
Chapter 3. REST, Resources, and Rails
Before REST came I (and pretty much everyone else) never really knew where to put stuff.
—Jonas Nicklas on the Ruby on Rails mailing list
With version 1.2, Rails introduced support for designing APIs consistent with the REST style. Representational State Transfer (REST) is a complex topic in information theory, and a full exploration of it is well beyond the scope of this chapter.1 We’ll touch on some of the keystone concepts, however. And in any case, the REST facilities in Rails can prove useful to you even if you’re not a REST expert or devotee.
The main reason is that one of the inherent problems that all web developers face is deciding how to name and organize the resources and actions of their application. The most common actions of all database-backed applications happen to fit well into the REST paradigm.
3.1 REST in a Rather Small Nutshell
REST is described by its creator, Roy T. Fielding, as a network architectural style, specifically the style manifested in the architecture of the World Wide Web. Indeed, Fielding is not only the creator of REST but also one of the authors of the HTTP protocol itself. REST and the web have a very close relationship.
Fielding defines REST as a series of constraints imposed upon the interaction between system components. Basically, you start with the general proposition of machines that can talk to each other, and you start ruling some practices in and others out by imposing constraints that include (among others):
• Use of a client-server architecture
• Stateless communication
• Explicit signaling of response cacheability
• Use of HTTP request methods such as GET, POST, PUT, and DELETE
The World Wide Web allows for REST-compliant communication. It also allows for violations of REST principles; the constraints aren’t always all there unless you put them there. As for this chapter, the most important thing you have to understand is that REST is designed to help you provide services using the native idioms and constructs of HTTP. You’ll find, if you look for it, lots of discussion comparing REST to, for example, SOAP—the thrust of the pro-REST argument being that HTTP already enables you to provide services, so you don’t need a semantic layer on top of it. Just use what HTTP already gives you.
One of the allures of REST is that it scales relatively well for big systems, like the web. Another is that it encourages—mandates, even—the use of stable, long-lived identifiers (URIs). Machines talk to each other by sending requests and responses labeled with these identifiers. Messages consist of representations (manifestations in text, XML, graphic format, and so on) of resources (high-level, conceptual descriptions of content) or simply HTTP headers.
Ideally at least, when you ask a machine for an XML representation of a resource—say, Romeo and Juliet—you’ll use the same identifier every time and the same request metadata indicating that you want XML, and you’ll get the same response. And if it’s not the same response, there’s a reason—like, the resource you’re retrieving is a changeable one (“The current transcript for Student #3994,” for example).
3.2 Resources and Representations
The REST style characterizes communication between system components (where a component is, say, a web browser or a server) as a series of requests to which the responses are representations of resources.
A resource, in this context, is a “conceptual mapping” (Fielding). Resources themselves are not tied to a database, a model, or a controller. Examples of resources include
• The current time of day
• A library book’s borrowing history
• The entire text of The Little Prince
• A map of Jacksonville Beach
• The inventory of a store
A resource may be singular or plural, changeable (like the time of day) or fixed (like the text of The Little Prince). It’s basically a high-level description of the thing you’re trying to get hold of when you submit a request.
What you actually do get hold of is never the resource itself, but a representation of it. This is where REST unfolds onto the myriad content types and actual deliverables that are the stuff of the web. A resource may, at any given point, be available in any number of representations (including zero). Thus your site might offer a text version of The Little Prince, but also an audio version. Those two versions would be understood as the same resource, and would be retrieved via the same identifier (URI). The difference in content type—one representation vs. another—would be negotiated separately in the request.
3.3 REST in Rails
The REST support in Rails consists of methods to define resources in the routing system, designed to impose a particular style and order and logic on your controllers and, consequently, on the way the world sees your application. There’s more to it than just a set of naming conventions (though there’s that too). In the large scheme of things, the benefits that accrue to you when you use Rails’s REST support fall into two categories:
• Convenience and automatic best practices for you
• A RESTful interface to your application’s services for everyone else
You can reap the first benefit even if you’re not concerned with the second. In fact, that’s going to be our focus here: what the REST support in Rails can do for you in the realm of making your code nicer and your life as a Rails developer easier.
I don’t mean to minimize the importance of REST itself, nor the seriousness of the endeavor of providing REST-based services. Rather, it’s an expedient; we can’t talk about everything, and this section of the book is primarily about routing and how to do it, so we’re going to favor looking at REST in Rails from that perspective.
Getting back to practical matters, the focus of the rest of this chapter will be showing you how REST support works in Rails opening the door to further study and practice including the study of Fielding’s dissertation and the theoretical tenets of REST. We won’t cover everything here, but what we do cover will be onward compatible with the wider topic.
The story of REST and Rails starts with CRUD...
3.4 Routing and CRUD
The acronym CRUD (Create Read Update Delete) is the classic summary of the spectrum of database operations. It’s also a kind of rallying cry for Rails practitioners. Because we address our databases through abstractions, we’re prone to forget how simple it all is. This manifests itself mainly in excessively creative names for controller actions. There’s a temptation to call your actions add_item and replace_email_address and things like that. But we needn’t, and usually shouldn’t, do this. True, the controller does not map to the database, the way the model does. But things get simpler when you name your actions after CRUD operations, or as close to the names of those operations as you can get.
The routing system does not force you to implement your app’s CRUD functionality in any consistent manner. You can create a route that maps to any action, whatever the action’s name. Choosing CRUD names is a matter of discipline. Except... when you use the REST facilities offered by Rails, it happens automatically.
REST in Rails involves standardization of action names. In fact, the heart of the Rails’s REST support is a technique for creating bundles of named routes automatically—named routes that are bundled together to point to a specific, predetermined set of actions.
Here’s the logic. It’s good to give CRUD-based names to your actions. It’s convenient and elegant to use named routes. The REST support in Rails gives you named routes that point to CRUD-based action names. Therefore, using the REST facilities gives you a shortcut to some best practices.
Shortcut hardly describes how little work you have to do to get a big payoff. If you put
resources :auctions
into your config/routes.rb file, you will have created four named routes, which, in a manner to be described in this chapter, connect to seven controller actions. And those actions have nice CRUD-like names, as you will see.
3.4.1 REST Resources and Rails
Like most of Rails, support for RESTful applications is “opinionated”; that is, it offers a particular way of designing a REST interface, and the more you play along, the more convenience you reap from it. Most Rails applications are database-backed, and the Rails take on REST tends to associate a resource very closely with an Active Record model, or a model/controller stack.
In fact, you’ll hear people using the terminology fairly loosely. For instance, they’ll say that they have created a Book resource. What they mean, in most cases, is that they have created a Book model, a book controller with a set of CRUD actions, and some named routes pertaining to that controller (courtesy of resources :books). You can have a Book model and controller, but what you actually present to the world as your resources, in the REST sense, exists at a higher level of abstraction: The Little Prince, borrowing history, and so on.
The best way to get a handle on the REST support in Rails is by going from the known to the unknown. In this case, from the topic of named routes to the more specialized topic of REST.
3.4.2 From Named Routes to REST Support
When we first looked at named routes, we saw examples where we consolidated things into a route name. By creating a route like
match 'auctions/:id' => "auction#show", :as => 'auction'
you gain the ability to use nice helper methods in situations like
link_to item.description, auction_path(item.auction)
The route ensures that a path will be generated that will trigger the show action of the auctions controller. The attraction of this kind of named route is that it’s concise and readable.
Now, think in terms of CRUD. The named route auction_path is a nice fit for a show (the R in CRUD) action. What if we wanted similarly nicely named routes for the create, update, and delete actions?
Well, we’ve used up the route name auction_path on the show action. We could make up names like auction_delete_path and auction_create_path but those are cumbersome. We really want to be able to make a call to auction_path and have it mean different things, depending on which action we want the URL to point to.
We could differentiate between the singular (auction_path) and the plural (auctions_path). A singular URL makes sense, semantically, when you’re doing something with a single, existing auction object. If you’re doing something with auctions in general, the plural makes more sense.
The kinds of things you do with auctions in general include creating. The create action will normally occur in a form:
form_tag auctions_path
It’s plural because we’re not saying “perform an action with respect to a particular auction,” but rather “with respect to the collection of auctions, perform the action of creation.” Yes, we’re creating one auction, not many. But at the time we make the call to our named route, auctions_path, we’re addressing auctions in general.
Another case where you might want a plural named route is when you want an overview of all of the objects of a particular kind, or at least, some kind of general view, rather than a display of a particular object. This kind of general view is usually handled with an index action. These index actions typically load a lot of data into one or more variables, and the corresponding view displays it as a list or table (possibly more than one).
Here again, we’d like to be able to say:
link_to "Click here to view all auctions", auctions_path
Already, though, the strategy of breaking auction_path out into singular and plural has hit the wall: We’ve got two places where we want to use the plural named route. One is create; the other is index. But they’re both going to look like
/auctions
How is the routing system going to know that when we use auctions_path as a link versus using it in a form that we mean the create action and not index? We need another qualifier, another flag, another variable on which to branch.
Luckily, we’ve got one.
3.4.3 Reenter the HTTP Verb
Form submissions are POSTs by default. Index actions are GETs. That means that we need to get the routing system to realize that
/auctions submitted in a GET request!
/auctions submitted in a POST request!
are two different things. We also have to get the routing system to generate the same URL—/auctions—but with a different HTTP request method, depending on the circumstances.
This is what the REST facility of Rails routing does for you. It allows you to stipulate that you want /auctions routed differently, depending on the HTTP request method. It lets you define named routes with the same name, but with intelligence about their HTTP verbs. In short, it uses HTTP verbs to provide that extra data slot necessary to achieve everything you want to achieve in a concise way.
The way you do this is by using a special routing method: resources. Here’s what it would look like for auctions:
resources :auctions
That’s it. Making this one call inside routes.rb is the equivalent of defining four named routes. And if you mix and match those four named routes with a variety of HTTP request methods, you end up with seven useful—very useful—permutations.
3.5 The Standard RESTful Controller Actions
Calling resources :auctions involves striking a kind of deal with the routing system. The system hands you four named routes. Between them, these four routes point to seven controller actions, depending on HTTP request method. In return, you agree to use very specific names for your controller actions: index, create, show, update, destroy, new, edit.
It’s not a bad bargain, since a lot of work is done for you and the action names you have to use are nicely CRUD-like.
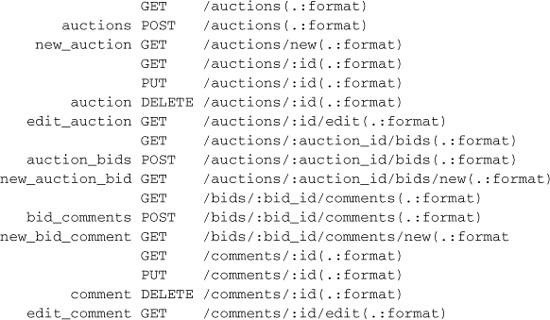
Table 3.1 summarizes what happens. It’s a kind of “multiplication table” showing you what you get when you cross a given RESTful named route with a given HTTP request method. Each box (the nonempty ones, that is) shows you, first, the URL that the route generates and, second, the action that gets called when the route is recognized. (The table lists _path methods rather than _url ones, but you get both.)
Table 3.1. RESTful Routes Table Showing Helpers, Paths, and the Resulting Controller Action

(The edit and new actions have unique named routes, and their URLs have a special syntax.)
Since named routes are now being crossed with HTTP request methods, you’ll need to know how to specify the request method when you generate a URL, so that your GET’d clients_url and your POST’d clients_url don’t trigger the same controller action. Most of what you have to do in this regard can be summed up in a few rules:
- The default request method is GET.
- In a
form_tagorform_forcall, the POST method will be used automatically. - When you need to (which is going to be mostly with PUT and DELETE operations), you can specify a request method along with the URL generated by the named route.
An example of needing to specify a DELETE operation is a situation when you want to trigger a destroy action with a link:
link_to "Delete", auction_path(auction), :method => :delete
Depending on the helper method you’re using (as in the case of form_for), you might have to put the method inside a nested hash:
form_for "auction", :url => auction_path(auction),
:html => { :method => :put } do |f|
That last example, which combined the singular named route with the PUT method, will result in a call to the update action when submitting the form (as per row 2, column 4 of Table 3.1). You don’t normally have to program this functionality specifically, because as we’ll see later in the book, Rails automatically figures out whether you need a POST or PUT if you pass an object to form helpers.
3.5.1 Singular and Plural RESTful Routes
As you may have noticed, some of the RESTful routes are singular; some are plural. The logic is as follows:
- The routes for
show,new,edit, anddestroyare singular, because they’re working on a particular resource. - The rest of the routes are plural. They deal with collections of related resources.
The singular RESTful routes require an argument, because they need to be able to figure out the id of the member of the collection referenced.
item_url(item) # show, update, or destroy, depending on HTTP verb
You don’t have to call the id method on item. Rails will figure it out (by calling to_param on the object passed to it).
3.5.2 The Special Pairs: new/create and edit/update
As Table 3.1 shows, new and edit obey somewhat special RESTful naming conventions. The reason for this has to do with create and update, and how new and edit relate to them.
Typically, create and update operations involve submitting a form. That means that they really involve two actions—two requests—each:
- The action that results in the display of the form
- The action that processes the form input when the form is submitted
The way this plays out with RESTful routing is that the create action is closely associated with a preliminary new action, and update is associated with edit. These two actions, new and edit, are really assistant actions: All they’re supposed to do is show the user a form, as part of the process of creating or updating a resource.
Fitting these special two-part scenarios into the landscape of resources is a little tricky. A form for editing a resource is not, itself, really a resource. It’s more like a pre-resource.A form for creating a new resource is sort of a resource, if you assume that being new—that is, nonexistent—is something that a resource can do, and still be a resource!
That line of reasoning might be a little too philosophical to be useful. The bottom line, as implemented in RESTful Rails, is the following: The new action is understood to be giving you a new, single (as opposed to plural) resource. However, since the logical verb for this transaction is GET, and GETting a single resource is already spoken for by the show action, new needs a named route of its own.
That’s why you have to use
link_to "Create a new item", new_item_path
to get a link to the items/new action.
The edit action is understood not to be giving you a full-fledged resource, exactly, but rather a kind of edit flavor of the show resource. So it uses the same URL as show, but with a kind of modifier, in the form of /edit, hanging off the end, which is consistent with the URL form for new:
/items/5/edit
The corresponding named route is edit_item_url(@item). As with new, the named route for edit involves an extra bit of name information, to differentiate it from the implied show of the existing RESTful route for GETting a single resource.
3.5.3 The PUT and DELETE Cheat
We have just seen how Rails routes PUT and DELETE requests. Some HTTP clients are able to use said verbs, but forms in web browsers can’t be submitted using anything other than a POST. Rails provides a hack that is nothing to worry about, other than being aware of what’s going on.
A PUT or DELETE request originating in a browser, in the context of REST in Rails, is actually a POST request with a hidden field called _method set to either "put" or "delete". The Rails application processing the request will pick up on this, and route the request appropriately to the update or destroy action.
You might say, then, that the REST support in Rails is ahead of its time. REST components using HTTP should understand all of the request methods. They don’t, so Rails forces the issue. As a developer trying to get the hang of how the named routes map to action names, you don’t have to worry about this little cheat. And hopefully some day it won’t be necessary any more. (HTML5 in particular adds PUT and DELETE as valid method attributes for forms.)
3.5.4 Limiting Routes Generated
It’s possible to add :except and :only options to the call to resources in order to limit the routes generated.
resources :clients, :except => [:index]
resources :clients, :only => [:new, :create]
3.6 Singular Resource Routes
In addition to resources, there’s also a singular (or singleton) form of resource routing: resource. It’s used to represent a resource that only exists once in its given context.
A singleton resource route at the top level of your routes can be appropriate when there’s only one resource of its type for the whole application, perhaps something like a per-user profile.
resource :profile
You get almost the full complement of resource routes, all except the collection route (index). Note that the method name resource, the argument to that method, and all the named routes generated are in the singular.

It’s assumed that you’re in a context where it’s meaningful to speak of the profile—the one and only—because there’s a user to which the profile is scoped. The scoping itself is not automatic; you have to authenticate the user and retrieve the profile from (and/or save it to) the database explicitly. There’s no real magic or mind-reading here; it’s just an additional routing technique at your disposal if you need it.
3.7 Nested Resources
Let’s say you want to perform operations on bids: create, edit, and so forth. You know that every bid is associated with a particular auction. That means that whenever you do anything to a bid, you’re really doing something to an auction/bid pair—or, to look at it another way, an auction/bid nest. Bids are at the bottom of a drill-down hierarchical structure that always passes through an auction.
What you’re aiming for here is a URL that looks like
/auctions/3/bids/5
What it does depends on the HTTP verb it comes with, of course. But the semantics of the URL itself are: the resource that can be identified as bid 5, belonging to auction 3.
Why not just go for bids/5 and skip the auction? For a couple of reasons. First, the URL is more informative—longer, it’s true, but longer in the service of telling you something about the resource. Second, thanks to the way RESTful routes are engineered in Rails, this kind of URL gives you immediate access to the auction id, via params[:auction_id].
To created nested resource routes, put this in routes.rb:
resources :auctions do
resources :bids
end
What that tells the mapper is that you want RESTful routes for auction resources; that is, you want auctions_url, edit_auction_url, and all the rest of it. You also want RESTful routes for bids: auction_bids_url, new_auction_bid_url, and so forth.
However, the nested resource command also involves you in making a promise. You’re promising that whenever you use the bid named route helpers, you will provide a auction resource in which they can be nested. In your application code, that translates into an argument to the named route method:
link_to "See all bids", auction_bids_path(auction)
When you make that call, you enable the routing system to add the /auctions/3 part before the /bids part. And, on the receiving end—in this case, in the action bids/index, which is where that URL points—you’ll find the id of auction in params[:auction_id]. (It’s a plural RESTful route, using GET. See Table 3.1 again if you forgot.)
You can nest to any depth. Each level of nesting adds one to the number of arguments you have to supply to the nested routes. This means that for the singular routes (show, edit, destroy), you need at least two arguments:
link_to "Delete this bid", auction_bid_path(auction, bid), :method =>
:delete
This will enable the routing system to get the information it needs (essentially auction.id and bid.id) in order to generate the route.
If you prefer, you can also make the same call using hash-style method arguments, but most people don’t because it’s longer code:
auction_bid_path(:auction => auction, :bid => bid)
3.7.1 RESTful Controller Mappings
Something we haven’t yet explicitly discussed is how RESTful routes are mapped to a given controller. It was just presented as something that happens automatically, which in fact it does, based on the name of the resource.
Going back to our recurring example, given the following nested route:
resources :auctions do
resources :bids
end
there are two controllers that come into play, the AuctionsController and the BidsController.
3.7.2 Considerations
Is nesting worth it? For single routes, a nested route usually doesn’t tell you anything you wouldn’t be able to figure out anyway. After all, a bid belongs to an auction.
That means you can access bid.auction_id just as easily as you can params[:auction_id], assuming you have a bid object already.
Furthermore, the bid object doesn’t depend on the nesting. You’ll get params[:id] set to 5, and you can dig that record out of the database directly. You don’t need to know what auction it belongs to.
Bid.find(params[:id])
A common rationale for judicious use of nested resources, and the one most often issued by David, is the ease with which you can enforce permissions and context-based constraints. Typically, a nested resource should only be accessible in the context of its parent resource, and it’s really easy to enforce that in your code based on the way that you load the nested resource using the parent’s Active Record association.
auction = Auction.find(params[:auction_id])
bid = auction.bids.find(params[:id]) # prevents auction/bid mismatch
If you want to add a bid to an auction, your nested resource URL would be
http://localhost:3000/auctions/5/bids/new
The auction is identified in the URL rather than having to clutter your new bid form data with hidden fields or resorting to non-RESTful practices.
3.7.3 Deep Nesting?
Jamis Buck is a very influential figure in the Rails community, almost as much as David himself. In February 2007, via his blog,2 he basically told us that deep nesting was a bad thing, and proposed the following rule of thumb: Resources should never be nested more than one level deep.
That advice is based on experience and concerns about practicality. The helper methods for routes nested more than two levels deep become long and unwieldy. It’s easy to make mistakes with them and hard to figure out what’s wrong when they don’t work as expected.
Assume that in our application example, bids have multiple comments. We could nest comments under bids in the routing like this:

Instead, Jamis would have us do the following:

Notice that each resource (except auctions) is defined twice, once in the top-level namespace, and one in its context. The rationale? When it comes to parent-child scope, you really only need two levels to work with. The resulting URLs are shorter and the helper methods are easier to work with.

I personally don’t follow Jamis’s guideline all the time in my projects, but I have noticed that limiting the depth of your nested resources helps with the maintainability of your codebase in the long run.
Courtenay says ...
Many of us disagree with the venerable Jamis. Want to get into fisticuffs at a Rails conference? Ask people whether they believe routes should be nested more than one layer deep.
3.7.4 Shallow Routes
As of Rails 2.3 resource routes accept a :shallow option that helps to shorten URLs where possible. The goal is to leave off parent collection URL segments where they are not needed. The end result is that the only nested routes generated are for the :index, :create, and :new actions. The rest are kept in their own shallow URL context.
It’s easier to illustrate than to explain, so let’s define a nested set of resources and set :shallow to true:

alternatively coded as follows (if you’re block-happy)

The resulting routes are:
If you analyze the routes generated carefully, you’ll notice that the nested parts of the URL are only included when they are needed to determine what data to display.
3.8 RESTful Route Customizations
Rails’s RESTful routes give you a pretty nice package of named routes, mapped to useful, common, controller actions—the CRUD superset you’ve already learned about. Sometimes, however, you want to customize things a little more, while still taking advantage of the RESTful route naming conventions and the multiplication table approach to mixing named routes and HTTP request methods.
The techniques for doing this are useful when, for example, you’ve got more than one way of viewing a resource that might be described as showing. You can’t (or shouldn’t) use the show action itself for more than one such view. Instead, you need to think in terms of different perspectives on a resource, and create URLs for each one.
3.8.1 Extra Member Routes
For example, let’s say we want to make it possible to retract a bid. The basic nested route for bids looks like this:
resources :auctions do
resources :bids
end
We’d like to have a retract action that shows a form (and perhaps does some screening for retractability). The retract isn’t the same as destroy; it’s more like a portal to destroy. It’s similar to edit, which serves as a form portal to update. Following the parallel with edit/update, we want a URL that looks like
/auctions/3/bids/5/retract
and a helper method called retract_auction_bid_url. The way you achieve this is by specifying an extra member route for the bids, as in Listing 3.1
Listing 3.1. Adding an extra member route
resources :auctions do
resources :bids do
member do
get :retract
end
end
end
Then you can add a retraction link to your view using
link_to "Retract", retract_bid_path(auction, bid)
and the URL generated will include the /retract modifier. That said, you should probably let that link pull up a retraction form (and not trigger the retraction process itself!). The reason I say that is because, according to the tenets of HTTP, GET requests should not modify the state of the server; that’s what POST requests are for.
So how do you trigger an actual retraction? Is it enough to add a :method option to link_to?
link_to "Retract", retract_bid_path(auction,bid), :method => :post
Not quite. Remember that in Listing 3.1 we defined the retract route as a get, so a POST will not be recognized by the routing system. The solution is to define an extra member route with post, like this:
resources :auctions do
resources :bids do
member do
get :retract
post :retract
end
end
end
If you’re handling more than one HTTP verb with a single action, you should switch to using a single match declaration and a :via option, like this:

Thanks to the flexibility of the routing system, we can tighten it up further using match with an :on option, like

which would result in a route like this (output from rake routes):
retract_auction_bid GET|POST
/auctions/:auction_id/bids/:id/retract(.:format)
{:controller => "bids", :action => "retract"}
3.8.2 Extra Collection Routes
You can use the same routing technique to add routes that conceptually apply to an entire collection of resources:
resources :auctions do
collection do
match :terminate, :via => [:get, :post]
end
end
In its shorter form:
![]()
This example will give you a terminate_auctions_path method, which will produce a URL mapping to the terminate action of the auctions controller. (A slightly bizarre example, perhaps, but the idea is that it would enable you to end all auctions at once.)
Thus you can fine-tune the routing behavior—even the RESTful routing behavior—of your application, so that you can arrange for special and specialized cases while still thinking in terms of resources.
3.8.3 Custom Action Names
Occasionally, you might want to deviate from the default naming convention for Rails RESTful routes. The :path_names option allows you to specify alternate name mappings. The example code shown changes the new and edit actions to Spanish-language equivalents.
resources :projects, :path_names => { :new => 'nuevo', :edit => 'cambiar'}
The URLs change (but the names of the generated helper methods do not).
new_report GET /reports/nuevo(.:format)
edit_report GET /reports/:id/cambiar(.:format)
3.8.4 Mapping to a Different Controller
You may use the :controller option to map a resource to a different controller than the one it would do so by default. This feature is occasionally useful for aliasing resources to a more natural controller name.
resources :photos, :controller => "images"
3.8.5 Routes for New Resources
The routing system has a neat syntax for specifying routes that only apply to new resources, ones that haven’t been saved yet. You declare extra routes inside of a nested new block, like this:
resources :reports do
new do
post :preview
end
end
The declaration above would result in the following route being defined.
preview_new_report POST /reports/new/preview(.:format)
{:action=>"preview", :controller=>"reports"}
Refer to your new route within a view form by altering the default :url.
= form_for(report, :url => preview_new_report_path) do |f|
...
= f.submit "Preview"
3.8.6 Considerations for Extra Routes
Referring to extra member and collection actions, David has been quoted as saying, “If you’re writing so many additional methods that the repetition is beginning to bug you, you should revisit your intentions. You’re probably not being as RESTful as you could be.”
The last sentence is key. Adding extra actions corrupts the elegance of your overall RESTful application design, because it leads you away from finding all of the resources lurking in your domain.
Keeping in mind that real applications are more complicated than code examples in a reference book, let’s see what would happen if we had to model retractions strictly using resources. Rather than tacking a retract action onto the BidsController, we might feel compelled to introduce a retraction resource, associated with bids, and write a RetractionController to handle it.
resources :bids do
resource :retraction
end
RetractionController could now be in charge of everything having to do with retraction activities, rather than having that functionality mixed into BidsController. And if you think about it, something as weighty as bid retraction would eventually accumulate quite a bit of logic. Some would call breaking it out into its own controller proper separation of concerns or even just good object-orientation.
3.9 Controller-Only Resources
The word resource has a substantive, noun-like flavor that puts one in mind of database tables and records. However, a REST resource does not have to map directly to an Active Record model. Resources are high-level abstractions of what’s available through your web application. Database operations just happen to be one of the ways that you store and retrieve the data you need to generate representations of resources.
A REST resource doesn’t necessarily have to map directly to a controller, either, at least not in theory. You could, if you wanted to, provide REST services whose public identifiers (URIs) did not match the names of your controllers at all.
What all of this adds up to is that you might have occasion to create a set of resource routes, and a matching controller, that don’t correspond to any model in your application at all. There’s nothing wrong with a full resource/controller/model stack where everything matches by name. But you may find cases where the resources you’re representing can be encapsulated in a controller but not a model.
An example in the auction application is the sessions controller. Assume a routes.rb file containing this line:
resource :session
It maps the URL /session to a SessionController as a singleton resource, yet there’s no Session model. (By the way, it’s properly defined as a singleton resource because from the user’s perspective there is only one session.)
Why go the RESTful style for authentication? If you think about it, user sessions can be created and destroyed. The creation of a session takes place when a user logs in; when the user logs out, the session is destroyed. The RESTful Rails practice of pairing a new action and view with a create action can be followed! The user login form can be the session-creating form, housed in the template file such as session/new.html.haml

When the form is submitted, the input is handled by the create method of the sessions controller:

Nothing is written to any database table in this action, but it’s worthy of the name create by virtue of the fact that it creates a session. Furthermore, if you did at some point decide that sessions should be stored in the database, you’d already have a nicely abstracted handling layer.
It pays to remain open-minded, then, about the possibility that CRUD as an action-naming philosophy and CRUD as actual database operations may sometimes occur independently of each other; and the possibility that the resource-handling facilities in Rails might usefully be associated with a controller that has no corresponding model. Creating a session on the server isn’t a REST-compliant practice, because REST mandates stateless transfers of representations of resources. But it’s a good illustration of why, and how, you might make design decisions involving routes and resources that don’t implicate the whole application stack.
Xavier says ...
Whether sessions are REST-compliant or not depends on the session storage.
What REST disallows is not the idea of application state in general, but rather the idea of client state stored in the server. REST demands that your requests are complete. For example, putting an auction_id in a hidden field of a form or in its action path is fine. There is state in that request that the edit action wants to pass to the update action, and you dumped it into the page, so the next request to update a bid carries all that is needed. That’s RESTful.
Now, using hidden fields and such is not the only way to do this. For example, there is no problem using a user_id cookie for authentication. Why? Because a cookie is part of a request. Therefore, I am pretty sure that cookie-based sessions are considered to be RESTful by the same principle. That kind of storage makes your requests self-contained and complete.
Sticking to CRUD-like action names is, in general, a good idea. As long as you’re doing lots of creating and destroying anyway, it’s easier to think of a user logging in as the creation of a session, than to come up with a whole new semantic category for it. Rather than the new concept of user logs in, just think of it as a new occurrence of the old concept, session gets created.
3.10 Different Representations of Resources
One of the precepts of REST is that the components in a REST-based system exchange representations of resources. The distinction between resources and their representations is vital.
As a client or consumer of REST services, you don’t actually retrieve a resource from a server; you retrieve representations of that resource. You also provide representations: A form submission, for example, sends the server a representation of a resource, together with a request—for example, PUT—that this representation be used as the basis for updating the resource. Representations are the exchange currency of resource management.
3.10.1 The respond_to Method
The ability to return different representations in RESTful Rails practice is based on the respond_to method in the controller, which, as you’ve seen in the previous chapter, allows you to return different responses depending on what the client wants. Moreover, when you create resource routes you automatically get URL recognition for URLs ending with a dot and a :format parameter.
For example, assume that you have resources :auctions in your routes file and some respond_to logic in the AuctionsController like

which will let you to connect to this URL: /auctions.xml
The resource routing will ensure that the index action gets executed. It will also recognize the .xml at the end of the route and interact with respond_to accordingly, returning the XML representation.
There is also a more concise way of handling this now using the respond_with method.

Here we’ve told our controller to respond to html, xml, and json so that each action will automatically return the appropriate content. When the request comes in, the responder would attempt to do the following given a .json extension on the URL:
• Attempt to render the associated view with a .json extension.
• If no view exists, call to_json on the object passed to responds_with.
• If the object does not respond to to_json, call to_format on it.
For nested and namespaced resources, simply pass all the objects to the respond_to method similar to the way you would generate a route.
respond_with(@user, :managed, @client)
Of course, all of this is URL recognition. What if you want to generate a URL ending in .xml?
3.10.2 Formatted Named Routes
Let’s say you want a link to the XML representation of a resource. You can achieve it by passing an extra argument to the RESTful named route:
link_to "XML version of this auction", auction_path(@auction, :xml)
This will generate the following HTML:
<a href="/auctions/1.xml">XML version of this auction</a>
When followed, this link will trigger the XML clause of the respond_to block in the show action of the auctions controller. The resulting XML may not look like much in a browser, but the named route is there if you want it.
The circuit is now complete: You can generate URLs that point to a specific response type, and you can honor requests for different types by using respond_to. All told, the routing system and the resource-routing facilities built on top of it give you quite a set of powerful, concise tools for differentiating among requests and, therefore, being able to serve up different representations.
3.11 The RESTful Rails Action Set
Rails REST facilities, ultimately, are about named routes and the controller actions to which they point. The more you use RESTful Rails, the more you get to know each of the seven RESTful actions. How they work across different controllers (and different applications) is of course somewhat different. Still, perhaps because there’s a finite number of them and their roles are fairly well-delineated, each of the seven tends to have fairly consistent properties and a characteristic feel to it.
We’re going to take a look at each of the seven actions, with examples and comments. You’ll encounter all of them again, particularly in Chapter 4, Working with Controllers, but here you’ll get some backstory and start to get a sense of the characteristic usage of them and issues and choices associated with them.
3.11.1 Index
Typically, an index action provides a representation of a plural (or collection) resource. However, to be clear, not all resource collections are mapped to the index action. Your default index representations will usually be generic, although admittedly that has a lot to do with your application-specific needs. But in general, the index action shows the world the most neutral representation possible. A very basic index action looks like

The associated view template will display information about each auction, with links to specific information about each one, and to profiles of the sellers.
You’ll certainly encounter situations where you want to display a representation of a collection in a restricted way. In our recurring example, users should be able to see a listing of all their bids, but may be you don’t want users seeing other people’s bids.
There are a couple of ways to do this. One way is to test for the presence of a logged-in user and decide what to show based on that. But that’s not going to work here. For one thing, the logged-in user might want to see the more public view. For another, the more dependence on server-side state we can eliminate or consolidate, the better.
So let’s try looking at the two bid lists, not as public and private versions of the same resource, but as different index resources. The difference can be reflected in the routing like:

We can now organize the bids controller in such a way that access is nicely layered, using filters only where necessary and eliminating conditional branching in the actions themselves:

There’s now a clear distinction between /bids and /auctions/1/bids/manage and the role that they play in your application.
On the named route side, we’ve now got bids_url and manage_auction_bids_url. We’ve thus preserved the public, stateless face of the /bids resource, and quarantined as much stateful behavior as possible into a discrete member resource, /auctions/1/bids/manage. Don’t fret if this mentality doesn’t come to you naturally. It’s part of the REST learning curve.
Lar says ...
If they are truly different resources, why not give them each their own controllers? Surely there will be other actions that need to be authorized and scoped to the current user.
3.11.2 Show
The RESTful show action is the singular flavor of a resource. That generally translates to a representation of information about one object, one member of a collection. Like index, show is triggered by a GET request.
A typical—one might say classic—show action looks like

You might want to differentiate between publicly available profiles, perhaps based on a different route, and the profile of the current user, which might include modification rights and perhaps different information.
As with index actions, it’s good to make your show actions as public as possible and offload the administrative and privileged views onto either a different controller or a different action.
3.11.3 Destroy
Destroy actions are good candidates for administrative safeguarding, though of course it depends on what you’re destroying. You might want something like this to protect the destroy action.
class ProductsController < ApplicationController
before_filter :admin_required, :only => :destroy
A typical destroy action might look like
def destroy
product.destroy
flash[:notice] = "Product deleted!"
redirect_to products_url
end
This approach might be reflected in a simple administrative interface like

That delete link appears depending on whether current user is an admin.
With Rails 3, the UJS (Unobtrusive JavaScript) API greatly simplifies the HTML emitted for a destroy action, using CSS selectors to bind JavaScript to (in this case) the “delete” link. See Chapter 12, Ajax on Rails, for much more information about how it works.
DELETE submissions are dangerous. Rails wants to make them as hard as possible to trigger accidentally—for instance, by a crawler or bot sending requests to your site. So when you specify the DELETE method, JavaScript that submits a form is bound to your “delete” link, along with a rel="nofollow" attribute on the link. Since bots don’t submit forms (and shouldn’t follow links marked “nofollow”), this gives a layer of protection to your code.
3.11.4 New and Create
As you’ve already seen, the new and create actions go together in RESTful Rails. A “new resource” is really just an entity waiting to be created. Accordingly, the new action customarily presents a form, and create creates a new record, based on the form input.
Let’s say you want a user to be able to create (that is, start) an auction. You’re going to need
- A
newaction, which will display a form - A
createaction, which will create a newAuctionobject based on the form input, and proceed to a view (showaction) of that auction.
The new action doesn’t have to do much. In fact, it has to do nothing. Like any empty action, it can even be left out. Rails will still figure out which view to render. However, your controller will need an auction helper method, like

If this technique is alien to you, don’t worry. We’ll describe it in detail in Section 10.1.5.
A simplistic new.html.haml template might look like Listing 3.2.
Listing 3.2. A New Auction Form

Once the information is filled out by a user, it’s time for the main event: the create action. Unlike new, this action has something to do.

3.11.5 Edit and Update
Like new and create, the edit and update actions go together: edit provides a form, and update processes the form input.
The form for editing a record appears similar to the form for creating one. (In fact, you can put much of it in a partial template and use it for both; that’s left as an exercise for the reader.)
The form_for method is smart enough to check whether the object you pass to it has been persisted or not. If it has, then it recognizes that you are doing an edit and specifies a PUT method on the form.
3.12 Conclusion
In this chapter, we tackled the tough subject of using REST principles to guide the design of our Rails applications, mainly as they apply to the routing system and controller actions. We learned how the foundation of RESTful Rails is the resources method in your routes file and how to use the numerous options available to make sure that you can structure your application exactly how it needs to be structured.
By necessity, we’ve already introduced many controller-related topics and code examples in our tour of the routing and REST features. In the next chapter, we’ll cover controller concepts and the Action Controller API in depth.