
The concurrent and incremental garbage collection algorithms of the preceding chapters strive to reduce the pause times perceived by the mutator, by interleaving small increments of collector work on the same processor as the mutator or by running collector work at the same time on another processor. Many of these algorithms were developed with the goal of supporting applications where long pauses result in the application providing degraded service quality (such as jumpy movement of a mouse cursor in a graphical user interface). Thus, early incremental and concurrent collectors were often called ‘real-time’ collectors, but they were real-time only under certain strict conditions (such as restricting the size of objects). However, as real-time systems are now understood, none of the previous algorithms live up to the promise of supporting true real-time behaviour because they cannot provide strong progress guarantees to the mutator. When the mutator must take a lock (within a read or write barrier or during allocation) its progress can no longer be guaranteed. Worse, preemptive thread scheduling may result in the mutator being descheduled arbitrarily in favour of concurrent collector threads. True real-time collection (RTGC) must account precisely for all interruptions to mutator progress, while ensuring that space bounds are not exceeded. Fortunately, there has been much recent progress in real-time garbage collection that extends the advantages of automatic memory management to realtime systems.
Real-time systems impose operational deadlines on particular tasks within an application. These real-time tasks must be able to respond to application inputs (events) within a fixed time window. A task that fails to meet its real-time constraint may degrade service (for example, dropping a frame while displaying digital video), or much worse, cause catastrophic failure of the system (such as mis-timing the spark-plug ignition signal resulting in damage to an internal combustion engine). Thus, a real-time system must not only be correct logically, it must also be correct with respect to responsiveness to real-time events.
A soft real-time system (like video display) can tolerate missed deadlines at the expense of service quality. Too many missed deadlines will result in unacceptable quality of service, but the occasional missed deadline will not matter much. Printezis [2006] suggests for systems a soft real-time goal that specifies a maximum garbage collection time, a time slice duration and an acceptable failure rate. In any interval in this time slice duration, the collector should avoid using more than the allowed maximum collection time, and any violations of this goal be within the acceptable failure rate.
Figure 19.1: Unpredictable frequency and duration of conventional collectors. Collector pauses in grey.
Such a soft goal is inadequate for hard real-time systems (like engine control) which consider missed deadlines to mean failure of the system. A correct hard real-time system must guarantee that all real-time constraints will be satisfied. In the face of such timing constraints, it is important to be able to characterise the responsiveness of garbage collection in real-time systems in ways that reflect both needs of the application (hard or soft real-time) and the behaviour of the garbage collector [Printezis, 2006].
Overall performance or throughput in real-time systems is less important than predictability of performance. The timing behaviour of a real-time task should be able to be determined analytically by design, or empirically during testing, so that its response-time when deployed in the field can be known ahead of time (to some acceptable degree of confidence). The worst-case execution time (WCET) of a task is the maximum length of time the task could take to execute in isolation (that is, ignoring re-scheduling) on a particular hardware platform. Multitasking real-time systems must schedule tasks so that their realtime constraints are met. Knowing that these constraints will be met at run time involves performing schedulability analysis ahead-of-time, assuming a particular (usually priority-based) run-time scheduling algorithm.
Real-time applications are often deployed to run as embedded systems dedicated to a specific purpose, such as the example above of a control system for engine timing. Single-chip processors predominate in embedded systems, so incremental garbage collection techniques translate naturally to embedded settings, but with multicore embedded processors becoming increasingly common, techniques for concurrent and parallel collection also apply. Moreover, embedded systems often impose tighter space constraints than general-purpose platforms.
For all of these reasons, stop-the-world, parallel, or even concurrent garbage collectors that impose unpredictable pause times are not suited to real-time applications. Consider the collector schedule illustrated in Figure 19.1 which results when the effort required to reclaim memory depends on the total amount and size of objects that the application uses, the interconnections among those objects, and the level of effort required to free enough memory to satisfy future allocations. Given this schedule, the mutator cannot rely on predictable and sustained utilisation of the processor.
19.2 Scheduling real-time collection
When and how to trigger collector work is the main factor affecting the impact of the collector on the mutator. Stop-the-world collectors defer all collector work until some allocation attempt detects that space is exhausted and triggers the collector. An incremental collector will piggyback some amount of collector work on each heap access (using read/write barriers) and allocation. A concurrent collector will trigger some amount of collector work to be performed concurrently (possibly in parallel) with the mutator, but imposes mutator barriers to keep the collector synchronised with the mutator. To maintain steady-state space consumption, the collector must free and recycle dead objects at the same rate (measured by space allocated) as the mutator creates new objects. Fragmentation can lead to space being wasted so that in the worst case an allocation request cannot be satisfied un less the collector itself or a separate compaction phase is able to relocate objects. But object relocation imposes an additional burden that can adversely affect real-time bounds.
There are a number of alternative techniques for scheduling the work of real-time garbage collectors, and for characterising how that work can affect the mutator [Henriksson, 1998; Detlefs, 2004b; Cheng and Blelloch, 2001; Pizlo and Vitek, 2008]. Work-based scheduling imposes collector work as a tax on units of mutator work. Slack-based scheduling runs collector work in the slack portions of the real-time task schedule (that is, when no real-time task is running). The slack can be a significant fraction of overall time when realtime tasks are infrequent or periodic (executing briefly at some known frequency). This can be achieved easily in a priority-scheduled system by giving the collector a lower priority than any of the real-time tasks. Time-based scheduling reserves a pre-defined portion of execution time solely for collector work during which the mutator is stopped. This allows meeting some pre-defined minimum mutator utilisation guarantee.
19.3 Work-based real-time collection
The classic Baker [1978] incremental semispace copying collector is one of the earliest attempts at real-time garbage collection. It uses a precise model for analysing for real-time behaviour founded on the limiting assumption that objects (in this case Lisp cons cells) have a fixed size. Recall that Baker’s read barrier prevents the mutator from accessing fromspace objects, by making the mutator copy any fromspace object it encounters into tospace. This work is bounded because the objects have a single fixed size. Also, each mutator allocation performs some bounded amount of collector work (scanning some fixed number of grey tospace fields, copying their fixed-size fromspace targets as necessary). The more fields scanned per allocation the faster the collection will finish, but the slower the mutator will run. Baker [1978] derived bounds on both time and space for his collector. His space bound was 2R(1 + 1/k), where R is the reachable space, and k is the adjustable time bound defined to be the number of fields scanned at allocation time. Baker did offer some solutions for incremental copying of variable-sized arrays, but these do not feature in his analysis.
Parallel, concurrent replication
Blelloch and Cheng [1999] extended the analysis of Baker [1978] for multiprocessor collection by devising a concurrent and parallel replicating copying collector for which they derive bounds on space and time. In evaluating their subsequent practical implementation of this collector, Cheng and Blelloch [2001] were the first to characterise intrusiveness of collection in terms of minimum mutator utilisation. Because their collector is still work-based, regardless of the efforts to which it goes towards minimising pause times, it can still suffer from unpredictable variation in the distribution of pauses that make it difficult to obtain real-time guarantees for the mutator. In Section 19.5 we will see that minimum mutator utilisation can also be used to drive time-based scheduling of real-time garbage collection by making minimum mutator utilisation an input constraint to the collector. Still, Blelloch and Cheng offer useful insights into the way in which pause times can be tightly bounded, while also bounding space, so we consider its detailed design here.
Machine model. Blelloch and Cheng assume an idealised machine model. A real implementation must grapple with differences between this idealised model and the actual target machine. The machine assumed is a typical shared-memory symmetric multiprocessor, having atomic TestAndSet and FetchAndAdd instructions for synchronisation. These are supported directly in hardware, or can be implemented easily on modern symmetric multiprocessors using LoadLinked/StoreConditionally or CompareAndSwap, though it is important that FetchAndAdd be implemented fairly so that all processors make progress. They also assume a simple interrupt that is used to start and stop incremental collection on each of the processors. This can be implemented using GC-safe points as described in Section 11.6. More importantly, they assume memory accesses to be sequentially consistent, which makes practical implementation of the collector more difficult, since some memory accesses must be ordered appropriately to ensure correctness.
The memory is organised as a contiguous set of locations addressable from [2..M + 1] (so pointers with value 0 and 1 have special meaning) where M is the maximum memory size. Each location can hold at least a pointer.
For timing analysis, the longest time taken by any one instruction is used as the cost of all instructions (interrupts occur between instructions and do not count towards this time).
Application model. The application model assumes the usual mutator operations Read and Write, and New(n) which allocates a new object with n fields and returns a pointer to the first field; it also includes a header word for use by the memory manager. In addition, Blelloch and Cheng require that on each processor every New(n) is followed by n invocations of InitSlot(v) to initialise each of the n fields of the last allocated object of the processor with v, starting at slot 0. A processor must complete all n invocations of InitSlot before it uses the new object or executes another New, though any number of other operations including Read and Write can be interleaved with the InitSlots. Furthermore, the idealised application model assumes that Write operations are atomic (no two processors can overlap execution of a Write). The memory manager further uses a function isPointer(p,i) to determine whether the ith field of the object referenced by p is a pointer, a fact often determined statically by the type of the object, or its class in an object-oriented language.
The algorithm. The collector is structured as a replicating collector in the style of Nettles and O’Toole [1993], except that, instead of a fromspace invariant and logging updates, the mutators obey a replication invariant: whenever the collector is active and a mutator wishes to update an object it must update both the primary and its replica (if one exists). When the collector is active, all allocations make both a primary and a replica in tospace for the mutators to manipulate. Blelloch and Cheng also use a snapshot-at-the-beginning style Yuasa [1990] deletion write barrier to ensure correctness.
Blelloch and Cheng assume a header field forwardingAddress(p) on each primary object p and copyCount (r) on each replica r (these can be stored in the same slot because they apply only to a primary or replica, respectively). The header is used for several purposes: for synchronisation on the primary to control which thread generates the replica, as a forwarding pointer from the primary to the replica, as a count on the replica of how much remains to be copied to it from the primary, and to synchronise on the replica among mutators and the thread copying the object. When a primary object p is white there is only a primary copy and its header is zero (forwardingAddress(p)=null). When the object turns grey and space has been allocated for the replica r, the header of the primary points to the replica (forwardingAddress(p)=r), and the header of the replica contains how many fields remain to be copied (copyCount(r)=n). When the object turns black (is fully copied) then the header of the replica will be zero (copyCount(r) = 0).
The heap is configured into two semispaces as shown in Figure 19.2. Fromspace is bounded by the variables fromBot and fromTop which are private to each thread. The collector maintains an explicit copy stack in the top part of tospace holding pointers to the grey objects. As noted in Section 14.6, Blelloch and Cheng [1999] offer several arguments that this explicit copy stack allows better control over locality and synchronisation than Cheney queues in sharing the work of copying among concurrent collector threads. The area between toBot and free holds all replicas and newly allocated objects. The area between sharedStack and toTop holds the copy stack (growing down from toTop to sharedStack). When free=sharedStack the collector has run out of memory. If the collector is off when this happens then it is turned on. Otherwise an out of memory error is reported. The variables toBot and toTop are also private to each thread, whereas free and sharedStack are shared.

Figure 19.2: Heap structure in the Blelloch and Cheng work-based collector
The code for copying a slot from a primary object to its replica is shown in Algorithm 19.1, where copyOneSlot takes the address of the grey primary object p as its argument, copies the slot specified by the current count stored in the replica, shades the object pointed to by that slot (by calling makeGrey), and stores the decremented count. Finally, the primary object p is still grey if it has fields that still need to be copied, in which case it is pushed back onto the local copy stack (the operations on the local stack are defined earlier in Algorithm 14.8).
The makeGrey function turns an object grey if it is white (has no replica allocated for it) and returns the pointer to the replica. The atomic TestAndSet is used to check if the object is white, since many processors could try to shade an object simultaneously, and it is undesirable to allocate more than one replica in tospace. The processor that manages to win this copy-copy race is the designated copier. The makeGrey function distinguishes three cases for the header forwardingAddress(p):
1. The TestAndSet returns zero so this processor becomes the designated copier and allocates the tospace replica r, sets its header copyCount(r) to the length of the object, sets the header forwardingAddress(p) of the primary to point to the replica, pushes a reference to the primary on a private stack and returns the pointer to r.
2. The TestAndSet returns non-zero, and the value of the header is a valid forwarding pointer so this pointer to the replica can be returned.
3. The TestAndSet returns non-zero, but the value in the header is 1, so another processor is the designated copier but has not yet set the forwarding pointer. The current processor must wait until it can return the proper forwarding pointer.
Algorithm 19.2 shows the code for the mutator operations when the collector is on. The New operation allocates space for the primary and replica copies using allocate, and sets some private variables that parametrise the behaviour of InitSlot, saying where it should write initial values. The variable lastA tracks the address of the last allocated object, lastL notes its length, and lastC holds the count of how many of its slots have already been initialised. The InitSlot function stores the value of the next slot to be initialised in both the primary and replica copies and increments lastC. These initialising stores shade any pointers that are stored to preserve the strong tricolour invariant that black objects cannot point to white objects. The statement collect(k) incrementally copies k words for every word allocated. By design, the algorithm allows a collection cycle to start while an object is only partially initialised (that is, when a processor has lastC≠lastL).
Algorithm 19.1: Copying in the Blelloch and Cheng work-based collector
1 shared gcOn ← false
2 shared free | /* allocation pointer */ |
3 shared sharedStack | /* copy stack pointer */ |
4
5 copyOneSlot (p) : | /* |
6 r ← forwardingAddress(p) | /* pointer to the replica copy */ |
7 i ← copyCount(r)-l | /* index of slot to be copied */ |
8 copyCount(r) ← –(i+i) | /* lock slot to prevent write while copying */ |
9 v ← p[i]
10 if isPointer(p, i)
11 v ← makeGrey(v) | /* grey if it is a pointer */ |
12 r[i] ← v | /* copy the slot */ |
13 copyCount(r) ← i | /* unlock object with decremented index */ |
14 if i > 0
15 localPush(p) | /* push back on local stack */ |
16
17 makeGrey(p) : | /* |
18 if TestAndSet(&forwardingAddress(p)) ≠ 0 | /* race to replicate primary */ |
19 /* we lost the race */
20 while forwardingAddress(p) = 1
21 /* do nothing: wait for a valid forwarding address */
22 else
23 /* we won the race */
24 count ← length(p) | /* length of primary */ |
25 r ← allocate(count) | /* allocate replica */ |
26 copyCount(r) ← count | /* set copy counter for replica */ |
27 forwardingAddress (p) ← r | /* set forwarding address for primary */ |
28 localPush(p) | /* push primary on stack for copying */ |
29 return forwardingAddress(p)
30
31 allocate(n):
32 ref ← FetchAndAdd(&free, n)
33 if ref + n > sharedStack | /* is tospace exhausted? */ |
34 if gcOn
35 error “Out of memory”
36 interrupt (collectorOn) | /* interrupt mutators to start next collection */ |
37 allocate(n) | /* try again */ |
38 return ref
The Write operation first shades any overwritten (deleted) pointer grey (to preserve snapshot reachability), and then writes the new value into the corresponding slot of both the primary and the replica (if it exists). When writing to a grey object it is possible that the designated copier is also copying the same slot. This copy-write race can lead to a lost update, if the mutator writes to the replica after the copier has read the slot from the primary but before it has finished copying the slot to the replica. Thus, the Write operation waits for the copier, both to allocate the replica and to finish copying the slot. It is not a problem for the mutator to write to the primary before the copier locks the slot, since the copier will then copy that value to the replica. The while statements that force the mutator to wait are both time-bounded, the first by the time it takes for the copier to allocate the replica and the second by the time it takes for the copier to copy the slot.
Algorithm 19.2: Mutator operations in the Blelloch and Cheng collector (gcOn=true)
1 lastA | /* per–processor pointer to last allocated object */ |
2 lastL | /* per–processor length of last allocated object */ |
3 lastc | /* per–processor count of number of slots last filled */ |
4
5 Read(p, i):
6 return p[i]
7
8 New(n):
9 p ← allocate(n) | /* allocate primary */ |
10 r ← allocate(n) | /* allocate replica */ |
11 forwardingAddress(p) ← r | /* primary forwards to replica */ |
12 copyCount(r) ← 0 | /* replica has no slots to copy */ |
13 lastA ← p | /* set last allocated */ |
14 lastc ← 0 | /* set count */ |
15 lastL ← n | /* set length */ |
16 return p
17
18 atomic Write(p, i, v):
19 if isPointer(p, i)
20 makeGrey(p[i]) | /* grey old value */ |
21 p[i] ← v | /* write new value into primary */ |
22 if forwardingAddress(p) ≠ 0 | /* check if object is forwarded */ |
23 while forwardingAddress(p) = 1
24 /* do nothing: wait for forwarding address */
25 r ← forwardingAddress(p) | /* get pointer to replica */ |
26 while copyCount(r) = ←(i + 1)
27 /* do nothing: wait while slot concurrently being copied */
28 if isPointer(p, i)
29 v ← makeGrey(v) | /* update replica with grey new value */ |
30 r[i] ← v | /* update replica */ |
31 collect (k) | /* execute k copy steps */ |
32
33 initSlot(v): | /* initialise next slot of last allocated */ |
34 lastA[lastC] ← v | /* initialise primary */ |
35 if isPointer(lastA, lastC)
36 v ← makeGrey(v) | /* replica gets grey initial value */ |
37 forwardingAddress(lastA)[lastC++] ← v | /* initialise replica */ |
38 collect (k) | /* execute k copy steps */ |
InitSlot is used for initialising stores instead of Write because it is much cheaper. The uninitialised slots are implicitly null so do not need a deletion barrier to preserve the snapshot. Also, the new object always has a replica so there is no need to check for the replica’s presence. Finally, the collector is designed so that if a collection cycle starts while an object is only partially initialised, only the initialised slots will be copied (see collectorOn in Algorithm 19.4).
Algorithm 19.3: Collector code in the Blelloch and Cheng work-based collector
1 collect(k):
2 enterRoom()
3 for i ← 0 to k–1
4 if isLocalStackEmpty() | /* local stack empty */ |
5 sharedPop() | /* move work from shared stack to local */ |
6 if isLocalStackEmpty() | /* local stack still empty */ |
7 break | /* no more work to do */ |
8 p ← localPop()
9 copyOneSlot(p)
10 transitionRooms()
11 sharedPush() | /* move work to shared stack */ |
12 if exitRoom()
13 interrupt(collectorOff) | /* turn collector off */ |
Algorithm 19.3 shows the collector function collect(k), which copies k slots. The shared copy stack allows the copy work to be shared among the processors. To reduce the number of invocations of the potentially expensive sharedPop operation (which uses FetchAndAdd), to improve the chances for local optimisation, and to enhance locality, each processor takes most of its work from a private local stack (the shared and private stack operations are defined earlier in Algorithm 14.8). Only when there is no work available in this local stack will the processor fetch additional work from the shared copy stack. After copying k slots, collect places any remaining work back into the shared stack. Note that no two processors can simultaneously execute the code to copy slots (obtaining additional work from the shared copy stack) in lines 2–10 and move copy work back to the copy stack after copying k slots in lines lines 10–12. This is enforced using the ‘rooms’ of Algorithm 14.9, which we discussed in Section 14.6.
Algorithm 19.4 shows the code to start (collectorOn) and stop (collectorOff) the collector. Here, the only roots are assumed to reside in the fixed number of registers REG private to each processor. The synch routine implements barrier synchronisation to block a processor until all processors have reached that barrier. These are used to ensure a consistent view of the shared variables gcOn, free, and sharedStack. When a new collection cycle begins, each processor sets the replica header of its partially initialised last allocated object to the last initialised slot lastC so that only the initialised slots need to be copied. When the collection cycle ends, the registers and the last allocated object are forwarded to refer to their replicas.
Other practical improvements. The original formulation of the real-time replication algorithm [Blelloch and Cheng, 1999] and its subsequent practical implementation [Cheng and Blelloch, 2001; Cheng, 2001] describe a number of other practical improvements to this algorithm. Instead of using FetchAndAdd in every invocation of allocate (line 32) each processor can allocate from a private allocation area as described in Section 7.7. Instead of spin-waiting for the forwarding pointer in makeGrey, because the processor can know the location at which it is going to place an object in its private space, it can then use a CompareAndSwap instead of TestAndSet. Other improvements include deferring the collector work performed in New and InitLoc until each local allocation area fills up with (small) objects, avoiding the cost of double allocations (primary and replica) in New and how to make Write atomic using rooms synchronisation (only one writer can enter the ‘writing room’ at any particular time).
Algorithm 19.4: Stopping and starting the Blelloch and Cheng work-based collector
1 shared gcOn
2 shared toTop
3 shared free
4 shared count ← 0 | /* number of processors that have |
5 shared round ← 0 | /* the current synchronisation round */ |
6
7 synch() :
8 curRound ← round
9 self ← FetchAndAdd(&cnt, 1) + 1
10 if self = numProc | /* round is done, reset for next one */ |
11 cnt ← 0
12 round+ +
13 while round = curRound
14 | /* do nothing: wait until last processor changes |
15
16 collectorOn():
17 synch()
18 gcOn ← true
19 toBot, fromBot ← fromBot, toBot | /* flip */ |
20 toTop, fromTop ← fromTop, toTop
21 free, sharedStack ← toBot, toTop
22 stackLimit ← sharedStack
23 synch()
24 r ← allocate(lastL) | /* allocate replica of last allocated */ |
25 forwardingAddress(lastA) ← r | /* forward last allocated */ |
26 copyCount(r) ← lastC | /* set number of slots to copy */ |
27 if lastC > 0
28 localPush(lastA) | /* push work onto local stack */ |
29 for i ← 0 to length(REG) | /* make roots grey */ |
30 if isPointer(REG, i)
31 makeGrey(REG[i])
32 sharedPush() | /* move work to shared stack */ |
33 synch()
34
35 collectorOff():
36 synch()
37 for i ← 0 to length(REG) | /* make roots grey */ |
38 if isPointer(REG, i)
39 REG[i] ← forwardingAddress(REG[i]) | /* forward roots */ |
40 lastA ← forwardingAddress(lastA)
41 gcOn ← false
42 synch()
Time and space bounds. The considerable effort taken by this algorithm to place a well-defined bound on each increment of collector work allows for precise bounds to be placed on space and the time spent in garbage collection. Blelloch and Cheng [1999] prove that the algorithm requires at most 2(R(1 + 2/k) + N + 5PD) memory words, where P is the number of processors, R is the maximum reachable space during a computation (number of words accessible from the root set), N is the maximum number of reachable objects, D is the maximum depth of any object and k controls the tradeoff between space and time, bounding how many words are copied each time a word is allocated. They also show that mutator threads are never stopped for more than time proportional to k non-blocking machine instructions. These bounds are guaranteed even for large objects and arrays, because makeGrey progresses the grey wavefront a field at a time rather than a whole object at a time.
Performance. Cheng and Blelloch [2001] implemented their collector for ML, a statically typed functional language. ML programs typically have very a high allocation rates, posing a challenge to most collectors. Results reported are for a 64-processor Sun Enterprise 10000, with processor clock speeds on the order of a few hundred megahertz. On a single processor, the collector imposes an average (across a range of benchmarks) overhead of 51% compared to an equivalent stop-the-world collector. These are the costs to support both parallel (39%) and concurrent (12%) collection. Nevertheless, the collector scales well for 32 processors (17.2 × speedup) while the mutator does not scale quite so well (9.2 × speedup), and near perfectly for 8 processors (7.8× and 7.2×, respectively). Minimum mutator utilisation for the stop-the-world collector is zero or near zero for all benchmarks at a granularity of 10ms, whereas the concurrent collector supports a minimum mutator utilisation of around 10% for k = 2 and 15% for k = 1.2. Maximum pause times for the concurrent collector range from three to four milliseconds.
Uneven work and its impact on work-based scheduling
The argument against work-based scheduling for real-time garbage collection is that it results in uneven minimum mutator utilisation, with the operations of the mutator so tightly-coupled to those of the collector. A worst-case execution time analysis for work-based copying collection must assume the worst-case time for all mutator operations on the heap. For the Baker [1978] collector, reading a pointer slot may require copying its target. For Lisp cons cells this is a bounded cost, but variable-sized objects like arrays cause problems. Allocation can cause some fixed amount of collector work, and at the beginning of the collection cycle will also involve the flip, scanning the roots and copying their targets. This includes the global variables (bounded in each particular program) and local (thread stack) variables (potentially unbounded up to stack overflow). In summary, the worst case is so far from the usual case that the resulting worst-case execution time analysis is virtually useless for schedulability analysis.
There have been several attempts at containing these worst-case overheads for work-based scheduling. To bound the cost of stack scanning Cheng and Blelloch [2001] propose dividing the stack into fixed-size stacklets. The flip needs only to scan the top-most stacklet in which the mutator is currently active, leaving the other stacklets for later scanning in due course. To prevent a mutator from returning to an unscanned stacklet, this approach adds a stack barrier to the operations that pop the stacklets as the mutator executes, requiring the mutator to scan the stacklet being returned to. Detlefs [2004b] notes two approaches for handling the case in which the mutator attempts to return into a stacklet that is already in the process of being scanned by the collector. Either the mutator must wait for the collector, or the collector must abort the scanning of that stacklet, deferring that work to the mutator.
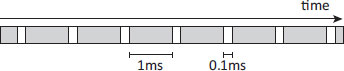
Figure 19.3: Low mutator utilisation even with short collector pauses. The mutator (white) runs infrequently while the collector (grey) dominates.
Similarly, variable-sized objects can be broken into fixed-size oblets, and arrays into arraylets, to place bounds on the granularity of scanning/copying to advance the collector wavefront. Of course, these non-standard representations require corresponding changes to the operations for accessing object fields and indexing array elements, increasing space and time overheads for the additional indirections [Siebert, 1998, 2000, 2010].
Nevertheless, Detlefs considers the asymmetric overheads of pure work-based scheduling to be the final nail in its coffin. For example, in the Baker concurrent copying collector mutator operations have costs that vary greatly depending on where in the collector cycle they occur. Before a flip operation, the mutator is taxed only for the occasional allocation operation in order to progress the wavefront, while reads are most likely to load references to already copied objects. For some time after the flip, when only mutator roots have been scanned, the average cost of reads may come close to the theoretical worst case as they are forced to copy their targets. Similarly, for the Blelloch and Cheng [1999] collector, even though writes are much less common than reads, there is still wide variability in the need to replicate an object at any given write.
This variability can yield collector schedules that preserve predictably short pause times, but do not result in satisfactory utilisation because of the frequency and duration of collector work. Consider the schedule in Figure 19.3 in which the collector pauses are bounded at a millisecond, but the mutator is permitted only a tenth of a millisecond between collector pauses in which to run. Even though collector work is split into predictably short bounded pauses, there is insufficient time remaining for a real-time mutator to meet its deadlines.
While work-based scheduling may result in collector overhead being spread evenly over mutator operations, on average, the big difference between average cost and worst-case cost leaves worst-case execution time analysis for work-based scheduling ineffective. The result is unnecessary over-provisioning of processor resources resulting in reduced utilisation of the processor by the mutator.
In a non-copying concurrent collector, where the mutator write barrier simply shades the source or old/new target object, mutator overheads for accessing the heap are relatively tightly bounded. However, because allocations come in bursts, work-based scheduling still results in wide variation in the GC overheads imposed on mutators.
For this reason, more advanced scheduling approaches treat collector work as something that must be budgeted for in a way that does not make it a pure tax on mutator work, essentially by treating garbage collection as another real-time task that must be scheduled. This results in mutator worst-case execution time analysis that is much closer to actual average mutator performance, allowing for better processor utilisation. Rare but potentially costly operations, such as flipping the mutator, need only be short enough to complete during the portion of execution made available to the collector.
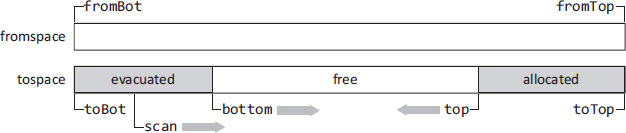
Figure 19.4: Heap structure in the Henriksson slack-based collector
19.4 Slack-based real-time collection
Henriksson attacks the real-time collector scheduling problem by adopting the rule that garbage collection should be completely avoided while high priority (real-time) tasks are executing [Magnusson and Henriksson, 1995; Henriksson, 1998]. Garbage collection work is instead delayed until no high-priority tasks are eligible for execution. Allocation by high-priority tasks is not taxed, while low-priority tasks perform some collector work when allocating. A special task, the high-priority garbage collection task, is responsible for performing collector work that was omitted while the high-priority tasks were executing, as implied by the allocations performed by the high-priority tasks. The high-priority garbage collection task has a priority lower than the high-priority tasks, but higher than the low-priority tasks. It must always ensure that enough free memory is initialised and available for allocation to meet the requirements of the high-priority tasks. Thus, collector work operates entirely in the slack in the real-time task schedule.
The heap is configured into two semispaces as shown in Figure 19.4. New objects are allocated at the top of tospace, at the position of the pointer top. Evacuated objects are placed at the bottom of tospace, at the position designated by bottom. The collector scans the evacuated objects in the usual Cheney style, evacuating all fromspace objects they refer to. Low-priority threads perform some evacuation work incrementally as new objects are allocated at the top of tospace. The position of scan indicates the progress of the collector in scanning the evacuated objects.
Henriksson describes his approach in the context of a Brooks-style concurrent copying collector that uses an indirection barrier on all accesses, including a Dijkstra insertion write barrier to ensure that the new target object is in tospace, copying it if not. This maintains a strong invariant for concurrent collection: no tospace object contains references to fromspace objects. However, Henriksson does not impose the full copying cost of the write barrier on high-priority tasks. Instead, objects are evacuated lazily. The write barrier simply allocates space for the tospace copy, but without actually transferring the contents of the fromspace original. Eventually, the garbage collector will run (whether as the high-priority garbage collection task, or as a tax on allocation by low-priority tasks), and perform the deferred copying work when it comes to scan the contents of the tospace copy. Before scanning the tospace version the collector must copy the contents over from the fromspace original. To prevent any mutator from accessing the empty tospace copy before its contents have been copied over, Henriksson exploits the Brooks indirection barrier by giving every empty tospace shell a back-pointer to the fromspace original. This lazy evacuation is illustrated in Figure 19.5.
As sketched in Algorithms 19.5 and 19.6, the collector is similar to that of concurrent copying (Algorithm 17.1), but uses the Brooks indirection barrier to avoid the need for a tospace invariant on the mutators, and (like Sapphire) defers any copying from the mutator write barrier to the collector. Note that the temporary toAddress pointer allows the collector to forward references held in tospace copies, even while the mutator continues to operate in fromspace, since this toAddress pointer is distinct from the forwardingAddress header word used by the mutator.
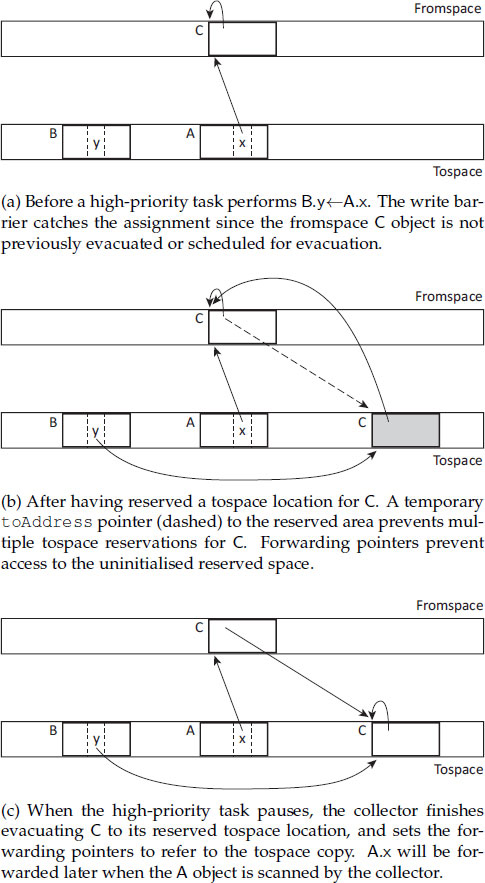
Figure 19.5: Lazy evacuation in the Henriksson slack-based collector. Henriksson [1998]. Reprinted by permission.
Algorithm 19.5: The Henriksson slack-based collector
1 coroutine collector:
2 loop
3 while bottom < top | /* tospace is not full */ |
4 yield /* revert to mutator */
5 flip()
6 for each fld in Roots
7 process(fld)
8 if not behind()
9 yield /* revert to mutator */
10 while scan < bottom
11 scan ← scanObject(scan)
12 if not behind()
13 yield /* revert to mutator */
14
15 flip():
16 toBot, fromBot ← fromBot, toBot
17 toTop, fromTop ← fromTop, toTop
18 bottom, top ← toBot, toTop
19 scan ← bottom
20
21 scanObject(toRef):
22 fromRef ← forwardingAddress(toRef)
23 move(fromRef, toRef)
24 for each fld in Pointers(toRef)
25 process(fld)
26 forwardingAddress(fromRef) ← toRef
27 return toRef + size(toRef)
28
29 process(fld):
30 fromRef ← *fld
31 if fromRef = null
32 fld ← forward(fromRef) | /* update with tospace reference */ |
33
34 forward(fromRef) :
35 toRef ← forwardingAddress(fromRef)
36 if toRef = fromRef | /* not evacuated */ |
37 toRef ← toAddress(fromRef)
38 if toRef = null | /* not scheduled for evacuation (not marked) */ |
39 toRef ← schedule(fromRef)
40 return toRef
41
42 schedule(fromRef):
43 toRef ← bottom
44 bottom ← bottom + size(fromRef)
45 if bottom > top
46 error “Out of memory”
47 toAddress(fromRef) ← toRef | /* schedule for evacuation (mark) */ |
48 return toRef
Algorithm 19.6: Mutator operations in the Henriksson slack-based collector
1 atomic Read(src, i) :
2 src ← forwardingAddress(src) | /* Brooks indirection */ |
3 return src[i]
4
5 atomic Write(src, i, ref):
6 src ← forwardingAddress(src) | /* Brooks indirection */ |
7 if ref in fromspace
8 ref ← forward(ref)
9 src[i] ← ref
10
11 atomic NewHighPrionty(size):
12 top ← top ← size
13 toRef ← top
14 forwardingAddress(toRef) ← toRef
15 return toRef
17 atomic NewLowPriority(size):
18 while behind()
19 yield /* wake up the collector */
20 top ← top ← size
21 toRef ← top
22 if bottom > top
23 error "Out of memory"
24 forwardingAddress(toRef) ← toRef
25 return toRef
The collector itself is specified as a coroutine, so that collector execution interleaves with the low-priority mutator tasks at well-defined yield points, though high-priority tasks can preempt the collector at any time to regain control. If the collector is in the middle of copying an object, the copy is simply aborted and restarted when the collector resumes. Also, Henriksson assumes that the execution platform is a uniprocessor, so that disabling scheduler interrupts is sufficient to implement atomic operations.
The amount of work to perform in each collector increment (controlled by the call to behind) must ensure that fromspace is completely evacuated before tospace fills up, thus finishing a collector cycle. Let us assume that the amount of work (in terms of bytes processed) needed in the worst case to evacuate all live objects out of fromspace and to initialise enough memory to satisfy allocation requests of the high-priority threads during a collection cycle is Wmax, and that after the flip at least Fmin bytes of memory must be free and available for allocation. That is, Wmax indicates the maximum work needed to complete a collection cycle and Fmin the minimum space that must be free when the cycle completes. Then the minimum GC ratio GCRmin is defined as:
The current GC ratio GCR is the ratio between performed GC work W and the amount A of new allocated objects in tospace:
Allocation by the mutator causes A to increase, while GC work increases W. The collector must perform enough work W to make sure that the current GC ratio is no less than the minimum GC ratio (GCR ≥ GCRmin). This will guarantee that fromspace is empty (all live objects have been evacuated) before tospace is filled, even in the worst case.
Allocation of memory by low-priority tasks is throttled so that the current GC ratio GCR does not drop too low (below GCRmin), by giving the collector task priority. The upper bound on the collector work performed during allocation will be proportional to the size of the allocated object.
If a high-priority task is activated shortly before a semispace flip is due then the remaining memory in tospace may not be sufficient to hold both the last objects to be allocated by the high-priority task and the last objects to be evacuated from fromspace. The collector must ensure a sufficiently large buffer between bottom and top for these objects, large enough to hold all new objects allocated by the high-priority tasks while the collector finishes the current cycle. To do this, the application developer must estimate the worst-case allocation needed by the high-priority tasks in order to run, as well as their periods and worst-case execution times for each period. Henriksson suggests that this job is easy enough for the developer because high-priority tasks in a control system are written to be fast and small, with little need to allocate memory. He provides an analytical framework for deciding schedulability and the memory headroom needed by high-priority tasks, given a large set of program parameters such as task deadlines, task periods, and so on.
The overhead to high-priority tasks for collector activity consists of tight bounds on the instructions required for memory allocation, pointer dereferencing and pointer stores. Of course, instruction counts alone are not always a reliable measure of time, in the face of loads that may miss in the cache. Worst-case execution time analysis must either assume caches are disabled (slowing down all loads) or the system must be tested empirically to ensure that real-time deadlines are met under the expected system load.
Heap accesses require single instruction indirection through the forwarding pointer, plus the overhead of disabling interrupts. Pointer stores have worst-case overhead on the order of twenty instructions to mark the target object for later evacuation. Allocation requires simply bumping a pointer and initialising the header (to include the forwarding pointer and other header information), having overhead on the order of ten instructions.
Low-priority tasks have the same overheads for heap accesses and pointer stores. On allocation, the worst-case requirement is to perform collector work proportional to the size of the new object. The exact worst case for allocation depends on the maximum object size, total heap size, maximum live object set, and the maximum collector work performed within any given cycle.
Worst-case latency for high-priority tasks depends on the time for the collector to complete (or abort) an ongoing item of atomic work, which is short and bounded. Henriksson states that latency is dominated more by the cost of the context switch than the cost of completing an item of atomic work.
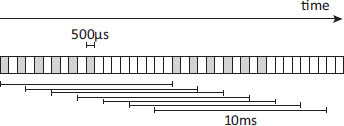
Figure 19.6: Metronome utilisation. Collector quanta are shown in grey and mutator quanta in white.
The programmer must provide sufficient information about the application program, and the high-priority tasks, to compute the minimum GC ratio and to track the GC ratio as the program executes so that the collector does not disrupt the high-priority tasks. The period and worst-case execution times for each high-priority task is required, along with its worst-case allocation need for any one of its periodic invocations, so as to calculate the minimum buffer requirements to satisfy high-priority allocations. The programmer must also provide an estimate of the maximum live memory footprint of the application. These parameters are sufficient to perform worst-case execution time analysis, and schedulability analysis, for the high-priority real-time tasks. Henriksson [1998] provides further details.
19.5 Time-based real-time collection: Metronome
Slack-based scheduling of the collector requires sufficient slack available in the schedule of high-priority real-time tasks in which to run the collector. Time-based scheduling treats minimum mutator utilisation as an input to the scheduling problem, with the scheduler designed to maintain minimum mutator utilisation while providing real-time bounds. This approach was first used in the Metronome real-time garbage collector for Java [Bacon et al, 2003a]. Metronome is an incremental mark-sweep collector with partial on-demand compaction to avoid fragmentation. It uses a deletion write barrier to enforce the weak tricolour invariant, marking live any object whose reference is overwritten during a write. Objects allocated during marking are black. The overhead of simply marking on writes is much lower (and more predictable) than replicating as in Blelloch and Cheng [1999].
After sweeping to reclaim garbage, Metronome compacts if necessary, to ensure that enough contiguous free space is available to satisfy allocation requests until the next collection. Like Henriksson [1998], Metronome uses Brooks-style forwarding pointers, imposing an indirection on every mutator access.
Metronome guarantees the mutator a predetermined percentage of execution time, with use of the remaining time at the collector’s discretion: any time not used by the collector will be given to the mutator. By maintaining uniformly short collector pause times Metronome is able to give finer-grained utilisation guarantees than traditional collectors. Using collector quanta of 500 microseconds over a 10 millisecond window Metronome sets a default mutator utilisation target of 70%. This target utilisation can also be tuned further for the application to meet its space constraints. Figure 19.6 shows a 20-millisecond Metronome collector cycle split into 500-microsecond time slices. The collector preserves 70% utilisation over a 10-millisecond sliding window: there are at most 6 collector quanta and correspondingly at least 14 mutator quanta in any window. Here, each collector quantum is followed by at least one mutator quantum so that pauses are limited to the length of one quantum, even if utilisation would still be preserved by back-to-back quanta so as to minimise pauses. Given a minimum mutator utilisation target below 50% then a window may schedule more collector quanta than mutator quanta so some instances of back-to-back collector quanta will be needed to ensure that the collector gets its share of the window.
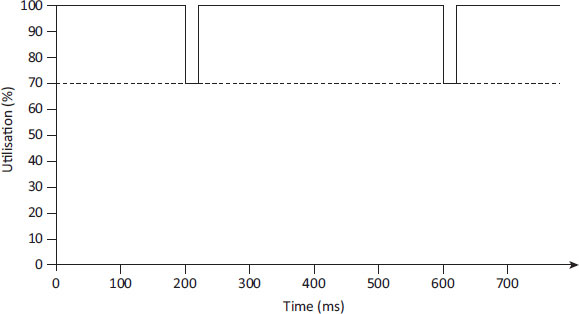
Figure 19.7: Overall mutator utilisation in Metronome
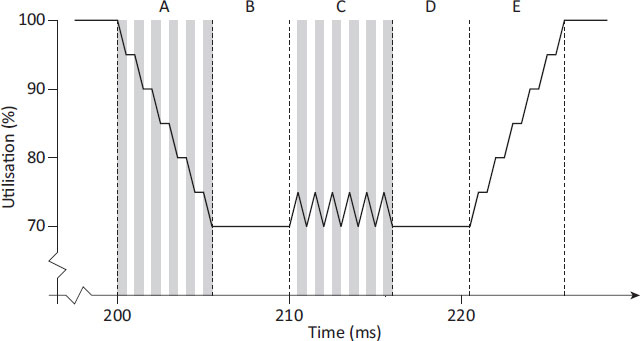
Figure 19.8: Mutator utilisation in Metronome during a collection cycle.
First published on IBM developerWorks: http://www.ibm.com/developerworks.
Of course, when the collector is not active all quanta can be used by the mutator, giving 100% utilisation. Overall, the mutator will see utilisation drop during periods that the collector is running, but never lower than the target utilisation. This is illustrated in Figure 19.7, which shows overall mutator utilisation dropping for each collector cycle.
Figure 19.8 shows mutator utilisation over the same collector cycle that was illustrated in Figure 19.6 (grey bars indicate each collector quantum while white is the mutator). At time t on the x-axis this shows utilisation for the ten millisecond window leading up to time t. Note that while the schedule in Figure 19.6 is perfect in that utilisation is exactly 70% over the collector cycle, real schedules will not be quite so exact. A real scheduler will typically allow collector quanta to run until minimum mutator utilisation is close to the target MMU and then back off to prevent overshooting the target.
Section A of the figure is a staircase graph where the descending portions correspond to collector quanta and the flat portions correspond to mutator quanta. The staircase shows the collector maintaining low pause times by interleaving with the mutator, as utilisation steps down to the target. Section B comprises only mutator activity so as to preserve mutator utilisation across all sliding windows that cover that section. It is common to see this pattern showing collector activity only at the beginning of a window because the collector runs whenever it is allowed to (while preserving pause times and utilisation). This means the collector will exhaust its allotted time at the beginning and then allow the mutator to recover for the remainder of the window. Section C shows collector activity when mutator utilisation is near the target. Ascending portions represent mutator quanta, where the scheduler detects utilisation rising above the target, and descending portions are collector quanta where the scheduler permits the collector to run to bring utilisation back close to the target. The sawtooth results from the interleaving of the mutator with the collector to preserve low pause times while also preserving the target utilisation. Section D shows that once the collector finishes its cycle the mutator must run for a while before utilisation begins to rebound. In Section E the mutator regains 100% utilisation stepping up the staircase from the target.
Metronome uses a number of techniques to achieve deterministic pause times while guaranteeing collector safety. The first of these addresses the unpredictability of allocating large objects when the heap becomes fragmented. The remainder advance predictability by keeping collector pause times deterministically short.
Arraylets. Metronome was implemented to support arraylets to allow allocation of arrays in multiple chunks. This allows a degree of tolerance to fragmentation without the need to perform compaction (which can adversely affect predictability). Large arrays can be allocated as a single contiguous spine object, which then contains pointers to separately allocated fixed-size arraylets that contain the array elements. The size is a power of two so that the division operation needed for indexing can be implemented using a shift. This allows simple computation of the element position, using an extra indirection through the spine. Metronome uses an arraylet size of two kilobytes and a maximum block size of sixteen kilobytes for the spine, allowing arrays of up to eight megabytes in size.
Read barrier. Like Henriksson [1998], Metronome uses a Brooks-style read barrier to ensure that the overhead for accessing objects has uniform cost even if the collector has moved them. Historically, read barriers were considered too expensive to implement in software — Zorn [1990] measured their run-time overhead at around 20% — but Metronome applies several optimisations to reduce their overhead to 4% on average. First, it uses an eager read barrier, forwarding all references as they are loaded from the heap, to make sure that they always refer to tospace. Thus, accesses from the stacks and registers via these references incur no indirection overhead. In contrast, a lazy read barrier would incur indirection every time a reference held in the stacks or registers is used. The cost for this is that whenever a collector quantum moves objects it must also forward all references held in the registers and stacks. Second, Metronome applies several common compiler optimisations to reduce the cost of read barriers, such as common subexpression elimination, and specialised optimisations such as barrier sinking to move the barrier to the point of use, allowing the barrier and use null-checks to be combined [Bacon et al, 2003a].
Scheduling the collector. Metronome uses two different threads to control for both consistent scheduling and short, uninterrupted pause times. The alarm thread is a very high priority thread (higher than any mutator thread) that wakes up every 500 microseconds. It acts as the ‘heartbeat’ for deciding whether to schedule a collector quantum. If so, it initiates suspension of the mutator threads, and wakes the collector thread. The alarm thread is active only long enough to carry out these duties (typically under 10 microseconds) so that it goes unnoticed by the application.
The collector thread performs the actual collector work for each collector quantum. It must first complete the suspension of the mutator threads that was initiated by the alarm thread. Then it will perform collector work for the remainder of the quantum, before restarting the mutator threads and going back to sleep. The collector thread can also preemptively sleep if it is unable to complete its work before the quantum ends.
Metronome produces consistent CPU utilisation because the collector and mutator are interleaved using fixed time quanta. However, time-based scheduling is susceptible to variations in memory requirements if the mutator allocation rate varies over time.
Suspending the mutator threads. Metronome uses a series of short incremental pauses to complete each collector cycle. However, it must still stop all the mutator threads for each collector quantum, using a handshake mechanism to make all the mutator threads stop at a GC-safe point. At these points, each mutator thread will release any internally held run-time metadata, store any object references from its current context into well-described locations, signal that it has reached the safe point and then sleep while waiting for a resume signal. Upon resumption each thread will reload object pointers for the current context, reacquire any necessary run-time metadata that it previously held and then continue. Storing and reloading object pointers allows the collector to update the pointers if their targets move during the quantum. GC-safe points are placed at regularly-spaced intervals by the compiler so as to bound the time needed to suspend any mutator thread.
The suspend mechanism is used only for threads actively executing mutator code. Threads that do not access the heap, threads executing non-mutator ‘native’ code, and already suspended mutator threads (such as those waiting for synchronisation purposes) are ignored. If these threads need to begin (or return to) mutating the heap (for example, when returning from ‘native’ code, invoking operations of the Java Native Interface, or accessing other Java run-time structures), they will suspend themselves and wait for the collector quantum to complete.
Ragged root scanning. Metronome scans each complete thread stack within a single collector quantum so as to avoid losing pointers to objects. Developers must make sure not to use deep stacks in their real-time applications so as to permit each stack to be scanned in a single quantum. Though each whole stack must be scanned atomically in a single quantum, Metronome does allow scanning of distinct thread stacks to occur in different quanta. That is, the collector and mutator threads are allowed to interleave their execution while the collector is scanning the thread stacks. To support this, Metronome imposes an insertion write barrier on all unscanned threads, to make sure they do not hide a root reference behind the wave front before the collector can scan it.
One of the biggest contributions of Metronome is a formal model of the scheduling of collection work and its characterisation in terms of mutator utilisation and memory usage [Bacon et al, 2003a]. The model is parametrised by the instantaneous allocation rate A* (τ) of the mutator over time, the instantaneous garbage generation rate G* (τ) of the mutator over time and the garbage collector processing rate P (measured over the live data). All are defined in units of data volume per unit time. Here, time τ ranges over mutator time, idealised for a collector that runs infinitely fast (or in practice assuming there is sufficient memory to run without collecting).
These parameters allow simple definitions of the amount of memory allocated during an interval of time (τ1, τ2) as
and similarly for garbage generated as
The maximum memory allocated for an interval of size Δτ is
which gives the maximum allocation rate1
The instantaneous memory requirement of the program (excluding garbage, overhead, and fragmentation) at a given time τ is
Of course, real time must also include the time for the collector to execute, so it is helpful to introduce a function Φ : t → τ that maps from real time t to mutator time τ, where τ ≤ t. A function that operates in mutator time is written f* whereas a function that operates in real time is written f. Thus, the live memory of the program at time t is
and the maximum memory requirement over the entire program execution is
Time utilisation. Time-based scheduling has two additional parameters: the mutator quantum QT and the collector quantum CT, being the amount of time that the mutator and collector (respectively) are allowed to run before yielding. These allow derivation of minimum mutator utilisation as
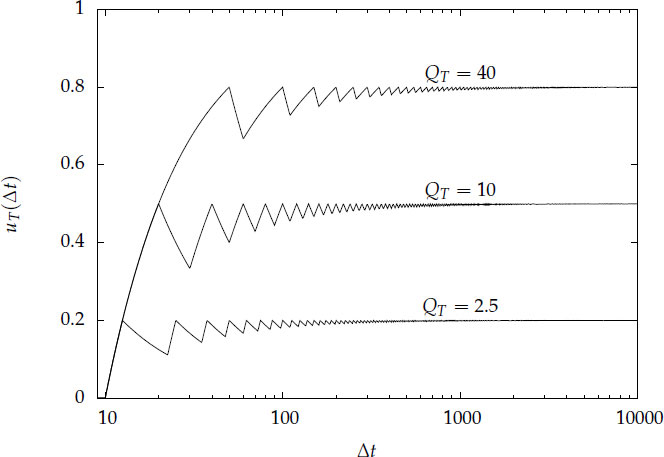
Figure 19.9: Minimum mutator utilisation uT(Δt) for a perfectly scheduled time-based collector. CT = 10. Utilisation converges to . Increasing the frequency of the collector (reducing the mutator quantum) produces faster convergence.
where is the length of whole mutator quanta in the interval and x is the size of the remaining partial mutator quantum, defined as
Asymptotically, minimum mutator utilisation approaches the expected ratio of total time given to the mutator versus the collector:
For example, consider a perfectly scheduled system that has a collector quantum CT = 10, which is the maximum pause that will be experienced by the mutator. Figure 19.9 plots minimum mutator utilisation for mutator quanta of QT = 2.5, QT = 10 and QT = 40. Notice that uT(Δt) converges to in the limit for large Δt, and that more frequent collection (reducing the mutator quantum QT) leads to faster convergence. Also, note that the x term has more impact at the small time scales of interest in real-time systems. Of course, in practice the collector will usually run only intermittently, so uT (Δt) is only a lower bound on mutator utilisation.
Space utilisation. As already noted, space utilisation will vary depending on the mutator allocation rate. Assuming constant collector rate P, at time t the collector will run for time m(t)/P to process the m(t) live data (work is proportional to the tracing needed to mark the live data). In that time, the mutator will run for quantum QT per quantum CT of the collector. Thus, to run a collection at time t requires an excess space overhead of
allowing definition of the maximum excess space required as
Freeing an object in Metronome can take as long as three collection cycles: one to collect the object, two if the object became garbage only after the current snapshot cycle began so it cannot be collected until the next cycle and three if the object needs also to be relocated before its space can be reused.
Thus, the space required (ignoring internal fragmentation) at time t is
while the overall space needed is
These are in the worst case that all garbage objects are dragged into the next collector cycle and that they all need to be moved. The expected space needed is simply m + eT.
Mutation. Mutation also has a space cost because the write barrier must record every deleted and inserted reference. It must filter null references and marked objects so as to place a bound on collector work (at most all the objects in the heap will be marked live), while keeping the cost of the write barrier constant. Thus, in the worst case, the write log can have as many entries as there are objects. This space must be accounted for by treating allocation of the log entries as an indirect form of allocation.
Sensitivity. Metronome will behave as predicted only when given accurate estimates of the parameters used to describe the application and the collector: the application allocation rate A*(t) and garbage generation rate G*(t), and the collector processing rate P and the quantisation parameters QT and CT. Utilisation uT depends solely on QT and CT, so utilisation will remain steady (subject only to any jitter in the operating system delivering a timely quantum signal and the minimum quantum it can support).
The excess space required for collection eT(t), which determines the total space sT needed, depends on both maximum application memory usage m and the amount of memory allocated over an interval. If the application developer underestimates either the total space required m or the maximum allocation rate a* then the total space requirement sT may grow arbitrarily. Time-based collectors suffer from such behaviour particularly when there are intervals of time in which the allocation rate is very high. Similarly, the estimate of the collector processing rate P must be a conservative underestimate of the actual rate.
Fortunately, a collection cycle runs for a relatively long interval of mutator execution time
so the allocation rate in that time will be close to the average allocation rate, resulting in little variation in space consumed so long as the estimate of maximum memory required m is accurate.
Comparison with work-based scheduling. A similar analysis of work-based scheduling yields the opportunity to compare time-based and work-based scheduling. However, this analysis is compromised because operations of the mutator can affect the time allocated to it. More formally, for time-based scheduling the time dilation Φ from t to τ is linear and fixed, whereas for work-based scheduling the dilation is variable and non-linear, and dependent on the application.
The parameters for work-based scheduling reflect that the mutator and collector interleave by triggering the collector after some amount of allocation to perform some amount of collector work: the work-based mutator quantum QW and collector quantum CW being the amount of memory that the mutator and collector (respectively) are allowed to allocate/process before yielding.
Because work-based time dilation is variable and non-linear there is no way to obtain a closed-form solution for minimum mutator utilisation. Each collector increment processes CW memory at rate P, so each pause for collection takes time d = CW/P. Each mutator quantum involves allocation of QW memory, so the minimum total mutator time Δτi, for i quanta is the minimum Δτi, that solves the equation
Increasing the time interval does not decrease the maximum amount of allocation in that time, so α* (Δτ) increases monotonically. Thus, Δτi > Δτi−1, so Equation 19.15 can be solved using an iterative method. Let k be the largest integer such that
so that the minimum mutator utilisation over an interval t is
where Δτk is the time taken by k whole mutator quanta in Δt and y is the size of the remaining partial mutator quantum, defined as
Note that minimum mutator utilisation uW(Δt) will be zero for Δt < d. Moreover, any large allocation of nQW bytes will force the collector to perform n units of work leading to a pause lasting time nd in which the mutator will experience zero utilisation. This reveals analytically that the application developer must take care with a work-based collector to achieve real-time bounds by avoiding large allocations and making sure that allocation is spaced evenly.
Now, minimum mutator utilisation depends on the allocation rate a* (Δτ), where Δτ ≤ Δt, and on the collector processing rate P. Suppose that the interval Δt over which we require real-time performance is small (say twenty milliseconds), so the peak allocation rate for this interval is likely to be quite high. Thus, at real-time scales work-based minimum mutator utilisation uW (Δt) will vary considerably with the allocation rate. In contrast, note that the Δτ in which the time-based collector is dependent on allocation rate is at a much larger scale: the time needed for a complete garbage collection cycle.
Analysing for space, the excess space required to perform a collection at time t is
and the excess space required for a collection cycle over its whole execution is
These will be accurate as long as the application developer’s estimate of total live memory m is accurate. Also, note that the excess eW for a whole collection cycle will exceed the maximum memory m needed for execution of the program unless QW < CW. The space requirement of the program at time t is
and the space required overall is
To sum up, while a work-scheduled collector will meet its space bound so long as m is correctly estimated, its minimum mutator utilisation will be heavily dependent on the allocation rate over a real-time interval, while a time-based collector will guarantee minimum mutator utilisation easily but may fluctuate in its space requirements.
Time-based scheduling yields the robustness needed for real-time collection, but when the input parameters to the collector are not accurately specified it may fail to reclaim sufficient memory. The only way for it to degrade gracefully is to slow down the allocation rate.
One approach to reducing the total allocation rate is to impose a generational scheme. This treats the nursery as a filter to reduce the allocation rate into the primary heap. Focusing collector effort on the portion of the heap most likely to yield free memory results in higher mutator utilisation and also reduces the amount of floating garbage. However, traditional nursery collection is unpredictable both in terms of the time to collect and the quantity of data that is promoted. Syncopation is an approach for performing nursery collection synchronously with the mature-space collector, where the nursery is evacuated at the beginning of the mature-space collection cycle and at the start of sweeping, as well as outside the mature-space collection cycle [Bacon et al, 2005]. It relies on an analytic solution for utilisation in generational collection taking the nursery survival rate as a parameter and sizing the nursery such that evacuation is needed only once per real-time window. The analysis informs whether generational collection should be used in any given application. Syncopation handles the situation where temporary spikes in allocation rate make it impossible to evacuate the nursery quickly enough to meet real-time bounds by moving the work triggered by the temporary spike to a later time. Frampton et al [2007] adopt a different approach, allowing nursery collection to be performed incrementally so as to avoid having pause times degenerate to the time needed to evacuate the nursery.
Another strategy for slowing the allocation rate is simply to add an element of work-based collection to slow the mutator down, but of course this can lead to missed deadlines. Alternatively, slack-based scheduling achieves this by preempting the low-priority threads as necessary for the collector to keep up with allocation. So long as sufficient low-priority slack is available then real-time deadlines will be preserved. These observations lead to the following Tax-and-Spend methodology that combines slack-based and time-based scheduling.
19.6 Combining scheduling approaches: Tax-and-Spend
Metronome works best on dedicated uniprocessor or small multiprocessor systems, because of its need to suspend the mutator while an increment of collector work is performed. Typical work-based collectors can suffer latencies that are orders of magnitude worse than time-based schemes. Henriksson’s slack-based scheduling is best-suited to periodic applications and is fragile under overload conditions when there is no available slack. To address these limitations Auerbach et al [2008] devised a general scheduling methodology called Tax-and-Spend that subsumes the work-based, slack-based and time-based approaches. When applied to Metronome, the Tax-and-Spend methodology results in latencies almost three times shorter, comparable utilisation at a time window two and a half times shorter, and mean throughput improvements of 10% to 20%.
The basic principle of Tax-and-Spend is that each mutator thread is required to engage in some amount of collection work (taxation) at a rate and intervals appropriate to its desired minimum mutator utilisation. Collection work also proceeds in any available slack left over by the mutators, building up credits that mutators can later spend to preserve or improve their utilisation by avoiding some amount of collector work.
Taxation can occur at any GC-safe point as a result of some global decision, but a thread-specific check for pending collector work is imposed on every slow path allocation (when the thread’s local allocation buffer is exhausted) that also enables a decision based on mutator work (measured by units of allocation, thread execution time, safe points executed, absolute physical time, or whatever virtualised time makes sense).
As we have already seen, minimum mutator utilisation is simple for developers to reason about because they can consider the system as just running somewhat slower than the native processor speed until the responsiveness requirements approach the quantisation limits of the garbage collector. As a measure of garbage collector intrusiveness, minimum mutator utilisation is superior to maximum pause time since it accounts for clustering of the individual pauses that cause missed deadlines and pathological slowdowns. Tax-and-Spend scheduling allows different threads to run at different utilisations, providing flexibility when threads have widely varying allocation rates, or for threads having particularly stringent deadlines that must be interrupted as little as possible. Also, background threads on spare processors can be used to offload collector work to obtain high utilisation for mutator threads. The time metric can be physical or virtual as best suits the application. Of course, this does mean that any analysis of the application must compose the real-time constraints of the individual threads to obtain a global picture of application behaviour.
Per-thread scheduling. To manage per-mutator utilisation, Tax-and-Spend must measure and schedule collector work based on per-thread metrics and allow a collector increment to be charged to a single mutator thread. All collector-related activity can be accounted for in each thread (including the overheads of extending the mutation log, initialising an allocation page, and other bookkeeping activities). The collector can track all of these so as to avoid scheduling too much work on any given mutator thread.
Also, by piggybacking collector increments on mutator threads before a thread voluntarily yields to the operating system (say to take an allocation slow path, or to perform I/O or execute native code that does not access the heap) Tax-and-Spend avoids having the operating system scheduler assume that the thread has finished with its operating system time quantum and schedule some unrelated thread in its place. This is particularly important in a loaded system. By interleaving mutation and collection on the same operating system thread the operating system scheduler is less likely to interfere in the scheduling of the collection work.
Allowing different threads to run with different utilisation is important when allocation rates vary significantly across threads or when high-priority threads like event handlers desire minimal interruption. This also permits threads that can tolerate less stringent timing requirements to lower their quantisation overheads by running with larger quanta, and so increase throughput.
Tax-based versus slack-based scheduling.
Slack-based scheduling works well in classical periodic real-time systems, but it degrades badly when the system is overloaded and has insufficient slack. This makes it poorly suited to queuing, adaptive (where the system saturates the processor to compute as accurate a result as possible, but tolerates less accuracy to avoid total overload) or interactive real-time systems. Work-based scheduling taxes mutator allocation work, choosing some amount of collector work proportional to allocation work that will permit the collector to finish its cycle before memory is exhausted. It often suffers from poor minimum mutator utilisation and wide variations in pause time. Time-based scheduling taxes mutator utilisation to interleave the collector with the mutator for given amounts of processor time. It is robust to overload because the tax continues to be assessed, but when there is sufficient slack in the system it can result in unnecessary jitter since collection can occur at any time so long as minimum mutator utilisation requirements are preserved.
Combining tax-based and slack-based scheduling. Tax-and-Spend combines these different scheduling approaches by adopting an economic model. Each mutator thread is subject to a tax rate that determines how much collector work it must perform for a given amount of execution time, specified as a per-thread minimum mutator utilisation. Dedicated collector threads run at low or idle priority during slack periods and accumulate tax credits for their work. Credits are typically deposited in a single global account, though it is possible to consider policies that use multiple accounts.
The aggregate tax over over all threads, combining the tax on the mutator threads with the credits contributed by the collector threads, must be sufficient for the collector to finish its cycle before memory is exhausted. The number of background collector threads is typically the same as the number of processors, configured so that they naturally run during slack periods in overall system execution. They execute a series of quanta each adding the corresponding amount of credit. On real-time operating systems it is desirable to run these threads at some low real-time priority rather than the standard idle priority so that they are scheduled similarly to other threads that perform real work rather than as a true idle thread. These low-priority real-time threads will still sleep for some small amount of time, making it possible for non-real-time processes to make progress even when collection might saturate the machine. This enables administrators to log in and kill run-away real-time processes as necessary.
Each mutator thread is scheduled according to its desired minimum mutator utilisation, guaranteeing that it can meet its real-time requirements while also allowing the collector to make sufficient progress. When a mutator thread is running and its tax is due, it first attempts to withdraw credit from the bank equal to its tax quantum. If this is successful then the mutator thread can skip its collector quantum because the collector is keeping up, so the mutator pays tax only when there is insufficient slack-scheduled background collection. Even if only a partial quantum’s credit is available then the mutator can perform a smaller quantum of collector work than usual. Thus, if there is any slack available the mutator can still run with both higher throughput and lower latencies without having the collector falling behind. This treats slack in a uniprocessor and excess capacity in a multiprocessor in the same way.
Tax-and-Spend requires an underlying garbage collector that is both incremental (so collector work can be levied as a work-scheduled tax on the mutator threads) and concurrent (so slack-scheduled collector work can run on a spare processor concurrently with the mutators). To exploit multiprocessors effectively it should also be parallel (so slack-scheduled collector work can run concurrently with work-scheduled collector work). While Metronome is incremental, it was not originally devised to be concurrent, because time-based scheduling requires that the mutator interleave with the collector at precise intervals, with the mutator suspended while the collector executes. Thus, Tax-and-Spend makes two key changes. First, collector work occurs in collector threads concurrently with mutator threads. This makes it easy for the collector threads to exploit any available slack on some processors while the other processors continue to run mutator threads. Second, mutator threads can be taxed by piggybacking an increment of collector work on them when the load on the system makes it necessary to steal some time from the mutator.
Concurrent collection by itself is insufficient, since it devolves scheduling of the collector threads to the operating system which does not provide the precision needed to meet real-time guarantees and prevent heap exhaustion. Even a real-time operating system cannot account for the allocation patterns and space needs of the application in making its scheduling decisions.
We describe below how Tax-and-Spend extends Metronome to achieve on-the-fly, concurrent, parallel and incremental collection. These extensions are similar to those of other on-the-fly concurrent and parallel collectors, but we reiterate them here in this context for completeness.
Ragged epochs for global consensus. Rather than stopping all the mutator threads to impose global consensus about the current activities of the collector, Tax-and-Spend substitutes a ragged epoch protocol. This is used for several purposes. For example, during certain phases of the collector all the mutators must install a particular write barrier. Alternatively, for termination of the collector, all mutator threads must have drained their private store buffer. The thread installing the barrier, or checking for termination, uses the epoch mechanism to assert that the new state is in effect for all threads.
The epoch mechanism uses a single shared epoch number that can be atomically incremented by any thread to initiate a new epoch, plus a per-thread local epoch number. Each thread updates its local epoch number by copying the shared epoch, but it does so only at GC-safe points. Thus, each thread’s local epoch is always less than or equal to the shared epoch. Any thread can examine the local epochs of all threads to find the least local epoch, which is called the confirmed epoch. Only when the confirmed epoch reaches or passes the value a thread sets for the global epoch can it be sure that all other threads have noticed the change. On weakly-ordered hardware a thread must use a memory fence before updating its local epoch. To cope with threads waiting on I/O or executing native code, Tax-and-Spend requires that they execute a GC-safe point on return to update their local epoch before they resume epoch-sensitive activities. Thus, such threads can always be assumed to be at the current epoch, so there is no need to wait for them.
Phase agreement using ‘last one out’.
Metronome easily achieved agreement on the collector phase (such as marking, sweeping, finalising, and so on) because all collector work occurred on dedicated threads that could block briefly to effect a phase change so long as there was enough remaining time in their shared collector quantum. With concurrent collection piggy-backed on the mutator threads, each mutator might be at a different place in its taxation quantum, so it is essential that phase detection be non-blocking or else a taxed mutator might fail to meet its deadlines. Using ragged epochs for this is not efficient because it does not distinguish taxed mutator threads from others. Instead, the ‘last one out’ protocol operates by storing a phase identifier and worker count in a single shared and atomically updatable location.
Every taxed mutator thread atomically increments the worker count, leaving the phase identifier unchanged. When a mutator thread exhausts its taxation quantum without completing the phase it atomically decrements the worker count, also leaving the phase identifier unchanged. When any thread believes that the phase might be complete because there is (apparently) no further work to do in that phase, and it is the only remaining worker thread (the count is one), then it will change the phase and decrement the worker count in one atomic operation to establish the new phase.
This protocol works only so long as each worker thread returns any incomplete work to a global work queue when it exits. Eventually there will be no work left, some thread will end up being the last one and it will be able to declare the next phase.
Unfortunately, termination of the mark phase in Metronome is not easily achieved using this mechanism, because the deletion barrier employed by Metronome deposits the overwritten pointer into a per-thread mutation log. Mark phase termination requires that all threads have an empty mutation log (not just those performing collector work). Thus, Tax-and-Spend introduces a final marking phase in which the remaining marking work is handled by one thread which uses the ragged epoch mechanism to ensure that there is global agreement that all the mutation logs are empty. If this check fails then the deciding thread can declare a false alarm and switch back to parallel marking. Eventually all the termination conditions will be met and the deciding thread can move to the next post-marking phase.
Per-thread callbacks. Most phases of a collection cycle need just enough worker threads to make progress, but others require that something be done by (or to) every mutator thread. For example, the first phase of collection must scan every mutator stack. Other phases require that the mutator threads flush their thread-local state to make information available to the collector. To support this some phases impose a callback protocol instead of ‘last one out’.
In a callback phase some collector master thread periodically examines all the mutator threads to see if they have performed the desired task. Every active thread that has not is asked to perform a callback at their next GC-safe point to perform the required action (stack scanning, cache flushing, and so on). Threads waiting on I/O or executing native code are prevented from returning while the action is performed on their behalf. Thus, the maximum delay to any thread during a callback phase is the time taken to perform the action.
Priority boosting to ensure progress. It is imperative that a real-time collector make progress so that it finishes collection before the heap is exhausted. All three of the prior protocols (ragged epochs, last one out and callback) can be prevented from making progress if some lower priority thread is unable to respond because higher priority threads are saturating the processors. The solution is to boost the priority of the lower priority thread temporarily until it has been heard from.
19.7 Controlling fragmentation
A real-time collector must bound both its time and its space consumption. Unfortunately, over time fragmentation can eat away at the space bound. Accounting for fragmentation is impossible without precise characterisation of application-specific behaviours such as pointer density, average object size, and locality of object size. Thus, a real-time collector must be designed to manage and limit fragmentation in some way. One way to achieve this is through compaction. Another approach is to allocate objects in fragments (oblets and arraylets) so as to preclude external fragmentation at the expense of some (bounded) internal fragmentation and overhead on the mutator to access the appropriate fragment during reads and writes to the heap. In this section we discuss both of these approaches.
The challenge in concurrent compaction is for the collector to relocate objects concurrently with the mutator while guaranteeing that mutator accesses retain tight time bounds. The replicating collectors of Chapter 17 and Blelloch and Cheng [1999] were originally devised expressly to allow concurrent copying but they maintain two copies of each object. Keeping these copies consistent on modern multiprocessors that lack strict coherence usually requires some form of locking, particularly for volatile fields. Moreover, replicating collectors rely on a synchronous termination phase to ensure that the mutator roots have been forwarded. Per-object locking does not scale. Compressor and Pauseless rely on page-level synchronisation using page protection, but suffer from poor minimum mutator utilisation both because of the cost of the traps and because they are work-based, with a trap storm following a phase shift.
The absence of lock-freedom means we cannot guarantee progress of the mutator let alone preserve time bounds. There are a number of approaches to making mutator accesses wait-free or lock-free in the presence of concurrent compaction, which we now discuss.
Incremental compaction in Metronome
Metronome was designed as a mostly non-copying collector under the assumption that external fragmentation is rare. It uses arraylets to break large objects (arrays) into chunks which form the largest contiguous units allocated by the system. This combination greatly reduces the number of objects that must be copied in order to minimise fragmentation. Bacon et al [2003b] derive an analytical framework to decide how many pages to defragment during each collection so as to ensure that the mutator never needs to wait for any allocation request. Because Metronome is an incremental collector it can perform defragmentation while all the mutator threads are stopped. When the mutator threads resume they are forwarded to any copies as necessary via the Brooks indirection barrier. There is no need to be concerned with mutators seeing objects in the middle of being copied. The only cost to the mutator is the cost of the extra indirection, which has tight time bounds. The Tax-and-Spend extension of Metronome is a concurrent collector but it does not perform any compaction.
The framework of Bacon et al [2003b] divides the defragmentation work (as determined by the derived defragmentation target) as evenly as possible across the size classes of their segregated-fits allocator. Each size class consists of a linked list of pages (as opposed to individual objects). The algorithm for defragmenting a size class consists of the following steps.
1. Sort the pages by the number of unused (free) objects per page from dense to sparse.
2. Set the allocation page to the first (densest) non-full page in the resulting list.
3. Set the page to evacuate to the last (sparsest) page in the list.
4. While the target number of pages to evacuate in this size class has not been met, and the page to evacuate does not equal the page in which to allocate, move each live object from the sparsest page to the next available free cell on the allocation page (moving to the next page in the list whenever the current allocation page fills up).
Algorithm 19.7: Replication copying for a uniprocessor
1. atomic Read(p, i):
2 return p[i]
3
4 atomic | /* |
5 /* deletion barrier code also needed here for snapshot collection */
6 p[i] ← value
7 r ← forwardingAddress(p)
8 r[i] ← value
9 /* insertion barrier code also needed here for incremental update collection */
This moves objects from the sparsest pages to the densest pages. It moves the minimal number of objects and produces the maximal number of completely full pages. The choice of the first allocation page in step 2 as the densest non-full page may result in poor cache locality because previously co-located objects will be spread among the available dense pages. To address this, one can set a threshold for the density of the page in which to allocate at the head of the list, so that there are enough free cells in the page to satisfy the locality goal.
References to relocated objects are redirected as they are scanned by the subsequent tracing mark phase. Thus, at the end of the next mark phase, the relocated objects of the previous collection can be freed. In the meantime, the Brooks forwarding barrier ensures proper mutator access to the relocated objects. Deferring update of references to the next mark phase has three benefits: there is no extra ‘fixup’ phase, fewer references need to be fixed (since any object that dies will never be scanned) and there is the locality benefit of piggybacking fixup on tracing.
Incremental replication on uniprocessors
Before considering more complicated schemes for concurrent compaction, it is worth noting that many real-time applications run in embedded systems, where uniprocessors have been the predominant platform. Preserving atomicity of mutator operations (with respect to the collector and other mutators) is simple on a uniprocessor, either by disabling scheduler interrupts or by preventing thread switching except at GC-safe points (making sure that mutator barriers never contain a GC-safe point). In this setting, the collector can freely copy objects so long as mutators subsequently access only the copy (using a Brooks indirection barrier to force a tospace invariant), or they make sure to update both copies (in case other mutators are still reading from the old version in a replicating collector).
Kalibera [2009] compares replication copying to copying with a Brooks barrier in the context of a real-time system for Java running on uni-processors. His replication scheme maintains the usual forwarding pointer in all objects, except that when the object is replicated the forwarding pointer in the replica refers back to the original instead of to itself (in contrast to Brooks [1984]). This arrangement allows for very simple and predictable mutator barriers. On Read the mutator need not be concerned whether it is accessing a fromspace or tospace object, and can simply load the value from whichever version the mutator references. All that Write needs to do is to make sure that the update is performed on both versions of the object to keep them coherent. Pseudo-code for these barriers (omitting the support necessary for concurrent tracing) is shown in Algorithm 19.7. Not surprisingly, avoiding the need to forward every read is a significant benefit, and the cost of the double-write is negligible given that most of the time both writes will be to the same address because the forwarding address is a self-reference.
Concurrent compaction on a multiprocessor prevents us from assuming that Read and Write can be made straightforwardly atomic. For that we must consider more finegrained synchronisation among mutators, and between mutator and collector, as follows.
Stopless: lock-free garbage collection
Pizlo et al [2007] describe an approach to concurrent compaction for their lock-free Stopless collector that ensures lock-freedom for mutator operations (allocation and heap accesses) even while compaction proceeds concurrently. Unlike Blelloch and Cheng [1999], Stopless does not require that the mutator update both copies of an object to keep them coherent. Instead, it enforces a protocol that always updates just one definitive copy of the object. The innovation in Stopless is to create an intermediate ‘wide’ version of the object being copied, where each field has an associated status word, and to use CompareAndSwapWide to synchronise copying of those fields with mutation. The field’s status word changes atomically with its data and indicates the up-to-date location of the data (in the fromspace original, the wide copy, or the final tospace copy). As in Blelloch and Cheng [1999] a header word on each object stores a Brooks forwarding pointer, either to the wide copy or to the tospace copy. During the compaction phase, mutator and collector threads race to create the wide copy using CompareAndSwap to install the forwarding pointer.
Once the wide copy has been created, and its pointer installed in the original’s forwarding pointer header field, the mutator can update only the wide copy. The status word on each field lets the mutator know (via read and write barriers) where to read/write the up-to-date field, encoding the three possibilities: inOriginal, inWide and inCopy. All status words on the fields in the wide object are initialised to inOriginal. So long as the status field is inOriginal then mutator reads occur on the fromspace original. All updates (both by the collector as it copies each field and the mutator as it performs updates) operate on the wide copy, atomically updating both the field and its adjacent status to inWide using CompareAndSwapWide. The collector must assert that the field is inOriginal as it copies the field. If this fails then the field has already been updated by the mutator and the copy operation can be abandoned.
Once all fields of an object have been converted to inWide (whether by copying or mutation), the collector allocates its final ‘narrow’ version in tospace, whose pointer is then installed as a forwarding pointer into the wide copy. At this point there are three versions of the object: the out-of-date fromspace original which forwards to the wide copy, the up-to-date wide copy which forwards to the tospace copy, and the uninitialised tospace copy. The collector concurrently copies each field of the wide copy into the narrow tospace copy, using CompareAndSwapWide to assert that the field is unmodified and to set its status to inCopy. If this fails then the field was updated by the mutator and the collector tries again to copy the field. If the mutator encounters an inCopy field when trying to access the wide copy then it will forward the access to the tospace copy.
Because Stopless forces all updates to the most up-to-date location of a field it also supports Java volatile fields without the need for locking. It is also able to simulate application-level atomic operations like compare-and-swap on fields by the mutator. For details see Pizlo et al [2007]. The only remaining issue is coping with atomic operations on double-word fields (such as Java long) where the CompareAndSwapWide is not able to cover both the double-word field and its adjacent status word. The authors of Stopless propose a technique based on emulating n-way compare-and-swap using the standard CompareAndSwap [Harris et al, 2002].
Some might object to the space overhead of Stopless(three copies including one double-width), but Pizlo2 points out that so long as sparse pages are being evacuated, with at most one third occupancy, one can make use of the dead space for the wide copies. Of course, the reason for evacuating the page is that it is fragmented, so there may not be sufficient contiguous free space available for all the copies. But if segregated-fits allocation is used then the free portions are uniformly sized, and it is possible to allocate the wide objects in multiple wide fragments so as to allocate each data field and its status word side-by-side. In Stopless, the space for the wide objects is retained until the next mark phase has completed, having forwarded all pointers to their tospace copies.
Staccato: best-effort compaction with mutator wait-freedom
Whereas Metronome performs compaction while the mutator is stopped during a collector quantum, Staccato [McCloskey et al, 2008] permits concurrent compaction without requiring the mutators to use locks or atomic operations like compare-and-swap in the common case, even on multiprocessors with weak memory ordering. Storms of atomic operations are avoided by moving few objects (only as necessary to reclaim sparsely-occupied pages) and by randomising their selection.
Staccato inherits the Brooks-style indirection barrier of Metronome, placing a forwarding pointer in every object header. It also relies on ragged synchronisation: the mutators are instrumented to perform a memory fence (on weakly ordered machines like the PowerPC) at regular intervals (such as GC-safe points) to bring them up to date with any change to global state. The collector reserves a bit in the forwarding pointer to denote that the object is being copied (Java objects are always word-aligned so a low bit in the pointer can be used). This COPYING bit and the forwarding pointer can be changed atomically using compare-and-swap/set. To move an object, the collector performs the following steps:
1. Set the COPYING bit using compare-and-swap/set. Mutators access the forwarding pointer without atomic operations so this change takes some time to propagate to the mutators.
2. Wait for a ragged synchronisation where every mutator performs a read fence to ensure that all mutators have seen the update to the COPYING bit.
3. Perform a read fence (on weakly ordered machines) to ensure that the collector sees all updates by mutators from before they saw the change to the COPYING bit.
4. Allocate the copy, and copy over the fields from the original.
5. Perform a write fence (on weakly ordered machines) to push the newly written state of the copy to make it globally visible.
6. Wait for a ragged synchronisation where every mutator performs a read fence to ensure that it has seen the values written into the copy.
7. Set the forwarding address to point to the copy and simultaneously clear the COPYING bit using compare-and-swap/set. This commits the move of the object. If this fails then the mutator must have modified the object at some point and the move is aborted.
The collector will usually want to move a number of objects, so the cost of the ragged synchronisation can be amortised by batching the copying, as illustrated by the copyObjects routine in Algorithm 19.8. This takes a list of candidates to be moved and returns a list of aborted objects that could not be moved.
Algorithm 19.8: Copying and mutator barriers (while copying) in Staccato
1 copyObjects(candidates):
2 for each p in candidates
3 /* set COPYING bit */
4 CompareAndSet(&forwardingAddress(p), p, p | COPYING)
5 waitForRaggedSynch(readFence) | /* ensure mutators see |
6 readFence() | /* ensure collector sees mutator updates from before CAS */ |
7 for each p in candidates
8 r ← allocate(length(p)) | /* allocate the copy */ |
9 move(p, r) | /* copy the contents */ |
10 forwardingAddress(r) | /* the copy forwards to itself */ |
11 add(replicas, r) | /* remember the copies */ |
12 writeFence() | /* flush the copies so the mutators can see them */ |
13 waitForRaggedSynch(readFence) | /* ensure mutators see the copies */ |
14 for each (p in candidates, r in replicas)
15 /* try to commit the copy */
16 if not CompareAndSet(&forwardingAddress(p), p | COPYING, r)
17 /* the commit failed so deal with it */
18 free (r) | /* free the aborted copy */ |
19 add(aborted, p) | /* remember the aborts */ |
20 return aborted 21
22 Access(p):
23 r ← forwardingAddress(p) | /* load the forwarding pointer */ |
24 if r & COPYING = 0
25 return r | /* use the forwarding pointer only if not copying */ |
26 | /* try to abort the copy */ |
27 if CompareAndSet(&forwardingAddress(p), r, p)
28 return p | /* the abort succeeded */ |
29 /* collector committed or another aborted */
30 atomic | /* force reload of current |
31 r ← forwardingAddress(p)
32 return r
33
34 Read(p, i):
35 p ← Access(p)
36 return p[i]
37
38 Write(p, i, value):
39 p ← Access(p)
40 p[i] ← value
Algorithm 19.9: Heap access (while copying) in Staccato using CompareAndSwap
1 Access(p):
2 r ← forwardingAddress(p) | /* load the forwarding pointer */ |
3 if r & COPYING = 0
4 return r | /* use the forwarding pointer only if not copying */ |
5 /* otherwise try to abort the copy */
6 r ← CompareAndSwap(&forwardingAddress(p), r, p)
7 /* failure means collector committed or another aborted so r is good */
8 return r & ~COPYING | /* success means we aborted so clear |
Meanwhile, when the mutator accesses an object (to examine or modify its state for any reason) it performs the following steps:
1. Load the forwarding pointer.
2. Use the forwarding pointer as the object pointer only if the COPYING bit is clear.
3. Otherwise, try to abort the copy by using a compare-and-set to clear the COPYING bit (which is the same as storing the original pointer).
4. Use the forwarding pointer (with the COPYING bit cleared) as the object pointer only if the compare-and-set succeeds.
5. Otherwise, the failure of the compare-and-set means either that the collector committed the copy or else another mutator aborted it. So, reload the forwarding pointer using an atomic read (needed on weakly ordered machines), guaranteed to see the current value of the forwarding pointer (that is, the value placed there by the collector or other mutator).
These steps are shown in the Access barrier helper function, used by both Read and Write in Algorithm 19.8.
We note that when using compare-and-swap (instead of compare-and-set) Access can avoid the atomic read of the forwarding pointer and simply use the value that Compare-AndSwap returns, as shown in Algorithm 19.9, clearing its COPYING bit just in case the compare-and-swap succeeded.
McCloskey et al [2008] note that frequently-accessed objects might prove difficult to relocate because their move is more likely to be aborted. To cope with this they suggest that when such a popular object is detected then its page can be made the target of compaction. That is, instead of moving the popular object off of a sparsely populated page it suffices simply to increase the population density of the page.
Also, abort storms can occur when the collector chooses to move objects that have temporal locality of access by the mutator, so degrading its minimum mutator utilisation because of the need to run an increased number of CompareAndSwap operations in a short time. This is unlikely because only objects on sparsely populated pages are moved, so objects allocated close together in time are unlikely all to move together. The probability of correlated aborts can be reduced by breaking the defragmentation into several phases to shorten the time window for aborts. Also, the set of pages chosen for defragmentation in each phase can be randomised. Finally, by choosing to run several defragmentation threads at much the same time (though not synchronously, and respecting minimum mutator utilisation requirements), there will be fewer mutator threads running so reducing the likelihood of aborts.
Algorithm 19.10: Copying and mutator barriers (while copying) in Chicken
1 copyObjects(candidates):
2 for each p in candidates
3 /* set COPYING bit */
4 forwardingAddress(p) ← p | COPYING
5 waitForRaggedSynch() | /* ensure mutators see |
6 for each p in candidates
7 r ← allocate(length(p)) | /* allocate the copy */ |
8 move(p, r) | /* copy the contents */ |
9 forwardingAddress(r) | /* the copy forwards to itself */ |
10 /* try to commit the copy */
11 if not CompareAndSet(&forwardingAddress(p), p | COPYING, r)
12 /* the commit failed so deal with it */
13 free (r) | /* free the aborted copy */ |
14 add(aborted, p) | /* remember the aborts */ |
15 return aborted
16
17 Read(p, i):
18 r ← forwardingAddress(p) | /* load the forwarding pointer */ |
19 return r[i]
20
21 Write(p, i, value):
22 r ← forwardingAddress(p) | /* load the forwarding pointer */ |
23 if r & COPYING ≠ 0 | /* use the forwarding pointer only if not copying */ |
24 /* otherwise try to abort the copy */
25 CompareAndSet(&forwardingAddress(p), r, r & ~COPYING)
26 /* failure means collector committed or another aborted */
27 r ← forwardingAddress(p) | /* reload |
28 r [i] ← value
Chicken: best-effort compaction with mutator wait-freedom for x86
Pizlo et al [2008] offer a solution similar to Staccato (see Algorithm 19.10). Their Chicken algorithm, developed independently, is essentially the same as Staccato, though they assume the stronger memory model of x86/x86-64 (recall Table 13.1). This means that only writes need abort a copy (because atomic operations order reads) and that the ragged synchronisations need not perform the read fence. Both Staccato and Chicken support wait-free mutator reads and writes, and wait-free copying at the cost that some copy operations might be aborted by the mutator.
Clover: guaranteed compaction with probabilistic mutator lock-freedom
Pizlo et al describe an alternative approach called Clover that relies on probabilistic detection of writes by the mutator to deliver guaranteed copying with lock-free mutator accesses (except in very rare cases) and lock-free copying by the collector. Rather than preventing data races between the collector and the mutator, Clover detects when they occur, and in that rare situation may need to block the mutator until the copying phase has finished. Clover picks a random value a to mark fields that have been copied and assumes that the mutator can never write that value to the heap. To ensure this, the write barrier includes a check on the value being stored, and will block the mutator if it attempts to do so.
Algorithm 19.11: Copying and mutator barriers (while copying) in Clover
1 copySlot(p, i):
2 repeat
3 value ← p[i]
4 r ← forwardingAddress(p)
5 r[i] ← value
6 until CompareAndSet(&p[i], value, a)
7
8 Read(p, i):
9 value ← p[i]
10 if value =
11 r ← forwardingAddress(p)
12 value ← r[i]
13 return value
14
15 Write(p, i, newValue):
16 if newValue = a
17 sleep until copying ends
18 repeat
19 oldValue ← p[i]
20 if oldValue =
21 r ← forwardingAddress(p)
22 r[i ] ← newValue
23 break
24 until CompareAndSet(&src[i], oldValue, newValue)
As the collector copies the contents of the original object to the copy it marks the original fields as copied by overwriting them with the value a using compare-and-swap. Whenever the mutator reads a field and loads the value a it knows that it must reload the up-to-date value of the field via the forwarding pointer (which points to the original if its copy has not been made yet, or the copy if it has). This works even if the true value of the field is from before the copy phase began.
Whenever the mutator tries to overwrite a field containing the value a it knows that it must store to the up-to-date location of the field via the forwarding pointer. If the mutator actually tries to store the value then it must block until copying ends (so that no longer means a copied field that must be reloaded via the forwarding pointer). We sketch Clover’s collector copying routine and mutator barriers in Algorithm 19.11.
For some types α can be guaranteed not to clash with a proper value: pointers usually have some illegal values that can never be used and floating point numbers can use any one of the NaN forms so long as the program never generates them. For other types, needs to be chosen with care to minimise overlap with values used in the program. To make the chance of overlap virtually impossible, Pizlo et al [2008] offer an innovative solution using a random choice for α. They use the largest width CompareAndSwap-Wide available on the processor to assert copying of multiple fields at once. For example, modern x86-64 processors support a 128-bit compare-and-swap, resulting in the infinitesimal chance of overlap of 2−128. Of course, this implies that when testing for α every Read/Write must look at the full aligned 128-bit memory location and extract/insert the value to load/store.
Stopless versus Chicken versus Clover
Pizlo et al [2008] compare Chicken and Clover to their earlier Stopless collector as well as to a non-compacting concurrent mark-sweep collector. Qualitatively, Stopless cannot guarantee progress to the collector, because there is a chance that repeated writes to a field in a ‘wide’ copy may cause copying to be postponed indefinitely. Chicken guarantees progress for the collector, at the expense of aborting some copies. Pizlo et al claim that Clover can guarantee collector progress, though in the simple formulation presented here it may stall waiting to install α into a field it is copying while the mutator repeatedly updates the field, causing its CompareAndSwap to fail repeatedly.
All three algorithms aim for lock-free heap access, but with subtle differences. Chicken guarantees wait-free access for both reads and writes. Clover and Stopless provide only lock-free writes, and reads require branching. Clover’s lock-free writes are only probabilistic, since it is possible that a heap write must be stalled until copying is complete as noted above.
Clover never aborts an object copy. Stopless can abort copying an object in the unlikely situation that two or more mutator threads write to the same field at much the same time during entry into the compaction phase (see Pizlo et al [2007] for details). Chicken is much less careful: any write to an object while it is being copied will force the copy to abort.
Benchmarks comparing these collectors and non-compacting concurrent mark-sweep collection show that throughput is highest for the non-compacting collector (because it has much simpler barriers). The copying collectors install their copying-tailored barriers only during the compaction phase by hot-swapping compiled code at phase changes using the techniques of Arnold and Ryder [2001]. Chicken is fastest (three times slow-down while copying according to Pizlo3), though it results in many more copy aborts, followed by Clover (five times slower while copying) and Stopless (ten times slower while copying). All the collectors scale well on a multiprocessor up to six processors. Because of the throughput slow-downs copying degrades responsiveness to real-time events for both Clover and Stopless. Responsiveness for Chicken is much better because it stays out of the mutator’s way by aborting copies quickly when necessary.
The preceding discussion of compaction for real-time systems reveals that any real-time collector relying on defragmentation to ensure space bounds must trade off throughput and responsiveness to real-time events against the level of fragmentation it is willing to tolerate. Wait-freedom of mutator heap accesses was guaranteed only by Chicken/Staccato at the price of aborting some copies. Stopless and Clover offer stronger space guarantees but only with the weaker progress guarantee of lock-freedom for heap accesses. A real-time collector needing hard space bounds may find this tradeoff unacceptable.
For this reason, Siebert has long advocated bounding external fragmentation by allocating all objects in (logically if not physically) discontiguous fixed-size chunks [Siebert, 1998, 2000, 2010], as implemented in his Jamaica VM for real-time Java. The Jamaica VM splits objects into a list of fixed-size oblets, with each successive oblet requiring an extra level of indirection to access, starting at the head of the list. This results in linear-time access for object fields, depending on the field index. Similarly, arrays are represented as a binary tree of arraylets arranged into a trie data structure [Fredkin, 1960]. Thus, accessing an array element requires a number of indirections logarithmic in the size of the array. The main problem with this scheme is this variable cost of accessing arrays. Worst-case execution time analysis requires knowing (or bounding) statically the size of the array being accessed. However, array size in Java is a dynamic property, so there is no way to prove general bounds for programs in which array size is not known statically. Thus, in the absence of other knowledge the worst-case access time for trie-based arrays can in general be bounded only by the size of the largest allocated array in the application, or (worse) the size of the heap itself if that bound is unknown.
To solve this problem, Pizlo et al [2010b] marry the spine-based arraylet allocation techniques of Metronome to the fragmented allocation techniques of the Jamaica VM in a system they call Schism. By allowing objects and arrays to be allocated as fixed-size fragments there is no need to worry about external fragmentation. Moreover, both object and array accesses have strong time bounds: indirecting a statically known number (depending on the field offset) of oblets for object accesses, and indirecting through the spine to access the appropriate arraylet for array accesses. To a first order approximation (ignoring cache effects) both operations require constant time. Schism’s scheme for allocating fragmented objects and arrays is illustrated in Figure 19.10. An object or array is represented by a ‘sentinel’ fragment in the heap. Every object or array has a header word for garbage collection and another to encode its type. The sentinel fragment, representing the object or array, contains these and additional header words to encode the remaining structure. All references to an object or array point to its sentinel fragment.
Objects are encoded as a linked list of oblets as in Figure 19.10a. An array that fits in a single fragment is encoded as in Figure 19.10b. Arrays requiring multiple arraylet fragments are encoded with a sentinel that refers to a spine, which contains pointers to each of the arraylet fragments. The spine can be ‘inlined’ into the sentinel fragment if it is small enough as in Figure 19.10c. Otherwise, the spine must be allocated separately.
The novelty of Schism is that separately allocated array spines need not be allocated in the object/array space. That space is managed entirely as a set of fixed-size fragments using the allocation techniques of the immix mark-region collector. The 128-byte lines of immix are the oblet and arraylet fragments of Schism. Schism adds fragmented allocation and on-the-fly concurrent marking to immix, using an incremental update Dijkstra style insertion barrier. The fragments never move, but so long as there are sufficient free fragments available any array or object can be allocated. Thus, fragmentation is a non-issue, except for the variable-sized array spines.
To bound the fragmentation due to array spines, Schism allocates them in a separately managed space that uses replication copying collection to perform compaction. Because the array spines are immutable (they contain only pointers to arraylet fragments, which never move) there is no problem of dealing with updates to the spines. Indeed, a mutator can use either a fromspace primary spine or tospace replica spine without fear. Moreover, each spine has a reference from at most one array sentinel. When replicating, the reference to the primary from the sentinel can be lazily replaced with a reference to the replica at the collector’s leisure, without needing to synchronise with the mutator. Mutators can freely continue to use the spine primary or switch over to using the spine replica when next they load the spine pointer from the sentinel. Once replication of the spines has finished the fromspace spines can be discarded without needing to fix any other pointers because the tospace spines have only the single reference from their sentinel. A ragged synchronisation of the mutators ensures that they all agree and are no longer in the middle of any heap access that is still using a fromspace spine.
Figure 19.10: Fragmented allocation in Schism.
Pizlo et al [2010b], doi: 10.1145/1806596.1806615.
© 2010 Association for Computing Machinery, Inc. Reprinted by permission.
Schism has a number of desirable properties. First, mutator accesses to the heap are wait-free and tightly-bounded (costing constant time). Second, fragmentation is strictly controlled. Indeed, Pizlo et al [2010b] prove that given the number and type of objects and arrays (including their size) in the maximum live set of the program, then total memory needed for the program can be strictly bounded at 1.3104b where b is the size of the maximum live set. Third, as proposed for Jamaica VM by Siebert [2000], Schism can run with contiguous allocation of arrays (objects are always fragmented) when there is sufficient contiguous space. Contiguous arrays are laid out as in Figure 19.10d, except with the payload extending into successive contiguous fragments. This allows for much faster array access without indirection through the spine. These properties mean that Schism has superior throughput compared to other production real-time collectors, while also being tolerant of fragmentation by switching to fragmented allocation of arrays when contiguous allocation fails. This comes at the cost of some slow-down to access the fragmented arrays. The cost of the read and write barrier machinery to access fragmented arrays is throughput 77% of pure concurrent mark-region garbage collection (without the fragmented array access support).
For application developers requiring predictability of the cost for array accesses Schism can be configured always to use fragmented allocation for arrays at the cost of having to perform spine indirections on all array accesses. The benefit for this is much improved maximum pause times. Since all allocations are performed in terms of fragments, pauses due to allocation are essentially the cost of zero-initialising a four kilobyte page in the slow path of allocation — 0.4 milliseconds on a forty megahertz embedded processor. When allocating arrays contiguously the allocator must first attempt to locate a contiguous range of fragments, which slows things down enough to cause maximum pauses around a millisecond on that processor.
Real-time systems demand precise control over garbage collection to ensure short pauses and predictable minimum mutator utilisation. This chapter brings together techniques from all the previous chapters in order to achieve these goals. In the absence of parallelism and concurrency, real-time garbage collection is conceptually straightforward so long as collection can be scheduled to preserve adequate responsiveness and performance. Our focus here has been on the real-time garbage collection algorithms themselves, and not so much on how to integrate their schedulability with that of the application. Real-time application developers still need accurate analysis of worst-case execution time to feed into schedulability analyses that will ensure that real-time constraints will be met [Wilhelm et al, 2008]. The literature on real-time systems offers an abundance of guidance on analysis of garbage collected applications for worst-case execution time and schedulability [Kim et al, 2001; Robertz and Henriksson, 2003; Chang and Wellings, 2005, 2006a,b; Chang, 2007; Chang and Wellings, 2010; Cho et al, 2007, 2009; van Assche et al, 2006; Kalibera et al, 2009; Feizabadi and Back, 2005, 2007; Goh et al, 2006; Kim et al, 1999, 2000, 2001; Kim and Shin, 2004; Schoeberl, 2010; Zhao et al, 1987].
While we have focused on minimum mutator utilisation as the primary metric for measuring garbage collector responsiveness over time, we note that other metrics may be just as important. Printezis [2006] argues that application-specific metrics are often more appropriate. Consider a periodic real-time task that must deliver a response within a fixed window. From the perspective of this task, minimum mutator utilisation is immaterial, so long as the real-time expectations of that task are met. Moreover, minimum mutator utilisation and maximum pause time may be difficult to account for when the only pauses related to garbage collection that the mutator experiences are those due to executing the compiler-inlined slow path of a read or write barrier, or the slow path during allocation when the thread’s local allocation buffer is exhausted. For some collectors, such as Schism, these are the only collector-related pauses that the mutator will see (assuming collector work can be offloaded to another processor). Should these pauses be charged to the garbage collector? If so, then how can a system account for them? Pizlo et al [2010a] even go so far as to account for these slow paths using specialised hardware for on-device profiling of an embedded processor. To aid developers lacking such specialised hardware, Pizlo et al [2010b] provide a worst-case execution mode for their Schism collector that forces slow path execution so that developers can get some reasonable estimate of worst-case execution times during testing.
1Note carefully here the distinction between a* (the maximum allocation rate over an interval) and α* (the maximum allocated memory over an interval).
2Filip Pizlo, personal communication.
3Personal communication.