
Chapter 4. Data Movement Service
Data scientists spend 16% of their time moving data [1]. The time spent in making data available impacts productivity and slows down the overall time to insights. Ideally, moving data should be self-serve such that data scientists can select a source, a target, and a schedule to move data. The service under the covers should do the heavy lifting of orchestrating the data movement, verifying data correctness, and adapting to any schema or configuration changes that occur on the data source. The success criteria for such a service is reducing the time to data availability.
Journey Map Context
This section talks about the different scenarios in the data scientist journey map where data movement is required.
Aggregating Data Across Sources
Traditionally, data from transactional data sources was aggregated in a data warehouse for analytical purposes. Today, the variety of data sources has increased significantly to include structured, semi-structured, and unstructured data -- including transactional databases, behavioral data, geospatial data, server logs, IoT sensors, and so on. Aggregating data from these sources is a challenge for data users.
To add to the complexity, data sources are getting increasingly siloed with the emergence of the microservices paradigm [2] for application design. In this paradigm, developers can select different underlying data stores and data models best suited for their microservice. In the real world, a typical data user needs to grapple with different data silos and typically coordinates across teams managing product-based transactions, behavioral clickstream data, marketing campaigns, billing activity, customer support tickets, sales records, and so on. In this scenario, the role of the data movement service is to automate the aggregation of data within a central repository, called a data lake.
Moving Raw Data to Specialized Query Engines
A growing number of query processing engines are optimized for different types of queries and data workloads. For instance, for slice-and-dice analysis of time-series datasets, data is copied into specialized analytical solutions such as Druid (https://druid.apache.org/), Pinot (https://pinot.apache.org/). Simplifying data movement can help leverage the right analysis tool for the job. In cloud-based architectures, query engines increasingly run directly on the data lake reducing the need for this scenario.
Moving Processed Data to Serving Stores
Consider the scenario where data is processed and stored as key-value pairs that need to be served by the software application to millions of end-users. To ensure the right performance and scaling, the right NoSQL store needs to be selected as a serving store depending on the data model and consistency requirements.
Exploratory Analysis Across Sources
During the initial phases of model building, data users need to explore a multitude of data attributes. These attributes may not be all available in the data lake. The exploration phase doesn’t require full tables, but rather samples of the data for quick prototyping. Given the iterative nature of the prototyping effort, automating data movement as a point-and-click capability is critical. This scenario serves as a pre-step to deciding the datasets that need to be aggregated within the data lake on a regular basis.
Minimizing Time to Data Availability
Today, time to data availability is spent on the four activities discussed in this section. The goal of the data movement service is to minimize this time spent.
Data Ingestion Configuration and Change Management
Data needs to be read from the source data store and written to a target data store. A technology-specific adapter is required to read/write the data from and to the data store. Source teams managing the data store need to enable the configuration to allow data to be read. Typically, there are concerns related to performance impact on the source data store that needs to be addressed. This process is tracked as Jira tickets and can take days.
After the initial configuration, changes to the schema and configuration can occur at the source and target data stores. Such changes can disrupt downstream ETLs and ML models relying on specific data attributes that may have been either deprecated or changed to represent a different meaning. These changes need to be proactively coordinated. Unless the data movement is one-time, ongoing change management is required to ensure source data is correctly made available at the target.
Compliance
Before the data can be moved across systems, it needs to be verified for regulatory compliance. For instance, if the source data store is under regulatory compliance laws such as PCI (https://www.pcisecuritystandards.org/), the data movement needs to be documented with clear business justification. For data with personally identifiable information (PII) attributes, these need to be encrypted during transit as well as on the target datastore. Emerging data rights laws such as General Data Protection Regulation GDPR (https://eugdpr.org/),California Consumer Privacy Act CCPA (https://oag.ca.gov/privacy/ccpa) further limit the data that can be moved from source data stores for analytics. Compliance validations can take significant time depending on the applicable regulations.
Data Quality Verification
Data movement needs to ensure that source and target are in parity. In real-world deployments, quality errors can arise from a multitude of reasons such as source errors, adapter failures, aggregation issues, and so on. Monitoring of data parity during movement is a must-have to ensure that data quality errors don’t go unnoticed and impact correctness of business metrics and ML models.
During data movement, data at the target may not exactly resemble the data at the source. The data at the target may be filtered, aggregated, or a transformed view of the source data. For instance, if the application data is sharded across multiple clusters, a single aggregated materialized view may be required on the target. Transformations need to be defined and verified before deploying in production.
Although there are multiple commercial and open-source solutions available today, there is no one-size-fits-all solution for implementing a data movement service. The rest of the chapter covers requirements and design patterns for building the data movement service.
Defining Requirements
There are four key modules of a data movement service:
- Ingestion module
Responsible for copying data from the source to the target data store either one-time or on an ongoing basis.
- Transformation module
Responsible for transforming the data as it is copied from source to target.
- Compliance module
Ensures data moved for analytical purposes meets compliance requirements.
- Verification module
Ensures data parity between source and target.
The requirements for each of these components varies from deployment to deployment depending on several factors, including industry regulations, maturity of the platform technology, types of insights use-cases, existing data processes, skills of data users, and so on. This section covers the aspects data users need to consider for defining requirements related to the data movement service.
Ingestion Requirements
Three key aspects need to be defined as a part of data ingestion requirements.
Source and target data store technologies
To read and write data from a data store, a technology-specific adapter is required. Available solutions vary in the adapters they support. As such, it is important to list the data stores currently deployed. Table 4-1 lists the popular categories of data stores.
| Data store category | Popular examples |
| Transactional databases | Oracle, SQL Server, MySQL |
| NoSQL datastores | Cassandra, Neo4j, MongoD |
| Filesystems | Hadoop filesystem, NFS appliance, Samba |
| Data warehouses | Vertica, Oracle Exalogic, AWS Redshift |
| Object store | AWS S3 |
| Messaging frameworks | Kafka, JMS |
| Event logs | Syslog, Ngnix logs |
Data scale
The key aspects of scale that data engineers need to understand are: a) How big are the tables in terms of number of rows -- that is, do they have thousands or billions of rows? b) What is the ballpark size of the tables in TB? and c) What is the ballpark of number of tables that would be copied on an ongoing basis? Another aspect of scale is the rate of change -- estimate whether the table is fast changing with regard to the number of inserts, updates, and deletes. Using the size of the data and rate of updates, data engineers can estimate the scaling requirements.
Acceptable refresh lag
For exploratory use-cases, the data movement typically is a one-time move. For the ongoing copy of data, there are a few different options, as shown in Figure 4-1. In the figure, scheduled data copy can be implemented as a batch (periodic) versus continuous operation. Batch operations can be either full-copy of the table or incremental copy of only the changes from the last change. For continuous copy, changes on the source are transmitted to the target in near real-time (order of seconds or minutes)
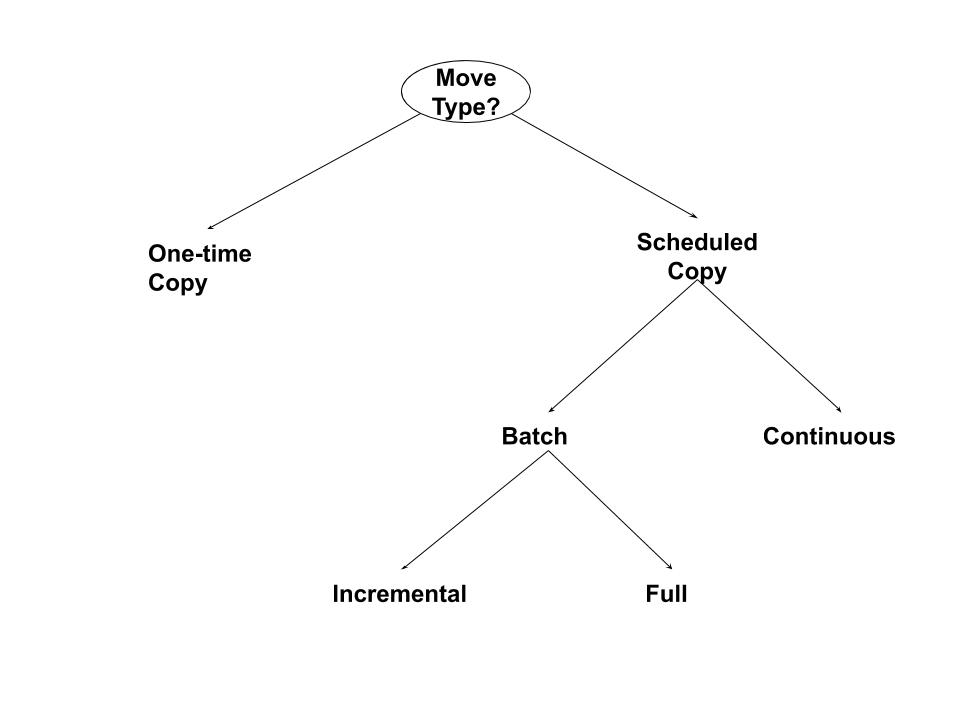
Figure 4-1. Decision tree showing the different types of data movement requests
Transformation Requirements
During data movement, the target may not be the exact replica of the source. As a part of the data movement service, it is important to define the different types of transformations that need to be supported by the service. There are four categories of transformation:
- Format transformation
The most common form is for the target data to be a replica of the source table. Alternatively, the target can be an append log of updates or a list of change events representing updates, inserts, deletes on the table.
- Automated schema evolution
For scheduled data movement, the schema of the source table can get updated. The data movement service should be able to automatically adapt to changes.
- Filtering
The original source table or event may have fields that needs to be filtered from the target. For instance, only a subset of columns from the source table may be required on the target. Additionally, filtering can be for deduping duplicate records. Depending on the type of analytics, filtering of deleted records could need special handling. For example, financial analytics require deleted records to be available marked with a delete flag (called a soft delete) instead of the actual delete (a hard delete).
- Aggregation
In scenarios where the source data is sharded across multiple silos, the transformation logic aggregates and creates a single materialized view. Aggregation can also involve enriching data by joining across sources.
Compliance Requirements
During data movement, you should consider multiple aspects of compliance. Figure 4-2 represents “Maslow’s hierarchy of requirements” that should be considered. At the bottom of the triangle are the three As of compliance: authentication, access control, and audit tracking. Above that are considerations for handling personally identifiable information (PII) with regard to encryption as well as masking. Next up are any requirements specific to regulatory compliance such as SOX, PCI, and so on. At the top is data rights compliance with laws such as CCPA, GDPR, and so on.
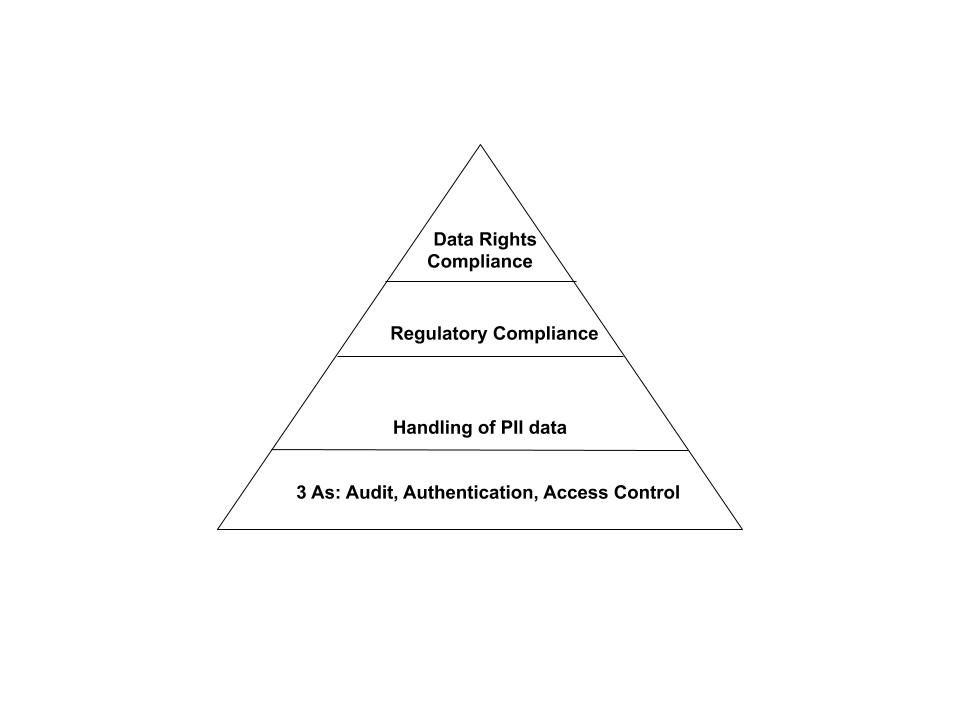
Figure 4-2. Hierarchy of compliance requirements to be considered during data movement
Verification Requirements
Ensuring the source and target are at parity is critical for the data movement process. There are different parity check requirements that can be defined depending on the type of analytics and nature of data that is involved. For instance, row count parity to ensure all the source data is reflected on the target. Sampling parity where a subset of rows are compared to verify that records on source and target match exactly and there was no data corruption (such as data columns appearing as null) during the data movement. There are multiple other quality checks such as column value distributions and cross-table referential integrity, which are covered in Chapter 8. If the errors are detected, the data movement service should be configured to either raise the alert or make the target data unavailable.
Non-functional Requirements
Similar to any software design, the following are some of the key NFRs that should be considered in the design of a data movement service:
- Ease of onboarding for new source datastores
Simplifying the experience of data source owners in onboarding to the service. Applicability to support a wide range of source and target datastores
- Automated monitoring and failure recovery
Ability to checkpoint and recover from any data movement failures. This is especially important when large tables are being moved. Also, the solution should have a comprehensive monitoring and alerting framework.
- Minimizing performance impact on data source performance
Data movement should not slow down performance of data sources as this can directly impact application user experience.
- Scaling of the solution
Given the constant growth of data, support for thousands of daily scheduled data moves.
Open-source technology used extensively by the community: In selecting open-source solutions, there are several graveyard projects. Ensuring the open-source project is mature and extensively used by the community.
Implementation Patterns
As discussed in the previous section, there are four modules of the data movement service: Ingestion, Transformation, Compliance, and Verification module. This chapter focuses on the patterns that implement the Ingestion and Transformation modules. The patterns for Compliance and Verification modules are generic building blocks, and are covered in Chapters 9 and 17 respectively.
Given the rate of rapid innovation, any list of available commercial and open-source technologies will soon become outdated. Our approach in this book is to instead focus on implementation patterns underlying these technologies. This section covers the following patterns:
Batch Ingestion pattern
Continuous Change Ingestion pattern
Event ingestion pattern
Batch Ingestion Pattern
Batch Ingestion is a traditional pattern that was popular in the early days of the big data evolution. It is applicable for both one-time as well as scheduled data movement. The term batch implies that updates on the sources are grouped together and then periodically moved to the target. Batch ingestion is typically used for data movement of large sources that doesn’t have a requirement for real-time updates. The batch process is typically scheduled every 6-24 hours.
There are three phases to the batch ingestion pattern (as shown in Figure 4-3):
- Partition phase
The source table to be copied is logically partitioned into smaller chunks to parallelize the data move.
- Map phase
Each chunk is allocated to a Mapper (in the MapReduce terminology). A Mapper fires queries to read data from the source table and copies to the target. Using more mappers will lead to a higher number of concurrent data transfer tasks, which can result in faster job completion. However, it will also increase the load on the database potentially saturating the source. For incremental table copies, the mappers process the inserts, updates, deletes to the source table since the last update.
- Reduce phase
The output of the mappers in stored as staging files and combined by the Reducer into a single materialized view on the target data store. Reducers can also implement transformation functions.

Figure 4-3. Batch Ingestion pattern involves using Map phase (of MapReduce) to partition the source data object and parallel copy into the target data object
A popular implementation of the batch ingestion pattern is Apache Sqoop (https://sqoop.apache.org/). Sqoop is used for bulk data movement typically between relational databases and filesystems to Hadoop Distributed File System (HDFS) and Apache Hive. It is implemented as a client-server model -- the clients are installed on source and target datastores, and the data movement is orchestrated as MapReduce jobs by the Sqoop server that coordinates with the clients. The technology-specific adapters for connecting to the datastores are installed on the client (in the newer Sqoop2 version, the drivers are installed on the server). Data movement is a MapReduce job where the Mappers on the source clients would be transporting the data from the source, while the Reducers on the target clients would be copying and transforming the data. Sqoop supports both full table refresh as well as incremental table copy based on a high watermark.
Strengths of the Batch Ingestion pattern include the following:
Traditional data movement pattern applicable to a wide range of source and target datastores. Minimal effort required by data source owners to onboard, manage and maintain their source datastores.
Supports scaling to 1000s of daily scheduled data moves. Implements failure recovery leveraging MapReduce.
In-built support for data validation after copy
Weaknesses of the Batch Ingestion pattern include the following:
Does not support data refresh in near real-time
Potential impact on the performance of source datastores. Also, potential compliance concern with JDBC connection used to connect source datastores that are under regulatory compliance
Limited support for incremental table refresh with hard deletes. Limited support for data transformation capabilities
No support for schema evolution at source
Batch ingestion is a good starting point for organizations early in the Big Data journey. Depending on the maturity of the analytics teams, batch-oriented might be sufficient. Data engineering teams typically use this pattern to get fast coverage on the available data sources.
Database Change Data Capture Ingestion Pattern
As organizations mature beyond Batch ingestion, they move to the Change Data Capture (CDC) pattern.It is applicable for ongoing data movement where the source updates need to be available on the target with low latency (order of seconds or minutes). CDC is implies capturing every change event (updates, deletes, inserts) on the source and applying the update on the target. This pattern is typically used in conjunction with batch ingestion that is used for the initial full copy of the source table while the continuous updates are done using the CDC pattern.
There are three phases to the CDC ingestion pattern (as shown in Figure 4-4):
- Generating CDC events
A CDC adapter is installed and configured on source database. The adapter is a piece of software that is specific to the source data store for tracking inserts, updates, deletes to the user-specified table.
- CDC published on event bus
CDC is published on the event bus and can be consumed by one or more analytics use-cases. The events on the bus are durable and can be replayed in case there are failures.
- Merge of events
Each event (insert, delete, update) is applied to the table on the target. The end result is a materialized view of the table that lags the source table with a low latency. The metadata corresponding to the target table is updated in the data catalog to reflect refresh timestamp and other attributes.

Figure 4-4. The phases of a CDC ingestion pattern
There is a variant of the CDC ingestion pattern where the events can be consumed directly instead of a merge step (that is, excluding step 3 in Figure 4-4). This is typically applicable for scenarios where raw CDC events are transformed into business-specific events. Another variant is to store the CDC events as a time-based journal which is typically useful for risk and fraud detection analytics.
A popular open-source implementation of the CDC ingestion pattern is Debezium (https://debezium.io/) combined with Apache Kafka (https://kafka.apache.org/). Debezium is a low latency CDC adapter. Debezium captures committed database changes in a standardized event model irrespective of the database technologies. The event describes what changed, when and where. Events are published on Apache Kafka in one or more Kafka topics (typically one topic per database table). Kafka ensures that all the events are replicated and totally ordered, and allows many consumers to independently consume these same data change events with little impact on the upstream system. In the event of failures during the merge process, it can be resumed exactly where it left off. The events can be delivered exactly-once or at-least-once -- all data change events for each database/table are delivered in the same order they occurred in the upstream database.
For merging the CDC records into materialized target table, the popular approaches are using either batch-oriented using MapReduce or streaming-oriented using technologies such as Spark. Two popular open-source solutions: Apache Gobblin (https://gobblin.apache.org/) uses MapReduce while Uber’s Marmaray (https://github.com/uber/marmaray) uses Spark. The merge implementation in Gobblin includes de-serialization/extract, convert format, validate quality, and write to the target. Both Gobblin and Marmaray are design for any source to any target data movement.
Strengths of the CDC pattern include the following:
CDC pattern is a low latency solution to update the target with minimal performance impact on the source datastore.
CDC adapters available are available for a wide-range of datastores
Supports filtering and data transformation during the data movement process
Supports large tables using incremental ingestion
And here are some of the weakness of the CDC pattern:
Ease of onboarding is limited given expertise required for selecting optimal configuration options of CDC adapters.
Robustness at scale given the complexity of update merges.
Requires table with a CDC column to track incremental changes.
Merge implementations using Spark (instead of Hadoop MapReduce) may encounter issues for very large tables (order of billion rows)
Supports limited filtering or data transformation
This approach is great for large fast-moving data. It is employed widely and is one of the most popular approaches. The approach requires operational maturity across source teams and data engineering teams to ensure error-free tracking of updates, and merging of the updates at scale.
Event Aggregation Pattern
The Event Aggregation pattern is a common pattern for aggregating log files as well as application events where these events are required to be aggregated on an ongoing basis in real-time for fraud detection, alerting, IoT, and so on. The pattern is increasingly applicable with the growing number of logs namely web access logs, ad logs, audit logs, syslog, as well as sensor data.
The pattern involves aggregating from multiple sources, unifying into a single stream, and make it available for batch or streaming analytics. There are two phases to the pattern (as shown in Figure 4-5):
- Event forwarding
Events and logs from edge nodes, log servers, IoT sensors and so on are forwarded to the aggregation phase. Light-weight clients are installed to push logs in real-time.
- Event aggregation
Events from multiple sources are normalized, transformed and made available to one or more targets. Aggregation is based on streaming data flows: streams of events are buffered and periodically uploaded to the data store targets

Figure 4-5. The phases of an Event aggregation pattern
A popular implementation of the pattern is Apache Flume (https://flume.apache.org/). As a part of the data movement, a configuration file defines the sources of events and the target where the data is aggregated. Flume’s source component picks up the log files and events from the sources and sends it to the aggregator agent where the data is processed. Log aggregation processing is stored in the memory and streamed to the destination.
Flume was originally designed to quickly and reliably stream large volumes of log files generated by web servers into Hadoop. Today, it has evolved to handle event data including sources like Kafka brokers, Facebook, and Twitter. Other popular implementations are Fluent Bit (https://fluentbit.io/) and Fluentd (https://www.fluentd.org/), which are popular as open source log collector and log aggregator.
Strengths of the Event Aggregation pattern are:
Event aggregation pattern is a real-time solution optimized for logs and events. Highly reliable, available, and scalable (horizontally).
Minimal impact on source performance
Highly extensible and customizable, as well as incurs minimal operational overhead
Supports filtering and data transformation during the data movement process
Scales to deal with large volumes of log and event data
Weakness of the Event Aggregation pattern are:
Does not provide ordering guarantee for the source events
At Least once instead of exactly once delivery of messages requiring target to deal with duplicate events
In summary, this pattern is optimized for logs and events data. While it is easy to get started, it is designed for analytics use-cases that can handle out-of-ordering of data as well as duplicate records.
Summary
Data can be in the form of tables, streams, files, events, and so on. Depending on the type of analytics, the data movement may have different requirements w.r.t. refresh lag and consistency Depending on the requirements and the current state of the data platform, the movement service should be designed to move data between any source to any target using one or more patterns in this chapter.
References