
Many programming languages assume the availability of garbage collection. This has led to the development of various means for interacting with the collector in ways that extend the basic semantics of programming language memory management. For example, a program might want to be informed and take some action when a given object is about to be, or has been, reclaimed. We describe such finalisation mechanisms in Section 12.1. Conversely, it is sometimes helpful to support references that do not of themselves force an object to be retained. We consider such weak pointer mechanisms in Section 12.2.
Automatic storage reclamation with a garbage collector provides the appropriate semantics for most objects. However, if a managed object refers to some other resource that lies outside the scope or knowledge of the collector, automatic garbage collection does not help, and in fact can lead to resource leaks that are hard to fix. A typical case is open files. The interface to the operating system usually represents each open file with a small integer called a file descriptor, and the interface limits the number of files that a given process may have open at one time. A language implementation will generally have, for each open file, an object that the programmer uses to manage that file stream. Most of the time it is clear when a program has finished with a given file stream, and the program can ask the run-time system to close the stream, which can close the corresponding file descriptor at the operating system interface, allowing the descriptor number to be reused.
But if the file stream is shared across a number of components in a program, it can be difficult to know when they have all finished with the stream. If each component that uses a given stream sets its reference to the stream to null when the component is finished with the stream, then when there are no more references the collector can (eventually) detect that fact. We show such a situation in Figure 12.1. Perhaps we can arrange for the collector somehow to cause the file descriptor to be closed.
To do so, we need the ability to cause some programmer-specified action to happen when a given object becomes no longer reachable — more specifically, when it is no longer reachable by any mutator. This is called finalisation. A typical finalisation scheme allows the programmer to indicate a piece of code, called a finaliser, that is to be run when the collector determines that a particular object is no longer mutator reachable. The typical implementation of this has the run-time system maintain a special table of objects for which the programmer has indicated a finaliser. The mutators cannot access this table, but the collector can. We call an object finaliser-reachable if it is reachable from this table but not from mutator roots. In Figure 12.2 we show the previous situation but with a finaliser added. The finaliser’s call to close the descriptor is conditional, since the application may have already closed the file.
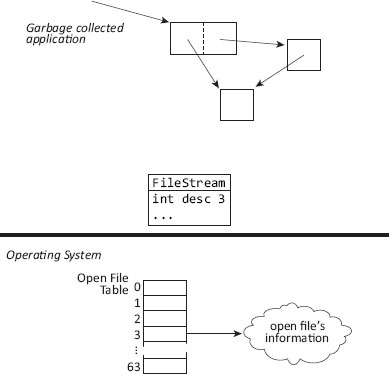
Figure 12.1: Failure to release a resource: a FileStream object has become unreachable, but its file descriptor has not been closed.
In a reference counting system, before freeing an object the collector checks the finalisation table to see if the object requires finalisation. If it does, then the collector causes the finaliser function to run, and removes the object’s entry in the finalisation table. Similarly, in a tracing system, after the tracing phase the collector checks the finalisation table to see if any untraced object has a finaliser, and if so, the collector causes the finaliser to run, and so on.
There are a range of subtly different ways in which finalisation can work. We now consider some of the possibilities and issues.
At what time do finalisers run? In particular, finalisation might occur during collection, as soon as the collector determines the need for it. However, the situation during collection might not support execution of general user code. For example, it may not be possible for user code to allocate new objects at this time. Therefore most finalisation approaches run finalisers after collection. The collector simply queues the finalisers. To avoid the need to allocate space for the queue during collection, the collector can partition the finalisation table into two portions, one for objects queued for finalisation and one for objects that have a finaliser but are not yet queued. When the collector enqueues an object for finalisation, it moves that queue entry to the enqueued-objects partition. A simple, but possibly inefficient, approach is to associate an enqueued flag with each entry and have the finalisation activity scan the finalisation table. To avoid scanning, we can group the enqueued objects together in the table, perhaps permuting entries when the collector needs to enqueue another object.

Figure 12.2: Using a finaliser to release a resource: here, an unreachable FileStream object has a finaliser to close the descriptor.
In general, finalisers affect shared state; there is little reason to operate only on finalisable objects since they are about to disappear. For example, finalisers may need to access some global data to release a shared resource, and so often need to acquire locks. This is another reason not to run finalisers during collection: it could result in a deadlock. Worse, if the run-time system provides re-entrant locks — locks where the same thread can acquire a lock that it already holds — we can have the absence of deadlock and silent corruption of the state of the application.1
Even assuming that finalisers run after collection, there remain several options as to exactly when they run. One possibility is immediately after collection, before mutator thread(s) resume. This improves promptness of finalisation but perhaps to the detriment of mutator pause time. Also, if finalisers communicate with other threads, which remain blocked at this time, or if finalisers compete for locks on global data structures, this policy could lead to communication problems or deadlock.
A last consideration is that it is not desirable for a language’s specification of finalisation to constrain the possible collection techniques. In particular, collection on the fly, concurrent with mutation, most naturally leads to running finalisers at arbitrary times, concurrent with mutator execution.
Which thread runs a finaliser?
In a language that permits multiple threads, the most natural approach is to have a background finalisation thread run the enqueued finalisers asynchronously with the mutator threads. In this case finalisers may run concurrently with mutators and must therefore be safe for concurrent execution. Of particular concern is the possibility that a finaliser for an object of type T might run at the same time as the allocation and initialisation code for a new instance of T. Any shared data structures must therefore be synchronised to handle that case.2
In a single-threaded language, which thread runs a finaliser is not a question — though it does reraise the question of when finalisers run. Given the difficulties previously mentioned, it appears that the only feasible and safe way, in general, to run finalisers in a single-threaded system is to queue them and have the program run them under explicit control. In a multithreaded system, as previously noted it is best that distinct finalisation threads invoke finalisers, to avoid issues around locks.
Can finalisers run concurrently with each other?
If a large concurrent application uses finalisers, it may need more than one finalisation thread in order to be scalable. Thus, from the standpoint of language design it appears better to allow finalisers to run concurrently with each other, as well as concurrently with mutators. Since, in general, programmers must code finalisers carefully so that they operate correctly in the face of concurrency — because finalisers are essentially asynchronous with respect to mutator operations — there should be no additional problem with running finalisers concurrently with each other.
Can finalisers access the object that became unreachable?
In many cases it is convenient for a finaliser to access the state of the object being reclaimed. In the file stream example, the operating system file descriptor number, a small integer, might most conveniently be stored as a field in the file stream object, as we showed in Figure 12.2. The simplest finaliser can read that field and call on the operating system to close the file (possibly after flushing a buffer of any pending output data). Notice that if the finaliser does not have access to the object, and is provided no additional data but is just a piece of code to run, then finalisation will not be very useful — the finaliser needs some context for its work. In a functional language, this context may be a closure; in an object-oriented language it may be an object. Thus the queuing mechanism needs to provide for the passing of arguments to the finaliser.
On balance it seems more convenient if finalisers can access the object being finalised. Assuming finalisers run after collection, this implies that objects enqueued for finalisation survive the collection cycle in which they are enqueued. So that finalisers have access to everything they might need, the collector must also retain all objects reachable from objects enqueued for finalisation. This implies that tracing collectors need to operate in two passes. The first pass discovers the objects to be finalised, and the second pass traces and preserves objects reachable from the finaliser queue. In a reference counting collector the system can increment the object’s reference count as it enqueues it for finalisation, that is, the finalisation queue’s reference to the object ‘counts’. Once the object is dequeued and its finaliser runs, the reference count will become zero and the object can be reclaimed. Until then, objects reachable from it will not even be considered for reclamation.
When are finalised objects reclaimed?
The fact that finalisers usually hold a reference to the object being finalised means that they might store that reference in a global data structure. This has been called resurrection. In a mechanical sense resurrection is not a problem, though it may be surprising to the programmer. Since it is probably difficult to detect stores that resurrect objects, and since setting up an object for future finalisation tends to happen as part of allocation and initialisation, resurrected objects will generally not be re-finalised. Java, for example, guarantees that an object will not be finalised more than once. A language design in which setting up finalisation works more dynamically might allow the programmer to request finalisation for a resurrected object — because it allows such requests for any object.

Figure 12.3: Object finalisation order. Unreachable BufferedStream and FileStream objects, which must be finalised in that order.
If a finalised object is not resurrected, then the next collection cycle can reclaim it. In a system with partitioned spaces, such as a generational collector, the finalised object might reside in a space that will not be collected again for a long time, so making it available to the finaliser can substantially extend the object’s physical lifetime.
What happens if there is an error in a finaliser?
If finalisation is run synchronously at times known to the application, then programmers can easily wrap finalisation actions with recovery handlers for when a finaliser returns an error or throws an exception. If finalisers run asynchronously then it may be best to catch and log exceptions for later handling by the application at an appropriate time. This is more a concern of software engineering than of garbage collection algorithm or mechanism.
Is there any guaranteed order to finalisation?
Finalisation order can matter to an application. For example, consider a BufferedStream object connected to a FileStream that holds an open operating system file descriptor, as shown in Figure 12.3. Both objects may need finalisers, but it is important to flush (write) the buffer of the BufferedStream before closing the file descriptor.3
Clearly, in a layered design like this, the sensible semantics will finalise from higher layers to lower. In this case, because the lower level object is reachable from the higher level one, it is possible for finalisation to occur in the sensible order automatically. Notice that if we impose order on finalisations, ultimate finalisation may be slow, since we finalise only one ‘level’ in the order at each collection. That is, in a given collection we finalise only those unreached objects that are not themselves reachable from other unreached objects.

Figure 12.4: Restructuring to force finalisation order in cyclic object graphs
This proposal has a significant flaw: it does not handle cycles of unreachable objects where more than one needs finalisation. Given that such cases appear to be rare, it seems simpler and more helpful to guarantee finalisation in order of reachability; that is, if B is reachable from A, the system should invoke the finaliser for A first.
In the rare case of cycles, the programmer will need to get more involved. Mechanisms such as weak references (see Section 12.2) may help, though using them correctly may be tricky. A general technique is to separate out fields needed for finalisation in such a way as to break the cycle of objects needing finalisation, as suggested by Boehm [2003]. That is, if A and B have finalisers and cross reference each other as shown in Figure 12.4a, we can split B into B and B′, where B does not have a finaliser but B′ does (see Figure 12.4b). A and B still cross reference each other, but (importantly) B′ does not refer to A. In this scenario, finalisation in reachability order will finalise A first and then B′.
Lest we think that finalisation can be used straightforwardly without risk of subtle bugs, even in the case of objects not requiring special finalisation order there is a subtle kind of race condition that can arise [Boehm, 2003]. Consider the FileStream example shown in Figure 12.2. Suppose that the mutator is making its last call to write data to the file. The writeData method of FileStream may fetch the descriptor, and then as its last action call write on the descriptor, passing the data. Significantly, at this point the method’s reference to the FileStream object is dead, and the compiler may optimise it away. If collection happens during the call to write, the finaliser on FileStream may run and close the file, before write actually invokes the operating system to write the data. This is a difficult problem and Boehm’s experience is that the bug is pervasive, but rarely incurred because the window of vulnerability is short.
One fix for this is the Java rule that we mentioned previously that an object must be considered live whenever its lock is held and a finaliser could run that requires synchronisation on the object. A more general way to avoid the race is to force the compiler to retain the reference to the FileStream longer. The trick to doing this is to pass the FileStream reference in a later call (to a routine that does nothing) that the compiler cannot optimise away. The .NET framework and C# (for example) provide a function for this called GC.KeepAlive. At present Java does not provide a similar call.
Algorithm 12.1: Process finalisation queue
1 process_finalisation_queue():
2 while not isEmpty(Queue)
3 while not isEmpty(Queue)
4 obj ← remove(Queue)
5 obj.finalize()
6 if desired | /* whatever condition is appropriate */ |
7 collect()
As noted, for example by Boehm [2003], the purpose of a finaliser is usually to update some global data structure in order to release a resource connected with the object that becomes unreachable. Since such data structures are global, they generally require synchronised access. In cases such as closing open file handles, some other software component (in this case, the operating system) handles the synchronisation implicitly, but for data structures within the program, it must be explicit. The concern is that, from the standpoint of most code in the program, finalisers are asynchronous.
There are two general approaches a programmer can take to the situation. One is to apply synchronisation to all operations on the global data structure — even in the single threaded case (because a finaliser could run in the middle of a data structure operation otherwise). This counts on the underlying implementation not to elide synchronisation on an apparently private object if that object has a finalisation method. The other approach is to arrange for the collector only to queue the object for finalisation, but not to begin the actual finalisation work. Some language implementations offer such queueing mechanisms as built-in features; if a particular implementation does not, then the programmer can code the finalisation method so that all it does is place the object in a programmer-defined queue. In the queueing approach, the programmer will add code to the program, at desirable (that is, safe) points. The code will process any enqueued objects needing finalisation. Since running finalisers can cause other objects to be enqueued for finalisation, such queue-processing code should generally continue processing until the queue is empty, and may want to force collections if it is important to reclaim resources promptly. Suitable pseudocode appears in Algorithm 12.1. As previously noted, the thread that runs this algorithm should not be holding a lock on any object to be finalised, which constrains the places where this processing can proceed safely.
The pain involved in this approach is the need to identify appropriate places in the code at which to empty the finalisation queue. In addition to sprinkling enough invocations throughout the code, the programmer must also take care that invocations do not happen in the middle of other operations on the shared data structures. Locks alone cannot prevent this, since the invoking thread may already hold the lock, and thus can be allowed to proceed. This is the source of the statement in the Java Language Specification that the system will invoke finalize methods only while holding no user-visible locks.
Finalisation in particular languages
Java. The Object class at the top of the Java class hierarchy provides a method named finalize, which does nothing. Any subclass can override the method to request finalisation. Java does not guarantee finalisation order, and with respect to concurrency says only that finalisation runs in a context starting with no (user-visible) synchronisation locks held. This pretty much means that finalisation runs in one or more separate threads, even though the specification is not quite worded that way. If finalize throws an exception, the Java system ignores it and moves on. If the finalised object is not resurrected, a future collection will reclaim it. Java also provides support for programmer-controlled finalisation through appropriate use of the java.lang.ref API, as we describe in Section 12.2.
Lisp. Liquid Common Lisp offers a kind of object called a finalisation queue. The programmer can register an ordinary object with one or more finalisation queues. When the registered object becomes otherwise unreachable, the collector enters it into the finalisation queues with which it was registered. The programmer can extract objects from any finalisation queue and do with them what she will. The system guarantees that if objects A and B are both registered and become unreachable in the same collection, and B is reachable from A but not vice versa, then the collector will enter A in the finalisation queue before it enters B. That is, it guarantees order of finalisation for acyclic object graphs. The finalisation queues of Liquid Common Lisp are similar to the guardians described by Dybvig et al [1993].
CLisp offers a simpler mechanism: the programmer can request that the collector call a given function f when it detects that a given object O is no longer reachable. In this case f must not refer to O or else O will remain reachable and the system will never call the finaliser. Since f receives O as an argument, this system permits resurrection. Also, f could register O again, so O can be finalised more than once. A variant of the basic mechanism allows the programmer to specify a guardian G in addition to the object O and function f. In this case, when O becomes unreachable the system calls f only if G is still reachable. If at this time G is unreachable, then the system reclaims O but does not call f. This can be used to implement guardians of the kind described by Dybvig et al [1993] — f can add O to the internal queue of G.
C++. The C++ language offers destructors to handle disposal of objects, as a converse to constructors which initialise new objects. The primary role of most destructors is to cause explicit freeing of memory and its return to the allocator for reuse. However, since programmers can offer any code they want, C++ destructors can handle the case of closing a file, and so forth. Destructors also provide a hook through which a programmer can support reference counting to reclaim (acyclic) shared data structures. In fact, C++ templates allow a general smart pointer mechanism to drive the reference counting. But this shows again that destructors are mostly about reclaiming memory — a job that a garbage collector already handles. Thus, true finalisation remains relatively rare, even for C++. The memory reclamation aspect of destructors is relatively safe and straightforward, not least because it does not involve user-visible locks. However, as soon as the programmer veers into the realm of ‘true’ finalisation, all the issues we mention here arise and are dropped into the programmer’s lap. This includes dealing with locking, order of invocation of finalisers, and so on. Placing the responsibility for all this on the programmer’s shoulders makes it difficult to ensure that it is done correctly.
.NET. The .NET framework adds finalisers to the existing notion of destructors in C, C++, and the other languages supported by the framework. Destructors are called deterministically, starting with compiler-generated code for cleaning up objects as they go out of scope. A destructor may call other objects’ destructors, but all destructors are concerned with reclaiming managed resources, that is, resources known to the language and .NET runtime system, primarily memory. Finalisers, on the other hand, are for explicitly reclaiming unmanaged resources, such as open file handles and the like. If a kind of object needs finalisation, then the destructor should call the finaliser, to cover the case when the object is reclaimed explicitly by compiler-generated code. However, the collector will call the finaliser if the object is being reclaimed implicitly, that is, by the collector. In that case the destructor will not be called. In any case, the finalisation mechanism itself is very similar to that of Java. The end result is a mixture of C++ destructors and something close to Java finalisation, with both synchronous and asynchronous invocation of finalisers possible.
Various languages have supported finalisation for decades, and have evolved mechanisms suitable to their contexts. Systematic consideration of the issues and various design approaches across several languages appears more recently in the literature in works such as Hudson [1991] and Hayes [1992]. More careful inspection of the semantics of finalisation and some of the thorny problems at its heart was performed by Boehm [2003], to whom we are indebted as a primary source.
Garbage collection determines which memory to retain and which to reclaim using reachability through chains of pointers. For automatic reclamation this is a sound approach. Still, there are a number of situations in which it is problematic.
For example, in a compiler it can be useful to ensure that every reference to a given variable name, say xyz, uses exactly the same string instance. Then, to compare two variable names for equality it suffices to compare their pointers. To set this up, the compiler builds a table of all the variable names it has seen so far. The strings in the table are the canonical instances of the variable names, and such tables are therefore sometimes called canonicalisation tables. But consider what happens if some names fall into disuse as the compiler runs. There are no references to the names from other data structures, but the canonical copy remains. It would be possible to reclaim a string whose only reference is from the table, but the situation is difficult for the program to detect reliably.
Weak references (also called weak pointers) address this difficulty. A weak reference continues to refer to its target so long as the target is reachable from the roots via a chain consisting of ordinary strong references. Such objects are called strongly reachable. However, if every path from roots to an object includes at least one weak reference, then the collector may reclaim the object and set any weak reference to the object to null. Such objects are called weakly-reachable. As we will see, the collector may also take additional action, such as notifying the mutator that a given weak reference has been set to null.
In the case of the canonicalisation table for variable names, if the reference from the table to the name is a weak reference, then once there are no ordinary references to the string, the collector can reclaim the string and set the table’s weak reference to null. Notice that the table design must take this possibility into account, and it may be necessary or helpful for the program to clean up the table from time to time. For example, if the table is organised by hashing with each hash bucket being a linked list, defunct weak references result in linked list entries whose referent is null. We should clean those out of the table from time to time. This also shows why a notification facility might be helpful: we can use it to trigger the cleaning up.
Below we offer a more general definition of weak references, which allows several different strengths of references, and we indicate how a collector can support them, but first we consider how to implement just two strengths: strong and weak. First, we take the case of tracing collectors. To support weak references, the collector does not trace the target of a weak reference in the first tracing pass. Rather, it records where the weak pointer is, for processing in a second pass. Thus, in the first tracing pass the collector finds all the objects reachable via chains of strong references only, that is, all strongly reachable objects. In a second pass, the collector examines the weak references that it found and noted in the first pass. If a weak reference’s target was reached in the first pass, then the collector retains the weak reference, and in copying collectors it updates the weak reference to refer to the new copy. If a weak reference’s target was not reached, the collector sets the weak reference to null, thus making the referent no longer reachable. At the end of the second pass, the collector can reclaim all unreached objects.
The collector must be able to identify a weak reference. It may be possible to use a bit in the reference to indicate that it is weak. For example, if objects are word-aligned in a byte-addressed machine, then pointers normally have their low two bits set to zero. One of those bits could indicate a weak reference if the bit is set to one. This approach has the disadvantage that it requires the low bits to be cleared before trying to use a reference that may be weak. That may be acceptable if weak references arise only in certain restricted places in a given language design. Some languages and their implementations may use tagged values anyway, and this simply requires one more possible tag value. Another disadvantage of this approach is that the collector needs to find and null all weak references to objects being reclaimed, requiring another pass over the collector roots and heap, or that the collector remember from its earlier phases of work where all the weak pointers are.
An alternative to using low bits is to use high order bits and double-map the heap. In this case every heap page appears twice in the virtual address space, once in its natural place and again at a high memory (different) address. The addresses differ only in the value of a chosen bit near the high-order end of the address. This technique avoids the need to mask pointers before using them, and its test for weakness is simple and efficient. However, it uses half the address space, which may make it undesirable except in large address spaces.
Perhaps the most common implementation approach is to use indirection, so that specially marked weak objects hold the weak references. The disadvantage of the weak object approach is that it is less transparent to use — it requires an explicit dereferencing operation on the weak object — and it imposes a level of indirection. It also requires allocating a weak object in addition to the object whose reclamation we are trying to control. However, an advantage is that weak objects are special only to the allocator and collector — to all other code they are like ordinary objects. A system can distinguish weak objects from ordinary ones by setting a particular bit in the object header reserved for that purpose. Alternatively, if objects have custom-generated tracing methods, weak objects will just have a special one.
How does a programmer obtain a weak reference (weak object) in the first place? In the case of true weak references, the system must supply a primitive that, when given a strong reference to object O, returns a weak reference to O. In the case of weak objects, the weak object types likewise supply a constructor that, given a strong reference to O, returns a new weak object whose target is O. It is also possible for a system to allow programs to change the referent field in a weak object.
Canonicalisation tables are but one example of situations where weak references of some kind help solve a programming problem, or solve it more easily or efficiently. Another example is managing a cache whose contents can be retrieved or rebuilt as necessary. Such caches embody a space-time trade-off, but it can be difficult to determine how to control the size of a cache. If space is plentiful, then a larger size makes sense, but how can a program know? And what if the space constraints change dynamically? In such situations it might be useful to let the collector decide, based on its knowledge of available space. The result is a kind of weak reference that the collector may set to null if the referent is not strongly reachable, if it so desires. It can make the judgement based on the space consumed by the weakly reachable objects in question.
It is sometimes useful is to let a program know when an object is weakly reachable but not strongly reachable, and to allow it to take some action before the collector reclaims the object. This is a generalisation of finalisation, a topic we took up in Section 12.1. Among other things, suitable arrangements of these sorts of weak references can allow better control of the order in which the program finalises objects.
Supporting multiple pointer strengths
Weak references can be generalised to provide multiple levels of weak pointers in addition to strong references. These levels can be used to address the issues described above. A totally ordered collection of strengths allows each strength level to be associated with a positive integer. For a given integer α > 0, an object is α*-reachable if it can be reached by a path of references where each reference has strength at least α. An object is α-reachable (without the superscript*) if it is α*-reachable but not (α + 1)*-reachable. An object is α-reachable if every path to it from a root includes at least one reference of strength α, and at least one path includes no references of strength less than α. Below we will use the names of strengths in place of numeric values; the values are somewhat arbitrary anyway, since what we rely on is the relative order of the strengths. Also, for gracefulness of expression, we will say Weakly-reachable instead of Weak-reachable, and so on.
Each level of strength will generally have some collector action associated with it. The best-known language that supports multiple flavours of weak reference is Java; it provides the following strengths, from stronger to weaker.4 Tomoharu et al [2014] provide a formal definition.
Strong: Ordinary references have the highest strength. The collector never clears these.
Soft: The collector can clear a Soft reference at its discretion, based on current space usage. If a Java collector clears a Soft reference to object O (that is, sets the reference to null), it must at the same time atomically5 clear all other Soft references from which O is Strongly-reachable. This rule ensures that after the collector clears the reference, O will no longer be Softly-reachable.
Weak: The collector must clear a (Softly*-reachable) Weak reference after determining that its referent is Weakly-reachable (and thus not Softly*-reachable). As with Soft references, if the collector clears a Weak reference to O, it must simultaneously clear all other Softly*-reachable Weak references from which O is Softly*-reachable.
Finaliser: We term a reference from the table of objects with finalisers to an object that has a finaliser a finaliser reference. We described Java finalisation before, but list it here to clarify the relative strength of this kind of weak reference, even though it is internal to the run-time system as opposed to a weak object exposed to the programmer.
Phantom: These are the weakest kind of weak reference in Java. The program must explicitly clear a Phantom for the collector to reclaim the referent. It makes sense to use this only in conjunction with notification, since the Phantom Reference object does not allow the program to obtain a reference to the Phantom’s referent — it only permits clearing of the referent.
The point of the different strengths in Java is not so much the levels of strength, but the special semantics associated with each kind of weak reference that the language specification defines. Soft references allow the system to shrink adjustable caches. Weak references help with canonicalisation tables and other constructs. Phantom references allow the programmer to control the order and time of reclamation.
Implementing multiple strengths requires multiple additional passes in the collector cycle, but they typically complete quickly. We use Java’s four strengths as an example, and describe the actions for a copying collector — a mark-sweep collector would be similar, though simpler. We consider reference counting collectors afterwards. The passes the collector must make are as follows.
1. Working from the roots, trace and copy all Strongly-reachable objects, noting (but not tracing through) any Soft, Weak, or Phantom objects found.
2. Optionally, clear all Soft references atomically.6 If we chose not to clear Soft references, then trace and copy from them, finding all Softly*-reachable objects, continuing to note any Weak or Phantom objects found by tracing through Soft objects.
3. If the target of any Weak object noted previously has been copied, update the Weak object’s pointer to refer to the new copy. If the target has not been copied, clear the Weak object’s pointer.
4. If any object requiring finalisation has not yet been copied, enqueue it for finalisation. Go back to Step 1, treating the objects newly enqueued for finalisation as new roots. Notice that in this second round through the algorithm there can be no additional objects requiring finalisation.7
5. If the referent of any Phantom object noted previously has not yet been copied, then enqueue the Phantom on its ReferenceQueue. In any case, trace and copy all Phantom* -reachable objects, starting from the Phantom’s target. Notice that the collector cannot clear any Phantom object’s pointer — the programmer must do that explicitly.
While we worded the steps as for a copying collector, they work just as well for mark-sweep collection. However, it is more difficult to construct a reference counting version of the Java semantics. One way to do this is not to count the references from Soft, Weak and Phantom objects in the ordinary reference count, but rather to have a separate bit to indicate if an object is a referent of any of these Reference objects. It is also convenient if an object has a separate bit indicating that it has a finaliser. We assume that there is a global table that, for each object O that is the referent of at least one Reference object, indicates those Reference objects that refer to O. We call this the Reverse Reference Table.
Since reference counting does not involve separate invocations of a collector, some other heuristic must be used to determine when to clear all Soft references, which must be done atomically. Given that approach, it seems easiest to count Soft references as ordinary references which, when they are cleared using the heuristic, may trigger reclamation, or processing of weaker strengths of pointers.
When an object’s ordinary (strong) reference count drops to zero, the object can be reclaimed (and the reference counts of its referents decrements) unless it is the referent of a Reference object and requires finalisation. If the object’s bits indicate that it is the referent of at least one Reference, we check the Reverse Reference Table. Here are the cases for handling the Reference objects that refer to the object whose ordinary reference count went to zero; we assume they are processed from strongest to weakest.
Weak: Clear the referent field of the WeakReference and enqueue it if requested.
Finaliser: Enqueue the object for finalisation. Let the entry in the finalisation queue count as an ordinary reference. Thus, the reference count will go back up to one. Clear the object’s ‘I have a finaliser’ bit.
Phantom: If the referent has a finaliser, then do nothing. Otherwise, enqueue the Phantom. In order to trigger reconsideration of the referent for reclamation, increment its ordinary reference count and mark the Phantom as enqueued. When the Phantom’s reference is cleared, if the Phantom has been enqueued, decrement the referent’s ordinary reference count. Do the same processing when reclaiming a Phantom reference.
There are some more special cases to note. When we reclaim a Reference object, we need to remove it from the Reverse Reference Table. We also need to do that when a Reference object is cleared.
A tricky case is when a detector of garbage cycles finds such a cycle. It appears that, before doing anything else, we need to see if any of the objects is the referent of a Soft object, and in that case retain them all, but keep checking periodically somehow. If none are Soft referents but some are Weak referents, then we need to clear all those Weak objects atomically, and enqueue any objects requiring finalisation. Finally, if none of the previous cases apply but there are some Phantom referents to the cycle, we need to retain the whole cycle and enqueue the Phantoms. If no object in the cycle is the referent of a Reference object or requires finalisation, we can reclaim the whole cycle.
Using Phantom objects to control finalisation order
Suppose we have two objects, A and B, that we wish to finalise in that order. One way to do this is to create a Phantom object A′, a Phantom reference to A. In addition, this Phantom reference should extend the Java PhantomReference class so that it holds an ordinary (strong) reference to B in order to prevent early reclamation of B.8 We illustrate this situation in Figure 12.5.
When the collector enqueues A′, the Phantom for A, we know not only that A is unreachable from the application, but also that the finaliser for A has run. This is because reachability from the table of objects requiring finalisation is stronger than Phantom reachability. Then, we clear the Phantom reference to A and null the reference to B. At the next collection the finaliser for B will be triggered. We further delete the Phantom object itself from the global table, so that it too can be reclaimed. It is easy to extend this approach to ordered finalisation of three or more objects by using a Phantom between each pair of objects with a finalisation order constraint.

Figure 12.5: Finalising in order. Application objects A and B are unreachable from the application and we want to finalise them in that order. Phantom A′ has a phantom reference to A and a strong reference to B.
We need Phantoms — Weak objects are not enough. Suppose we used an arrangement similar to that of Figure 12.5. When A is no longer reachable, the weak reference in A′ will be cleared and A′ will be enqueued. We can then clear the reference from A′ to B. Unfortunately, the clearing of the weak reference to A happens before the finaliser for A runs, and we cannot easily tell when that finaliser has finished. Therefore we might cause the finaliser for B to run first. Phantoms are intentionally designed to be weaker than finalisation reachability, and thus will not be enqueued until after their referent’s finaliser has run.
We note that, just as certain compiler optimisations can lead to a race that can cause premature finalisation, the same situations can lead to premature clearing of weak pointers. We described the finalisation case in Section 12.1.
Notification of weak pointer clearing
Given a weak reference mechanism, the program may find it useful to know when certain weak references are cleared (or, in the case of Phantoms, could be cleared), and then to take some appropriate action. To this end, weak reference mechanisms often also include support for notification. Generally this works by inserting the weak object into a queue. For example, Java has a built-in class ReferenceQueue for this purpose, and a program can poll a queue or use a blocking operation to wait (with or without a timeout). Likewise a program can check whether a given weak object is enqueued (Java allows a weak object to be enqueued on at most one queue). It is straightforward to add the necessary enqueuing actions to the collector’s multi-pass processing of weak pointers described above. A number of other languages add similar notification support.
Weak pointers in other languages
We discussed Java separately because of its multiple strengths of weak references. Other languages offer alternative or additional weak reference features.
A number of Lisp implementations support weak arrays and vectors.9 These are simply multi-entry weak objects: when a referent O is no longer strongly-reachable, the collector sets to nil any weak array or vector slots that refer to O.
Some Lisp implementations also support weak hash tables. These often come in three varieties. One offers weak keys, in which the keys, but not the values, are weak. In this case, once the key of a given key-value pair is no longer strongly-reachable, the collector removes the entire pair from the hash table. This is useful for things like canonicalisation tables and certain kinds of caches. A second variety offers weak values, where the collector removes the key-value pair once the value is no longer strongly-reachable. The third variety supports weak keys and values, removing the pair once either the key or the value is no longer strongly-reachable.
Some Lisp implementations support weak-AND and weak-OR objects. The elements of these objects are potentially weak, but in the following way. A weak-AND will set all its elements to nil if one or more of them becomes not-strongly-reachable. Thus, it is analogous to a Lisp AND, which returns nil if any argument to AND is nil. A weak-OR is the converse: it retains all its arguments until none of them are strongly-reachable, and then sets all of its fields to nil. We refer readers to the documentation on the Platform Independent Extensions to Common Lisp10 for more details and further generalisations, including weak associations, weak AND- and OR-mappings, weak association lists, and a version of weak hash tables similar to what we discussed above.
Ephemerons [Hayes, 1997]11 are a particular form of weak key-value pairs useful for maintaining information attached to other objects. Suppose we wish to associate information I with object O through a side table. We can use an ephemeron with key O and value I. The semantics of an ephemeron are as follows. Its reference to the key is weak. Its reference to the value is strong while the key is non-null, but is weak after the key is set to null. In the example, the reference to the base object O is weak, and initially the reference to the associated information I is strong. Once O is reclaimed and the weak reference to it is set to null, the reference to I is treated as weak. Thus, I is not reclaimable while O is alive, but may become reclaimable once O has gone. A weak-key/strong-value pair with notification (to allow the value reference to be set to null, or to be replaced with a weak reference to the value) more or less simulates an ephemeron. A subtle difference, though, is that it does not ‘count’ toward reachability of the ephemeron’s key if it is reachable from the ephemeron’s value. Thus, if I refers to O, as it well might, an ephemeron can still collect O but the weak-pair approach would prevent O from being reclaimed. The only way around this without ephemerons would seem to be to ensure that any path from I to O includes a weak reference.
Here is a sketch of how to implement ephemerons (ignoring any other forms of weak pointers or other finalisation mechanisms). First, trace through strong pointers from the roots, recording ephemerons but not tracing through them. Iterate over the recorded ephemerons repeatedly. If an ephemeron’s key has been traced, then trace through the ephemeron’s value field and remove the ephemeron from the set of recorded ephemerons. Such tracing may reach other ephemerons’ keys, and may also find new ephemerons to consider. Eventually we obtain a set, possibly empty, of ephemerons that we have recorded whose keys are not reachable. We clear the key fields of these ephemerons, and the value fields if the value object is not yet traced. Alternatively, we can use a notification mechanism and enqueue the ephemerons, at the risk of possible object resurrection. It may be better to clear the ephemeron’s fields and enqueue a new pair that presents the key and the value to a finalisation function.
Various other languages have weak pointer support, at least in some implementations. These languages include ActionScript, C++ (for example, the Boost library), Haskell, JavaScript, OCAML, python, and Smalltalk. There has also been at least one attempt to give a formal semantics for the feature [Donnelly et al, 2006].
While we have termed finalisation and weak pointers ‘language-specific’ concerns, they are now largely part of the accepted landscape of automatic memory management. Automatic management is a software engineering boon, enabling easier construction of more complex systems that work correctly, but various specific problems motivate finalisation and weak pointers as extensions to language semantics — extensions that have been introduced precisely because of the assumption that memory will be managed automatically.
If the collector and run-time system implementer receive the language being implemented as a given, then many of the design considerations mentioned here have already been decided: the language is what it is. The design questions mentioned earlier, particularly with respect to choices in the design of support for finalisation, are more relevant in the context of designing a new programming language. Likewise, the varieties of weak pointer mechanisms, such as which ‘weak’ data structures to offer, how many strengths of references to support, and so on, are also more the province of language design.
Where a collector and run-time system implementer has more scope is in the choice and design of allocation and collection techniques. Here are some of the considerations of how those choices relate to the mechanisms discussed in this chapter.
• Weak pointers and finalisation tend to require additional tracing ‘passes’. These typically complete quickly — their performance is typically not of unusual concern. However, they complicate otherwise basic algorithms, and require considerable care in their design. It is best to design in the necessary support from the beginning rather than to attempt to add it on later. Needless to say, it is very important to gain a solid understanding of the semantics of the features and of how proposed implementation strategies enact those semantics.
• Some mechanisms, notably some of the ‘strengths’ of Java’s weak references, require that a whole group of related weak references be cleared at the same time. This is relatively easy to accomplish in a stop-the-world collector, but in a more concurrent setting it requires additional mechanism and care. As mentioned in earlier discussion, traversing the weak references needs to include a check of a shared flag and possibly some additional synchronisation, to ensure that collector and mutator threads make the same determination as to which weakly-referenced objects are live — they need to resolve the race between any mutator thread trying to obtain a strong reference and the collector trying to clear a group of weak references atomically. This race is by no means peculiar to Java’s weak reference mechanisms, and is a potentiality in supporting weak pointers in any concurrent setting.
• Given the concerns about atomic clearing of sets of weak references and the general complexity of weak pointer and finalisation support, it may be reasonable to handle those features in a stop-the-world phase of an otherwise concurrent collector, or at least to use locks rather than lock-free or wait-free techniques. Chapter 13 discusses these different approaches to controlling concurrent access to data structures.
• Java soft references require a collector mechanism to decide whether it is appropriate to clear them during a given collection cycle.
1Java avoids this by indicating that a finalisation thread will invoke a finaliser with no locks held. Thus the finalisation thread must be one that does not hold a lock on the object being finalised. In practice this pretty much requires finalisation threads to be distinct threads used only for that purpose.
2Java has a special rule to help prevent this: if an object’s finaliser can cause synchronisation on the object, then the object is considered mutator reachable whenever its lock is held. This can inhibit removal of synchronisation.
3As a more subtle point, note that unless we can guarantee that the FileStream is used only by the BufferedStream, then the BufferedStream should not close the FileStream. Unfortunately this implies that it may require two collection cycles before the file descriptor is closed.
4In fact, we are not aware at this time of any language other than Java that supports multiple strengths, but the idea may propagate in the future.
5By atomically the Java specification seems to mean that no thread can see just some of the references cleared: either all of them are cleared or none are. This can be accomplished by having the reference objects consult a shared flag that indicates whether the referent field should be treated as cleared, even if it is not yet set to null. The reference object can itself contain a flag that indicates whether the single global flag should be consulted, that is, whether the reference is being considered for clearing. Doing this safely requires synchronisation in concurrent collectors. On-the-fly collection is particularly complex [Tomoharu et al, 2014].
6It is legal to be more selective, but following the rules makes that difficult. Note that by ‘all’ we mean all Soft references currently in existence, not just the ones found by the collector so far.
7Barry Hayes pointed out to us that a Weak object wl might be reachable from an object x requiring finalisation, and the Weak object’s referent y might be some object also requiring finalisation, which has another Weak object w2 referring to it, that is, both wl and w2 are Weak objects that refer to y. If w2 is strongly reachable, then it will have been cleared, while wl may not be cleared yet if it is reachable only from x. This situation becomes especially strange if the finaliser for y resurrects y, since then w2 is cleared by y is now Strongly-reachable. Unfortunately the issue seems inherent in the way Java defines Weak objects and finalisation.
8Fields added in subclasses of Java’s built-in reference classes hold strong pointers, not special weak referents.
9Arrays may be multi-dimensional while vectors have only one dimension, but the distinction does not affect weak reference semantics.
11Hayes credits George Bosworth with the invention of ephemerons.