
Chapter 4. Working with Controllers
Remove all business logic from your controllers and put it in the model. (My) instructions are precise, but following them requires intuition and subtle reasoning.
—Nick Kallen
Like any computer program, your Rails application involves the flow of control from one part of your code to another. The flow of program control gets pretty complex with Rails applications. There are many bits and pieces in the framework, many of which execute each other. And part of the framework’s job is to figure out, on the fly, what your application files are called and what’s in them, which of course varies from one application to another.
The heart of it all, though, is pretty easy to identify: It’s the controller. When someone connects to your application, what they’re basically doing is asking the application to execute a controller action. Sure, there are many different flavors of how this can happen and edge cases where it doesn’t exactly happen at all. But if you know how controllers fit into the application life cycle, you can anchor everything else around that knowledge. That’s why we’re covering controllers before the rest of the Rails APIs.
Controllers are the C in MVC. They’re the first port of call, after the dispatcher, for the incoming request. They’re in charge of the flow of the program: They gather information and make it available to the views.
Controllers are also very closely linked to views, more closely than they’re linked to models. It’s possible to write the entire model layer of an application before you create a single controller, or to have different people working on the controller and model layers who never meet or talk to each other. However, views and controllers are more tightly coupled to one another. They share a lot of information, and the names you choose for your variables in the controller will have an effect on what you do in the view.
In this chapter, we’re going to look at what happens on the way to a controller action being executed, and what happens as a result. In the middle, we’ll take a long look at how controller classes themselves are set up, particularly in regard to the many different ways that we can render views. We’ll wrap up the chapter with a couple of additional topics related to controllers: filters and streaming.
4.1 Rack
Rack is a modular interface for handling web requests, written in Ruby, with support for many different web servers. It abstracts away the handling of HTTP requests and responses into a single, simple call method that can be used by anything from a plain Ruby script all the way to Rails itself.

An HTTP request invokes the call method and passes in a hash of environment variables, akin to the way that CGI works. The call method should return a three-element array consisting of the status, a hash of response headers, and finally, the body of the request.
As of Rails 2.3, request handling was moved to Rack and the concept of middleware was introduced. Classes that satisfy Rack’s call interface can be chained together as filters. Rack itself includes a number of useful filter classes that do things such as logging and exception handling.
Rails 3 was re-architected from the ground up to fully leverage Rack filters in a modular and extensible manner. A full explanation of Rails’ Rack underpinnings are outside the scope of this book, especially since Rack does not really play a part in day-to-day development of applications. However, it is essential Rails 3 knowledge to understand that much of Action Controller is implemented as Rack middleware modules. Want to see which Rack filters are enabled for your Rails 3 application? There’s a rake task for that!

What’s Active Record query caching have to do with serving requests anyway?

Ahh, it’s not that Active Record query caching has anything specifically to do with serving requests. It’s that Rails 3 is designed in such a way that different aspects of its behavior are introduced into the request call chain as individual Rack middleware components or filters.
4.1.1 Configuring Your Middleware Stack
Your application object allows you to access and manipulate the Rack middleware stack during initialization, via config.middleware like

Rack lobster
As I found out trying to experiment with the hilariously-named Rack::Lobster, your custom Rack middleware classes need to have an explicit initializer method, even if they don’t require runtime arguments.
The methods of config.middleware give you very fine-grained control over the order in which your middleware stack is configured. The args parameter is an optional hash of attributes to pass to the initializer method of your Rack filter.
config.middleware.insert_after(existing_middleware, new_middleware, args)
Adds the new middleware after the specified existing middleware in the middleware stack.
config.middleware.insert_before (existing_middleware, new_middleware, args)
Adds the new middleware before the specified existing middleware in the middleware stack.
config.middleware.delete(middleware)
Removes a specified middleware from the stack.
config.middleware.swap(existing_middleware, new_middleware, args)
Swaps a specified middleware from the stack with a new class.
config.middleware.use(new_middleware, args)
Takes a class reference as its parameter and just adds the desired middleware to the end of the middleware stack.
4.2 Action Dispatch: Where It All Begins
Controller and view code in Rails has always been part of its Action Pack framework. In Rails 3, dispatching of requests has been extracted into its own sub-component of Action Pack called Action Dispatch. It contains classes that interface the rest of the controller system to Rack.
4.2.1 Request Handling
The entry point to a request is an instance of ActionDispatch::Routing::RouteSet, the object on which you can call draw at the top of config/routes.rb.
The route set chooses the rule that matches, and calls its Rack endpoint. So a route like
match 'foo', :to => 'foo#index'
has a dispatcher instance associated to it, whose call method ends up executing
FooController.action(:index).call
As covered in Section 2.2.9 “Routes as Rack Endpoints”, the route set can call any other type of Rack endpoint, like a Sinatra app, a redirect macro, or a bare lambda. In those cases, no dispatcher is involved.
All of this happens quickly, behind the scenes. It’s unlikely that you would ever need to dig into the source code of Action Dispatch; it’s the sort of thing that you can take for granted to just work. However, to really understand the Rails way, it is important to know what’s going on with the dispatcher. In particular, it’s important to remember that the various parts of your application are just bits (sometimes long bits) of Ruby code, and that they’re getting loaded into a running Ruby interpreter.
4.2.2 Getting Intimate with the Dispatcher
Just for the purpose of learning, let’s trigger the Rails dispatching mechanism manually. We’ll do this little exercise from the ground up, starting with a new Rails application:
$ rails new dispatch_me
Now, create a single controller, with an index action:
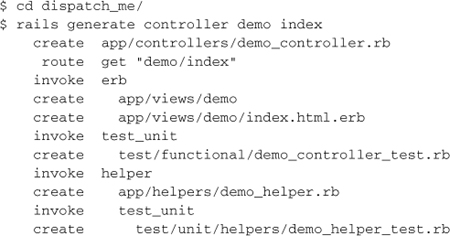
If you take a look at app/controllers/demo_controller.rb, you’ll see that it has an index action:
class DemoController < ApplicationController
def index
end
end
There’s also a view template file, app/views/demo/index.html.erb with some placeholder language. Just to see things more clearly, let’s replace it with something we will definitely recognize when we see it again. Replace the contents of index.html.erb with
Hello!
Not much of a design accomplishment, but it will do the trick.
Now that we’ve got a set of dominos lined up, it’s just a matter of pushing over the first one: the dispatcher. To do that, start by firing up the Rails console from your Rails application directory.
$ rails console
Loading development environment.
>>
There are some variables from the web server that Rack expects to use for request processing. Since we’re going to be invoking the dispatcher manually, we have to set those variables like this in the console (output ommited for brevity):
>> env = {}
>> env['REQUEST_METHOD'] = 'GET'
>> env['PATH_INFO'] = '/demo/index'
>> env['rack.input'] = StringIO.new
We’re now ready to fool the dispatcher into thinking it’s getting a request. Actually, it is getting a request. It’s just that it’s coming from someone sitting at the console, rather than from a web server:
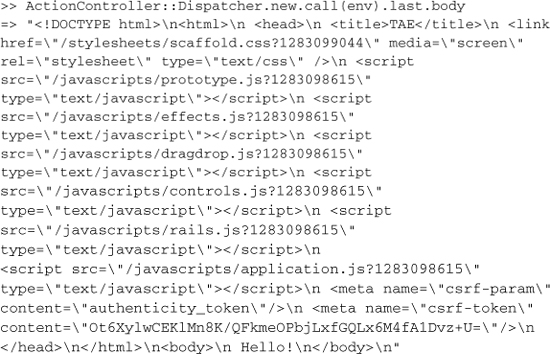
If you want to see everything contained in the ActionDispatch::Response object returned from call then try the following code:
>> y ActionController::Dispatcher.new.last.call(env)
The handy y method formats its argument as a yaml string, making it a lot easier to understand. We won’t reproduce the output here because it’s huge.
So, we’ve executed the call method of a Dispatcher object and as a result, the index action got executed and the index template (such as it is) got rendered and the results of the rendering got wrapped in some HTTP headers and returned.
Just think: If you were a web server, rather than a human, and you had just done the same thing, you could now return that document, headers and “Hello!” and all, to a client.
You can follow the trail of bread crumbs even further by diving into the Rails source code, but for purposes of understanding the chain of events in a Rails request, and the role of the controller, the peek under the hood we’ve just done is sufficient.
Tim says ...
Note that if you give Rack a path that resolves to a static file, it will be served directly from the web server without involving the Rails stack. As a result, the object returned by the dispatcher for a static file is different from what you might expect.

4.3 Render unto View ...
The goal of the typical controller action is to render a view template—that is, to fill out the template and hand the results, usually an HTML document, back to the server for delivery to the client. Oddly—at least it might strike you as a bit odd, though not illogical—you don’t actually need to define a controller action, as long as you’ve got a template that matches the action name.
You can try this out in under-the-hood mode. Go into app/controller/demo_controller.rb, and delete the index action so that the file will look empty, like this:
class DemoController < ApplicationController
end
Don’t delete app/views/demo/index.html.haml, and then try the console exercise (Dispatcher.dispatch and all that) again. You’ll see the same result.
By the way, make sure you reload the console when you make changes—it doesn’t react to changes in source code automatically. The easiest way to reload the console is simply to type reload!. But be aware that any existing instances of Active Record objects that you’re holding on to will also need to be reloaded (using their individual reload methods). Sometimes it’s simpler to just exit the console and start it up again.
4.3.1 When in Doubt, Render
Rails knows that when it gets a request for the index action of the demo controller, what really matters is handing something back to the server. So if there’s no index action in the controller file, Rails shrugs and says, “Well, let’s just assume that if there were an index action, it would be empty anyway, and I’d just render index.html.haml. So that’s what I’ll do.”
You can learn something from an empty controller action, though. Let’s go back to this version of the demo controller:
class DemoController < ApplicationController
def index
end
end
What you learn from seeing the empty action is that, at the end of every controller action, if nothing else is specified, the default behavior is to render the template whose name matches the name of the controller and action, which in this case means app/views/demo/index.html.haml.
In other words, every controller action has an implicit render command in it. And render is a real method. You could write the preceding example like this:
def index
render "demo/index"
end
You don’t have to, though, because it’s assumed that it’s what you want, and that is part of what Rails people are talking about when they discuss convention over configuration. Don’t force the developer to add code to accomplish something that can be assumed to be a certain way.
The render command, however, does more than just provide a way of telling Rails to do what it was going to do anyway.
4.3.2 Explicit Rendering
Rendering a template is like putting on a shirt: If you don’t like the first one you find in your closet—the default, so to speak—you can reach for another one and put it on instead.
If a controller action doesn’t want to render its default template, it can render a different one by calling the render method explicitly. Any template file in the app/views directory tree is available. (Actually, that’s not exactly true. Any template on the whole system is available!) But why would you want your controller action to render a template other than its default? There are several reasons, and by looking at some of them, we can cover all of the handy features of the controller’s render method.
4.3.3 Rendering Another Action’s Template
A common reason for rendering an entirely different template is to redisplay a form, when it gets submitted with invalid data and needs correction. In such circumstances, the usual web strategy is to redisplay the form with the submitted data, and trigger the simultaneous display of some error information, so that the user can correct the form and resubmit.
The reason that process involves rendering another template is that the action that processes the form and the action that displays the form may be—and often are—different from each other. Therefore, the action that processes the form needs a way to redisplay the original (form) template, instead of treating the form submission as successful and moving on to whatever the next screen might be.
Wow, that was a mouthful of an explanation. Here’s a practical example:

On failure, that is, if @event.save does not return true, we render the “new” template. Assuming new.html.haml has been written correctly, this will automatically include the display of error information embedded in the new (but unsaved) Event object. You’ve already seen this in some examples, as f.error_messages.
Note that the template itself doesn’t “know” that it has been rendered by the create action rather than the new action. It just does its job: It fills out and expands and interpolates, based on the instructions it contains and the data (in this case, @event) that the controller has passed to it.
4.3.4 Rendering a Different Template Altogether
In a similar fashion, if you are rendering a template for a different action, it is possible to render any template in your application by calling render with a string pointing to the desired template file. The render method is very robust in its ability to interpret which template you’re trying to refer to.
render :template => '/products/index.html.haml'
A couple of notes: It’s not necessary to pass a hash with :template, because it’s the default option. Also, in our testing, all of the following permutations worked identically when called from ProductsController:

The :template option only works with a path relative to the template root (app/views, unless you changed it, which would be extremely unusual).
Tim says ...
Use only enough to disambiguate. The content type defaults to that of the request and if you have two templates that differ only by template language, you’re Doing It Wrong.
4.3.5 Rendering a Partial Template
Another option is to render a partial template (usually referred to simply as a partial). Usage of partial templates allows you to organize your template code into small files. Partials can also help you to avoid clutter and encourage you to break your template code up into reusable modules.
There are a few ways to trigger partial rendering. The first, and most obvious, is using the :partial option to explicitly specify a partial template. Rails has a convention of prefixing partial template file names with an underscore character, but you never include the underscore when referring to partials.
render :partial => 'product' # renders
app/views/products/_product.html.haml
Leaving the underscore off of the partial name applies, even if you’re referring to a partial in a different directory from the controller that you’re currently in!
render :partial => 'shared/product' # renders
app/views/shared/_product.html.haml
The second way to trigger partial rendering depends on convention. If you pass render :partial an object, Rails will use its class name to find a partial to render. You can even omit the :partial option, like in the following example code.
render :partial => @product
render @product
render 'product'
All three lines render the app/views/products/_product.html.haml template.
Partial rendering from a controller is mostly used in conjunction with Ajax calls that need to dynamically update segments of an already displayed page. The technique, along with generic use of partials in views, is covered in greater detail in Chapter 10, Action View.
4.3.6 Rendering Inline Template Code
Occasionally, you need to send the browser the result of translating a snippet of template code, too small to merit its own partial. I admit that this practice is contentious, because it is a flagrant violation of proper separation of concerns between the MVC layers.
Rails treats the inline code exactly as if it were a view template. The default type of view template processing is ERb, but passing an additional :type option allows you to choose Haml.
render :inline => "%span.foo #{@foo.name}", :type => "haml"
Courtenay says ...
If you were one of my employees, I’d reprimand you for using view code in the controller, even if it is only one line. Keep your view-related code in the views!
4.3.7 Rendering Text
What if you simply need to send plain text back to the browser, particularly when responding to Ajax and certain types of web service requests?
render :text => 'Submission accepted'
Unfortunately, if you don’t pass an additional :content_type option, Rails will default the response MIME type to text/html, rather than text/plain. The solution is to be explicit about what you want.
render :text => 'Submission accepted', :content_type => 'text/plain'
4.3.8 Rendering Other Types of Structured Data
The render command also accepts a series of (convenience) options for returning structured data such as JSON or XML. The content-type of the response will be set appropriately and additional options apply.1
:json
JSON2 is a small subset of JavaScript selected for its usability as a lightweight data-interchange format. It is mostly used as a way of sending data down to JavaScript code running in a rich web application via Ajax calls. Active Record has built-in support for conversion to JSON, which makes Rails an ideal platform for serving up JSON data, as in the following example:
render :json => @record
As long as the parameter responds to to_json, Rails will call it for you, which means you don’t have to call it yourself with ActiveRecord objects.
Any additional options passed to render :json are also included in the invocation of to_json.
render :json => @projects, :include => :tasks
Additionally, if you’re doing JSONP, you can supply the name of a callback function to be invoked in the browser when it gets your response. Just add a :callback option with the name of a valid JavaScript method.
render :json => @record, :callback => 'updateRecordsDisplay'
:xml
Active Record also has built-in support for conversion to XML, as in the following example:
render :xml => @record
As long as the parameter responds to to_xml, Rails will call it for you, which means you don’t have to call it yourself with ActiveRecord objects.
Any additional options passed to render :xml are also included in the invocation of to_xml.
render :xml => @projects, :include => :tasks
We cover XML-related topics like this one extensively in Chapter 15, Active Resource.
4.3.9 Rendering Nothing
On rare occasions, you don’t want to render anything at all. (To avoid a bug in Safari, rendering nothing actually means sending a single space character back to the browser.)
render :nothing => true, :status => 401 # Unauthorized
It’s worth noting that, as illustrated in this snippet, render :nothing => true is often used in conjunction with an HTTP status code.
4.3.10 Rendering Options
Most calls to the render method accept additional options. Here they are in alphabetical order.
:content_type
All content flying around the web is associated with a MIME type.3 For instance, HTML content is labeled with a content-type of text/html. However, there are occasions where you want to send the client something other than HTML. Rails doesn’t validate the format of the MIME identifier you pass to the :content_type option, so make sure it is valid.
:layout
By default, Rails has conventions regarding the layout template it chooses to wrap your response in, and those conventions are covered in detail in Chapter 10, Action View. The :layout option allows you to specify whether you want a layout template to be rendered if you pass it a boolean value, or the name of a layout template, if you want to deviate from the default.
![]()
:status
The HTTP protocol includes many standard status codes4 indicating a variety of conditions in response to a client’s request. Rails will automatically use the appropriate status for most common cases, such as 200 OK for a successful request.
The theory and techniques involved in properly using the full range of HTTP status codes would require a dedicated chapter, perhaps an entire book. For your convenience, Table 4.1 demonstrates some codes that I’ve occasionally found useful in my day-to-day Rails programming.
Table 4.1. Common HTTP status codes




4.4 Additional Layout Options
You can specify layout options at the controller class level if you want to reuse layouts for multiple actions.

The layout method can accept either a String, Symbol, or boolean, with a hash of arguments after.
• StringDetermines the template name to use.
• SymbolCall the method with this name, which is expected to return a string with a template name.
• trueRaises an argument error.
• falseDo not use a layout.
The optional arguments are either :only or :except and expect an array of action names that should or should not apply to the layout being specified.
4.5 Redirecting
The life cycle of a Rails application is divided into requests. Rendering a template, whether the default one or an alternate one—or, for that matter, rendering a partial or some text or anything—is the final step in handling a request. Redirecting, however, means terminating the current request and asking the client to initiate a new one.
Look again at the example of the form-handling create method:

If the save operation succeeds, we store a message in the flash hash and redirect_to a completely new action. In this case, it’s the index action. The logic here is that if the new Event record gets saved, the next order of business is to take the user back to the top-level view.
The main reason to redirect rather than just render a template after creating or editing a resource (really a POST action) has to do with browser reload behavior. If you didn’t redirect, the user would be prompted to re-submit the form if they hit the back button or reload.
4.5.1 The redirect_to Method
The redirect_to method takes two parameters:
redirect_to(target, response_status = {})
The target parameter takes one of several forms.
HashThe URL will be generated by calling url_for with the argument provided.
redirect_to :action => "show", :id => 5
Active Record objectThe URL will be generated by calling url_for with the object provided, which should generate a named URL for that record.
redirect_to post
String starting with protocol like http://Used directly as the target url for redirection.
redirect_to "http://www.rubyonrails.org"
redirect_to articles_url
String not containing a protocolThe current protocol and host is prepended to the argument and used for redirection.
redirect_to "/"
redirect_to articles_path
:backBack to the page that issued the request. Useful for forms that are triggered from multiple places. Short-hand for redirect_to(request.env["HTTP_REFERER"]) When using redirect_to :back, if there is no referrer set, a RedirectBackError will be raised. You may specify some fallback behavior for this case by rescuing RedirectBackError.
Sebastian says ...
Which redirect is the right one? When you use Rails’s redirect_to method, you tell the user agent (i.e., the browser) to perform a new request for a different URL. That response can mean different things, and it’s why modern HTTP has four different status codes for redirection. The old HTTP 1.0 had two codes: 301 aka Moved Permanently and 302 aka Moved Temporarily. A permanent redirect meant that the user agent should forget about the old URL and use the new one from now on, updating any references it might have kept (i.e., a bookmark or in the case of Google, its search databases). A temporary redirect was a one-time only affair. The original URL was still valid, but for this particular request the user agent should fetch a new resource from the redirection URL.
But there was a problem: If the original request had been a POST, what method should be used for the redirected request? For permanent redirects it was safe to assume the new request should be a GET, since that was the case in all usage scenarios. But temporary redirects were used both for redirecting to a view of a resource that had just been modified in the original POST request (which happens to be the most common usage pattern), and also for redirecting the entire original POST request to a new URL that would take care of it.
HTTP 1.1 solved this problem with the introduction of two new status codes: 303 meaning See Other and 307 meaning Temporary Redirect. A 303 redirect would tell the user agent to perform a GET request, regardless of what the original verb was, whereas a 307 would always use the same method used for the original request. These days, most browsers handle 302 redirects the same way as 303, with a GET request, which is the argument used by the Rails Core team to keep using 302 in redirect_to. A 303 status would be the better alternative, because it leaves no room for interpretation (or confusion), but I guess nobody has found it annoying enough to push for a patch.
If you ever need a 307 redirect, say, to continue processing a POST request in a different action, you can always accomplish your own custom redirect by assigning a path to response.header["Location"] and then rendering with render : status => 307.
Redirection happens as a “302 Moved” header unless otherwise specified. The response_status parameter takes a hash of arguments. The code can be specified by name or number, as in the following examples:

It is also possible to assign a flash message as part of the redirection. There are two special accessors for commonly used the flash names alert and notice as well as a general purpose flash bucket.

Courtenay says ...
Remember that redirect and render statements don’t magically halt execution of your controller action method. To prevent DoubleRenderError, consider explicitly calling return after redirect_to or render like this:

4.6 Controller/View Communication
When a view template is rendered, it generally uses data that the controller has pulled from the database. In other words, the controller gets what it needs from the model layer, and hands it off to the view.
The way Rails implements controller-to-view data handoffs is through instance variables. Typically, a controller action initializes one or more instance variables. Those instance variables can then be used by the view.
There’s a bit of irony (and possible confusion for newcomers) in the choice of instance variables to share data between controllers and views. The main reason that instance variables exist is so that objects (whether Controller objects, String objects, and so on) can hold on to data that they don’t share with other objects. When your controller action is executed, everything is happening in the context of a controller object—an instance of, say, DemoController or EventController. Context includes the fact that every instance variable in the code belongs to the controller instance.
When the view template is rendered, the context is that of a different object, an instance of ActionView::Base. That instance has its own instance variables, and does not have access to those of the controller object.
So instance variables, on the face of it, are about the worst choice for a way for two objects to share data. However, it’s possible to make it happen—or make it appear to happen. What Rails does is to loop through the controller object’s variables and, for each one, create an instance variable for the view object, with the same name and containing the same data.
It’s kind of labor-intensive, for the framework: It’s like copying over a grocery list by hand. But the end result is that things are easier for you, the programmer. If you’re a Ruby purist, you might wince a little bit at the thought of instance variables serving to connect objects, rather than separate them. On the other hand, being a Ruby purist should also include understanding the fact that you can do lots of different things in Ruby—such as copying instance variables in a loop. So there’s nothing really un-Ruby-like about it. And it does provide a seamless connection, from the programmer’s perspective, between a controller and the template it’s rendering.
Stephen says ...
I’m a cranky old man, and dammit, Rails is wrong, wrong, wrong. Using instance variables to share data with the view sucks. If you want to see how my Decent Exposure library helps you avoid this horrible practice, skip ahead to Section 10.1.5.
4.7 Filters
Filters enable controllers to run shared pre and post processing code for its actions. These filters can be used to do authentication, caching, or auditing before the intended action is performed. Filter declarations are macro style class methods, that is, they appear at the top of your controller method, inside the class context, before method definitions. We also leave off the parentheses around the method arguments, to emphasize their declarative nature, like this:
before_filter :require_authentication
As with many other macro-style methods in Rails, you can pass as many symbols as you want to the filter method:
before_filter :security_scan, :audit, :compress
Or you can break them out into separate lines, like this:
before_filter :security_scan
before_filter :audit
before_filter :compress
In contrast to the somewhat similar callback methods of Active Record, you can’t implement a filter method on a controller by adding a method named before_filter or after_filter.
You should make your filter methods protected or private; otherwise, they might be callable as public actions on your controller (via the default route).
Tim says ...
In addition to protected and private, one can declare a method should never be dispatched with the more intention-revealing hide_action.
Importantly, filters have access to request, response, and all the instance variables set by other filters in the chain or by the action (in the case of after filters). Filters can set instance variables to be used by the requested action, and often do so.
4.7.1 Filter Inheritance
Controller inheritance hierarchies share filters downward. Your average Rails application has an ApplicationController from which all other controllers inherit, so if you wanted to add filters that are always run no matter what, that would be the place to do so.
class ApplicationController < ActionController::Base
after_filter :compress
Subclasses can also add and/or skip already defined filters without affecting the superclass. For example, consider the two related classes in Listing 4.1, and how they interact.
Listing 4.1. A pair of cooperating before filters

Any actions performed on BankController (or any of its subclasses) will cause the audit method to be called before the requested action is executed. On the VaultController, first the audit method is called, followed by verify_credentials, because that’s the order in which the filters were specified. (Filters are executed in the class context where they’re declared, and the BankController has to be loaded before VaultController, since it’s the parent class.)
If the audit method happens to call render or redirect_to for whatever reason, verify_credentials and the requested action are never called. This is called halting the filter chain.
4.7.2 Filter Types
A filter can take one of three forms: method reference (symbol), external class, or block. The first is by far the most common and works by referencing a protected method somewhere in the inheritance hierarchy of the controller. In the bank example in Listing 2.1, both BankController and VaultController use this form.
Filter Classes
Using an external class makes for more easily reused generic filters, such as output compression. External filter classes are implemented by having a static filter method on any class and then passing this class to the filter method, as in Listing 4.2. The name of the class method should match the type of filter desired (e.g., before, after, around).
Listing 4.2. An output compression filter

The method of the Filter class is passed the controller instance it is filtering. It gets full access to the controller and can manipulate it as it sees fit. The fact that it gets an instance of the controller to play with also makes it seem like feature envy, and frankly, I haven’t had much use for this technique.
Inline Method
The inline method (using a block parameter to the filter method) can be used to quickly do something small that doesn’t require a lot of explanation or just as a quick test.

The block is executed in the context of the controller instance, using instance_eval. This means that the block has access to both the request and response objects complete with convenience methods for params, session, template, and assigns.
4.7.3 Filter Chain Ordering
Using before_filter and after_filter appends the specified filters to the existing chain. That’s usually just fine, but sometimes you care more about the order in which the filters are executed. When that’s the case, you can use prepend_before_filter and prepend_after_filter. Filters added by these methods will be put at the beginning of their respective chain and executed before the rest, like the example in Listing 4.3.
Listing 4.3. An example of prepending before filters

The filter chain for the CheckoutController is now :ensure_items_in_cart, :ensure_items_in_stock, :verify_open_shop. So if either of the ensure filters halts execution, we’ll never get around to seeing if the shop is open.
You may pass multiple filter arguments of each type as well as a filter block. If a block is given, it is treated as the last argument.
4.7.4 Around Filters
Around filters wrap an action, executing code both before and after the action that they wrap. They may be declared as method references, blocks, or objects with an around class method.
To use a method as an around_filter, pass a symbol naming the Ruby method. Use yield within the method to run the action.
For example, Listing 4.4 has an around filter that logs exceptions (not that you need to do anything like this in your application; it’s just an example).
Listing 4.4. An around filter to log exceptions

To use a block as an around_filter, pass a block taking as args both the controller and the action parameters. You can’t call yield from blocks in Ruby, so explicitly invoke call on the action parameter:

Tim says ...
Since processing of filter blocks is done with instance_eval, you don’t actually have to use the controller parameter in Rails 3. It’s there for backward-compatibility reasons.
To use a filter object with around_filter, pass an object responding to :around. With a filter method, yield to the block like this:

4.7.5 Filter Chain Skipping
Declaring a filter on a base class conveniently applies to its subclasses, but sometimes a subclass should skip some of the filters it inherits from a superclass:

4.7.6 Filter Conditions
Filters may be limited to specific actions by declaring the actions to include or exclude, using :only or :except options. Both options accept single actions (like :only => :index) or arrays of actions (:except => [:foo, :bar]).

4.7.7 Filter Chain Halting
The before_filter and around_filter methods may halt the request before the body of a controller action method is run. This is useful, for example, to deny access to unauthenticated users. As mentioned earlier, all you have to do to halt the before filter chain is call render or redirect_to. After filters will not be executed if the before filter chain is halted.
Around filters halt the request unless the action block is called. If an around filter returns before yielding, it is effectively halting the chain and any after filters will not be run.
4.8 Verification
This official Rails verification plugin5 provides a class-level method for specifying that certain actions are guarded against being called without certain prerequisites being met. It is essentially a special kind of before_filter.
An action may be guarded against being invoked without certain request parameters being set or without certain session values existing. When a verification is violated, values may be inserted into the flash and a redirection triggered. If no specific action is configured, verification failure will in a 400 Bad Request response.
Note that these verifications are apart from the business rules expressed in your models. They do not examine the content of the session or the parameters nor do they replace model validations.
4.8.1 Example Usage
The following example prevents the updates action from being invoked unless the privileges key is present in params. The request will be redirected to the settings action if the verification fails.

4.8.2 Options
The following options are valid parameters to the verify method.
:paramsA single key or an array of keys that must be present in the params hash in order for the action(s) to be safely called.
:sessionA single key or an array of keys that must be present in the session in order for the action(s) to be safely called.
:flashA single key or an array of keys that must be present in the flash in order for the action(s) to be safely called.
:methodA single key or an array of keys that must match the current request method in order for the action(s) to be safely called. Valid keys are symbols like :get and :post.
:xhrSet to true or false to ensure that the request is coming from an Ajax call or not.
:add_flashA hash of name/value pairs that should be merged into the session,Äôs flash if verification fails.
:add_headersA hash of name/value pairs that should be merged into the response,Äôs headers hash if verification fails.
:redirect_toThe parameters to be used when redirecting if verfication fails. You can redirect either to a named route or to the action in some controller.
:renderThe render parameters to be used if verification fails.
:onlyOnly apply this verification to the actions specified in the array. (Single value permitted).
:exceptDo not apply this verification to the actions specified in the array (Single value permitted).
4.9 Streaming
Rails has built-in support for streaming binary content back to the browser, as opposed to its normal duties rendering view templates.
4.9.1 Via render :text => proc
The :text option of the render method optionally accepts a Proc object, which can be used to stream on-the-fly generated data to the browser or control page generation on a fine-grained basis. The latter should generally be avoided unless you know exactly what you’re doing, as it violates the separation between code and content.
Two arguments are passed to the proc you supply, a response object and an output object. The response object is equivalent to the what you’d expect in the context of the controller, and can be used to control various things in the HTTP response, such as the Content-Type header. The output object is an writable IO-like object, so one can call write and flush on it.
The following example demonstrates how one can stream a large amount of on-the-fly generated data to the browser:

Rails also supports sending buffers and files with two methods in the ActionController::Streaming module: send_data and send_file.
4.9.2 send_data(data, options = {})
The send_data method allows you to send textual or binary data in a buffer to the user as a named file. You can set options that affect the content type and apparent filename, and alter whether an attempt is made to display the data inline with other content in the browser or the user is prompted to download it as an attachment.
Options
The send_data method has the following options:
:filenameSuggests a filename for the browser to use.
:typeSpecifies an HTTP content type. Defaults to 'application/octet-stream'.
:dispositionSpecifies whether the file will be shown inline or downloaded. Valid values are inline and attachment (default).
statusSpecifies the status code to send with the response. Defaults to '200 OK'.
Usage Examples
Creating a download of a dynamically generated tarball:
send_data generate_tgz('dir'), :filename => 'dir.tgz'
Sending a dynamic image to the browser, like for instance a captcha system:

4.9.3 send_file(path, options = {})
The send_file method sends an existing file down to the client using Rack::Sendfile middleware, which intercepts the response and replaces it with a webserver specific X-Sendfile header. The web server then becomes responsible for writing the file contents to the client instead of Rails. This can dramatically reduce the amount of work accomplished in Ruby and takes advantage of the web servers optimized file delivery code.6
Options
Here are the options available for send_file:
:filename suggests a filename for the browser to use. Defaults to File.basename (path)
:type specifies an HTTP content type. Defaults to 'application/octet-stream'.
:disposition specifies whether the file will be shown inline or downloaded. Valid values are 'inline' and 'attachment' (default).
:status specifies the status code to send with the response. Defaults to '200 OK'.
:url based filename should be set to true if you want the browser to guess the filename from the URL, which is necessary for i18n filenames on certain browsers (setting :filename overrides this option).
There’s also a lot more to read about Content-* HTTP headers7 if you’d like to provide the user with additional information that Rails doesn’t natively support (such as Content-Description).
Security Considerations
Note that the send_file method can be used to read any file accessible to the user running the Rails server process, so be extremely careful to sanitize8 the path parameter if it’s in any way coming from an untrusted users.
If you want a quick example, try the following controller code:
class FileController < ActionController::Base
def download
send_file(params[:path])
end
end
Give it a route
match 'file/download' => 'file#download'
then fire up your server and request any file on your system:
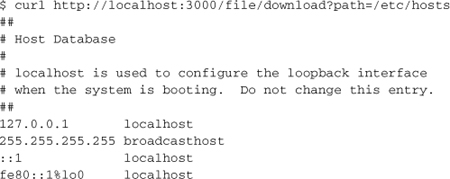
Be aware that your sent file may be cached by proxies and browsers. The Pragma and Cache-Control headers declare how the file may be cached by intermediaries. They default to require clients to validate with the server before releasing cached responses.9
Usage Examples
Here’s the simplest example, just a simple zip file download:
send_file '/path/to.zip'
Courtenay says ...
There are few legitimate reasons to serve static files through Rails. Unless you are protecting content, I strongly recommend you cache the file after sending it. There are a few ways to do this. Since a correctly configured web server will serve files in public/ and bypass rails, the easiest is to just copy the newly generated file to the public directory after sending it:
![]()
All subsequent views of this resource will be served by the web server. Alternatively, you can try using the caches_page directive, which will automatically do something similar for you. (Caching is covered comprehensively in Chapter 17.)
Sending a JPG to be displayed inline requires specification of the MIME content-type:
send_file '/path/to.jpg',
:type => 'image/jpeg',
:disposition => 'inline'
This will show a 404 HTML page in the browser. We append a charset declaration to the MIME type information:
send_file '/path/to/404.html,
:type => 'text/html; charset=utf-8',
:status => 404
How about streaming an FLV file to a browser-based Flash video player?
send_file @video_file.path,
:filename => video_file.title + '.flv',
:type => 'video/x-flv',
:disposition => 'inline'
Regardless of how you do it, you may wonder why you would need a mechanism to send files to the browser anyway, since it already has one built in—requesting files from the public directory. Well, often a web application will front files that need to be protected from public access.10 (Practically every porn site in existence!)
4.10 Conclusion
In this chapter, we covered some concepts at the very core of how Rails works: the dispatcher and how controllers render views. Importantly, we covered the use of controller action filters, which you will use constantly, for all sorts of purposes. The Action Controller API is fundamental knowledge, which you need to understand well along your way to becoming an expert Rails programmer.
Moving on, we’ll leave Action Pack and head over to the other major component API of Rails: Active Record.