
Chapter 3. Feature Store Service
Data Scientists spend 60% of their time in creating training datasets for ML models. A training dataset is composed of historic values associated with data attributes (referred to as features). Formally defined, a feature is a data attribute that can be either extracted directly from data sources or derived by computing from one or more data sources e.g., the age of a person, a coordinate emitted from a sensor, a word from a piece of text, or an aggregate value like the average number of purchases within the last hour.
In the process of building ML models, data scientists iterate on feature combinations. Building data pipelines to generate the features for training as well as for inference is a significant pain-point. First, data scientists have to write low level code for accessing datastores, requiring data engineering skills. Second, the pipelines for generating these features have multiple implementations that are not always consistent i.e., separate pipelines for training and inference. Third, the pipeline code is duplicated across ML projects and not reusable since they are embedded as part of the model implementation. Finally, there is no change management or governance of features. These aspects impact the overall time to insights and made worse with data users having limited engineering skills to develop robust pipelines and monitor them in production, as well as lack of sharing across ML projects making it expensive to build new models since the feature pipelines are repeatedly built from scratch.
Ideally, a feature store service should provide well-documented, governed, versioned, and curated features for training and inference of ML models. Data users should be able to search and use features to build models with minimal data engineering. The feature pipeline implementations for training as well as inference are consistent. In addition, features are cached and re-used across ML projects reducing training time and infrastructure costs. The success metric of this service is time to featurize. As the feature store service is built up with more features, it provides economies of scale by making it easier and faster to build new models.
Journey Map Context
Developing and managing features is a critical piece of developing ML models. This section discusses the key scenarios in the journey map for the feature store service.
Finding Available Features
As a part of the exploration phase, data scientists search for available features that can be leveraged to build the ML model. The goal of this phase is to reuse and reduce the cost to build the model. The process involves analyzing whether the available features are of good quality and how they are being used currently. Due to lack of a centralized feature repository, data scientists often skip the search phase and develop ad-hoc training pipelines that have a tendency to become complex over time. As the number of models increases, it quickly becomes a pipeline jungle that is hard to manage.
Training Set Generation
During model training, datasets consisting of one or more features are required to train the model. The training set is generated that contains the historic values of these features along with a prediction label. The training set is prepared by writing queries that extract the data from the dataset sources, transforms, cleanses, and generates historic data values of the features. Significant amount of time is spent in developing the training set. Also, the feature set needs to be continuously updated with new values (a process referred to as backfilling). With a Feature store, the training datasets for features is available during the building of the models.
Feature Pipeline for Online Inference
For model inference, the feature values are provided as an input to the model that then generates the predicted output. The pipeline logic for generating features during inference should match the logic used during training. Else, the model predictions will be incorrect. Besides the pipeline logic, an additional requirement is having a low latency to generate the feature for inferencing in online models. Today, the feature pipelines are embedded within the ML pipeline that are not easily re-usable. Further, changes in training pipeline logic may not be coordinated correctly with corresponding model inference pipelines.
Minimize Time to Featurize
Time to featurize is the time spent to create and manage features. The time spent today is broadly divided into two categories: feature computation and feature serving. Feature computation involves data pipelines for generating features both for training as well as inference. Feature serving focuses on serving bulking training datasets, low-latency feature values for model inference, and making it easy for data users to search and collaborate across features.
Feature Computation
Feature computation is the process to convert raw data into features. This involves building data pipelines for generating historic training values of the feature as well as current feature values used for model inference. Training datasets need to be continuously backfilled with newer samples. There are two key challenges with feature computation.
First, the complexity of managing pipeline jungles. Pipelines extract the data from the source datastores and transforms them into features. These pipelines have multiple transformations and need to handle corner cases that arise in production. Managing these at scale in production is a nightmare. Also, the number of feature data samples continues to grow especially for deep learning models. Managing large datasets at scale requires distributed programming optimizations for scaling and performance. Overall, building and managing data pipelines is typically one of the most time consuming pieces in the overall time to insights of model creation.
Second, separate pipelines are written for training and inference of a given feature. The reason for separate pipelines is different freshness requirements since model training is typically batch oriented while model inference is streaming with near real-time latency. Discrepancies in training and inference pipeline computation is a key reason for model correctness issues, and a nightmare to debug at production scale.
Feature Serving
Feature serving involves serving feature values in bulk for training as well as at low latency for inference. It requires features to be easy to discover, as well as compare and analyze with other existing features. In a typical large scale deployment, feature serving supports thousands of model inferences. Scaling performance is one of the key challenges as well as avoiding duplicate features given the fast paced exploration of data users across 100s of model permutations during prototyping.
Today, one of the common issues is “the model performs well on the training data set, but does not in production.” While there are can multiple reasons, the key problem is referred to as label leakage. This arises due to incorrect point-in-time values served for the model features. Finding the right feature values is tricky. To illustrate, figure 3-1 shows the feature values selected in training for prediction at Time T1. There are three features shown (F1, F2, F3) -- for prediction P1, feature values 7, 3, 8 need to selected for training features F1, F2, F3 respectively. Instead, if the feature values post prediction are used (such as value 4 for F1), there will be feature leakage since the value represents the potential outcome of the prediction and incorrectly represent a high correlation during training.

Figure 3-1. The selection of correct point-in-time values for features F1, F2, F3 during training for prediction P1. The actual outcome Label L provided for training the supervised ML model.
Defining Requirements
Feature Store service is a central repository of features providing both the historical values of features over long durations such as weeks or months as well as near real-time feature values over several minutes. The requirements are of a feature store are divided into feature computation and feature serving.
Feature Computation
Feature computation requires deep integration with data lake as well as other data sources. There are three dimensions to consider for feature computation pipelines.
First, the diverse types of features to be supported. Features can be associated with individual data attributes or are composite aggregates. Further, features can be relatively static versus changing continuously relative to nominal time. Computing features typically requires multiple primitive functions to be supported by the feature store similar to the ones that are currently used by data users such as converting categorical data into numeric data, normalizing data when features originate from different distributions, one-hot-encoding or feature binarization, feature binning (e.g., convert continuous features into discrete), feature hashing (e.g., to reduce the memory footprint of one-hot-encoded features), computing aggregate features (e.g., count, min, max, stdev).
Second, the programming libraries required to be supported for feature engineering. Spark is a preferred choice for data wrangling among our users that are working with large-scale datasets; users working with small datasets prefer frameworks such as Numpy and Pandas, Feature engineering jobs are built using notebooks, python files, or .jar files and run on a computation frameworks such as Samza,Spark, Flink and Beam.
Third, the source system types where the feature data is persisted. The source systems can be a range of relational databases, NoSQL datastores, streaming platforms, file and object stores.
Serving
A feature store needs to support strong collaboration capabilities. Features should be defined and generated in a way that they are shareable across teams.
Feature Groups
A feature store has two interfaces: writing features to the store and reading features for training and inference. Features are typically written to a file or a project-specific database. Features can be further grouped together based on the ones that are computed by the same processing job or computed from the same raw dataset. For instance, in a car riding service like Uber, all the trip related features for a geographical region can be managed as a feature group since they all can be computed by one job that scans through the trip history. Features can be joined with labels (in case of supervised learning) and materialized into a training dataset. Feature groups typically share a common column, such as a timestamp or a customer-id, that allows feature groups to be joined together into a training dataset. The feature store creates and manages the training dataset, and persisted as tfrecords, parquet, csv, tsv, hdf5, or npy files.
Scaling
Key aspects to consider from the standpoint of scaling: number of features to be supported in the feature store; number of models calling the feature store for online inferences; number of models for daily offline inference as well as training; amount of historic data to be included in training datasets; number of daily pipelines to backfill the feature datasets as new samples are generated. Additionally, there are specific performance scaling requirements associated with online model inference i.e., TP99 latency value for computing the feature value. For online training, taking into account time to backfill training sets as well as account for DB schema mutations. Typically, historical features need to be less than 12 hours old, and near real-time feature values need to less than 5 mins old.
Feature Analysis
Features should be searchable and easily understandable to ensure they are re-used across ML projects. Data users need to be able to identify the transformations, as well as analyze the features finding outliers, distribution drift, and feature correlations.
Non-functional Requirements
Similar to any software design, the following are some of the key NFRs that should be considered in the design of a feature store service:
- Automated monitoring and alerting
- The health of the service should be easy to monitor. Any issues during production should generate automated alerts.
- Response times
It is important to have the service respond to feature search queries in the order of milliseconds.
- Intuitive interface
For the feature store service to be effective, it needs to adopted across all the data users within the organization. As such, it is critical to have APIs, CLIs, and the web portal that are easy to use and understand.
Implementation
Feature Store service is becoming increasingly popular -- Uber’s Michaelango (https://eng.uber.com/michelangelo/), AirBnb’s Zipline (https://www.slideshare.net/databricks/zipline-airbnbs-machine-learning-data-management-platform-with-nikhil-simha-and-andrew-hoh), GO-JEK’s Feast (https://github.com/gojek/feast), Comcast’s Applied AI (https://databricks.com/session/operationalizing-machine-learning-managing-provenance-from-raw-data-to-predictions), Logical Clock’s Hopsworks (https://github.com/dc-sics/hopsworks), are some of the popular open-source examples of a feature store service. From an architecture standpoint, each of these implementations have two key building blocks: feature computation and serving.
This section covers the following patterns related to feature computation and serving respectively:
Hybrid Feature Computation pattern
Feature Registry Pattern
Hybrid Feature Computation pattern
The feature computation module has to support two sets of ML scenarios: 1) Offline training and inference where bulk historic data is calculated at the frequency of hours; 2) Online training and inference where feature values are calculated every few minutes.
In the Hybrid Feature Computation pattern, there are three building blocks (as shown in Figure 3-2):
- Batch compute pipeline
Traditional batch processing run as an ETL job every few hours or daily to calculate historic feature values. The pipeline is optimized to run on large time windows.
- Streaming compute pipeline
Streaming analytics on data events in a real-time message bus to compute features values at low latency. The feature values are backfilled into the bulk historic data from the batch pipeline.
- Feature spec
To ensure consistency, instead of data users creating pipelines for new features, they define a feature spec using a Domain Specific Language (DSL). The spec specifies the data sources, dependencies, and the transformation required to generate the feature. The spec is automatically converted into batch and streaming pipelines. This ensures consistency in pipeline code for training as well as inference without user involvement.
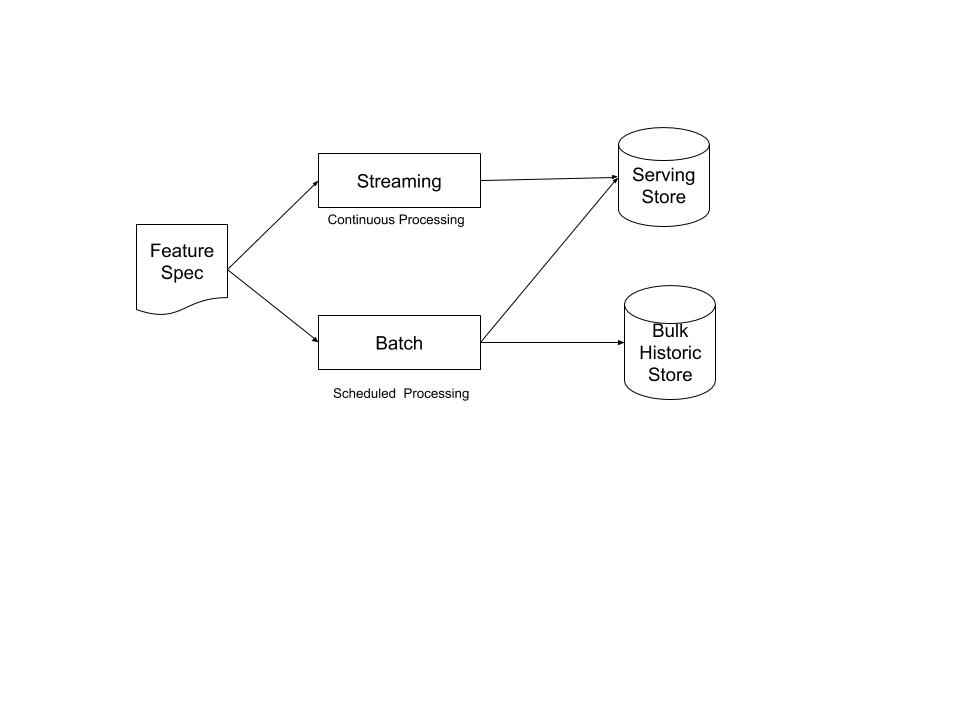
Figure 3-2. Parallel pipelines in the Hybrid Feature Computation pattern
An example of the Hybrid Feature Computation pattern is Uber’s Michaelango (https://eng.uber.com/michelangelo/). It implements a combination of Apache Spark and Samza. Spark is used for computing batch features and the results are persisted in Hive. Batch jobs compute feature groups and write to single Hive table as a feature per column. For example, UberEATS (food delivery service) uses the batch pipeline for features like a restaurant’s average meal preparation time over the last seven days. For streaming pipeline, Kafka topics are consumed with Samza streaming jobs to generate near real-time feature values that are persisted in Key-Value format in Cassandra. On a regular basis, bulk precomputing and loading of historical features happens from Hive into Cassandra on a regular basis. For example, UberEATS uses the streaming pipeline for features like a restaurant’s average meal preparation time over the last one hour. Features are defined using a DSL that selects, transforms, and combines the features that are sent to the model at training and prediction times. The DSL is implemented as sub-set of Scala which is a pure functional language with a complete set of commonly used functions. Data users also have the ability to add their own user-defined functions.
Strengths of the Hybrid Feature Computation pattern are:
Optimal performance of feature computation across batch and streaming time windows.
DSL to define features avoids inconsistencies associated with discrepancies in pipeline implementation for training and inference.
Weakness of the Hybrid Feature Computation pattern are:
The pattern is non-trivial to implement and manage in production. It requires a fair amount of maturity of the data platform.
The Hybrid Feature Computation pattern is an advanced approach for implementing computation of features that is optimized for both batch and streaming. Programming models such as Apache Beam are increasingly converging the batch and streaming divide.
Feature Registry Pattern
Feature registry pattern ensures it is easy to discover and manage features, as well as performant in serving the feature values for online/offline training and inference. The requirements for these use-cases are quite varied as observed by Li et. al [http://proceedings.mlr.press/v67/li17a/li17a.pdf]. For batch training and inference, efficient bulk access is required. For real-time prediction, low latency per record access is required. A single store is not optimal for both historical and near real-time features because of the following reasons: 1) Data stores are efficient for either point queries or for bulk access, but not both; 2) Frequent bulk access can adversely impact the latency of point queries making them difficult to co-exist. Irrespective of the use-case, features are identified via canonical names.
For feature discovery and management, the Feature Registry pattern is the user interface for publishing and discovering features and training datasets. The feature registry pattern also serves as a tool for analyzing feature evolution over time by comparing feature versions. When a new data science project is started, data scientists within the project typically begin by scanning the feature registry for available features, and only add new features for their model that do not already exist in the feature store.
The Feature Registry pattern has the following building blocks:
- Feature values store
Stores the feature values. Common solutions for bulk store are Hive (used by Uber and AirBnb, S3 (used by Comast), Google BigQuery (used by GO-JEK). For online data, a NoSQL store such as Cassandra is typically used.
- Feature registry store
Stores code to compute features, feature version information, feature analysis data, and feature documentation. The feature registry provides automatic feature analysis, feature dependency tracking, feature job tracking, feature data preview, keyword search on feature/feature group/training dataset metadata.
An example of the feature registry pattern is Hopsworks Feature Store (https://github.com/logicalclocks/hopsworks). Feature groups and training datasets in Hopsworks feature store are linked to Spark/Numpy/Pandas jobs which enables the reproduction and recompution of the features when necessary. On addition of a feature group or training dataset, the feature store does a data analysis step looking at cluster analysis of feature values, feature correlation, feature histograms, and descriptive statistics. For instance, feature correlation information can be used to identify redundant features, feature histograms can be used to monitor feature distributions between different versions of a feature to discover covariate shift, and cluster analysis can be used to spot outliers. Having such statistics accessible in the feature registry helps users decide on which features to use.
Strengths of the Feature Registry pattern are:
Provides a performant serving of training datasets and feature values
Reduces feature analysis time of the data users.
Weakness of the Feature Registry pattern are:
Potential performance bottleneck while serving 100s of models
Scaling for continuous feature analysis with growing number of features
Summary
Today, there is no principled way to access features during model serving and training. Features cannot easily be re-used between multiple machine learning pipelines and ML projects work in isolation without collaboration and re-use. Given the features are deeply embedded in ML pipelines, when new data arrives, there is no way to pin down exactly which features needs to be recomputed, rather the entire ML pipeline needs to be run to update features. A feature store addresses these symptoms and enable economies of scale in developing ML models.