
10
Looking Ahead
The world is constantly moving forward, and the devices and development techniques that support our culture move forward with it. This book has covered the most critical subjects to develop quality Cortex-M software in late 2022. Technologies that enable smart, connected, and secure devices are increasing in demand as individuals, companies, and governments see the value such products bring. Accordingly, we as developers must refine our development processes to create devices at a faster pace, lower cost, and higher quality every year.
The desire for smart, connected, and secure devices is as widespread as it is new. Twenty years ago, the concept of the Internet of Things (IoT) existed in name only. Devices were not connected to the internet by default, security was largely an afterthought (outside of sensitive industries), and machine learning was implemented only in cutting-edge applications. In twenty more years, the embedded software development landscape may be equally different.
This chapter is different from the previous chapters. It is intended to zoom out and provide general tips to be a successful Cortex-M software developer now and into the future. There are two distinct sections. The first contains tips and resources to develop quality Cortex-M devices today. The second section provides a look into the future. We look at over-arching trends and map how Cortex-M devices—and development techniques—will consequently evolve.
The now – tips to being a great developer
In each focus area of this book, we have attempted to atomize the topic, explain the underlying details, then showcase examples in a realistic context. In every area, there is so much to potentially cover that we selected the most salient points to write about and provide examples for. Two topics in particular (cloud development and testing/CI) are largely unutilized in embedded development and offer many avenues to increase your overall development efficiency. We will now expand on these two topics, presenting more options, context, and advice to move from being a good developer to a great one.
The cloud
As shown in Chapter 8, Streamlining with the Cloud, there are two main ways to think about leveraging the cloud: as a means to increase development efficiency, and as a means to increase device functionality and management when deployed. This section will offer further advice on both these axes.
Tip #1 – Try cloud service free tiers
Due to the fierce competition between cloud services and the fact that once people like a cloud provider, they largely stick with them, they all offer free tiers to evaluate their options without paying upfront. Google Cloud, Amazon Web Services, Oracle Cloud, Microsoft Azure, Alibaba Cloud, and IBM Cloud all enable you to try various services at no charge.
We highly recommend you try the free tier of multiple cloud service providers to learn about what cloud services are available. You might discover a service that would be prohibitively expensive for your team to create but is already offered. It will also introduce you to different techniques that can enable you to select what works best for your project. It is always helpful to get more context, and learning more in this area can pay off down the road.
Tip #2 – Saving and sharing AMIs
We have used Amazon Machine Instances (AMIs) throughout this book, specifically leveraging the Arm Virtual Hardware AMI to run examples on a virtual model of the Corstone-300 platform with the Arm Cortex-M55. We also discussed, toward the end of Chapter 8, how to develop code on EC2 instances with a VS Code IDE.
We suggest that you create your own custom EC2 instance for cloud-based development with all the tools and software you need pre-installed and save it as an AMI. You can then reuse it, spinning up new EC2 instances based on your custom AMI in a matter of seconds, to start with a fresh machine and all your required materials ready to go.
This is especially useful in projects that can leverage Arm Virtual Hardware during development, enabling you to code, compile, run, and debug all in the cloud with your favorite tools. You can then access this from anywhere without needing to bring a board with you when working from home or the office (or the beach). It is also useful in projects that have a non-trivial number of required tools and software to be present during development, as the AMI essentially checkpoints a machine’s state right when you get it set up just the way you want.
A further benefit of this approach is the ability to share this AMI with your software development team. All developers in the same project can use the same AMI. This reduces overhead in each person setting up their machine with the right prerequisites and ensures everyone has the same environment and can reproduce any software issues.
Another advantage is the ability to try new things on the machine without fear of breaking your personal computer. Most developers have accidentally caused a computer to permanently break due to some low-level system tampering. When using virtual machines in the cloud, there is no fear and it’s easy to be up and running minutes later due to this saved AMI development approach! It’s freeing to know you can try things and just throw away the computer if they don’t work out as hoped.
Tip #3 – Investigate other remote access tools
When developing embedded software in the cloud, a common annoyance is the quality of the remote connection. A slow or jerky connection to graphical tools can make development a hassle. We presented a few options in Chapter 8, including accessing VS Code over a web browser and opening a VNC connection. We recommend you look at other options to best fit your use case requirements. There are several good tools that exist today; here is an introduction to a few we have used with success:
- Remote.It: Offers a secure method to connect to multiple devices without exposing them to the public internet. Devices in this case can be edge IoT devices, and also cloud server instances.
- Jfrog Connect: Provides a secure way to manage IoT device fleets. Updating, controlling, monitoring, and managing are all use cases for Jfrog Connect.
Important note
Both Remote.It and Jfrog Connect can connect to Cortex-M-based devices and high-end cloud servers if desired.
- NoMachine: A like-for-like tool replacement for a VNC connection, offering a graphical connection to a remote machine that is exceptionally fast. It is not intended to manage IoT devices, but instead, to enable easier connection to a single cloud server to use it like a desktop. We have used this tool for personal, non-commercial projects to great success as it delivers a full remote connection to a remote server without any noticeable lag. Note that it does require a license for commercial applications.
Tip #4 – Cloud connector services
There are numerous cloud services available that connect IoT devices and collect IoT data. In Chapter 9, Implementing Continuous Integration, we used an example demonstrating how to connect an IoT device to AWS services and send messages using Message Queueing Telemetry Transport (MQTT). MQTT is a simple messaging protocol for low bandwidth connections and constrained devices such as Cortex-M IoT devices. The example software demonstrated how to set up an AWS thing, a representation of a physical device or sensor.
All major cloud service providers have IoT services to connect devices and collect data. There are numerous examples available to learn about the device connection process, data transmission, and ways to visualize the collected data. Beyond cloud service providers, there are several companies offering dedicated IoT products for various markets. Additional services include device management, provisioning new devices, remote software update functionality, and more. Some services focus on connectivity when Wi-Fi is not possible using cellular solutions and LoRa and LoRaWAN protocols for long-distance radio transmission.
Even though it’s not based on Cortex-M, a good way to learn about cloud services for IoT is to get a Raspberry Pi 3, Pi 4, or Pi Zero 2 W to learn. These devices run Linux on Cortex-A, but having Linux makes it very easy to learn the basics of IoT. There are many tutorials available, and the concepts translate well to Cortex-M IoT projects. One good place to start is Balena (https://www.balena.io/).
If Linux is not your thing, look for tutorials with the Raspberry Pi Pico W, and try out the numerous tutorials available. Collecting temperature data from a sensor and sending it to a cloud service is an easy place to start.
One of my favorite services is Initial State (https://www.initialstate.com/). It provides one of the easiest platforms to write simple code and stream to a data bucket. You can view the collected data with ease, and custom dashboards can be created in minutes. For some project ideas, visit https://www.initialstate.com/learn/pi/.
One of the trends in 2022 is Matter. Matter is an open source project that aims to connect devices from many vendors together in the “smart home.” All of us have smart home devices and are likely familiar with their successes and failures as consumers trying to get them to work. Compatibility is an industry challenge with room for improvement. To check out more, look at the GitHub project at https://github.com/project-chip/connectedhomeip. For a higher-level description of the Matter project, see the home page here: https://buildwithmatter.com.
Testing, CI, and safety
As shown in the previous chapter, there is a multitude of benefits when turning a traditional board farm into a board garden with a virtual farm. This section will cover separate but related topics around testing best practices that can add value to embedded CI flows, primarily around code coverage concepts and test implementation tips.
Basics of code coverage
Chapter 9 mentioned code coverage only briefly in passing, as a technique to avoid production errors when using CI. Code coverage, perhaps more accurately called test coverage, measures the proportion of your code exercised by an automated test suite. It can range from 0% (meaning no part of your code is being tested) to 100% (meaning every line of your code is being tested).
Having a higher code coverage leads to higher quality code, as you and your team can see the health of your code base in real time. Measuring your code coverage can be added as the last step to your CI pipeline while the CI manager, such as Jenkins and GitHub Actions, can be configured to automatically display the code coverage percentage. Modern code coverage tools will even identify which files are covered well and which are not exercised, indicating where to focus your attention to increase coverage. Without measuring code coverage, you don’t know whether your code base is working as intended or whether there are bugs waiting to be exposed in production when your software is used in unexpected ways.
If you investigate adding code coverage to your project, note that the Cobertura format (Spanish for coverage) is the most popular. It was intended for Java-based code but can be utilized by embedded developers in other formats by using a compatible testing library that outputs in the same format. It is open source and is supported by the most popular managers such as Jenkins and GitHub Actions. There are other options that are commercially available and combine a test framework and code coverage measurement for embedded software, such as Bullseye Coverage and VectorCAST.
The downside of implementing code coverage is time. It takes time to write tests that cover every line of your code. There are a few guidelines that can help your project get the most value from having code coverage without overdoing it:
For most projects, 75% code coverage is the inflection point where achieving more coverage becomes unrealistic and the cost outweighs the bug-catching reward.
Note that 100% code coverage does not mean you will identify 100% of faults, errors, and bugs; it is estimated it will expose about 50% of potential issues by the nature of how tests are being performed.
Don’t choose a code coverage goal before measuring your existing baseline for what your code coverage is today. Overestimation is common.
Your specific coverage goals will depend on your project’s resources, design testability, and cost of failure in production.
With this overview of code coverage value and limitations, we will now discuss the different types of code coverage available.
Types of code coverage
We mentioned that code coverage measures the proportion of your code exercised by an automated test suite. But what does exercised really mean? This concept is different than splitting up tests by unit, integration, and system tests, which segment tests by scope. Unit tests look at small units of your code base, whereas system tests look at your whole system.
There are many different ways to measure how thoroughly tests exercise your code. The most obvious solution is line coverage. It essentially measures the number of lines that were tested, the total number of lines in your software, translated into a percentage. Line coverage is the oldest and perhaps more intuitive method of measuring code coverage, but, as is often the case, the first idea you think of is probably not the best solution. It can give unhelpful numbers when measuring common code situations. For example, suppose an if-else statement contains 1 statement in the if clause and 99 statements in the else clause. As a test exercises one of the two possible paths, statement coverage gives extreme results: either 1% or 99% coverage. This is not a helpful way to think about measuring code health and the percentage of code base coverage but is still a useful tool in the toolbox.
Note that there are often alternate names for the same measurement; line coverage is also referred to as statement coverage and C0 code coverage. The C0 references a quick way to talk about the three simplest types of code coverage. C1 is branch coverage, which measures whether each control structure (such as an if-else statement or while statement) has been evaluated to be both True and False. C2 is condition coverage, which measures whether each Boolean variable in a conditional statement has been tested in all combinations of True and False.
The following table summarizes the most common types of code coverage for your reference. We encourage you to research examples of these different types in practice as that is the easiest way to understand what exactly they are measuring. Simply searching the metric name in Google is sufficient:
|
Name |
Definition |
Benefits |
Drawbacks |
|
Statement Coverage (Line coverage) |
Reports if each executable statement is encountered |
Discover control flow issues |
Insensitive to some control structures; reports if loop body was reached, not if terminated |
|
Branch Coverage (Decision coverage) |
Reports whether Boolean in control statements evaluates to True or False |
Simplicity |
Insensitive to “short-circuit” operators; insensitive to compiler optimizations |
|
Condition Coverage |
Reports the True or False outcome of each condition (an operand of a legal operator) |
Thorough test |
Full condition coverage does not guarantee full decision coverage |
|
Modified Condition / Decision Coverage (MC/DC) |
Every entry/exit point is hit, every decision has had all possible outcomes, all possible directions taken, and each condition has independently affected a decision’s outcome, all at least once |
One of the most thorough coverage types |
Insensitive to short-circuit operators |
|
Call Coverage (Function coverage) |
Reports if each function call is executed |
Useful in verifying component interaction |
Limited scope being analyzed, good as an additional metric to measure |
Table 10.1 – Summary of basic code coverage types
You can choose to implement any of these code coverage metrics, depending on the needs of your code base. There are many more code coverage types that are less common that may be interesting to explore, such as Object Code Branch Coverage, Loop Coverage, Race Coverage, Relational Operator Coverage, and Table Coverage. The area of code coverage, measuring how well your tests exercise your code base, is still only one (albeit the most common) way to measure your code base health. With a proper CI flow in place, you can measure any metrics that you want to track progress, developer efficiency, and more. Here are some examples for you to think about:
- Lines/function
- Tests/function
- Number of hits/function
- Number of hits/code line
- Code change/time
- Different developer edits/function
- Number of GitHub check-ins/developer
- Number of failures/GitHub check-in
You should now have a baseline understanding of what code coverage metrics there are. The next section will cover the different ways to actually implement tests and code coverage in your test suite.
Implementing tests and code coverage
There are several ways to implement tests and code coverage in your project. This section will give an overview of some options that we have encountered, and subsequent considerations.
VectorCAST, Bullseye, and Parasoft are all excellent tools to instrument your embedded code base with tests. Implementing your tests with these tools enables you to automatically measure various code coverage metrics with their built-in capabilities. They are commercially available and are commonly used in the Cortex-M software space to create test suites for medium to large projects.
For small projects, there are several test frameworks that offer no or minimal code coverage metrics but are straightforward to implement. For tests that you plan to run on a host machine and not your embedded system, GoogleTest and CppUTest are two simple options. To mock and stub certain functions or hardware peripherals that you want to replicate in a testing environment, the Fake Function Framework is a very simple offering, as is the Ceedling tool. You can investigate any of these options if interested in learning more, as I (Zach) think this topic is best understood through exploration and experimentation. With these options, you would need to integrate a separate code coverage measurement technique/tool if desired.
If you are using the GCC compiler, the Gcov tool adds the ability to measure line coverage without the need to modify your existing source code or tests. It is a standard tool with the GNU Compiler suite. Simply call gcc from the command line with extra flags, as shown here:
$ gcc -fprofile-arcs -ftest-coverage test.c
This will generate an instrumented executable file as well as some profile files. You can then run gcov on the source file to generate a simple code coverage report:
$ gcov test.c
Important note
gcov only measures line coverage, and more complex code coverage measurements require more robust tools.
The embedded software testing space can be complex to navigate. For larger projects and teams, there are excellent commercial tools for developing test suites effectively, and should be leveraged appropriately. For smaller groups, the space is quite fragmented, and you should select a framework that you are familiar with and can achieve your goals with minimal overhead.
Now, let’s transition away from discussing code coverage and return to a broader embedded software development theme. Examples are often the best way to learn what is possible and how to develop software better. The next section will provide references to project examples, useful code bases, and tools to improve your overall Cortex-M awareness.
Exploring useful examples and code
The Arm Cortex-M space moves fast. New boards and new example software are created every month, and it is helpful to any Cortex-M developer to be aware of emerging resources that can help your own development. These resources can be anything from new hardware, code bases, tools, or excellent examples showcasing what is possible today. Let’s dive in!
Examples on the Raspberry Pi Pico
The Raspberry Pi Pico was released in 2021 on the RP2040, the first SoC designed by Raspberry Pi themselves. It has exploded in popularity, with the Arm Cortex-M community creating examples exploring what is possible on the Pico. Here are some examples that showcase Pico’s possibilities.
Multi-core Pico
This example highlights a core (pun intended) feature of the RP2040 SoC on the Pico: two Cortex-M0+ processors. As discussed in Chapter 1, Selecting the Right Hardware, Arm optimized the Cortex-M0+ to minimize power and area. This comes at a cost of performance, making it difficult to run concurrent tasks on one Cortex-M0+ such as communication and sensing data.
The multi-core nature of the Pico offsets this disadvantage by enabling two tasks to run in parallel, one on each Cortex-M0+. This example highlights, in simple yet powerful terms, how to utilize this functionality with provided source code. You can view and replicate the example here:
https://learnembeddedsystems.co.uk/basic-multicore-pico-example
Multilingual Blinky
This example is a good reference to explore the different languages that the Pico can run. It shows how to go from zero to blink for several languages supported by the Pico at the time of publication. The languages included are as follows:
- C (naturally)
- MicroPython
- CircuitPython
- JavaScript
- Arduino
- Rust
- Lua
- Go
- FreeRTOS (an OS port, not a language port)
View the blog to implement these languages yourself:
https://www.raspberrypi.com/news/multilingual-blink-for-raspberry-pi-pico/
USB microphone
This example illustrates how flexible the RP2040 SoC can be, defining how to create a low-cost microphone cleverly named the Mico. It uses a software microphone library for the Pico and a small PDM microphone, as well as a custom-defined PCB to situate the components. You can view how to create your own custom Mico or learn from the software libraries provided for future projects. An example can be found here:
https://www.cnx-software.com/2021/12/31/mico-a-usb-microphone-based-on-raspberry-pi-rp2040-mcu/
Micro-ROS
This example showcases how to bring the Pico into the world of robotics, through a modified version of the Robot Operating System (ROS). ROS (https://www.ros.org/) is a purpose-built suite of software, libraries, and tools to enable the creation of robotics applications. It is intended to be run on rich OSes such as Windows and Linux, targeting powerful computers controlling robot components. Historically, there has been a gap between easily controlling and communicating with resource-constrained microcontrollers in robotics, tasked with real-time behavior and reducing power draw.
The Micro-ROS project bridges the gap between large processors and tiny microcontrollers in robotic applications. If you are interested in exploring this project and its possibilities, you can find its overview here: https://micro.ros.org/. This blog on running Micro-ROS on the Pico is a great example of how to use the Pico in unique ways: https://ubuntu.com/blog/getting-started-with-micro-ros-on-raspberry-pi-pico.
Examples for machine learning
Going beyond examples for the Raspberry Pi Pico, there is more content on websites, forms, and tools that highlight various Cortex-M-based board capabilities. The following are some helpful examples in the machine learning space.
Image classification
This example walks you through how to create an edge device with the ability to recognize objects in your house. It is flexible, with several hardware board options that can use the same flow, including the Raspberry Pi 4. This tutorial focuses on simplifying the machine learning implementation with the Edge Impulse tool. Consider it a great resource to understand the end-to-end machine learning implementation process, including data collection, preprocessing, ML algorithm selection, model training, model validation, and flashing to your board. Find examples on the Edge Impulse website: https://docs.edgeimpulse.com/docs/tutorials/image-classification.
Speech recognition
This example enables you to port a TensorFlow Lite model to an edge device to perform on-device wake-word detection. It features the NXP i.MX RT1010 board based around a Cortex-M7. You can get hands-on experience with using the TensorFlow Lite Micro library and can use these same principles in other projects with related goals. See the example here: https://www.hackster.io/naveenbskumar/speech-recognition-at-the-edge-40ba12.
Code bases, tools, and other resources to leverage
Examples are useful resources when developing software. There are also helpful code bases to expedite software development, assorted tools to make development easier, and educational resources to learn more about a specific topic. Hundreds of these libraries, tools, and resources exist; there are too many to list here. Instead, we will focus on a select few that we see as adding substantial value to common themes in Cortex-M projects.
Pigweed
While still new and under development, Pigweed is poised to represent a step-change in usability for embedded development. Pigweed aims to enable faster and more reliable development to microcontrollers, bringing common advantages that web developers have (such as saving a file then instantly seeing the change on a browser, and reproducible environment initialization) into embedded development.
It was announced in 2020 headed by the Google Open Source program and is slowly growing with support from the embedded community. It already offers modules that simplify environment setup, development, code validation, unit testing, and even memory allocation. The Raspberry Pi Pico is under development as a target for Pigweed, and you can view the announcement and documentation here:
- https://opensource.googleblog.com/2020/03/pigweed-collection-of-embedded-libraries.html
- https://pigweed.dev/
DSP Education Kit
Digital Signal Processing (DSP) is a wide topic that can be quite complex to implement efficiently in certain use cases. Arm University, a program from Arm that provides resources to schools to educate people on the latest technology from Arm and its ecosystem, has an education kit dedicated to DSP. Publicly available on GitHub, the DSP Education Kit contains individual modules that focus on creating audio applications on Arm processors. It covers convolution, fast Fourier transform (FFTs), finite impulse response (FIR) filters, noise cancelation, predictive algorithms, and adaptive FIR filters, to name a few.
The GitHub repository offers example code with associated PowerPoint/Word documents that provide context. It is an excellent resource to learn audio algorithm implementation and utilizes an STM32F746G Discovery board. The repository is located here: https://github.com/arm-university/Digital-Signal-Processing-Education-Kit.
CMSIS tools
CMSIS libraries offer a simplification for Cortex-M software developers, and this book has shown several examples of leveraging CMSIS software. For more than a decade, CMSIS has provided software reuse across the Cortex-M microcontroller industry. It is a valuable learning tool and saves significant time in any project.
Developers continue to consume CMSIS in the form of CMSIS-Packs. A Pack is a delivery mechanism to package source code, libraries, documentation, and examples into an easy-to-consume bundle. Packs have always been easy to find and import into Cortex-M development tools such as Keil Microcontroller Development Kit (MDK) and other similar tools.
The Open-CMSIS-Pack project was recently started to open the development of the infrastructure and tools for Packs. This will make the standards and associated tools open source.
Open-CMSIS-Pack is important because, as we have highlighted, Cortex-M developers are taking advantage of new tools and technology using the cloud and automation. Historically, most Cortex-M development has been done on Windows PCs but is now shifting to the cloud and using other operating systems such as Linux and macOS. There is also increasing use of VS Code for microcontroller development. The Open-CMSIS-Pack project delivers new tools that can work on a variety of machines including Linux and macOS, and even machines that use the Arm architecture. This freedom and flexibility ensure that developers can continue to get the benefits of software reuse and take advantage of example code, no matter what kind of computer they use. If you have been using Packs with a traditional IDE, now is a good time to investigate the Open-CMSIS-Pack development tools.
View the repository here: https://github.com/Open-CMSIS-Pack/devtools.
Vectorization on the Cortex-M55 and Cortex-M85
The two newest Cortex-M processors both bring the power of vector processing to the Cortex-M family. Due to its recency, many microcontroller developers are not used to working with vectors in this low-resource context.
There are many available resources to learn more about this topic, summarized brilliantly on an ongoing basis by Joseph Yiu in the Arm Community. Here is the link to that page: https://community.arm.com/arm-community-blogs/b/architectures-and-processors-blog/posts/armv8_2d00_m-based-processor-software-development-hints-and-tips.
Reviewing these resources will give you a broad understanding of Cortex-M possibilities, and great places to start from today. In addition to these great community resources, there are several Arm projects being developed today (mid-2022) that will offer great value to Cortex-M software developers as they mature. Next is a brief overview of these projects to be aware of.
Official Arm projects under development
When we say official Arm projects, we mean projects that are managed and maintained by Arm employees under the Arm company umbrella. The primary place to look for these software projects is on GitHub under the Arm Software organization: https://github.com/ARM-software/. We have referred to several well-established repositories from this organization in this book already. Here are a few projects that Arm is actively developing to be helpful resources as they expand wider.
IoT SDK
The Arm Open-IoT SDK is intended to guide developers to explore and evaluate Arm IP, CMSIS APIs, and tools. Today, it is mainly focused on Arm Total Solution applications, with resources highlighting Arm Virtual Hardware, continuous integration, and the ML Embedded Evaluation Kit (all of which we have explored in this book). It also will include reference implementations for PSA (such as TF-M, covered in Chapter 7, Enforcing Security) and the Open-CMSIS-CDI, which is covered next. This is the GitHub link: https://github.com/ARM-software/open-iot-sdk.
Open-CMSIS-CDI
This project is new and launched in the summer of 2022. It is a collaboration between Arm and Linaro to define a common device interface for microcontrollers in the IoT. An ambitious goal is just getting started, planning on defining a common set of interfaces that will enable cloud service-to-device interaction and enable common IoT software stacks to run across Cortex-M-based devices with minimal porting required.
At the time of publication, there is very little public code on GitHub, but a repository has been established with the potential to fundamentally change how developers work on IoT projects. Keep an eye on this repository in the future: https://github.com/Open-CMSIS-Pack/open-cmsis-cdi-spec.
2D graphics library
The seemingly natural arc of technology is to start as new and difficult to use, then expand to mass-market adoption by being easy to use. This is primarily how computers became widespread: improving on the command-line-based interaction from older computers to a graphical interface that was easier for most people to work with. The IoT is at a similar point now, exacerbated by people’s expectations due to their slick smartphone interfaces. IoT devices will require GUIs to be widely adopted.
Offering this from Cortex-M-based microcontrollers, running at tens or hundreds of MHz, can prove challenging. Most GUI libraries are built on top of rich OS drivers, enabling Linux developers but not Cortex-M developers. The Arm-2D project aims to solve this problem by accelerating fundamental low-level 2D image processing, abstracting away complexity to jump-start IoT GUI development. It is built on CMSIS components and is under active development. You can view the GitHub project at this link, which provides excellent context and examples to get started: https://github.com/ARM-software/Arm-2D.
So far in this chapter, we have reviewed examples, tools, software libraries, and Arm projects that you can reference to create better Cortex-M software. From here onward, we will focus not on what is possible now, but instead on what may be possible in the future.
The future – how trends will affect Cortex-M developers
In the final section of this book, we attempt to translate emerging societal and technological trends into their impact on Cortex-M software development. This is a very subjective undertaking, as predicting the future is fraught with biases and faulty assumptions, but we nonetheless will try.
We are at a critical inflection point in human history, with technological capabilities increasing exponentially as advancements in computation produce faster advancements of computation. Our society is rapidly reconfiguring around technology but is largely still based on centuries-old institutions; our governments were created when the newspaper was the primary mass communication method. Our human brains have largely remained the same for thousands of years, with our core instincts and intuition developing in a completely different society based around hunting and gathering. So, humanity now has a problem: we have Paleolithic emotions, medieval institutions, and godlike technology.
This fundamental clash is causing tectonic societal shifts and continual change that we can all feel in the early 2020s. There are three primary areas that we will focus on here, breaking down how these trends could influence the ways we as embedded software developers work:
- 5G and the Internet of Everything
- Environmental sustainability
- Decentralization of information
There are numerous other shifts occurring as well, such as job automation, which we do not have the space to cover in this book. We suggest that you investigate how societal shifts in your locale may alter how or what software you develop, as it can place you as knowledgeable in a critical area before others are aware of the need.
Trend 1 – 5G and the Internet of Everything
5G, for those not already aware, is the fifth generation of cellular mobile communications. It is, like its predecessors 4G, 3G, and 2G, a system that connects devices to the internet through cell towers. The 5G network represents a huge leap in capabilities over 4G and 4G LTE, enabling orders of magnitude better performance in traffic capacity, network efficiency, connection density, latency, and throughput.
We have not talked explicitly about 5G technology in this book as many readers will already be familiar with the topic. The topics we have discussed—such as security, machine learning, and cloud computing—will naturally become more essential as the 5G network expands. New IoT use cases that were previously prohibited by cost, complexity, or network capability will soon become possible (and profitable).
5G as an enabler
At the risk of sounding clichéd, a global 5G network will truly unlock the value of IoT. Opportunities will arise to make the world of “things” more effective and efficient. We will be able to better understand and act through “things” in the world around us. These “things” will be the next generation of IoT devices. I (Zach) like to break down these devices into two categories: sensors that help us understand, and actuators that help us act.
Sensing devices are already numerous and will grow to encompass a huge range of capabilities, measuring things such as air quality, traffic congestion, parking availability, trash levels, electricity consumption, drinking water quality, food freshness, ocean acidification levels, manufacturing defects, and so on. Actuating devices act on or in our world to achieve a goal, such as moving a car without human input, running factories, flying drones, providing dynamic city lighting, and thousands more.
While IoT is set to grow dramatically, its growth will still largely depend on the core software concepts we have discussed in this book. Concepts of particular importance include security, machine learning, and cloud development practices. We also expect that, due to 5G network capabilities, market opportunities, and societal priorities, IoT will grow broader and become the Internet of Everything. This means sensing and acting not only on limited elements of the world but on essential societal systems and even human beings.
The Internet of Everything
The term Internet of Everything is used to differentiate from the Internet of Things by the nature of what is being sensed and acted upon. The distinct terminology helps us think differently about what is possible in this solution space. The ability to automatically understand and modify the behaviors of people is fundamentally different than sensing and acting on inanimate objects. Even controlling critical infrastructure is different in kind from controlling other inanimate objects as they are essential to a functioning modern society.
Using the term IoT to describe what exists today versus the next generation of connected devices is like calling the first cars mechanical horses. Cars, in their forms and abilities, are so much more than horses that using the name mechanical horses limits our thinking about what they even do—and what they can affect.
The monitoring and modifying of the human body and behaviors is one hallmark of the Internet of Everything. Health wearables fall into this category, although today the most common devices, such as smart watches and fitness trackers, only monitor activity. Some specialized devices do act on our bodies today. Pacemakers stimulate heart muscles to beat and transmit status information to a smartphone. Continuous glucose monitors sense glucose in the bloodstream and dynamically allocate insulin as appropriate.
The next generation of Internet of Everything devices will take these specialized use cases to everyday human health. Imagine, while eating dinner, receiving a notification from your phone that cancerous cells were detected on your stomach lining. Luckily, you are told that your wristband has already injected nanobots into your bloodstream that have isolated and neutralized the threat. Medication will arrive at your door tomorrow that you can take if you experience any minor side effects, such as stomach discomfort.
This scenario may seem far-fetched and perhaps a bit sinister, but there are many possible ways to automatically monitor and modify someone’s health that are within technological reach today. The natural human desire to be healthy, combined with the scale of the number of humans on earth, will create large monetary incentives to develop this type of product.
The second major hallmark of the Internet of Everything is the ubiquity of control over critical infrastructure. This includes the electricity grid, water treatment facilities, oil and gas pipelines, nuclear weapons facilities, and internet services, among other essentials of modern life. Previously, these facilities were controlled by a select few individuals with private access to physical resources. The proliferation of digital connectivity granted governments/companies the ability to automatically monitor and control this infrastructure.
This level of automation creates cost-saving efficiencies and improved service reliability. It also creates a larger attack surface for hackers to disrupt critical systems. There have already been examples of this happening to countries and companies all over the world. Security will be even more important in the future as more of humanity’s critical infrastructure becomes digitally connected.
The Internet of Everything requires reliability, security, and privacy principles above and beyond the standards set for IoT devices today. Software developers targeting Cortex-M devices can start sharpening skills now to plan for the expansion of IoT and the emergence of the Internet of Everything.
Here are some takeaways for embedded software developers:
- Learn how to effectively implement security and machine learning on edge devices
- Learn techniques to provision and manage a large number of IoT devices deployed in the field at once
- Learn the reliability and safety capabilities of Cortex-M processors, and how to develop safety-certified software, to work in the critical infrastructure and medical industries
- Learn about ethical design in healthcare, and how to ethically modify human behavior with informed consent
The next trend has broad implications across all of society, and specific implications for Cortex-M developers: environmental sustainability.
Trend 2 – environmental sustainability
A core reason why technology has advanced so quickly in modern times is due to our access to hyper-compressed forms of energy, releasing thousands of years of solar energy at a time through buried hydrocarbons. Oil and natural gas were created over millions of years and are considered non-renewable resources; they cannot be replaced in a human-scale time frame. While we are not on the cusp of using all oil and natural gas in the world, it will become more expensive over time to extract and refine them.
In the process of burning fossil fuels at societal scales, Earth’s climate has begun to change. This is considered a scientific fact (https://climate.nasa.gov/scientific-consensus/). As the effects of climate change become starker, investing in fossil fuels becomes less viable. The head of BlackRock, the world’s largest asset manager, with $10 trillion under management, sends out an annual letter to CEOs that he invests in. His letter in 2022 indicated that BlackRock is “asking companies to set short-, medium-, and long-term targets for greenhouse gas reductions.” This is an example of a large economic priority shift from fossil fuels to renewable energy sources, and pressure to decrease energy consumption generally.
Renewable energy challenges
Even if the world switches 100% to renewable energy, renewable energy sources such as wind, solar, and hydroelectric power cannot exactly replace the energy output of fossil fuels. Transporting a barrel of oil is straightforward enough; it can be done en masse to move energy from where it originated to where it is needed in a stable liquid form, storable, and ready to be burned by combustion engines when needed.
Transporting solar energy is much more complicated. Transmitting the energy requires high-voltage power lines that must be built at high up-front costs from new solar farm locations to local substations. Old power lines must be upgraded to handle the larger energy throughput. Solar energy also cannot be easily stored on location in a ready-to-use form. Furthermore, solar energy (and renewable energy in general) is also significantly less dense than non-renewable energy, requiring more energy to capture the same amount of power from other sources per unit volume.
All of this is to say that economic and moral pressure is being placed on maintaining and increasing our standard of living while drastically reducing the power required to do so. For developers in the Cortex-M space, this means focusing more on ultra-low power devices.
The ultra-low power solution
Ultra-low power refers to devices that require an exceptionally small amount of power to run, by today’s standards. This enables devices based on Arm Cortex-M processors to be run by small batteries that last for many years or, in emerging cases, without batteries at all. Energy harvesting enables some devices to gather energy from the surrounding environment to power their components. Sources include indoor solar, ambient RF waves, vibration, and thermal gradients.
There are several emerging examples today of battery-less devices. The University of Michigan has spun out Everactive, a startup focused on making battery-less sensors: https://everactive.com/. RELOC has also developed a Bluetooth 5.0 module that can harvest energy for battery-less sensors. It is called the RM_BE1 and is based on a Renesas MCU featuring the Arm Cortex-M0+. Universal Electronics has announced an SoC that can harvest energy from ambient RF and indoor light, intended for voice-activated remote controls. It will also leverage Arm TrustZone security technology. That announcement can be found here: https://www.uei.com/news/uei-unveils-extreme-low-power-chip-platform.
Creating sustainable devices that are ultra-low power and last decades also addresses another looming problem: electronic waste and precious metal depletion. The currently known accessible supply of lithium (an essential element for batteries today) is smaller than the proposed rate of global electrification. As lithium demand outpaces accessible supply, the requirements for ultra-low power devices will likely skyrocket. Software developers targeting Cortex-M devices can start gaining skills now to plan for this likely future focus on ultra-low power consumption in IoT.
Here are some takeaways for embedded software developers:
- Learn how to implement Cortex-M power optimization techniques in software, such as hibernation states
- Learn about how ultra-low power applications restrict software capabilities, and how to work within these constraints to deliver a functional device
- Learn about battery-less devices and energy harvesting as the technology advances over time
- Learn how to extend your device’s life cycle to decades instead of years, including field updates and repairability
The next trend focuses on a broad trend with a few different repercussions for the technology industry: the decentralization of information.
Trend 3 – decentralization of information
When the internet started to become mainstream in the 1990s and early 2000s, it was anticipated to be a medium where individuals could interact directly with other individuals on their own terms. Radio had strict frequency allocation maps that restricted public communications, and television was a one-way medium communicating information from media monopolies to the public. The internet was supposed to be decentralized, with the power to create and share imbued to individuals.
The centralized web
Over the last two decades, it has become clear that monopolies naturally form on the internet due to network effects. A network effect occurs when the value of something increases the more people use it, leading to exponential value creation. Think of social media companies; it is easier to connect with friends when they are all on one social media network, and new social media companies cannot compete with existing ones that have all people on it. Why switch to a social media platform when there is no one to be social with?
This is as true for social media platforms as it is for search-based companies. The more people search on a given website, the more data they can collect and the better they can get at serving results people want. Advertising-based business models on the internet follow the same dynamics, resulting in a handful of hyper-scale companies that centrally control much of the internet landscape.
The most valuable asset these massive internet companies has is their users’ personal information and data (including the machine learning models based on this data). The value of large quantities of personal information also leads these companies to sell user data to make money, through commercial and political advertising. In the past few years, public sentiment has started to turn against the free gathering and inappropriate sharing of personal data, exacerbated by certain scandals. First envisioned as a decentralized medium to empower individuals, the internet from the 2000s to today has largely done the opposite. There is still a societal desire to develop technology that redistributes power from centralized sources to individuals, however. This desire is currently dovetailing with new decentralization technologies, such as blockchain, and we are now on the cusp of a new type of internet: Web 3.0.
Web 3.0 and decentralized IoT
The term Web 3.0 (also referred to as Web3) is largely a shorthand buzzword describing a larger idea: a new iteration of the internet that leverages decentralization and blockchain technologies. Blockchain technology is a key technology that enables mass decentralization. There are many resources explaining what blockchain is, what it can do, and its value. IBM has a succinct and helpful explanation here: https://www.ibm.com/topics/what-is-blockchain.
This new decentralized internet is just emerging and use cases are still being proven in practice. The potential range of Web3 applications is massive. Decentralized money, such as cryptocurrency, could fundamentally change how our economy operates. You will certainly be familiar with the popular example of Bitcoin, with hundreds of others being used today as well. Decentralized information on a blockchain has the potential to securely trace food through supply chains to minimize food waste. Decentralized data ownership could enable individuals to profit from their personal information instead of companies. The web browser Brave offers this today by enabling users to opt in to see targeted ads, who receive Basic Attention Tokens (a cryptocurrency) in exchange.
These possibilities will influence what skills embedded developers need to be successful in the Web3 space, with the largest areas being increased attention to security and data privacy. Another possibility is a shift in how IoT devices are managed to better align with the core value of Web3: decentralization.
Today, the predominant management model of IoT device networks is centralized. All IoT devices for a single use case are managed by a central node in the system. This arrangement makes it simple to push secure firmware updates to all devices and manage incoming device data, to take two examples. It also minimizes the amount of storage and processing power required on each device as most storage and processing is performed at a central server. Complying with data protection regulations, such as GDPR, becomes easier due to storing and managing information on a small number of well-defined server controllers.
At the opposite end of the spectrum is a distributed IoT network. Here, each device node acts completely autonomously and is interconnected with other network nodes. This requires more storage and processing capabilities to be built into each device, increasing costs. Issues also arise when trying to comply with data protection regulations, and maintenance requires more thought and effort. There are, however, many benefits to this appro ach. A high potential to scale exists due to efficient task distribution; stability is formed from a lack of a single point of failure, and complex tasks can be processed quickly throughout the network nodes.
There is also the concept of a decentralized IoT network, which is between a centralized and distributed network in nature. Its IoT nodes are clustered into smaller networks that connect to one another through “super-nodes.” The costs and benefits of this approach are between a centralized and distributed management model.
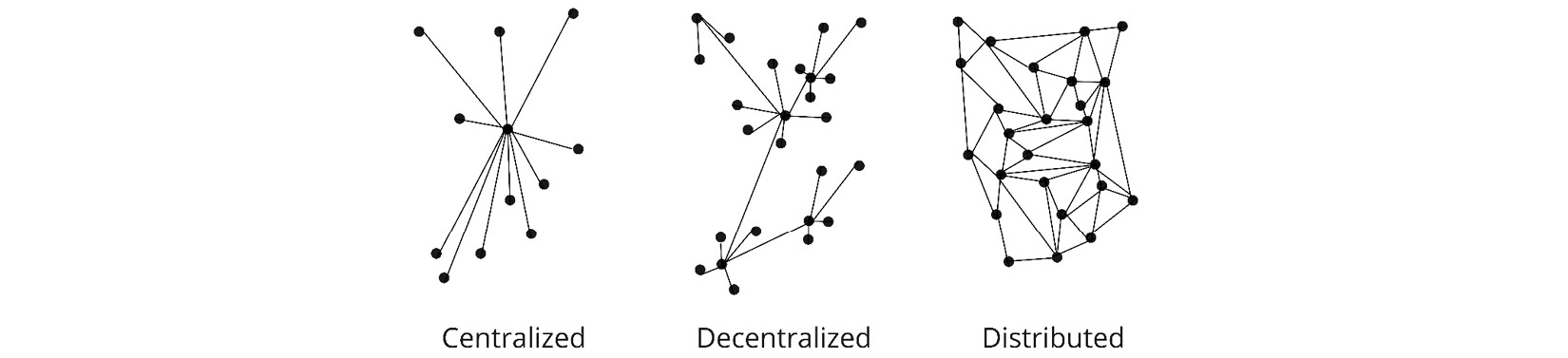
Figure 10.1 – Different network architectures, visualized
The overarching idea of moving power away from central sources is obeyed by both a distributed and decentralized IoT network. In practice, applying one of these management models to your next IoT project may require new ways of approaching things such as device management, firmware updates, secure storage locations, data privacy, and distributed computation.
In summary, as decentralized concepts grow more popular, embedded programmers should be ready to apply them. This means properly enabling the decentralized internet with IoT devices and creating decentralized/distributed IoT networks.
Here are some takeaways for embedded software developers:
- Learn about different business models involving people owning their own data, and how this will affect what is possible with ML at the edge
- Learn how to effectively implement security best practices on edge devices, with special attention to private user information
- Learn about the principles of distributed versus decentralized versus centralized IoT network models, and how to effectively manage IoT fleets without centralized control.
To learn more about how to design technology products that take into account these (and more) societal trends, check out the Center for Humane Technology. They have excellent resources such as articles, podcasts, and expert interviews that expand on these kinds of topics (https://www.humanetech.com/).
The end
With that, our journey comes to an end. Throughout this book, we covered a lot of ground across various Cortex-M topics. Part 1, Get Set Up, detailed how to intelligently select the right hardware, software, and tools for your specific project requirements. Part 2, Sharpen Your Skills, showed how to implement key software topics (booting to main, optimizing performance, leveraging machine learning, and enforcing security) and development techniques (streamlining with the cloud and implementing continuous integration). This last chapter offered avenues to continue learning how to be a better Cortex-M software developer: helpful tips and examples to view today, projects to leverage in the coming months, and our subjective previews into futuristic shifts to get ahead of in the coming years.
Be sure to reference our GitHub repository containing all example code referenced in this book. If you have any questions or comments about the book or Cortex-M development in general, feel free to contact us directly. We have listed our email addresses here for your convenience.
- Zach Lasiuk – [email protected]
- Pareena Verma – [email protected]
- Jason Andrews – [email protected]
Finally, thank you for reading! We (Jason, Pareena, and Zach) are all passionate about helping Cortex-M developers change the world through technology. We hope that after reading this book, you are better equipped to create the next generation of smart, secure, and connected devices.