
Chapter 2. Search Service
Given a business problem, the first step is to find relevant datasets (tables, views, schema, files, streams, events) and artifacts (metrics, dashboards, models, ETLs, ad-hoc queries) that can be used for developing ML models, dashboards, and other insights.
The complexity of data discovery arises due to the difficulty of knowledge scaling within the organization. Data teams typically start small with tribal knowledge that is easily accessible and reliable. As data grows and teams scale, silos are built across business lines leading to no single source of truth. The number of iterations required in the search process has a negative multiplicative effect on the overall time to insights. And though locating relevant datasets and assets becomes difficult across the silos, determining their quality and reliability is often an even bigger pain point. For instance, if the model is built using a table that is not populated correctly or has bugs in its data pipelines, the resulting model will be incorrect and unreliable.
A search service simplifies the discovery of datasets and artifacts. With a search service, data users express what they are looking for using keywords, wildcard searches, business terminology, and so on. Under the hood the service does the heavy lifting of discovering sources, indexing datasets and artifacts, ranking results, ensuring access governance, and managing continuous change. Data users get a list of datasets and artifacts that are most relevant to the input search query. The success criteria for such a service is reducing the time to find. Speeding up time to find significantly improves time to insights as data users are able to rapidly search and iterate with different datasets and artifacts.
Journey Map Context
The need to find datasets and artifacts is a starting point in the data scientist journey map. This section discusses the key scenarios in the journey map for the search service.
Feasibility Analysis of Business Problem
Given a business problem, the first step in the discovery phase is to determine feasibility with respect to availability of relevant datasets. The datasets can be in one of the following availability states:
Data does not exist and requires the application to be instrumented
Data is available in the source systems but is not being aggregated in the data lake
Data is available and is already being used by other artifacts.
Feasibility analysis provides an early ballpark for the overall time to insightand is key for better project planning. The gaps discovered in data availability are used as requirements for the data collection phase.
Selecting relevant datasets for data prep
This is a key scenario for the search service with the goal to shortlist one or more datasets that can be potentially used for the next phases of the overall journey map. Selecting relevant datasets for data prep is an iterative process involving searching for datasets using keywords, sampling search results, and selecting deeper analysis in the meaning and lineage of data attributes. With well-curated data, this scenario is easier to accomplish. Often the business definitions and descriptions are not updated, making identifying the right datasets difficult. A common scenario is the existence of multiple sources of truth where a given dataset can be present in one or more data silos with a different meaning. If existing artifacts are already using the dataset, that is a good indicator of the dataset quality.
Re-using existing artifacts for prototyping
Instead of starting from scratch, the goal of this phase is to find any building blocks that can be re-used. These might include data pipelines, dashboards, models, queries, and so on. A few common scenarios typically arise:
dashboard already exists for a single geographic location that can be reused by parameterizing geography and other inputs
Extending an existing ML models with additional features to solve the business problem
Leveraging standardized business metrics generated by hardened data pipelines
Re-using exploratory queries shared in notebooks.
Minimizing Time to Find
Time to find is the total time required to iteratively shortlist relevant datasets and artifacts. Given the complexity of the discovery process, teams often reinvent the wheel resulting in clones of data pipelines, dashboards, and models within the organization. In addition to causing wasted effort, reinventing results in longer time to insights. Today, time to find is spent on the three activities discussed in this section. The goal of the search service is to minimize the time spent in each activity.
Indexing of datasets and artifacts
Indexing involves two aspects:
Locating sources of datasets and artifacts.
Probing these sources to aggregate details such as schema and metadata properties.
Both these aspects are time consuming. Locating datasets and artifacts across silos is an ad-hoc process today -- tribal knowledge in the form of cheat-sheets, wikis, anecdotal experiences, and so on is used to get information about datasets and artifacts. Tribal information is hit-or-miss and not always correct or updated.
Probing sources for additional metadata such as schema, lineage, execution stats, and so on requires APIs or CLIs specific to the source technology. There is no standardization to extract this information irrespective of the underlying technology. Data users need to work with source owners and tribal knowledge to aggregate the meaning of column names, data types, and other details. Similarly, understanding artifacts such as data pipeline code requires analysis of the query logic and how it can be reused. Given the diversity of technologies, representing the details in a common searchable model is a significant challenge.
Indexing is an ongoing process as new applications and artifacts are continuously being developed. Existing datasets and artifacts are also continually evolving. Being able to update the results and keeping up with the changes is time consuming.
Ranking results
Today, a typical search ranking process starts by manually searching data stores, catalogs, git repos, dashboards, and so on. The search involves reaching out on Slack groups, wikis, or brown bag sessions to gather tribal knowledge. Ranking results for the next phases of the analysis is time-consuming due to the following ground realities:
Tables do not have clear names or a well-defined schema.
Existence of graveyard datasets and artifacts that are not actively being used or managed.
Attributes within the table are not appropriately named.
Schema has not evolved in sync with how the business has evolved.
Curation and best practices for schema design are not being followed. A common heuristic, or shortcut, is to only look at popular assets that are used across use-cases and that have a high number of access requests. Also, new data users are wise to follow the activity of known data experts within the team.
Access control
There are two dimensions of access control:
Securely connecting to the dataset and artifact sources.
Limiting access to the search results.
Connecting to the sources is time consuming, requiring approvals from security and compliance teams that validate the usage. For encrypted source fields, appropriate decryption keys are also required. Read access permissions can limit the data objects that are allowed to be accessed, such as select tables, views, schemas.
The other dimension is limiting the access to search results to the right teams. Limiting the search results is a balancing act between able to discover the presence of a dataset or artifact and gaining access to secure attributes.
Defining Requirements
The search service should be able to answer some data user questions. Are there datasets or artifacts related to topic X? The match to X can be related to names, descriptions, metadata, tags, categories, and so on. What are the most popular datasets and artifacts related to topic X and the related data user teams? What are the details of the metadata (such as lineage, stats, creation date, and so on) associated with a shortlisted dataset?
There are three key modules required to build the search service:
- Indexer module
Discovers available datasets and artifacts, extracts schema and metadata properties, and adds to the catalog. It tracks changes and continuously updates the details.
- Ranking module
Responsible for ranking the search results based on a combination of relevance and popularity.
- Access module
Ensures search results shown to a data user adhere to the access control policies.
Indexer Requirements
The Indexer requirements vary from deployment to deployment based on the types of datasets and artifacts to be indexed by the search service. Figure 2-1 illustrates the different categories of datasets and artifacts. As a part of the requirements, an inventory of these categories as well as the list of deployed technologies. For instance, structured data in the form of tables and schema can be in multiple technologies such as Oracle, SQL Server, MySQL, and so on.
Figure 2-1 shows the entities covered by the search service -- it includes both data and artifacts. Datasets spans structured, semi-structured, and unstructured data. Semi-structured NoSQL datasets can be key-value stores, document stores, graph databases, time-series stores, and so on. Artifacts include generated insights as well as recipes such as ETLs, notebooks, ad-hoc queries, data pipelines, and GitHub repos that can be potentially re-used.

Figure 2-1. Categories of datasets and artifacts covered by the search service
Another aspect of requirements is updating the indexes as datasets and artifacts continuously evolve. It is important to define requirements related to how the updates are reflected within the search service:
How quickly indexes need to be updated to reflect the changes -- the acceptable lag to refresh
Indexes across versions and historic partitions i.e., defining whether the scope of search is limited only to the current partitions.
Ranking Requirements
Ranking is a combination of relevance and popularity. Relevance is based on the matching of name, description and metadata attributes. As a part of the requirements, the list of metadata attributes most relevant for the deployment can be defined. Table 2-1 represents a normalized model of metadata attributes. The metadata model can be customized based on the requirements of the data users.
| Metadata Categories | Example properties |
| Basic | Size, format, last modified, aliases, access control lists |
| Content-based | Schema, number of records, data fingerprint, key fields |
| Lineage | Reading jobs, writing jobs, downstream datasets, upstream datasets |
| User-defined | Tags, categories |
| People | Owner, teams accessing, teams updating |
| Temporal | Change history |
In addition to normalized metadata attributes, technology-specific metadata can also be captured. For instance, for Apache HBase, hbase_namespace and hbase_column_families are examples of technology-specific metadata. These attributes can be used to further search and filter the results.
Access Control Requirements
Access control policies of search results can be defined either on the specifics of the user or specifics of the data attributes or both. User-specific policies are referred to as Role Based Access Control (RBAC), whereas attribute-specific policies are referred to as Attribute-based Access Control (ABAC). For instance, limiting visibility for specific user groups is an RBAC policy, and a policy defined for a data tag or personally identifiable information (PII) is a ABAC policy.
In addition to access policies, other special handling requirements might be required:
Masking of row or column values.
Time varying policies such that datasets and artifacts are not visible until a specific timestamp e.g., table with the quarterly results are not visible until the date the results are officially announced.
Non-functional Requirements
Similar to any software design, the following are some of the key NFRs that should be considered in the design of a search service:
- Response times for search
It is important to have the search service respond to search queries in the order of seconds.
- Scaling to support large indexes
As enterprises grow, it is important that the search service scales to support thousands of datasets and artifacts.
- Ease of onboarding for new sources
Simplifying the experience of data source owners to add their sources to the search service.
- Automated monitoring and alerting:
The health of the service should be easy to monitor. Any issues during production should generate automated alerts.
Implementation Patterns
As discussed in the previous section, there are three modules of the search service: Ingestion, Indexer, Ranking, and Access Control. This section covers the following patterns:
Push-Pull Indexer pattern
Hybrid Search Ranking pattern
Catalog Access Control pattern
Push-Pull Indexer pattern
The Push-Pull Indexer pattern discovers and updates available datasets and artifacts across the silos of an enterprise. The pull aspect of the indexer discovers sources, extracts datasets and artifacts, and adds them to the catalog. This is analogous to search engines crawling websites on the internet and pulling associated web pages to make them searchable. The push aspect is related to tracking changes in datasets and artifacts. In this pattern, sources generate update events that are pushed to the catalog for updating the existing details.
The Push-Pull Indexer pattern has the following phases (as illustrated in Figure 2-2):
- Connect phase
Indexer connects to available sources such as databases, catalogs, model and dashboard repositories, and so on. These sources are either added manually or discovered in an automated fashion. There are several ways for automated source discovery -- scanning the network similar to the approach used in vulnerability analysis; using cloud account APIs for discovering deployed services within the account; and so on.
- Extract phase
The next phase is extracting details such as name, description, and other metadata of the discovered dataset and artifacts. For datasets, the indexer provides source credentials to the catalog for extraction of the details (as covered in Chapter 1). There is no straightforward way to extract details of artifacts. For notebooks, data pipeline code, and other files persisted in Git repositories, the indexer looks for a metadata header such as a small amount of structured meta-data at the beginning of the file that includes author(s), tags, and a TLDR. This is especially useful for notebook artifacts where the entirety of the work, from the query to the transforms, visualizations, and write-up, is contained in one file,
- Update phase
Sources publish updates to datasets and artifacts on the event bus. These events are used to make updates to the catalog. For example, when a table is dropped, the catalog subscribes to this push notifications and deletes the records.

Figure 2-2. The Connect, Extract, Update phases of the Push-Pull Indexer pattern
An example of artifacts repository is AirBnB’s open source project called Knowledge repo (https://github.com/airbnb/knowledge-repo). At the core there is a Git repository, to which notebooks, query files, scripts are committed. Every file starts with a small amount of structured meta-data, including author(s), tags, and a TLDR. A Python script validates the content and transforms the post into plain text with Markdown syntax. GitHub’s pull request is used to review the header contents and organized by time, topic, or contents. To prevent low quality, similar to code reviews, peer review checks are done for methodological improvements, connections with preexisting work, and precision in details. Additionally, each post has a set of metadata tags, providing a many-to-one topic inheritance that goes beyond the folder location of the file. Users can subscribe to topics and get notified of a new contribution.
An example of the Push-Pull Indexer pattern implementation is Netflix’s open-source Metacat catalog (https://github.com/Netflix/metacat) with the capability to index datasets. Metacat uses pull model to extract dataset details as well as a push notification model where datasources publish their updates to an event bus such as Kafka. Datasources can also invoke explicit REST API to publish a change event. In Metacat, changes are also published to Amazon SNS. Publishing events to SNS allows other systems in our data platform to “react” to these metadata or data changes accordingly. For example, when a table is dropped, the garbage collection service can subscribe to the event and clean up the data appropriately.
Strengths of the Push-pull Indexer pattern:
Index updates are timely -- new sources are periodically crawled and change events are pushed on the event bus for processing.
Extensible pattern for extracting and updating different categories of metadata attributes.
Scalable to support large number of sources given the combination of push and pull approach.
Weakness of the Push-pull Indexer pattern:
Configuration and deployment for different source types can be challenging.
To access details via pull, source permissions are required that might be a concern for regulated sources.
The Push-Pull Indexer pattern is an advanced approach for implementing indexing (compared to a push only pattern). To ensure sources are discovered, the onboarding process should include adding the source to the list of pull targets as well as creating a common set of access credentials.
Hybrid Search Ranking Pattern
Given a string input, the ranking pattern generates a list of datasets and artifacts. The string can be a table name, business vocabulary concept, classification tag, and so on. This is analogous to page ranking used by search engines for generating relevant results. The success criteria of the pattern is that the most relevant results are in the top 5. The effectiveness of search ranking is critical for reducing time to insights. For instance, if the relevant result is in the top three on the first page versus several pages down, time will be spent in reviewing and analyzing several other irrelevant results. Hybrid Search Ranking pattern implements a combination of relevance and popularity to find the most relevant datasets and artifacts.
There are three phases to the pattern (as illustrated in Figure 2-3):
- Parsing phase
Search starts with an input string typically in plain english. In addition to searching, there can be multiple criteria for filtering the results. The service is backed by a conventional inverted index for document retrieval, where each dataset and artifact becomes a document with indexing tokens derived based on the metadata. Each metadata can be associated with a specific section of the index. For example, metadata derived from the creator of the dataset is associated with the “creator” section of the index. Accordingly, the search “creator:x” will match keyword “x” on dataset creator only, whereas the unqualified atom “x” will match the keyword in any part of a dataset’s metadata. An alternative starting point to the parsing process is to browse a list of popular tables and artifacts and finding the ones that are most relevant to the business problem.
- Ranking phase
Ordering of the results is a combination of relevance and popularity. Relevance is based on fuzzy matching of the entered text to table name, column name, table description, metadata properties, and so on. Popularity based matching is based on activity i.e., highly queried datasets and artifacts show up higher in the list, while those queried less show up later in the search results. An ideal result is one that is both popular and relevant. There are several other heuristics to consider. For instance, newly created datasets have a higher weightage on relevance (since they are not yet popular). Another heuristic is to sort based on quality metrics such as number of issues reported and whether the dataset is generated as a part of a hardened data pipeline versus an ad-hoc process.
- Feedback phase
Weightage between relevance and popularity needs to be adjusted based on feedback. The effectiveness of search ranking can be measured explicitly or implicitly: Explicitly in the form of thumbs up/down rating for the displayed results; implicitly as Click Through Rate (CTR) on top 5 results. This will fine-tune the weightage as well as the fuzzy matching logic for relevance matching.
Figure 2-3 illustrates the phases of the Hybrid Search Ranking pattern
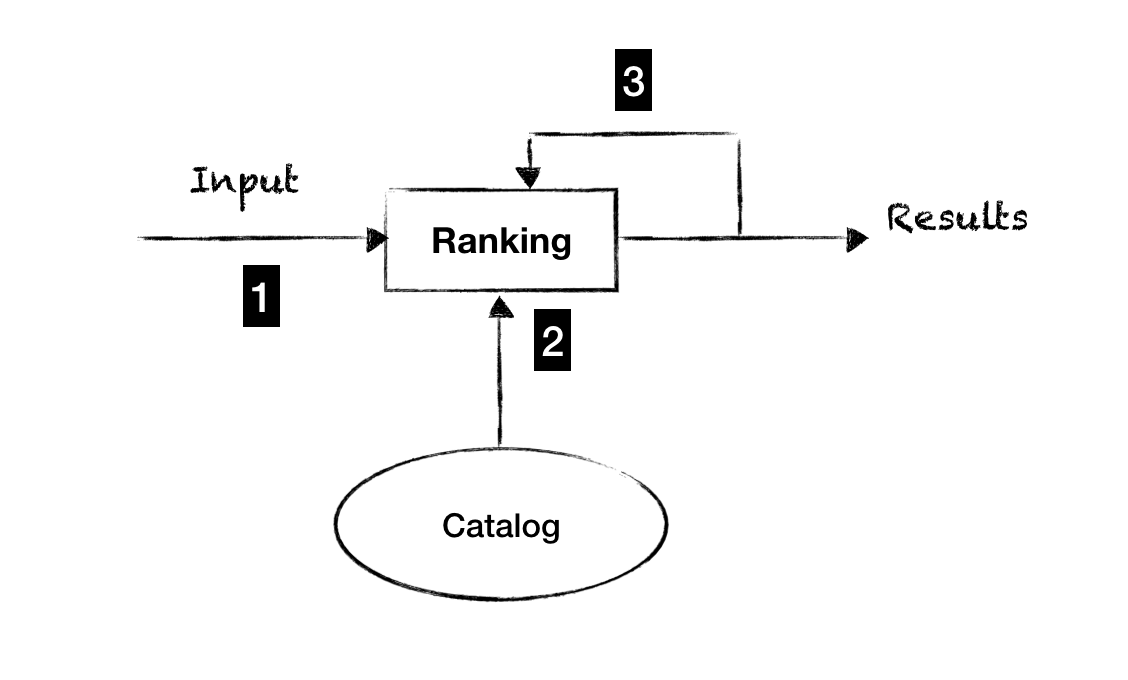
Figure 2-3. An example of the Hybrid Search Ranking pattern is the Amundsen (https://github.com/lyft/amundsen) open-source project
Amundsen indexes datasets and artifacts. The input parsing implements type-ahead capability (to improve the exact matching). The input string supports wildcards as well as keywords, categories, business vocab, and so on. The input can be further narrowed using filters. There are different types of filters:
Search by category such as dataset, table, stream, tags, and so on
Filter by keyword: value such as column: users or column_description: channels.
Amundsen enables fuzzy searches by implementing a thin Elasticsearch proxy layer to interact with the catalog. Metadata is persisted in Neo4j. It uses a data ingestion library for building the indexes. The search results show a subset of the in-line metadata — description about the table as well the last date when the table was updated.
Scoring is generally a hard problem and involves tuning the scoring function based on users’ experience. Following are some of the heuristics used in the scoring function by Google’s dataset search service (https://ai.google/research/pubs/pub45390):
- The importance of a dataset depends on its type.
Scoring function favors a structured table over a file dataset, all else being equal. The intuition is that a dataset owner has to register a dataset as a table explicitly, which in turn makes the dataset visible to more users. This action can be used as a signal that the dataset is important
- The importance of a keyword match depends on the index section
For instance, a keyword match on the path of the dataset is more important than a match on jobs that read or write the dataset, all else being equal.
- Lineage fan-out is a good indicator of dataset importance as it indicates popularity
Specifically, this heuristic favors datasets with many reading jobs and many downstream datasets. The intuition is that if many production pipelines access the dataset, then most likely the dataset is important. One can view this heuristic as an approximation of PageRank in a graph where datasets and production jobs are vertices and edges denote dataset accesses from jobs.
- A dataset that carries an owner-sourced description is likely to be important
Our user interface enables dataset owners to provide descriptions for datasets that they want other teams to consume. The presence of such a description is treated as a signal of dataset importance. If a keyword match occurs in the description of a dataset then this dataset is weighted higher as well.
Strengths of the Hybrid Search Ranking pattern:
Balances relevance and popularity allowing data users to quickly shortlist the most relevant data.
Not bottlenecked by the need to add extensive metadata for relevance matching on Day 1. Metadata can be incrementally annotated while the pattern uses more of the popularity-based ranking
Weakness of the Hybrid Search Ranking pattern:
Does not replace the need for curated datasets. The pattern relies on the correctness of the metadata details that are synchronized with the business details.
Getting the right balance between popularity and relevance is difficult
The Hybrid Search Ranking pattern provides the best of both worlds -- for datasets and artifacts where extensive amounts of metadata is available, it leverages the relevance matching. For assets that are not well-curated, it relies on the popularity matching.
Catalog Access Control Pattern
The goal of the search service is to make it easy to discover datasets and artifacts. But it is equally important to ensure that access control policies are not violated. The search results displayed to different users can exclude select datasets or vary in the level of metadata details. This pattern enforces access control at the metadata catalog and provides a centralized approach for fine-grained authorization and access control.
There are three phases to the Catalog Access Control pattern:
- Classify
In this phase users as well as datasets/artifacts are classified into categories. Users are classified into groups based on their role: data steward, finance users, data quality admins, data scientists, data engineers, admins, and so on. The role defines the datasets and artifacts that are visible during the search process. Similarly datasets and artifacts are annotated with user-defined tags such as finance, PII, and so on.
- Define
Policies define the level of search details to be shown to a given user for a given dataset or artifact. For instance, tables related to financial results can be restricted to finance users. Similarly data quality users see advanced metadata and change log history. Policy definitions fall into two broad buckets: Role-based Access control (RBAC) where policies are defined based on users and Attribute-based Access Control (ABAC) where policies are defined on attributes such as user-defined tags, geographical tags based on IP address, time-based and so on.
- Enforce
Typically there are three ways to enforce access control policies in the search results:
Basic metadata for everyone: In response to the search query, the results show basic metadata (such as name, description, owner, date updated, user-defined tags, and so on) to everyone whether or not they have access. The reasoning for this approach is to ensure user productivity by showing the dataset and artifacts that exist. If the dataset matches the requirement, the user can request access.
Selective advanced metadata: Select users get advanced metadata like column stats, data preview based on the access control policies
Masking of columns and rows: Based on access control, the same dataset will have different number of columns as well as different rows in the data preview. The updates to the catalog are automatically propagated to the access control. For instance, if a column is labeled as sensitive, the search results will automatically start reflecting in the search results.
An example of a popular open-source solution for fine-grained authorization and access control is Apache Ranger (https://ranger.apache.org/). It provides a centralized framework to implement security policies for the Atlas catalog as well as all Hadoop ecosystem. It supports both RBAC and ABAC policies based on individual users, groups, access-types user-defined tags, dynamic tags like IP-address, and so on. Apache Ranger policy model has been enhanced to support row-filtering and data-masking features such that only a subset of rows in a table can be accessed or masked/redacted values for sensitive data. Ranger policy validity periods enables configuring a policy to be effective for a specified time range such as restricting access to sensitive financial information until the earnings release date.
Strengths of the Catalog Access Control pattern:
Easy to manage given the centralized access control policies on the catalog level
Tunable access control based on different users and use-cases.
Weakness of the Catalog Access Control pattern:
The catalog access control policies can get out-of-sync with the data source policies. For instance, the data user can access the metadata based on the catalog policies but not the actual dataset based on the backend source policy.
The Catalog Access pattern is a must-have to balance discoverability and access control. It is a flexible pattern allowing simple heuristics as well as complex fine-grained authorization and masking.
Summary
Real-world deployments have non-curated and siloed datasets and artifacts. They lack well-defined attribute names, descriptions, as well as are typically out-of-sync with the business definitions. A search service can automate the process of shortlisting relevant datasets and artifacts significantly simplifying the discovery phase in the journey map.