
In the previous chapter we looked at generational and other age-based collection schemes. Those algorithms partitioned objects by their age and chose a partition to collect based on some age-related property. For example, generational collectors preferentially collect the youngest partition (or generation). Although this strategy in particular is highly effective for a wide range of applications, it does not address all the problems facing the collector. In this chapter we examine schemes outside the age-based collection framework but still based on partitioning the heap.
We start by considering one of the commonest forms of segregation, allocating large objects in a separate space. We then examine collectors that partition the heap based on the topology of the object graph, before looking at possibilities for allocation on thread stacks or into scoped regions. We conclude by discussing hybrid algorithms that partition the heap and collect different spaces at different times or using different algorithms, or both.
Large object spaces are one of the most common ways to partition the heap. The definition of ‘large’ can be chosen on the basis of either the absolute size of an object (say, greater than 1024 bytes [Ungar and Jackson, 1988] or its size relative to that of the blocks used by the allocator [Boehm and Weiser, 1988]), or relative to the heap [Hosking et al, 1992]. Large objects meet several of the criteria for segregation that we identified in Chapter 8. They are more expensive to allocate and more likely to induce fragmentation, both internal and external. It is therefore worthwhile using policies and mechanisms to manage them that would be inefficient if applied to smaller ones. Allocation in a copying space is particularly expensive since additional space must also be reserved so that they can be copied. Performing the copy may also be expensive, although that cost is likely to be dominated by the cost of updating the object’s fields processing child pointers if the object is a large array of pointers. For these reasons, large object spaces are often managed by collectors that usually do not physically move their objects, although the trade-off between the performance advantages of not moving objects and the costs of fragmentation make it likely that even large objects may need to be compacted occasionally [Lang and Dupont, 1987; Hudson and Moss, 1992].
There are a number of ways in which large object spaces might be implemented and managed. The simplest is to use one of the free-list allocators described in Chapter 7 and to reclaim objects with a mark-sweep collector. It is also possible to combine a non-moving large object space with a wider range of algorithms including copying. Several implementations have separated large objects into a small (possibly fixed-size) header and a body [Caudill and Wirfs-Brock, 1986; Ungar and Jackson, 1988, 1992; Hosking et al, 1992]. The body is kept in a non-moving area, but the header is managed in the same way as other small objects. The header may also be handled by a generational garbage collector; opinions differ on whether large object headers should be promoted by the collector [Hudson et al, 1991] or not (so that the large amount of space that they occupy can be reclaimed as soon as possible after the object’s death [Ungar and Jackson, 1992]). Other Java virtual machines, including Sun’s ExactVM [Printezis, 2001], Oracle’s JRockit and Microsoft’s Marmot [Fitzgerald and Tarditi, 2000], have not used a separate space but allocated large objects directly into the old generation. Since large objects are by their nature likely to survive for some time, this approach saves copying them from the young generation.

Figure 10.1: The Treadmill collector: objects are held on a double-linked list. Each of the four segments hold objects of a different colour, so that the colour of an object can be changed by ‘unsnapping‘ it from one segment and ‘snapping’ it into another. The pointers controlling the Treadmill are the same as for other incremental copying collectors [Baker, 1978]: scanning is complete when scan meets T, and memory is exhausted when free meets B.
Jones [1996]. Reprinted by permission.
The Treadmill garbage collector
It is also possible to copy or move objects logically without moving them physically. In this section we discuss the Treadmill; in the next section we consider how to move objects with operating system support. In terms of the tricolour abstraction, a tracing garbage collector partitions heap objects into four sets: black (scanned), grey (visited but not fully scanned), white (not yet visited) and free; it processes the grey set until it is empty. Each collection algorithm provides a different way to represent these sets. The Treadmill [Baker, 1992a] provides some of the advantages of semispace copying algorithms but in a non-moving collector. Although it was intended as an incremental collector its virtues have also led it to be used in stop-the-world configurations for managing large objects.
The Treadmill is organised as a cyclic, double-linked list of objects (Figure 10.1) so that, considered anticlockwise, the black segment is followed by the grey segment then the white segment and finally the free segment. The black and grey segments comprise the tospace, and the white segment the fromspace of the heap. Four pointers are used to operate the Treadmill. Just as with Cheney’s algorithm, scan points to the start of the grey segment and divides that segment from the black one. B and T point to the bottom and top of the white fromspace list respectively, and free divides the free segment from the black segment.
Before a stop-the-world collection, all objects are black and in tospace. An object is allocated by advancing the free pointer clockwise, thus removing it from the free segment and adding it to the start of the black segment. When the free pointer meets the B pointer at the bottom of fromspace, free memory is exhausted and it is time to flip. At this point, the Treadmill contains at most two colours, black and white. The black segment is reinterpreted as white and the T and B pointers are swapped. The collector then behaves much as any semispace copying collector. As grey objects are scanned, the scan pointer is moved anticlockwise to add the object to the end of the black segment. When a white object in fromspace is visited by the collector, it is evacuated to tospace by unsnapping it from the white segment and snapping it into the grey segment. When the scan pointer meets the T pointer, the grey segment is empty and the collection is complete.
The Treadmill has several benefits. Allocation and ‘copying’ are fairly fast. A concurrent Treadmill can allocate objects of any colour simply by snapping them into the appropriate segment. As objects are not moved physically by snapping, allocation and ‘copying’ are constant time operations not dependent on the size of the object. Snapping simplifies the choice of traversal order compared with other techniques discussed in Chapter 4. Snapping objects to the end of the grey segment (before the T pointer) gives breadth-first traversal. Snapping objects at the start of the segment (at the scan pointer) gives depth-first traversal without needing an explicit auxiliary stack, although effectively a stack is embedded in the links of the Treadmill for all traversal orders.
One disadvantage of the Treadmill for general purpose collection is the per-object overhead of the two links. However, for copying collection, this overhead is offset by removing the need for any copy reserve as the Treadmill does not physically copy objects. Another issue for the Treadmill is how to accommodate objects of different sizes (see [Brent, 1989; White, 1990; Baker et al, 1985]). One solution is to use separate Treadmills for each size class [Wilson and Johnstone, 1993]. However, these disadvantages are less of an issue for large objects. Large object Treadmills (for example, as used in Jikes RVM) keep each object on its own page (or sequences of pages). If links are kept in the pages themselves, they may simply consume some of the space otherwise wasted when rounding up the size to an integral number of pages. Alternatively, the links can be stored together, outside the pages. The best reason for keeping links separate from user data is to reduce the risk of rogue code corrupting the collector’s metadata, but doing so may also reduce cache and paging overheads.
Moving objects with operating system support
It is also possible to ‘copy’ or ‘compact’ large objects without physically moving them, using support from the operating system. In this case, each large object must again be allocated to its own set of pages. Instead of copying the object word by word, its pages can be re-mapped to fresh virtual memory addresses [Withington, 1991]. It is also possible to use operating system support to initialise large objects incrementally.1 Rather than zero the space for the whole object in one step, the object’s pages can be memory protected. Any attempt to access uninitialised sections of the object will spring this trap, at which point the page in question can be zeroed and unprotected; see also our discussion of zeroing in Section 11.1.
There are good reasons for segregating typically large objects not directly related to their size. If an object does not contain any pointers, it is unnecessary to scan it. Segregation allows knowledge of whether the object is pointer-free to be derived from its address. If the mark bit for the object is kept in a side table, then it is not necessary to touch the object at all. Allocating large bitmaps and strings in their own area, managed by a specialised scanner, can lead to significant performance improvements, even if the size of the area is modest. For example, Ungar and Jackson [1988] obtained a fourfold pause time reduction by using a separate space of only 330 kilobytes, tiny by today’s standards.
One way of arranging objects in the heap is to relate their placement to the topology of pointer structures in the heap. This arrangement offers opportunities for new garbage collection algorithms, which we consider in this section.
Mature object space garbage collection
One of the goals of generational garbage collection is to reduce pause times. By and large the pause to collect the youngest generation can be bounded by controlling the size of the youngest generation. However, the amount of work done to collect the oldest generation is limited only by the volume of live data in the heap. As we saw in Chapter 9, the Beltway.X.X generational configuration [Blackburn et al, 2002] attempted to address this by collecting each belt in fixed-size increments. However, this approach trades one problem for another: cycles of garbage too large to be accommodated in a single increment cannot be reclaimed. Both Bishop [1977] and Beltway.X.X.100 add a further area/increment of unlimited size to provide a collector that is complete but that no longer bounds the work done in each collection cycle.
Hudson and Moss [1992] seek to manage a mature object space (MOS) outside an age-based scheme. They too divide this space into a number of fixed-size areas. At each collection, a single area is condemned and any survivors are copied to other areas. Hudson and Moss resolve the cycle problem by structuring the areas, which they call cars, into a number of first-in, first-out lists called trains: hence, the algorithm is colloquially known as the ‘Train collector’. As might be expected, at each collection they condemn a single car but they also impose a discipline on the destination cars to which they copy any survivors. This ensures that a garbage cycle will eventually be copied to a train of its own, all of which can be reclaimed in isolation from other trains. The algorithm proceeds as follows.
1. Select the lowest numbered car c of the lowest numbered train t as the from-car.
2. If there are no root references to t and if t’s remembered set is empty, then reclaim this train as a whole as its contents are unreachable. Otherwise…
3. Copy any object in c that is referenced by a root to a to-car c′ in a higher numbered train t′, possibly a fresh one.
4. Recursively copy objects in c that are reachable from to-car c′ to that car; if c′ is full, append a fresh car to t′.
5. Move any object promoted from the generational scheme to a train holding a reference to it.
6. Scan the remembered set of from-car c. If an object o in c is reachable from another train, copy it to that train.
7. Copy any other object reachable from other cars in this train t to the last car of t, appending a new car if necessary.
Step 2 reclaims whole trains that contain only garbage, even if this includes pointer structures (such as cycles) that span several cars of the train. As the train’s remembered set is empty, there can be no references to it from any other train. Steps 3 and 4 move into a different train all objects in the from-car that are reachable from roots via reference chains contained in this car. These objects are certainly live, and this step segregates them from any possibly-garbage objects in the current train. For example, in Figure 10.2, objects A and B in car C1, train T1 are copied to the first car of a new train T3. The last two steps start to disentangle linked garbage structures from other live structures. Step 6 removes objects from this train if they are reachable from another one: in this example, P is moved to train 2, car 2. Finally, step 7 moves the remaining potentially live objects in this car (for example, X) to the end of its train. It is essential that these steps are done in this order since a single object may be reachable from more than one train. Following step 7, any objects remaining in car c are unreachable from outside it and so this from-car is discarded, just as a semispace collector would do.
The Train algorithm has a number of virtues. It is incremental and bounds the amount of copying done at each collection cycle to the size of a single car. Furthermore, it attempts to co-locate objects with those that refer to them. Because of the discipline imposed on the order in which trains and cars are collected, it requires only references from high to low numbered trains/cars to be remembered. If it is used with a young generation collector so that all spaces outside the mature object space are collected at each cycle, no references from outside that space need be remembered.
Unfortunately, the Train collector can be challenged by several common mutator behaviours.2 Isolating a garbage structure into its own train may require a number of garbage collection cycles quadratic in the number of cars over which the structure is distributed. As presented above, the algorithm may fail to make progress in certain conditions. Consider the example in Figure 10.3a where there is insufficient room for both objects (or pointer structures) to fit in a single car. Object A will be moved to a fresh car at the end of the current train when the first car is collected. Provided that none of the pointers in this example are modified, the next collection will find an external reference to the leading car, so B will be evacuated to a higher numbered train. Similarly, the third collection will find a reference to A from B’s train and so move A there. There are no cars left in this train, so we can dispose of it. The next cycle will collect the first car of the next train, as desired. However, now suppose that, after each collection cycle, the mutator switches the external reference to the object in the second car, as in Figure 10.3b. The Train collector never discovers an external reference to the object in the leading car, and so the object will forever be moved to the last car of the current train, which will never empty. The collector can never progress to collect other trains. Seligmann and Grarup [1995] called these ‘futile’ collections. They solve the problem by remembering external pointers further down the train and using these in futile collections, thereby forcing progress by eventually evacuating the whole train.

Figure 10.2: The Train copying collector.
Jones [1996]. Reprinted by permission.

Figure 10.3: A ‘futile’ collection. After a collection which moves A to a fresh car, the external reference is updated to refer to A rather than B. This presents the same situation to the collector as before, so no progress can be made.
The Train algorithm bounds the amount of copying done in each collection cycle but does not bound other work, such as remembered set scanning and updating references. Any ‘popular’, highly referenced objects will induce large remembered sets and require many referring fields to be updated when they are moved to another car. Hudson and Moss suggest dealing with such objects by moving them to the end of the newest train, into their own car, which can be moved logically rather than physically in future collections without need to update references. Unfortunately this does not guarantee to segregate a garbage cycle that spans popular cars. Even if a popular car is allowed to contain more than one popular item, it may still be necessary to disentangle these to separate cars unless that are part of the same structure. Both Seligmann and Grarup [1995] and Printezis and Garthwaite [2002] have found popular objects to be common in practice. The latter address this by allowing remembered sets to expand up to some threshold (say 4,096 entries) after which they coarsen a set by rehashing its entries into a set of the same size but using a coarser hashing function. Seligmann and Grarup tune the frequency of train collections by tracking a running estimate of the garbage collected (a low estimate allows the collection frequency to be reduced). But Printezis and Garthwaite found it to be common for an application to have a few very long trains of long lived data; this defeats such a tuning mechanism.
Connectivity-based garbage collection
Management of remembered sets can contribute significantly to the time and space costs of the Train algorithm. The performance of a partitioned collector would be improved if the number of inter-partition pointers that need to be remembered could be reduced or even eliminated. In the previous chapter, we saw how Guyer and McKinley [2004] used a static analysis to place new objects in the same generation as the object to which they would be connected, and Zee and Rinard [2002] eliminated write barriers for the initialisation of the newest object in a generational collector. Hirzel et al [2003] explored connectivity-based allocation and collection further. They observed that the lifetimes of Java objects are strongly correlated with their connectivity. Those reachable only from the stack tend to be short-lived whereas those reachable from globals tend to live for most of the execution of the program (and they note that this property is largely independent of the precise definition of short- or long-lived). Furthermore, objects connected by a chain of pointers tend to die at the same time.
Based on this observation, they proposed a new model of connectivity-based collection (CBGC) [Hirzel et al, 2003]. Their model has four components. A conservative pointer analysis divides the object graph into stable partitions: if an object a may point to an object b then either a and b share a partition or there is an edge from a’s partition to b’s partition in the directed acyclic graph (DAG) of partitions. Although new partitions may be added (for example, as classes are loaded), partitions are never split. The collector can then choose any partition (or set of partitions) to collect provided it also collects all its predecessor partitions in the DAG. Partitions in the condemned set are collected in topological order. This approach has two benefits. The collector requires neither write barriers nor remembered sets. Partitions can be reclaimed early. By collecting in topological order, as soon as the collector has finished tracing objects in a partition, any unvisited (white) objects in that partition or earlier ones must be unreachable and so can be reclaimed. Note that this also allows popular child partitions to be ignored.
Hirzel et al suggest that the performance of connectivity-based garbage collectors depends strongly on the quality of partitioning, their estimate of the survivor volume of each partition and their choice of partitions to collect. However, they obtained disappointing results (from simulation) for a configuration based on partitioning by the declared types of objects and their fields, estimating a partition’s chance of survival from its global or stack reachability, moderated by a partition age based decay function, and using a greedy algorithm to choose partitions to collect. Although mark/cons ratios were somewhat better than those of a semispace copying collector, they were much worse than those of an Appel-style generational collector. On the other hand, worst-case pause times were always better. Comparison with an oracular collector, that received perfect advice on the choice of partition, suggested that there was a performance gap that might be exploited by a better configuration. Dynamic partitioning based on allocation site also improved performance of the collector at the cost of re-introducing a write barrier to combine partitions.
Thread-local garbage collection
One way to reduce garbage collection pause times is to run the collector concurrently with the mutator threads. A variation on this is to perform collection work incrementally, interleaving the mutator and collector. Both approaches increase the complexity of implementations, chiefly by requiring greater synchronisation between collectors and mutators; we defer discussion of incremental and concurrent garbage collection to later chapters. However, if we can prove that a set of objects can only ever be accessed by a single thread, and if these objects are stored in their own thread-local heaplet, then these heaplets can be managed without synchronisation: the problem is reduced to stop-the-world collection for each thread. In this section, we investigate different designs for thread-local collection. Of course, thread-local approaches cannot deal with objects that may be shared; they must still be dealt with by halting all mutator threads during collection or by more complex concurrent or incremental techniques.
The key to thread-local collection is to segregate objects that can be reached by just one thread from those that are potentially shared. Typically, heaps configured for thread-local collection use a single shared space and a set of per-thread heaplets. This requires strict regulation on the direction of pointers. An object in a thread-local heaplet may point to another object in the same heaplet or to a shared object. Shared objects may not reference thread-local ones, nor may thread-local objects refer to objects in other thread-local heaplets. The segregation of objects may be made statically, using a pointer analysis, or it may be dynamic, requiring infringements of the pointer direction rule to be detected at run time. Note that any organisation can be used within a heaplet (for example, a flat arrangement or with generations). However, it is also possible to mark objects as shared on an object by object basis.
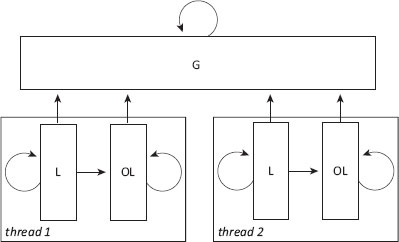
Figure 10.4: Thread-local heaplet organisation, indicating permitted pointer directions between purely local (L), optimistically-local (OL) and shared heaplets (G) [Jones and King, 2005].
Steensgaard [2000] used a fast but conservative pointer analysis similar to that of Ruf [2000] to identify Java objects potentially reachable from a global variable and by more than one thread. The goal of his flow-insensitive, context-sensitive escape analysis is to allow methods that create objects to be specialised in order to allocate the object in either the thread’s local heaplet or the shared heaplet. Each heaplet comprises an old and a young generation. His collector is only mostly thread-local. Because Steensgaard treats all static fields as roots for a local heaplet, each collection requires a global rendezvous. A single thread scans the globals and all thread stacks in order to copy any directly reachable objects, before Cheney-scanning the shared heaplet. The local threads are released only after the shared scan is complete in order to finish independent collections of their own heaplets. These threads may encounter uncopied objects in the shared heaplet: if so a global lock must be acquired before the object is copied.
Static segregation of shared and thread-local objects requires a whole program analysis. This is a problem for any language that permits classes to be loaded dynamically, since polymorphic methods in sub-classes loaded after the analysis is complete may ‘leak’ references to local objects by writing references into fields of globally reachable ones. Jones and King address this problem and provide a design for a truly thread-local collector [King, 2004; Jones and King, 2005]. Their escape analysis builds on Steensgaard’s but is compositional: it supports Java’s dynamic class loading, dealing safely with classes loaded after the analysis is complete. Designed for long running Java applications, the analysis was sufficiently fast to be deployed at run time in a background thread, with Sun’s ExactVM Java virtual machine running on a multiprocessor under Solaris. They provide each thread with two local heaplets: one for objects that are guaranteed to be reachable by only the thread that allocated them, no matter what further classes may be loaded, and one for optimistically-local objects: those that are accessible by no more than one thread at the time of the analysis but which may become shared if an antagonistic class is loaded. Purely thread-local objects turn out to be comparatively rare: these are mostly objects that do not escape their allocating method. Optimistically-local objects are fairly common, however. The rules for pointer directionality are extended. Local objects may also point to optimistically-local ones, but not vice-versa; optimistically-local objects may refer to global ones. A schematic of permissible pointers is shown in Figure 10.4. Jones and King collect each thread independently, with no global rendezvous. Both a thread’s local and optimistically-local heaplets are collected together, provided no classes have been loaded that compromise the analysis. Whenever a class is loaded dynamically, it is analysed both to specialise its methods, and to discover whether it extends a class already loaded and whether any of its methods potentially cause an allocation site marked optimistically-local to become shared. If so — and such ‘non-conforming’ methods are very rare — the optimistically-local heaplets of all threads that may use this method are marked shared and no longer collected thread-locally, but instead are collected alongside the shared heap.
Steensgaard segregated objects statically, at the cost of a global rendezvous; Jones and King also used a static escape analysis but collect purely thread-locally, with a dynamic class loading check to handle non-conforming methods. However, it is also possible to detect objects dynamically as they escape from their allocating thread. Domani et al [2002] created objects in thread-local allocation buffers but detect escapement precisely, using a write barrier. Because shared and local objects are intermingled in the heap, each object is associated with a global bit (held in a separate bitmap) which is set by the write barrier just before a thread creates a reference to an object it did not allocate. The barrier must also set this bit for every object in the transitive closure of the target object. The parallel mark-sweep collector of Domani et al collects threads independently. It stops all threads only if it is unable to allocate a large object or a fresh allocation buffer. They also allocate objects known to be always global (such as thread and class objects or those identified as global by off-line profiling) into a separate shared region. Co-existence of global and local collections requires some synchronisation to ensure that a global collection is not initiated while a local one is in progress; we discuss the handshakes necessary in later chapters.
Collecting thread-locally is simpler if all objects are immutable. Erlang [Armstrong et al, 1996] is a strict, dynamically typed, functional programming language. Erlang programs typically use very large numbers of extremely light-weight processes which communicate with each other through asynchronous message passing. The original Erlang/OTP runtime system was process-centric, with each process managing its own private memory area. Because Erlang does not allow destructive assignment, message passing uses copying semantics and thread-local heaps can be collected independently. The costs of this design are that message passing is an O(n) operation (where n is the size of the message) and message data are replicated between processes.
Sagonas and Wilhelmsson add to this architecture a shared area for messages and one for binaries, in order to reduce the cost of message passing [Johansson et al, 2002; Sagonas and Wilhelmsson, 2004; Wilhelmsson, 2005; Sagonas and Wilhelmsson, 2006]. They impose the usual restrictions on pointer direction between the process-local areas and the shared messages area. Their shared message area does not contain any cyclic data and the binaries do not contain references. A static message analysis guides allocation: data that is likely to be part of a message is allocated speculatively on the shared heap and otherwise in a process’s local heap. All message operands are wrapped in a copy-on-demand operation that checks that the operand is indeed in the shared heap and otherwise copies it; often this test can be eliminated by the compiler. Note that the copying semantics of Erlang message passing allow the analysis to both over-approximate and under-approximate sharing. Local heaps are managed with a generational, stop-and-copy Cheney-style collector, using generational stack scanning [Cheng et al, 1998]. As they contain no cycles, the shared binaries are reference counted. Each process maintains a remembered list3 of pointers to binaries. When a process dies, the reference counts of binaries in this list are decremented. The shared message area is collected by an incremental mark-sweep collector, which requires global synchronisation. We discuss incremental mark-sweep algorithms in Chapter 16.
Doligez and Leroy [1993] were the first to introduce the thread-local/shared region memory architecture. In their case, the local/shared regions also served as the young/old generations of their collector. Their target was Concurrent Caml Light, ML with concurrency primitives. Unlike Erlang, ML does have mutable variables. In order to allow threads to collect their young generations independently, mutable objects are stored in the shared old generation. If a mutable object is updated to refer to an object in a thread-local young generation, then the transitive closure of the young object is copied to the old generation. As in the Erlang case, making two copies of the data structure is safe since young objects are guaranteed to be immutable. As well as copying the young objects, the collector updates a forwarding address in each object header to refer to its shared replica. These addresses are used by subsequent thread-local, young generation collections; the mutator write barrier has done some of the collector’s work for it. Note that the forwarding pointer must be stored in a reserved slot in the object’s header rather written destructively over user data since the young copy is still in use. This additional header word is stripped from the old generation copy as it is not required by the shared heap’s concurrent mark-sweep collector. While this additional word imposes a space overhead in the young generations, this overhead may be acceptable since young generation data will usually occupy a much smaller fraction of total heap size than old generation data.
Several researchers have proposed allocating objects on the stack rather than in the heap, wherever possible. A wide variety of mechanisms have been suggested, but fewer have been implemented, especially in production systems. Stack allocation has some attractions. It potentially reduces the frequency of garbage collection, and expensive tracing or reference counting is unnecessary for stack allocated data. Thus, stack allocation should in theory be gentler on caches. On the down side, it may prolong the lifetime of objects allocated in frames that persist on the stack for a long time.
The key issue is to ensure that no stack allocated object is reachable from another object with a longer lifetime. This can be determined either conservatively through an escape analysis (for example, [Blanchet, 1999; Gay and Steensgaard, 2000; Corry, 2006]) or by runtime escape detection using a write barrier. Baker [1992b] was the first to suggest (but not implement) stack allocation in the context of an otherwise garbage collected heap. Laying out the stack to grow away from the heap could use an efficient address-based write barrier to detect references to objects on the stack from locations that might outlive them. In such a case, the object would be copied (‘lazily allocated’) into the heap. He also required a read barrier to handle the forwarding addresses that copying introduced. Others have suggested allocating objects in a stack of frames separate from the call stack. Cannarozzi et al [2000] used a write barrier to partition the heap, with each partition associated with the oldest activation record that might refer to it. Unfortunately the cost (in Sun’s handle-based JDK 1.1.8) was large: an extra four 32-bit words per object. Qian and Hendren [2002] allocated frames lazily to avoid allocating any empty ones. They used a write barrier to mark such a frame as global if any of its objects escaped. In this case, the write barrier also marked the site in the method allocating the object as non-local but this requires storing a site identity in the object’s header. They share the lock word for this purpose at the cost of making the frame global if an object is ever locked; unfortunately, library code often contains redundant (that is, local) locking (which is why biased locking is so effective). Corry [2006] used a cheaper intraprocedural escape analysis that associates object frames with loops rather than method invocations and hence works well with dynamic class loading, reflection, factory methods and so on.
Azul Systems’ multicore, multiprocessor Java appliances provide hardware-supported object-by-object escape detection. When an object is allocated on the stack, some pointer bits are used to store the frame’s depth in the stack. These bits are ignored by pointer loads but checked by stores: storing a reference to an object in a new frame into an object in an old frame causes a trap which moves the object and fixes up references to it (which can only be held by objects in newer frames). The fixup is expensive so needs to be rare for stack allocation be be effective. If stack allocating an object would cause the frame to become too large, Azul place the object in an overflow area to the side. Azul find that they still need occasional thread-local collections to deal with dead stack allocated objects in long lived frames.
Overall, most of these schemes have either not been implemented, are reported with insufficient detail of comparative systems, or do not offer significant performance improvements. While it is likely that for many applications a large fraction of objects might be stack allocatable, most of these are likely to be short-lived. Azul find that over half of all objects may be stack allocated in large Java applications. However, this scenario is precisely the one in which generational garbage collection excels. It is not clear that stack allocation reduces memory management costs sufficiently to make it worthwhile. Another rationale for stack allocation is that it can reduce memory bandwidth by keeping these objects entirely in the cache, given a sufficiently large cache. One related strategy that is effective is scalar replacement or object inlining whereby an object is replaced by local variables representing its fields [Dolby, 1997; Dolby and Chien, 1998, 2000; Gay and Steensgaard, 2000]. A common application of scalar replacement is for iterators in object-oriented programs.
Stack allocation is a restricted form of more general region-based memory management. The key idea behind region-based memory is that objects are allocated into regions and that entire regions are reclaimed as soon as none of their contents is required by the program. Typically, region reclamation is a constant time operation. The decisions as to when to create a region, into which region to place an object and when to reclaim a region may fall to the programmer, the compiler, the run-time system or a combination of these. For example, the programmer may be required to add explicit instructions or annotations to create and destroy regions or to indicate the region into which an object must be allocated. Possibly the best known explicit system is the Real-Time Specification for Java (RTSJ). In addition to the standard heap, the RTSJ provides an immortal region and scoped regions. The RTSJ enforces strict rules on pointer directionality: an object in an outer scoped region cannot refer to one in an inner scope.
Other region-based systems may relax the requirements on pointer direction, allowing regions to be reclaimed even if there are references into that region from other, live regions. To be safe, such systems require a guarantee that the mutator will never follow a dangling pointer into a deallocated region. These systems require compiler support, either for inferring the region to which an object should be allocated and when it is safe to reclaim the region, or to check programmer annotations (possibly in the form of non-standard type systems). The best known, fully automatic, region inferencing system is that for Standard ML [Tofte et al, 2004]. Used with care, their system can lead to programs that are efficient and use less memory. However, this is very dependent on program style, often requiring the programmer to have a deep understanding of the inferencing algorithm (although not its implementation). Region inferencing can also make programs harder to understand and more difficult to maintain as small changes can have significant effects on the inferencing decisions. The ML Kit inferencing algorithm was also very expensive for large programs (for example a 58,000 line program took one and a half hours to compile). Tofte et al report that it was often best to restrict region inferencing to well understood coding patterns and manage other parts of the program by garbage collection.

Figure 10.5: A continuum of tracing collectors. Spoonhower et al contrast an evacuation threshold — sufficient live data to make a block a candidate for evacuation — with an allocation threshold — the fraction of a block’s free space reused for allocation.
Spoonhower et al [2005], doi: 10.1145/1064979.106498 9.
© 2005 Association for Computing Machinery, Inc. Reprinted by permission.
10.3 Hybrid mark-sweep, copying collectors
When considering how the volume of live objects in a block can be used to make evacuate or mark decisions, Spoonhower et al [2005] contrast an evacuation threshold — whether the block contains sufficiently little live data to make it a candidate for evacuation — with an allocation threshold — how much of the block’s free space should be reused for allocation. These thresholds determine when and how fragmentation is reduced. For example, a mark-sweep collector has an evacuation threshold of zero (it never copies) but an allocation threshold of 100% (it reuses all free space in a block), whereas a semispace copying collector has an evacuation threshold of 100% but an allocation threshold of zero (fromspace pages are not used for allocation until after the next collection); these two collectors are shown in Figure 10.5. Overly passive memory managers with low evacuation and allocation thresholds can suffer from fragmentation; overly aggressive managers, where both thresholds are high, have high overheads either because they replicate data or because they require more passes to collect the heap.
The performance of a large or long running application may eventually suffer from fragmentation unless the heap is managed by a compacting collector. Unfortunately, compaction is likely to be expensive in time or space compared with non-moving collection. Semispace copying requires a copy reserve but mark-compact algorithms require several passes over the heap in addition to the cost of moving objects. To address these problems, Lang and Dupont [1987] proposed combining mark-sweep collection with semispace copying to compact the heap incrementally, one region at a time. The heap is divided into k + 1 equally sized windows, one of which is empty. At collection time, some window is chosen to be the fromspace and the empty window is used as the tospace. All other windows are managed by a mark-sweep collector. As the collector traces the heap, objects are evacuated to the tospace window if they are in the fromspace window, otherwise they are marked (see Figure 10.6). References in any window to fromspace objects must be updated with their tospace replicas.

Figure 10.6: Incremental incrementally compacting garbage collection. One space (fromspace) is chosen for evacuation to an empty space (tospace), shown as grey; the other spaces are collected in place. By advancing the two spaces, the whole heap is eventually collected.
Jones [1996]. Reprinted by permission.
By rotating the window chosen to be the fromspace through the heap, Lang and Dupont can compact the whole heap in k collections at a space overhead of 1/k of the heap. Unlike mark-compact algorithms, no extra passes or data structures are required. They observe that this algorithm can provide flexibility in tracing order, especially if tospace is managed by a Cheney algorithm. At each tracing step, the collector can choose whether to take the next item from the mark-sweep or the copying work list: Lang and Dupont advocate preferring the mark-sweep collector in order to limit the size of its stack. There is also a locality argument here since mark-sweep tends to have better locality than Cheney copying.
The Spoonhower et al [2005] collector for C# takes a more flexible approach. It uses block residency predictions to decide whether to process a block in place to tospace or to evacuate its contents. Predictions may be static (for example, large object space pages), use fixed evacuation thresholds (generational collectors assume few young objects survive) or dynamic ones (determined by tracing). Spoonhower et al use residency counts from the previous collection to determine whether to evacuate or mark objects in a block (blocks containing pinned objects are processed in place) in order not to need an extra pass at each collection. In a manner similar to Dimpsey et al [2000] (discussed below), they maintain a free-list of gaps, and bump allocate into these.
Garbage-First [Detlefs et al, 2004] is a sophisticated and complex incrementally compacting algorithm, designed to meet a soft real-time performance goal that collection should consume no more than x milliseconds of any y millisecond time slice. It was introduced in Sun Microsystems’ HotSpot VM in JDK 7 as a longer term replacement for a concurrent mark-sweep collector in order to provide compaction with more predictable response times. Here we focus on how it treats partitions.
Like the Lang and Dupont collector, Garbage-First divides the heap into equal sized windows of contiguous virtual memory. Allocation is made into a current allocation window, taken from a list of empty windows. To minimise synchronisation between mutator threads, each thread has its own bump-a-pointer local allocation buffer. Thread-local buffers are acquired from the current allocation window with an atomic CompareAnd-Swap operation; larger objects may similarly be allocated directly in the allocation window. ‘Humongous’ objects, larger than three-quarters of a window, are allocated in their own sequence of windows.
Unlike Lang and Dupont, Garbage-First allows an arbitrary set of windows to be chosen for collection. It therefore requires the mutator’s write barrier to record any interwindow pointers that it writes. Almost all such pointers must be remembered unlike, say, the Train collector which requires only unidirectional remembered sets since cars are collected in a predetermined order. Garbage-First uses a filtering write barrier that records interesting pointers in card tables (we discuss these in Chapter 11).
A single collector thread marks the heap concurrently with mutator execution (see Chapter 16), based on Printezis and Detlefs [2000] bitmap marking (which we saw in Chapter 2). Once the heap has been marked, Garbage-First uses the bitmap to select windows for evacuation. Regions are compacted in parallel with all mutator threads stopped (see Chapter 14). In general, the windows to be evacuated will be those with low fractions of live data. However, Garbage-First can also operate generationally. In a pure, ‘fully young’ generational mode, the windows chosen for evacuation are just those used for allocation since the last collection. A ‘partially young’ collector can add further windows to this condemned set. In either generational mode, the mutator write barrier can filter out pointers with young sources. As with other schemes, Garbage-First attempts to identify popular objects and to segregate these in their own windows, which are never candidates for evacuation and so do not require remembered sets.
We now examine three collectors that trade off the space-time costs of mark-sweep collection and fragmentation. Each takes a different approach to the problems of trying to make best use of available heap space, avoiding the need to defragment (whether through evacuation or mark-compact), and reducing time overheads in the collector’s loops.
Dimpsey et al [2000] describe a sophisticated parallel mark-sweep (with occasional compaction) collector for IBM’s server Java virtual machine, version 1.1.7. Like Sun’s 1.1.5 collectors, the IBM server used thread-local allocation buffers.4 Small objects were bump-allocated within a buffer without synchronisation; synchronised allocation of buffers and other large objects (greater than 0.25 times the buffer size) was performed by searching a free-list. Dimpsey et al found that this architecture on its own led to poor performance. Although most large object requests were for local allocation buffers, free chunks that could not satisfy these requests tended to congregate at the start of the free-list, leading to very long searches. To address this, they introduced two further free-lists, one for objects of exactly local allocation buffer size (1.5 kilobytes plus header) and one for objects between 512 kilobytes and buffer size. Whenever the buffer list became empty, a large chunk was obtained from the large object list and split into many buffers. This optimisation substantially improved Java performance on uniprocessors and even more so on multiprocessors.
The IBM server collector marked objects in a side bitmap. Sweeping traversed the bitmap, testing bits a byte or a word at a time. Dimpsey et al optimise their sweep by ignoring short sequences of unused space; a bit in the object header was used to distinguish a large object from a small one followed by garbage, and two tables were used to translate arbitrary byte values in the mark bitmap to counts of leading and trailing zeroes. The consequence of this is that, after a collection, parts of an allocation buffer may be free but not usable for allocation since the server bump-allocates only from fresh buffers. However, not only did this approach reduce sweep time but it also reduced the length of the free-lists, since they no longer contain any small blocks of free space.

Figure 10.7: Allocation in immix, showing blocks of lines. Immix uses bump pointer allocation within a partially empty block of small objects, advancing lineCursor to lineLimit, before moving onto the next group of unmarked lines. It acquires wholly empty blocks in which to bump-allocate medium-sized objects. Immix marks both objects and lines. Because a small object may span two lines (but no more), immix treats the line after any sequence of (explicitly) marked lines as implicitly marked: the allocator will not use it.
Blackburn and McKinley [2008], doi: 10.1145/1375581.1375586.
© Association for Computing Machinery, Inc. Reprinted by permission.
The potential cost of this technique is that some free space is not returned to the allocator. However, objects tend to live and die together and Dimpsey et al use this property to avoid compaction as much as possible. They follow the advice of Johnstone [1997] by using an address-ordered, first-fit allocator in order to increase the chance of creating holes in the heap large enough to be useful. Furthermore, they allow local allocation blocks to be of variable length. If the first item on the local allocation buffer free-list is smaller than a desired size T (they use six kilobytes), it is used as is (note that the item must be larger than the minimum size accepted for inclusion in the free-list). If it is between T and 2T, it is split into two evenly sized buffers. Otherwise, the block is split to yield a buffer of size T. Dimpsey et al also set aside 5% of the heap beyond the ‘wilderness boundary’ [Korn and Vo, 1985], to be used only if insufficient space is available after a collection.
Like the Dimpsey et al IBM server, the immix collector [Blackburn and McKinley, 2008] attempts to avoid fragmentation. It too is a mostly mark-sweep collector, but it eliminates fragmentation when necessary by copying rather compacting collection. Immix employs a block structured heap, just as the other collectors discussed in this section. Its 32 kilobyte blocks are the basis for both thread-local allocation and the units for defragmentation. At collection time, immix chooses whether to mark a block in place or to evacuate its live objects, using liveness estimates gathered from the previous collection cycle (in the same way as Spoonhower et al but in contrast to Detlefs who obtain their estimates from concurrent marking). Both the IBM server and immix use fast bump-pointer allocation. Whereas Dimpsey et al reduce fragmentation by allocating from variable sized buffers, immix can also sequentially allocate into line-sized gaps in partially filled buffers. Immix lines are 128 bytes, chosen to roughly match cache line lengths. Just as Dimpsey et al optimise their collector’s sweep by ignoring short sequences of unused space, so Blackburn and McKinley reclaim space in recyclable blocks at the granularity of lines rather than individual objects. Let us look at the immix collector in detail.
Immix allocates from either completely free or partially filled (‘recyclable’) blocks. Figure 10.7 shows the structure of recyclable blocks. For the purpose of allocation, immix distinguishes large objects (which are allocated in a large object space), medium sized objects whose size is greater than a line, and small objects; most Java objects are small. Algorithm 10.1 shows the immix algorithm for small and medium sized objects. Immix preferentially allocates into empty line-sized gaps in partially filled blocks using a linear, next-fit strategy. In the fast path, the allocator attempts to bump-allocate into the current contiguous sequence of free lines (line 2). If this fails, the search distinguishes between small and medium sized allocation requests.
Algorithm 10.1: Allocation in immix
1 alloc(size):
2 addr ← sequentialAllocate(lines)
3 if addr ≠ null
4 return addr
5 if size ≤ LINE_SIZE
6 return allocSlowHot(size)
7 else
8 return overflowAlloc(size)
9
10 allocSlowHot(size):
11 lines ← getNextLineInBlock()
12 if lines = null
13 lines ← getNextRecyclableBlock()
14 if lines = null
15 lines ← getFreeBlock()
16 if lines = null
17 return null | /* Out of memory */ |
18 return alloc(size)
19
20 overflowAlloc(size):
21 addr ← sequentialAllocate(block)
22 if addr ≠ null
23 return addr
24 block ← getFreeBlock()
25 if block = null
26 return null | /* Out of memory */ |
27 return sequentialAllocate(block)
We consider small requests first. In this case, the allocator searches for the next sequence of free lines in the current block (line 11). If this fails, immix tries to allocate from free lines in the next partially filled block (line 13) or the next empty block (line 15). If neither request succeeds, the collector is invoked. Notice that, unlike first-fit allocation, the immix allocator never retreats even though this may mean that some lines are only partially filled.
In most applications, a small number of Java objects are likely to be larger than a line but not ‘large’. Blackburn and McKinley found that treating these like the small objects above led to many lines being wasted. To avoid fragmenting recyclable blocks, these medium sized objects are bump-allocated into empty blocks (overflowAlloc). They found that the overwhelming proportion of allocation was into blocks that were either completely free or less than a quarter full. Note that allocation of both small and medium sized objects is into thread-local blocks; synchronisation is required only to acquire a fresh block (either partially filled or completely empty).
The immix collector marks both objects (to ensure correct termination of the scan) and lines — the authors call this ‘mark-region’. A small object is by definition smaller than a line, but it may still span two lines. Immix marks the second line implicitly (and conservatively): the line following any sequence of marked lines is skipped by the allocator (see Figure 10.7) even though, in the worst case, this might waste nearly a line in every gap. Blackburn and McKinley found that tracing performance was improved if a line was marked as an object was scanned rather than when it was marked and added to the work list, since the more expensive scanning operation better hid the latency of line marking. Implicit marking improved the performance of the marker considerably. In contrast, medium sized objects are marked exactly (a bit in their header distinguishes small and medium objects).
Immix compacts opportunistically, depending on fragmentation statistics, and in the same pass as marking. These statistics are recorded at the end of each collection by the sweeper, which operates at the granularity of lines. Immix annotates each block with the number of gaps it contains and constructs histograms mapping the number of marked lines as a function of the number of gaps blocks contain. The collector selects the most-fragmented blocks as candidates for compaction in the next collection cycle. As these statistics can provide only a guide, immix can stop compacting early if there is insufficient room to evacuate objects. In practice, compaction is rare for many benchmarks.
Copying collection in a constrained memory space
As we have seen, these incremental techniques require a copy reserve of just one block but take many collections to compact the whole heap. Sachindran and Moss [2003] adopt this approach for generational collection in memory constrained environments, dividing the old generation into a sequence of contiguous blocks. Rather than evacuate a single block at each collection, Mark-Copy collects the whole heap one block at a time at each full heap collection. Like any other generational collector, objects are allocated into the nursery which is collected frequently, with any survivors being copied to the old generation. If the space remaining drops to a single block, a full heap collection is initiated.
Independent collection of each block requires a remembered set for each one, but this would complicate the generational write barrier since it would have to record not only inter-generational pointers but also inter-block ones. Instead, Mark-Copy’s first phase marks all live objects, and also constructs per-block unidirectional remembered sets and counts the volume of live data for each block. Two advantages arise from having the marker rather than the mutator construct the remembered sets: the remembered sets are precise (they contain only those slots that actually hold pointers from higher numbered to lower numbered blocks at the time of collection) and they do not contain any duplicates. Windows of consecutive blocks are evacuated one at a time, starting with the lowest numbered (to avoid the need for bidirectional remembered sets), copying live data to the free block. Because the marker has counted the volume of live data in each block, we can determine how many blocks can be evacuated in each pass. For example, the second pass in Figure 10.8 was able to evacuate a window of three blocks. At the end of each pass, the space consumed by the evacuated blocks is released (unmapped).
By evacuating blocks one at time if necessary, collectors like Mark-Copy effectively increase the space available compared with a standard semispace collector, which may lead to fewer collections given the same space budget. Mark-Copy may also be incremental, interleaving collections of blocks in the old generation with nursery collections. However, it has disadvantages. Each full collection scans every object twice, once to mark and once to copy. Marking requires space for a mark stack and for the remembered sets. Each copying pass may require thread stacks and global data to be rescanned. Still, under some useful range of conditions it performs well compared with copying generational collectors that must reserve more of the available space for copying into.

Figure 10.8: Mark-Copy divides the space to be collected into blocks. After the mark phase has constructed a remembered set of objects containing pointers that span blocks, the blocks are evacuated and unmapped, one at a time.
Sachindran and Moss [2003], doi: 10.1145/949305.949335.
© 2003 Association for Computing Machinery, Inc. Reprinted by permission.
The MC2 collector [Sachindran et al, 2004] relaxes Mark-Copy’s requirement for blocks to occupy contiguous locations by numbering blocks logically rather than by their (virtual) address. This has several advantages. It removes the need for blocks to be remapped at the end of each pass (and hence the risk of running out of virtual address space in a 32-bit environment). It also allows blocks to be evacuated logically simply by changing their block number, which is useful if the volume of live data in the block is sufficiently high to outweigh the benefit of copying and compacting it. Numbering the blocks logically also allows the order of collection of blocks to be modified at collection time. Unlike Mark-Copy, MC2 spreads the passes required to copy old generation blocks over multiple nursery collections; it also marks the old generation incrementally using a Steele insertion barrier (we discuss incremental marking in Chapter 15). Because of its incrementality it starts collecting the old generation somewhat before space runs out, and adaptively adjusts the amount of work it does in each increment to try to avoid a large pause that might occur if space runs out. Like other approaches discussed in this chapter, MC2 segregates popular objects into a special block for which it does not maintain a remembered set (thus treating them as immortal although this decision can be reverted). Furthermore, in order to bound the size of remembered sets, it also coarsens the largest ones by converting them from sequential store buffers to card tables (we explain these techniques in Chapter 11). Large arrays are also managed by card tables, in this case by allocating space for their own table at the end of each array. Through careful tuning of its combination of techniques, it achieves high space utilisation, high throughput, and well-balanced pauses.
10.4 Bookmarking garbage collection
These incremental compaction techniques have allowed the heap to be compacted (eventually) without the time overhead of traditional mark-compact algorithms or the space overhead of standard semispace collection. Nevertheless, programs will still incur a significant performance penalty if the number of pages occupied by the heap is sufficiently large that either mutator activity or garbage collector tracing leads to paging. The cost of evicting and loading a page is likely to be of the order of millions of cycles, making it worth expending considerable effort to avoid page faults. The Bookmarking collector [Hertz et al, 2005] mitigates the total cost of mutator page faults and avoids faults during collection.
The collector cooperates with the operating system’s virtual memory manager to guide its page eviction decisions. In the absence of such advice, the manager is likely to make a poor choice of which page to evict. Consider a simple semispace collector and a virtual memory manager which always evicts the least recently used page. Outside collection time, the page chosen will always be an as yet unused but soon to be occupied tospace page. Indeed, if most objects are short-lived, it is quite likely that the least recently used page will be the very next one to be used by the allocator — the worst possible paging scenario from its point of view! A fromspace page would be a much better choice: not only will it not be accessed (and hence reloaded) until the next collection but its contents do not need to be written out to the backing store.
The Bookmarking collector can complete a garbage collection trace without faulting in non-resident pages. The trace conservatively assumes that all objects on a non-resident page are live but it also needs to locate any objects reachable from that page. To support this, if a live page has to be scheduled for eviction, the run-time system scans it, looking for outgoing references, and ‘bookmarks’ their targets. When this page is reloaded, its bookmarks are removed. These bookmarks are used at collection time to propagate the trace.
The virtual memory manager is modified to send a signal whenever a page is scheduled for eviction. The Bookmarking collector always attempts to choose an empty page. If this is not possible it calls the collector and then selects a newly emptied page. This choice can be communicated to the virtual memory manager through a system call, for example madvise with the MADV_DONTNEED flag. Thus Bookmarking attempts to shrink the heap to avoid page faults. It never selects pages in the nursery or those containing its metadata. If Bookmarking cannot find an empty page, it chooses a victim (often the scheduled page) and scans it for outgoing references, setting a bit in their targets’ headers. Hertz et al extend the Linux kernel with a new system call allowing user processes to surrender a list of pages.
If the whole heap is not memory resident, full heap collections start by scanning the heap for bookmarked objects, which are added to the collector’s work list. While this is expensive, it is cheaper in a small heap than a single page fault. Occasionally it is necessary to compact the old generation. The marking phase counts the number of live objects of each size class and selects the minimum set of pages needed to hold them. A Cheney pass then moves objects to these pages (objects on the target page are not moved). Bookmarked objects are never moved in order to avoid having to update pointers held in non-resident pages.
10.5 Ulterior reference counting
So far we have seen a number of different partitioned organisations of the heap. Each partitioning scheme allows different spaces of the heap to be managed by different policies or algorithms, collected either at the same or at different times. Segregation has been used to distinguish objects by their expected lifetimes, by their size or in order to improve heap utilisation. In the final section of this chapter, we consider segregation of objects according to the rate at which they are mutated.
There is ample evidence that for a wide range of applications young objects are allocated and die at very high rates; they are also mutated frequently (for example to initialise them) [Stefanović, 1999]. Evacuation is an effective technique for such objects since it allows fast bump pointer allocation and needs to copy only live data, little of which is expected. Modern applications require increasingly large heaps and live sets. Long lived objects tend to have lower mortality and update rates. All these factors are inimical to tracing collection: its cost is proportional to the volume of live data and it is undesirable to trace long lived data repeatedly. On the other hand, reference counting is well suited to such behaviour as its cost is simply proportional to the rate at which objects are mutated. Blackburn and McKinley [2003] argue that each space, young and old, should be managed by a policy appropriate to its size, and to the expected lifetimes and mutation rate of the objects that it contains.
Their Ulterior reference counting collector therefore manages young objects by copying and older ones by reference counting. It allocates young objects into a bounded-size nursery space, using bump pointer allocation. Any young objects that survive a nursery collection are copied to a mature space, managed with segregated fits free-lists. The mutator write barrier is responsible both for managing reference counts of objects in the mature space and for remembering pointers from that space to young objects. Reference counting is deferred for operations involving stacks or registers, and the collector coalesces reference count updates made to other heap objects. Whenever a pointer field of an unlogged object is updated, the object is logged. Logging records the address of the object and buffers a decrement for each of the object’s referents in the reference counted mature space.5
At garbage collection time, the collector moves surviving young objects into the reference counted world, and reclaims unreachable data in both spaces. It increments the count of each reference counted child in the mutation log; any targets in the nursery are marked as live, and added to the nursery collector’s work list. As surviving young objects are promoted and scavenged, the collector increments the reference counts of their targets. As with many other implementations of deferred reference counting, the counts of objects directly reachable from the roots are also incremented temporarily during collection. All the buffered increments are applied before the buffered decrements. Cyclic garbage is handled using by the Recycler algorithm [Bacon and Rajan, 2001]. However, rather than invoking it at each collection on all those decremented objects whose count did not reach zero, Blackburn and McKinley trigger cycle detection only if the available heap space falls below a user-defined limit.

Figure 10.9: Ulterior reference counting schematic: the heap is divided into a space that is managed by reference counting and one that is not. The schematic shows whether reference counting operations on pointer loads or stores should be performed eagerly, deferred or ignored.
Blackburn and McKinley [2003], doi: 10.1145/949305.94 933 6.
© 2003 Association for Computing Machinery, Inc. Reprinted by permission.
An abstract view of Ulterior reference counting is shown in Figure 10.9: compare this with standard deferred reference counting shown in Figure 5.1 in Chapter 5.
As we have seen in this chapter, there are several reasons other than age to segregate objects in the heap. We partition the set of objects in the heap so that we can manage different partitions or spaces under different policies and with different mechanisms: the policies and mechanisms adopted will be those most appropriate to the properties of the objects in the space. Partitioning by physical segregation can have a number of benefits including fast address-based space membership tests, increased locality, selective defragmentation and reduced management costs.
One of the most common policies is to manage large objects differently from small objects. Large objects are placed in their own space, which is typically a non-moving space in order to avoid the cost of copying or compacting these objects. Typically, large objects are allocated to their own sequence of pages, which are not shared with other objects. It can be worthwhile distinguishing objects that do not contain pointers (such as bitmaps representing images) from large arrays of pointers: it is not necessary to trace the former and, if they are marked in a separate bitmap, it is never necessary for the collector to access them, thus avoiding page and cache faults.
Partitioning can also be used to allow the heap to be collected incrementally rather than as a whole. Here, we mean that the collector can choose to collect only a subset of the spaces in the heap in the same way that generational collectors preferentially collect only the nursery generation. The benefit is the same: that the collector has a more tightly bounded amount of work to do in any single cycle and hence that it is less intrusive.
One approach is to partition the graph by its topology or by the way in which the mutator accesses objects. One reason for doing this is to ensure that large pointer structures are eventually placed in a single partition that can be collected on its own. Unless this is done, garbage cyclic structures that span partitions can never be reclaimed by collecting a single partition on its own. Collectors like the Train algorithm [Hudson and Moss, 1992] or connectivity-based garbage collection [Hirzel et al, 2003] used the topology of objects. The Train algorithm collects a small space at a time and relocates survivors into the same spaces as other objects that refer to them. Connectivity-based collection uses a pointer analysis to place objects into a directed acyclic graph of partitions, which can be collected in topological order. Objects can also be placed into regions that can be reclaimed in constant time, once it is known that all the objects in a region are dead. Placement can either be done explicitly, as for example by the Real-Time Specification for Java, or automatically guided by a region inferencing algorithm [Tofte et al, 2004].
Pointer analyses have also been used to partition objects into heaplets that are never accessed by more than one thread [Steensgaard, 2000; Jones and King, 2005]. These heaplets can then be collected independently and without stopping other threads. Blackburn and McKinley [2003] exploit the observation that mutators are likely to modify young objects more frequently than old ones. Their Ulterior collector thus manages young objects by copying and old ones by reference counting. High mutation rates do not impose any overhead on copying collection which is also well suited to spaces with high mortality rates. Reference counting is well suited to very large, stable spaces which would be expensive to trace.
Another common approach is to divide the heap into spaces and apply a different collection policy to each space, chosen dynamically [Lang and Dupont, 1987; Detlefs et al, 2004; Blackburn and McKinley, 2008]. The usual reason for this is to allow the heap to be defragmented incrementally, thus spreading the cost of defragmentation over several collection cycles. At each collection, one or more regions are chosen for defragmentation; typically their survivors are evacuated to another space whereas objects in other spaces are marked in place. Copying live data space by space also reduces the amount of space required to accommodate the survivors compared with standard semispace collection. At the extreme, the Mark-Copy collector [Sachindran and Moss, 2003], designed for collection in restricted heaps, copies the whole of its old generation in a single collection cycle, but does so block by block in order to limit the space overhead to a single block. Its successor, MC2 [Sachindran et al, 2004], offers greater incrementality working to achieve good utilisation of available memory and CPU resources while also avoiding large or clustered pauses.
1http://www.memorymanagement.org/.
2It was superseded as the ‘low pause’ collector in Sun Microsystems’ JDK after Java 5 in favour of a concurrent collector.
3Not to be confused with reference lists used by distributed reference counting systems where the target maintains a list of processes that it believes hold references to it.
4Contrary to our conventions, Dimpsey et al call these ‘thread-local heaps’.
5In contrast, the write barrier of Levanoni and Petrank [2001] records a snapshot of the mutated object (see Chapter 5).