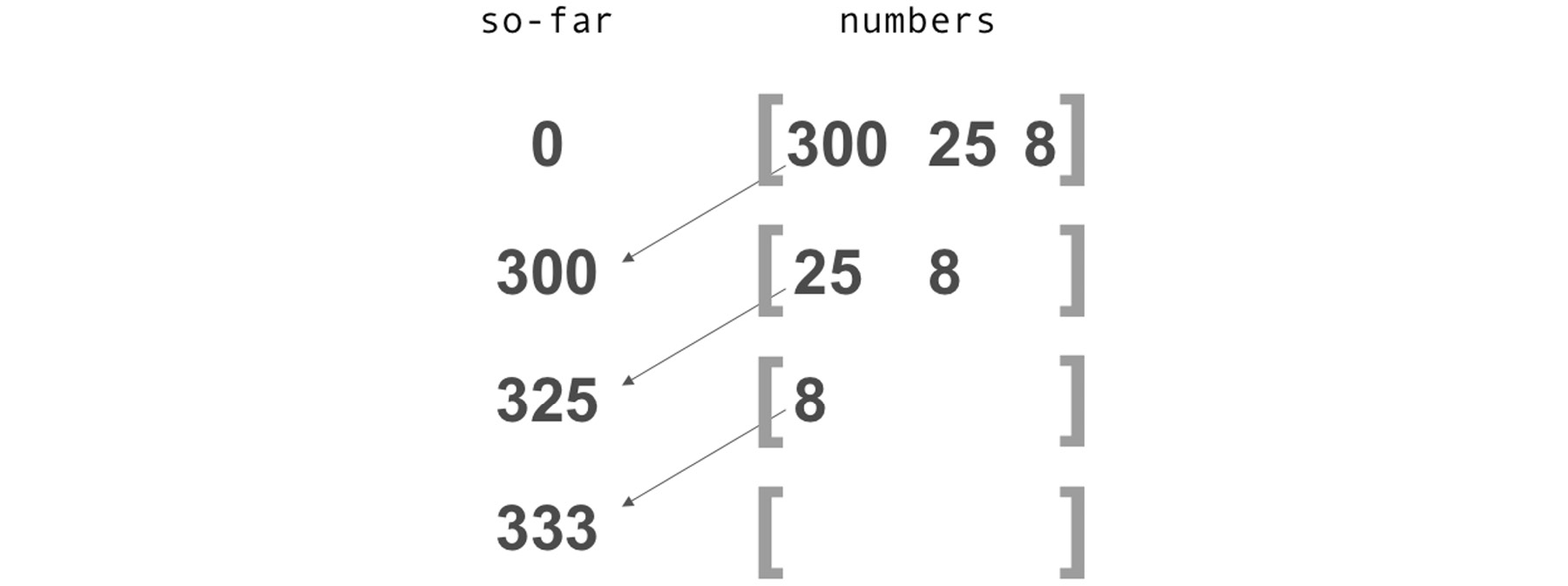
Figure 6.1: Recursively moving items from the input sequence to the output integer
With reduce, we don't need to think about how to advance through the sequence. The reduce function itself takes care of the mechanics of the iterations: moving from one item to the next and stopping when there are no more items. With a recursive function, it's up to us to make sure that each function call receives the right data and that the function stops when the data has been consumed. When you need it, recursion is extremely powerful because, as the programmer, you have complete control over the iteration. You get to decide what the arguments of each successive call will hold. You also get to decide how and when the recursion will stop.
So, how do we move through the sequence? On each call to recursive-sum, the input sequence is split between the first item and all the following items. The call to first gives us the current item, and the call to next helps set up the argument for the next function call. Repeating this splitting action moves us down the sequence.
There is one more problem, though: when do we stop? This is why our function, like the vast majority of recursive functions, is organized around a condition. Ours is simple: stop adding or keep going? The next function is important here too. When called on an empty list, next returns nil:
user> (next '())
nil
In this case, nil reliably means that it is time to stop iterating and just return the value that we have accumulated. More complex situations will require more complicated branching, but the basic idea generally remains the same.
Exercise 6.02: Partitioning Grocery Bags
In this exercise, we'll go back to the grocery conveyor belt simulation from the previous exercise. Now that we can simulate an endless stream of random articles, we need to be able to place the food items into grocery bags as they arrive at the end of the belt. If the bag gets too full, it will break or start to overflow. We need to know when to stop before it gets too full. Luckily, a barcode reader can tell us the weight and longest dimension of the items. If either of these gets beyond a certain number, the bag is removed and replaced with an empty bag:
- Use the same environment as in the previous exercise.
- Our grocery bags will be modeled as lists of articles. Define a full-bag? predicate so that we'll know when to stop filling a bag:
(defn full-bag? [items]
(let [weight (apply + (map :weight items))
size (apply + (map :max-dimension items))]
(or (> weight 3200)
(> size 800))))
- Test full-bag? with the output from grocery streams of different lengths:
groceries> (full-bag? (article-stream 10))
true
groceries> (full-bag? (article-stream 1))
false
groceries> (full-bag? (article-stream 1000))
true
groceries> (full-bag? '())
false
- Set up two functions, bag-sequences and its recursive helper function, bag-sequences*. Define bag-sequences* first, since bag-sequences will call it:
(defn bag-sequences* [{:keys [current-bag bags] :as acc} stream]
;; TODO: write code
)
(defn bag-sequences [stream]
(bag-sequences* {:bags []
:current-bag []} stream))
As you can see from the arguments to the helper function, we've defined an accumulator, this time with two fields: :bags will hold the list of all the completed bags and :current-bag will hold the items we are testing. When :current-bag fills up, we will place it in :bags and start off with a fresh, empty vector in :current-bag.
The second function, without the asterisk, will be the public-facing function. Users of our library won't have to worry about supplying the accumulator; bag-sequences* will be the truly recursive function and do all the work.
- Inside the bag-sequences* function, we will use a cond expression to react to the state of the articles as they arrive. Write the first, negative condition of the cond expression:
(defn bag-sequences* [{:keys [current-bag bags] :as acc} stream]
(cond
(not stream)
(conj bags current-bag)
;; TODO: the other cond branches
))
Here, we decide what happens if there are no more articles in stream. If there's nothing left to put in the bag, then it's time to add current-bag to the list and return everything we've accumulated so far.
Note
In recursive functions, it's common practice to test whether the end of the input sequence has been reached as early as possible. This test is often a simple one, so it's good to get it out of the way. More importantly, if we know that the input sequence is not empty, we don't have to guard against nil values in the tests that follow. This helps eliminate some possible errors in the subsequent test clauses and allows us to write simpler, more readable code.
- Add the condition for when the current bag is full:
(defn bag-sequences* [{:keys [current-bag bags] :as acc} stream]
(cond
(not stream)
(conj bags current-bag)
(full-bag? (conj current-bag (first stream)))
(bag-sequences* (assoc acc
:current-bag [(first stream)]
:bags (conj bags current-bag))
(next stream))
;; TODO: one more branch, for when the bag is not full yet
))
Thanks to the convenient full-bag? function, we know that the current bag is full. This means we need to move some data around inside acc when we make the next call to bag-sequences*. Both of the arguments to bag-sequences* need to be updated. Our call to assoc may look strange at first glance, but assoc can accept multiple pairs of keys and values.
The most recent article in stream is going to become the first article in a new "bag" vector, so we assign that to the :current-bag key in acc. At this point, the current-bag binding (from the destructuring in the function's parameters) still refers to the bag we decided is full. We are going to add it to the list of bags we are maintaining in the :bags key in acc.
And since we want to keep advancing through stream, we use next to move on to the next article: (next stream).
- Write the final, default condition. If we've made it past the two previous conditions, we know that stream is not empty and that the current bag is not full. In this case, all we need to do is add the current article to the current bag. With this condition, our function is complete:
(defn bag-sequences* [{:keys [current-bag bags] :as acc} stream]
(cond
(not stream)
(conj bags current-bag)
(full-bag? (conj current-bag (first stream)))
(bag-sequences* (assoc acc
:current-bag [(first stream)]
:bags (conj bags current-bag))
(next stream))
:otherwise-bag-not-full
(bag-sequences* (update acc :current-bag conj (first stream))
(next stream))))
This time, we'll use update instead of assoc to "modify" the :current-bag key in acc. This form of the update function takes, as its third argument, a function that will be applied to the value corresponding to the key provided and any further arguments. That means that, in this case, conj will be called as if we had written (conj (:current-bag acc) (first stream)).
- Test the function using the article-stream function that we wrote in the previous exercise:
groceries> (bag-sequences (article-stream 12))
[[{:name "Pepper", :weight 85, :max-dimension 90}
{:name "Pepper", :weight 85, :max-dimension 90}
{:name "Green beans", :weight 300, :max-dimension 120}
{:name "Flour", :weight 1000, :max-dimension 140}
{:name "Olive oil", :weight 400, :max-dimension 280}]
[{:name "Bread", :weight 350, :max-dimension 250}
{:name "Pepper", :weight 85, :max-dimension 90}
{:name "Green beans", :weight 300, :max-dimension 120}
{:name "Olive oil", :weight 400, :max-dimension 280}]
[{:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Bread", :weight 350, :max-dimension 250}]]
This seems to work! Each bag appears as a vector of items. The length of the vectors varies depending on the size and weight of the items.
We've solved one of the problems we mentioned at the beginning of the chapter: traversing a sequence in steps of different lengths. In this example, we've partitioned the input sequence into chunks whose size depends on the properties of the underlying data.
When to Use recur
Now, bag-sequence worked fine for relatively short grocery-stream sequences, but when we moved it into production in our multimodal grocery mega-platform, the entire system ground quickly to a halt. Here's the message that appeared on all the technicians' consoles:
packt-clj.recursion> (def production-bags (bag-sequences (article-stream 10000)))
Execution error (StackOverflowError) at packt-clj.recursion/article-stream$fn (recursion.clj:34).
null
So, what happened? What's a StackOverflowError?
The stack is how the JVM keeps track of nested function calls. Each function call requires a little bit of bookkeeping to maintain some contextual information, such as the value of local variables. The runtime also needs to know where the results of each call should go. When a function is called within another function, the outer function waits for the inner function to complete. If the inner function also calls other functions, it too must wait for those to complete, and so on. The job of the stack is to keep track of these chains of function calls.
We can use a very simple function as an illustration. This one takes two integers and performs two different operations on them:
user> (defn tiny-stack [a b]
(* b (+ a b)))
#'user/tiny-stack
user> (tiny-stack 4 7)
77
Here's a simplified version of what happens when we call tiny-stack:
We call tiny-stack and an initial stack frame is produced. It waits for the contents of the function to be evaluated.
While tiny-stack waits, the * function is called. A new stack frame is produced. The b binding evaluates right away, but it can't return yet because of the call to +.
+ is finally called, producing a new, short-lived stack frame. The two integers are added together, the value is returned, and the stack frame of + is erased.
The call to * can now complete. It passes its return value back up to tiny-stack and then its stack frame is erased.
tiny-stack returns 77 and its stack frame is erased:
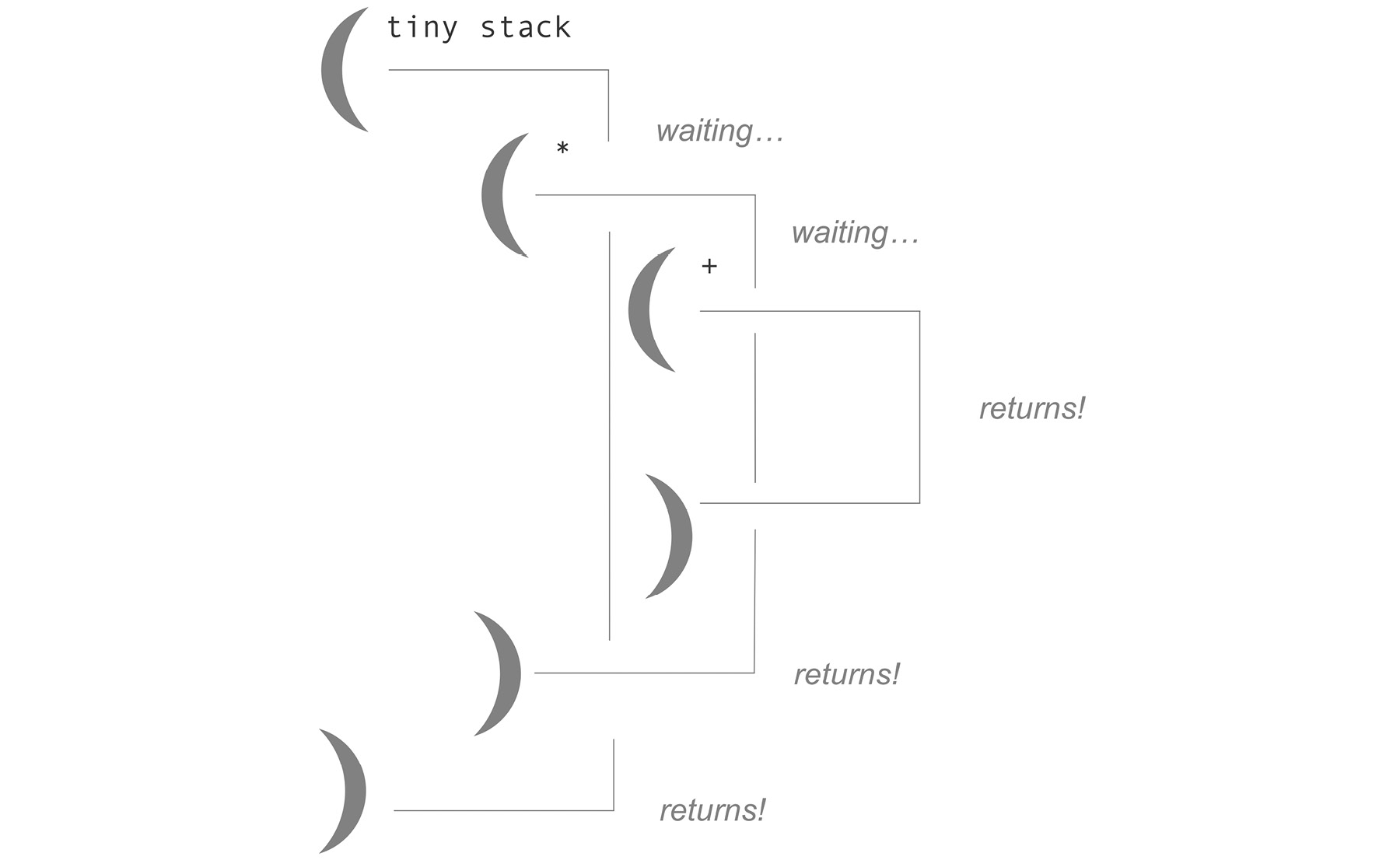
Figure 6.2: A visualization of stack frames in nested function calls
This is how the stack frame is supposed to work. Most of the time, we don't have to think about it at all. However, when we use recursion to walk the length of a sequence, we are actually using the stack, through nesting, to move along the sequence. Because there are limits to how many stack frames the runtime can handle, if we have a very long sequence, we will eventually run out of stack frames and our program will explode:
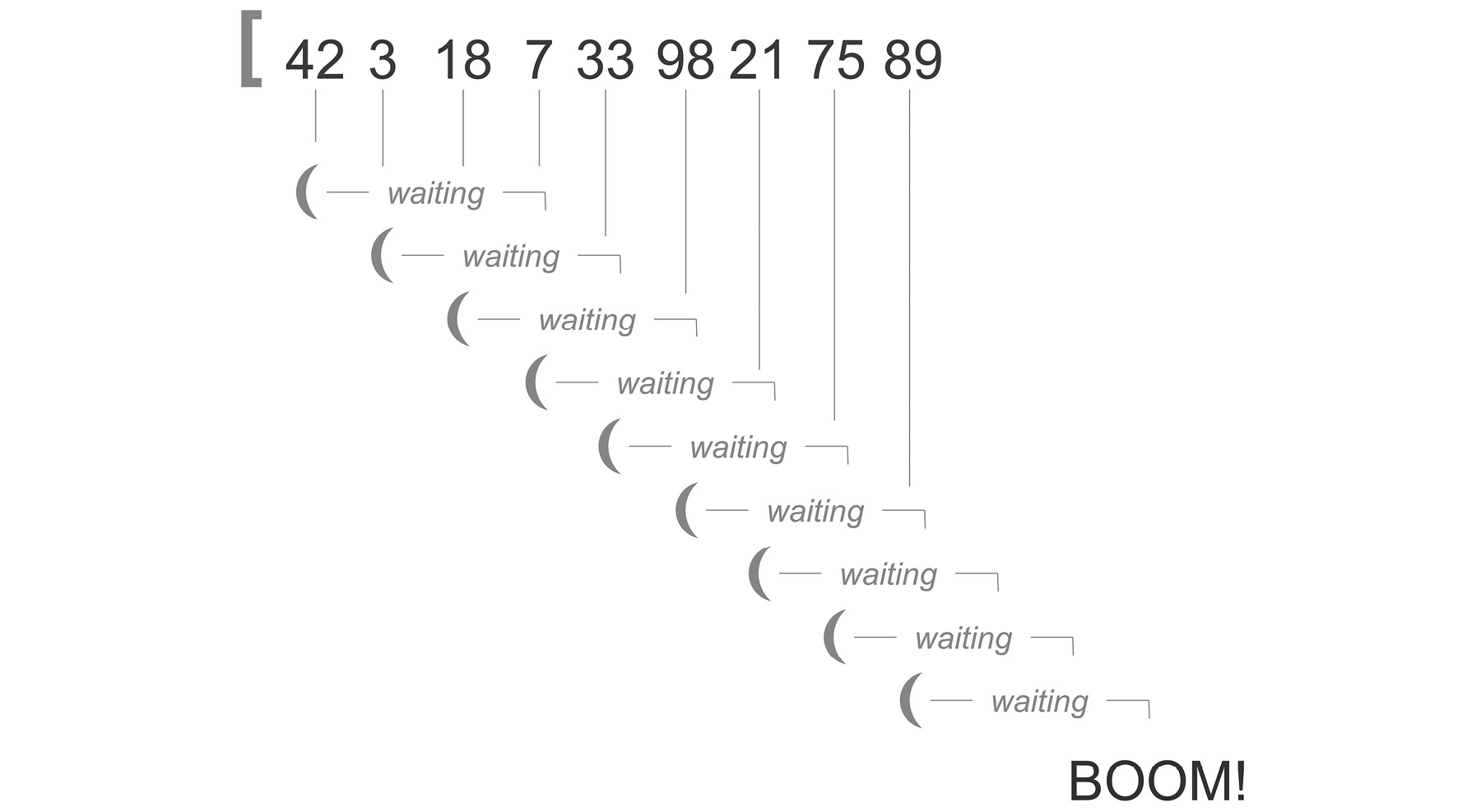
Figure 6.3: Representation of recursion
With recursion, the length of the input vector is translated into depth in the call stack until it goes too far
At this point, you're probably thinking that recursion doesn't sound like such a great pattern after all. This is actually due to a limitation that is built into the JVM. Other Lisps, not based on the JVM, do not have this limitation, and, in those languages, the preceding code would work just fine.
There is, however, a solution in Clojure, and it is called recur. Let's take another look at the recursive-sum function that we wrote in the last section:
(defn recursive-sum [so-far numbers]
(if (first numbers)
(recursive-sum
(+ so-far (first numbers))
(next numbers))
so-far))
First, let's watch this explode on a long input sequence:
user> (recursive-sum 0 (range 10000))
Execution error (StackOverflowError) at user/recursive-sum (REPL:53).
null
To use recur, we simply replace the call to recursive-sum with the recur in our original equation:
user> (defn safe-recursive-sum [so-far numbers]
(if (first numbers)
(recur
(+ so-far (first numbers))
(next numbers))
so-far))
#'user/safe-recursive-sum
user> (safe-recursive-sum 0 (range 10000))
49995000
Why does this work? Well, with recur, a function becomes tail recursive. Tail recursion means that successive calls don't add to the call stack. Instead, the runtime treats them as repetitions of the current frame. You can think of this as a way of staying in the same frame rather than waiting for all the nested calls to resolve. In this way, the looping can continue without adding to the stack. This allows us to process large amounts of data without running into the dreaded stack overflow.
A function can only be tail recursive if it returns a complete call to itself and nothing more. This is a little hard to understand at first, but it should become clearer as we work through some examples. In the next exercise, we'll look at a straightforward use of recur in a tail recursive function.
Exercise 6.03: Large-Scale Grocery Partitioning with recur
As we mentioned before, our previous experiment with bag-sequences did not scale well once the input stream became too long because we ran into stack overflow exceptions. Maybe we can improve on the previous design by using recur:
- Set up the same environment as in the previous exercise.
- Make a copy of the bag-sequences and bag-sequences* functions with new names, such as robust-bag-sequences and robust-bag-sequences*.
- In robust-bag-sequences*, use recur instead of calling bag-sequences*:
(defn robust-bag-sequences* [{:keys [current-bag bags] :as acc} stream]
(cond
(not stream)
(conj bags current-bag)
(full-bag? (conj current-bag (first stream)))
(recur (assoc acc
:current-bag [(first stream)]
:bags (conj bags current-bag))
(next stream))
:otherwise-bag-not-full
(recur (assoc acc :current-bag (conj current-bag (first stream)))
(next stream))))
The only difference with the previous version of bag-sequences* is that we've replaced the recursive calls (where we wrote out the function name, bag-sequences*) with recur. This function is tail recursive. Why? Well, let's look at the three possible outputs that correspond to the three branches of the cond expression. The first branch simply returns data, so there is no recursion at all there. The other two return calls to recur that are the last things to be evaluated in the function. This fits our definition of tail recursion, which is that the function must return a call to itself and nothing else.
- In the public-facing robust-bag-sequences function, don't forget to update the call to bag-sequences* to the new function name:
(defn robust-bag-sequences [stream]
(robust-bag-sequences* {:bags []
:current-bag []} stream))
- Evaluate your namespace and test the new function on a very long article-stream. Don't forget to assign the result to a variable, otherwise it will fill your REPL!
Here, we put 1 million articles into 343,091 bags:
groceries> (def bags (robust-bag-sequences (article-stream 1000000)))
#'packt-clj.recursion/bags
groceries> (count bags)
343091
groceries> (first bags)
[{:name "Olive oil", :weight 400, :max-dimension 280}
{:name "Potatoes", :weight 2500, :max-dimension 340}]
Because the contents of article-stream are random, your results will be slightly different.
This example shows the basics of using recur to easily improve the performance of the recursive function. The robust-bag-sequences* function is indeed tail recursive because it returns a complete call to itself and nothing more.
What about loop?
As you may already know, Clojure does, in fact, have a loop macro. If, on hearing that, you're suddenly thinking "Great, I can just use loop instead!," you are probably going to be disappointed. The loop macro can indeed be useful, but the terrible secret of loop is that it is almost identical to writing a recursive function with recur.
The advantage of the loop macro is that it can be contained inside a function. This removes the need to write a public function that sets up the recursion and possibly does some "post-production" on the result, and a helper function that does the actual recursion. There is nothing wrong with that pattern, of course, but using loop can make a namespace easier to read by limiting the number of functions that need to be defined.
Note
Clojure provides another mechanism for avoiding public functions. Functions defined with defn- instead of defn are only available inside the namespace where they are defined.
The basic logic and structure of loop is really quite similar to that of a function with recur: a call to loop starts with one or more bindings and, just like a recursive function, starts over again thanks to recur. Just like with a recursive function, the parameters to recur must be modified on each iteration to avoid looping infinitely. And calls to loop must also be tail recursive, just like functions using recur.
Here is a simple skeleton for a function that uses loop to do something to the articles in our imaginary grocery store. Let's suppose that the process function does something important with each article, such as sending an API call to a different service. For now, we'll define it as a stub function aliased to identity, which is the Clojure function that simply returns whatever arguments it is provided with:
(def process identity)
(defn grocery-verification [input-items]
(loop [remaining-items input-items
processed-items []]
(if (not (seq remaining-items))
processed-items
(recur (next remaining-items)
(conj processed-items (process (first remaining-items)))))))
Obviously, the basic pattern is very similar to the recursive functions that we've already looked at: the conditionals to detect whether to continue iterating, and the call to recur at the end, are starting to become very familiar to you. It's important to remember that the initial bindings are just that: initial. Just like arguments to a function, they are assigned at the beginning of the loop and then reassigned by the calls to recur. Making sure that the iteration continues smoothly and not infinitely is up to you.
Exercise 6.04: Groceries with loop
Use loop to rewrite the robust-bag-sequences function from the previous exercise:
- Use the same environment as the previous exercises.
- Write the outline for a function with the same call signature as robust-bag-sequences:
(defn looping-robust-bag-sequences [stream]
)
- Set up a loop inside the function with the same arguments as robust-bag-sequences*:
(defn looping-robust-bag-sequences [stream]
(loop [remaining-stream stream
acc {:current-bag []
:bags []}]
;;TODO: the real work
))
As you can see, the initial setup of our accumulator is going to happen in the bindings.
- Fill in the rest of the logic by reusing the code from robust-bag-sequences* in the previous exercise:
(defn looping-robust-bag-sequences [stream]
(loop [remaining-stream stream
acc {:current-bag []
:bags []}]
(let [{:keys [current-bag bags]} acc]
(cond (not remaining-stream)
(conj bags current-bag)
(full-bag? (conj current-bag (first remaining-stream)))
(recur (next remaining-stream)
(assoc acc
:current-bag [(first remaining-stream)]
:bags (conj bags current-bag)))
:otherwise-bag-not-full
(recur (next remaining-stream)
(assoc acc :current-bag (conj current-bag (first remaining-stream))))))))
This version is almost the same as the original. The primary difference is that, because of the way the variables are bound, we end up using a let binding to destructure the accumulator in order to have the current-bag and bags bindings. Other than that, the code is the same.
- Test the new version of the function:
groceries> (looping-robust-bag-sequences (article-stream 8))
[[{:name "Bread", :weight 350, :max-dimension 250}
{:name "Potatoes", :weight 2500, :max-dimension 340}]
[{:name "Potatoes", :weight 2500, :max-dimension 340}]
[{:name "Potatoes", :weight 2500, :max-dimension 340}
{:name "Olive oil", :weight 400, :max-dimension 280}]
[{:name "Flour", :weight 1000, :max-dimension 140}
{:name "Green beans", :weight 300, :max-dimension 120}
{:name "Pepper", :weight 85, :max-dimension 90}]]
This version of the code illustrates how similar loop and a recursive function can be. Choosing one form or the other depends mostly on which version will make your code easier to understand. Thinking of loop as a form of recursion will also make it easier to remember to write tail recursive code inside the loop.
Tail Recursion
As we said earlier, recur tells the JVM to expect the function to be tail recursive. What does that mean exactly, though? Replacing the function name with recur is not, in fact, enough to make a recursive function call tail recursive.
Let's start with an example of what happens when a recursive function is not tail recursive. So far, we've done a lot of adding of sequences of integers. Here's a new twist: suppose the integers are not in a simple sequence, but in nested sequences, perhaps like this:
(def nested [5 12 [3 48 16] [1 [53 8 [[4 43]] [8 19 3]] 29]])
Nested vectors like this are a common way of representing trees in Clojure. The vectors themselves are the branch nodes and the integers, in this case, are the leaves:
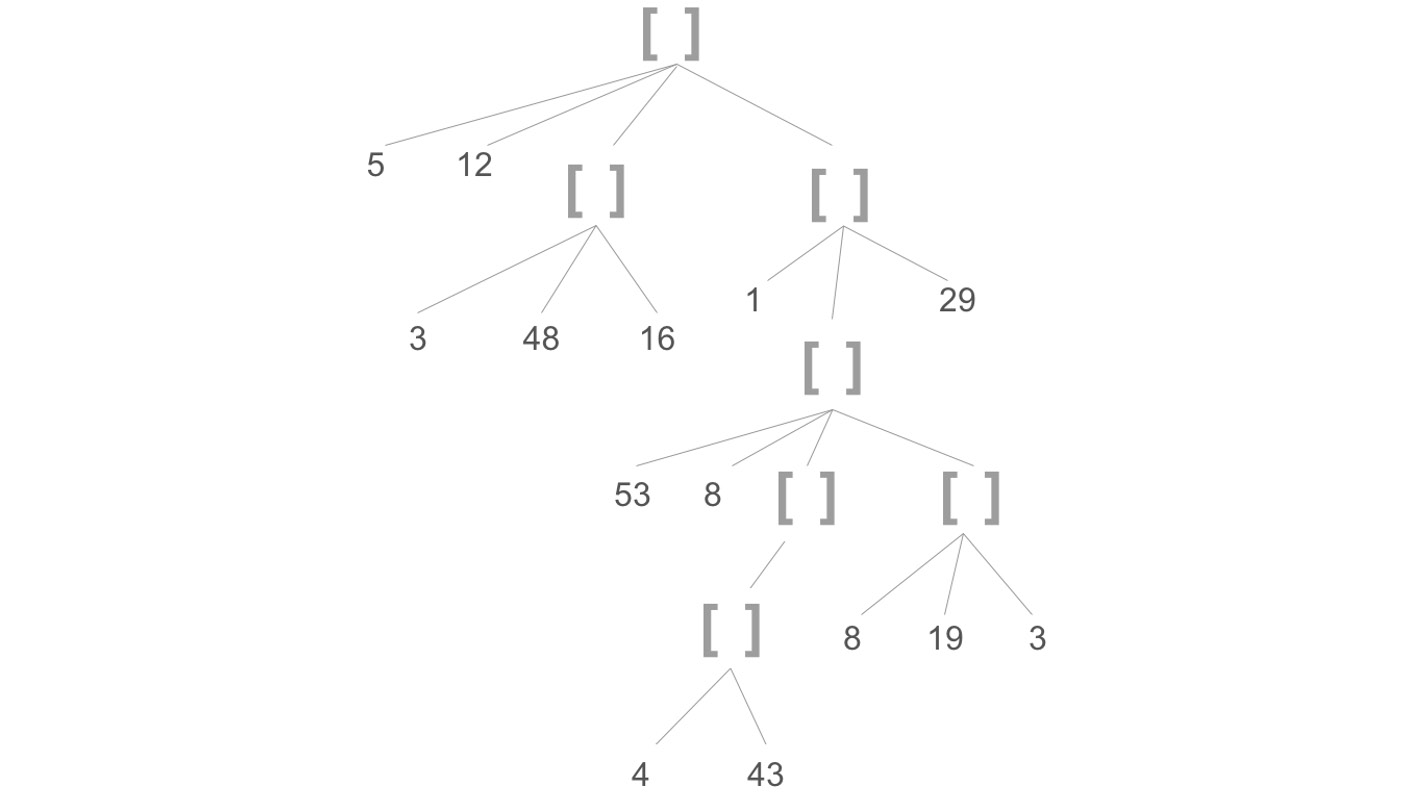
Figure 6.4: Nested vectors are a common way of representing tree structures
We haven't seen this kind of problem yet. It happens to be the kind of problem for which recursion is possibly the best or even the only solution. It's also an important kind of problem: these nested vectors actually define a tree structure. Trees are, of course, one of the most useful ways of representing data, so this is a fairly important subject.
Essentially, to solve this problem, we need a recursive function that adds when it sees a number and calls itself when it sees a list. Here's a start that looks a lot like some of the other functions we've written so far:
(defn naive-tree-sum [so-far x]
(cond (not x) so-far
(integer? (first x)) (recur (+ so-far (first x)) (next x))
; TODO: more code
))
The first condition in the cond form is pretty standard: if we're at the end of the input, we just return whatever is in so-far, our accumulator. The next condition should also seem pretty straightforward by now: if we have a number, add it to our running total and keep going by splitting the input sequence between the first item and the next items.
Now, let's write that last condition for when (first x) is a vector. The new call to recur will need to calculate (first x) so that it can be an integer. Here's what that would have to look like:
(defn naive-tree-sum [so-far x]
(cond (not x) so-far
(integer? (first x)) (recur (+ so-far (first x)) (next x))
(or (seq? (first x)) (vector? (first x)))
(recur (recur so-far (first x)) (next x)))) ;; Warning!!!
If you type this into your REPL and evaluate it, you'll get an error:
1. Caused by java.lang.UnsupportedOperationException
Can only recur from tail position
What's going on? Why doesn't this work?
On the surface, we're just respecting the established pattern. The nested call to recur does look a little strange. But if (first x) is a vector or a list, we can't just add it to so-far. Our function needs an integer as the so-far argument. We need to transform the vector at (first x) into an integer by evaluating that entire part of the tree. And when that's done, and we have a nice, simple integer instead of a subtree, we can finally move on to the rest of the sequence, with (next x).
The reason that the compiler refuses to compile our code, though, is that, because of the final line, the function is not tail recursive. In the last line of the function, the first recur has to wait for the second one to finish before moving on. That is a violation of the tail position requirement of recur: simultaneous calls to recur are forbidden. As we said before, to be tail recursive, a function must return only a call to itself, and nothing more. But in this case, one recur is waiting for the other to return.
We could also think about this in terms of stack frames. Tail recursion means that when the recursive function is called again (through recur), a new frame is not produced: the previous function call is "forgotten," or "erased," by the new one. The only trace of the previous calls is in the changes made to the arguments to the current call. The problem with this function is that the first call to recur can't be "forgotten." It's waiting for the result of the second call. It's only when the second call is resolved that the first will be able to continue. If we're in a situation where two stack frames need to coexist, we can't use recur. When treating linear data, this is generally not a problem. Tree structures, on the other hand, usually can't be handled in the linear way required by recur.
Let's try rewriting the same function without using recur:
user> (defn less-naive-tree-sum [so-far x]
(cond (not x) so-far
(integer? (first x)) (less-naive-tree-sum (+ so-far (first x)) (next x))
(or (seq? (first x)) (vector? (first x)))
(less-naive-tree-sum (less-naive-tree-sum so-far (first x)) (next x))))
#'user/less-naive-tree-sum
user> (less-naive-tree-sum 0 nested)
252
This works! We might have a new problem, though. Without recur, this version of the function will explode the stack when run on a tree with too many items. This may, or may not, be a problem, depending on what kind of data needs to be processed. If we did have many thousands of items and sub-vectors, we would need to find another solution. For that, you'll need to wait until the next chapter, where we'll learn about producing our own lazy sequences, which will permit us to use recursion on large, complex trees.
Recursion without recur and without lazy sequences can work just fine in many cases, though. When the input data is not in the thousands or millions of items, "normal" non-lazy recursion will probably be all you need. For now, the important thing is to understand that there are limits to when recur can be used. Luckily, many of the tasks you'll need to accomplish with recursion fit nicely into a tail recursive pattern. And don't worry: if you forget, the compiler is always there to remind you.
Solving Complex Problems with Recursion
When we talk about recursion, there are really two categories of use cases that are quite different from each other. This is particularly true of Clojure. On the one hand, recursion is the primary, low-level way to build loops where other languages would use for, foreach, or with. On the other hand, functional languages such as Clojure generally make it easier for programmers to find elegant, recursive solutions to complex problems.
Tail recursion and functions, or loops, built around recur are suited for problems where the data, input, and output, is essentially linear. Because tail recursive functions can only return one call at a time, they cannot handle problems where it is necessary to follow multiple, forking paths through the data. Clojure provides the tools you need. Using them may require some practice in approaching the problem in a recursive style.
To help build this skill, the remaining exercises in this chapter will be dedicated to solving a complex problem: finding the most efficient path through a network of nodes. Or, to put it differently: how to travel cheaply between European capitals. These exercises will show you how to break a problem down and resolve it recursively.
Exercise 6.05: Europe by Train
In this exercise, we need to find the least expensive way for a traveler to get from one European city to another. All we have is a list of city-to-city connections and an amount in euros. For the sake of this exercise, we will pretend that these are the only routes available and that the price of train tickets is constant for a given route. Here are our routes:
train_routes.clj
1 (def routes
2 [[:paris :london 236]
3 [:paris :frankfurt 121]
4 [:paris :milan 129]
5 [:milan :rome 95]
6 [:milan :barcelona 258]
7 [:milan :vienna 79]
8 [:barcelona :madrid 141]
9 [:madrid :lisbon 127]
10 [:madrid :paris 314]
The full code for this step is available at https://packt.live/2FpIjVM
And here is a visual representation:
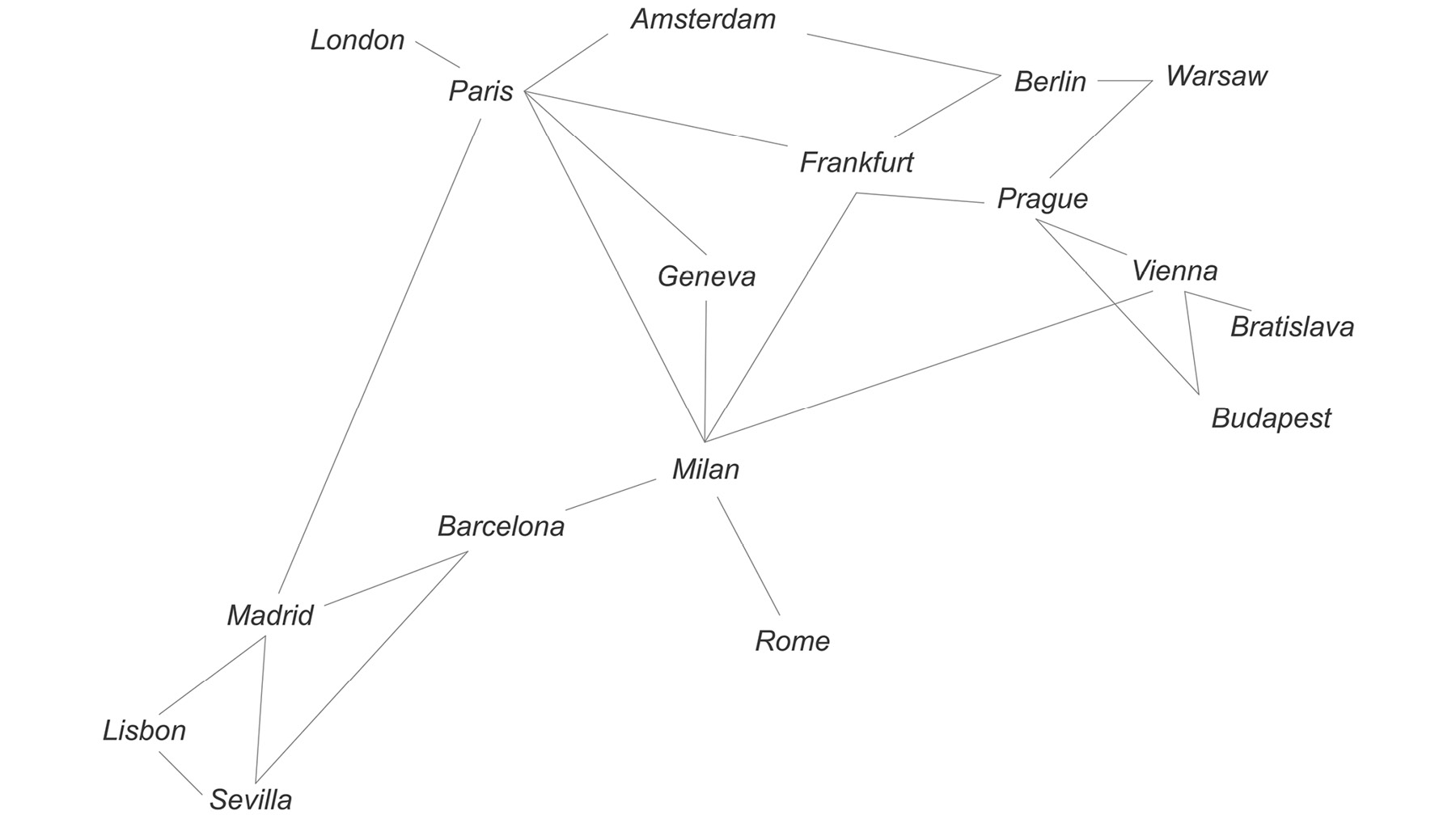
Figure 6.5: Train routes across Europe
Note
The list of paths between cities and the visual map are two ways of representing a graph, which is the computer science term for a system of nodes. A tree is one kind of graph in which there are no "cycles": you can't go from point A, to point B, to point C, and then back to point A. The European railroad network, on the other hand, has plenty of cycles. In graph theory, each city would be called a node and the paths between cities would be called an edge.
The goal is to write a function that takes two cities and returns a list of cities that represents the best route. To solve this problem, we will use recursion, as well as many of the techniques from the last two chapters.
In this exercise, we will set up the project and transform the list of routes into a table that we'll be able to query to see 1) if City A is connected to City B and, if so, 2) the cost of travel between cities A and B.
Thus, the table would look like this:
{:paris {:london 236
:frankfurt 121
:milan 129
;;...etc...
}
:milan {:paris 129
:vienna 79
:rome 95
;;...etc...
}}
We also have to make sure that all of the routes are represented in both directions. In the initial list, we have [:paris :milan 129]. We also need to represent the reverse route, that is, Milan to Paris. In the preceding example, we have :milan in the :paris section, as well as :paris in the :milan section:
- Create a new project directory with a deps.edn file containing just an empty map, {}, and start a new REPL.
- Open a new file called train_routes.clj with just a (ns train-routes) namespace declaration.
- Copy the routes variable from https://packt.live/39J0Fit into the new namespace.
- The first step is to group all the routes together by origin city. Use group-by to do this. Start by defining a function called grouped-routes:
(defn grouped-routes
[routes]
(->> routes
(group-by first)))
- Run this early version of the function on the route list and look at the results for just one city:
train-routes> (:paris (grouped-routes routes))
[[:paris :london 236]
[:paris :frankfurt 121]
[:paris :milan 129]
[:paris :amsterdam 139]]
With the call to group-by, we have a list of all the :paris routes. We now need a way to change this sub-list into a map.
- Write a function that accepts one of these sub-lists and returns a map:
(defn route-list->distance-map [route-list]
(->> route-list
(map (fn [[_ city cost]] [city cost]))
(into {})))
This function uses the map-into pattern to create a list of two-item vector tuples. We don't need the first item because it's the same as the key associated with the sub-list, so we use destructuring to place city and cost in a new vector.
- Test route-list->distance-map in the REPL with some sample data:
train-routes> (route-list->distance-map [[:paris :milan 129]
[:paris :frankfurt 121]])
{:milan 129, :frankfurt 121}
- Continue building the grouped-routes function. Use the map-into pattern again to apply route-list->distance-map to all the sub-lists returned by the call to group-by:
(defn grouped-routes
[routes]
(->> routes
(group-by first)
(map (fn [[k v]] [k (route-list->distance-map v)]))
(into {})))
The call to map treats the key-value pairs of the top-level map as a series of two-item vectors and runs route-list->distance-map on each value. The call to into converts the sequence back into a map.
- Test this version of grouped-routes in the REPL:
train-routes> (:paris (grouped-routes routes))
{:london 236, :frankfurt 121, :milan 129, :amsterdam 139}
Perfect! This kind of map will make it easy to look up a route between an origin (:paris) and a destination (:amsterdam).
We still need to produce the reverse routes. We'll use mapcat, in a pattern we mentioned back in Chapter 4, Mapping and Filtering, to produce two routes for each input route. This can go before the call to group-by:
(defn grouped-routes
[routes]
(->> routes
(mapcat (fn [[origin-city dest-city cost :as r]]
[r [dest-city origin-city cost]]))
(group-by first)
(map (fn [[k v]] [k (route-list->distance-map v)]))
(into {})))
The anonymous function in the mapcat call returns a vector containing two sub-vectors. The first of these is the original route, and the second is the same route with the origin and destination cities reversed. Thanks to mapcat, the result is a flattened list with twice as many elements as the input list.
- Test this in the REPL again:
train-routes> (:paris (grouped-routes routes))
{:london 236,
:frankfurt 121,
:milan 129,
:madrid 314,
:geneva 123,
:amsterdam 139}
Now, the [:madrid :paris 34] route is also included as a :paris to :madrid route.
- Define a lookup variable with the lookup table:
train-routes> (def lookup (grouped-routes routes))
#'train-routes/lookup
We'll need this variable later.
- Test the lookup table. First, we'll ask for a route from Paris to Madrid:
train-routes> (get-in lookup [:paris :madrid])
314
Can we go back to Paris?
train-routes> (get-in lookup [:madrid :paris])
314
Let's try a route that we know does not exist:
train-routes> (get-in lookup [:paris :bratislava])
nil
Our lookup table answers two important questions: Is there a route between City A and City B? How much does it cost?
We now have a data store that we can consult when we need to find which cities are available from any given point in the European rail graph. Rearranging data into an easy-to-query form can be an important step when dealing with a complex problem like this one. The next steps will be easier thanks to this easy access to our data.
Pathfinding
If we are in a city that is not directly connected to the city we want to travel to, we need to choose intermediate cities. To get from City A to City F, maybe we can go to City C first; or, maybe we'll need to go to City B and then City D before reaching City F. To find the best path, we first need to find all the possible paths.
This is why a recursive approach is a good fit. The basic strategy is to test whether City A and City F are connected. If so, we've already found the answer. If not, we look at all the cities we can reach directly from City A. We go through the same process on each of those, and so on and so forth, until finally we find a city that is connected directly to City F. The process is recursive because we repeat the same process on each node until we find what we are looking for.
Let's try to visualize this process, using a small part of the network. In this example, we'll start in Paris and search for Berlin. The first step is to test the cities we can reach from Paris. In London, Amsterdam, and Frankfurt, we ask: are you Berlin?
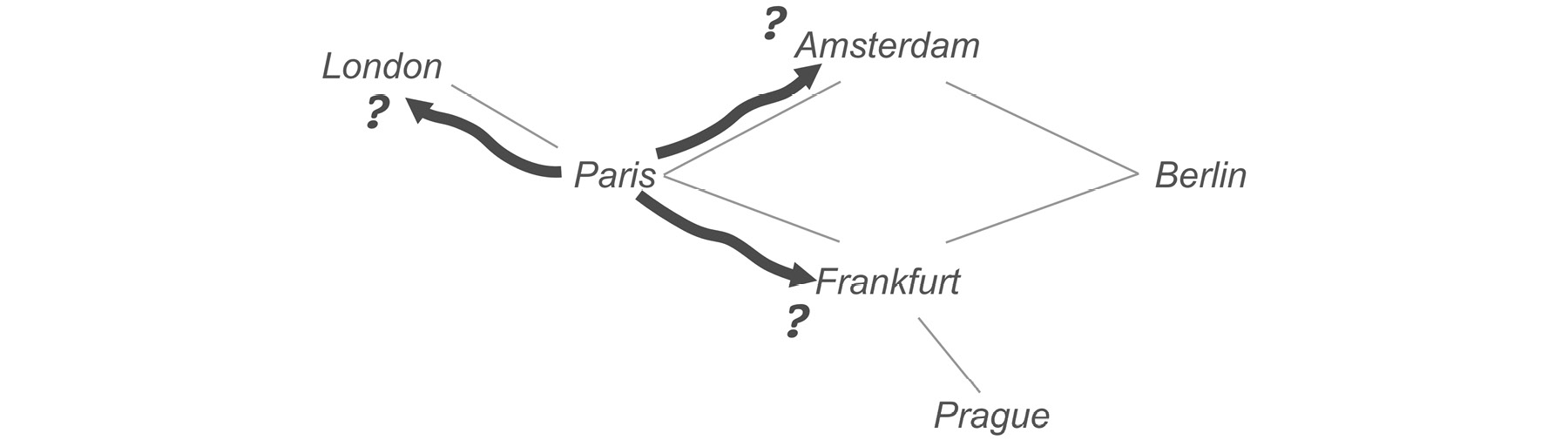
Figure 6.6: Starting in Paris, we query all the available cities
Since none of the cities is the one that we are looking for, we repeat the process from London, Amsterdam, and Frankfurt:
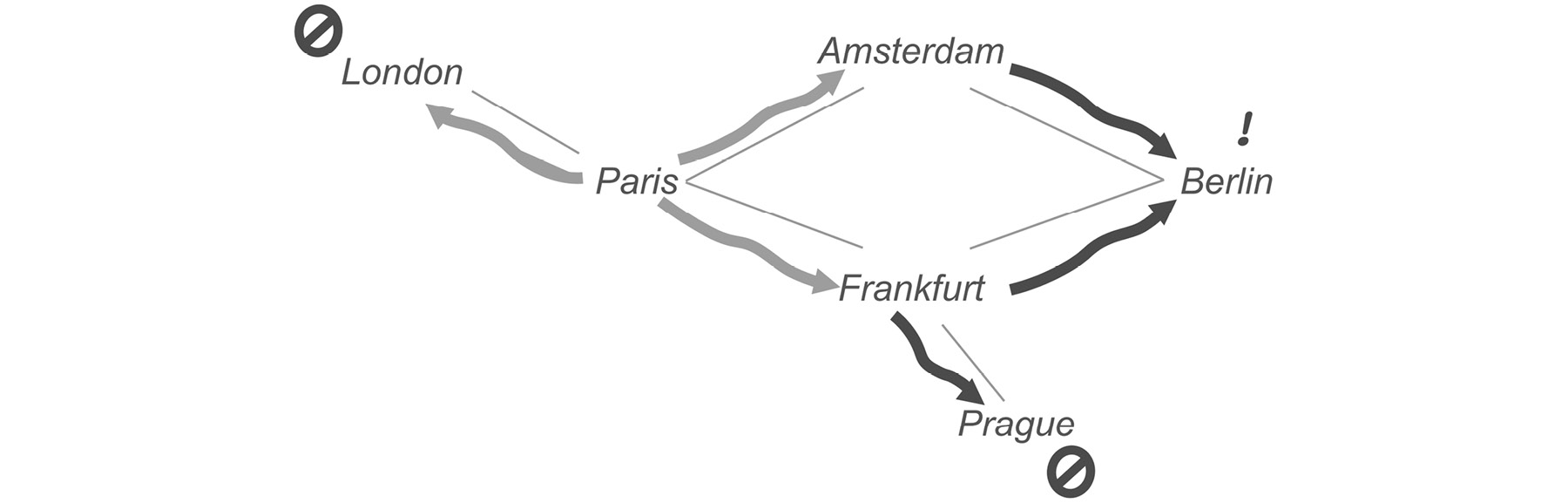
Figure 6.7: Searching again from the previously found cities
From London, we have nowhere left to go. But from Amsterdam and Frankfurt, we can reach Berlin. Success! Not only have we found Berlin, but we've found two paths to get there.
We could represent these paths as Clojure vectors:
[:paris :london nil]
[:paris :amsterdam :berlin]
[:paris :frankfurt :berlin]
[:paris :frankfurt :prague nil]
Notice that the paths going through Prague and London end with nil. This is how we will represent paths that do not lead to our destination and must be removed from the result set.
There is one more issue that we haven't dealt with yet. What prevents us from going from Amsterdam back to Paris? This would create infinite loops where we search from Paris, then search Amsterdam, then search Paris again, and so on. To get around this problem, we will need to "remember" where we've been.
This is our general approach. Now, let's write some more code!
Exercise 6.06: The Search Function
The next step is to write the main search function, a recursive function that we'll call find-path*. The find-path function will be the public interface that calls find-path*:
- At this point, we are ready to write the main search function. The find-path function can be used for the wrapper function that will serve as the public interface. To get started, let's write the empty functions:
(defn find-path* [route-lookup destination path]
;; TODO: write code
)
(defn find-path [route-lookup origin destination]
;; TODO: write code
)
We've written the "private" function, find-path*, first since the "public" function, find-path, will refer to it.
There are already some design decisions here in the function arguments. Both functions accept the route-lookup argument. This will be the lookup table generated by grouped-routes. They both accept the destination argument as well. Since we want to build up a list of cities, a path, the private function, find-path*, doesn't take an origin argument like find-path does. Instead, it will take whatever the current path is. Since it's a recursive function, the current "origin" will always be whatever the last city in the path is.
In other words, if we're testing a path, the value of path might be [:paris :milan]. That means that on the next iteration, find-path* will try all the cities available from :milan, making :milan the temporary origin. The next cities are tested in the same way and the path gets lengthened by one city on each successive call.
- Call find-path* from find-path:
(defn find-path [route-lookup origin destination]
(find-path* route-lookup destination [origin]))
This is simple. We package the initial origin in a vector to pass off to find-path*. This way, we know that we will always have at least one city in the path parameter.
- Set up the basic conditional structure of the recursive function:
(defn find-path* [route-lookup destination path]
(let [position (last path)]
(cond
(= position destination) path
(get-in route-lookup [position destination])
(conj path destination)
;; TODO: still not there
)))
This part does two things. We are going to need to refer to the current position a lot, so it's a good idea to create a let binding immediately. As we mentioned earlier, our current position is always the last item in the path argument. The whole process is about adding cities on to the end of this list.
The next thing we do is to start setting up the different checks we'll use. The two conditions we add here both end the recursion and return a value. These are the "Are we there yet?" tests. The second one is the one that will be called the most, so let's look at it first.
If you remember how our lookup table is structured, there is a top-level set of keys, one for each city in our system. The value of each of those keys is a map of reachable cities. That's why we can use get-in here. Say our lookup table looks something like this:
{:paris {:frankfurt 121
:milan 129
;; etc.
}
;; etc.
}
If we call (get-in routes-lookup [:paris :milan]), we will get 129. If our current position is :paris and our destination is :milan, then this call will return truthy. In that case, we add :milan to the current path and we return the path. We've arrived.
So, why do we need the first condition then? In what circumstances would the destination city already be in the path? There is only one way that could happen, but we do have to take care of it. Someday, a user will call your function and ask the best route from :paris to :paris and we don't want to blow up the stack on such a simple request.
- Test the simple cases. We already have enough code for two cases, so let's see whether our functions work. Try find-path* first with a one-city path:
train-routes> (find-path* lookup :sevilla [:sevilla])
[:sevilla]
Now, let's try the same thing with find-path:
train-routes> (find-path lookup :sevilla :sevilla)
[:sevilla]
The current code should also work if the destination city is only one "hop" away from the origin:
train-routes> (find-path* lookup :madrid [:sevilla])
[:sevilla :madrid]
So far so good. Onward!
- Start building the recursive logic to find-path*:
(defn find-path* [route-lookup destination path]
(let [position (last path)]
(cond
(= position destination) path
(get-in route-lookup [position destination])
(conj path destination)
:otherwise-we-search
(let [path-set (set path)
from-here (remove path-set (keys (get route-lookup position)))]
(when-not (empty? from-here)
(->> from-here
(map (fn [pos] (find-path* route-lookup destination (conj path pos))))
(remove empty?)))))))
For the final condition, we use an expressive Clojure keyword such as :otherwise-we-search as a condition, but anything that isn't false or nil will do. If we get this far, we know that we haven't reached the destination yet, so we have to keep searching.
- Let's look at this line by line. The first thing we do is define path-set, which will allow us to test whether a city is already in our path. You can try building and using a set in the REPL:
train-routes> (set [:amsterdam :paris :milan])
#{:paris :milan :amsterdam}
train-routes> ((set [:amsterdam :paris :milan]) :berlin)
nil
train-routes> ((set [:amsterdam :paris :milan]) :paris)
:paris
The reason this is important becomes apparent in the next line. We bind from-here to this:
(remove path-set (keys (get route-lookup position)))
We can't use get-in like we did earlier because this time, we don't want just one city reachable from position, we want all of them. So, we grab the entire sub-map for the current city, with (get route-lookup position), and then extract a list of keywords. Now, the path-set binding from the previous line becomes useful. We use it to remove any cities that we've already visited. This is how we avoid recursively going back and forth between :paris and :amsterdam forever.
The from-here binding now contains all the cities we still need to test. First, though, we check to see whether from-here is empty, using Clojure's well-named empty? predicate. Let's say our destination is :berlin and our current path is [:paris :london]. The only way out of :london is to go back to :paris, but we've already been there. This means it's time to give up, so we return nil. As you'll soon see, paths that resolve to nil will be ignored.
- After this, we start threading from-here through a series of s-expressions. The first one is where the actual recursion is going to happen:
(map (fn [pos] (find-path* route-lookup destination (conj path pos))))
- We're mapping over the cities that we can reach from our current position. Say we've arrived in :paris from :london. In the lookup table, the value for :paris is as follows:
train-routes> (:paris lookup)
{:london 236,
:frankfurt 121,
:milan 129,
:madrid 314,
:geneva 123,
:amsterdam 139}
- We can't go back to :london, so that means from-here is [:frankfurt :milan :madrid :geneva :amsterdam]. The anonymous function provided to map will be called once for each of these cities as pos. Each city will thus be appended to the path argument in the recursive calls to find-path*. The following values will be tried as the path argument to find-path*:
[:london :paris :frankfurt]
[:london :paris :milan]
[:london :paris :madrid]
[:london :paris :geneva]
[:london :paris :amsterdam]
Remember that map returns a list. The list returned here will be the result of calling find-path* on each city. Each of those calls will produce a list as well, until the search finds the destination city or runs out of places to look.
Now, we can start to visualize the recursive structure of our path search:
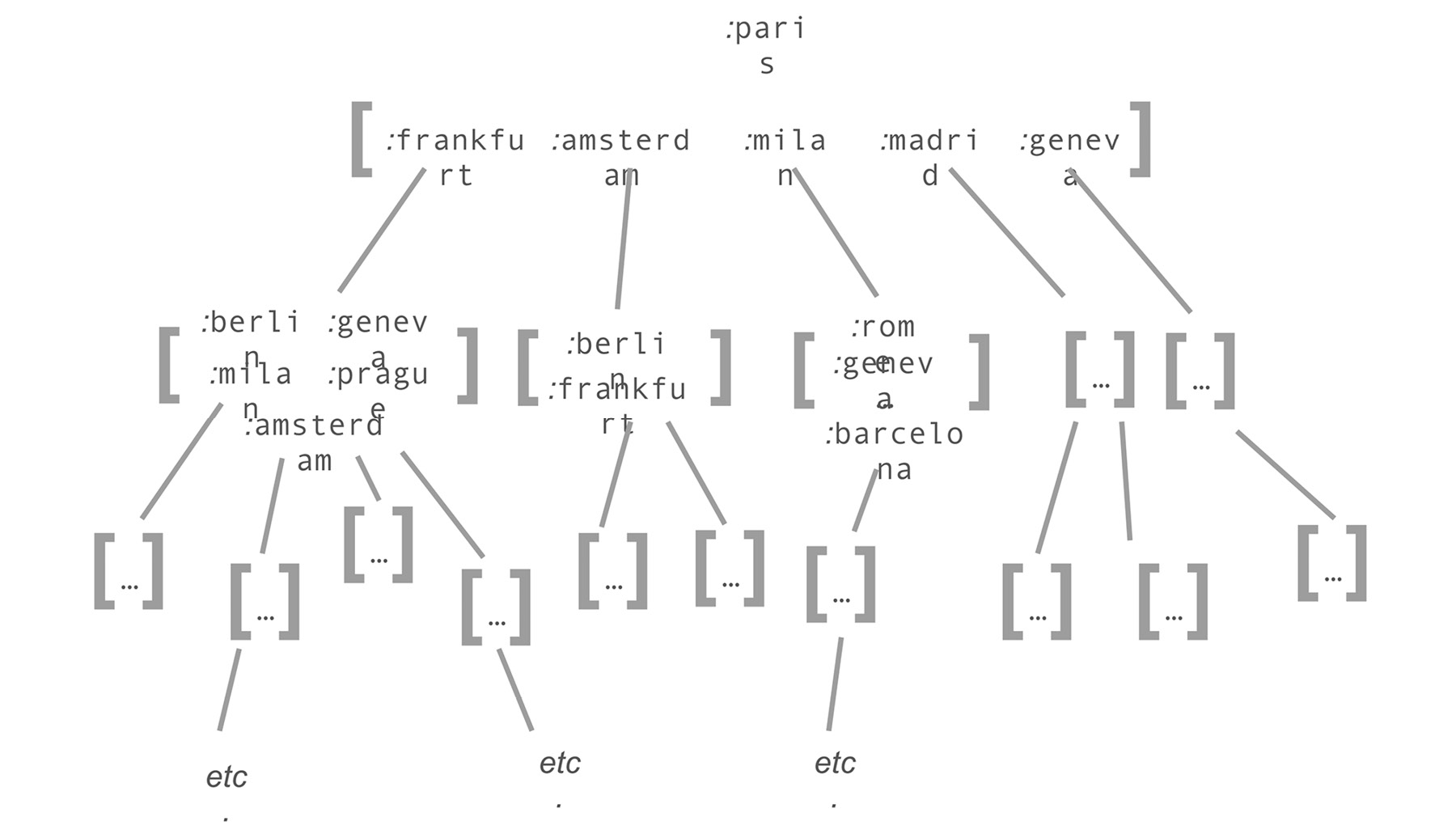
Figure 6.8: Each city resolves to a new list of cities, each of which resolves to a new list
Eventually, the search will either find the destination or run out of options, at which point the lists will all be resolved. If there are no more options and the destination still hasn't been found, nil is returned. Otherwise, a list of resolved paths is returned. This simple call to map ends up walking the entire city graph until all the possible routes are found.
Before returning, though, the call to map gets threaded through one last s-expression: (remove empty?). This is how we filter out the nil paths that never find the destination.
- Test the current state of the function on a short path.
To make this easier to test, we'll use a smaller rail network. Start by defining a new variable for the lookup table:
train-routes> (def small-routes (grouped-routes [[:paris :milan 100][:paris :geneva 100][:geneva :rome 100][:milan :rome 100]]))
#'train-routes/small-routes
train-routes> small-routes
{:paris {:milan 100, :geneva 100},
:milan {:paris 100, :rome 100},
:geneva {:paris 100, :rome 100},
:rome {:geneva 100, :milan 100}}
There should be precisely two paths between :paris and :rome:
train-routes> (find-path* small-routes :rome [:paris])
([:paris :milan :rome] [:paris :geneva :rome])
- Test the current state of the function with a slightly bigger network. We'll add another route between :paris and :milan:
train-routes> (def more-routes (grouped-routes [[:paris :milan 100]
[:paris :geneva 100]
[:paris :barcelona 100]
[:barcelona :milan 100]
[:geneva :rome 100]
[:milan :rome 100]]))
#'train-routes/more-routes
- With this set of routes, our result is not quite what we expect:
train-routes> (find-path* more-routes :rome [:paris])
([:paris :milan :rome]
[:paris :geneva :rome]
([:paris :barcelona :milan :rome]))
- The data looks good, but where did those extra parentheses come from? This is a consequence of using map in a recursive way. map always returns a list. The :barcelona route requires an extra level of recursion because it is one item longer than the others. As a result, it is wrapped in a list. We can verify this by adding another possible route:
train-routes> (def even-more-routes (grouped-routes [[:paris :milan 100]
[:paris :geneva 100]
[:paris :barcelona 100]
[:barcelona :madrid 100]
[:madrid :milan 100]
[:barcelona :milan 100]
[:geneva :rome 100]
[:milan :rome 100]]))
#'train-routes/even-more-routes
train-routes> (find-path* even-more-routes :rome [:paris])
([:paris :milan :rome]
[:paris :geneva :rome]
(([:paris :barcelona :madrid :milan :rome])
[:paris :barcelona :milan :rome]))
As you can see, the five-city path that goes through :madrid is wrapped in an extra set of parentheses.
- Unnest the nested lists. To solve this problem, use mapcat to strip away the containing lists. Here is the final version of find-path*:
(defn find-path* [route-lookup destination path]
(let [position (last path)]
(cond
(= position destination) path
(get-in route-lookup [position destination])
(conj path destination)
:otherwise-we-search
(let [path-set (set path)
from-here (remove path-set (keys (get route-lookup position)))]
(when-not (empty? from-here)
(->> from-here
(map (fn [pos] (find-path* route-lookup destination (conj path pos))))
(remove empty?)
(mapcat (fn [x] (if (keyword? (first x))
[x]
x)))))))))
The last addition is the call to mapcat. It might look strange at first, but remember: mapcat removes the outer parentheses from the items in the list that it returns. That's why we have the conditional: if x is just a path, like [:prague :bratislava], we don't want it to be directly concatenated, which is why we return [x] instead. The new wrapper is instantly removed when the items are concatenated together, and the original vector remains intact. In the other cases though, when the underlying vector is wrapped in a list, mapcat "removes" it.
- Test this version on the small and large railroad networks. First, we'll test it with even-more-routes:
train-routes> (find-path* even-more-routes :rome [:paris])
([:paris :milan :rome]
[:paris :geneva :rome]
[:paris :barcelona :madrid :milan :rome]
[:paris :barcelona :milan :rome])
Much better!
- Now, try it with the full-sized lookup table. We won't print the full results here because they're quite long:
train-routes> (find-path* lookup :rome [:paris])
([:paris :frankfurt :milan :rome]
[:paris :frankfurt :berlin :warsaw :prague :vienna :milan :rome]
[:paris :frankfurt :berlin :warsaw :prague :bratislava :vienna :milan :rome]
[:paris :frankfurt :berlin :warsaw :prague :budapest :vienna :milan :rome]
[:paris :frankfurt :geneva :milan :rome]
[:paris :frankfurt :prague :vienna :milan :rome]
[:paris :frankfurt :prague :bratislava :vienna :milan :rome]
[:paris :frankfurt :prague :budapest :vienna :milan :rome]
;; etc. )
Now, we can walk the entire network. Our find-path function returns all the possible routes between any two cities.
Once again, Clojure has helped us write a concise solution to a fairly complex problem. A recursive algorithm such as this depends on a design that combines two elements. On the one hand, the recursive function treats each new node as if it were the first node. Recursive solutions are often perceived as "elegant" because of this. By solving the problem for one item, it can be solved for an entire network of items. To work, however, this requires the second design element: a way of accumulating the results from one node to another. In this example, we built up our knowledge by adding cities to one of the parameters. In the next exercise, we'll use different techniques for bringing the data together.
This exercise also shows the value of using small, sample inputs at the REPL. The interactive programming experience allows you to quickly try things and verify your hypotheses.
Exercise 6.07: Calculating the Costs of the Routes
There's just one more problem to solve. In our original problem description, we didn't ask for all the possible routes, but just the least expensive one! We need a way to evaluate the cost of all the paths and choose one. To accomplish this, we will use the lookup table from the two previous exercises to calculate the cost of each path returned by find-path*. Then, we can use a reducing pattern from Chapter 5, Many to One: Reducing, for finding the path with the lowest cost:
- Write a cost-of-route function.
To do this, we'll use a pattern from Chapter 4, Mapping and Filtering, map, with two input lists. The first will be the path, and the second will be the path offset by one item so that each call can evaluate the cost of going from one city to the next. It should look like this:
(defn cost-of-route
[route-lookup route]
(apply +
(map (fn [start end]
(get-in route-lookup [start end]))
route
(next route))))
By now, this should look familiar. (next route) provides the offset version of route. For each pair of cities, we use get-in the same way we did earlier. That call gives us the cost of a given segment in the path. Then, we use the (apply +) pattern to find the grand total.
- Test the new function:
train-routes> (cost-of-route lookup [:london :paris :amsterdam :berlin :warsaw])
603
And it even works with the edge cases:
train-routes> (cost-of-route lookup [:london])
0
- Write a min-route function to find the least expensive route.
Now, we'll leverage another familiar pattern, this time using reduce. We want to find the route with the lowest total cost and we need a function like min, except that it will return the item that has the minimum cost, and not just the minimum cost itself:
(defn min-route [route-lookup routes]
(reduce (fn [current-best route]
(let [cost (cost-of-route route-lookup route)]
(if (or (< cost (:cost current-best))
(= 0 (:cost current-best)))
{:cost cost :best route}
current-best)))
{:cost 0 :best [(ffirst routes)]}
routes))
The only slightly tricky aspect of this function is the initialization value in the call to reduce: {:cost 0 :best [(ffirst routes)]}. We start with a default cost of 0. So far so good. The default :best route should be the route corresponding to a distance of zero, which means that we're not going anywhere. That's why we use ffirst, which is not a typo but a convenience function for nested lists. It is a shortcut for (first (first my-list)), so it returns the first element of the first element of the outer list.
- Now, put it all together. Add a call to min-route to the public-facing find-path function:
(defn find-path [route-lookup origin destination]
(min-route route-lookup (find-path* route-lookup destination [origin])))
- Test this out on several pairs of cities:
train-routes> (find-path lookup :paris :rome)
{:cost 224, :best [:paris :milan :rome]}
train-routes> (find-path lookup :paris :berlin)
{:cost 291, :best [:paris :frankfurt :berlin]}
train-routes> (find-path lookup :warsaw :sevilla)
{:cost 720,
:best [:warsaw :prague :vienna :milan :barcelona :sevilla]}
Working through this code involved a lot of different steps, but, in the end, it was worth it. We've actually solved a somewhat difficult problem in about 50 lines of code. Best of all, the solution involved many techniques that we've already seen, which shows, one more time, how important and powerful they can be when used together.
A Brief Introduction to HTML
In many of the remaining chapters of this book and starting with the activity at the end of this chapter, we will be working in one way or another with Hypertext Markup Language (HTML), which holds together just about every web page you've ever seen. Producing HTML from data is an extremely common programming task. Just about every mainstream programming language has multiple templating libraries for generating web pages. Even before Clojure, Lisps have used nested s-expressions for this. S-expressions are a particularly good fit for HTML documents, which are structured like logical trees.
In case you're not familiar with the essentials of producing HTML, it's worth briefly reviewing the basics. HTML is the content of the text file that provides the structure for other kinds of content (that is, images, audio, and video resources) on a web page. The fundamental unit of HTML is called an element. Here is a simple paragraph element, using the <p> tag:
<p>A short paragraph.</p>
The HTML standard, of which there are several versions, contains many, many kinds of elements. The <html> element contains a web page in its entirety. In turn, this contains the <head> and <body> elements. The first of these contains various kinds of metadata for displaying the page; the second contains the actual content that will be shown to the user. The <body> element can contain both text and more elements.
We'll only use a small handful of elements here:
- <div>: Perhaps the most widely used element of all, <div> is a generic container for anything from the size of the paragraph up to an entire document. It can't be used for content below the size of a paragraph, however, because the end of a <div> causes a break in the text flow.
- <p>: The paragraph element.
- <ul> and <li>: "UL" stands for "unordered list," that is, a list without numbers. A <ul> should only contain "list items," that is, <li> elements.
- <span>, <em>, and <strong>: These elements are part of the text; they are for wrapping single words or single letters. They do not cause breaks in text flow. <span> is a generic element. <em> (for emphasis) generally produces italicized text, while <strong> generally produces bold text.
- <a>: A hypertext link element. This is also a text-level element. The href attribute (we'll explain attributes in a second) of an <a> element tells the browser where to go when you click on a link.
- <img>: The <img> tag inserts an image, referenced by its src attribute.
- <h1>, <h2>, and <h3>:These are the heading elements, for page titles, section titles, subsection titles, and more.
These few elements are enough to get started producing web content. You can learn about others as needed by consulting, for example, the Mozilla Developers Network's MDN web documentation.
Note
The MDN web docs can be referred to at https://packt.live/2s3M8go.
Since we will be producing HTML, there are only a few things you need to know in order to produce well-formed HTML:
- Most HTML tags have three parts: a start tag, a closing tag, and some content.
- A start tag consists of a short string wrapped in angle brackets: <h1>.
- A closing tag is similar, except that there is a slash, /, in front of the tag name, </h1>.
- Opening tags can contain attributes, which are key-value pairs, with the values in quotes: <h1 class="example-title">Example</h1>.
- Certain attributes, known as "Boolean attributes", don't need to have a value. The presence of a key is enough:
<input type="checkbox" checked>
- Some tags do not have any content. They can be written as a single element containing a slash after the tag name: <br/>.
- In some dialects of HTML, certain tags without content can be written without a slash: <img>.
- If an element begins inside another element, its end tag must occur before the end of the containing element.
The last point is important. This means that it would be invalid to write something like this:
<div>Soon a paragraph <p>will start</div>, then end too late.</p>
The <p> element here should be a child element of <div>. A child element must be contained completely by its parent element. This is a very good thing when manipulating HTML because it means that correctly formed HTML is always a tree structure, with a root note, the <html> element that contains nodes that contain other nodes, and so on. As you'll see, this matches well with the kinds of tree structures that we've already looked at here.
Now, you know enough to write a system that will produce well-formed HTML. (To become a renowned web designer, however, you'll need to learn a little bit more.)
In Clojure, vectors are generally used for representing the structure of an HTML document. One of the more popular libraries that does this is called Hiccup. With Hiccup, a short paragraph containing a link would look like this:
[:p "This paragraph is just an "
[:a {:href "http://example.com"} "example"] "."]
The output would be as follows:
<p>This paragraph is just an <a href="http://example.com">example</a>.</p>
The syntax for this is quite simple. Besides using vectors, it uses keywords to identify HTML tags and maps to add attributes such as href or class.
Some tags, such as <link>, <meta>, <br>, <input>, and <img>, are generally not closed, so they should receive special handling. All other tags should be explicitly closed even if they don't have any content.
Note
More information on Hiccup can be found at https://packt.live/36vXZ5U.
Activity 6.01: Generating HTML from Clojure Vectors
The company you work for is building a new web application. Generating and serving HTML pages is, quite logically, a key part of the operation. Your team has been asked to write a library for generating HTML from Clojure data.
Producing HTML from data is an extremely common programming task. Just about every mainstream programming language has multiple templating libraries for generating web pages. Even before Clojure, Lisps have used nested s-expressions for this. S-expressions are a particularly good fit for HTML documents that are structured like logical trees.
Goal
In this activity, you are going to write your own system for generating HTML from nested vectors, using this format. The goal is to be able to take any vector written with this syntax, including an arbitrary number of descendant vectors, and produce a single string containing correctly structured HTML.
Your code should also handle "Boolean attributes." Clojure maps don't allow keys to have no value to do this of course. You'll need to invent a convention so that users of your library can assign some non-string value to these attributes and get a Boolean attribute in the output string.
Steps
The following steps will help you to complete the activity:
- Set up a new project directory with an empty deps.edn file. You don't need any external dependencies for this activity. Make your own namespace with a catchy name for this new library.
- If you decide to use the clojure.string library, now is the time to reference it in the :require part of your namespace.
- It's often a good idea to start by writing some of the smaller functions. Simple functions that take a keyword and output a string containing either an opening tag or a closing tag would be convenient, for example. You'll need the name function for converting a keyword into a string.
A good choice for this would be the function that will accept a map, such as {:class "my-css-class"}, and return a properly formatted set of HTML attributes: class="my-css-class". Don't forget to handle the case of Boolean attributes too. Remember that a Clojure map can be read as a sequence of key-value pairs. And don't forget to put quotes around the values. A string containing a single escaped quotation mark looks this: """.
It might be useful to have a predicate function to determine whether the second element in a vector is an attribute map.
When parsing a vector, you'll know that the first element is a keyword. The second element might be a map if there are attributes, but it might not. Use the map? predicate to test that.
- The fun part will be writing the recursive function. We won't say much about that, except that the basic tree walking pattern that we used in the "Europe by train" example should provide you with a rough base. You won't be able to use recur because you need to handle a real tree.
There are a lot of different kinds of elements that you need to handle, in addition to string content. In cases like this, it is often a good idea to write very clear predicates that you will use when deciding how to handle an element, such as singleton-with-attrs?, for example. These will be useful when writing the conditional part of your recursive function.
Upon completing the activity, you will be able to test your code with an input of your choice. You should see an output similar to the following:

Figure 6.9: Expected output
Note
The solution to this activity can be found on page 696.
Summary
We've covered a lot of ground in this chapter. Recursion in Clojure, as in many functional languages, is a central concept. On the one hand, it can be necessary for some fairly simple looping situations. In those cases, recur, whether used with loop or in a recursive function, can almost be seen as just "Clojure's syntax for looping." Understanding tail recursion is important for avoiding mistakes, but otherwise, it is relatively simple. On the other hand, recursion can be an extremely powerful way of solving complex problems. If it makes your head spin from time to time, that's normal: recursion is more than just a technique. It's a way of thinking about problem solving. Don't worry, though. In the next chapter, you are going to be able to practice your recursion skills some more!
In the next chapter, we will continue exploring the recursive techniques and focus on lazy evaluation.