
Chapter
4
Step Definitions: From the Outside
Now that you know how to use Gherkin to describe what you want your tests to do, the next task is to tell them how to do it. Whether you choose to drive your acceptance tests from Cucumber scenarios or simple Test::Unit scripts, there’s no escaping the fact that you’re going to need to write some code eventually. It’s about that time.
Step definitions sit right on the boundary between the business’s domain and the programmer’s domain. They’re written in Ruby,[11] and their responsibility is to translate each plain-language step in your Gherkin scenarios into concrete actions in Ruby code. As an example, take this step from the ATM scenario in the previous chapter:
| | Given I have $100 in my Account |
The step definition for this step needs to make the following things happen:
-
Create an account for the protagonist in the scenario (if there isn’t one already).
-
Set the balance of that account to be $100.
How exactly those two goals are achieved depends a great deal on your specific application. Automated acceptance tests generally try to simulate user interactions with the system, and the step definitions are where you’ll tell Cucumber how you want it to poke around with your system. That might involve clicking buttons on a user interface or reaching beneath the covers and directly inserting data into a database, writing to files, or even calling a web service. We think of step definitions themselves as distinct from the automation code that does the actual poking so that the layers separate out like Figure 3, Step definitions are translators.
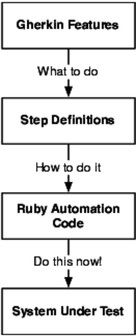
Figure 3. Step definitions are translators.
There are two sides to a step definition. On the outside, it translates from plain language into Ruby, and on the inside it tells your system what to do using Ruby automation code. Ruby has an incredibly rich set of libraries for automating a whole variety of systems, from JavaScript-heavy web applications to REST web services. We’re not going to show you how to use all of those libraries in this chapter; that will come later in the book. Here we’re going to concentrate on the main responsibility of this layer of your Cucumber tests, which is to interpret a plain-language Gherkin step and decide what to do.
We’re going to start by explaining some of the mechanics of how step definitions match up to plain-language steps and then work through an example of how to write a single step definition that can handle many different steps. We’ll finish off by explaining how Cucumber executes step definitions and deals with their results. When we’re done, you should understand enough to start writing and running your own step definitions.